- The paper reveals that human-LLM coding collaboration exhibits distinct interaction topologies (linear, star, tree) that strongly influence task performance.
- It uses rigorous statistical methods on curated datasets to quantify instruction-following fidelity, showing non-compliance rates up to 94% in complex workflows.
- The study highlights that session length and conversation structure significantly impact human satisfaction, guiding strategies to improve collaborative coding.
Empirical Analysis of Human-LLM Collaboration in Coding Conversations
Introduction
This study provides a comprehensive empirical dissection of human-LLM coding collaborations by analyzing large-scale, real-world multi-turn conversation datasets, specifically LMSYS-Chat-1M and WildChat. The work targets three core dimensions: (1) structural patterns of collaborative interactions, (2) instruction-following fidelity of LLMs, and (3) human satisfaction dynamics during iterative coding sessions. Emphasis is placed on isolating how task typology, conversation structure, and temporal factors modulate both collaborative efficacy and user experience.
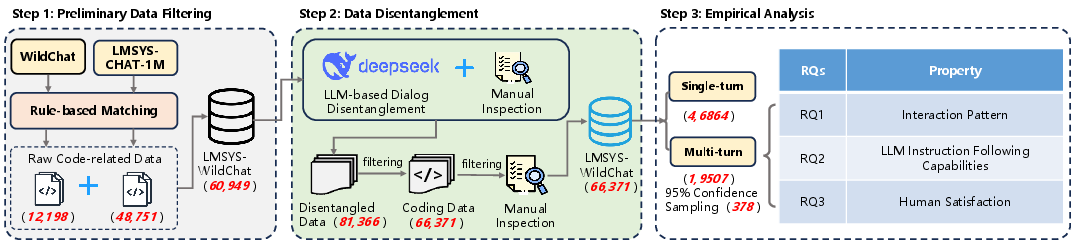
Figure 1: Overview of the research pipeline, including dataset selection, dialog disentanglement, sampling, and multi-level empirical analyses.
Dataset Curation and Methodology
From the original datasets, rule-based filtering retrieves 66,371 single-topic coding dialogues, of which 19,507 are multi-turn. The methodology leverages LLM-assisted disentanglement, manual validation with expert and graduate annotators, and stratified sampling (378 multi-turn conversations) for statistical robustness. The analysis deploys open card sorting for taxonomy building, Fisher’s exact test and standardized residuals for linkages, and satisfaction trajectory scoring for sentiment tracking.
Interaction Pattern Taxonomy
Annotators identify five principal coding task types (design-driven, requirements-driven, code quality optimization, environment configuration, information querying) and three dominant interaction topologies: linear (sequential progression), star (single-topic divergence), and tree (hierarchical exploratory structures).
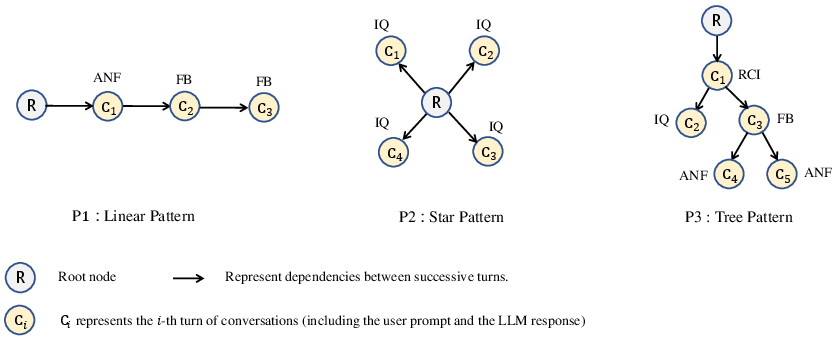
Figure 2: Interaction pattern archetypes—linear, star, and tree—with nodes mapping prompt-response pairs and arrows showing dependency flows.
Statistical testing reveals that code quality optimization overwhelmingly prefers linear sequences (86.8% in low-turn cases, residual = 1.39), while design-driven development is biased toward tree-like branching (residual = 1.56). Information queries disproportionately adopt star patterns. Turn depth is pivotal: short dialogs (up to 4 turns) are predominantly linear, but longer interactions (>4 turns) transition toward complex tree configurations.
