Adopt $\neq$ Adapt: Longitudinal Analyses of LLM Conversations in the Wild
Abstract: Although a growing body of research has begun to describe user--LLM interactions, the picture it paints is largely static; little is known about how individual users change their behavior over time. To address this gap, we analyze the conversational trajectories of $\sim$12,000 randomly sampled Microsoft Bing Copilot users and compare these with data from WildChat-4.8M. While the Copilot data contains significant population-level trends, we find that trends in individual user trajectories are much weaker; user habits prove to be overwhelmingly sticky. We also find stark differences between users of different activity levels: more active users have more successful conversations and use the LLM for more complex and professionally oriented tasks. Some user trends also appear in WildChat-4.8M, but we find evidence that this dataset is significantly skewed towards highly proficient "power" users. Ultimately, our results suggest that existing user behavior is difficult to change and demonstrate the extent of user heterogeneity. Our comparison between datasets highlights that WildChat does not represent typical user-AI interactions, an important caveat for downstream uses of the data.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper studies how people actually use AI chatbots over time. Instead of just taking a snapshot of chats on one day, the researchers followed the same users across months to see whether they “adapt” their habits. They looked at two places:
- Microsoft Bing Copilot (a popular chatbot used by everyday people)
- WildChat-4.8M (a public dataset of chats collected from free GPT tools hosted on Hugging Face)
Their big idea: adopting an AI tool isn’t the same as adapting your behavior. Do people really change how they use AI as they gain experience?
What did the researchers want to find out?
In simple terms, they asked:
- Do individual people change how they talk to an AI over time, or do their habits stay the same?
- How do heavy users (“power users”) differ from casual users?
- Are the patterns seen in a public dataset (WildChat) similar to those from a mainstream tool like Bing Copilot?
- What types of tasks do people try, how complex are their messages, and how often do they get what they wanted?
How did they study it?
The two datasets
- Bing Copilot: They followed about 12,000 randomly chosen users over six months in 2024. They split people into activity groups by how many days they used Copilot in that period:
- Low: 1–10 days
- Middle: 11–25 days
- High: 26+ days
- WildChat-4.8M: A big public dataset of chats. Because it doesn’t have user accounts, they used hashed IP addresses as a rough stand-in for “users.” They filtered out suspicious cases (like shared networks or huge volumes) and focused on chats before September 2024 to avoid later spikes of automated, non-conversational use.
What they measured
Think of each conversation like a mini project. For each conversation, they looked at:
- Usage intensity: How many messages per conversation? How many conversations per day?
- Linguistic complexity: How long the sentences were, as a simple stand-in for “how detailed or complex are the prompts.”
- Task completion: Did the AI actually do the main thing the user seemed to want? (Important note: if there was no clear task—like just saying “Hi”—this counted as “incomplete.” So “completion” is partly about how concrete the task was.)
- Intent: What was the user trying to do? For example, “look up information,” “summarize,” “generate text,” “translate,” etc.
- Domain: What topic area was the chat about? For example, “programming,” “creative writing,” “entertainment,” “travel,” etc.
To label intent, domain, and completion, they used an AI classifier (another model) carefully prompted to tag each conversation.
How they compared over time
- Population-level trends: What’s changing for all users as a group month by month?
- Individual trajectories: For each person, how do their own habits shift from their early days to later days?
“Longitudinal” here means tracking the same people over time. A helpful analogy: instead of measuring how fast students run on one day, you track each student’s running times across an entire season to see who actually improves.
What did they discover?
Here are the main takeaways, explained simply:
- People’s habits are “sticky.”
- At the individual level, most users don’t change much. How they write, what they try, and whether they complete tasks stays surprisingly steady over their personal timeline.
