A paradox of AI fluency
Abstract: How much does a user's skill with AI shape what AI actually delivers for them? This question is critical for users, AI product builders, and society at large, but it remains underexplored. Using a richly annotated sample of 27K transcripts from WildChat-4.8M, we show that fluent users take on more complex tasks than novices and adopt a fundamentally different interactional mode: they iterate collaboratively with the AI, refining goals and critically assessing outputs, whereas novices take a passive stance. These differences lead to a paradox of AI fluency: fluent users experience more failures than novices -- but their failures tend to be visible (a direct consequence of their engagement), they are more likely to lead to partial recovery, and they occur alongside greater success on complex tasks. Novices, by contrast, more often experience invisible failures: conversations that appear to end successfully but in fact miss the mark. Taken together, these results reframe what success with AI depends on. Individuals should adopt a stance of active engagement rather than passive acceptance. AI product builders should recognize that they are designing not just model behavior but user behavior; encouraging deep engagement, rather than friction-free experiences, will lead to more success overall. Our code and data are available at https://github.com/bigspinai/bigspin-fluency-outcomes
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “A paradox of AI fluency”
Overview: What is this paper about?
This paper asks a big question: Does being good at using AI change what you get out of it? By studying thousands of real chat conversations between people and an AI, the authors show that skilled users act like active teammates with the AI, while beginners are more passive. Surprisingly, skilled users see more failures—but those failures are easier to spot and fix, and the skilled users also succeed more often on harder tasks.
What questions did the researchers ask?
They focused on three easy-to-understand questions:
- Do more skilled users try harder, more complex tasks?
- Do skilled users “work with” the AI differently than beginners do?
- How do skill levels relate to failures—especially failures that are hard to notice—and to overall success?
How did they study it?
They looked at 27,000 anonymous ChatGPT conversations from a public dataset, covering 27 months (May 2023–July 2025). Then they asked AI tools to label each conversation in three ways:
- User fluency (how skilled the person seemed):
- High, moderate, low, or minimal.
- Interaction style: “augmentative” (treating AI like a thought partner) vs “delegative” (handing off the task and accepting whatever comes back).
- Specific behaviors (like asking for clarification, iterating, or passively accepting answers).
- Task complexity (how hard the task was):
- A 1–5 scale, plus notes about what made it hard (like needing domain knowledge or having an unclear goal).
- Failure type:
- Visible failures: the problem is obvious in the conversation (for example, the user says, “That’s wrong—try again”).
- Invisible failures: the chat looks fine, but the result is off-target or wrong (for example, the AI sounds confident but is incorrect, and no one notices).
- They also tracked patterns like “The Confidence Trap” (AI is wrong but sounds sure) or “The Walkaway” (the user quietly gives up).
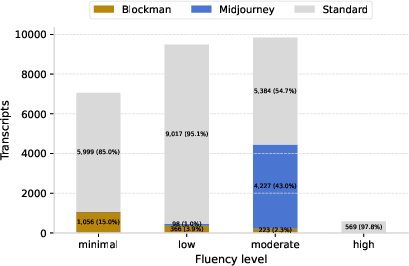
To avoid skewed results, they mostly excluded two unusual groups of chats:
- “Midjourney” prompting scripts that went viral in 2023 (lots of similar prompts).
- “Blockman Go” group chats that looked like an automated agent using the system.
Finally, they used a statistical model (think: a careful math check) to see whether user fluency still predicts success after accounting for other things like task difficulty, conversation length, and topic.
What did they find, and why does it matter?
Here are the main results, with simple examples and why they’re important:
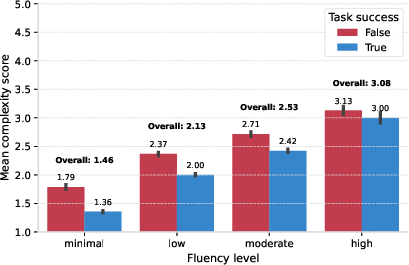
- Skilled users take on harder work.
- On a 1–5 difficulty scale, the highest-fluency users tackled tasks averaging about 3.1 vs about 1.5 for the lowest-fluency users (a 1.6-point gap).
- Why it matters: Skilled users push AI toward more ambitious goals.
