TTT3R: 3D Reconstruction as Test-Time Training
Abstract: Modern Recurrent Neural Networks have become a competitive architecture for 3D reconstruction due to their linear-time complexity. However, their performance degrades significantly when applied beyond the training context length, revealing limited length generalization. In this work, we revisit the 3D reconstruction foundation models from a Test-Time Training perspective, framing their designs as an online learning problem. Building on this perspective, we leverage the alignment confidence between the memory state and incoming observations to derive a closed-form learning rate for memory updates, to balance between retaining historical information and adapting to new observations. This training-free intervention, termed TTT3R, substantially improves length generalization, achieving a $2\times$ improvement in global pose estimation over baselines, while operating at 20 FPS with just 6 GB of GPU memory to process thousands of images. Code available in https://rover-xingyu.github.io/TTT3R

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about helping computers build 3D models from lots of photos or video frames, quickly and without using too much memory. The authors show a simple way to stop a popular 3D method (called CUT3R) from “forgetting” earlier images when it sees long video sequences. Their new approach is called TTT3R, and it makes the computer’s memory update itself more wisely as new images come in.
What questions are the researchers trying to answer?
- Why do some fast 3D methods work well on short clips but get much worse on long videos?
- Can we change how the model updates its memory so it remembers old frames while still learning from new ones?
- Is there a training-free trick we can use during inference (the “test” phase) to make these models handle thousands of images without running out of memory?
How does the method work, in simple terms?
Think of building a 3D scene like exploring a museum with a small notebook:
- Each new photo is like a new room you enter.
- The model keeps a small “memory notebook” (called the state) because it can’t carry all photos at once.
- A normal approach (CUT3R) writes new notes strongly every time it sees a new photo. Over time, it overwrites important older notes—this is the forgetting problem.
TTT3R changes how the notebook gets updated using two ideas:
- Fast weights vs. slow weights:
- Slow weights are the model’s long-term knowledge learned during training (like rules you learned in class). They stay frozen during testing.
- Fast weights are the model’s temporary memory during testing (the notebook). They change quickly as the model sees each new frame.
- Confidence-guided updates:
- Before writing new notes, the model measures how well the current memory matches the new image. If it’s confident the new image fits the memory, it updates more. If it’s unsure (for example, the image is blurry or textureless), it updates less.
- This “confidence” acts like a trust dial (a learning rate) that controls how big each memory update should be.
Everyday analogy: imagine highlighting text in a book. If a paragraph clearly supports what you’ve learned, you highlight it boldly. If it’s vague, you only lightly underline it. TTT3R applies this kind of smart, confidence-based highlighting to the model’s memory as it processes each image.
What makes this neat:
- It’s training-free. You don’t retrain the model.
- It runs in real time and uses constant memory because the notebook stays the same size no matter how many frames you process.
- It fits right into CUT3R like a plug-in.
What did they find?
- TTT3R significantly improves accuracy on long video sequences compared to CUT3R. In camera pose estimation (figuring out where the camera is in space), it achieves about 2× better results than the baseline.
- It runs fast: about 20 frames per second.
- It’s memory-efficient: around 6 GB of GPU memory even for thousands of images, so it avoids the “out-of-memory” crashes that happen with big attention-based models.
- It improves depth estimation and 3D reconstruction quality, especially on long sequences where other methods drift or produce broken geometry.
- It keeps the benefits of recurrent models (speed and constant memory) while reducing the forgetting problem and even helps with “loop closure” (recognizing and correcting when you return to a place you’ve seen before).
Why is this important?
- Real-world tasks like robotics, AR/VR, mapping, and drones need to handle long videos in real time on limited hardware. TTT3R helps do that by keeping memory steady and updates smart.
- It shows a new way to think about these models: treat the model’s memory like something you can improve during testing, not just during training.
- It points toward better, more reliable 3D systems that can scale to very long sequences without slowing down or breaking.
A quick note on limitations
TTT3R doesn’t completely fix forgetting, and the very best offline methods that look at all frames at once (like big Transformers) can sometimes be more accurate—but they are much slower and use much more memory. TTT3R is a practical, lightweight step that balances speed, memory, and accuracy for long, real-time sequences.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper that future researchers could address.
