$R^3$: 3D Reconstruction via Relative Regression
Abstract: Recent feed-forward geometry foundation models have demonstrated impressive generalization by recovering depth and poses in a single forward pass. However, these models are typically constrained by a global coordinate frame assumption. This dependency becomes a significant bottleneck for long-context and streaming reconstruction, as it forces the network to maintain an arbitrary temporal origin and handle translation magnitudes that grow unbounded over time. Our solution, which we call $R3$, employs relative regression. We employ a lightweight MLP to predict confidence-weighted relative constraints. These confidences serve as a unified anchor: weighting losses during training and guiding pose aggregation during inference. $R3$ supports both full-context offline reconstruction and causal, bounded-memory streaming. Our evaluation in both offline and streaming settings validates the effectiveness of our relative mechanism. Project page: https://kevinxu02.github.io/r3-site







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to build 3D maps from videos using a method called (short for “3D Reconstruction via Relative Regression”). Instead of trying to place every camera view on one big, fixed map from the start, focuses on how each pair of images is related—how the camera moved and turned between them—and then pieces the whole path together. This makes it especially good for long videos and live streams, where new frames keep coming in.
What questions were the researchers trying to answer?
They asked:
- Can we make 3D reconstruction work better for long, streaming videos by predicting how images relate to each other locally, instead of forcing everything into one global coordinate system right away?
- Can we teach the model to know how much to “trust” each prediction, so it can combine many small, local steps into a reliable big picture?
- Can the same model handle both live streaming (with limited memory) and offline processing of full clips without retraining?
How did they do it?
Think of making a 3D map like walking through a house with a camera. Traditional systems try to keep a single, global map from the very first step, which can get messy and inaccurate as the walk gets long. takes a different approach:
Predict relationships, not absolute positions
- Instead of placing each camera frame on a fixed world map, predicts the “relative pose” between pairs of frames—the rotation (how much the camera turned) and translation (how far it moved) from one frame to another.
- Analogy: Rather than saying “I’m at (X, Y) on a map,” it says “From where I was a moment ago, I turned a bit left and stepped forward two steps.” Do that reliably for many pairs and you can reconstruct the whole path.
Use “trust scores” for each prediction
- For every pair of frames, the model also predicts two confidence scores—one for rotation and one for translation. These are like “trust meters” that say how reliable that estimate is.
- Why two scores? Sometimes it’s easier to tell how much the camera turned than how far it moved (or vice versa), depending on textures, lighting, or motion. Separate trust scores let the system weigh them differently.
Assemble the big picture from small pieces
- Once predicts many pairwise relationships, it blends them together into a single global path. The blending uses the trust scores to give more weight to the most reliable pairs.
- Analogy: If several friends tell you directions and some sound more certain than others, you trust the confident ones more when drawing your route.
Stream videos with a small “memory”
- For live streaming, keeps a small “keyframe bank”: a set of important past frames that are useful for placing new frames. It picks new keyframes when they look different enough (so they add new info) and removes older, less useful ones when memory is full.
- This keeps memory usage bounded and steady, even for very long videos.
Train with confidence-aware loss
- During training, those same trust scores guide learning: the model is encouraged to give higher confidence to accurate pairs and lower confidence to tricky or unreliable ones. This helps it learn when to be bold and when to be cautious.
- The system also predicts depth for each frame (how far things are), which helps build dense 3D point clouds.
One model, two modes
- Streaming mode: handles frames as they arrive with limited memory.
- Full-context mode: if you already have the whole video, the same model can use all frames at once and do a quick final pass to refine the path.
What did they find?
