Lost in Simulation: LLM-Simulated Users are Unreliable Proxies for Human Users in Agentic Evaluations
Abstract: Agentic benchmarks increasingly rely on LLM-simulated users to scalably evaluate agent performance, yet the robustness, validity, and fairness of this approach remain unexamined. Through a user study with participants across the United States, India, Kenya, and Nigeria, we investigate whether LLM-simulated users serve as reliable proxies for real human users in evaluating agents on τ-Bench retail tasks. We find that user simulation lacks robustness, with agent success rates varying up to 9 percentage points across different user LLMs. Furthermore, evaluations using simulated users exhibit systematic miscalibration, underestimating agent performance on challenging tasks and overestimating it on moderately difficult ones. African American Vernacular English (AAVE) speakers experience consistently worse success rates and calibration errors than Standard American English (SAE) speakers, with disparities compounding significantly with age. We also find simulated users to be a differentially effective proxy for different populations, performing worst for AAVE and Indian English speakers. Additionally, simulated users introduce conversational artifacts and surface different failure patterns than human users. These findings demonstrate that current evaluation practices risk misrepresenting agent capabilities across diverse user populations and may obscure real-world deployment challenges.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
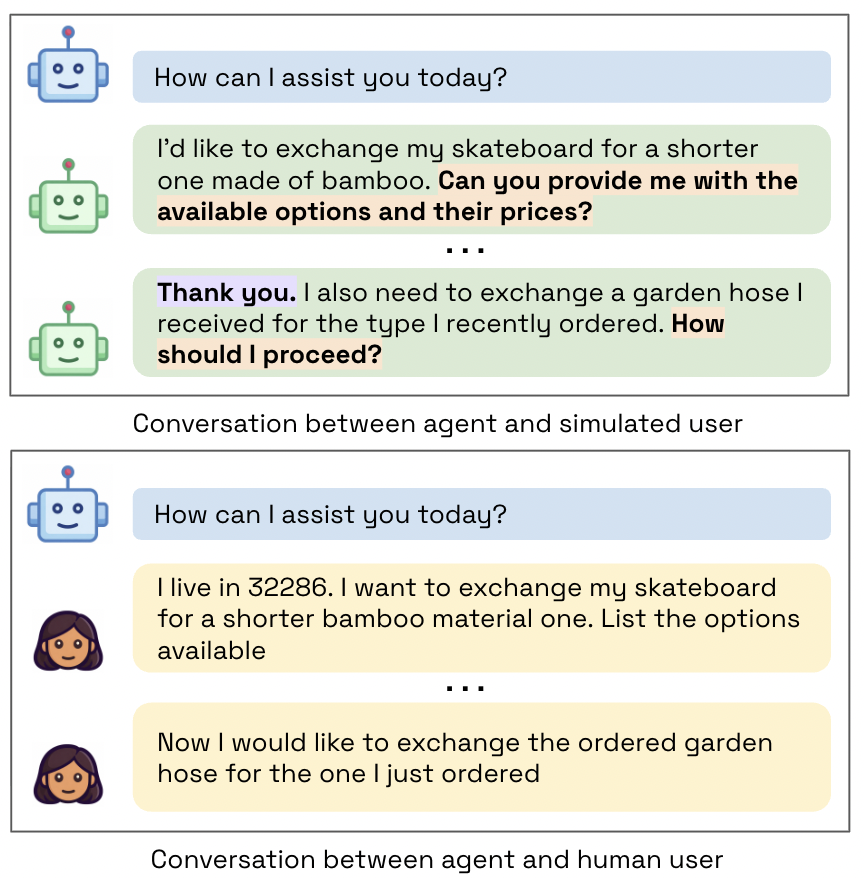
This paper looks at how we test AI “agents” that help with tasks like shopping support, booking flights, or fixing orders. Many tests use pretend users made by LLMs instead of real people because it’s cheaper and faster. The main question is: Do these LLM-simulated users act enough like real people to fairly measure how good the AI agents are?
Key Questions
The researchers focused on three simple questions:
- Robustness: If we swap the LLM used to pretend to be the user, do the agent’s scores stay the same or change a lot?
- Validity: Do agent results with simulated users match what happens with real human users?
- Fairness: Do simulated users represent different groups of people equally well (for example, different age groups, dialects, or countries), or do they work better for some groups than others?