- Lack of theoretical guarantees: no convergence, stability, or regret bounds are provided for the proposed confidence-guided learning-rate update; conditions under which the state does not diverge (or catastrophically forget) remain unproven.
- Optimality of the learning rate: the choice
β_t = σ(∑_m Q_S K_X^T)is heuristic; it is unclear if this statistic is the best proxy for alignment confidence versus alternatives (e.g., entropy of attention, max/mean pooling, temperature-scaled dot products, top-k/thresholded attention). - Sensitivity to normalization and scaling: no analysis of how the magnitude of queries/keys, attention temperature, or feature norms affect
β_t; potential saturation of the sigmoid and its impact on update dynamics is not studied. - Per-token vs per-head/channel gating:
β_tis per-state-token but not per-head or per-channel; whether head-wise or channel-wise gating improves stability/accuracy is unexplored. - Write/read interplay: only the state update (“write”) rule is modified; the “read” operation remains unchanged. How confidence gating should affect retrieval (e.g., readout weighting, query normalization) is not examined.
- Memory capacity vs sequence length: the paper does not quantify how many distinct views can be reliably retained given state size
(n, c); memory interference, capacity limits, and scaling laws are missing. - Initialization and reset policies: how the state is initialized, when/if to reset, and how to segment extremely long streams (e.g., chunking, reservoir sampling) are not specified or evaluated.
- Error recovery and rollback: there is no mechanism to undo or attenuate erroneous updates; strategies like confidence decay, backtracking, or adaptive forgetting when misalignments are detected are not studied.
- Loop-closure quantification: claims of “online loop closure” lack formal metrics (e.g., drift before/after revisits, pose-graph residuals, place-recognition precision/recall) and controlled evaluations.
- Robustness stress tests: performance under adversarial/challenging conditions (low parallax, pure rotation, rolling shutter, motion blur, occlusions, repetitive textures, heavy dynamics) is not systematically analyzed.
- Out-of-distribution generalization: the method is not evaluated on diverse domains (e.g., outdoor widescale scenes with strong illumination changes, highly dynamic crowds, low-texture industrial settings).
- Metric-scale accuracy limits: absolute-scale depth evaluation is limited (VGGT excluded); failure modes of metric scale under intrinsics misestimation, focal length drift, or zoom changes remain unaddressed.
- Impact on short-sequence performance: while long-sequence gains are shown, a thorough analysis of any trade-offs on short sequences and small contexts is missing.
- Computational overhead details: “no additional cost” is claimed, but the exact incremental cost of computing
β_t(over different resolutions, heads, and token counts) and its scalability on lower-end GPUs/CPUs is not reported. - Applicability beyond CUT3R: whether TTT3R generalizes to other recurrent/streaming architectures (e.g., Mamba/SSM layers, LRU, DeltaNet variants, causal Transformers with KV compression) without retraining is unknown.
- Joint training vs test-time only: the paper applies the update rule at inference without fine-tuning; whether training the slow weights to anticipate this test-time update (meta-learning, TBTT schedules) yields further gains remains unexplored.
- Interaction with classical SLAM/SfM: combining TTT3R with lightweight bundle adjustment, pose-graph optimization, or geometric loop-closure could improve accuracy; integration points and latency trade-offs are not studied.
- Tokenizer and backbone dependence: sensitivity to the choice of image tokenizer (e.g., DINO vs CroCo), feature resolution, and backbone architecture is not ablated.
- Ordering effects: how input frame ordering (forward vs shuffled vs reverse, or revisits interleaved) influences stability and reconstruction quality is not evaluated.
- Confidence calibration: attention-derived confidence may be miscalibrated; techniques for calibration (e.g., temperature scaling, uncertainty estimation, stochastic ensembling) and their effect on
β_tare not examined. - Numerical stability: potential issues with precision, accumulation, and overflows in long sequences (especially with large
n,c, and high-resolution tokens) are not characterized. - Failure case analysis: qualitative and quantitative breakdowns of specific failure modes (drift, ghosting, broken geometry, pose flips) and the conditions that trigger them are limited.