Here’s what their tests showed across multiple datasets and benchmarks:
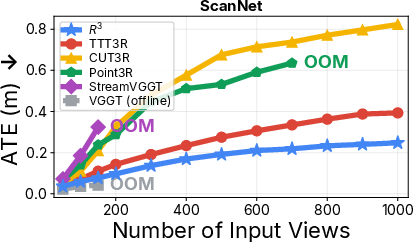
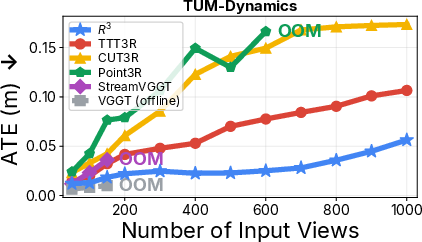
- Strong accuracy: matches or beats other advanced systems at estimating camera motion and building dense 3D maps, even though it’s smaller than many competitors.
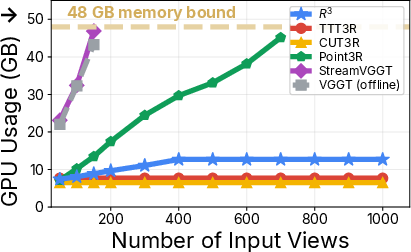
- Scales to long videos: It stays stable on long sequences (hundreds to thousands of frames) without running out of memory, thanks to the keyframe bank and confidence-weighted fusion.
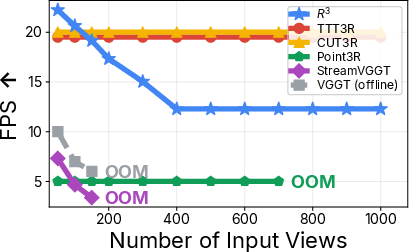
- Efficient and fast: It runs at over 20 frames per second with a relatively compact model (about 372 million parameters), which is much smaller than many 1-billion-parameter models.
- Robust to “distractors”: Using the confidence scores, it can detect frames that don’t belong (like sudden scene changes or heavy blur) and avoid adding them to the map, preventing errors from spreading.
- Flexible: The same trained model can switch between streaming and full-context modes, no retraining needed.
Why this matters: It shows that focusing on local relationships (with smart trust scoring) can build a more stable, scalable 3D understanding of the world from video, especially for long and changing scenes.
Why is this important?
- Better for real-world use: Robots, drones, AR/VR devices, and autonomous systems often deal with long, continuous video. is designed for that, using limited memory and staying stable over time.
- More reliable mapping: By weighting predictions based on confidence, the system avoids compounding errors and handles tricky frames gracefully.
- Simpler and lighter: It avoids complicated memory modules or expensive optimization loops, yet still delivers high-quality results.
- A general idea that could spread: The core idea—predict local relations with confidence and assemble globally—could be applied to other problems that involve building big structures from many small, uncertain pieces.
In short, shows a practical, scalable way to turn long videos into accurate 3D maps by focusing on trustworthy, local steps and smartly combining them into a global view.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed at guiding future research.
- Absolute scale ambiguity: Depth is supervised in median-normalized space and real data uses a DA3 teacher, leaving global metric scale estimation unresolved and its coupling with the focal-length head unclear.
- Limited intrinsics modeling: Only per-frame focal length is predicted; principal point and lens distortion are not modeled, which may degrade accuracy for wide-FOV or consumer cameras with distortion.
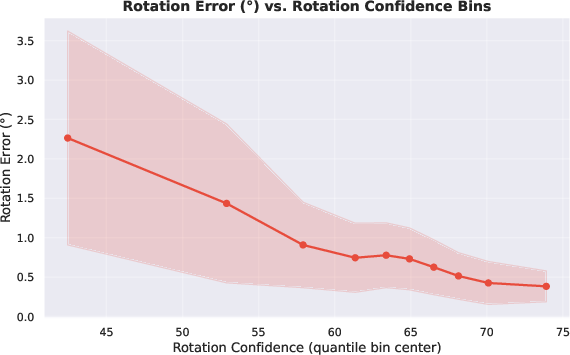
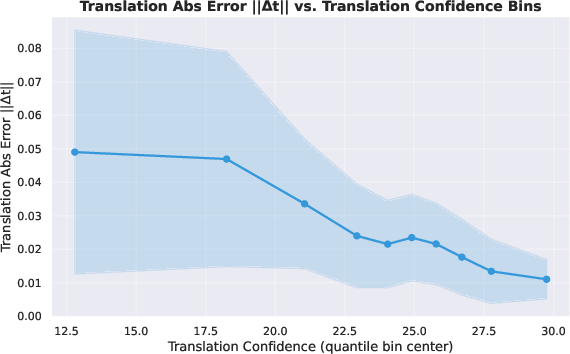
- Confidence calibration and probabilistic meaning: Rotation/translation confidences are used as weights but their calibration (e.g., correspondence to noise variances) is not evaluated; no reliability or sharpness metrics (ECE/Brier) are reported.