Instruction-Following Challenges
Instruction adherence is quantified using LLM-based evaluators (DeepSeek-Reasoner) and multi-level accuracy metrics. At the conversation level, the loose accuracy is 24.07%, indicating that nearly 76% of coding sessions have at least one instruction-following failure. At the instruction level, loose accuracy rises to 48.24%.
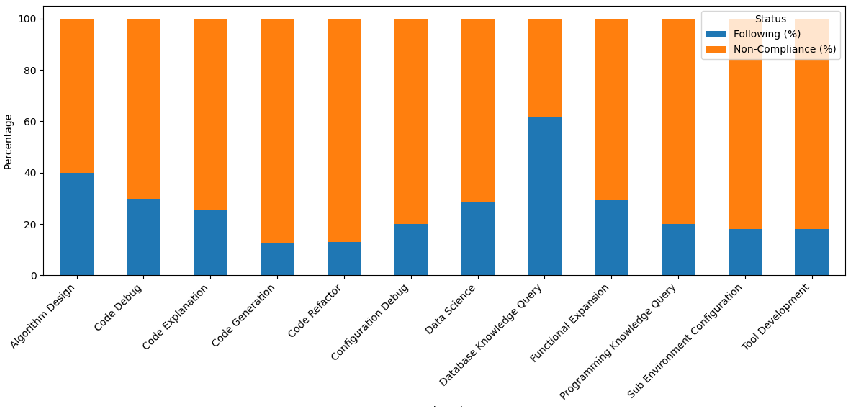
Figure 3: Substantial variability in compliance and non-compliance rates across subtasks; tasks such as code refactoring and environment configuration display the highest non-compliance.
Subtask-wise, code generation, code refactoring, tool development, and environment configuration exhibit non-compliance rates >80%, whereas structured query tasks (e.g., database querying) perform best (non-compliance of 38%). Interaction topology is also a strong modulator: the tree pattern is a high-risk form, with a non-compliance probability of 94%, compared to 64%–73% for star/linear.
Errors in adherence are temporally skewed, clustering at turn 2 for short dialogs and in the final quintile (81–100%) for extended sessions. Instruction intent is a critical determinant—intents like bug fixing, code refactoring, and “question LLM response” experience non-compliance rates >60–70%, while information queries are less error-prone.
Human Satisfaction and Experience Dynamics
Satisfaction is evaluated via a combination of automated (DeepSeek) and manual means, with sentiment inferred both from explicit user responses and implicit lexicon.
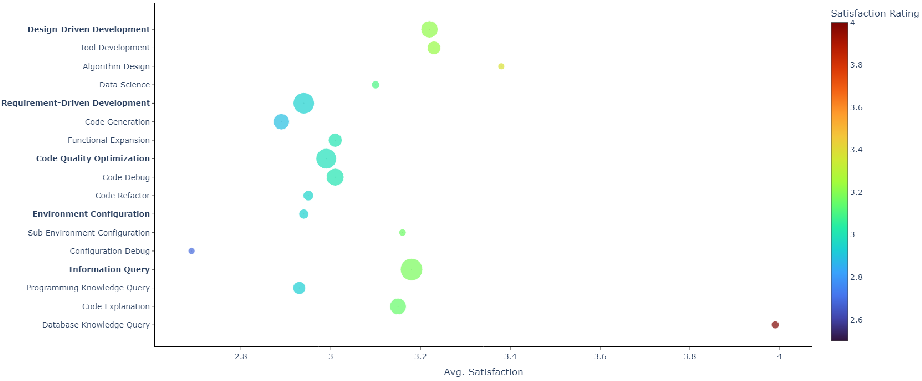
Figure 4: Mean satisfaction ratings, stratified by task type and subtask. Design-driven development and structured queries yield the highest scores.
Code quality optimization and requirements-driven development are associated with lower satisfaction (<3.0 on a five-point scale), while database knowledge querying or high-level design elicit more positive feedback (up to ~4.0). Satisfaction is inversely correlated with turn count; as sessions extend, content shifts toward bug-fixing and error correction, with satisfaction degrading accordingly.
