- The paper introduces a teacher-guided framework that integrates structured chain-of-thought rationales to improve robotic control policies.
- It employs a multi-objective fine-tuning process that jointly optimizes action prediction and rationale generation, using selective layer freezing.
- Experimental results demonstrate significant improvements in task success and interpretability across benchmarks, validating the approach’s effectiveness.
Detailed Summary of ReFineVLA
The paper introduces ReFineVLA, a teacher-guided, multimodal reasoning-aware fine-tuning framework for vision-language-action (VLA) models. The method augments conventional robotic demonstration datasets with structured natural-language rationales generated by an expert teacher model. These reasoning traces, which capture explicit observation, situational analysis, spatial reasoning, and task planning, are leveraged via a multi-objective learning formulation that jointly optimizes action prediction and rationale generation. This augmentation allows the model to go beyond direct, reactive mappings and incorporate step-by-step multimodal reasoning into its control policies.

Figure 1: Visualization of Attention Tokens in standard VLAs, demonstrating the narrow focus on immediate visual elements.
Multimodal Reasoning and Data Augmentation
A central component of ReFineVLA is to address the inherent limitation of pretrained VLAs that only learn to output actions without explicit reasoning. To this end, the authors seed a large-scale dataset (~125,000 trajectories) with detailed reasoning annotations generated via an expert teacher (e.g., Gemini-2.0) using a structured chain-of-thought (CoT) prompt. The annotated rationales cover:
Fine-Tuning Framework and Learning Objectives
ReFineVLA builds upon a pretrained 3.5B VLA model, such as SpatialVLA, and employs selective transfer fine-tuning that targets the upper transformer layers and the policy head. Lower layers, which capture general visual-linguistic representations, remain frozen to preserve domain-general knowledge. The combined loss function is formulated as
Ltotal=Laction+λrLreasoning,
where the action prediction loss ensures accurate replication of expert actions and the reasoning loss encourages the generation of structured rationales. The hyperparameter λr is critical; experiments show that setting λr=0.3 results in an average 9.7% improvement in task success, while too high or too low values degrade performance.
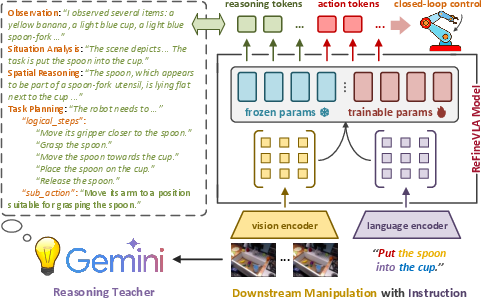
Figure 3: Overview of ReFineVLA's Training Flow demonstrates the integration of reasoning supervision into the fine-tuning pipeline where visual, language, and action inputs are fused to produce interpretable policies.
The paper details an efficient implementation using a combination of automated reasoning trace generation (with multi-view image aggregation) and selective parameter freezing, making the method both computationally tractable and effective.
Experimental Evaluation and Numerical Results
ReFineVLA is evaluated on diverse simulated manipulation benchmarks across Google Robot and WidowX tasks within the SimplerEnv framework. On the WidowX benchmark, ReFineVLA achieves an average task success of 47.7%, improving performance by 5.0% over the second-best baseline. In visually and contextually diverse scenarios on Google Robot tasks, Quantitative gains are reported as follows:
- In the Visual Matching setting, the method scores an average success of 76.6%, with a notable 9.6% improvement on the Move Near task compared to SpatialVLA.
- In the Variant Aggregation setting, an average success of 68.8% is achieved, with improvements of 8.2% on challenging Open/Close Drawer tasks.