- SE(3) averaging choices: Pose aggregation uses weighted averaging of quaternions/translations rather than geodesic means or Lie-group optimization; the impact on bias and stability, especially under multi-modal hypotheses or large rotations, is not analyzed.
- Inverse and cycle consistency: The method predicts directed edges (i→j and j→i) but does not enforce inverse or cycle-consistency constraints during training; potential gains from such regularization remain unexplored.
- Loop closure and global optimization: Only a “lightweight” pose-graph refinement (no BA or reprojection errors) is applied; robustness to large loops and long-range drift, and benefits from integrating full bundle adjustment, are open questions.
- Pair selection and scalability: Full-context evaluation implies O(N²) pair queries; the top-K approximation lacks principled selection criteria or adaptive K, and no analysis quantifies accuracy–cost trade-offs for very long sequences.
- Keyframe bank design: Token-novelty thresholds, utility scoring u_j = d_j·c_j, and capacity M_max are heuristic; sensitivity, failure cases (e.g., repetitive textures, slow motion), and potential learned policies for admission/culling are not studied.
- Handling long-term resets: The system rejects frames with low confidence and resets after consecutive failures, but lacks relocalization to prior segments or cross-segment alignment strategies; how to reconnect maps across resets is unresolved.
- Dynamic and non-rigid scenes: Beyond simple distractor handling, the method assumes rigidity; there is no motion segmentation or dynamic object modeling, and robustness to strong dynamics is not systematically evaluated.
- Rolling shutter and rapid motion: The impact of rolling shutter, motion blur, and high-speed camera motion on relative regression and confidence gating is not characterized.
- Domain breadth and generalization: Evaluations exclude common benchmarks like KITTI Odometry/Visual-Inertial datasets and large-scale outdoor driving/UAV settings; generalization across sensors, FOVs, and environments is unknown.
- Real-time constraints at scale: The 20+ FPS claim is not deeply profiled across different sequence lengths, bank sizes, or hardware; latency breakdowns and scheduling under tight real-time budgets are not reported.
- Depth fusion pipeline: The paper does not detail the fusion method (e.g., pointmap filtering, TSDF, confidence-aware integration); how pose/depth uncertainties propagate into dense reconstruction quality remains unquantified.
- Teacher-induced bias: Using a frozen DA3 teacher for depth on real data can transfer teacher biases; whether the system learns to correct or amplifies those biases is not evaluated.
- Confidence–coverage trade-off: Using confidence both to weight losses and to aggregate poses may over-favor easy pairs and reduce coverage of challenging baselines; coverage metrics and strategies to avoid “mode collapse” are missing.
- Baseline-length robustness: Translation reliability often degrades with very short or very long baselines; the relationship between baseline, texture/overlap, and learned confidences is not analyzed.
- Focal-length head validation: There is no quantitative evaluation of intrinsics estimation accuracy or its impact on metric pose/dense reconstruction quality.
- Variable intrinsics in a stream: The approach does not address frame-to-frame intrinsics changes (e.g., zoom, focus, mobile cameras), nor joint intrinsics/pose estimation in streaming.
- Token-only pairwise head: Relative pose is predicted from a single camera token per frame, ignoring pixel-level co-visibility or geometry; the benefit of incorporating patch/grid tokens or learned correspondence cues remains untested.
