The Adoption and Usage of AI Agents: Early Evidence from Perplexity
Abstract: This paper presents the first large-scale field study of the adoption, usage intensity, and use cases of general-purpose AI agents operating in open-world web environments. Our analysis centers on Comet, an AI-powered browser developed by Perplexity, and its integrated agent, Comet Assistant. Drawing on hundreds of millions of anonymized user interactions, we address three fundamental questions: Who is using AI agents? How intensively are they using them? And what are they using them for? Our findings reveal substantial heterogeneity in adoption and usage across user segments. Earlier adopters, users in countries with higher GDP per capita and educational attainment, and individuals working in digital or knowledge-intensive sectors -- such as digital technology, academia, finance, marketing, and entrepreneurship -- are more likely to adopt or actively use the agent. To systematically characterize the substance of agent usage, we introduce a hierarchical agentic taxonomy that organizes use cases across three levels: topic, subtopic, and task. The two largest topics, Productivity & Workflow and Learning & Research, account for 57% of all agentic queries, while the two largest subtopics, Courses and Shopping for Goods, make up 22%. The top 10 out of 90 tasks represent 55% of queries. Personal use constitutes 55% of queries, while professional and educational contexts comprise 30% and 16%, respectively. In the short term, use cases exhibit strong stickiness, but over time users tend to shift toward more cognitively oriented topics. The diffusion of increasingly capable AI agents carries important implications for researchers, businesses, policymakers, and educators, inviting new lines of inquiry into this rapidly emerging class of AI capabilities.
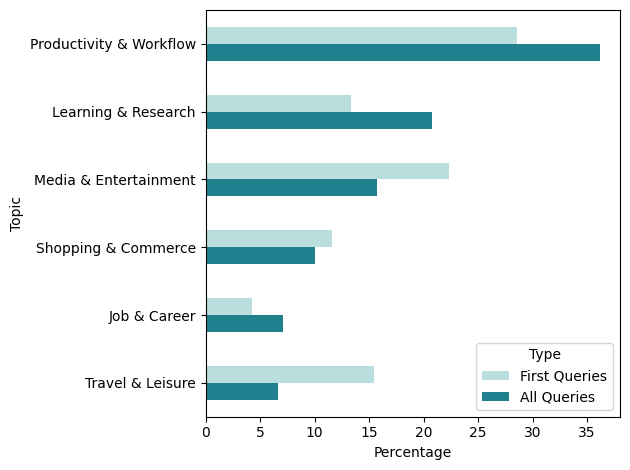

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at how people are starting to use a new kind of AI called “agents.” Instead of just chatting like regular AI chatbots, these agents can take actions for you on the web—like organizing emails, booking flights, editing documents, or shopping—based on your instructions. The researchers studied real, anonymous activity from Perplexity’s Comet browser, which has a built-in agent called Comet Assistant. Using hundreds of millions of interactions, they explain who uses AI agents, how much they use them, and what they use them for.
Key questions the researchers asked
To guide their study, the researchers focused on three simple questions:
- Who is using AI agents?
- How intensively are they using them?
- What are they using them for?
How they studied it
What is an AI agent?
Think of an AI agent as a smart helper that doesn’t just talk—it can do things online for you. A regular chatbot gives you answers; an AI agent can open sites, click buttons, send emails, edit files, and more. In short:
- The AI’s “brain” is a LLM that thinks and decides.
- The AI’s “hands” are tools and connections to websites and apps that let it act.
How does an agent work?
Agents often follow a loop called ReAct (short for “Reasoning + Acting”):
- Thinking: The agent plans steps to reach your goal (like “find, compare, then buy”).
- Acting: It uses tools or controls the browser to take those steps.
- Observing: It checks what happened and adjusts its plan if needed.
What data did they use?
They looked at Comet browser activity between July 9 and October 22, 2025. They used three main samples:
- Sample A: Every Comet user and all their queries (to track overall adoption and usage).
- Sample B: 100,000 randomly chosen users (to see patterns by job types using standard job categories called O*NET clusters).
- Sample C: 100,000 randomly chosen agent users and all of their agent actions (to understand detailed use cases over time).
Important note: Everything was anonymized (no names, emails, or personal details), and results are reported only in aggregated form.
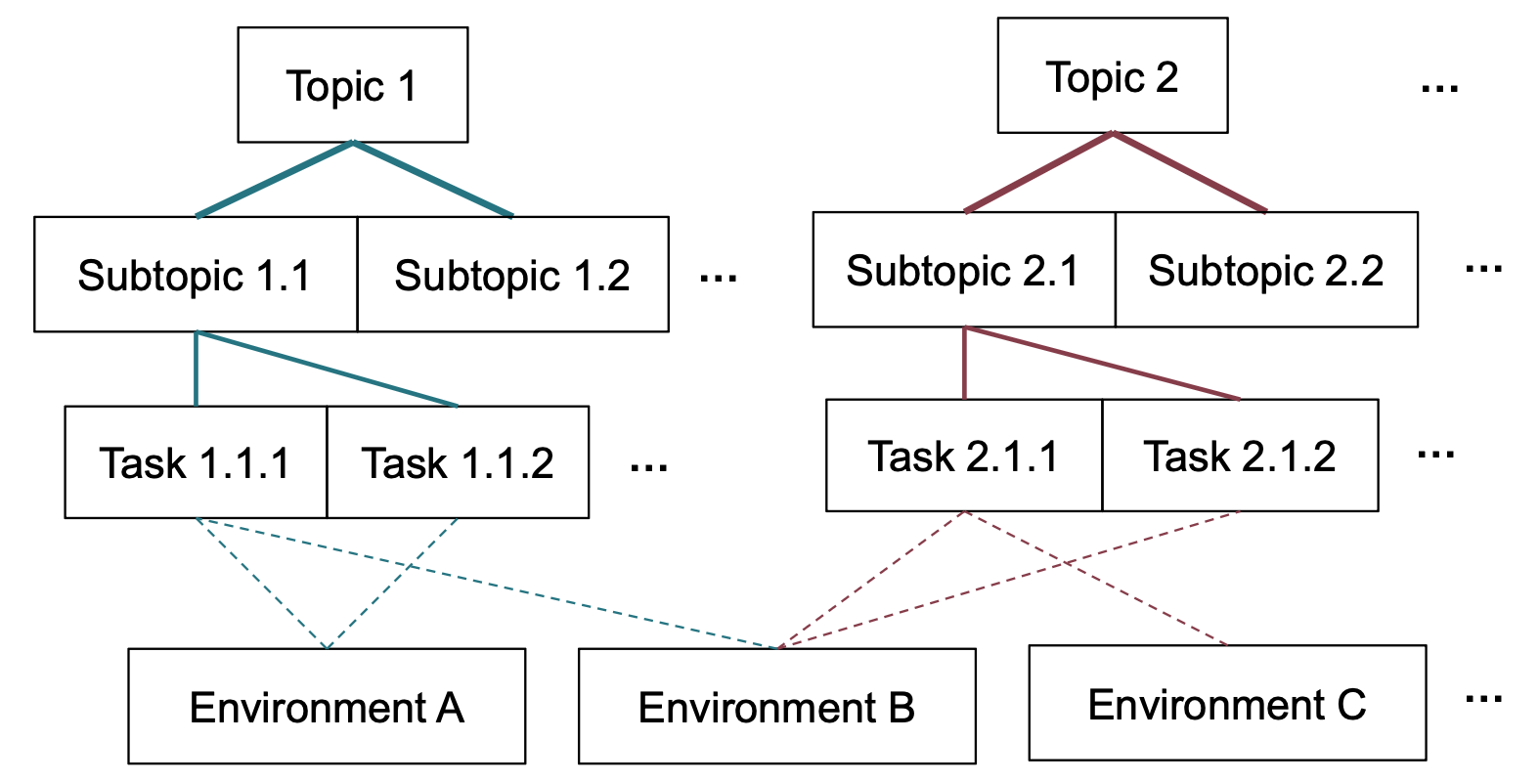
How they organized use cases (a “taxonomy”)
To make sense of what people ask agents to do, the researchers built a “taxonomy”—a structured map of use cases with three levels:
- Topic (big category, like Productivity or Learning)
- Subtopic (a smaller category inside each topic, like Email Management within Productivity)
- Task (the exact action, like “filter emails” or “unsubscribe from newsletters”)
How they built it:
- They grouped similar queries using a math method called “embeddings” (turning meaning into numbers) and “K-means clustering” (grouping similar items—like sorting songs into playlists by vibe).