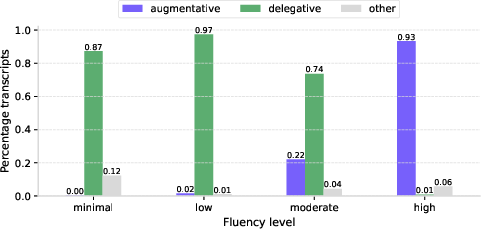
- Skilled users collaborate; beginners delegate.
- 93% of high-fluency chats were “augmentative” (the user iterates, asks follow-up questions, sets constraints, and critiques the AI).
- Under 1% of minimal-fluency chats were augmentative; these users mostly “delegate” and accept whatever the AI replies.
- Why it matters: Treating AI like a teammate you guide leads to better outcomes.
- The paradox: more skilled users see more failures—but that’s good.
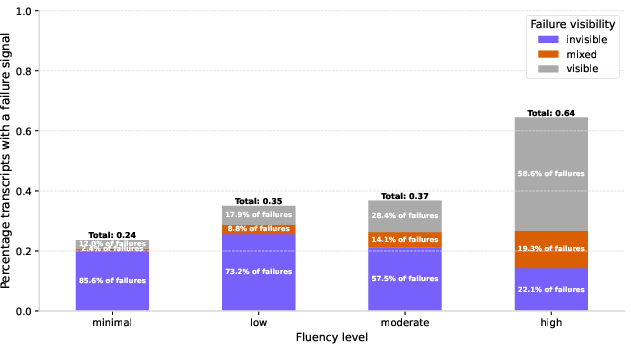
- High-fluency users: 64% of their chats showed at least one failure signal.
- Minimal-fluency users: 24% showed a failure signal.
- Why this isn’t bad: For high-fluency users, 59% of failures were visible (they noticed issues and engaged to fix them). For minimal-fluency users, only 12% were visible—most failures were invisible (they “looked” fine but missed the goal).
- Translation: Beginners often walk away with results that seem OK but aren’t. Experts catch and correct mistakes.
- Skilled users are better at hard tasks and recovery.
- They succeed more often on complex tasks.
- They also show “partial recovery” patterns (they notice a problem, steer the AI, and get closer to the goal).
- Why it matters: Real progress often comes from noticing errors early and iterating.
- Fluency itself predicts outcomes, even after controlling for other stuff.
- After accounting for task difficulty, conversation length, and topic, higher user fluency still:
- Increases the chance of success overall.
- Increases the chance that failures are visible (and therefore fixable).
- Extra context: Who’s using AI, and how is it changing?
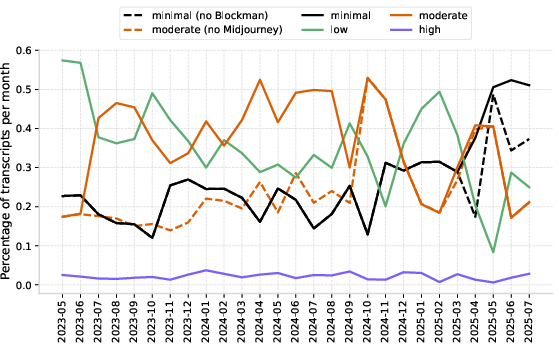
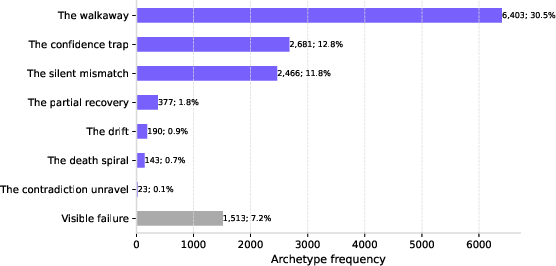
- High-fluency users are rare and stayed rare throughout the time period.
- The number of minimal-fluency users grew over time.
- Why it matters: Most people need help learning how to use AI effectively.
What does this mean for the future?
Here are the practical takeaways:
- For everyday users:
- Be an active partner. Ask the AI to clarify, add constraints, compare options, show sources, and check its work.
- Don’t accept the first answer. Iterate. If something feels off, say so and steer the conversation.
- Think of AI like a smart but sometimes overconfident teammate. Your job is to guide and verify.
- For teachers and trainers:
- Teach “AI fluency” skills: how to refine prompts, question outputs, detect subtle misses, and recover from errors.
- Emphasize that “sounds confident” doesn’t equal “correct.”