- Uncertainty propagation downstream: Scalar confidences weight pair fusion but are not propagated to depth fusion, point geometry, or final map uncertainty; uncertainty-aware mapping is not explored.
- Robustness to repetitive/textureless regions: Failure modes in low-texture, repetitive patterns, or strong parallax remain under-characterized; targeted stress tests and failure diagnostics are absent.
- Solver details and robustness: The “lightweight” pose-graph optimization lacks specification (loss, robust kernels, manifold handling); its sensitivity to outliers and convergence behavior is not reported.
- Self-supervised or semi-supervised training: The method relies on supervised pairs/teacher depth; leveraging self-supervision (e.g., photometric/epipolar constraints) to reduce labeling/teacher dependence remains an open avenue.
- Multi-sensor fusion: Integration with IMU, wheel odometry, GNSS, or event cameras is not considered; the framework’s compatibility with cross-modal constraints is unexplored.
- Theoretical grounding: No formal analysis explains why relative regression should generalize better (e.g., distribution shift with sequence length, bias–variance trade-offs); conditions under which it outperforms absolute regression remain theoretical open questions.
Practical Applications
Immediate Applications
The R3 framework enables fast, bounded-memory, and robust streaming 3D reconstruction by predicting confidence-weighted relative poses and assembling global trajectories downstream. The following are deployable now with current hardware and software stacks (e.g., GPU-equipped edge devices, Jetson-class robots, or desktop workstations).
- Mobile robotics and drones: streaming SLAM front-end (Robotics)
- What: Use R3 as a monocular SLAM front-end to estimate trajectories and dense pointmaps on-device in real time (20+ FPS), supporting long missions via a bounded keyframe bank and confidence gating.
- Tools/workflows: ROS2 node or Jetson/Orin module; confidence-weighted pose-graph aggregator; outlier-gated tracking with segment resets; export to TSDF/GS/NeRF back-ends for dense mapping.
- Use cases: Warehouse AMRs, aerial inspection (bridges, towers), agriculture crop scouting, security patrolling where bandwidth is limited.
- Assumptions/dependencies: Moderate-GPU edge compute; scenes with sufficient texture; tolerance for scale ambiguity unless additional sensors provide metric scale (e.g., wheel odometry/IMU/LiDAR); handling of dynamic objects via confidence gating rather than explicit motion segmentation.
- AR/VR room-scale scanning and content anchoring (Software/Consumer)
- What: Live scene capture from handheld or head-mounted cameras to build consistent pointmaps for placing virtual content, pre-visualization, or quick room scans.
- Tools/workflows: R3-based SDK integrated into Unity/Unreal; stream-to-cloud or on-device mapping; confidence gate to ignore scene cuts and blurred frames during live capture.
- Use cases: Indoor navigation aids, MR content anchoring, event/venue quick mapping, indie VR content creation.
- Assumptions/dependencies: GPU-capable device (mobile deployment may need distillation/quantization); metric scale via ARKit/ARCore, IMU, or a known object size; limited robustness in low-light/low-texture scenes.
- AEC and facilities management: rapid site walkthrough capture (Construction/Real Estate)
- What: Convert long, unbounded walkthrough videos into consistent trajectories and point clouds for site logging, progress tracking, and as-built checks.
- Tools/workflows: Field app capturing monocular video; R3 streaming reconstruction on a ruggedized laptop or edge server; export to CAD/BIM alignment pipelines; periodic full-context refinement at the end of a segment.
- Use cases: Daily progress documentation, punch-listing, residential real-estate tours with auto-generated 3D previews.
- Assumptions/dependencies: Accepting non-metric scale unless fused with survey control, laser scans, or known baselines; occasional operator re-scans for poorly textured areas.
- Media/VFX and sports production: live previsualization and location scouting (Media/Entertainment)
- What: On-set or on-location 3D previews from continuous handheld footage with robust handling of scene cuts via confidence gating.
- Tools/workflows: R3 plugin for capture apps; quick pointmap overlays for framing and blocking; export camera paths to DCC tools.