- They refined these groups and then used a classifier (a labeling tool) to tag each agent query.
- Their classifier agreed with a hand-checked “gold” set about 80–90% of the time, which is considered strong.
A few technical terms in simple words
- General availability (GA): The date when the product is available to everyone.
- GDP per capita: A country’s average income per person (used here to compare economic development).
- O*NET occupation clusters: Standard job categories (like Digital Technology, Finance, Healthcare).
- AAR/AUR: Ratios showing whether a group is using agents more or less than you’d expect from its size. AAR is for adoption, and AUR is for usage intensity.
What they found
Adoption and usage patterns
- Use is growing fast: More people started using agents over time, especially after Comet became available to everyone.
- Early users do more: People who got access earlier used the agent much more. For example, the earliest cohort was roughly twice as likely to adopt and made about nine times more agent actions than those who joined at GA.
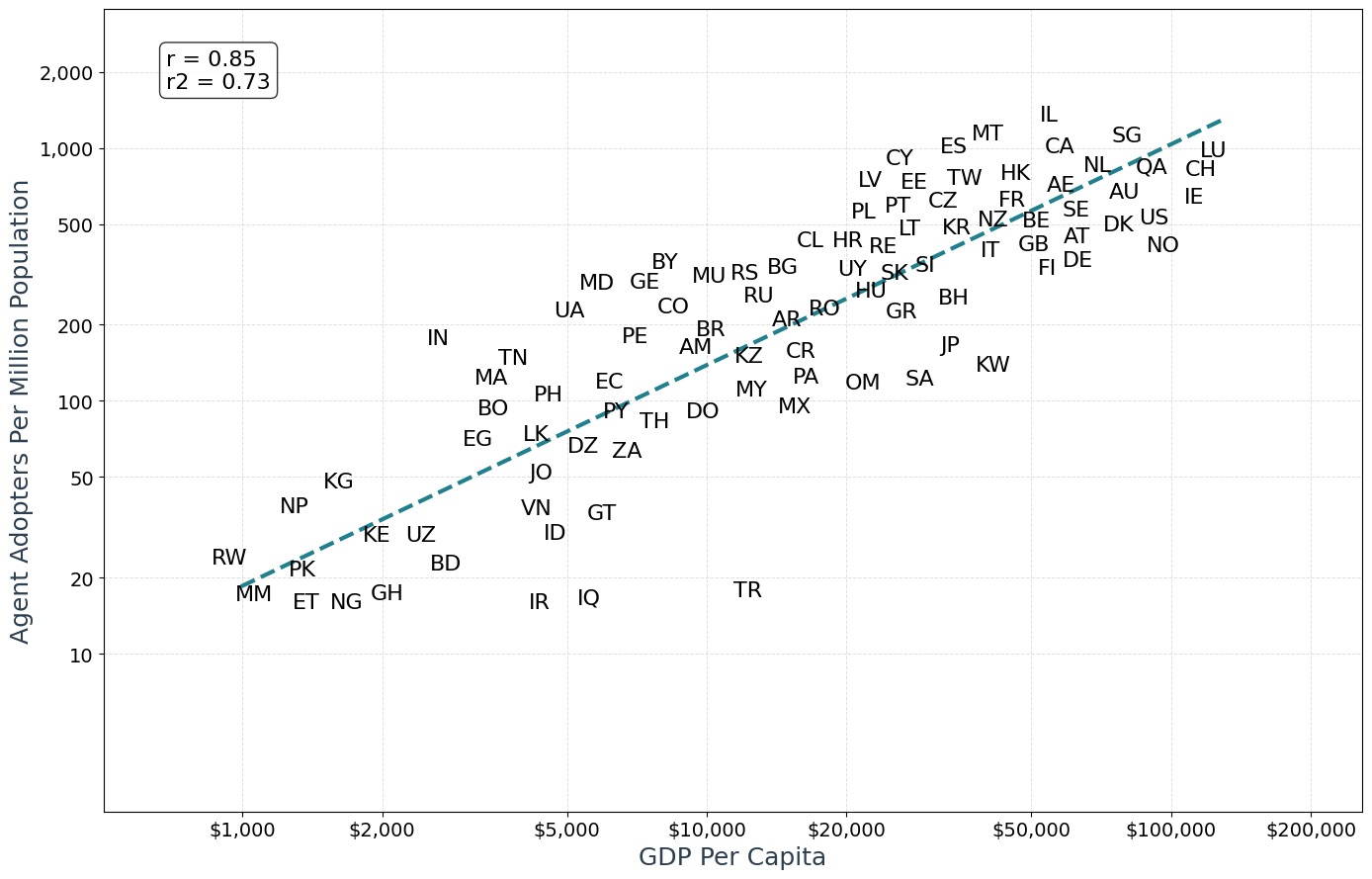
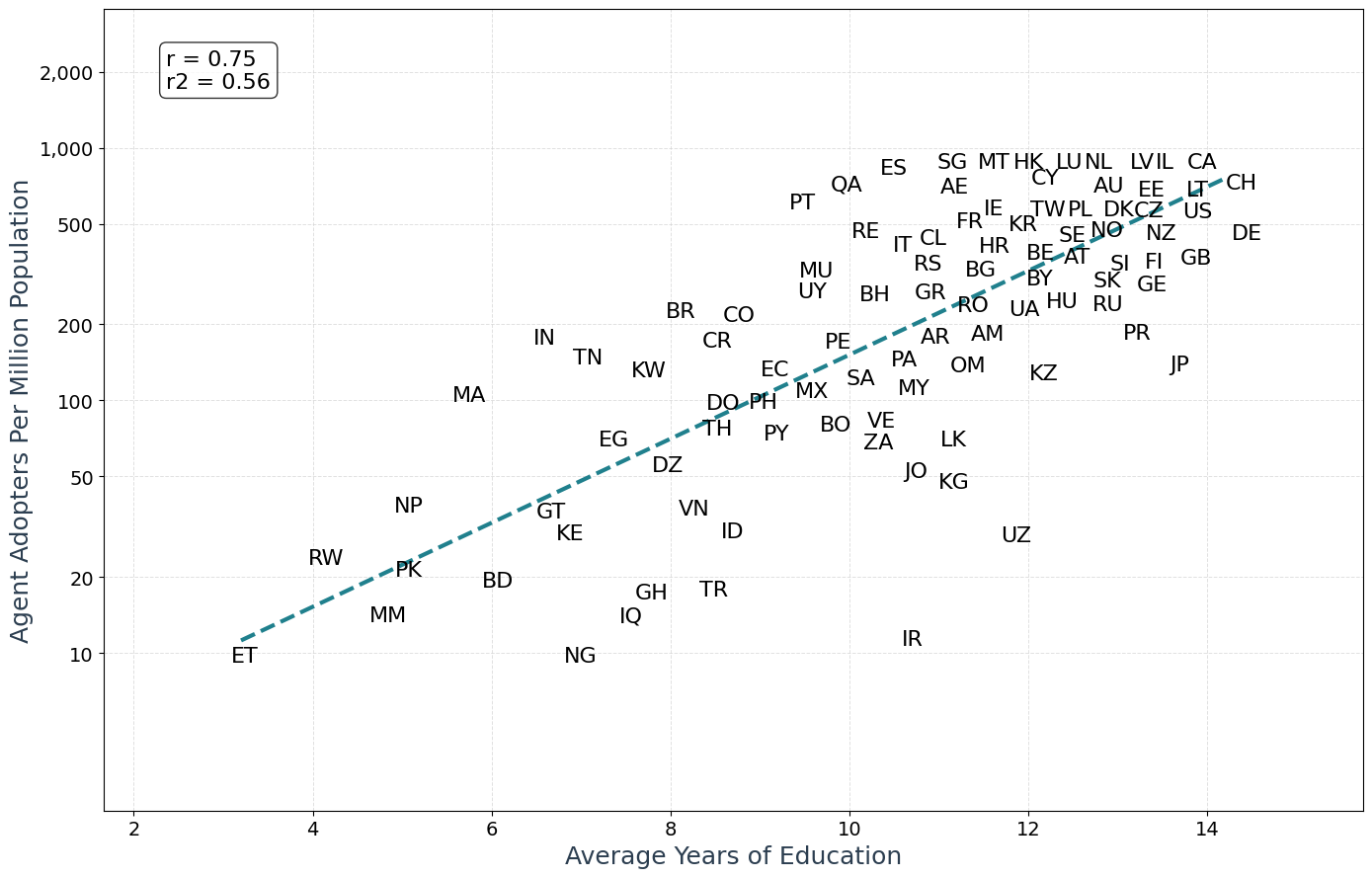
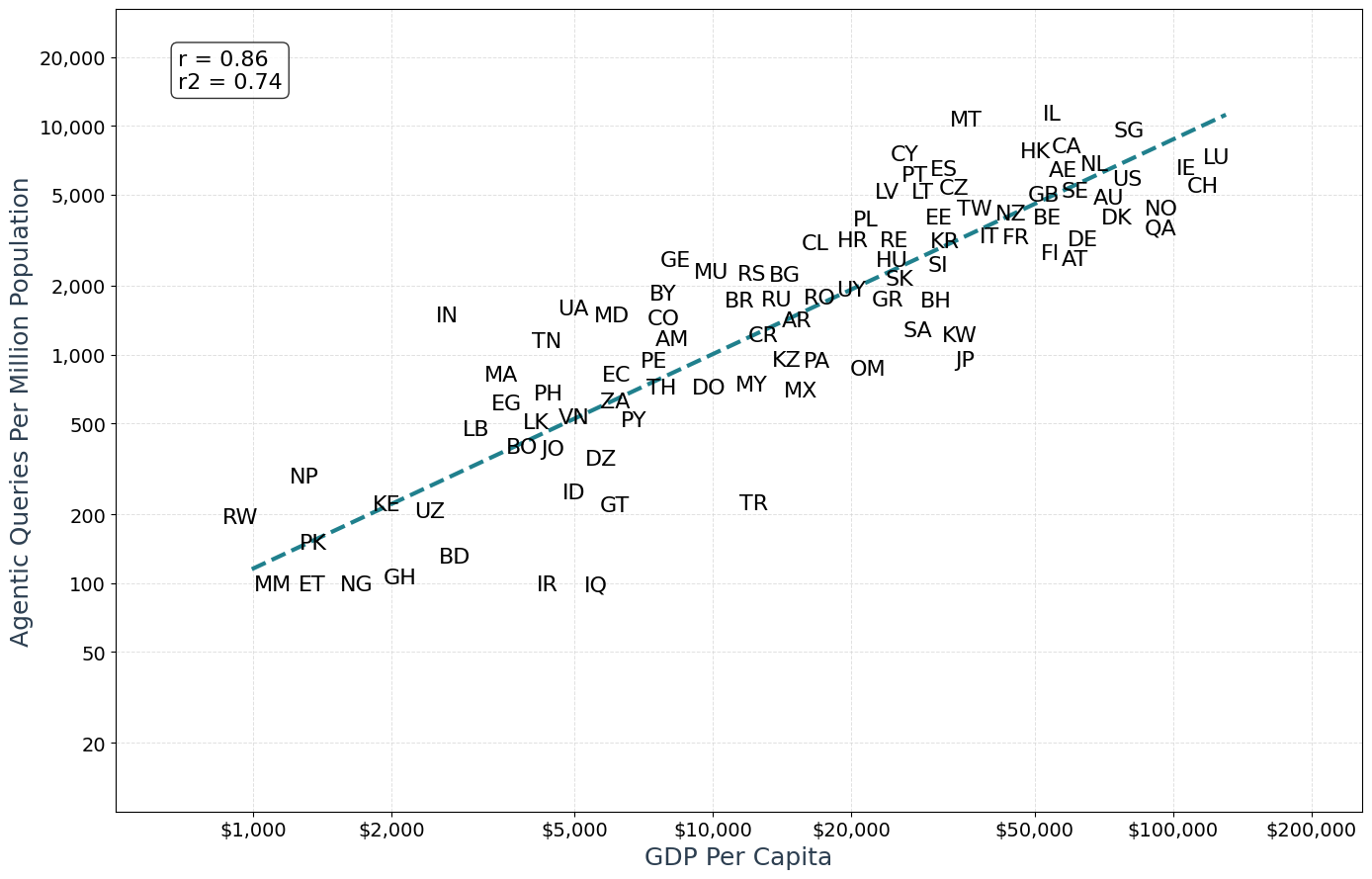