- For product designers and AI builders:
- Design for engagement, not just convenience. Interfaces should invite users to check, compare, and iterate.
- Build features that surface uncertainty, encourage critique, and make it easy to revise.
- Short-term “friction” (more steps) can improve long-term outcomes.
In short: Success with AI isn’t just about how powerful the model is. It’s also about how you use it. The people getting the most value don’t passively accept answers—they actively work with the AI, catch problems early, and improve the results step by step.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several important issues unresolved that future work could address to strengthen validity, causal claims, and generalizability.
- External validity: Results are drawn from a free, English-only, deidentified ChatGPT dataset (WildChat-4.8M). It is unclear whether findings hold for paid/professional users, other platforms/models, or non-English interactions.
- Model-version confounds: Analyses do not control for the specific LLM used (e.g., GPT‑3.5 vs GPT‑4 variants) or model updates over time, which could affect failure visibility and success rates independently of user fluency.
- User identity and clustering: Lack of persistent user IDs prevents modeling user-level random effects or learning dynamics; per-user trajectories and within-user changes in fluency are unobservable.
- Representativeness of the “Standard” subset: Excluding the large Midjourney and Blockman subsets improves internal focus but may reduce ecological validity; sensitivity analyses beyond fluency distributions (e.g., outcomes, failures) are not fully reported.
- Non-toxic filter bias: Using only the non-toxic subset may remove important failure patterns (e.g., safety refusals, abuse), potentially underestimating or reshaping failure visibility and archetype distributions.
- LLM-driven annotation reliability: Fluency, complexity, and failure labels are produced by LLMs; no human validation, inter-annotator agreement, or calibration is reported, leaving measurement error and bias unquantified.
- Cross-construct dependence: The same or closely related LLM families annotate multiple constructs (fluency, complexity, failures), risking correlated errors or circularity in measuring predictors and outcomes.
- Annotation pipeline consistency over time: Early months reuse failure labels from a prior study; later months are newly annotated. Cross-period consistency checks for annotation criteria and thresholds are not reported.
- Construct validity of “fluency”: The 17 fluency and 7 anti-fluency behaviors are LLM-defined; evidence that these behaviors measure a coherent, stable construct across tasks, domains, and time is not provided.
- Complexity metric ambiguity: The paper alternates between “confidence_score” and “complexity_score” for a 1–5 scale; the exact variable used, its semantic meaning, and its validation are unclear.
- Success definition tied to failure labels: “Success” is defined as the absence of any failure indicators, which could penalize high-fluency users who make failures visible and may not reflect whether the user’s goal was actually achieved.
- Ground truth outcomes: There is no independent ground truth (e.g., task completion judged by humans, external result checks, or user-reported outcomes) to validate success/failure labels, especially for “invisible” failures.
- Domain confounds: Task domain is only a random intercept; domain-by-fluency interactions and domain-specific effects (e.g., coding vs writing vs brainstorming) are not analyzed, limiting actionable guidance by task type.
- Causal inference: Observational correlations between fluency and outcomes cannot establish that augmentative behaviors cause better outcomes; randomized or quasi-experimental interventions are needed.
- UI/product implications untested: The recommendation to “encourage friction” and deeper engagement is not evaluated via controlled UX experiments (A/B tests), leaving user satisfaction and long-term retention effects unknown.
- Mediation mechanisms: Which specific fluency behaviors mediate improvements (e.g., iterative refinement vs verification steps) is not disentangled; mediation analyses are absent.
- Ordinal treatment of fluency: Fluency levels are encoded as a linear scalar in GLMMs; ordered-logit models or non-linear effects (e.g., thresholds) are not explored.
- Missing interactions: Potential interactions (e.g., fluency × complexity, fluency × number of turns) are not modeled, obscuring how fluency advantages vary with task difficulty or conversation length.
- Statistical uncertainty: Figures and PPMI heatmaps lack confidence intervals or significance testing; small high-fluency sample sizes may inflate apparent associations.
- Archetype stability: The prevalence and interpretation of invisible failure archetypes are not validated across annotator models or with human judgment; portability of archetype detection is uncertain.
- Partial recovery vs success: “Partial recovery” is treated as a failure archetype; alternative success taxonomies that recognize partial goal achievement are not tested, potentially undercounting meaningful success.
