The Era of Real-World Human Interaction: RL from User Conversations
Abstract: We posit that to achieve continual model improvement and multifaceted alignment, future models must learn from natural human interaction. Current conversational models are aligned using pre-annotated, expert-generated human feedback. In this work, we introduce Reinforcement Learning from Human Interaction (RLHI), a paradigm that learns directly from in-the-wild user conversations. We develop two complementary methods: (1) RLHI with User-Guided Rewrites, which revises unsatisfactory model outputs based on users' natural-language follow-up responses, (2) RLHI with User-Based Rewards, which learns via a reward model conditioned on knowledge of the user's long-term interaction history (termed persona). Together, these methods link long-term user personas to turn-level preferences via persona-conditioned preference optimization. Trained on conversations derived from WildChat, both RLHI variants outperform strong baselines in personalization and instruction-following, and similar feedback enhances performance on reasoning benchmarks. These results suggest organic human interaction offers scalable, effective supervision for personalized alignment.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to improve AI chatbots by learning directly from real conversations with people, not just from carefully prepared training data. The authors call it RLHI, short for “Reinforcement Learning from Human Interaction.” The main idea is: instead of training a chatbot only on expert-made examples, use the natural back-and-forth with everyday users to figure out what different people want and how the bot should respond better over time.
What questions were the researchers asking?
The paper tries to answer simple, practical questions:
- Can AI learn to be more helpful and more personal by paying attention to what users say in real chats?
- How can we turn everyday user messages—like “please add more details” or “make it more formal”—into training signals the AI understands?
- Does learning from actual conversations make the AI better at following instructions and solving problems?
How did they do the research?
The researchers used a large set of real chat logs (called WildChat) and built two training methods that make use of normal user behavior. Think of a chatbot as a student, and users as the teachers or coaches giving feedback during a conversation.
Method 1: User-Guided Rewrites
- Analogy: Imagine you write an essay, and your teacher says, “Add more facts and numbers.” You then rewrite your essay with those improvements.
- In chats, when a user isn’t satisfied, they often follow up with hints like “be more concise” or “explain step-by-step.” The AI takes that feedback and rewrites its previous answer to better match the user’s request.
- The system then learns that “the rewrite is better than the original” and trains itself to prefer answers matching that kind of feedback next time.
Method 2: User-Based Rewards (using personas)
- Analogy: A judge scores answers based on what a specific person likes. If Pat likes short, friendly tips, answers that are short and friendly get higher points.
- A “persona” is a short summary of a user’s preferences, built from their long conversation history (for example, likes expert tone, wants lots of details, prefers step-by-step explanations).
- For each new user request, the AI generates several possible answers. A reward model (a program that scores responses) looks at the user’s persona and the conversation, then gives higher scores to the answers that best fit that user’s style and needs. The AI learns to produce more of those high-scoring answers.
To train the AI, the authors use a preference-learning approach called DPO (Direct Preference Optimization). In simple terms, DPO teaches the model: “Choose the better answer over the worse one,” especially conditioned on the user’s persona, so the model learns personalized behavior.
They also apply quality checks to filter out noisy or harmful data, because real-world messages can sometimes be low-quality or inconsistent.
What did they find, and why is it important?
The team tested their methods across three areas: personalization, instruction-following, and reasoning.