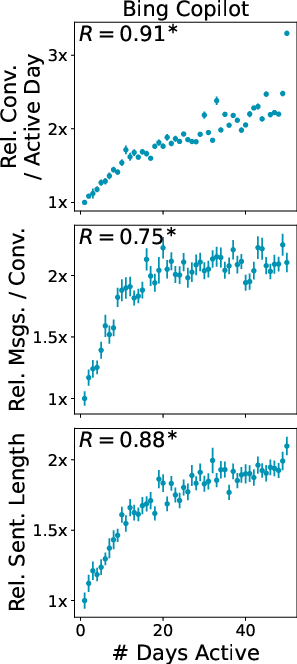
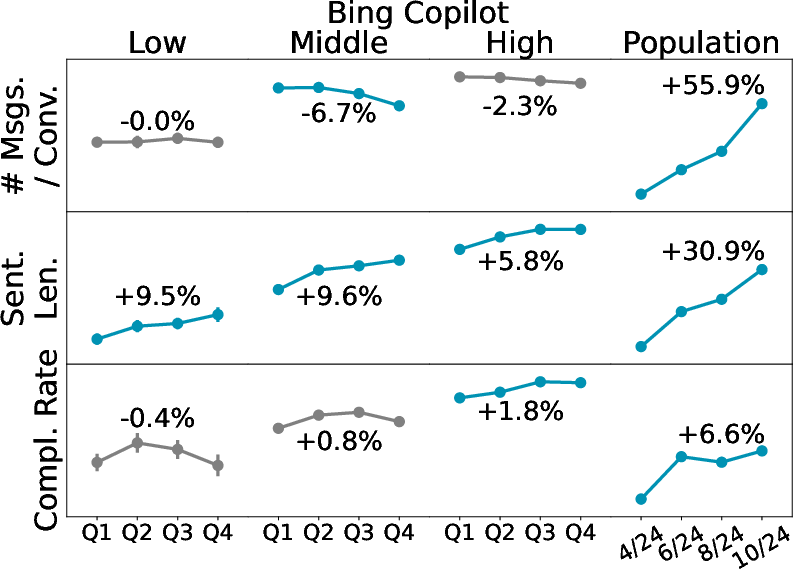
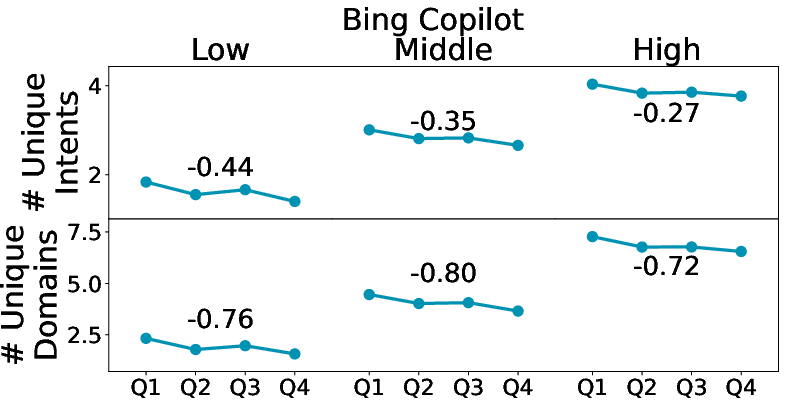
- Heavy users look different from casual users—and from the start.
- In Bing Copilot, the most active users:
- Send more messages and write more complex prompts
- Aim for more complex and professional tasks (like programming or professional writing)
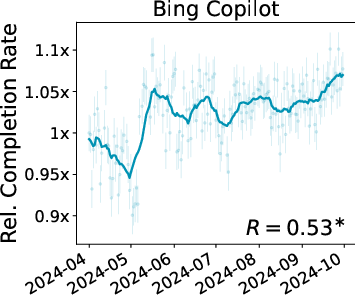
- Have more “completed” conversations (they get what they wanted more often)
- Crucially, these differences are visible very early, not just after months of use. This suggests that people who become “power users” arrive with different goals and styles, rather than learning to change later.
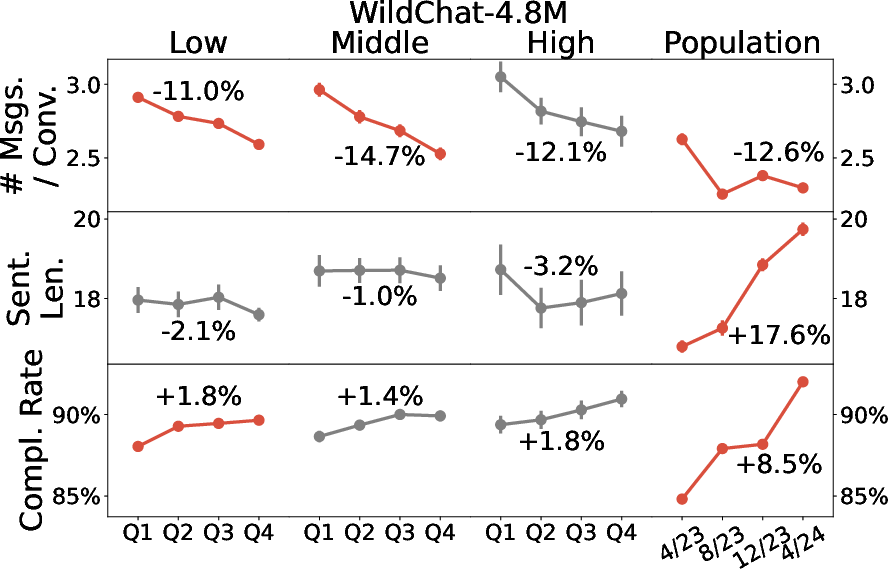
- The group changes even if individuals don’t.