- Time trends vs composition effects: Reported temporal trends in fluency may reflect changing user mix, task mix, or exogenous events rather than genuine population-level skill shifts; decomposition analyses are absent.
- Sensitivity to conversation length: Length (n_turns) is a covariate but also an outcome of engagement; causal direction (does engagement cause length or vice versa?) remains ambiguous.
- Domain expertise confound: The study does not measure users’ domain expertise; higher “AI fluency” may proxy for general task competence, confounding interpretation of fluency effects.
- Cross-language generalization: No analysis examines whether patterns hold in non-English conversations or multilingual users, limiting applicability to global user bases.
- Per-turn dynamics: Interaction styles are assigned at the transcript level; within-conversation shifts (e.g., delegative → augmentative) and their impact on outcomes are not modeled.
- Replicability across annotator models: Robustness of findings to different annotator LLMs or model settings (temperature, prompts) is not reported; version drift may affect reproducibility.
- Exogenous-event analytics: While Midjourney and Blockman are identified as influential, the paper stops short of modeling how such events systematically reshape fluency, failure visibility, and outcomes—useful for forecasting future shocks.
- Downstream impact of invisible failures: The real-world consequences of “invisible” failures (e.g., errors propagated to decisions or artifacts) are not measured; risk assessment remains speculative.
- Demographic and equity considerations: Without user demographics, it is unknown whether invisible failures disproportionately affect specific groups, or whether fluency interventions widen/narrow performance gaps.
- Task-type heterogeneity: The study aggregates across task types; identifying which tasks benefit most from augmentative strategies (and which do not) remains an open question.
- Data loss characterization: “Small random data loss” during annotation is mentioned but not quantified or audited for non-random patterns that could bias results.
- Guidance granularity: Recommendations (e.g., teach users to iterate) are high-level; concrete, testable pedagogical interventions and curricula for improving AI fluency are not specified.
- Measurement invariance over time: No checks assess whether fluency or complexity scales remain consistent across months and model eras, risking temporal drift in labels.
- Ethical implications of making failures visible: The trade-off between surfacing failures and user experience (frustration, trust erosion) is not empirically evaluated.
Practical Applications
Immediate Applications
Below are actionable uses you can deploy now, mapped to sectors where relevant and noting key dependencies/assumptions.
- UX patterns that nudge “augmentative” use over “delegative” use (Software, Enterprise SaaS)
- What: Add lightweight “engagement scaffolds” in LLM apps: intent-recap prompts (“Here’s what I think you want—confirm or correct”), success-criteria checks, critique buttons (“challenge this,” “show uncertainties,” “list assumptions”), plan–review–execute toggles, and end-of-session alignment checks (“Did we meet your goal?”).
- Why (from paper): High-fluency users iterate, question, and steer; novices passively accept. Making failure visible reduces “invisible failures.”
- Dependencies/assumptions: Modest UI/UX changes; minor latency budget for extra prompts; willingness to trade some short-term satisfaction for higher long-term success.
- “Invisible failure” watchdogs embedded in chat workflows (Software, Customer Support, Education)
- What: Heuristics or LLM-based detectors that flag likely archetypes in-session: silent mismatch (intent recap mismatch), drift (topic deviation), contradiction (response conflicts with prior turns), death spiral (repetition loops), walkaway risk (no closure). Trigger recovery macros (“ask clarifying Qs,” “summarize agreed goal,” “propose next step”).
- Why: Novices disproportionately suffer silent/invisible failures; experts recover more often.
- Dependencies/assumptions: Use zero-/few-shot detectors today; instrument for precision/recall and human review; privacy-safe logging.
- Fluency-aware “coach mode” for novices (Software, EdTech, Enterprise enablement)
- What: Real-time guidance that spots anti-fluency behaviors (passive acceptance, one-shot asks) and suggests augmentative moves (iterative refinement, critical review). Provide micro-tips, e.g., “Ask me to restate your constraints,” “Request alternatives and trade-offs.”
- Why: Paper’s 17 fluency behaviors and 7 anti-fluency behaviors give a ready-made rubric for coaching.
- Dependencies/assumptions: On-device or server-side classifiers approximating the paper’s tagging (tag_user_fluency.py); careful UX to avoid nagging.
- Analytics that track “failure visibility ratio,” fluency behaviors, and task complexity (Software, Product Ops, Policy evaluation)
- What: Add product telemetry to measure visible vs. invisible failure proxies, counts of augmentative behaviors, conversation length, and complexity attempted. Build dashboards to A/B test engagement scaffolds.