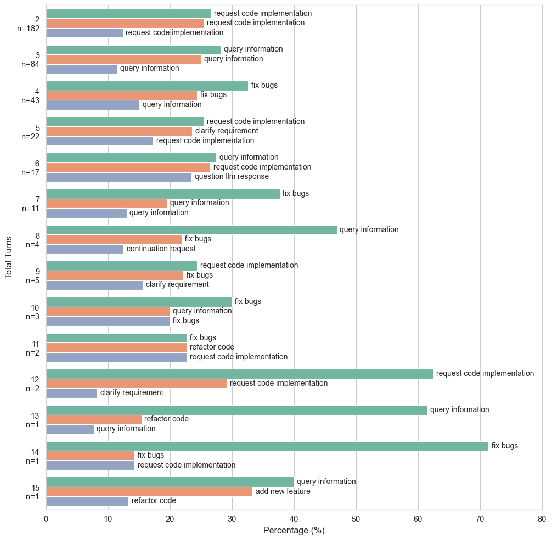
Figure 5: Distributional shift in dialog focus with turn length—longer conversations see an upsurge in bug-fixing as the core task, reflecting deteriorating collaboration efficiency.
Furthermore, satisfaction trajectories are predominantly negative in the tree pattern, reflecting the inability of current LLMs to reliably recover from early failures or manage branching reasoning.
Metrics and Comparative Analysis
A four-way comparison (human scorer and three metric variants) on satisfaction distributions confirms that LLM-based evaluators tend to overestimate user satisfaction, and conversation-level or trajectory-aware methods are necessary to closely approximate user experience.
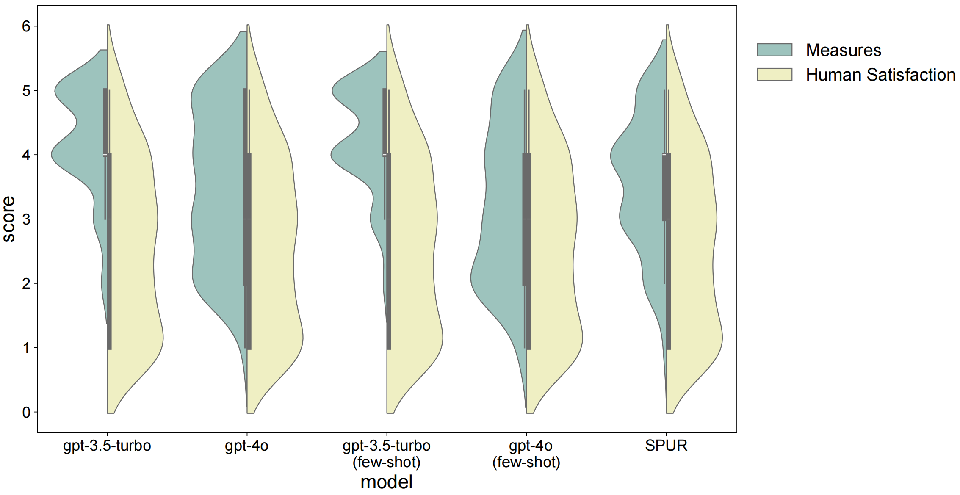
Figure 6: Comparative distribution of human satisfaction ratings vs. different LLM-based automatic evaluation methods.
Implications
From a practical standpoint, findings indicate that LLM-powered coding copilots should structurally bias users toward linear workflows for most tasks to minimize context fragmentation and non-compliance. Developers should monitor session length and proactively mitigate conversational drift into complex tree-like patterns, especially for tasks with known high non-compliance rates. For research, advancing evaluation metrics that use satisfaction trajectories, incorporating psychological constructs like recency and emotional amplification, will be critical for aligning model improvements with authentic human experience.
Future Directions
This work highlights the necessity for:
- Robust context management and memory retention mechanisms in LLMs to evade rapid context erosion in iterative dialogs.
- Adaptive dialog systems capable of detecting high-risk interaction topologies and intervening (e.g., by summarization, re-centering, or clarification).
- Development of multi-level satisfaction metrics that account for conversational dynamics, emotional valence, and eventual outcome, not just single-turn response quality.
Conclusion
The study provides systematic empirical evidence that task structure, interaction topology, and instruction intent profoundly shape the efficiency and satisfaction of real-world human-LLM coding collaborations (2512.10493). The results underscore acute limitations in current LLMs’ multi-turn reliability—especially as session complexity grows—and identify targeted directions for improving collaborative AI interfaces, adaptive dialog strategies, and human-centered evaluation protocols.