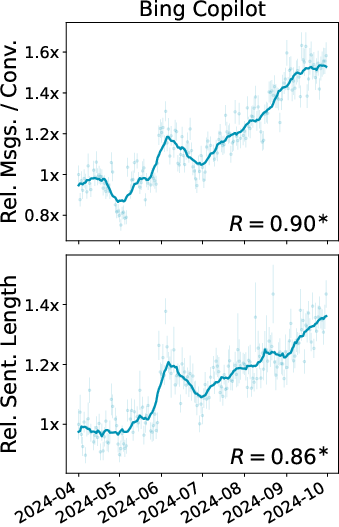
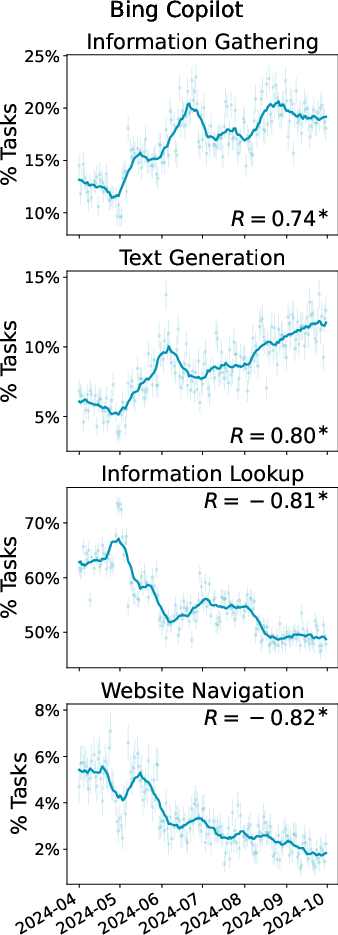
- In Bing Copilot, across the months, the overall user base starts doing more complex tasks and writing more complex prompts, and completion rates go up.
- But this is mostly because new users joining later are different from earlier users—not because the same individuals are learning and changing a lot.
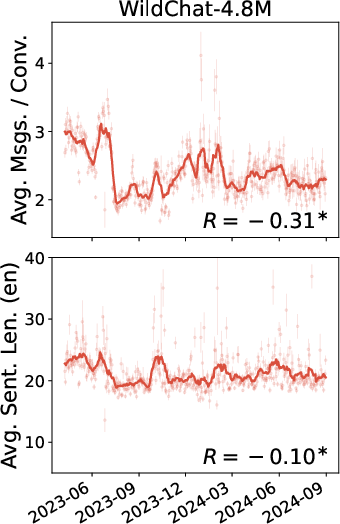
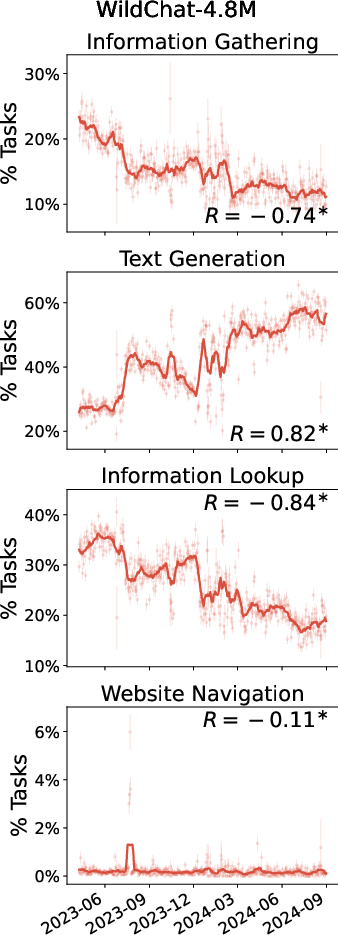
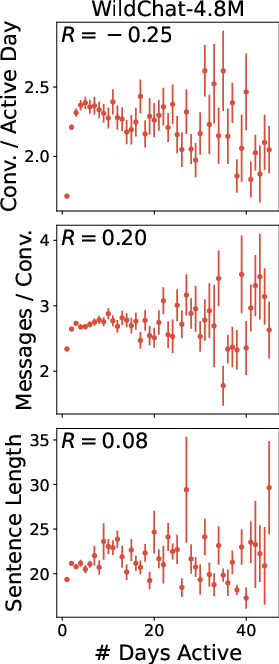
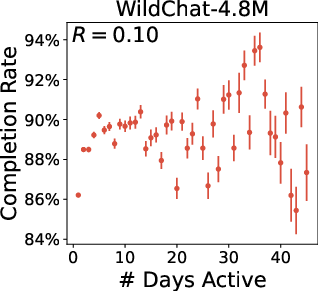
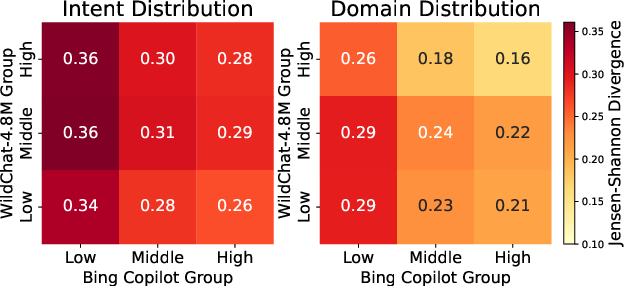
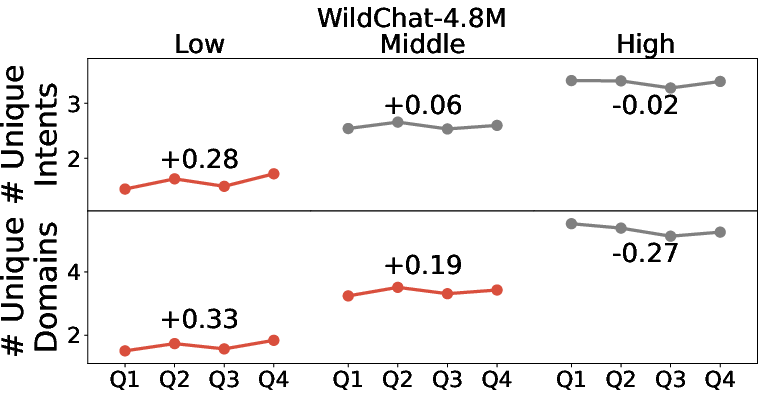
- WildChat looks less like typical casual users and more like “power users.”
- In WildChat, differences between low- and high-activity users are much smaller.
- Many WildChat conversations look “API-like”—short, templated prompts used to run bulk tasks (like translation over and over). That’s not how most people chat normally.
- As a result, WildChat doesn’t fully represent the average person’s chatbot use.
- Some trends are shared, but not all.
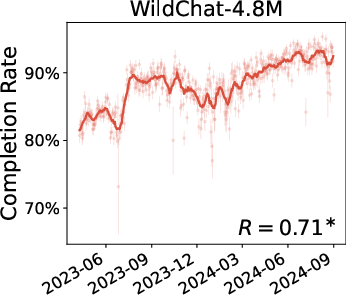
- Both datasets show certain population-level shifts (like increased completion over time), but the details often differ.
- Overall, WildChat is skewed toward heavier, more technical use, while Bing Copilot reflects broader everyday usage.
Why this is important:
- If we only look at the population as a whole, we might mistakenly assume individuals are “learning” a lot. The user-level view shows that most people don’t change much; it’s the mix of who’s using the system that changes.
Why does this matter?
- Don’t count on “natural discovery.” Because habits are sticky, many people won’t magically find better ways to use AI just by using it more. Designers may need to actively help users improve, for example with:
- Smart tips, onboarding tours, starter templates, or examples tailored to the user’s goals
- Gentle nudges that suggest more effective prompts or features
- One size doesn’t fit all. Users vary widely. Tools and help messages could adapt to whether someone is a casual or heavy user, and to the kinds of tasks they’re doing.
