- The paper presents a dual-memory architecture that decouples rapid pose tracking via an implicit fast-weight module from persistent geometric mapping, enhancing long-sequence performance.
- Methodologically, Mem3R integrates a lightweight implicit memory and a token-based explicit memory with channel-wise gating, reducing model size by 19% and curbing temporal drift.
- Empirical evaluations demonstrate up to 39% lower absolute trajectory error and improved depth and reconstruction metrics across prominent datasets like TUM Dynamics and ScanNet.
Streaming 3D Reconstruction with Hybrid Memory: An Expert Summary of Mem3R
Motivation and Problems in Long-Horizon Streaming 3D Perception
The central challenge addressed by this paper is accurate and efficient 3D reconstruction and camera pose tracking from long visual streams, a requirement fundamental to robotics, AR, and scalable embodied applications. Prior Transformer-based feed-forward approaches deliver high accuracy but suffer quadratic computational and memory scaling with increased sequence length, rendering them impractical for real-time streaming. The most promising efficient alternatives, notably CUT3R, leverage fixed-size recurrent latent states. While these enable constant memory inference, they suffer substantial temporal forgetting and trajectory drift when stream lengths surpass training horizon—a core performance bottleneck in long-sequence settings.
Mem3R Architecture: Dual-Memory Design
Mem3R introduces a principled RNN-based architecture built on the CUT3R paradigm but fundamentally improves representational efficiency via hybrid memory. The distinguishing feature is the decoupling of camera tracking from geometric mapping:
- Implicit Memory (Fast-Weight MLP): Pose estimation leverages a lightweight MLP-based fast-weight module updated at inference via Test-Time Training (TTT). This module efficiently encodes short-term pose cues and is adapted online for frame-specific accuracy.
- Explicit Memory (Token-Based State): Global geometric context is maintained in fixed-size state tokens, which are persistently updated using a novel channel-wise gating mechanism.
- Learnable Channel-Wise State Gate: This module provides fine-grain control over explicit memory updates, mitigating temporal forgetting by preserving stable geometric features and selectively integrating new observations.
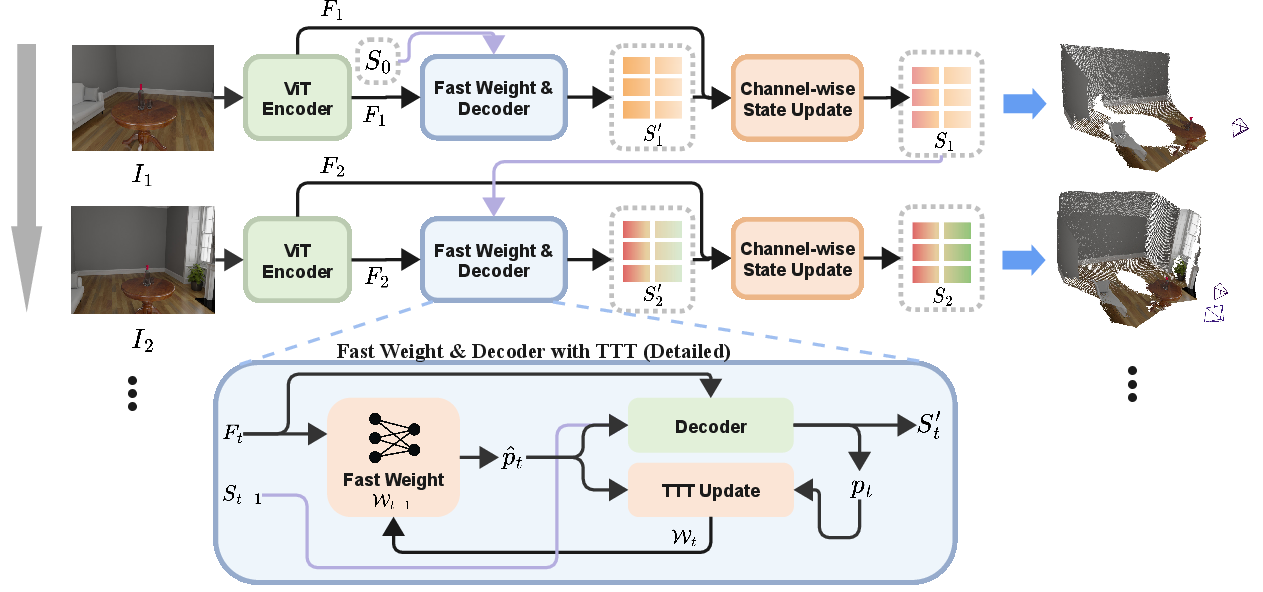
Figure 1: Mem3R processes streaming image sequences with a ViT encoder, fast-weight module for pose tracking, and token-based explicit memory for geometry, combining outputs via channel-wise gating.