- Assumptions/dependencies: GPU-assisted laptops; quality sufficient for previz and scouting; later high-precision assets captured by photogrammetry/lidar if needed.
- Remote inspection and telepresence (Energy/Utilities/Field Service)
- What: Field technicians stream long videos of assets (pipes, turbines) to reconstruct geometry in near real time for remote experts.
- Tools/workflows: Edge inference with bounded memory; web viewer of evolving pointmaps/trajectories; auto-suppression of unusable frames; optional end-of-session refinement.
- Assumptions/dependencies: Adequate lighting and texture; stable network optional (processing can be on-device); metric accuracy improved by integrating IMU or rangefinder.
- Academic research: long-context 3D benchmarks and method prototyping (Academia)
- What: Use R3’s relative-pose and confidence mechanism as a lightweight, controllable front-end to study long-sequence behavior, robust tracking, and confidence-weighted aggregation.
- Tools/workflows: Drop-in head on DA3/DINOv2 backbones; ablations on confidence-weighted losses; plug-and-play keyframe bank for reproducible streaming experiments.
- Assumptions/dependencies: Access to published weights/datasets; familiarity with evaluation on TUM/ScanNet/7-Scenes; non-metric scale unless aligned.
- Privacy-preserving on-device mapping (Policy/Compliance, Software)
- What: Run reconstruction locally to avoid transmitting raw video for AR, robotics, or facility scans, reducing privacy exposure while keeping compute bounded.
- Tools/workflows: On-device inference with limited memory footprint; ephemeral keyframe banks; export only derived geometry.
- Assumptions/dependencies: Sufficient edge compute; organizational policies accepting derived geometry storage; compliance with local privacy regulations.
- E-commerce and furniture/home improvement: quick 3D capture from turntable/handheld videos (Retail)
- What: Generate approximate geometry of products or rooms from videos without controlled rigs.
- Tools/workflows: Merchant or consumer app that streams R3 output; optional scale via known target/object; simple cleanup tools.
- Assumptions/dependencies: Tolerating approximate scale and surface detail; background/distractor handling via outlier gating; reflective/transparent objects remain challenging.
Long-Term Applications
These opportunities require further research, domain adaptation, integration with other sensors, or infrastructure at larger scales.
- City-scale AR Cloud and multi-session map fusion (Software/Mapping)
- What: Build persistent, large-scale maps by fusing many long, crowd-sourced video streams using R3’s relative edges and confidences as priors.
- Tools/workflows: Back-end global pose-graph with cross-session loop closures; scalable keyframe indexing; privacy-preserving on-device preprocessing.
- Dependencies: Robust loop closure across sessions; drift management at urban scale; policies for data retention and PII redaction.
- Multi-sensor fusion for metric, robust autonomy (Autonomous Vehicles/Robotics)
- What: Fuse R3 with IMU, wheel odometry, GNSS, or LiDAR to obtain metric-scale, dynamic-scene-robust trajectories and maps.
- Tools/workflows: Factor-graph combining confidence-weighted visual edges and inertial/range constraints; online calibration of intrinsics/extrinsics.
- Dependencies: Tight synchronization; motion segmentation in highly dynamic scenes; compute budgets on automotive-grade hardware; safety certification pathways.
- Live neural scene representations (NeRF/3DGS) driven by streaming trajectories (Software/Graphics)
- What: Feed confidence-weighted trajectories into online NeRF/3D Gaussian Splatting for real-time radiance field updates during capture.
- Tools/workflows: Streaming pose exporter; incremental training with buffer management keyed by R3’s keyframe bank; on-the-fly mesh extraction.
- Dependencies: Stable, low-latency training loops; memory and thermal limits on portable rigs; managing catastrophic frames without destabilizing training.
- Collaborative multi-agent mapping (Swarm Robotics)
- What: Multiple robots/devices share relative-pose constraints and confidences to jointly build consistent global maps across large areas.