- Be careful with public chat datasets. WildChat is popular for research, but it doesn’t look like typical consumer use:
- It overrepresents “power users” and includes lots of automated, template-like prompts.
- Models trained or evaluated on it might not match what everyday users actually do.
- Population trends aren’t the same as personal change. When usage looks more advanced over time, it might be because new, different users are joining—not because the same people are changing their behavior.
In short: Adopting an AI chatbot doesn’t mean people naturally adapt their habits. Most individuals stay consistent, power users are different from the start, and public datasets like WildChat can paint an unbalanced picture of how people use AI in the real world.
Knowledge Gaps
Below is a list of knowledge gaps, limitations, and open questions identified in the research paper "Adopt Adapt: Longitudinal Analyses of LLM Conversations in the Wild":
Knowledge Gaps and Limitations
- Limited Scope of User Data: The research only evaluates interactions with the Microsoft Bing Copilot and WildChat dataset within specified time periods. Further studies could analyze users across various LLM platforms and longer durations.
- User Behavior Evolution: While population-level trends are identified, the paper notes that individual user habits remain largely unchanged over time. This calls for a deeper investigation into why habits are "sticky" and what mechanisms might enable behavioral change.
- User Identification in WildChat Data: The analysis uses hashed IP addresses as proxies for user identification in WildChat, which could result in inaccuracies due to shared networks or device changes. Future work should address more precise methods for user identification.
- Complexity of Completed Tasks: Completion rates are used as a proxy for task success, yet the analysis considers task completion without accounting for varying levels of task complexity. Future work should integrate metrics that measure task difficulty more precisely.
- Exploration vs. Exploitation Dynamics: The shift from exploration to exploitation in user behavior is minimally studied. Research could further investigate the factors that influence users to explore or exploit different intents and domains.
Open Questions
- Factors Influencing High Activity Levels: What specific factors or user characteristics contribute to users becoming "power users" as opposed to occasional users? Identifying these factors could lead to methods for fostering more complex interactions with LLMs.
- Impact of Guided Interventions: Given the inherent stickiness of user habits, what types of proactive interventions would effectively assist users in discovering successful LLM use cases? How could these interventions be implemented within LLM platforms?
- Generalization Across Datasets: How can discrepancies between datasets like Bing Copilot and WildChat affect research findings? Can methodologies be developed to ensure consistent generalization to typical LLM interactions across different platforms?
Practical Applications
Immediate Applications
Below are actionable opportunities that can be deployed with current capabilities, derived from the paper’s findings and methods.
Industry (software, search, productivity suites, developer tools, customer support)
- Segment-and-serve user cohorts by activity level
- What: Build analytics and personalization that classify users early (e.g., within 1–3 active days) into “casual” vs “power” cohorts, and tailor prompts, help content, and UI accordingly.
- Tools/workflows: Cohort dashboards; early-signal models using messages-per-conversation, conversations-per-day, and prompt complexity; cohort-specific onboarding flows.
- Sectors: Software, search, productivity suites, developer tools, B2B SaaS.
- Assumptions/dependencies: Access to telemetry; privacy-preserving aggregation; stable mapping from early signals to long-term behavior on your platform.
- “Task discovery” onboarding and nudges to counter habit stickiness
- What: Proactively recommend higher-value, concrete, and professional tasks (e.g., research, structured analysis, text generation) rather than expecting users to discover them through exploration.
- Tools/workflows: Intent-aware templates, dynamic prompt suggestions, “explore a new intent” micro-coaching; periodic “Try this next” cards.
- Sectors: Productivity suites, search, customer support, education platforms.
- Assumptions/dependencies: High-quality intent taxonomy; UX real estate for interventions; A/B testing and guardrails to avoid interrupting flow.
- Concreteness/Completion checker to increase success rates
- What: Add a “prompt concreteness” detector that flags vague queries (e.g., “Hi”, “help?”) and offers quick-clarifying scaffolds to increase task completion.
- Tools/workflows: Lightweight LLM or rules model classifying task concreteness; inline UI cues (“Specify goal, input, output format”); auto-suggested details.
- Sectors: Consumer chatbots, enterprise assistants, customer support.
- Assumptions/dependencies: Agreement that completion ≈ task concreteness proxy; calibration to reduce false positives for creative exploration.
- Dataset/benchmark audit for representativeness (avoid WildChat skew)
- What: Before training/evaluating with public logs (e.g., WildChat), compute representativeness against your user base to avoid power-user and API-like biases.