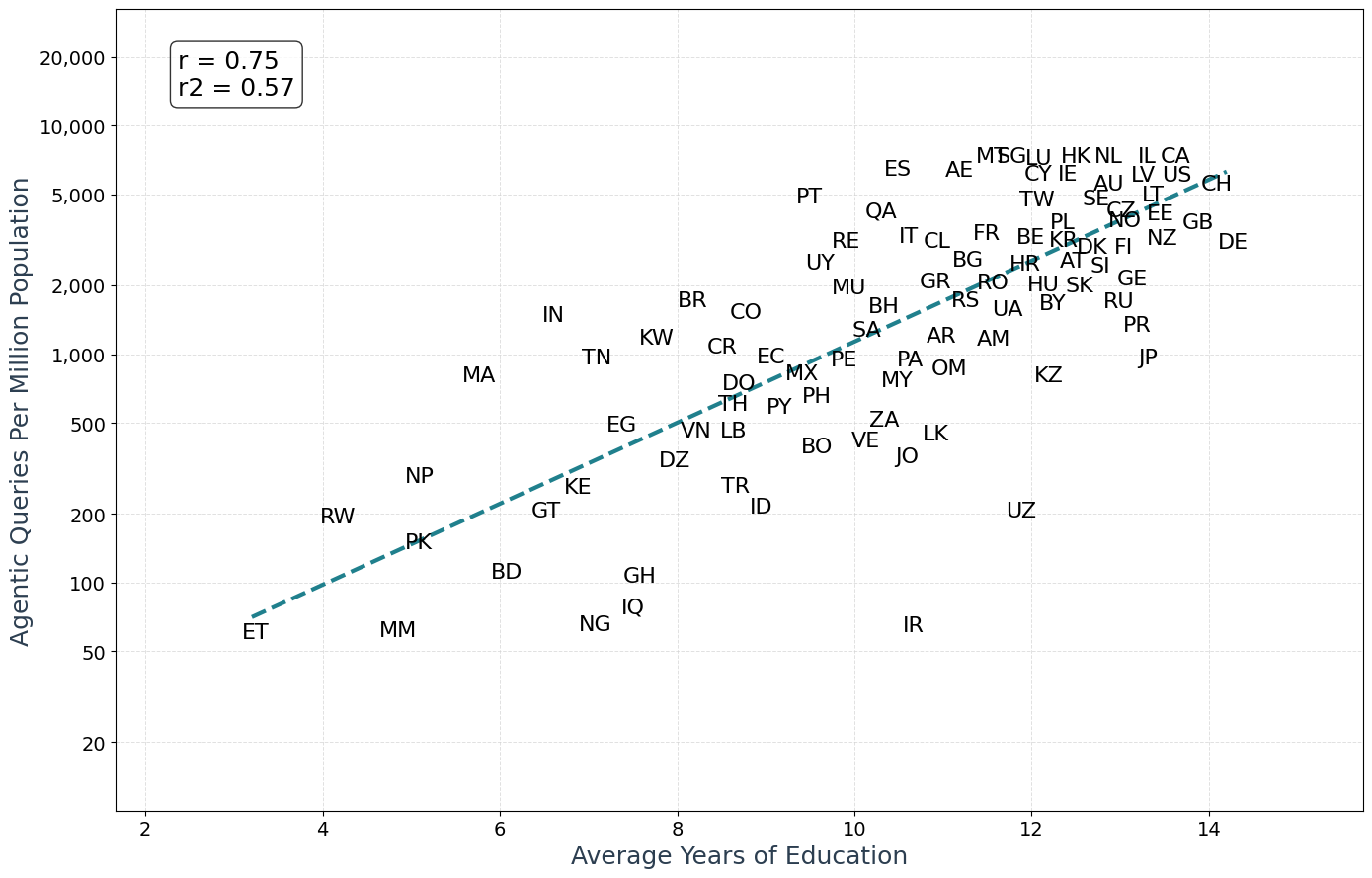
- Wealth and education matter: Countries with higher average income and more education had more agent users and more agent actions.
- Jobs that use computers a lot use agents more: Digital Technology (like software work), Academia (including students and educators), Finance, Marketing, and Entrepreneurship made up over 70% of agent users and actions.
What people use agents for
The researchers’ taxonomy showed:
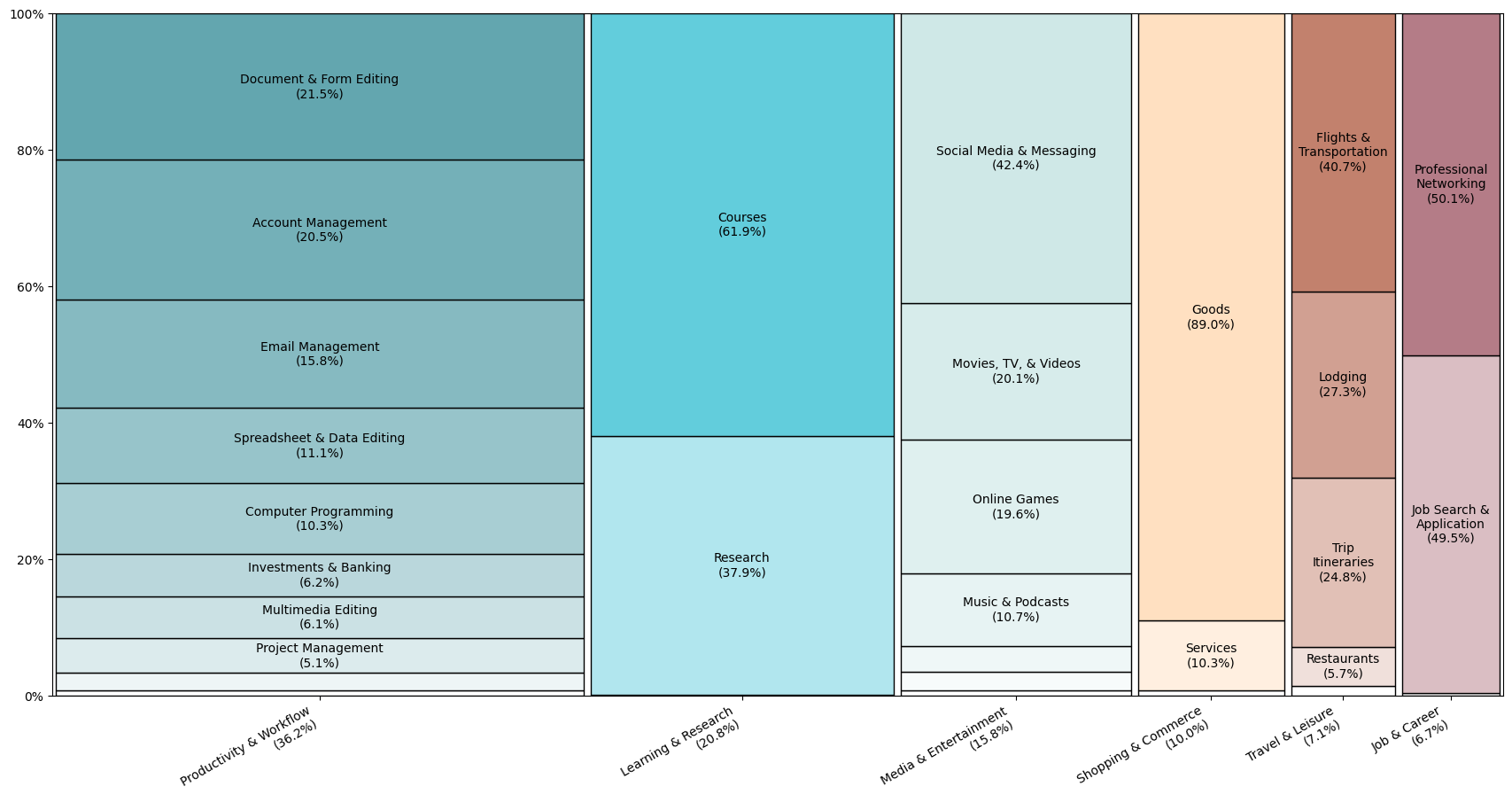
- Big topics:
- Productivity and Workflow, and Learning and Research together made up most actions (about 57%).
