- The paper introduces a weakly-supervised paradigm that bypasses traditional multi-view geometric annotations by leveraging pseudo monocular relative depths and sparse image correspondences.
- It employs an ambiguity-aware scale-invariant depth loss and a trigonometry-based reprojection loss to robustly align depth predictions and camera poses.
- Quantitative results show that Reliev3R rivals fully-supervised methods on benchmark datasets and generalizes well across diverse, unlabelled data.
Reliev3R: Weakly-Supervised Feed-Forward 3D Reconstruction Without Multi-View Geometric Annotations
Motivation and Problem Statement
Feed-forward reconstruction models (FFRMs) have achieved high-quality 3D reconstruction and rapid forward inference, scaling across multiple applications including text-3D grounding and embodied AI. However, their scalability is hampered by a reliance on multi-view geometric annotations—specifically, dense 3D point maps and camera poses—generated via elaborate structure-from-motion (SfM) and multi-view stereo (MVS) pipelines. These annotations demand extensive computational resources and curated datasets, limiting FFRM training data.
Reliev3R addresses this bottleneck by introducing a weakly-supervised paradigm for FFRM training from scratch, entirely circumventing cost-prohibitive multi-view geometric annotations. Instead, Reliev3R leverages pseudo monocular relative depths and sparse image correspondences produced by pretrained expert models, regularized through multi-view geometric constraints as weak supervision. This approach eliminates the dependency on SfM/MVS, enabling scalable training on more diverse and unlabelled data.
Figure 1: Reliev3R surpasses early FFRMs and weakly-supervised pose models by training entirely from scratch without multi-view geometric annotations.
Methodological Framework
Reliev3R modifies the standard feed-forward pipeline by implementing two principal forms of weak supervision:
- Ambiguity-Aware Scale-Invariant Depth Loss: Monocular depth pseudo-labels from pretrained models are employed to constrain depth shape distributions. The ambiguity-aware depth loss dynamically masks unreliable regions (e.g., sky, specular surfaces) by learning confidence maps, thereby mitigating multi-view inconsistency in monocular depth estimation.
- Trigonometry-Based Reprojection Loss: Sparse 2D correspondences across views serve as anchors for geometric registration. Reliev3R predicts depth maps, which are back-projected and registered into world coordinates via camera pose estimation, optimized using a differentiable reprojection loss computed via angular difference in 3D space. This loss produces robust gradients even for extreme pose configurations, in contrast with naïve Euclidean distance or pixel reprojection objectives.