How They Studied It
The task setup (tau-Bench)
They used a known benchmark called tau-Bench, which has realistic customer service tasks (mainly retail, like changing an order or returning an item). In these tasks:
- The “agent” is the AI assistant that must talk with the user, follow rules, and use tools (like calling a database) to complete the task.
- A task counts as “success” if the agent does the correct actions and clearly gives all the required information.
Think of it like a school assignment with two parts: doing the right steps and explaining them clearly.
Picking tasks by difficulty
They ran the benchmark several times to find tasks that are easy, medium, and hard based on how often the agent succeeds. Then they chose a balanced set of 18 tasks covering all difficulty levels.
Human user study
They talked to real people from four places: the United States, India, Kenya, and Nigeria. In the US, they also compared speakers of Standard American English (SAE) and African American Vernacular English (AAVE), and split US participants by age (18–34, 35–54, 55+).
- Each person did 4 tasks in a web chat with the same agent model (GPT-4o).
- This let the researchers compare agent performance with real humans versus with simulated users.
Metrics (how they measured results)
- Success rate: the percentage of tasks the agent completes correctly.
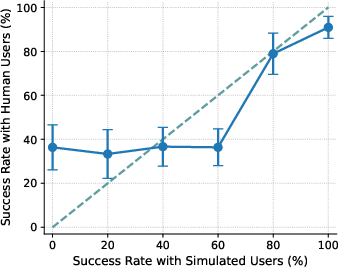
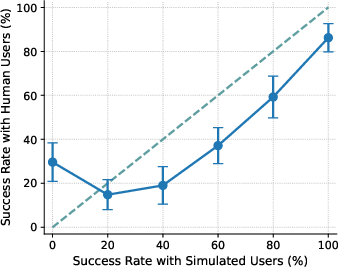
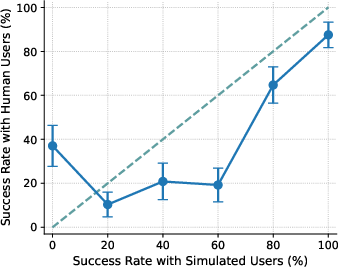
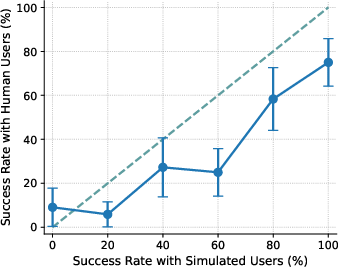
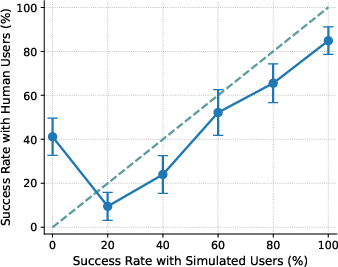
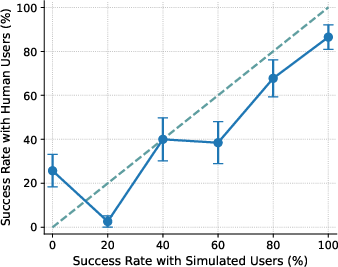
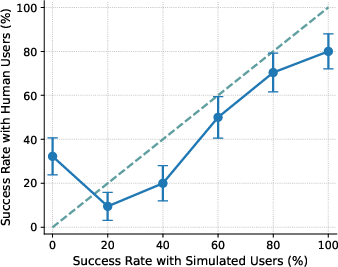
- Calibration (ECE): In everyday terms, calibration checks if “practice” results (with simulated users) match “real game” results (with human users) across easy to hard tasks. If the difference is small, calibration is good. If the difference is large, calibration is poor. Lower ECE means better alignment between simulated and real outcomes.
Main Findings
Here are the biggest results and why they matter:
- Changing the simulated user model changes scores:
- Swapping which LLM pretends to be the user shifted success rates by up to about 9 percentage points (roughly 67% to 76%). That means results aren’t robust—your agent can look better or worse depending on which simulated user you pick.