- Tools/workflows: A JSD-based “representativeness score” comparing intent/domain distributions; flags for API-like templated traffic; data selection filters.
- Sectors: Model training, evaluation, and MLOps across software and AI vendors.
- Assumptions/dependencies: Access to internal aggregate distributions; ability to safely compute JSD; public dataset metadata may be incomplete.
- API-like usage detection and filtering in telemetry
- What: Identify and downweight/remove templated, batch, or API-style prompts from training/evaluation to focus on real human-at-the-keyboard conversations.
- Tools/workflows: Template detection heuristics (n-gram repetition, parameter slots), clustering, rate-shape features; traffic labeling in pipelines.
- Sectors: Model training, analytics, platform integrity.
- Assumptions/dependencies: Sufficient text visibility under privacy policies; reliable sessionization and rate features.
- Report and optimize metrics stratified by activity level, not only global averages
- What: Track satisfaction and success by cohorts (low/middle/high-active users) to avoid masking gaps and to prioritize feature work where it matters.
- Tools/workflows: Cohort-based dashboards and OKRs; cohort-aware NPS/CSAT; per-cohort A/B tests.
- Sectors: Product analytics across software.
- Assumptions/dependencies: Product analytics instrumentation; statistical power for small high-activity cohorts.
- Product strategy pivot: prioritize acquisition/education over expecting adaptation
- What: Given users do not naturally adapt much, allocate more roadmap to onboarding, templates, and education content vs. assuming behavior will shift organically.
- Tools/workflows: Content libraries; in-product tours; success playbooks for role-based tasks (e.g., sales, engineering, HR).
- Sectors: SaaS, enterprise, prosumer.
- Assumptions/dependencies: Content maintenance costs; alignment with brand and support teams.
- Privacy-preserving analysis patterns
- What: Adopt aggregation thresholds, PII scrubbing, and secure compute for behavioral analytics as modeled in this study.
- Tools/workflows: Automated PII removal; aggregates over >N users; secure enclaves and data access controls.
- Sectors: Any platform analyzing chat logs.
- Assumptions/dependencies: Legal/privacy compliance; engineering resources for secure data handling.
Academia
- Longitudinal methods blueprint for human–AI interaction studies
- What: Replicate the stratified sampling by activity level, quartered trajectories, and paired tests to separate population shifts from individual adaptation.
- Tools/workflows: Public code templates; clear reporting of cohort definitions; intent/domain taxonomies; JSD for cross-dataset comparisons.
- Assumptions/dependencies: Access to consistent user identifiers (or proxies); IRB and privacy safeguards.
- Re-assessment of WildChat-derived benchmarks and fine-tuning sets
- What: Audit, reweight, or curate WildChat subsets to reduce power-user/API-like skew in training/evaluation.
- Tools/workflows: Representativeness scoring; intent/domain resampling; release of “typical-user” benchmark splits.
- Assumptions/dependencies: Rights to redistribute subsets; community alignment on taxonomy.
Policy and Governance
- Provenance and representativeness disclosures for training/evaluation datasets
- What: Require that AI providers disclose dataset sources, cohort composition, and known skews (e.g., power users, templated traffic).
- Tools/workflows: Standardized datasheets/model cards with representativeness metrics; auditing checklists.
- Sectors: Regulators, standards bodies, public procurement.
- Assumptions/dependencies: Feasible to compute and disclose high-level aggregates without violating privacy or IP.
- Cohort-stratified transparency and bias audits
- What: Encourage/require stratified performance reporting by user activity level and use-case domain.
- Tools/workflows: Audit protocols; cohort-aware performance thresholds in procurement contracts.
- Assumptions/dependencies: Adequate sample sizes; agreed cohort definitions.
Daily Life (individual users, educators)
- Use templates and concrete prompts to raise success
- What: Start with role- or task-specific templates and specify inputs/outputs to increase completion rates.
- Tools/workflows: Personal prompt library; checklists for clarity (goal, data, format, constraints).
- Assumptions/dependencies: Access to vetted templates; basic prompt literacy.
- Plan deliberate exploration bursts
- What: Because habits are sticky, schedule short “explore a new intent” sessions (e.g., weekly) to discover higher-value uses (analysis, research, structured writing).
- Tools/workflows: Calendar reminders; curated “new task” lists.
- Assumptions/dependencies: Motivation/time; availability of examples.