- Why: The paper’s regressions show fluency predicts success and visibility; complexity depresses success—teams need to see these trade-offs.
- Dependencies/assumptions: Consent, anonymization, and governance for transcript analytics; adopt the paper’s tagging scripts as baselines.
- Rapid upskilling programs on AI fluency (Academia, Workforce Development, Corporate L&D)
- What: Short courses and micro-credentials that train augmentative habits: iterative refinement, goal negotiation, verification, contradiction checks, uncertainty awareness, and recovery techniques tied to the archetypes.
- Why: Success depends on user behavior as much as model capability; experts show higher success on complex tasks.
- Dependencies/assumptions: Curriculum built from the paper’s behavior taxonomy; pre/post assessments using classifier-based rubrics.
- Domain-specific “alignment checks” embedded in existing workflows
- Healthcare: In clinical documentation assistants, require: patient-specific constraints echo, uncertainty lists, source links, and clinician confirmation before saving. Dependencies: Clinical validation and privacy compliance.
- Finance/Legal: For memos/reports, require: constraints checklist, regulatory references, contradiction scan across sections, and sign-off prompts. Dependencies: Compliance frameworks; auditable logs.
- Software engineering: In code-gen flows, require: “spec echo” (restate requirements), test-plan proposal, and contradiction checks vs. prior requirements. Dependencies: CI integration; unit-test harnesses.
- Customer support: Ticket assistants perform: intent recap with the customer, drift alerts, and “resolution confirmation” before closure. Dependencies: CRM integration.
- Retrospective audits of internal chat logs using the paper’s methods (Industry, Academia)
- What: Apply tag_task_complexity.py and failure-archetype annotators to historical interactions to quantify invisible failures, identify high-impact archetypes, and prioritize product fixes and training.
- Dependencies/assumptions: Secure data access; acceptable LLM annotator costs; sampling for validation given LLM-based annotation noise.
- Procurement and IT governance guidance emphasizing engagement (Policy, Public Sector)
- What: Update evaluation checklists to require augmentative affordances (clarification prompts, goal restatements, recovery pathways) and training plans for end users.
- Dependencies/assumptions: Cross-agency consensus; alignment with accessibility and language access policies.
- Everyday personal assistant features that reduce invisible failures (Daily Life)
- What: Travel/booking/task assistants that auto-verify hours/prices, prompt for constraints and preferences, and propose alternatives with rationale.
- Dependencies/assumptions: API access to verification sources; users accept one or two added questions for higher accuracy.
- Product KPIs that reward “engagement quality,” not just CSAT (Software, Management)
- What: Add metrics like “visible failure ratio,” “recovery rate after drift,” and “goal confirmation rate” to performance dashboards.
- Dependencies/assumptions: Leadership buy-in to re-balance incentives away from frictionless experiences.
Long-Term Applications
These require additional research, scaling, validation, or regulatory work before broad deployment.
- Adaptive UIs that personalize scaffolding to detected fluency level (Software, EdTech, Enterprise)
- What: Real-time user modeling that tunes the degree of guidance—novices get structured plans and mandatory alignment checks; experts get advanced controls and optional scaffolds.
- Dependencies/assumptions: Reliable fluency classifiers across domains/languages; guardrails to avoid misclassification harms.
- LLMs trained to be proactive collaborators (Model training, RLHF/RLAIF)
- What: Fine-tune/reward models to initiate intent recap, ask clarifying questions, surface uncertainties, detect contradictions, and propose partial recoveries—explicitly optimizing to reduce invisible failures.
- Dependencies/assumptions: High-quality supervised signals for archetype detection; evaluation benchmarks for invisible failure reduction.
- Standardized “Invisible Failure Prevention” SDKs and telemetry schemas (Software ecosystem)
- What: Open libraries that provide conversation-state tracking, archetype detectors, contradiction/drift checkers, and plug-in recovery macros; common telemetry fields for cross-app comparisons.
- Dependencies/assumptions: Community consensus on archetype taxonomy; performance guarantees; privacy-first designs.
- Sector-specific co-pilots with safety-grade visibility guarantees
- Healthcare: Co-pilots that meet evidence-tracking and uncertainty-exposure standards, with measurable reductions in silent mismatches; EHR-integrated recovery workflows.