Pseudo labels for monocular relative depth and correspondences are produced with pretrained models (Depth Pro and CoTracker), neither of which is trained on the target dataset, simulating real-world scenarios of large-scale unlabeled data.
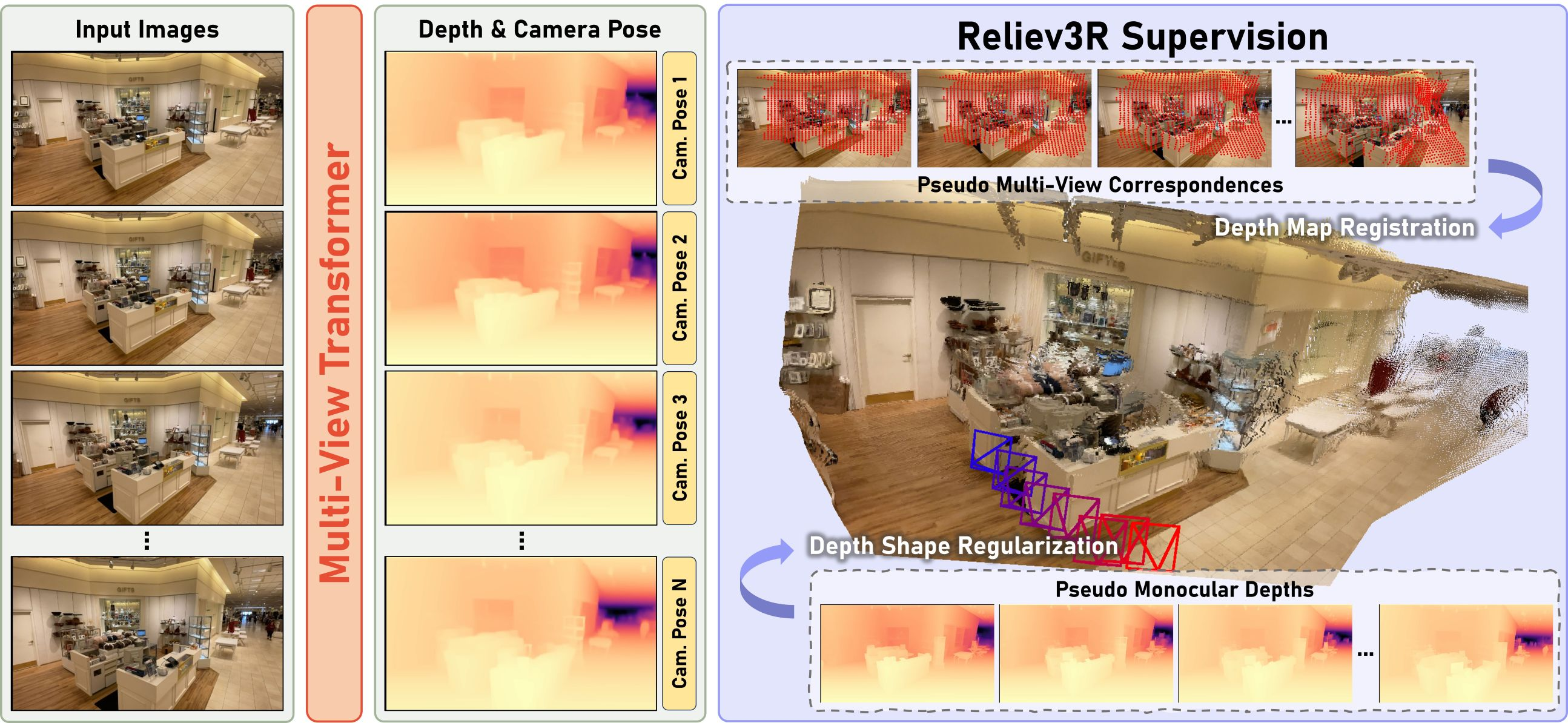
Figure 2: Reliev3R reconstructs geometry without multi-view geometric annotation by regularizing view-wise depth via pseudo labels and geometric correspondence.
Quantitative and Qualitative Evaluation
Extensive benchmarking on DL3DV-benchmark demonstrates that Reliev3R achieves point map reconstruction, camera pose estimation, and depth prediction efficacy comparable to fully-supervised state-of-the-art FFRMs, including π3 (when trained on the same data), and surpasses prior early FFRMs such as MVDUSt3R and FLARE. Reliev3R also outperforms weakly-supervised pose models like AnyCam in both reconstruction and pose estimation metrics. Notably, the absolute relative error, inlier ratio, and average trajectory error highlight Reliev3R's competitive performance despite drastically reduced reliance on geometric labels.

Figure 3: Point map and camera pose visualization on DL3DV-benchmark shows Reliev3R matching the accuracy of fully-supervised FFRMs.
Zero-shot evaluation on ScanNet++ further reveals that Reliev3R generalizes robustly across dataset domain shifts in focal length and resolution. While both Reliev3R and fully-supervised π3† drop in accuracy due to focal length mismatch, Reliev3R holds significant advantage in depth estimation and remains comparable in overall reconstruction, outperforming AnyCam.

Figure 4: Visualizations on ScanNet++ highlight Reliev3R's robust zero-shot performance relative to fully-supervised and weakly-supervised baselines.
Weak Losses and Registration Dynamics
The ambiguity-aware scale-invariant depth loss regularizes the spatial shape of multi-view depth predictions by assigning confidence weights per pixel, dynamically masking those regions with high uncertainty or cross-view inconsistency. The trigonometric reprojection loss aligns the predicted depth and pose by minimizing the angular difference between corresponding 3D points across views, circumventing typical coordinate scaling issues and producing meaningful pose gradients even under random initialization.
Implications and Limitations
Reliev3R demonstrates that competent FFRM training can be achieved solely through weak supervision, dramatically reducing the annotation barrier and opening pathways for foundation-model-scale training on unlabeled video. The paradigm is directly extensible to robust robot vision, scene understanding, and large-scale embodied AI systems where data annotation is infeasible.
Current formulation does not explicitly address dynamic scenes with moving objects, nor does it provide empirical scaling analysis for much larger datasets. Additionally, robustness is limited by the quality of pseudo-labeling models and their inherent domain biases.