- Tools/workflows: Inter-robot pose graph with confidence-weighted edge sharing; bandwidth-aware edge selection; decentralized optimization.
- Dependencies: Reliable inter-agent communication; cross-device time sync and extrinsic calibration; robustness to heterogeneous sensors and viewpoints.
- Surgical/endoscopic and industrial borescope 3D reconstruction (Healthcare/Manufacturing)
- What: Apply relative regression in challenging, texture-poor, deforming scenes like endoscopy or borescope inspections to stabilize trajectories over long videos.
- Tools/workflows: Domain-adapted training on medical/industrial data; integration with shape/soft-body priors; confidence-driven frame rejection for specularities and fluids.
- Dependencies: Clinical/industrial data access and labeling; handling non-rigid motion; regulatory approval and validation for clinical use; sterilizable compute hardware.
- Edge/mobile deployment at scale (Consumer/IoT)
- What: Run R3-class models on smartphones or low-power IoT devices for ubiquitous AR and navigation.
- Tools/workflows: Model compression (distillation, pruning, quantization), sparse attention, and hardware acceleration (NPUs).
- Dependencies: Aggressive optimization to fit memory/latency constraints; battery/thermal management; maintaining accuracy post-compression.
- Asset-level digital twins with accuracy guarantees (Energy/Infrastructure)
- What: Use long, repeated captures to maintain high-fidelity, temporally consistent twins with uncertainty quantification derived from confidences.
- Tools/workflows: Confidence-propagating pipelines that flag low-certainty regions; periodic metric alignment to surveyed ground truth.
- Dependencies: Integration with metrology (total stations, LiDAR); QA/QC workflows; change detection and alerting built on per-edge/pixel confidences.
- Regulatory/standards frameworks for low-carbon, privacy-first mapping (Policy)
- What: Leverage bounded-memory, on-device inference to set guidelines for energy-efficient, privacy-preserving 3D mapping.
- Tools/workflows: Reporting templates for compute/energy budgets; best-practice playbooks for on-device processing and ephemeral storage; certification programs.
- Dependencies: Cross-industry coordination; measurement standards; alignment with data protection laws (e.g., GDPR, CCPA).
- Automated dataset curation and active learning for 3D (Academia/Software)
- What: Use learned confidences to auto-curate “hard” pairs/frames and guide targeted data collection or annotation.
- Tools/workflows: Mining low-confidence segments for human review; curriculum learning schedules weighted by confidence.
- Dependencies: Scalable data tooling; careful handling to avoid reinforcing bias (e.g., discarding minority scene types).
- Finance and insurance risk assessment via rapid scene capture (Finance/InsurTech)
- What: Fast 3D reconstructions of sites (e.g., claims, appraisals) with uncertainty estimates guiding human escalation.
- Tools/workflows: Field capture apps; confidence-aware triage dashboards; integration with underwriting/claims systems.
- Dependencies: Acceptance of non-metric outputs unless augmented; regulatory compliance for evidence standards; operator training.
Cross-cutting assumptions and dependencies
- Metric scale: Depths are median-normalized and focal length is estimated; true metric scale typically requires auxiliary cues (IMU, known baselines, object sizes, or external alignment).
- Hardware: Reported 20+ FPS is on GPU-class hardware; mobile-class deployment needs model optimization.
- Scene conditions: Performance degrades in textureless, low-light, reflective/transparent, or highly dynamic environments; confidence gating mitigates but does not eliminate failure modes.
- Camera intrinsics: Variable zoom or poorly known intrinsics may reduce accuracy; focal-length head helps but benefits from calibration.
- Data and generalization: Domain shifts (e.g., medical, underwater) require finetuning with representative data.
- Privacy/compliance: Field use must incorporate PII redaction and govern storage of derived geometry per jurisdiction.
Glossary
- Active context: The subset of previously accepted frames used as the current reference set during streaming. "The active context contains frame $1$, which fixes the trajectory origin, and a dynamic keyframe bank of previously accepted frames: ."