- Finance: Advisors with audit trails linking claims to sources and policy constraints; automated contradiction scans across reports.
- Dependencies/assumptions: Regulatory approval; third-party audits; liability frameworks.
- Regulatory standards and audits for human–AI interaction quality (Policy, Standards bodies)
- What: ISO-/NIST-like guidance that requires augmentative affordances, measures of failure visibility, and user training provisions for high-stakes deployments.
- Dependencies/assumptions: Multi-stakeholder processes; sector-specific tailoring; enforcement mechanisms.
- Longitudinal causal studies on training impacts (Academia, Policy evaluation)
- What: Randomized field experiments that quantify how AI fluency courses change failure visibility, recovery rates, task complexity attempted, and real productivity outcomes.
- Dependencies/assumptions: Access to telemetry; ethical approvals; representative samples beyond public chat datasets.
- “Engagement OS” for enterprises (Software, IT)
- What: A cross-app layer that standardizes intent recap, alignment checks, and recovery prompts across all in-house AI tools; central dashboards for invisible failure risk.
- Dependencies/assumptions: Integration with heterogeneous systems; change management across teams.
- Evaluation suites and leaderboards for invisible failure reduction (Research, Model evaluation)
- What: Benchmarks that stress-test models for drift, contradiction, and silent mismatch across domains; report “Invisible Failure Score” alongside accuracy.
- Dependencies/assumptions: Public datasets with gold labels; consensus metrics; community adoption.
- Agentic systems with internal “self-critique loops” (Robotics, Autonomy, Software agents)
- What: Agents that monitor for drift and contradiction in their own plans, initiate clarifying queries to humans, and trigger safe fallbacks when recovery stalls.
- Dependencies/assumptions: Reliable online detectors; human-in-the-loop protocols; real-time constraints.
- Credentialing for AI fluency (Education, HR)
- What: Recognized certifications tied to demonstrable augmentative behaviors and recovery skills; used in hiring and promotion for AI-augmented roles.
- Dependencies/assumptions: Validated assessments; industry recognition; avoidance of credential inflation.
- Incentive redesign in organizations (Management, Operations)
- What: Shift success metrics from speed-only to “successful completion without invisible failures,” rewarding teams for visible failure surfacing and recovery.
- Dependencies/assumptions: Cultural buy-in; alignment with customer satisfaction and compliance goals.
Cross-cutting assumptions and dependencies
- Generalizability: Findings are derived from WildChat-4.8M (public ChatGPT usage, English, 2023–2025) and LLM-based annotations; domain, language, and model differences may affect transfer.
- Annotation reliability: Automated fluency/archetype tagging should be validated and periodically recalibrated as models evolve.
- Privacy and governance: Any telemetry or transcript analysis requires strong anonymization, consent, and data minimization.
- User experience trade-offs: Engagement scaffolds add “constructive friction”; measure and balance against user satisfaction and abandonment.
- Model drift and upgrades: As LLMs improve, archetype prevalence may change; tooling and training must evolve accordingly.
Glossary
- Agency: The capacity of a user to actively shape and direct AI interactions and outcomes. Example: "Agency is a prominent theme of recent work on how AI expertise relates to outcomes"
- AI fluency: Expertise in effectively using AI systems, including prompting, iteration, and critical evaluation of outputs. Example: "Our own approach to AI fluency is inspired by \citet{anthropic2026fluency}"
- Anti-Fluency Behaviors: Behaviors that undermine effective AI use, such as passivity or uncritical acceptance. Example: "Anti-Fluency Behaviors: A list of zero or more behavior_name annotations with metadata:"
- Augmentative: An interaction style that treats the AI as a collaborator, iterating and refining toward the goal. Example: "Fluent users adopt an augmentative stance: they iterate collaboratively with the AI, refining their goals and critically assessing outputs as they go"
- Augmentative mode: A collaborative mode of working with the AI that surfaces and addresses failures during the interaction. Example: "these failures stem from experts' augmentative mode, which makes failure more visible and leads to a higher likelihood of recovery"
- Augmentative stance: A user's posture of actively collaborating with the AI rather than delegating tasks entirely. Example: "Fluent users adopt an augmentative stance: they iterate collaboratively with the AI, refining their goals and critically assessing outputs as they go"
- Binomial: A statistical family used in generalized linear models for binary outcomes. Example: "family=binomial"
- BOBYQA optimizer: A derivative-free optimization algorithm (Bound Optimization BY Quadratic Approximation) used to fit complex models. Example: "with the BOBYQA optimizer."