Here are the main takeaways:
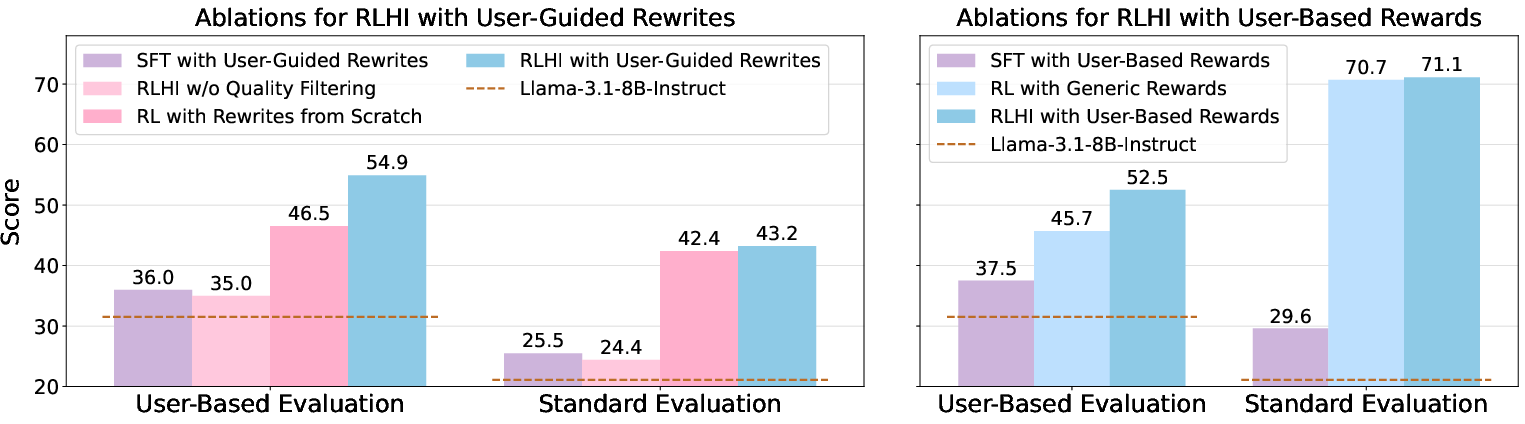
- Learning from real user feedback makes the AI more personal. It aligns better with individual user preferences (for example, tone and level of detail). In their tests, models using RLHI often beat strong baselines in personalization.
- It also improves instruction-following. The AI becomes better at doing exactly what users ask. One method reached about 78% win rate on a standard benchmark (AlpacaEval 2.0, length-controlled), which is a big jump over the base model.
- It helps reasoning too. Even when users only pointed out mistakes (without giving the correct solution), the AI improved at math and other reasoning tasks. Accuracy went up from about 26.5% to 31.8% across several benchmarks.
- Reinforcement learning (optimizing over “better vs. worse” answers) worked better than simple supervised finetuning (only learning from “good” answers). Comparing pairs provides stronger training signals.
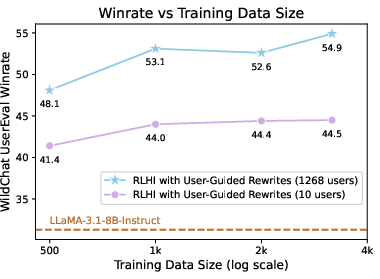
- Diversity and quality matter. Training on feedback from many different users helped the AI learn broader preferences. Filtering out low-quality data was crucial to avoid learning the wrong lessons.
Why this matters: It shows that everyday conversations are a powerful, scalable source of training. Instead of being stuck with limited, expert-made datasets, AI can keep improving by listening to real people and adjusting in real time.
What does this mean for the future?
This research points to a practical path for building smarter, more personalized assistants:
- AI can learn continually from real interactions, not just from one-off, static datasets.
- It can adapt to each person’s style and needs, making it feel more like a helpful personal assistant.
- With good safety and privacy practices, this approach could enable “personal superintelligence”: assistants that know your preferences and get better the more you use them.
In short, the paper argues we’re entering an “era of real-world human interaction,” where AI learns most effectively by working with us in our everyday conversations—and RLHI is a simple, scalable way to make that happen.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps that remain unresolved and could guide future research:
- Data provenance, consent, and governance: The paper uses in-the-wild logs (WildChat) but does not address whether end-user consent, opt-out mechanisms, or lawful bases (e.g., GDPR/CCPA) were obtained for persona inference and model training; a concrete consent and governance framework is missing.