- Media (like social media, music, videos) and Shopping also had many actions.
- Common subtopics:
- Courses (13%), Shopping for Goods (9%), Research (8%), Document Editing (8%), Account Management (7%), Social Media (7%).
- Frequent tasks:
- Exercise assistance (9%), Research summarizing/analysis (7%), Document creation/editing (7%), Product searching/filtering (6%), Research searching/filtering (6%).
- Where actions happen (websites and apps):
- Some areas are very concentrated (for example, top 5 sites cover 97% of music/video/professional networking actions).
- Other areas are spread out across many sites (like account management or project management).
- Personal vs. school vs. work:
- About 55% of actions were personal, 30% were professional/work-related, and 16% were educational.
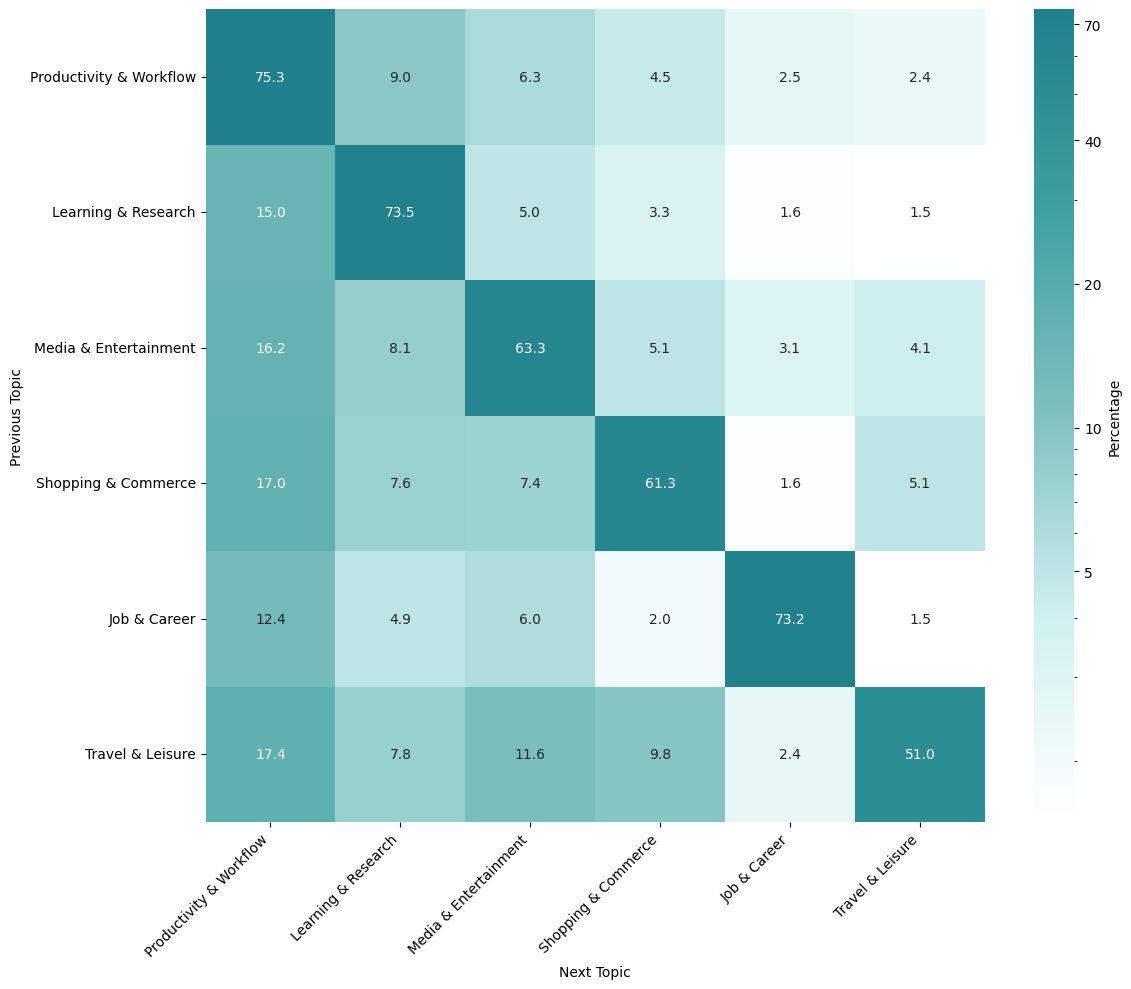
- How use changes over time:
- In the short term, people keep using agents for the same kinds of tasks (their habits “stick”).
- Over time, users shift away from travel and entertainment toward more thinking-heavy tasks like productivity, learning, and career activities.
Why these results matter
This is one of the first large studies showing how real people use general-purpose AI agents in the wild. It tells us:
- Agents aren’t just a trend—they’re already helping with everyday tasks.
- People who work with information (and people in richer, more educated places) are leading the way.
- The most common uses are practical: learning, getting work done, managing accounts and documents, and shopping.
Understanding these patterns helps builders, schools, and governments prepare for wider agent use.
What this could mean for the future
- For researchers: The taxonomy and data open up new questions about how agents change behavior, productivity, and skills over time.
- For businesses: Agents could streamline work, lower costs, and automate routine tasks. Early training and clear workflows may speed adoption.
- For policymakers: As use grows faster in richer, more educated countries, pay attention to digital access and education to avoid widening gaps.
- For educators and students: Agents are already used for courses and research. Schools may want to teach “agent literacy”—how to direct agents responsibly and check their work.
Overall, AI agents are starting to act as reliable digital helpers. As they get better, they could reshape how we learn, work, and handle everyday tasks—making some things faster and easier, while also raising new questions about skills, fairness, and responsible use.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper.
