- The paper presents VLA-Reasoner, a framework that integrates online Monte Carlo Tree Search with pretrained vision-language-action models to improve long-horizon planning in robotic manipulation.
- It employs a KDE-based expert prior and dense image-based reward shaping to simulate future states, thereby mitigating successive errors from short-sighted predictions.
- Experimental evaluations reveal average improvements of 5–9.8% and relative gains up to 86.4% across both simulated and real-world tasks without additional retraining.
VLA-Reasoner: Test-Time Reasoning for Vision-Language-Action Models via Online Monte Carlo Tree Search
Motivation and Problem Statement
Vision-Language-Action (VLA) models have demonstrated strong generalization in robotic manipulation by leveraging large-scale imitation learning and grounded vision-language representations. However, their deployment is fundamentally limited by short-sighted action prediction: VLAs typically map current observations and language instructions to the next action without explicit consideration of long-horizon consequences. This myopic approach leads to incremental deviations, compounding errors, and suboptimal performance in tasks requiring sequential reasoning or precise manipulation.
The paper introduces VLA-Reasoner, a plug-in framework designed to augment off-the-shelf VLAs with test-time reasoning capabilities. The core objective is to enable VLAs to foresee and reason about future states by simulating possible action trajectories, thereby mitigating the limitations of short-horizon prediction and improving robustness and interpretability in robotic manipulation.
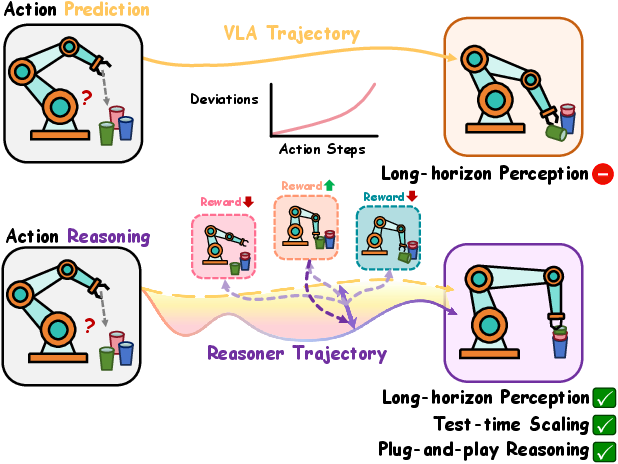
Figure 1: VLA-Reasoner augments VLA models with test-time reasoning via online tree search, enabling more robust and interpretable robotic manipulation than baselines.
Methodology: Online Monte Carlo Tree Search for VLA Reasoning
VLA-Reasoner operates as a test-time wrapper around any pretrained VLA policy. The framework leverages a lightweight, modified Monte Carlo Tree Search (MCTS) to explore possible future action trajectories, using a learned world model to simulate state transitions. The process is structured as follows:
- Expansion: Candidate actions are sampled from a KDE-based expert-like prior, efficiently generating plausible action sets for tree expansion.
- Simulation: Each candidate action is rolled out in a learned world model, predicting the resulting future state.
- Backpropagation: Rewards for intermediate states are estimated via a vision-based reward shaping network, enabling dense feedback and correction of deviations.
- Selection: The optimal action is selected using an Upper Confidence Bound (UCB) strategy, balancing exploitation and exploration.
The final action executed by the robot is a convex combination of the VLA's original prediction and the reasoned action from MCTS, controlled by an injection strength parameter α.
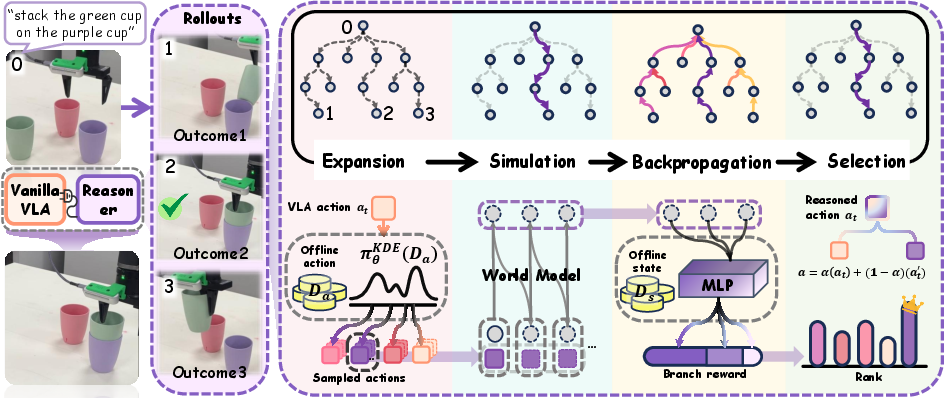
Figure 2: The overall pipeline of VLA-Reasoner, showing MCTS-based search, expert-like sampling, and reward shaping for plug-and-play augmentation of VLA policies.
Efficient Sampling and Reward Shaping
Kernel Density Estimation (KDE) is employed to model the distribution of expert actions from offline data, providing a non-parametric prior for action sampling. This approach reduces redundant VLA queries and improves exploration efficiency. For reward estimation, a frozen ResNet-34 encoder and a lightweight MLP are trained to regress visual progress, providing dense, image-based rewards for intermediate states. This design avoids sparse episode-level feedback and enables stable long-horizon guidance.