- Privacy-preserving personalization: No techniques (e.g., differential privacy, secure aggregation, federated learning, PII redaction) or metrics are provided to prevent deanonymization or leakage of sensitive traits inferred in personas.
- Safety of personalization: The methods could learn unsafe or norm-violating preferences (e.g., jailbreak tendencies, harmful advice). There is no multi-objective training with explicit safety constraints or policy for refusing to honor unsafe persona attributes.
- Persona construction validity: Personas are LLM-generated summaries without empirical evaluation of accuracy, bias, stability, or robustness to noisy/contradictory histories; no error analysis or agreement with human-labeled ground truth.
- Handling preference drift: There is no mechanism to detect and adapt to evolving preferences over time (e.g., recency weighting, drift detection, or change-point models) nor to evaluate performance under non-stationary user behavior.
- Mis-personalization detection and fallback: The system lacks safeguards to identify incorrect or overconfident personalization and fall back to user-agnostic behavior when confidence is low.
- Cold-start users: Users with sparse history were filtered out; methods for effective personalization with little or no history (e.g., meta-learning, population priors, active preference elicitation) are not explored.
- Shared devices and identity resolution: No approach is proposed for multi-user contexts, account sharing, or identity switching that could corrupt personas.
- Reward model personalization gap: The “user-based” reward simply conditions on a persona but is not trained with persona-conditioned labels; it’s unclear whether a reward model explicitly trained for persona-conditioned preferences would outperform the current approach.
- Reward model calibration and reliability: No off-policy evaluation, calibration, or robustness analysis of the reward model when conditioning on personas; vulnerability to reward hacking or gaming is untested.
- Pair construction via max/min scoring: Selecting the highest- and lowest-scored candidates may amplify reward noise/outliers; ablations on N (number of candidates), top-k vs. extreme pairs, and robustness to reward errors are missing.
- Quality filtering audit: Filtering relies on reward models and RIP heuristics, but there is no quantitative audit of false positives/negatives, demographic bias in filtering, or downstream impact on alignment.
- Feedback extraction reliability: The classification of user follow-ups (via GPT-4o) lacks reported accuracy and error modes; the sensitivity of the pipeline to misclassification is not evaluated.
- Conflict resolution between persona and task: Persona-guided inference sometimes hurts instruction-following; there is no method to reconcile conflicts (e.g., explicit preference hierarchies, constraint satisfaction, or arbitration policies).
- Factuality and calibration trade-offs: Improvements are shown for preference judgments, but the effects on factual accuracy, hallucination rates, and confidence calibration are not measured.
- Long-term user outcomes: No evidence on retention, satisfaction over weeks, or behavior change across sessions; only turn-level win rates are reported, without longitudinal A/B testing.
- Online learning and safety: The work is offline; open questions remain around safe exploration, off-policy evaluation, rollback strategies, and guardrailed deployment for continual online RL from live interactions.
- Computational scalability: Online DPO with N=64 candidates per prompt is costly; there is no analysis of compute/latency/energy, practical deployment strategies (e.g., bandit sampling, speculative decoding), or cost-performance trade-offs.
- Cross-lingual and domain generalization: The approach is evaluated primarily on English text and general tasks; performance under multilingual, code-switching, low-resource languages, and specialized domains (e.g., law, medicine) is untested.
- Broader modality and tool use: Methods and evaluation are text-only; extending RLHI to tool invocation, multimodal inputs, and action-taking (with grounded feedback) remains open.
- Synthetic reasoning realism: The reasoning setup uses simulated user comments in math; the ecological validity compared to real users is unclear, and comparisons to verifiable-feedback methods (e.g., PRM/RM trained on step-labels) are missing.
- Benchmark contamination and overlap: The paper does not audit for overlap between WildChat prompts and evaluation benchmarks; contamination risks and their impact on reported gains are unassessed.
- Evaluation reliability: Heavy reliance on closed LLM judges (o3, GPT-4 Turbo) may bias results; human evaluation is small (N=10, 50 turns each) with no inter-annotator agreement or statistical significance reporting.