Parameter efficiency is a notable outcome: Mem3R reduces model size by 19% compared to CUT3R (from 793M to 644M parameters) with improved performance throughout.
Test-Time Training and Plug-and-Play State Update Mechanisms
Mem3R remains fully compatible with advanced, training-free plug-and-play state update mechanisms originally developed for CUT3R, specifically TTT3R and TTSA3R. These strategies provide per-token update gating based on current relevance. Integration of these mechanisms in Mem3R yields further improvements in both pose tracking and mapping consistency, particularly in long-horizon streaming scenarios.
Quantitative and Qualitative Evaluation
Camera Pose Estimation
Empirical evaluation on TUM Dynamics and ScanNet datasets demonstrates that Mem3R achieves significant gains in pose accuracy relative to CUT3R and Point3R. Most pronounced is the reduction in Absolute Trajectory Error (ATE): Mem3R with TTT3R achieves up to 39% lower error on 500-frame benchmarks compared with TTT3R-equipped CUT3R. When sequence lengths increase, transformer and cache-based methods exhaust memory, underscoring the practical impact of Mem3R’s constant-memory design.
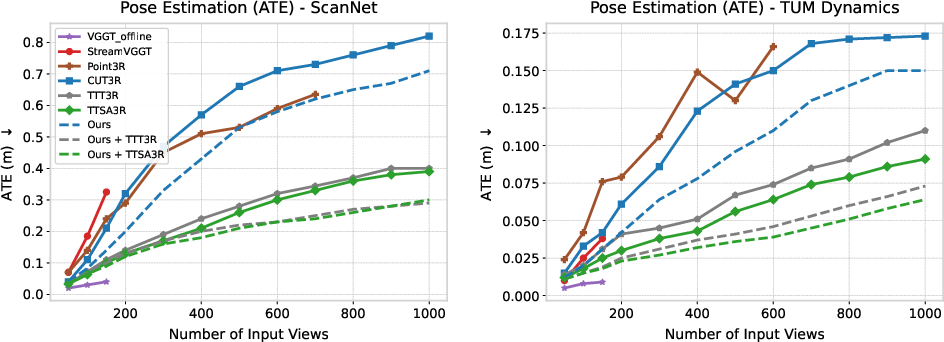
Figure 2: Pose estimation accuracy comparison on ScanNet and TUM Dynamics shows marked improvements of Mem3R, especially when combined with TTT3R or TTSA3R.