Figure 5: Visualization of Reliev3R showing depth maps, confidence maps, and pseudo labels highlighting superior multi-view consistency.

Figure 6: Inputs and outputs for Reliev3R further illustrate effective masking and depth alignment.
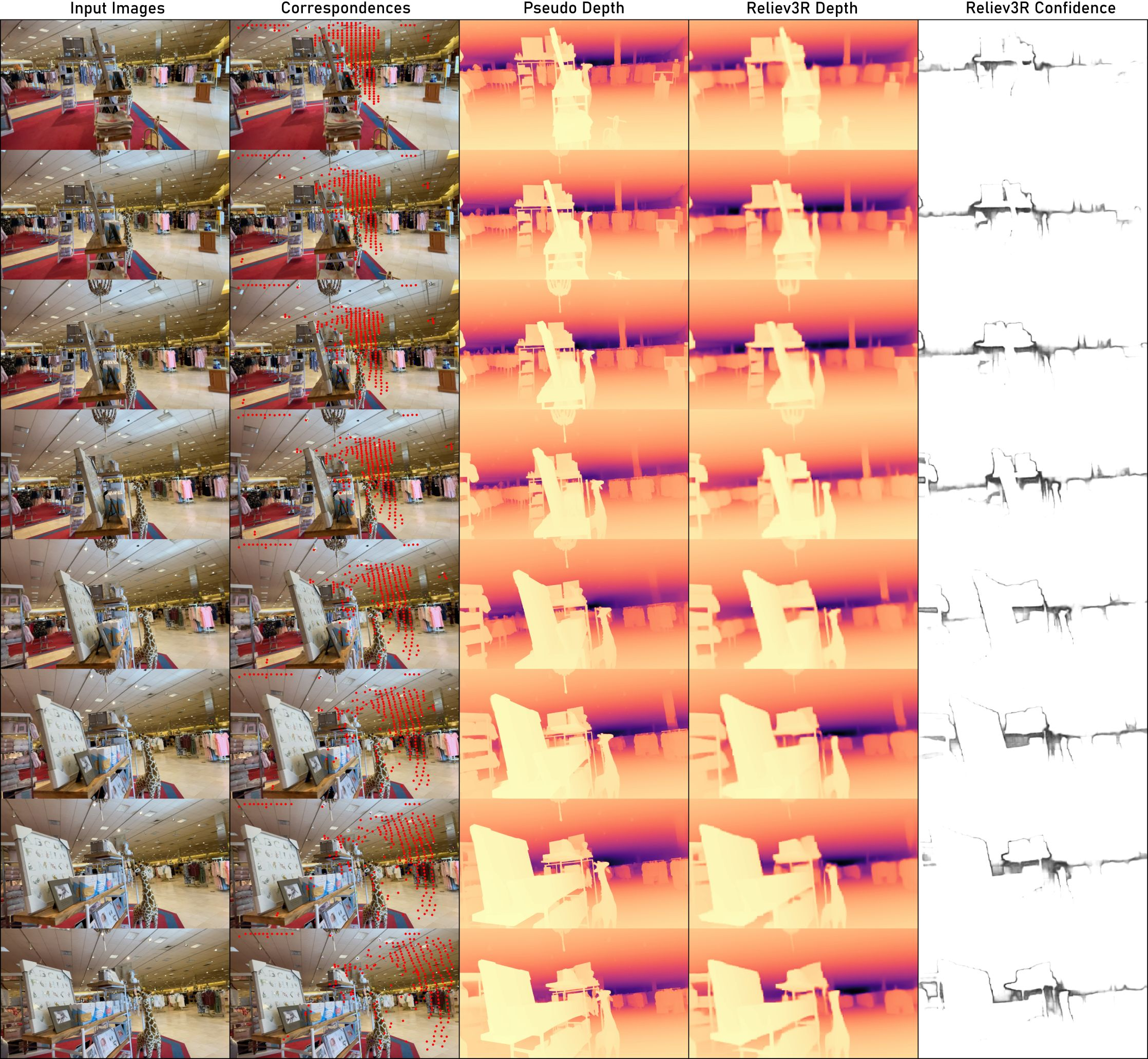
Figure 7: Reliev3R confidence maps successfully mask unreliable regions, aiding registration.