Experimental Evaluation
Simulation Benchmarks
VLA-Reasoner is evaluated on LIBERO and SimplerEnv benchmarks, wrapping three popular VLA policies: OpenVLA, Octo-Small, and SpatialVLA. Across diverse manipulation tasks, VLA-Reasoner consistently improves success rates over both vanilla VLAs and specialized variants. Notably, the method achieves an average absolute improvement of 5–9.8% over baselines, outperforming state-of-the-art models even without additional post-training or architectural modifications.
Real-World Robotic Manipulation
In real-world deployments on a Galaxea-A1 robot arm, VLA-Reasoner demonstrates substantial gains in success rates for challenging manipulation tasks. When attached to OpenVLA and π0-FAST, the framework yields absolute improvements of 19% and 10%, respectively, with relative gains up to 86.4%. The method is robust to embodiment gaps and environment shifts, providing adaptive correction of action drift and misalignment.

Figure 3: Setup of real world experiments, illustrating the diversity of tasks and robot embodiments used to validate VLA-Reasoner.
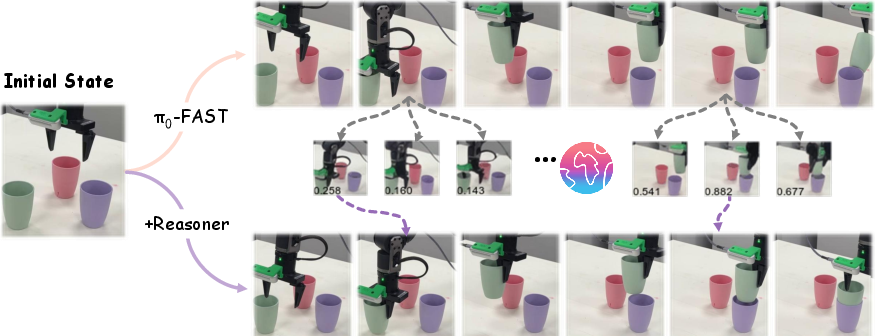
Figure 4: Case Visualization. The baseline policy (π0-FAST, top row) suffers from excessive action drift and fails by such deviations. With reasoning, VLA-Reasoner (bottom row) proactively corrects misalignment via reward-guided search, enabling success.
Ablation Studies
Ablation analysis reveals that moderate injection strengths (α=0.4–$0.6$) yield optimal performance, balancing the benefits of VLA generalization and reasoned correction. KDE-based sampling and image-based reward shaping are validated as critical components, outperforming noisy sampling and token-based reward heads.
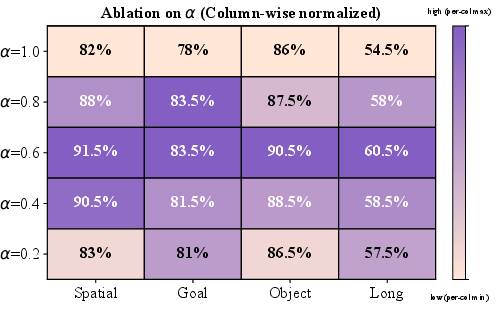
Figure 5: Analysis on injection strength α. α controls the trade-off between the VLA action and the reasoner action; a larger α assigns greater weight to the VLA action. α=1.0 means the vanilla VLA.
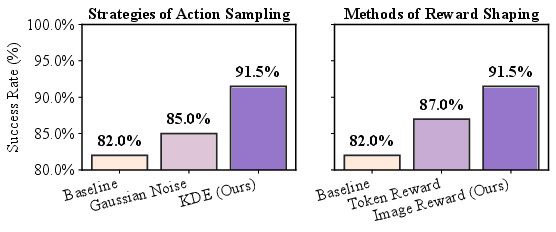
Figure 6: Analysis on Techniques. The comparison validates the design in our method, which is reflected by the significant growth in the success rate.
Implementation Considerations
- Computational Overhead: The framework introduces minimal additional latency due to efficient sampling and shallow reward networks. The world model is finetuned on small datasets, including failure cases, to improve fidelity without extensive retraining.
- Plug-and-Play Design: VLA-Reasoner is agnostic to the underlying VLA architecture and can be attached to any manipulation policy, facilitating rapid deployment and evaluation.
- Scalability: The method scales to large action spaces and diverse robot embodiments, with performance gains observed across both simulation and real-world settings.
Implications and Future Directions
VLA-Reasoner addresses a fundamental limitation in current VLA deployment by injecting structured, test-time reasoning without retraining or architectural changes. The approach demonstrates that scalable test-time computation, guided by model-based planning and expert priors, can substantially improve the robustness and generalization of embodied policies.
Future research may focus on enhancing world model fidelity, developing more principled reward functions, and integrating data-driven or learning-based reward shaping. These directions are orthogonal to the main contribution and promise further improvements in long-horizon reasoning and manipulation.
Conclusion
VLA-Reasoner provides a principled framework for augmenting vision-language-action models with online reasoning via Monte Carlo Tree Search. By simulating future trajectories and leveraging expert priors and dense visual rewards, the method mitigates incremental deviations and improves manipulation performance in both simulation and real-world environments. The plug-and-play design, empirical gains, and robustness to embodiment gaps position VLA-Reasoner as a compelling paradigm for scalable, general-purpose robotic manipulation. Future work will likely build on this foundation to explore more sophisticated world models and reward mechanisms, advancing the capabilities of embodied AI systems.