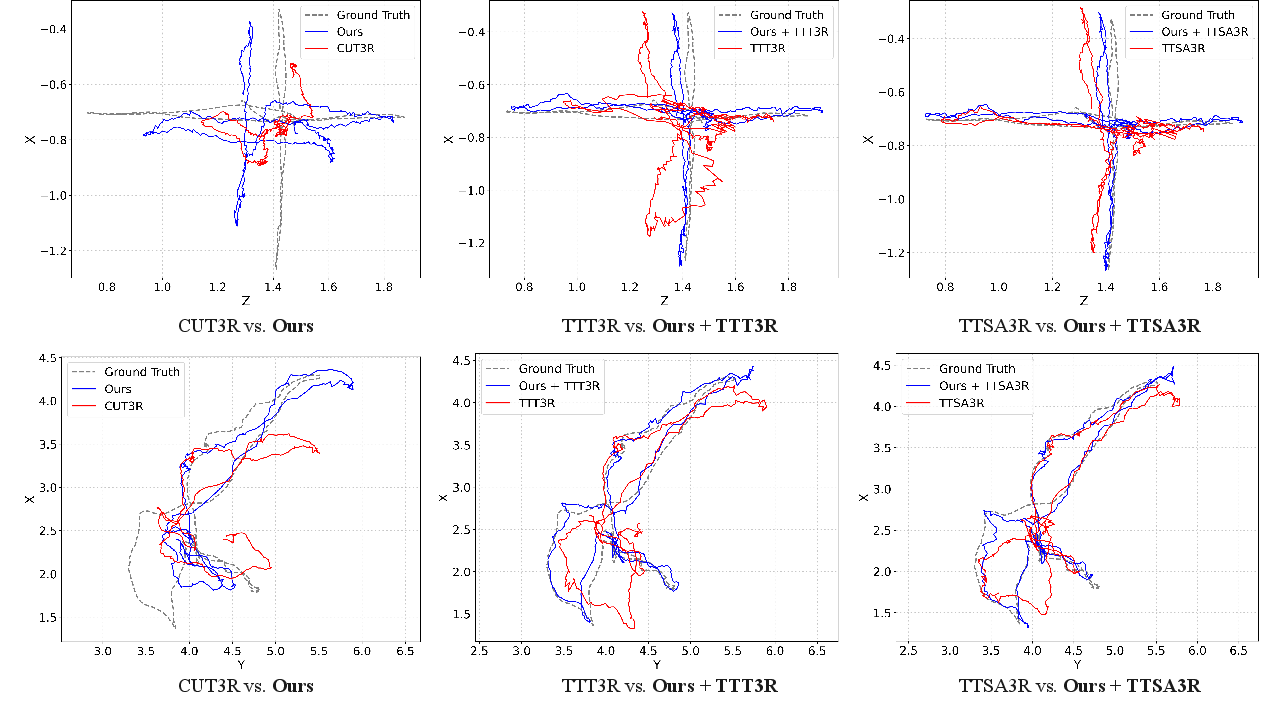
Figure 3: Mem3R yields reduced trajectory drift in predicted camera trajectories over long streaming sequences on TUM Dynamics and ScanNet.
Video Depth Estimation
Extensive experiments on KITTI and Bonn datasets demonstrate that Mem3R outperforms CUT3R and Point3R across both metric and scale-invariant depth metrics (Absolute Relative error and δ1.25 threshold). Performance gains persist when Mem3R is further equipped with TTT3R or TTSA3R variants.
3D Reconstruction
Mem3R achieves notably lower Chamfer Distance (CD) and superior Normal Consistency (NC) in long-sequence evaluation on 7-Scenes. When aligned with TTT3R/TTSA3R, Mem3R consistently outperforms not only CUT3R and Point3R, but also the offline baseline VGGT, which fails due to memory limitations.
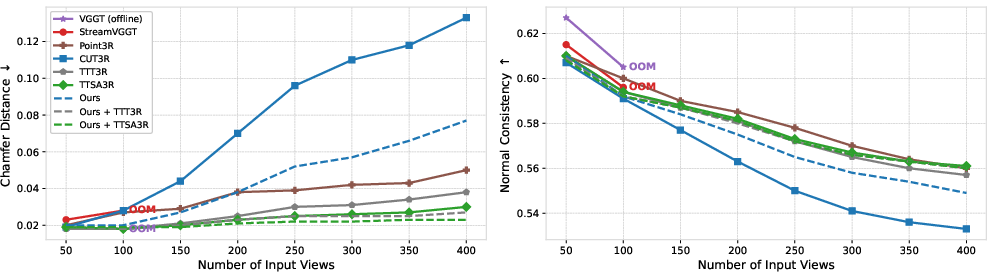
Figure 4: Quantitative evaluation of 3D reconstruction (Chamfer Distance) on 7-Scenes confirms Mem3R’s superiority versus CUT3R and other methods, particularly at high frame counts.

Figure 5: Qualitative 3D reconstructions on long sequences illustrate improvement in geometric detail and alignment for Mem3R and its plug-and-play variants.
Model Efficiency
Mem3R maintains constant GPU memory across sequence lengths and matches inference throughput of CUT3R, while reducing memory consumption by 7%. Lightweight memory modules contribute only 2.54M parameters, facilitating compact, high-throughput streaming without sacrificing accuracy.