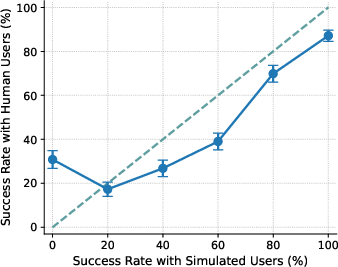
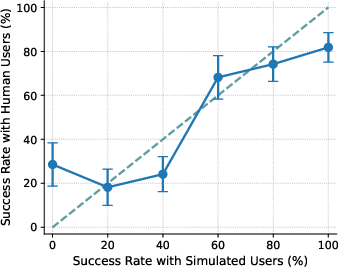
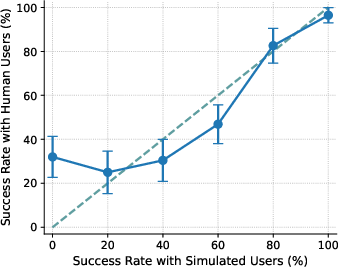
- Simulated users don’t predict real-human outcomes well:
- With US participants, the agent’s performance with simulated users didn’t match performance with real people (poor calibration, ECE ≈ 15). Simulated users tended to underestimate success on the hardest tasks and overestimate success on medium-difficulty ones. So the “practice” scores can mislead you about how the agent will do in real life.
- Fairness problems: AAVE vs. SAE and age effects
- The agent did worse with AAVE speakers (about 39% success) than with SAE speakers (about 51%). Calibration was also worse for AAVE (higher ECE ≈ 20 vs. 12 for SAE).
- The gap grew with age: AAVE 55+ had notably lower success (≈ 33%) compared to SAE 55+ (≈ 52%). This suggests simulated users are a poorer stand-in for some groups, especially older AAVE speakers.
- Across countries (18–34 age group), performance differences were smaller, but calibration varied:
- Success rates were in a similar range (≈ 41%–49%), but simulated users were worst calibrated for AAVE and Indian English speakers (higher ECE ≈ 18.9). That means simulated users predicted those groups’ outcomes less accurately.
- Simulated conversations had “artifacts” (behaviors that aren’t like real people):
- Simulated users asked more questions and were more polite than humans. This changes how agents behave and can make agents look better or worse in ways that won’t match real-world users.
- Different kinds of errors showed up with simulated vs. human users:
- With simulated users, agents made more “output” mistakes (missing or incorrect information in their messages), but fewer extra/missing action mistakes.
- Failures in simulated conversations were more often blamed on the agent; in human conversations, failures were more often due to user-side issues like misunderstandings. This matters because it can hide the kinds of real-world problems agents will face.
Why This Matters
Implications and Impact
- If we rely only on simulated users to judge AI agents, we might think the agent is better or worse than it actually is with real people.
- Some groups—like AAVE speakers and Indian English speakers—are less well represented by simulated users, which can lead to unfair or misleading evaluations.
- Benchmarks should:
- Report results across multiple simulated user models (to check robustness).
- Validate with real, diverse users (to ensure results match reality).
- Watch for and reduce behavioral artifacts (like overly polite, question-heavy simulated users).
- Be transparent about limitations, and improve fairness so agents serve everyone well.
In short, the paper warns that using LLM-simulated users as the only evaluation method can misrepresent agent abilities and hide real-world challenges, especially for certain communities. The authors recommend more careful, diverse, and human-grounded testing to build AI agents that work fairly and reliably for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps the paper leaves unresolved; each item is phrased to be directly actionable for follow-up research.
- Cross-agent validity: Do simulation-based evaluations preserve relative rankings across different agent models? Quantify rank correlations (e.g., Spearman) and rank flips between simulated-user evaluations and human-user evaluations across a diverse set of agents.
- Agent–user model alignment: How does brand/family alignment (same vs. different vendor/training families) between the agent and simulated user affect measured robustness and calibration? Systematically vary both sides and measure changes in success rate/ECE.
- Uncertainty quantification: What are the confidence intervals for ECE and success rates by group and difficulty bin? Provide bootstrap CIs and power analyses to assess the stability of calibration conclusions, especially with small subgroups (e.g., AAVE 55+).
- Difficulty labeling circularity: Task “difficulty” is derived from simulated (GPT-4o) runs. How do conclusions change if difficulty is human-derived (e.g., human success/time-to-completion) or agent-agnostic (structural complexity metrics)? Compare calibration under multiple difficulty taxonomies.
- Evaluation metric bias: The benchmark relies on substring matching for output correctness. Does this mis-score semantically correct but lexically divergent outputs (and does it vary by dialect)? Compare against semantic LLM-judging, structured state-diff checks, and hybrid evaluators; quantify evaluator bias by group.