- External validity of findings: results are drawn from Comet desktop consumer users only, excluding enterprise/government, logged‑out, and incognito users; generalizability to broader populations, mobile contexts, and other agent platforms is untested.
- Short observation window: the study covers July 9–Oct 22, 2025 and excludes a major agent update (rolled out Oct 23/Nov 6); stability of patterns across versions, seasonality, and longer‑run dynamics are unknown.
- Rollout endogeneity: pre‑GA access tied to subscription tiers creates selection bias (early adopters are not random); no identification strategy is used to separate rollout effects from user propensity to adopt/use.
- Lack of causal inference: country‑level correlations with GDP per capita and education are descriptive; confounding factors (e.g., language support, connector availability, pricing, regulatory frictions, payment access) are not controlled.
- Measurement error in occupation inference: occupations are inferred from query‑based classifiers, validated on only 1,000 items, with 81–89% accuracy; no inter‑annotator agreement, confusion matrices, or uncertainty propagation to
AAR/AURestimates are reported. - No ground truth linkage for occupations: lack of validation against self‑reported job titles or verified employment records to quantify systematic misclassification by sector or region.
- Sparse user attributes: absence of demographics (age, gender, income), firm characteristics, or education levels at the user level prevents equity/inequality analyses and within‑country heterogeneity tests.
- Narrow “agentic” definition: the study excludes tool‑only actions (e.g., code interpreter, web search) and multi‑call sessions; this likely undercounts complex or multi‑step agent workflows and biases use‑case shares.
- Episode/session granularity: queries are the unit of analysis; session‑level measures (multi‑step plans, dwell time, action chains) and outcomes (completion success) are not captured.
- Success and efficacy metrics missing: no measures of task completion rates, error/failure modes, handoffs to manual steps, time saved, or user satisfaction; usage intensity is proxied solely by query counts.
- Retention and habit formation: while short‑term stickiness and long‑run shifts are noted, the drivers of transitions (e.g., onboarding, UI prompts, performance improvements, pricing) are not modeled or tested causally.
- Pricing and friction effects: the impact of subscription tiers, OAuth/connector permission friction, and onboarding design on adoption and usage is not quantified or experimentally evaluated.
- Connector coverage as a confounder: cross‑country adoption may be driven by uneven availability/quality of connectors and environment integrations; coverage maps and controls are not included.
- Language support and localization: adoption/use by language is not analyzed; potential gaps from limited multilingual support and localized interfaces remain unexplored.
- Mobile and native app environments: analyses focus on web environments; native apps, OS‑level actions, and mobile ecosystems (potentially dominant for some tasks) are excluded.
- Environment measurement scope: only websites are mapped; app‑level telemetry (with consent) and cross‑environment task continuity are not instrumented.
- Taxonomy construction transparency: the embedding model, hyperparameters (e.g., K in K‑means), clustering stability across seeds, and decision rules for merges/splits are not specified; reproducibility and robustness are unclear.
- Taxonomy validation depth: the golden dataset size (n=1,000) and sampling strategy may be unrepresentative; per‑class precision/recall, calibration, and topic‑wise error analysis are not reported.
- Taxonomy drift: potential evolution of use cases over time and across products is not studied; procedures for maintaining, updating, and generalizing the taxonomy to new domains are unspecified.
- Uncertainty quantification:
AAR/AURand share estimates lack confidence intervals or error bars; classification error is not propagated into downstream metrics. - Distributional usage patterns: the heavy‑tail of user activity (e.g., Gini/Pareto) and concentration of usage among super‑users vs casual users is not characterized.
- Comparative baselines: substitution/complementarity between agents and traditional search/chatbot workflows is not measured; no A/B tests disabling agent features to estimate incremental value.
- Multi‑agent orchestration and network effects: predicted externalities from protocols like A2A are not empirically tested; no measurements of collaborator/agent‑to‑agent workflows.
- Safety and reliability: failure taxonomies, unsafe actions, misfires, and environment‑specific error rates are not analyzed; no guardrail efficacy or rollback metrics are reported.
- Economic and productivity impacts: the study does not quantify labor productivity, quality improvements, or economic outcomes (e.g., purchase conversions, revenue uplift) causally in professional or educational settings.
- Sectoral/regulatory constraints: adoption barriers in regulated industries (healthcare, finance, public sector) are not assessed, especially given the exclusion of enterprise/government cohorts.
- Cohort dynamics across updates: how major capability upgrades (e.g., multi‑tab control) change adoption, intensity, and use‑case mix is left unexplored.
- Permissions and privacy trade‑offs: how privacy settings, consent flows, and data retention preferences affect adoption and agent capability utilization is not examined.
- Bot/automation contamination: potential non‑human or scripted usage is not audited; no bot‑detection filters or sensitivity checks are reported.
- Marketing and awareness effects: the role of product launches, campaigns, and media coverage on adoption spikes and cohort composition is not modeled.
- Geography‑specific constraints: payment rails, local regulations, and infrastructure reliability as determinants of country‑level adoption are not incorporated.
- Cross‑topic transitions: mechanisms behind transitions toward more cognitively oriented topics (e.g., skill acquisition, trust formation) are not distinguished from compositional or UI effects.
- Data availability and reproducibility: no commitment to release code, aggregate datasets, or taxonomy artifacts (even in synthetic or privacy‑preserving forms) to enable replication and external validation.
- Personal/professional/educational context labeling: context classification accuracy (83%) is nontrivial; no per‑context error analysis or sensitivity of reported shares to misclassification.
- User deletion and survivorship bias: excluding users who deleted accounts may bias adoption/retention metrics; no sensitivity analyses including pre‑deletion activity.
- Within‑occupation task alignment: the mapping between O*NET task portfolios and the agentic taxonomy is not quantified; it remains unclear which job tasks are well‑served vs underserved by current agent capabilities.
- Interface design effects: the impact of UI choices (e.g., prompt suggestions, agent affordances) on adoption and task mix is not experimentally tested.
- Security/compliance posture: how security features and compliance constraints (e.g., SOC2, HIPAA readiness) influence enterprise adoption and use cases is not evaluated.
Glossary
- Agent Adoption Ratio (AAR): A metric quantifying adoption relative to a segment’s user share. "AAR (Agent Adoption Ratio) is the ratio between agent adopter share and user share."
- Agent Usage Ratio (AUR): A metric quantifying usage intensity relative to a segment’s user share. "AUR (Agent Usage Ratio) is the ratio between agentic query share and user share."
- Agent2Agent Protocol (A2A): A proposed standard for agent-to-agent collaboration. "For instance, Agent2Agent Protocol (A2A)."
- Agentic AI: AI systems that autonomously pursue user-defined goals by planning and acting to affect real-world environments. "We define agentic AI systems as AI assistants capable of autonomously pursuing user-defined goals by planning and taking multi-step actions on a user's behalf to interact with and effect outcomes across real-world environments."
- Agentic query: A query where the agent takes control of tools or the browser to act on external applications or environments. "We define an agentic query as one that involves the agent taking control of the browser or taking actions on external applications—such as email or calendar clients—through connectors built on the Model Context Protocol (MCP) or via API calls."