Ablation and Component Analysis
Ablation studies confirm the necessity of both the fast-weight implicit memory and the channel-wise explicit memory gate. Removal of either module deteriorates long-horizon performance, increasing temporal forgetting and drift.
Practical and Theoretical Implications
Mem3R establishes hybrid memory architectures as effective for long-horizon streaming 3D perception under resource constraints. The separation of pose tracking and geometric mapping, coupled with online-adaptive memory and learnable gating, addresses fundamental scalability obstacles. Practically, this enables robust, real-time reconstruction in robotics, AR and embodied systems without quadratic complexity. Theoretically, Mem3R’s findings underscore the value of modular recurrent memory, plug-and-play update strategies, and fast-weight adaptation in streaming visual inference.
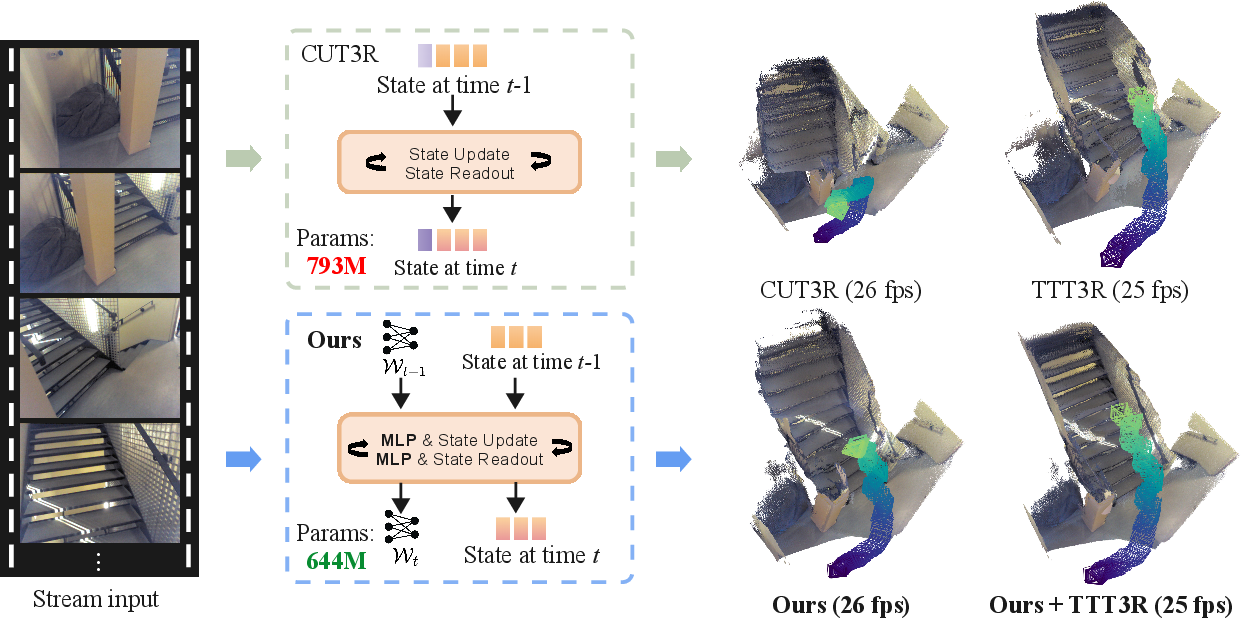
Figure 6: Mem3R hybrid memory design combines implicit MLP-based memory for pose and explicit token memory for geometry, reducing parameters and improving long-sequence performance.
Future Directions
Further research may explore expanding Mem3R’s hybrid memory principle to additional sensing modalities (e.g., multimodal sensor fusion), integrating advanced online meta-learning paradigms, scaling up sequence adaptation horizons, or embedding task-specific priors for downstream applications such as real-time semantic mapping.
Conclusion
Mem3R introduces a dual-memory, RNN-based framework for efficient streaming 3D reconstruction and pose tracking. By decoupling pose estimation from geometric mapping, leveraging adaptive implicit memory and persistent explicit memory with channel-wise gating, Mem3R delivers improved accuracy, robustness, and efficiency in long-horizon applications. Compatibility with plug-and-play state updates further amplifies these gains, establishing Mem3R as a strong architectural template for future scalable streaming 3D perception research (2604.07279).