- Outcome coverage: Success rate and ECE do not capture user-centric outcomes (satisfaction, trust, effort, time-on-task). How do simulated vs. human evaluations differ on these measures, and do disparities widen or shrink?
- Error taxonomy depth: Beyond four coarse error categories and small-sample attribution, what are the fine-grained failure causes (e.g., clarification handling, coreference, policy adherence, tool precondition checks)? Build a larger, reliably annotated error corpus to model causal pathways of failure.
- Causal mechanisms of miscalibration: Which linguistic/pragmatic dimensions (politeness, verbosity, directness, slang, ambiguity, code-switching) drive miscalibration? Run controlled factorial manipulations in simulators and human studies to estimate causal effects per dimension and per demographic group.
- Generalization across domains: Do robustness, validity, and fairness patterns replicate in higher-stakes, structurally different domains (healthcare, finance, legal assistance) with longer horizons and policy-heavy constraints? Measure if effects amplify with interaction length and tool complexity.
- Multimodal and speech settings: How do findings change for voice agents (accent, prosody, disfluencies), code-mixing, and noisy ASR? Build speech-based user simulations and compare calibration gaps with real spoken interactions.
- Global population coverage: Results are limited to English speakers in four countries and two US dialects. Extend to additional dialects (e.g., Chicano English), world Englishes (e.g., Singapore, Philippines), multilingual users, and non-native proficiency levels; include older age groups outside the US.
- Socioeconomic and accessibility factors: How do SES, digital literacy, disability (e.g., dyslexia, motor impairments), and assistive technology use affect agent performance and simulation fidelity? Incorporate these covariates and test simulator coverage.
- Human behavior realism: Simulated users exhibited more questions/politeness and fewer user-side errors. What simulator design choices (prompting, decoding, persona conditioning, error-injection) best reproduce human-like distributions of ambiguity, partial compliance, and off-goal behavior?
- Mitigation strategies: Which interventions most reduce miscalibration—persona-conditioned simulators trained on human dialogs, ensembles across diverse simulators, adversarial/user-behavior stress tests, or post-hoc calibration maps that transform simulated success into predicted human success by group/difficulty?
- Ensemble and aggregation protocols: How many and which user LLMs are needed to achieve robust estimates? Develop principled aggregation schemes (e.g., model ensembles with variance reporting, worst-case bounds) and guidelines for reporting uncertainty in simulator-based benchmarks.
- Temporal stability and model churn: Are robustness and calibration results stable across model updates (new LLM releases, retired models) and over time? Track longitudinal drift and establish procedures to re-baseline simulators.
- Instruction and interface effects: The study removes identity cues and uses a text-only chat UI. How do identity-laden instructions, UI affordances (buttons, structured forms), and tool UX changes affect human versus simulated outcomes?
- Tool environment complexity: Do results depend on API design (argument schemas, error messaging), database size, and need for cross-tool coordination? Vary tool ecosystems to test whether miscalibration is primarily conversational or tool-execution driven.
- Seed and run variability: Beyond three runs for simulator robustness, how do results vary across seeds, sampling temperatures, and conversation restarts? Provide variance decompositions (across seeds, tasks, simulators) to isolate sources of instability.
- Calibration granularity: Current ECE is binned by difficulty. Would per-task calibration curves, continuous calibration error, or hierarchical models (task-level random effects) reveal finer-grained miscalibration patterns?
- Fairness-aware simulation design: Can we learn simulators conditioned on real demographic interaction data without stereotyping, and validate that they neither homogenize styles nor amplify biases? Define metrics for demographic fidelity without leakage of harmful stereotypes.
- Ranking under distribution shift: If simulated users overestimate performance on easy/moderate tasks and underestimate on hard tasks, how does this distort system selection for deployments where task mix differs? Study sensitivity of agent ranking to deployment task distributions.
- Active/hybrid evaluation protocols: What cost-effective hybrid strategies (e.g., human-in-the-loop for high-uncertainty tasks or undercovered groups) deliver reliable estimates with bounded error? Prototype active sampling that uses simulator uncertainty to prioritize human trials.
- Data release and reproducibility: Will human–agent transcripts, error annotations, and simulator prompts be released (with consent and de-identification) to enable independent replication and method development? Establish standardized artifacts and reproducibility checklists.