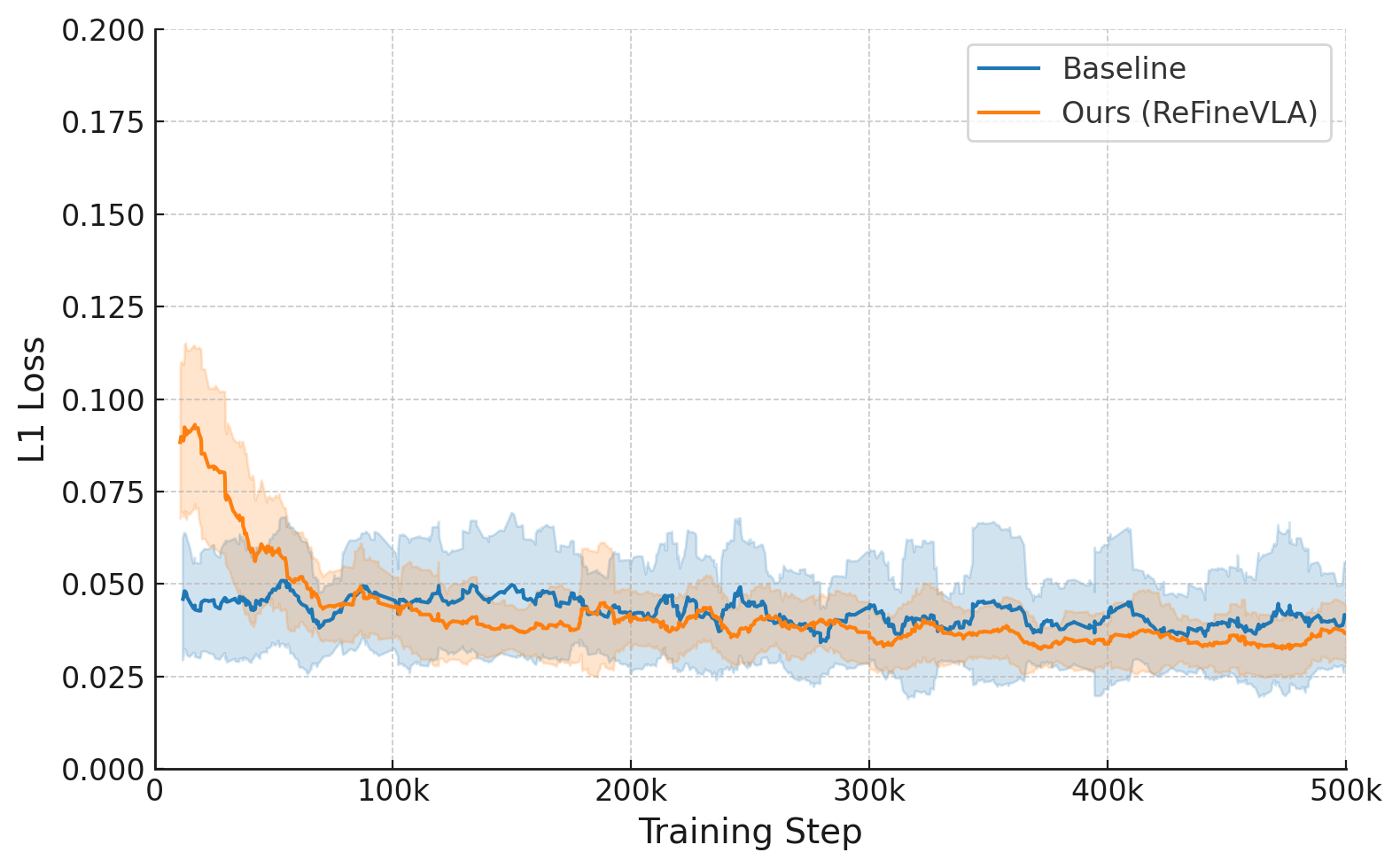
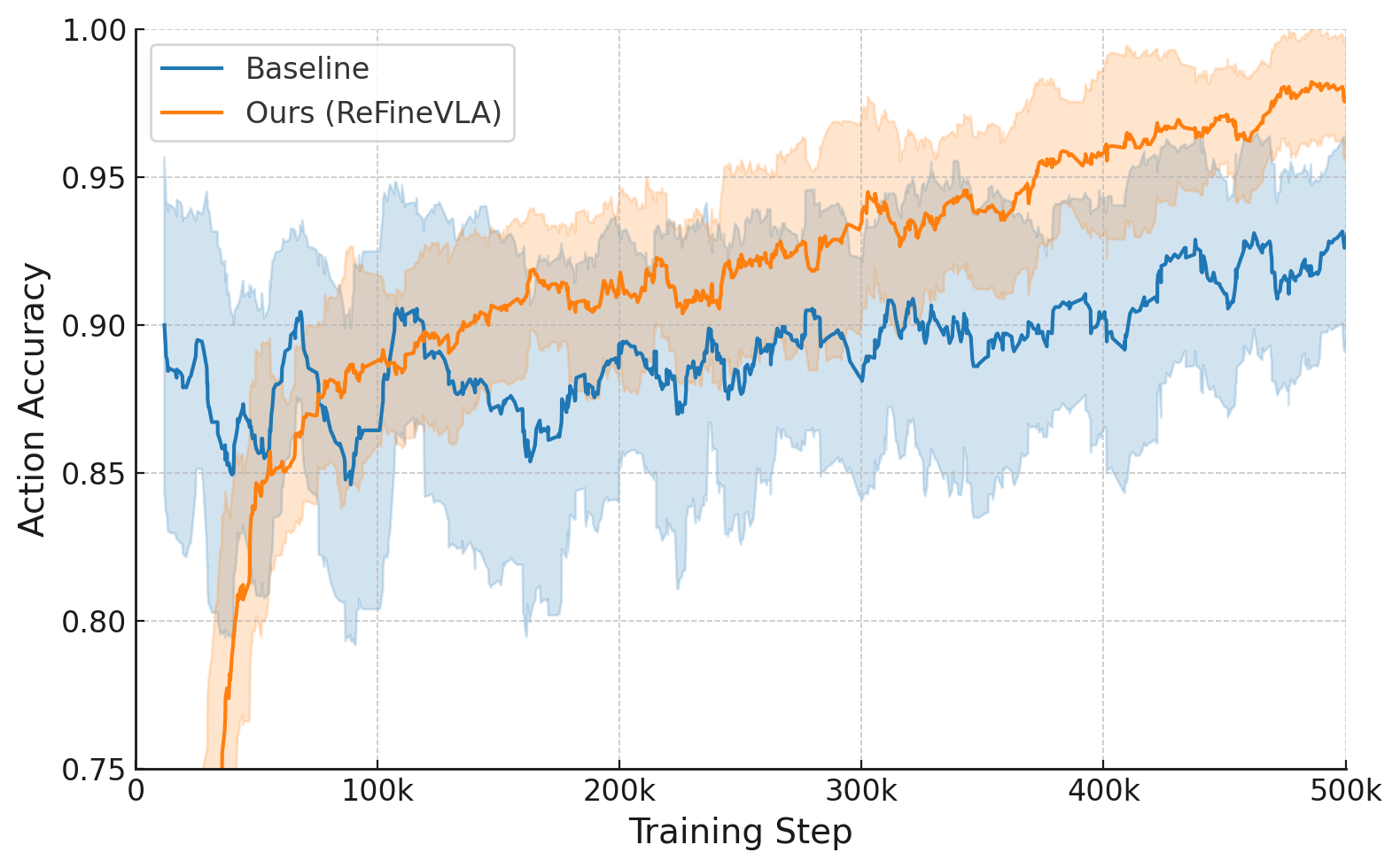
Figure 4: Training Loss and Action Accuracy During fine-tuning on the Fractal dataset, where ReFineVLA’s L1 loss decays more swiftly and action accuracy consistently surpasses that of the baseline, indicating efficient and stable learning dynamics.
Attention and Interpretability Analysis
The authors perform an in-depth attention analysis comparing standard VLAs to ReFineVLA. Prior to fine-tuning, conventional models display narrow attention profiles that focus only on immediate action cues. Post ReFineVLA training, attention maps reveal broader, semantically-aware focus that aligns with task instructions and spatial relationships. This indicates that the explicit reasoning supervision enables the model to form richer inter-modal correspondences and more interpretable decision-making processes.

Figure 5: Attention Visualization of ReFineVLA versus SpatialVLA, highlighting enhanced focus on related object regions conditioned on given prompts after reasoning-aware fine-tuning.
Chain-of-Thought Reasoning in Action Generation
ReFineVLA’s explicit chain-of-thought reasoning is further examined through qualitative examples. The model generates step-by-step rationales that effectively decompose complex manipulation tasks into actionable subsequences. For example, in tasks such as “Move the coke can near the orange” and “Close the drawer,” the system outputs detailed reasoning that encompasses object detection, spatial estimation, and temporal sequencing before issuing corresponding control commands.

Figure 6: Example of Chain-of-Thought Reasoning from ReFineVLA, where coherent multi-step rationales directly drive the subsequent robotic actions.
Implications and Future Directions
The proposed framework has both practical and theoretical implications. Practically, integrating explicit multimodal reasoning into VLA models results in improved generalization across diverse environments, robust handling of long-horizon tasks, and enhanced interpretability of robotic policies. Theoretically, this work underscores the effectiveness of combining chain-of-thought supervision with selective fine-tuning to bridge the gap between perception and decision-making. Future research may extend these methods to real-world robotic systems, explore human-in-the-loop refinement, and investigate memory mechanisms to further bolster long-horizon planning capabilities.
Conclusion
ReFineVLA represents a methodical advance in the design of generalist robotic policies by leveraging teacher-guided multimodal reasoning supervision. Its careful integration of structured chain-of-thought annotations into the fine-tuning process leads to significant quantitative improvements and enhances the interpretability of model predictions. The approach establishes a promising basis for future developments in reasoning-driven, vision-language-action models in robotics.