- Fairness and disparate impact: No analysis of performance across demographic groups, protected attributes potentially inferred in personas, or fairness metrics under personalization.
- Adversarial personas and poisoning: The system may be vulnerable to persona poisoning or adversarially crafted histories; no defenses (e.g., anomaly detection, trust scoring, provenance checks) are proposed.
- User agency and transparency: Users have no mechanism to view, edit, or delete their inferred persona, control personalization intensity, or opt-out; UI/UX and explainability for personalization are unaddressed.
- Memory vs. persona design: The trade-offs between free-text persona summaries and retrieval-based personal memory (e.g., KNN over user logs) are not studied; hybrid architectures and compression strategies remain open.
- Hyperparameter sensitivity and algorithmic variants: Limited exploration of DPO hyperparameters, KL strength, and alternatives (e.g., IPO, ORPO, PPO-Lag) for persona-conditioned optimization.
- Interference between personalization and global helpfulness: No systematic study of whether optimizing for personal style degrades general capabilities or transfer across tasks/users (catastrophic interference).
- Robustness to distribution shifts: The model’s stability under sudden shifts in tasks, seasonal trends, or UI changes is not evaluated.
- Reproducibility: Key components (classification, judges) rely on closed API models; releasing code, prompts, and persona construction tools, or open-source approximations, is necessary for replication.
- Governance for prohibited preferences: There is no normative framework for disallowing certain user preferences (e.g., discriminatory or manipulative goals) while still personalizing safely.
Practical Applications
Immediate Applications
Below are applications that can be deployed now by adapting the paper’s methods and findings with standard product, MLOps, and privacy practices.
- Persona-guided customer support chat
- Sectors: software, customer service, retail, telecom
- Workflow: ingest opt-in chat logs → infer per-customer persona cards (tone, verbosity, evidence preference) → detect “re-attempts with feedback” → trigger User-Guided Rewrites to improve answers → deploy persona-conditioned response generation; optionally rerank N candidates with a persona-conditioned reward model (RM) at inference time
- Tools/products: persona builder service; feedback-type classifier; rewrite agent; persona-conditioned RM reranker; evaluation harness (WildChat UserEval-style); dashboards for A/B testing
- Assumptions/dependencies: user consent and data retention policies; robust quality filtering (e.g., RM gating); accurate feedback classification; compute budget for sampling/reranking; rollback/guardrails
- Enterprise knowledge assistants and IT helpdesks
- Sectors: enterprise software, internal IT, HR
- Workflow: mine internal helpdesk chats to learn preferred formats by role (e.g., structured steps for IT engineers, concise summaries for executives); apply User-Based Rewards to select best candidate answers per persona; periodically retrain with persona-conditioned DPO
- Tools/products: on-prem RLHI pipeline; per-role persona catalogs; RM-guarded content filters; audit logs
- Assumptions/dependencies: on-prem or VPC deployment; PII redaction; approval workflows; change management for updated models
- Developer copilots that learn from edits
- Sectors: software engineering, DevOps
- Workflow: treat code edits/re-prompts as “re-attempts with feedback”; run User-Guided Rewrites to learn preferred idioms (e.g., docstring density, error handling style) and toolchains; infer per-developer persona for style and verbosity; optionally RM-based reranking for completions in IDE
- Tools/products: IDE plugins capturing accept/reject/edit signals; persona memory; rewrite trainer; RM reranker
- Assumptions/dependencies: enterprise code privacy; opt-in telemetry; security reviews; efficient online or frequent offline updates
- Personalized tutoring and learning assistants
- Sectors: education, edtech
- Workflow: summarize student learning personas (step-by-step preference, analogies, rigor); when a student flags “step 3 is unclear,” trigger User-Guided Rewrite to fix explanations; deploy persona-guided generation during lessons and assignments
- Tools/products: student persona cards; hint-level rewrite agent; mastery dashboards