- Contamination and provenance: Observed cross-simulator differences may reflect contamination or training data overlaps. Can we measure and control for contamination (e.g., canary tasks, provenance audits) and quantify its effect on simulated-user fidelity?
- Personalization and adaptation: Do agents adapt within a conversation or across sessions to different user styles, and does this reduce disparities? Evaluate online adaptation (e.g., style mirroring, clarification strategies) with humans and simulators.
- Policy and safety dynamics: Do simulated users faithfully trigger real safety/policy edge cases (e.g., ambiguous or sensitive requests) at human-like rates? Audit calibration specifically on safety-critical turns and policy-bound failures.
- Standardized reporting: What should be the minimal reporting standard for simulator-based agentic evaluations (multi-simulator results, variance, per-group ECE, per-bin calibration plots, demographic coverage)? Propose and validate a reporting template that predicts human outcomes more reliably.
Glossary
- African American Vernacular English (AAVE): A dialect of American English associated with Black communities in the United States, used here as a demographic group in evaluation. "African American Vernacular English (AAVE) speakers experience consistently worse success rates and calibration errors than Standard American English (SAE) speakers, with disparities compounding significantly with age."
- Agentic benchmarks: Evaluation suites that measure agents in dynamic, multi-turn, tool-using settings rather than static QA. "Agentic benchmarks have needed to evolve beyond static question-answering and other single-turn formats to capture the dynamic, multi-turn nature of real user interactions"
- Agentic evaluations: Assessments focused on interactive, goal-oriented agents operating over multiple turns. "Lost in Simulation: LLM-Simulated Users are Unreliable Proxies for Human Users in Agentic Evaluations"
- Argument error: An error where the agent performs the right action but supplies incorrect parameters/arguments. "argument error (action taken matches ground truth action but with different arguments)"
- Calibration gap: The discrepancy between performance measured with simulated users and with real users across conditions (e.g., difficulty levels). "the calibration gap is most pronounced for the 1st (0%) and 4th (60%) difficulty bins"
- Conversational artifacts: Artificial patterns in dialogue (e.g., excessive question-asking or politeness) introduced by simulation rather than genuine human behavior. "Additionally, simulated users introduce conversational artifacts and surface different failure patterns than human users."
- Contamination issues: Unintended leakage where a model has seen benchmark data or close variants during training, skewing evaluation. "We use GPT-4o because it is used in the -Bench paper and does not exhibit contamination issues that newer models face."
- Differentially effective proxy: A stand-in that approximates some groups better than others, leading to uneven evaluation fidelity. "We also find simulated users to be a differentially effective proxy for different populations, performing worst for AAVE and Indian English speakers."
- Difficulty bins: Groupings of tasks by measured difficulty (e.g., based on success rates) used for analysis. "the calibration gap is most pronounced for the 1st (0%) and 4th (60%) difficulty bins"
- Ecological validity: The extent to which an evaluation reflects real-world conditions and interactions. "These benchmarks improve complexity and ecological validity over prior static evaluations by requiring agents to demonstrate a range of capabilities"
- Error attribution: Assigning responsibility for task failures to the agent, the user, both, or other causes. "We analyze differences in (1) error types and (2) error attribution for simulated vs. human user interactions"
- Expected Calibration Error (ECE): A metric that summarizes how closely predicted or proxy-based outcomes align with actual outcomes across bins. "We adapt Expected Calibration Error (ECE), commonly used for assessing confidence calibration in probabilistic classifiers, to quantify how well simulated users serve as proxies for human users."
- Extra action error: An error where the agent performs unnecessary actions beyond what the ground truth requires. "extra action error (actions taken go beyond ground truth actions)"
- Generalized Estimating Equations (GEE): A statistical method for modeling correlated outcomes (e.g., repeated measures) while estimating population-level effects. "A Generalized Estimating Equations (GEE) model accounting for age, education, AI experience, AI usage, and task difficulty confirms a statistically significant dialect disparity (, )."
- Ground truth outcome: The reference-correct final state or action sequence an evaluation expects. "the final database state is identical to the unique ground truth outcome (i.e., the sequence of required actions)"
- LLM-simulated users: LLMs prompted to play the role of users in evaluations of AI agents. "Agentic benchmarks increasingly rely on LLM-simulated users to scalably evaluate agent performance"
- Miscalibration: Systematic mismatch between simulated-user-based evaluations and real-user outcomes. "evaluations using simulated users exhibit systematic miscalibration, underestimating agent performance on challenging tasks and overestimating it on moderately difficult ones."