- Interpret advice from power users cautiously
- What: Recognize that public advice and datasets may reflect atypical, highly proficient users and may not map directly to casual workflows.
- Tools/workflows: Seek guidance tailored to your role and experience level.
- Assumptions/dependencies: Availability of role-specific resources.
Long-Term Applications
These opportunities will benefit from additional research, integration, or scaling.
Industry (software, search, productivity suites, developer tools, enterprise)
- Adaptive LLM UX that morphs by cohort and intent in real time
- What: Interfaces that detect user type and task intent on the fly to adapt scaffolding, suggested actions, and evaluation views dynamically.
- Tools/workflows: Online cohort classifiers; bandit/RL-based UI policies; guardrail-aware personalization.
- Assumptions/dependencies: Robust intent detection; privacy and fairness controls; non-intrusive UX.
- Habit-change interventions for LLM use
- What: Design and validate micro-interventions (goal-setting, spaced prompts, progress feedback) to help users adopt higher-value tasks over time.
- Tools/workflows: Behavioral science-informed UX; long-horizon A/B tests; retention and task-shift metrics.
- Assumptions/dependencies: Causal experimentation infrastructure; ethical oversight.
- Conversion models to turn casuals into retained “proficient” users
- What: Predict which casual users can benefit from targeted education or templates and deliver tailored pathways.
- Tools/workflows: Uplift modeling; treatment assignment engines; CRM integration for enterprise.
- Assumptions/dependencies: Consent-based personalization; sufficient data history.
- Representative benchmark suites for “typical” chat users
- What: Create evaluation suites reflecting real-world distributions of intents/domains and activity levels, not just power-user tasks.
- Tools/workflows: Multi-tenant benchmarks; cohort-weighted scoring; public leaderboards with cohort breakdowns.
- Assumptions/dependencies: Access to representative logs; community uptake.
- Cross-platform dataset health and integrity services
- What: Third-party services that audit logs for API-like traffic, cohort skews, and drift over time.
- Tools/workflows: Pipeline hooks; standard schema for intent/domain labels; risk scoring.
- Assumptions/dependencies: Data-sharing agreements; secure computation.
Academia
- Causal studies on adaptation vs. selection effects in AI adoption
- What: Separate individual learning from population composition using experimental/observational causal methods across contexts and cultures.
- Tools/workflows: Randomized interventions; panel data; instrumental variables where feasible.
- Assumptions/dependencies: Long-term datasets; cross-institution collaboration; IRB approvals.
- Standardized, shareable taxonomies and classifiers for intent/domain
- What: Build open, validated taxonomies and lightweight classifiers to enable consistent comparisons across platforms and studies.
- Tools/workflows: Multilingual taxonomies; annotation guidelines; model cards for classifiers.
- Assumptions/dependencies: Community governance; funding for maintenance.
Policy and Governance
- Standards for “User Representativeness Index” in public AI deployments
- What: Bodies like ISO/NIST define a quantitative index scoring how well datasets and benchmarks match target populations.
- Tools/workflows: Reference distributions; computation guidelines; thresholds for certification.
- Assumptions/dependencies: Agreement on taxonomies and metrics; periodic updates.
- Procurement requirements for cohort-aware performance reporting
- What: Public-sector contracts require vendors to show performance and safety by use-case and cohort, not only overall aggregates.
- Tools/workflows: Templates for reporting; third-party audits; red-teaming per cohort.
- Assumptions/dependencies: Market readiness; legal frameworks.
Daily Life (individual users, educators, workforce development)
- Personalized skill-building assistants for LLM proficiency
- What: Tutors that infer your current usage profile and gently scaffold toward more complex, professional tasks over time.
- Tools/workflows: Adaptive curricula; micro-lessons; reflective feedback on task outcomes.
- Assumptions/dependencies: On-device or privacy-preserving modeling; content partnerships.
- Role-based LLM certifications and micro-credentials
- What: Training pathways aligned to typical intents/domains for professions (e.g., educators, analysts, support agents), validated with representative task sets.
- Tools/workflows: Assessment banks; simulations; employer-integrated credentials.
- Assumptions/dependencies: Employer and platform buy-in; maintenance as tools evolve.
Notes on Cross-Cutting Assumptions and Dependencies
- Generalizability: Findings are from Bing Copilot (Jan–Sep 2024) and WildChat (with pre-Sep 2024 focus). Other platforms and time periods may differ.