- Assumptions/dependencies: parental consent (minors), FERPA/GDPR compliance; bias checks to avoid stereotyping; safe math reasoning guards
- Writing and email assistants that adapt tone and structure
- Sectors: productivity software, enterprise communications
- Workflow: infer user tone/sign-off/structure preferences; when users request “add statistics” or “be concise,” treat as feedback for rewrite training; persona-conditioned generation for drafts and summaries
- Tools/products: email add-ins; persona controls UI; rewrite button with teach-back
- Assumptions/dependencies: user-controlled persona editing; content safety and confidentiality; robust quality filters
- E-commerce and shopping assistants with preference-aware answers
- Sectors: retail, marketplaces
- Workflow: derive personas for “evidence-seeking,” “budget-sensitive,” “eco-focused”; apply User-Based Rewards to elevate responses with stats, comparisons, or sustainability info as preferred
- Tools/products: product Q&A chat; RM reranker; persona-based merchandising hints
- Assumptions/dependencies: truthful data sources; compliance for claims; clear user consent
- Safety and moderation tuning via real interaction signals
- Sectors: platform safety, trust & safety
- Workflow: treat adversarial prompts and follow-ups as diverse supervision; use quality-filtered RLHI to improve refusal style and reduce jailbreak susceptibility; learn user-appropriate de-escalation tones
- Tools/products: safety-specific RM; adversarial-feedback filters; red-teaming loops
- Assumptions/dependencies: strict filtering to avoid learning from harmful instructions; safety review; conservative rollout
- Analytics and product research from persona mining
- Sectors: product, marketing, UX research
- Workflow: aggregate anonymized persona dimensions (tone, structure, evidence needs) to segment users and prioritize features/content templates
- Tools/products: persona analytics dashboard; cohort export
- Assumptions/dependencies: anonymization/aggregation; differential privacy where applicable; governance for downstream use
- Inference-time reranking without full RL training
- Sectors: any app embedding an LLM
- Workflow: sample k responses per prompt; apply persona-conditioned RM to pick best; no policy updates required
- Tools/products: lightweight RM service; sampler/reranker API
- Assumptions/dependencies: modest latency budget for k sampling; well-calibrated RM
- Academic replication and evaluation kits
- Sectors: academia, open-source
- Workflow: adopt persona-conditioned DPO, WildChat UserEval-style judges, and quality filtering to study personalization and instruction-following
- Tools/products: open-source pipelines, prompts, and metrics
- Assumptions/dependencies: ethical approvals for data use; transparent reporting
Long-Term Applications
These scenarios require further research, scaling, online learning infrastructure, safety guarantees, and/or regulatory alignment before broad deployment.
- Fully online, continual RLHI in production
- Sectors: consumer AI assistants, enterprise SaaS
- Workflow: always-on loop that mines live feedback, updates personas, applies online DPO with safe exploration, and ships gated policy improvements
- Tools/products: “RLHI Ops” platform (logging, consent, persona store, RM scoring, filtering, drift detection, rollback, audit trails)
- Assumptions/dependencies: robust guardrails and human-in-the-loop gating; causal evals to avoid reward hacking; versioned personas; incident response
- Privacy-preserving and federated RLHI
- Sectors: healthcare, finance, government, mobile OS
- Workflow: on-device persona construction; federated updates or secure enclaves; differentially private (DP) gradients; encrypted logs
- Tools/products: federated RLHI SDK; DP optimizers; secure enclaves
- Assumptions/dependencies: DP utility–privacy trade-offs; reliable edge compute; strict consent and retention policies (HIPAA/GDPR/CCPA)
- Clinical and regulated-domain copilots
- Sectors: healthcare, finance, legal, public sector
- Workflow: persona-aware assistants that adapt explanation depth and evidence but operate under domain-specific safety RMs and verified sources; staged deployment with human supervision
- Tools/products: compliance-tuned RM; provenance tracking; audit dashboards
- Assumptions/dependencies: regulatory approvals; liability frameworks; rigorous external validation; conservative online learning