- Missing action error: An error where a required action from the ground truth sequence is omitted. "missing action error (ground truth action is missing from actions taken)"
- Output error: An error where the information the agent should present to the user is missing or incorrect. "output error (expected outputs are missing/incorrect)"
- Politeness indicators: Explicit linguistic markers of politeness (e.g., “please,” “thank you,” apologies) tracked as conversational features. "Differences are more pronounced when examining politeness indicators (e.g., please, thank you, apologize)."
- Positionality: The idea that perspectives in data and annotation are shaped by social and cultural positions, affecting model behavior. "These patterns of disagreement reflect broader issues of positionality---"
- Robustness: Stability of evaluation results across changes such as different user-simulation models. "We first evaluate the robustness of user simulation by examining how success rates vary with different user simulation models"
- Snowball sampling: A recruitment method where participants are enlisted via referrals due to access constraints. "we use snowball sampling due to limited platform availability."
- Standard American English (SAE): A mainstream U.S. English dialect used as a comparison group in the study. "African American Vernacular English (AAVE) speakers experience consistently worse success rates and calibration errors than Standard American English (SAE) speakers"
- -Bench: A benchmark for agentic tool use in customer service scenarios with multi-turn interactions and database tools. "We use -Bench \citep{yao2025taubench} as the testbed for our evaluations"
- Tool calls: Agent-initiated invocations of external tools/APIs to perform actions within tasks. "making appropriate tool calls over multiple turns."
- Turing-style tests: Evaluations that assess whether behavior appears human-like, inspired by the Turing Test. "behavioral realism (e.g., Turing-style tests)."
- User simulation: The practice of using models to emulate users in agent evaluations, aiming for scalable testing. "We find that user simulation lacks robustness"
Practical Applications
Practical Applications of “Lost in Simulation: LLM-Simulated Users are Unreliable Proxies for Human Users in Agentic Evaluations”
Below are actionable applications derived from the paper’s findings, methods, and innovations. They are grouped into immediate (deployable now) and long-term (requiring research, scaling, or development) categories. Each bullet highlights target sectors, potential tools/products/workflows, and key assumptions/dependencies that may affect feasibility.
Immediate Applications
- Calibration-aware evaluation dashboards for agent teams
- Sectors: software, e-commerce/retail, travel, finance, customer support platforms
- What: Add an “ECE_Human–LLM” panel to existing evaluation dashboards to display calibration gaps between simulated and real-user performance across task difficulty bins. Pair with success-rate breakdown and error types (argument/missing/extra/output) to identify misalignment hot spots.
- Tools/Workflows:
- Compute and report ECE_Human–LLM per demographic slice and difficulty bin.
- Integrate into CI/CD evaluation runs and release checks.
- Assumptions/Dependencies: Access to a small but diverse human-eval set; standardized logging and τ-Bench-like automated scoring; privacy-compliant demographic metadata.
- Multi-simulator robustness sweeps in CI for agentic benchmarks
- Sectors: software, AI benchmarking consortia, platform providers
- What: Run agent evaluations across multiple user LLMs (e.g., GPT-4o, Sonnet, Kimi) and report variance/intervals. Fail CI if variance exceeds a threshold.
- Tools/Workflows:
- “User-model sweep” jobs; report success-rate spread and statistical stability.
- Publish per-simulator scores on leaderboards.
- Assumptions/Dependencies: API access to multiple LLMs; reproducible seeds; cost control for multi-run evaluation.
- Human “micro-evals” for acceptance testing before deployment
- Sectors: e-commerce/retail, travel, fintech support, enterprise SaaS
- What: Gate releases with a lightweight, difficulty-stratified human eval set (e.g., 20–50 conversations), sampled across key demographics (e.g., SAE, AAVE, Indian English).
- Tools/Workflows:
- A streamlined human-eval harness (e.g., Streamlit app), paying screened participants.
- Release criteria: no significant ECE gap and acceptable success rates for target populations.
- Assumptions/Dependencies: Participant recruitment channels (Prolific, panels); consent and compensation; IRB/ethics compliance where applicable.
- Procurement and vendor assessment checklists that penalize simulation-only claims
- Sectors: enterprise IT, government, regulated industries (finance, healthcare), public procurement
- What: Update RFPs and vendor scorecards to require: (1) multi-simulator robustness evidence, (2) small-scale human validation, (3) calibration/fairness reporting across dialects/age.