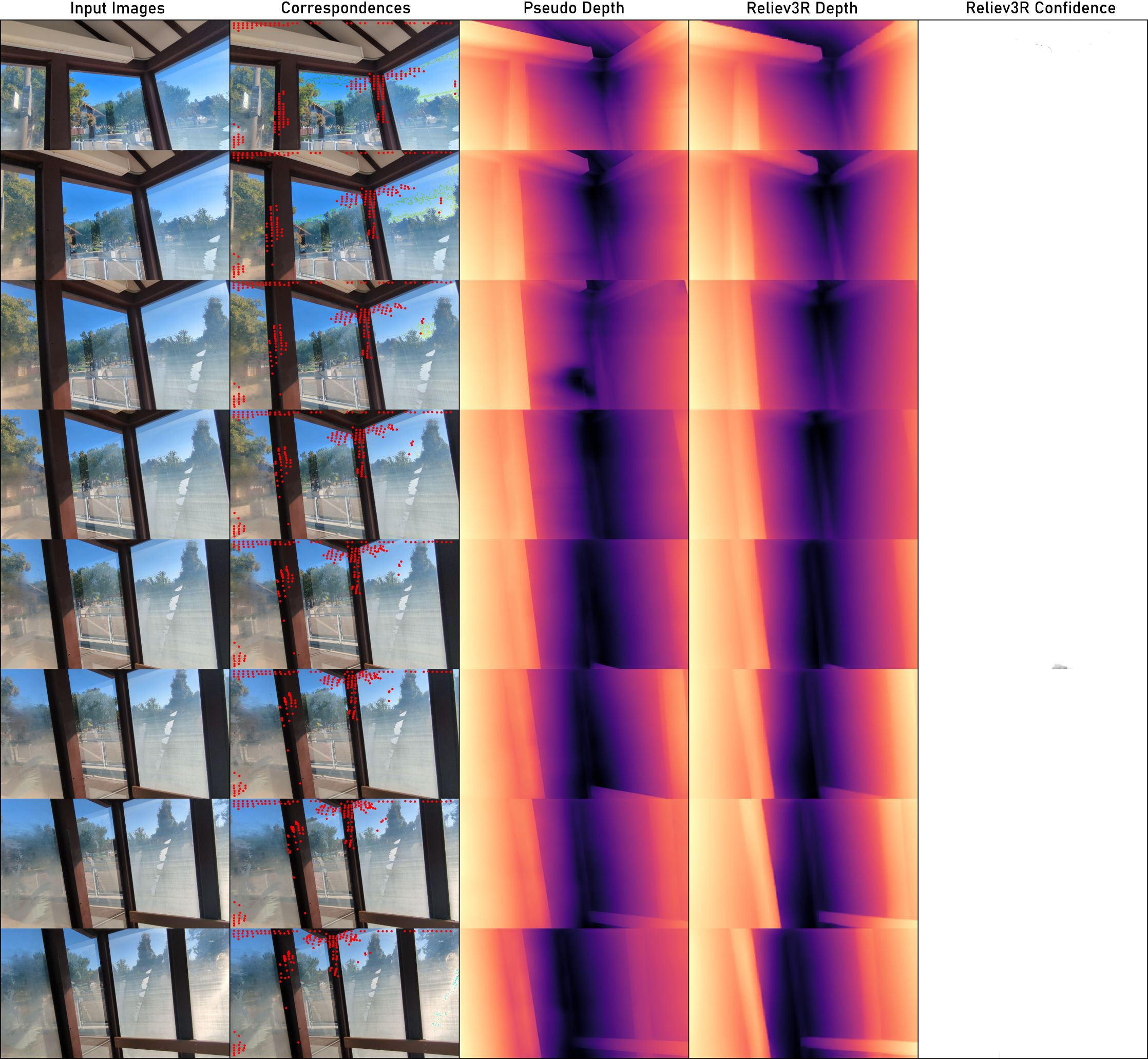
Figure 8: Consistent results across input views indicate strong generalizability and multi-view geometric registration.
Conclusion
Reliev3R inaugurates a scalable, weakly-supervised paradigm for feed-forward 3D reconstruction, eliminating the need for expensive multi-view geometric annotations. Its ambiguity-aware losses and trigonometric registration constraints enable competitive reconstruction and pose estimation, comparable to fully-supervised SOTA models on identical datasets. Reliev3R's framework is primed for broad adoption in scenarios demanding large-scale, annotation-free 3D learning. Future work should characterize behavior under massive data scaling, adapt to dynamic environments, and further refine pseudo-labeling strategies to fully realize foundation-scale FFRMs (2604.00548).