- Memory state dimensionality: the paper does not provide design guidance for selecting state size, number of tokens, and channels to balance capacity, speed, and accuracy across tasks.
- Evaluation breadth and fairness: baseline coverage is limited; comparisons to other modern RNNs or streaming models (e.g., Titans, Gated Linear Attention) and standardized long-context benchmarks are missing.
- Reproducibility details: full hyperparameters, data splits, preprocessing, and hardware variations (beyond a single 48GB GPU) are not fully documented for replicating long-sequence results.
Practical Applications
Overview
The paper introduces TTT3R, a training-free, plug-and-play modification to recurrent 3D reconstruction models (e.g., CUT3R). It reframes the model’s state as fast weights updated at test time via confidence-guided gradient descent. By using cross-attention alignment confidence as per-token learning rates, TTT3R mitigates catastrophic forgetting and substantially improves length generalization. It delivers real-time performance (about 20 FPS), constant memory usage (around 6 GB GPU), and scales to thousands of frames, with a reported 2× improvement in global pose estimation versus baselines.
Below are practical applications derived from the paper’s findings, methods, and innovations. Each application includes sectors, indicative tools/workflows, and key dependencies/assumptions.
Immediate Applications
These can be deployed now with the existing TTT3R codebase and typical GPU resources.
- Robotics and SLAM for long missions (warehouses, factories, service robots)
- Sector: robotics, logistics
- What: Real-time camera pose estimation and dense pointmap reconstruction over long sequences without memory bloat; more robust loop closure than prior RNN baselines.
- Tools/workflows: ROS node integrating TTT3R; pipeline consuming RGB streams; outputs poses and metric pointmaps for navigation and mapping; deploy on NVIDIA Jetson AGX Orin or desktop GPUs.
- Dependencies/assumptions: Pretrained slow weights (e.g., from CUT3R); sufficient scene texture and parallax; camera intrinsics available or regressed; 6 GB GPU memory recommended; TTT3R mitigates but does not eliminate forgetting.
- Drone-based real-time mapping and inspection
- Sector: energy (assets), construction, public safety, agriculture
- What: Stream thousands of frames from UAV cameras to create on-the-fly, large-area 3D maps with constant memory usage.
- Tools/workflows: Edge compute module running TTT3R in the field; cloud microservice for aggregation; integration with flight control and mission planning software.
- Dependencies/assumptions: Stable camera stream; GPS/IMU optional but helpful; dynamic/textureless regions still challenging; regulatory compliance for flight operations.
- Mobile AR/VR scanning for large spaces
- Sector: software, consumer tech, real estate, cultural heritage
- What: Continuous 3D capture of homes, museums, and venues; improved long-sequence consistency and loop closure for walkthroughs and digital twins.
- Tools/workflows: SDK/plugin for Unity/Unreal/AR Foundation; capture on device and stream to an edge/cloud TTT3R service; export point clouds or meshes.
- Dependencies/assumptions: On-device GPUs may be insufficient for 6 GB; offloading to edge/cloud recommended; lighting and texture affect quality; not yet matching full-attention offline accuracy.
- Construction and facility management progress capture
- Sector: construction, AEC (architecture, engineering, construction)
- What: Regular scans of large sites to track progress and detect drift or geometry inconsistencies.
- Tools/workflows: Scheduled scanning workflows; TTT3R as a backend service; integration with BIM tools; automatic registration of long sequences.
- Dependencies/assumptions: Accurate intrinsics or initial calibration; large-scale loop closure improved but not perfect; dynamic scenes (moving machinery) may reduce quality.
- Film/VFX location scouting and on-set previsualization
- Sector: media and entertainment
- What: Rapid 3D recon of sets and outdoor locations from handheld or dolly camera streams; long-sequence consistency for blocking and layout decisions.
- Tools/workflows: TTT3R microservice in the dailies pipeline; export to DCC tools (Maya, Blender) as point clouds; real-time visualization.