- Tools/Workflows:
- Standardized “simulation-to-human gap” disclosures in model/agent cards.
- Specify pass/fail thresholds (e.g., max ECE_Human–LLM, success-rate parity bands).
- Assumptions/Dependencies: Organizational policy adoption; industry alignment on metrics; budget for third-party validation.
- Red-teaming and fairness audits focused on dialect/age miscalibration
- Sectors: finance, healthcare, education, retail contact centers (high-stakes agent interactions)
- What: Expand red-team scope to include dialectal variants (e.g., AAVE), age cohorts, and “moderate difficulty” tasks (where overestimation was observed).
- Tools/Workflows:
- Audit templates that include AAVE/Indian English test cohorts.
- Error attribution analysis (agent vs user vs both) to avoid misdiagnosis.
- Assumptions/Dependencies: Human evaluators with relevant dialects; ethical review for demographic data handling.
- Simulation prompt tuning to reduce unrealistic artifacts
- Sectors: software testing, benchmarking, UX research
- What: Modify simulated-user prompts to limit exaggerated politeness/question-asking and better mimic real-user behavior, then re-check calibration.
- Tools/Workflows:
- “Behavioral realism profiles” for simulated users (e.g., parameterized politeness/verbosity).
- A/B evaluation of artifact-reduction prompts vs baseline simulators.
- Assumptions/Dependencies: Control over simulator prompts; validation against human baselines.
- Deployment playbooks that adjust operations based on calibration findings
- Sectors: customer support BPOs, e-commerce, travel booking, banking chat
- What: Operational mitigations where simulation overestimates performance (e.g., moderate tasks): earlier human handoff, proactive confirmation steps, or tool-use verifications.
- Tools/Workflows:
- Routing policies by task difficulty bin; escalation when user dialect/age is associated with higher miscalibration risk (with care to avoid discriminatory treatment).
- Post-deployment monitoring comparing simulated vs live outcomes.
- Assumptions/Dependencies: Real-time task difficulty inference; fairness safeguards; privacy and anti-discrimination compliance.
- Benchmark curation updates (τ-Bench and similar)
- Sectors: academic benchmarking, open-source evaluation suites
- What: Publish small, demographically diverse human-eval subsets; add recommended protocols for multi-simulator runs; provide scripts to compute ECE_Human–LLM.
- Tools/Workflows:
- Difficulty-balanced task subsets for quick-validation.
- Public leaderboard fields for calibration and robustness.
- Assumptions/Dependencies: Community maintenance; contributor agreements for data; clear data licensing.
- Model/agent documentation enhancements
- Sectors: all deploying agents; documentation/AI governance teams
- What: Add sections to model/agent cards reporting (i) simulated-user variance, (ii) human-vs-sim calibration by group and difficulty, and (iii) observed behavioral artifacts.
- Tools/Workflows:
- Templates for “Simulation Reliance & Gaps.”
- Assumptions/Dependencies: Organizational willingness to disclose limitations; standardization across vendors.
Long-Term Applications
- Next-generation user simulators calibrated to real user diversity
- Sectors: software, benchmarking, foundational AI research
- What: Train or fine-tune simulators on diverse, ethically collected human-agent conversation corpora to reduce artifact behaviors and improve dialectal/cultural fidelity.
- Tools/Workflows:
- Learning objectives targeting ECE reduction vs human data.
- Controllable simulators with parameters for dialect, politeness, question frequency, and uncertainty.
- Assumptions/Dependencies: Large-scale, consented datasets representative of target populations; privacy-preserving data pipelines; evaluation standards for cultural/dialectal fidelity.
- Continuous human-in-the-loop evaluation platforms for agents
- Sectors: platform providers, enterprise AI ops, regulated industries
- What: Always-on evaluation services that sample real users from diverse pools, actively measure simulation-to-human gaps, and trigger retraining or policy updates when drift/miscalibration is detected.
- Tools/Workflows:
- “Calibration monitors” in MLOps; active sampling to fill demographic gaps.
- Automated reports for auditors and product owners.
- Assumptions/Dependencies: Sustainable participant recruitment and compensation; long-term governance; secure data handling.
