- The paper introduces SSR, a training-free regularization method that stabilizes state evolution in streaming 3D reconstruction by constraining hidden states on Grassmannian manifolds.
- SSR employs an analytic correction using a sliding window affinity matrix to enforce local self-expressiveness, resulting in improved pose and depth estimates.
- Experimental results demonstrate lower trajectory errors and enhanced geometric consistency compared to state-of-the-art baselines, particularly on long and looping sequences.
Self-Expressive Sequence Regularization for Training-Free Streaming 3D Reconstruction
Introduction
Streaming 3D reconstruction aims to estimate camera trajectories and scene geometry online from continuous visual data, but stateful recurrent models systematically accumulate geometric drift over long observation horizons. SSR introduces a training-free, plug-and-play regularization framework—Self-expressive Sequence Regularization (SSR)—that analytically constrains hidden state sequences using the geometric structure of Grassmannian manifolds. This method leverages the self-expressive property of latent recurrent state representations to minimize temporal drift and maintain coherent manifold structure, achieving substantial improvements in pose and geometry estimation across diverse streaming scenarios.
Grassmannian Manifold Perspective
SSR departs from conventional unconstrained recurrent neural networks by interpreting the latent state as an evolving point on the Grassmannian G(n,r), where n denotes the ambient feature dimension and r is the subspace rank. Here, each persistent state encodes the current scene via a low-dimensional subspace that smoothly traverses the Grassmannian manifold. Temporal coherence is naturally enforced by constraining the trajectory of the hidden state to remain near this manifold.
The self-expressive property is foundational: any state in a locally smooth sequence can be approximated as a linear combination of temporally adjacent states. This insight, derived from NRSfM literature, allows construction of an affinity matrix to regularize current updates, effectively anchoring new states to their historical context.
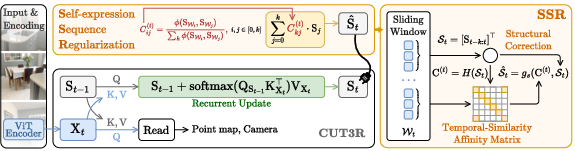
Figure 1: The SSR mechanism refines frame-wise states using a sliding window and a training-free affinity computation, ensuring manifold-consistent regularization of pre-trained foundation models during streaming inference.
Self-Expressive Sequence Regularization Mechanism
SSR applies a windowed affinity-based regularization process entirely at inference time, without gradient updates or auxiliary parameters. Given a sliding window of k recent latent states, an affinity matrix C is computed using normalized dot-product similarities. The current hidden state is expressed as a weighted sum of its neighbors, enforcing local self-consistency and pulling the state trajectory back to the manifold when it begins to drift.
Critically, SSR’s analytic correction operates directly on off-the-shelf foundation models, requiring no retraining or architectural modifications. The correction stabilizes geometric and pose estimates produced by downstream regression heads, as shown in sequential 3D perception tasks.
Empirical Results and Analysis
Quantitative Improvements
SSR achieves superior or on-par performance with respect to strong baselines (such as CUT3R, TTT3R, and other recent foundation models) across video depth estimation, pose estimation, and sequence-based 3D reconstruction. On long-horizon sequence benchmarks (KITTI, Sintel, Bonn, TUM-dynamics, ScanNet), SSR effectively suppresses cumulative drift, yielding lower absolute trajectory errors and higher depth accuracy. Notably, SSR demonstrates the ability to outperform other training-free test-time regularization baselines (e.g., TTT3R) particularly on extended, dynamic, or looped trajectories.
SSR is especially robust for streaming, online reconstruction tasks, where context forgetting and temporal inconsistency are critical bottlenecks for existing methods. The analytic regularization leads to stable, drift-free hidden state evolution, as evidenced by qualitative and quantitative metrics.

Figure 2: SSR demonstrates effective loop-closure and drift suppression on long and looping sequences compared to baseline models, providing more accurate and visually consistent reconstructions.
Contextual Affinity and Temporal Coherence
The affinity matrix produced by SSR captures nontrivial long-range dependencies, indicated by block structures and off-diagonal activations in the temporal similarity heatmaps. Rather than only using adjacent frames, SSR recalls relevant historical states, imposing robust constraints that are not susceptible to catastrophic drift.
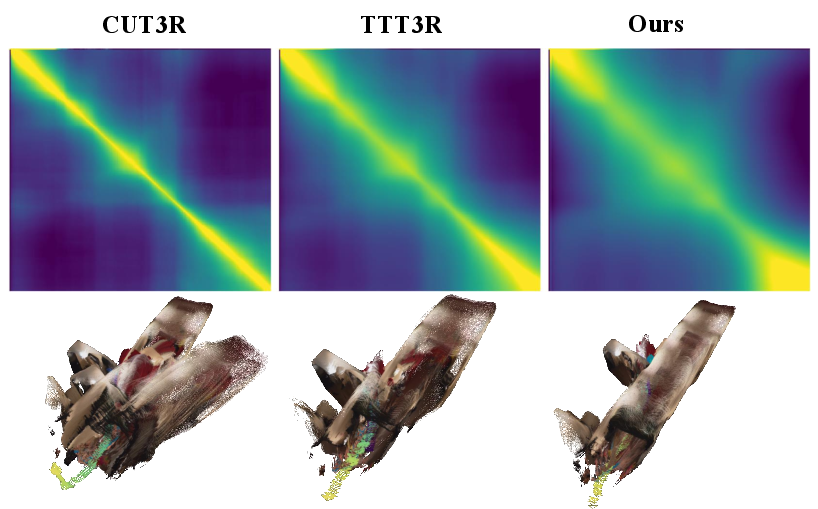
Figure 3: Off-diagonal patterns in the affinity matrix indicate that SSR consistently leverages long-term contextual relationships, enhancing the regularization of current estimates.
Robustness, Limitations, and Ablation
SSR maintains high efficiency and strong regularization when the streaming data exhibits adequate temporal continuity. However, SSR’s performance degrades with extremely sparse or short input sequences, as the affinity-based regularization depends on a non-degenerate historical window. In these settings, the method may inadvertently merge unrelated states due to residual temporal similarity, unlike the identity mapping ideal. Ablation demonstrates diminishing returns for window size k beyond moderate lengths, indicating fixed and controllable computational overhead.
In sequence-based evaluations (with denser and more continuous inputs), SSR regains its superiority, confirming that degradation in highly sparse scenarios is tied to input structure, not intrinsic model bias.
Practical and Theoretical Implications
SSR establishes a principled, geometry-driven framework for sequence regularization in foundation model-based perception. Its training-free, inference-time design is highly amenable to deployment with large-scale streaming models and persistent state architectures, expanding their applicability to robotics, AR/VR, and real-time scene understanding. The method forges a tight connection between geometric manifold theory (Grassmannians, self-expressiveness) and high-dimensional neural latent representations, enabling new opportunities in test-time adaptation, online generalization, and continual 3D learning.
The analytic regularization strategy may inspire further research in plug-and-play test-time adaptation, geometry-aware sequence models, and the development of more sophisticated, context-sensitive affinity computations, potentially making these models robust across a broader set of input distributions and sparsity regimes.
Conclusion
SSR presents an inference-time, training-free regularization scheme that stabilizes state evolution in streaming 3D reconstruction by enforcing local self-expressiveness on the Grassmannian manifold. By substantially reducing temporal drift and supporting contextual recall, SSR directly benefits pose and geometry predictions of strong foundation models. Future work can explore expansion to sparser settings and more adaptive affinity matrix designs to further enhance long-horizon streaming consistency and robustness.