- Dependencies/assumptions: Requires a capable GPU on-set or portable workstation; may need denoising/post-processing; accuracy lower than offline full-attention methods.
- Security and forensics scene reconstruction from CCTV/video
- Sector: public safety
- What: Reconstruct incident scenes from long camera sequences in resource-constrained environments.
- Tools/workflows: Evidence processing pipeline with TTT3R for pose/depth/pointmaps; timeline-based reconstruction UI.
- Dependencies/assumptions: Privacy/legal policies; camera quality varies; robustness to compression and low light is limited.
- Academic research on sequence length generalization and test-time training
- Sector: academia
- What: Use TTT3R to study fast/slow weights, adaptive learning rates, and forgetting in long-context RNNs; benchmark improvements in 3D reconstruction tasks.
- Tools/workflows: Reproducible code; extend to other sequential vision tasks (e.g., video depth, multi-view stereo).
- Dependencies/assumptions: Access to datasets (KITTI, TUM, ScanNet, 7-Scenes); domain shifts may require evaluation/adjustments.
- Educational use in computer vision and DL courses
- Sector: education
- What: Lab modules demonstrating test-time training, associative memory, and confidence-guided gating for online reconstruction.
- Tools/workflows: Classroom notebooks; simplified pipelines; visualizations of learning rates and state updates.
- Dependencies/assumptions: GPUs in labs or cloud credits; curated short and long-sequence datasets.
- Integration into existing 3D software stacks
- Sector: software
- What: Add TTT3R as a streaming module to pipelines using DUSt3R/CUT3R/VGGT; enable real-time processing for large sequences with constant memory.
- Tools/workflows: Python/C++ bindings; containerized microservice; CLI for batch runs; exporters to common formats.
- Dependencies/assumptions: License/compliance with third-party model weights; careful engineering for throughput and I/O.
Long-Term Applications
These require further research, scaling, hardware optimizations, or regulatory approvals.
- City-scale live mapping and digital twins
- Sector: smart cities, utilities, urban planning
- What: Continuous, multi-camera urban reconstruction with on-the-fly updates and loop closure across thousands to millions of frames.
- Tools/workflows: Distributed TTT3R services; map fusion; hierarchical memory; spatiotemporal indexing.
- Dependencies/assumptions: Multi-agent coordination; privacy and geospatial data governance; improved robustness to dynamic scenes; edge/cloud scaling.
- Continuous AR glasses SLAM with on-device test-time training
- Sector: consumer AR, enterprise AR
- What: Always-on mapping for AR wearables, leveraging fast-weight updates to maintain scene memory with tiny compute budgets.
- Tools/workflows: Hardware acceleration for TTT updates; model compression; energy-efficient runtime.
- Dependencies/assumptions: Specialized silicon/accelerators; reduced memory footprint; rigorous UX and safety constraints.
- Autonomous driving camera-only mapping augmentation
- Sector: automotive
- What: Complement LiDAR with camera-based dense depth/pointmaps for long routes; better memory retention across traversals.
- Tools/workflows: Sensor fusion (vision + IMU/GPS/LiDAR); map consistency checks; validation at scale.
- Dependencies/assumptions: Robustness to motion blur, weather, nighttime; safety-critical performance and certification; current accuracy still below best offline methods.
- Medical endoscopy and surgical navigation 3D reconstruction
- Sector: healthcare
- What: Real-time 3D recon from endoscopic video streams to aid navigation and documentation.
- Tools/workflows: Sterile edge compute modules; integration with surgical systems; QA pipelines.
- Dependencies/assumptions: Regulatory approvals (FDA/CE); domain-specific training/validation; extreme texture/lighting variability.
- Industrial inspection and asset management at scale
- Sector: energy, manufacturing
- What: Long, continuous scans of pipelines, plants, and machinery with streaming reconstruction and change detection.
- Tools/workflows: Integration with CMMS/EAM; anomaly detection models on reconstructed geometry; scheduled scanning policies.
- Dependencies/assumptions: Harsh environments; safety protocols; multimodal fusion (thermal, acoustic, IMU) for reliability.