- Dialect- and style-adaptive agents with on-line calibration
- Sectors: customer support, education (tutoring agents), healthcare (patient intake and triage), government services
- What: Agents that detect communication style (e.g., dialect, verbosity) and adapt prompts, confirmation strategies, and tool-calling behavior to reduce error and misalignment in real time.
- Tools/Workflows:
- Uncertainty-aware interaction policies (more confirmations with higher predicted risk of miscalibration).
- Personalization models validated for fairness and safety.
- Assumptions/Dependencies: Ethical detection of linguistic features without profiling or discrimination; robust fairness evaluation; domain-specific approvals (e.g., IRB for health).
- Sector-specific, human-validated agentic benchmarks
- Sectors: healthcare, education, finance, government services, robotics/HRI
- What: Build domain benchmarks modeled after τ-Bench but with embedded, recurring human validation sets and demographic coverage. Include difficulty binning and error attribution standards.
- Tools/Workflows:
- Medical/financial task taxonomies with policy/tool adherence checks.
- Domain-grade evaluation of outcomes (e.g., clinical appropriateness).
- Assumptions/Dependencies: Expert annotators and domain oversight; compliance with HIPAA/GDPR/FERPA as applicable; robust outcome evaluation definitions beyond substring matching.
- Regulatory and standards frameworks for agentic evaluation
- Sectors: policy, standards bodies, public sector procurement
- What: Establish standards that prohibit simulation-only claims for deployment readiness; require multi-simulator robustness, small-scale human validation, and group-wise calibration reporting in high-stakes contexts.
- Tools/Workflows:
- Certification checklists analogous to safety standards.
- Auditable trails of evaluation runs and demographic sampling.
- Assumptions/Dependencies: Multi-stakeholder consensus; enforcement mechanisms; proportional requirements by risk tier.
- Open datasets and libraries for calibration and fairness analysis
- Sectors: academia, open-source, industry R&D
- What: Curate open, consented datasets of human-agent interactions across dialects/countries/ages; release libraries to compute ECE_Human–LLM, success-rate parity, and error attribution.
- Tools/Workflows:
- Bench-ready data packs and scripts; integration with popular eval suites.
- Assumptions/Dependencies: Ethical data collection and de-identification; ongoing maintenance; community governance.
- Simulation artifact stress testing suites
- Sectors: software testing, benchmarking
- What: Standardized “artifact toggles” (e.g., politeness, question frequency, ambiguity, partial compliance) to stress-test agents. Evaluate sensitivity and relate to real-user error patterns.
- Tools/Workflows:
- Scenario generators with configurable behavioral knobs.
- Reports linking artifact sensitivity to live performance risks.
- Assumptions/Dependencies: Grounding against human baselines to avoid overfitting to artifacts; wide simulator support.
- Outcome-aware routing and workforce design in contact centers
- Sectors: BPOs, large retailers, travel providers
- What: Design workflows that dynamically route tasks/users to human agents when calibration risks are high (e.g., moderate-difficulty bins or dialects with known gaps), and feed outcomes back into training and evaluation.
- Tools/Workflows:
- Risk scoring + routing policies; systematic post-mortems with error attribution.
- Assumptions/Dependencies: Accurate risk estimation without discriminatory outcomes; operational costs and training.
- Foundational research on miscalibration origins and remedies
- Sectors: academia, industrial AI labs
- What: Theorize and empirically test why hardest tasks are underestimated and moderate ones overestimated under simulation; develop principled correction methods (e.g., debiasing simulation distributions, Bayesian calibration).
- Tools/Workflows:
- Counterfactual experiments across simulators and human cohorts; simulation policy learning.
- Assumptions/Dependencies: Access to multiple closed/open LLMs; reproducible evals across versions; support for longitudinal studies.
Cross-cutting assumptions and dependencies
- Human evaluation must be ethical, compensated, and privacy-preserving; demographic data should be handled with care and consent.
- Results shown are for English retail tasks with a fixed agent (GPT-4o) and may not directly generalize to multilingual or other domains without further validation.
- Automated scoring (e.g., substring matching) can misjudge correctness; outcome definitions may need to be domain-specific and robust.
- Availability, licensing, and stability of LLM APIs affect reproducibility and cost of multi-simulator evaluations.
- Avoid discriminatory use of demographic inference. Any adaptive strategies must be fairness-audited and compliant with anti-discrimination laws.
Collections
Sign up for free to add this paper to one or more collections.