- Cross-modal RLHI (voice, vision, actions)
- Sectors: multimodal assistants, accessibility, AR/VR
- Workflow: extend personas to prosody, visual formatting, and interaction pacing; learn from voice corrections and gaze/interaction signals
- Tools/products: multimodal RMs; signal fusion; accessibility personas
- Assumptions/dependencies: robust multimodal logging with consent; bias and fairness audits; latency constraints
- Implicit-feedback rewards and satisfaction modeling
- Sectors: consumer apps, content platforms
- Workflow: build RMs from dwell time, follow-on actions, subscription churn; combine with explicit feedback; optimize for measured satisfaction rather than proxy clicks
- Tools/products: counterfactual evaluation, uplift modeling; causality-aware RMs
- Assumptions/dependencies: avoiding clickbait/engagement traps; causal identification; long-horizon credit assignment
- Fairness- and safety-constrained personalization
- Sectors: platforms, edtech, hiring/HR tools
- Workflow: incorporate constraints into persona-conditioned optimization to prevent stereotyping or unequal quality; periodic fairness audits and red-team testing
- Tools/products: constraint-aware DPO; bias diagnostics; policy checkers
- Assumptions/dependencies: agreed fairness metrics; representative evaluation data; governance processes
- Persona portability and user-controlled profiles
- Sectors: platform ecosystems, identity/wallets
- Workflow: standardize a user-owned “persona card” that travels across apps with consent; apps consume, update, and respect user-edited preferences
- Tools/products: Personalization API standard; permissioned wallets; syncing services
- Assumptions/dependencies: cross-vendor standards; security and revocation; UX for transparency/editing
- Team- and organization-level personas for collaboration
- Sectors: enterprise collaboration, project management
- Workflow: learn shared norms (templates, definitions of done, tone) for teams; co-assistants that mediate between individual and team personas
- Tools/products: multi-level persona hierarchy; conflict resolution strategies
- Assumptions/dependencies: change management; privacy boundaries between users; auditing
- Government service chatbots tailored to literacy and languages
- Sectors: public services, social programs
- Workflow: adapt explanations to reading level, preferred language, and required evidence; rigorous safety and fairness constraints
- Tools/products: public-sector RLHI stack; certified content sources
- Assumptions/dependencies: procurement and compliance cycles; accessibility standards; oversight bodies
- Human–robot interaction informed by RLHI
- Sectors: robotics, smart devices
- Workflow: transfer RLHI principles to physical agents: use natural corrections to refine routines; long-term household personas for preferences
- Tools/products: multimodal feedback capture; safe exploration in the physical world
- Assumptions/dependencies: safety certification; sim-to-real transfer; robust perception
- Lifelong learning in education with curriculum-aware personas
- Sectors: education, workforce upskilling
- Workflow: track evolving learner personas across courses and years; adapt pedagogy and assessment strategies through continual RLHI
- Tools/products: longitudinal persona graphs; progression-aware RMs
- Assumptions/dependencies: longitudinal consent and portability; equity monitoring; standardized evaluations
Notes on feasibility across applications:
- Quality filtering is critical to leverage noisy real-world interactions; reward models must gate harmful or low-quality feedback.
- RL methods (persona-conditioned DPO/online DPO) outperform pure SFT when learning from preference pairs; expect compute and MLOps investment.
- Benefits depend on interaction diversity; systems should encourage lightweight, natural feedback and make personas transparent and user-editable.
- Strong privacy, safety, and fairness governance is a prerequisite for any large-scale deployment, especially in regulated sectors.
Glossary
- Ablation study: A methodological analysis that removes or varies components of a system to assess their impact on performance. "Our ablation studies further show that RLHI benefits from user guidance and interaction diversity, that reinforcement learning outperforms supervised finetuning, and that quality filtering is essential for effectively leveraging noisy human interaction data."