- Absolute pose loss: A training objective that supervises camera poses in a fixed global frame. "replaces the fixed absolute pose loss with relative pose supervision"
- Absolute Trajectory Error (ATE): A metric measuring global trajectory accuracy by comparing estimated and ground-truth camera trajectories. "ATE / RPE-T / RPE-R, all lower is better"
- Baseline: The geometric separation between two camera views that governs the scale of relative pose and depth constraints. "its scale depends on the baseline between two frames rather than on the total trajectory length"
- Bounded-memory streaming: Online processing where memory usage is capped regardless of sequence length. "supports both full-context offline reconstruction and causal, bounded-memory streaming."
- Bundle adjustment: A nonlinear optimization refining camera poses and 3D structure jointly. "It does not run bundle adjustment, point reprojection, or depth optimization."
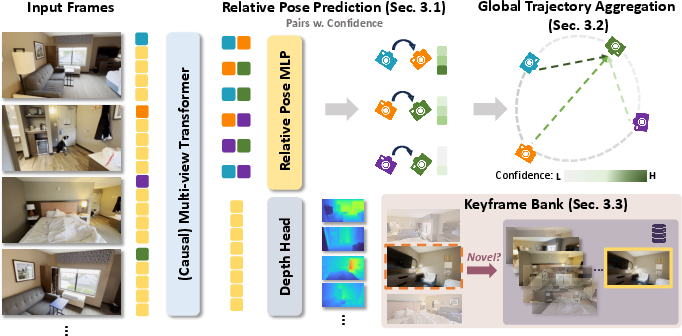
- Camera token: A learned per-frame feature vector summarizing the frame for geometric prediction. "A causal geometry backbone extracts a single camera token from each frame."
- Camera-to-world poses: Rigid transforms mapping camera coordinates into a shared world frame. "camera-to-world poses "
- Causal attention mask: An attention constraint that prevents a frame from accessing future frames. "removing the causal attention mask at test time"
- Confidence-weighted fusion: Combining multiple pose proposals using learned confidences as weights. "Confidence-weighted Fusion."
- Confidence-weighted residual losses: Losses where residuals are weighted by learned confidence scalars. "confidence-weighted residual losses."
- Covisibility: The extent to which two frames observe overlapping scene content. "hand-designed motion and covisibility rules"
- Culling: Evicting low-utility keyframes when the bank reaches capacity. "Culling."
- Depth-ray target: A representation that predicts geometry along image rays for consistent depth inference. "predicts spatially consistent geometry through a unified depth-ray target."
- DINOv2: A large-scale self-supervised vision backbone used for feature extraction. "built on DINOv2~\cite{oquab2024dinov2}, it predicts spatially consistent geometry through a unified depth-ray target."
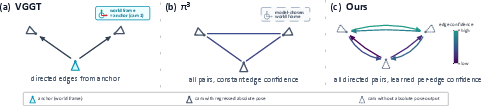
- Directed pose graph: A graph where nodes are frames and directed edges carry relative pose estimates and confidences. "yielding a fully-connected directed pose graph."
- Feed-forward geometry foundation models: Large models that predict geometry (depth/pose/pointmaps) in a single forward pass. "Feed-forward geometry foundation models have made camera and geometry prediction much more robust."
- Focal length: A camera intrinsic parameter controlling projection scale. "A separate per-frame head predicts the focal length from each token ."
- Full-context inference: Inference using all frames simultaneously (no causal masking). "providing a full-context inference mode without retraining or a second model."
- Global coordinate frame: A single shared coordinate system used to express all camera poses. "directly regress every in one global coordinate frame"
- Keyframe bank: A maintained set of representative frames used as references for pose estimation. "a dynamic keyframe bank of previously accepted frames: ."