- Measurement validity: “Completion” is a proxy for task concreteness; use care in interpreting as success.
- Privacy and ethics: Cohort analytics and longitudinal tracking require strong privacy safeguards, aggregation thresholds, and user consent.
- Data quality: Mapping users reliably (beyond IP hashes) and filtering API-like usage are critical for accurate insights.
- Taxonomy stability: Intent/domain taxonomies must be clear, validated, and maintained across versions and languages.
- Statistical power: High-activity cohorts are smaller; plan experiments and reporting to ensure adequate power.
Glossary
- API-like usage: Programmatic use of a chat interface that mimics automated API calls rather than human, back-and-forth dialogue. "We find this is driven by API-like usage, i.e., a large number of prompts with identical templates performing tasks like translation and named entity recognition"
- Bonferroni correction: A multiple-comparisons adjustment that controls the family-wise error rate by tightening significance thresholds. "( after Bonferroni correction within each dataset)"
- chain-of-thought prompting: A prompting technique that elicits step-by-step reasoning by asking models to generate intermediate explanations before answers. "We use GPT-4o-mini with temperature 0 and chain-of-thought prompting~\citep{wei2022chain} for all semantic classification tasks."
- exploration–exploitation: The trade-off between trying new options (exploration) and reusing known, effective options (exploitation). "shift from exploration to exploitation"
- exponential cutoff: A modification to a power-law where extremely large values become less likely due to an exponential decay in the tail. "Activity level follows a power-law distribution with exponential cutoff~\cite{clauset2009power}"
- hashed IP address: A pseudonymized identifier created by applying a hash function to an IP address. "WildChat provides a hash of each user's IP address"
- Jensen–Shannon divergence: A symmetric, smoothed measure of distance between probability distributions derived from Kullback–Leibler divergence. "The heatmaps show the Jensen--Shannon divergence (smaller = more similar) between the intent (left) and domain (right) distributions of Bing Copilot and WildChat users in each activity group."
- LLM classifier: Using a LLM to assign labels to text (e.g., intent, domain) rather than to generate open-ended outputs. "We also evaluate several high-level semantic properties of each conversation using LLM classifiers: user intent, conversational domain, and task completion."
- named entity recognition: An NLP task that identifies and categorizes mentions of real-world entities (e.g., person, organization, location) in text. "named entity recognition"
- ODC-By license: The Open Data Commons Attribution license requiring attribution for data reuse and sharing. "under an ODC-By license."
- paired t-test: A statistical test comparing the means of two related samples (e.g., before vs. after within the same users). "we run a paired -test for difference in means"
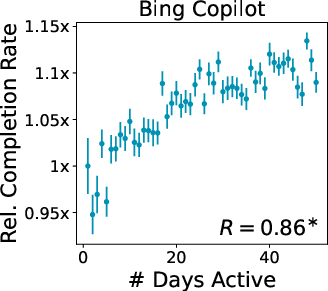
- Pearson's R: The Pearson correlation coefficient measuring linear association between two variables. "Asterisks here and in all other plots indicate Pearson's is significantly different from 0 ()."
- power-law distribution: A heavy-tailed distribution where large events are rare but more common than in exponential/Gaussian tails. "Activity level follows a power-law distribution with exponential cutoff~\cite{clauset2009power}"
- proxy variable: An indirect measure used to stand in for an unobserved or difficult-to-measure quantity. "we use hashed IP addresses as a proxy for individual users"
- spaCy: An open-source Python library for natural language processing used for tasks like tokenization and parsing. "calculated with spaCy."
- standard error: The estimated standard deviation of a sampling distribution (e.g., of a mean), used to quantify uncertainty. "points are daily metrics with standard error."
- stratified sampling: A sampling method that divides a population into subgroups (strata) and samples within each to ensure representation. "We stratify the sampled users by activity level"
- temperature (LLM decoding): A parameter controlling randomness in probabilistic text generation; lower values yield more deterministic outputs. "temperature 0"
- templated prompts: Prompts generated from fixed patterns with variable slots, often used at scale for repetitive tasks. "prompts with identical templates"
- two-proportion Z-test: A hypothesis test for comparing two population proportions to assess whether they differ significantly. "Bold numbers indicate a significant two-proportion -test vs the low activity group ( after Bonferroni correction within each dataset)."
Collections
Sign up for free to add this paper to one or more collections.