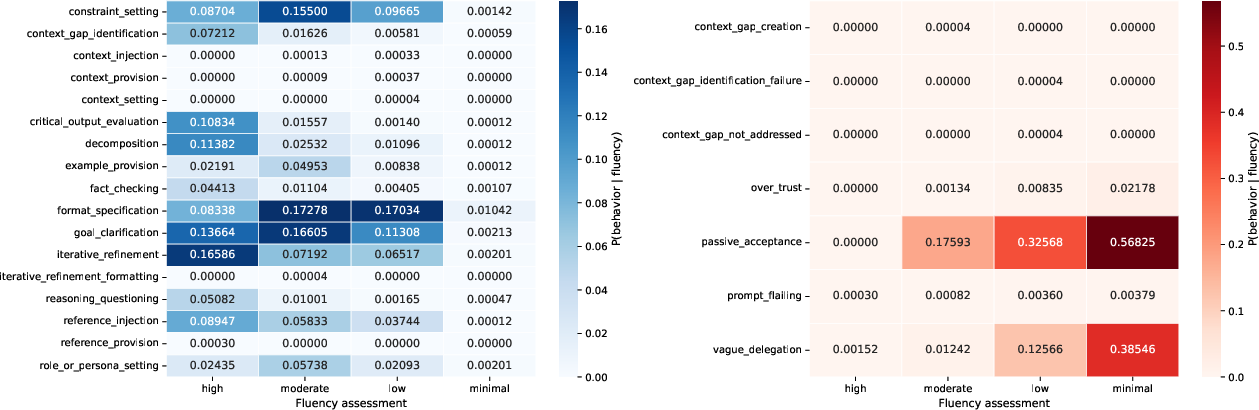
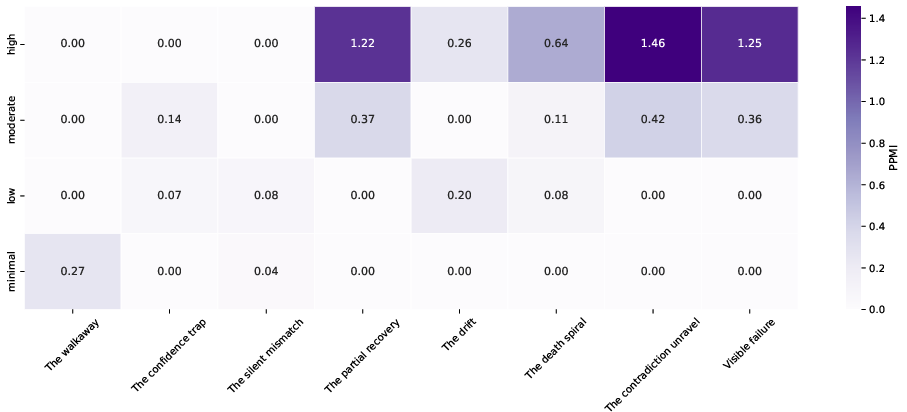
- Co-occurrence matrix: A matrix counting how often pairs of categories (e.g., archetypes and fluency levels) appear together. Example: "we first compiled a co-occurrence matrix between the archetypes and the fluency levels"
- Common ground: Shared knowledge and assumptions that conversational partners rely on to coordinate meaning. Example: "with a familiar sense of how common ground is established and negotiated"
- Conceptual replication: A study that tests the same underlying claim as prior work using different data or methods. Example: "We provide what is in effect a conceptual replication of this result using \mbox{WildChat-4.8M}"
- Delegative: An interaction style where users hand off tasks to the AI and passively accept outputs. Example: "By contrast, novice users are delegative: they tend to passively accept the AI's plans and responses, and often fail to get the information they need as a result."
- Domain expertise: Knowledge and skill in the task’s subject area (distinct from AI expertise). Example: "identify connections between domain expertise and productivity."
- Exogenous events: External, atypical factors that affect a dataset but are not inherent to the underlying process. Example: "they are exogenous events, and future events might have a different character."
- Fixed-effects predictors: Predictors in a statistical model whose effects are assumed to be constant across groups or clusters. Example: "The other fixed-effects predictors are {n_turns}, {complexity_score}, and {fluency_behavior_count}."