- AlpacaEval 2.0: An automated benchmark for evaluating instruction-following ability of LLMs. "User-Based Rewards attains a 77.9% length-controlled win rate on AlpacaEval 2.0, surpassing all baselines."
- Arena-Hard: A challenging benchmark suite for instruction-following with strong correlation to human preferences. "We evaluate models on AlpacaEval 2.0 and Arena-Hard, which are robust instruction following benchmarks that have a high correlation with human preferences."
- Athene-RM-8B: A specific large reward model used to score candidate responses. "with the Athene-RM-8B reward model \citep{frickathene} providing user-based rewards."
- Cosine distance: A similarity metric based on the angle between vectors in an embedding space; distance is 1 minus cosine similarity. "and compute average pairwise cosine distances."
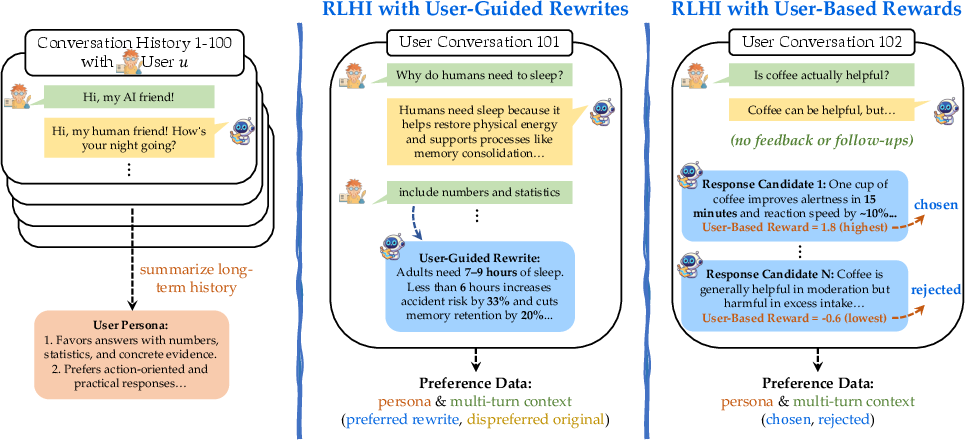
- Direct Preference Optimization (DPO): A preference-based training objective that optimizes a policy directly from chosen vs. rejected examples without explicit RL. "We perform preference optimization using persona-conditioned Direct Preference Optimization (DPO)"
- Embedding: A vector representation of text used for similarity and retrieval in high-dimensional space. "embed their contexts using OpenAI's text-embedding-3-small model"
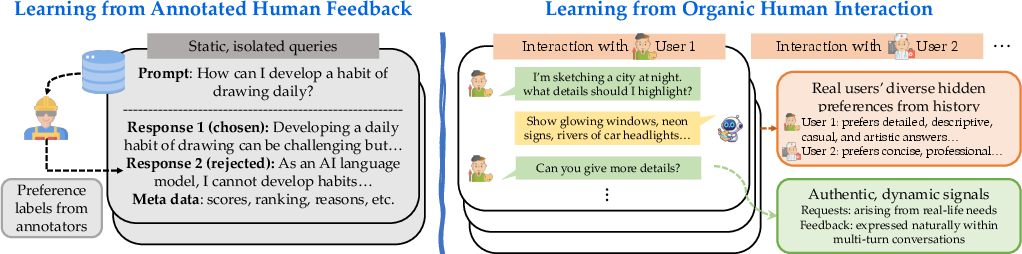
- In-the-wild (data/interactions): Naturally occurring, real-world user interactions rather than curated or lab-annotated data. "we introduce Reinforcement Learning from Human Interaction (RLHI), a paradigm that learns directly from in-the-wild user conversations."
- Jailbreak attempts: Adversarial prompts intended to make a model violate its safety or instruction constraints. "such as jailbreak attempts, which require careful handling, but also offer valuable information."