- Agentic taxonomy: A hierarchical classification of agent use cases across topic, subtopic, and task. "we introduce a hierarchical agentic taxonomy that organizes use cases across three levels: topic, subtopic, and task."
- Agentic workflow: The iterative cycle an agent follows—thinking, acting, observing—to achieve a goal. "Under the ReAct framework, an agentic workflow typically cycles automatically between three iterative phases to achieve the end goal: thinking, acting, and observing"
- Embeddings: Vector representations of text used to capture semantic meaning for tasks like clustering. "extract their embeddings, and apply K-means clustering to group them based on semantic similarity."
- Extensive margin: The adoption dimension of behavior (whether users adopt). "We report two sets of results on the adoption and use of AI agents: the extensive and intensive margins"
- General availability (GA): A release stage when a product is available to all users. "Overall, agent adoption and usage intensity demonstrate sustained growth with acceleration following the general availability (GA) of Comet."
- Golden dataset: A trusted, validated set used to benchmark classification accuracy. "We validate the classification accuracy against a golden dataset of 1,000 anonymized and desensitized queries."
- Intensive margin: The usage intensity dimension (how much adopters use). "We report two sets of results on the adoption and use of AI agents: the extensive and intensive margins"
- Jitter: A plotting technique adding small offsets to labels or points to reduce overlap. "Jitter is applied to the country labels to provide better visual separation."
- K-means clustering: An unsupervised algorithm that partitions data into K clusters by minimizing within-cluster variance. "apply K-means clustering to group them based on semantic similarity."
- LLM: A machine learning model trained on large text corpora to understand and generate language. "2025 is frequently heralded as the year of agentic AI, as the frontier shifts from conversational LLM chatbots to action-oriented AI agents."
- Log scale: A plotting scale using logarithms to handle wide value ranges. "The plots are on a log scale, but the labels are in absolute values for better readability."
- Model Context Protocol (MCP): A protocol enabling agents to connect to external tools and applications via context. "through connectors built on the Model Context Protocol (MCP) or via API calls."
- Multi-agent orchestration: The capability to coordinate workflows across multiple collaborating agents. "More advanced agent capabilities also include multi-agent orchestration—the ability to interface with and manage workflows across multiple collaborating agents—"
- National Career Clusters Framework: A framework organizing occupations into clusters and pathways. "classify their O*NET occupation clusters and subclusters based on the National Career Clusters Framework"
- O*NET: A U.S. database of standardized occupational information and taxonomies. "classify their O*NET occupation clusters and subclusters"
- Open-world web environments: Real-world, unconstrained web contexts in which agents act across sites and services. "general-purpose AI agents operating in open-world web environments."
- p-value: A statistical measure indicating significance of a correlation or regression coefficient. "p is the p-value of the correlation coefficient"
- R-squared: The proportion of variance explained by a regression model. "R2 is the R-squared of the regression lines."
- ReAct framework: An agent design pattern alternating reasoning with actions and observations. "Under the ReAct framework, an agentic workflow typically cycles automatically between three iterative phases"
- Self-evolution: An agent’s capability to identify resource gaps and dynamically expand them. "and self-evolution—the ability to identify gaps in pre-specified resources and dynamically expand them."
- Semantic similarity: A measure of how similar texts are in meaning, used for grouping or clustering. "group them based on semantic similarity."
Practical Applications
Overview
Below are practical, real-world applications that follow directly from the paper’s findings, methods, and innovations around general-purpose AI agents operating in open-world web environments (Perplexity Comet and Comet Assistant). Applications are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring further research, scaling, or development). Each item notes sectors, potential tools/products/workflows, and assumptions or dependencies that may affect feasibility.
Immediate Applications
These applications leverage the paper’s observed adoption patterns, hierarchical agentic taxonomy (topics → subtopics → tasks), and the agent’s demonstrated ability to act across web environments via browser control and MCP/API connectors.
- Software/IT (Digital Technology)
- Use case: Agent-assisted code authoring, execution, and review; automated issue triage across repositories and ticketing systems.
- Tools/products/workflows: “Developer Copilot for the Web” with connectors to GitHub/GitLab/Jira; code-run sandboxes; agent-led PR preparation and unit test generation.
- Assumptions/Dependencies: Reliable code execution sandboxes; permissioned access to repos and CI; guardrails for secure tool use.
- Marketing and Sales
- Use case: Social media content creation, scheduling, and engagement; market research synthesis; discount/search automation for partner procurement.
- Tools/products/workflows: “Social Media Autopilot” using the Media → Social Media subtopic; “Market Insights Synthesizer” using Learning → Research tasks; “Promo Hunter” for Shopping → Goods/Services discount search.
- Assumptions/Dependencies: Platform API access and rate limits; ToS-compliant automated posting/engagement; human-in-the-loop approvals for outbound messaging.
- Finance
- Use case: Investment research summarization and filtering; portfolio monitoring dashboards; light-weight trade preparation (not execution) with supervisor approvals.
- Tools/products/workflows: “Investment Research Assistant” (Productivity → Investments/Banking); automated analyst briefings; broker-neutral pre-trade checklists.
- Assumptions/Dependencies: Read-only access to financial data sources; strict compliance controls; trade execution stays human-supervised.
- Education (Academia and Students)
- Use case: Course navigation; exercise assistance; research search and synthesis; citation-linked reading lists.
- Tools/products/workflows: “Course Copilot” integrated with LMS; “Exercise Assistant” (Learning → Courses); “Research Synthesizer” with inline citations and source verification.
- Assumptions/Dependencies: LMS connectors; academic integrity policies; institutional acceptance for agent-aided assignments; opt-in data usage.
- Enterprise Productivity and Knowledge Work
- Use case: Email triage and unsubscribe workflows; document/spreadsheet creation and editing; calendar scheduling; project status summarization.
- Tools/products/workflows: “Inbox Cleanup” (Productivity → Email Management) including unsubscribe routines; “Doc/Sheet Composer”; “Calendar Coordinator”; “Project Summarizer.”
- Assumptions/Dependencies: Identity and access management (IAM); fine-grained permissions; audit logs; clear escalation paths.
- Retail and Commerce
- Use case: Product search/filtering, discount code application, cart management, order tracking, and returns.
- Tools/products/workflows: “Shopping Agent” that spans Shopping → Goods/Services; connectors to retailers, discount platforms, and payments.
- Assumptions/Dependencies: E-commerce APIs and payment integrations; fraud prevention; user consent for transactions; adherence to site ToS.
- Travel and Leisure
- Use case: Flight/hotel discovery and booking; restaurant reservations; itinerary planning; loyalty program management.
- Tools/products/workflows: “Trip Planner” (Travel → Flights/Lodging/Restaurants); reservation scraping; booking with confirmation and receipts to email.
- Assumptions/Dependencies: Stable booking APIs; payment and identity verification; transparent refund/changes policies.
- HR and Career
- Use case: Job search and application completion; professional networking outreach (message drafting, connection requests).