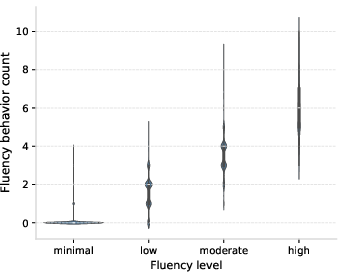
- Fluency behaviors: Observable actions indicating effective AI use (e.g., iteration, critical assessment). Example: "high-fluency users show many high-fluency behaviors, and low-fluency users show many anti-fluency behaviors."
- Generalized linear mixed-effects models: Statistical models that handle non-normal outcomes and include both fixed and random effects. Example: "we developed two generalized linear mixed-effects models"
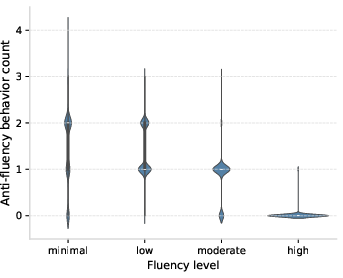
- Invisible failure: A failure where the interaction appears successful but the user’s goal is not actually met. Example: "Failure rates rise consistently by fluency level, but invisible failure rates fall by fluency level."
- Invisible failure archetypes: Named patterns that characterize how subtle, unnoticed failures occur in AI interactions. Example: "the invisible failure archetypes of \citealt{potts2026invisible}"
- Iterative_refinement: A fluency behavior involving repeated, focused improvement of the AI’s outputs. Example: "One pattern that stands out is that of {iterative_refinement}: it is highly characteristic of high-fluency users and essentially absent from low-fluency transcripts."
- Mixed (failure mode): A classification indicating that both visible and invisible failure signals are present. Example: "Basic failure mode classification: {visible}, {invisible}, or {mixed}"
- Passive_acceptance: An anti-fluency behavior where users accept AI outputs without sufficient scrutiny or iteration. Example: "A counterpart of this is {passive_acceptance}, which is the strongest single indicator of minimal- and low-fluency."
- Positive pointwise information (PPMI): A nonnegative association measure highlighting unexpectedly frequent co-occurrences. Example: "positive pointwise information (PPMI; \citealt{church-hanks-1990-word,Bullinaria2007})"
- Pragmatic: Relating to how meaning is inferred from context and conversational norms beyond literal content. Example: "they will be pragmatic, human-like conversationalists"
- PPMI matrix: A co-occurrence matrix reweighted by PPMI to emphasize informative associations. Example: "The heatmap is a PPMI matrix."
- Random intercept: A model component allowing each group (e.g., domain) its own baseline level. Example: "we included a random intercept for each domain."
- R2 (marginal/conditional): Goodness-of-fit measures for mixed models; marginal R2 for fixed effects only, conditional R2 including random effects. Example: "R2 Marg."
- RMSE: Root Mean Squared Error, a measure of the typical prediction error magnitude. Example: "RMSE"
- Scope ambiguity: Uncertainty about the boundaries or interpretation of the user’s task or request. Example: "{scope_ambiguity}"
- The Confidence Trap: An archetype where the AI’s unwarranted certainty leads the user to accept incorrect information. Example: "The Confidence Trap"
- The Contradiction Unravel: An archetype where the AI contradicts its prior statements without acknowledgment. Example: "The Contradiction Unravel"
- The Death Spiral: An archetype characterized by repetitive, unproductive loops that fail to incorporate feedback. Example: "The Death Spiral"
- The Drift: An archetype where the conversation veers off-topic from the user’s original goal. Example: "The Drift"
- The Mystery Failure: An archetype where the interaction fails without a clear, identifiable pattern. Example: "The Mystery Failure"
- The Partial Recovery: An archetype where some progress is recovered after a failure, but the goal is not fully achieved. Example: "The Partial Recovery"
- The Silent Mismatch: An archetype where the AI competently answers the wrong question without either party noticing. Example: "The Silent Mismatch"
- The Walkaway: An archetype where the user silently stops the conversation without resolution. Example: "The Walkaway"
- Visible failure: A failure that is overtly signaled in the interaction (e.g., user correction, explicit recognition). Example: "If the failure is {visible}, then only {Visible failure} is assigned."
Collections
Sign up for free to add this paper to one or more collections.