- Keyframe sparsification: Reducing the number of stored frames to a compact, informative subset. "The bank mirrors classical keyframe sparsification~\cite{klein2007ptam,murartal2015orbslam,murartal2017orbslam2,engel2017dso,campos2021orbslam3}"
- KV-cache: The transformer key–value memory used to store past tokens for causal attention. "we invalidate its KV-cache entries"
- L1 residuals: Absolute-value error terms used in optimization losses. "confidence-weighted residuals:"
- Median-normalized space: A depth scaling scheme that divides by per-frame median to remove scale ambiguity. "The depth head is supervised in median-normalized space"
- MLP: A lightweight multi-layer perceptron used here as a relative-pose prediction head. "a lightweight MLP to predict confidence-weighted relative constraints."
- Multi-View Stereo (MVS): A class of methods that reconstruct dense 3D from multiple calibrated images. "Classical pipelines split reconstruction into SfM~\cite{schonberger2016structure,pan2024glomap}, MVS~\cite{furukawa2010accurate,schonberger2016pixelwise,yao2018mvsnet}, and SLAM~\cite{klein2007ptam,murartal2017orbslam2,engel2017dso,campos2021orbslam3}"
- Novelty threshold: A similarity cutoff deciding whether a new frame is sufficiently different to be added as a keyframe. "novelty threshold."
- Out-of-scene detector: A mechanism identifying distractor frames that do not belong to the current scene. "doubles as an out-of-scene detector"
- Outlier gate: A confidence-based rule to reject unreliable frames or pair predictions. "function as an effective outlier gate."
- Pairwise constraints: Relative geometric relations between frame pairs used to assemble a global trajectory. "yields many pairwise constraints instead of only absolute poses."
- Permutation-equivariant: A property where outputs are invariant/equivariant to permutations of input order. "global, permutation-equivariant, dynamic, and prior- or metric-aware reconstruction"
- Pointmaps: Per-pixel 3D point predictions expressed in a (possibly shared) coordinate frame. "made pointmaps a general target"
- Pose-graph optimization: Solving for poses by minimizing residuals over a graph of relative constraints. "pose-graph optimization"
- Pose-graph refinement: A post-processing step that refines poses using the confidence-weighted relative edges. "confidence-weighted pose-graph refinement"
- Quaternion (unit quaternion): A 4D rotation representation constrained to unit norm. "relative rotation (unit quaternion)"
- Relative pose supervision: Training using relative rotations/translations between frames rather than absolute poses. "relative pose supervision"
- Relative Pose Error (RPE): A metric evaluating local motion accuracy; RPE-T for translation, RPE-R for rotation. "ATE / RPE-T / RPE-R, all lower is better; RPE-R is in degrees."
- RMSE (ATE-RMSE / Rot RMSE): Root-mean-square error metrics for trajectory and rotation accuracy. "ATE-RMSE / Rot RMSE, all lower is better; Rot RMSE is in degrees."
- SE(3): The Lie group of 3D rigid transformations (rotation and translation). ""
- SfM: Structure from Motion; reconstructing 3D and camera motion from images. "Classical pipelines split reconstruction into SfM~\cite{schonberger2016structure,pan2024glomap}, MVS~..., and SLAM~..."
- SLAM: Simultaneous Localization and Mapping; jointly estimating camera trajectory and a map. "Classical pipelines split reconstruction into SfM, MVS, and SLAM~\cite{klein2007ptam,murartal2017orbslam2,engel2017dso,campos2021orbslam3}"
- Softmax normalizations: Converting confidence scores into normalized weights via the softmax function. "softmax normalizations of $c^{\mathrm{R}_{i\rightarrow j}, c^{\mathrm{T}_{i\rightarrow j}$"
- Streaming inference: Online processing of frames as they arrive, without seeing the full sequence. "enabling streaming inference with a bounded active keyframe bank."
- Test-time training (TTT): Adapting the model during inference to use the current scene as memory. "use test-time training as scene memory"
- Trajectory origin: The initial reference pose that defines the world-frame origin and orientation. "Frame $1$ defines the origin and orientation of the shared coordinate system"
- Visual Odometry (VO): Estimating camera motion from image sequences without necessarily building a global map. "SfM/VO/SLAM components"
Collections
Sign up for free to add this paper to one or more collections.