- KL penalty: A regularization term that constrains divergence from a reference policy during optimization. "KL penalty β = 0.01"
- Length-controlled win rate: An evaluation metric that adjusts for response length to reduce bias in preference judgments. "User-Based Rewards attains a 77.9% length-controlled win rate on AlpacaEval 2.0"
- Multi-turn context: The accumulated dialogue history across several conversational turns used to condition generation. "Both methods leverage personas and multi-turn context to enable personalized alignment."
- Offline DPO: Preference optimization using pre-collected preference pairs without generating new candidates during training. "This can be instantiated as either offline DPO, where preference pairs are pre-collected, or online DPO, where new candidates are generated dynamically and preferences are updated on the fly."
- Online DPO: Preference optimization that generates and evaluates new candidates during training for continual updates. "This can be instantiated as either offline DPO, where preference pairs are pre-collected, or online DPO, where new candidates are generated dynamically and preferences are updated on the fly."
- Persona (user persona): A natural-language summary of a user’s long-term preferences and behaviors derived from past interactions. "a reward model conditioned on knowledge of the user's long-term interaction history (termed persona)."
- Persona-conditioned preference optimization: Training that conditions preference objectives on an inferred user persona to align outputs with individual preferences. "Together, these methods link long-term user personas to turn-level preferences via persona-conditioned preference optimization."
- Persona-guided inference: Decoding that explicitly includes a user’s persona in the prompt to personalize responses at inference time. "Persona-guided inference enhances personalization, though sometimes at the cost of instruction-following."
- Preference pairs: Chosen vs. rejected response pairs used to learn relative preferences. "creating preference pairs between the original and rewritten responses"
- Quality filtering: The process of removing low-quality or harmful data/signals before training to improve learning outcomes. "our ablation studies further show ... that quality filtering is essential for effectively leveraging noisy human interaction data."
- Reference model (frozen reference model): A fixed baseline policy used for relative scoring or KL regularization during optimization. "a frozen reference model (a copy of the base model used as a baseline)"
- Reinforcement Learning from Human Feedback (RLHF): A framework that trains reward models from human preferences and optimizes policies against them. "Learning from human feedback (RLHF) trains a reward model on preference data and optimizes the base model with RL"
- Reinforcement Learning from Human Interaction (RLHI): Learning directly from natural user conversations, leveraging personas and feedback for alignment. "we introduce Reinforcement Learning from Human Interaction (RLHI), a paradigm that learns directly from in-the-wild user conversations."
- Reward model: A model that scores candidate responses according to quality and alignment criteria (possibly personalized). "learns via a reward model conditioned on knowledge of the user's long-term interaction history (termed persona)."
- T (sampling temperature): A decoding parameter controlling randomness; higher values increase variability in generated text. "sampling parameters T=0.6 and top-p=0.9"
- Top-p (nucleus sampling): A decoding method that samples tokens from the smallest set whose cumulative probability exceeds p. "sampling parameters T=0.6 and top-p=0.9"
- User-agnostic rewards: Reward signals that do not incorporate user-specific personas or histories. "RL with User-Agnostic Rewards, which performs online DPO training on the same prompts used in RLHI with User-Based Rewards, but uses generic rewards that do not consider user personas"
- User-Based Rewards: Personalized reward modeling that conditions scores on a user’s persona to select preferred responses. "RLHI with User-Based Rewards uses persona-conditioned online DPO training"
- User-Guided Rewrites: A method that revises unsatisfactory model outputs using the user’s follow-up feedback to produce improved responses. "RLHI with User-Guided Rewrites, which revises unsatisfactory model outputs based on users' natural-language follow-up responses"
- WildChat UserEval: An automated evaluation framework using held-out real user conversations to assess personalization and instruction-following. "We introduce WildChat UserEval, an LLM-based automated evaluation of personalization and instruction-following on real-world queries."
Collections
Sign up for free to add this paper to one or more collections.