- Tools/products/workflows: “Job Application Assistant” (Job/Career → Job Search/Application); “Networking Assistant” for LinkedIn-like platforms with templated outreach and follow-ups.
- Assumptions/Dependencies: Platform ToS compliance; user approval for messages; resume parsing; privacy-preserving storage.
- Media and Communications
- Use case: News filtering and summarization; playlist management for music/podcasts; video navigation and clipping for internal briefs.
- Tools/products/workflows: “News Digest” (Media → News); “Playlist Curator”; “Video Navigator” with transcript and clip exports.
- Assumptions/Dependencies: Content access rights; fair-use boundaries; API stability; locale/language support.
- Policy and Public Administration (Immediate actions informed by findings)
- Use case: Digital inclusion initiatives targeting lower-GDP/education geographies; workforce training for knowledge-intensive sectors (marketing, entrepreneurship, digital tech).
- Tools/products/workflows: Government-funded “Agent Literacy” programs; public-sector pilots using Comet-like assistants for document management and citizen inquiry triage.
- Assumptions/Dependencies: Procurement and compliance pathways; privacy-by-design; accessibility standards; multilingual support.
- Analytics and Product Strategy (Using AAR/AUR metrics)
- Use case: Adoption and usage dashboards using Agent Adoption Ratio (AAR) and Agent Usage Ratio (AUR) to identify over-/under-represented segments; targeted onboarding flows by occupation cluster.
- Tools/products/workflows: “Agent Ops Dashboard” for tracking AAR/AUR; cohort-based onboarding; taxonomy-informed feature bundles.
- Assumptions/Dependencies: Clean telemetry; transparent metric definitions; segment classification accuracy; privacy-preserving aggregation.
Long-Term Applications
These applications build on the paper’s signals about diffusion, multi-agent orchestration, cross-environment action-taking, and taxonomy-guided generalization, but need further capability gains, standardization, governance, or integration with physical systems.
- Cross-Agent Orchestration and Agent-to-Agent Commerce
- Use case: Agents negotiating and executing cross-platform workflows (e.g., procurement-to-pay across vendors, multi-supplier sourcing, service-level coordination).
- Tools/products/workflows: Standards like A2A Protocol; “Agent Mesh” routers; multi-agent planners coordinating tasks across tabs/services.
- Assumptions/Dependencies: Interoperability protocols; trust frameworks; dispute resolution; auditability and non-repudiation.
- Autonomous Enterprise Operations (RPA 2.0 with Open-Web Reach)
- Use case: End-to-end workflows spanning email, docs, ERP/CRM, supplier sites, and financial approvals with minimal human intervention.
- Tools/products/workflows: “Ops Autopilot” combining taxonomy-defined task packs (e.g., Account Management, Project Management, Investments/Banking) with robust guardrails and review queues.
- Assumptions/Dependencies: Deep system integrations; role-based access; robust exception handling; regulatory compliance (SOX, GDPR).
- Sectoral Expansion into Physical Environments (IoT and Robotics)
- Use case: Bridging lower-adoption physical clusters (manufacturing, healthcare, construction) by coupling agents to IoT/edge/robotic systems for scheduling, monitoring, and physical task dispatch.
- Tools/products/workflows: “Factory Floor Coordinator” aligning ERP tasks with machine telemetry; “Clinical Intake Orchestrator” for healthcare admin; construction permit and inspection scheduling.
- Assumptions/Dependencies: Secure control channels; safety certifications; liability frameworks; strong identity and environment isolation.
- Personalized Education at Scale
- Use case: Adaptive curricula, exercise generation, and continuous formative assessment across institutions, with agent-managed course logistics and research coaching.
- Tools/products/workflows: “Adaptive Course Copilot” integrated with LMS, digital reading rooms, and institutional repositories; longitudinal learning analytics aligned to the taxonomy.
- Assumptions/Dependencies: Institutional buy-in; academic integrity safeguards; explainability; accessibility for diverse learners.
- Consumer Autonomy with Advanced Safeguards
- Use case: Durable “Life Ops” agents managing shopping, travel, finance, subscriptions, and communications, with explicit constraints and consent layers.
- Tools/products/workflows: “Personal Agent Wallet” for payments, identity, and permissions; policy-based action controls; continuous transparency reports.
- Assumptions/Dependencies: Strong privacy and consent mechanisms; universal identity standards; redress and rollback capabilities for erroneous actions.
- Policy, Governance, and Measurement Frameworks
- Use case: National/regional strategies to address adoption inequality; agent safety standards; economic measurement of agentic contributions (leveraging AAR/AUR-like statistics).
- Tools/products/workflows: “Agent Safety Baselines” (permissioning, rate limits, logs); public dashboards tracking adoption/usage; regulatory sandboxes for autonomous purchasing and messaging.
- Assumptions/Dependencies: Multi-stakeholder consensus; international alignment on standards; reliable, privacy-preserving data collection.
- Taxonomy-Driven Ecosystems and Marketplaces
- Use case: A marketplace of “task packs” mapped to the hierarchical agentic taxonomy (topics → subtopics → tasks), tailored by sector and occupation.
- Tools/products/workflows: “Agent Connector Marketplace” that binds tasks to environments; vetted templates per occupation cluster (e.g., marketing, entrepreneurship, academia).
- Assumptions/Dependencies: Continuous taxonomy maintenance; third-party developer ecosystem; quality assurance and certification programs.
- Human-Agent Collaboration Patterns and Workforce Transformation
- Use case: Redesign of roles to emphasize higher-cognition tasks, consistent with observed user migration toward cognitively oriented topics over time.
- Tools/products/workflows: Role restructuring playbooks; collaboration protocols; training curricula for “agent supervisors” and “workflow designers.”
- Assumptions/Dependencies: Organizational change management; updated performance metrics; ethical guidelines for task allocation.
- Cross-Lingual and Global Inclusion
- Use case: Broadening adoption beyond high-GDP/education contexts via localization, affordability, and digital literacy programs.
- Tools/products/workflows: “Global Agent Access” bundles with localized connectors and training; subsidy programs; low-bandwidth modes.
- Assumptions/Dependencies: Government/NGO partnerships; robust multilingual models; culturally aware UX; sustainable funding.
- Safety, Compliance, and Audit Innovations
- Use case: Comprehensive guardrails for autonomous actions (purchases, messaging, bookings) with explainability and traceable citations.
- Tools/products/workflows: “Compliance Sandbox” for agents; immutable action logs; user-visible reasoning summaries; automated incident handling.
- Assumptions/Dependencies: Explainable action planning; secure logging; standard APIs for audits; alignment with sector-specific regulations.
These applications are grounded in the paper’s empirical insights—who adopts and uses agents (by cohort, country, occupation), how intensively they use them, and for what tasks—as well as the methodological contributions (hierarchical agentic taxonomy and segment-level metrics like AAR/AUR). They can guide product roadmaps, deployment priorities, policy design, and everyday workflows as agentic AI diffuses across sectors and geographies.
Collections
Sign up for free to add this paper to one or more collections.