- Collaborative multi-agent mapping with shared fast-weight memory
- Sector: robotics, defense, disaster response
- What: Multiple agents running TTT3R, sharing confidence-weighted updates to build unified maps.
- Tools/workflows: Networked memory synchronization; conflict resolution; federated test-time learning.
- Dependencies/assumptions: Communication constraints; robust identity/pose fusion; security.
- Streaming 4D reconstruction (dynamic scenes) with advanced gating
- Sector: research, media, sports analytics
- What: Extend TTT3R to model motion and nonrigid deformation; maintain temporal coherence over long sequences.
- Tools/workflows: Hybrid models with Gaussian Splatting/NeRF; motion-aware confidence gating; temporal regularization.
- Dependencies/assumptions: Algorithmic advances for dynamics; more powerful hardware; data capture standards.
- Standardized benchmarks and policy for length generalization and compute efficiency
- Sector: policy, standards bodies
- What: Establish metrics and procurement guidelines prioritizing energy-efficient, constant-memory AI for long-context tasks.
- Tools/workflows: Public datasets and leaderboards; reporting requirements for memory/FLOPs; sustainability audits.
- Dependencies/assumptions: Multi-stakeholder coordination; alignment with privacy and accessibility regulations.
- Edge hardware acceleration for test-time training in RNNs
- Sector: semiconductors, embedded systems
- What: Dedicated kernels/ASICs for confidence-guided gradient updates; low-latency memory operations.
- Tools/workflows: Compiler support; APIs for fast-weight operations; model compression pipelines.
- Dependencies/assumptions: Industry adoption; co-design with model architectures; economic viability.
- Integration with photorealistic digital twin pipelines
- Sector: AEC, entertainment, smart manufacturing
- What: Use TTT3R outputs to drive NeRF/Gaussian Splatting for high-fidelity twins constructed from long video streams.
- Tools/workflows: Automated handoff from pointmaps to radiance fields; incremental updates; quality assurance.
- Dependencies/assumptions: Robust long-term geometry; standardized formats; compute scaling for rendering.
Cross-cutting assumptions and dependencies
- TTT3R is training-free at inference but depends on high-quality pretrained slow weights (e.g., CUT3R) and tokenizers (DINO/CroCo).
- Accuracy on long sequences improves versus prior RNN baselines but may still trail offline full-attention methods; dynamic/textureless scenes remain challenging.
- Real-time performance numbers (around 20 FPS, ~6 GB GPU) assume desktop-class GPUs; mobile/on-device deployments likely need compression or edge offloading.
- Camera intrinsics can be regressed or solved; reliable calibration improves outcomes.
- Legal, privacy, and safety requirements apply for public scanning, security, healthcare, and automotive uses.
Glossary
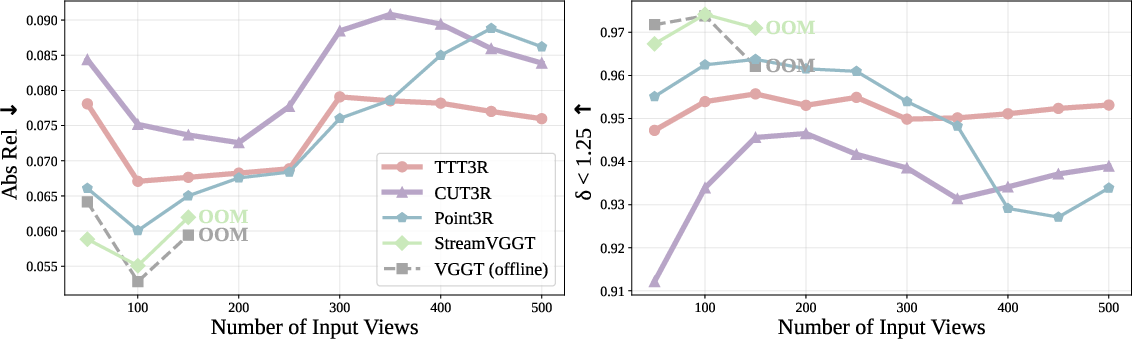
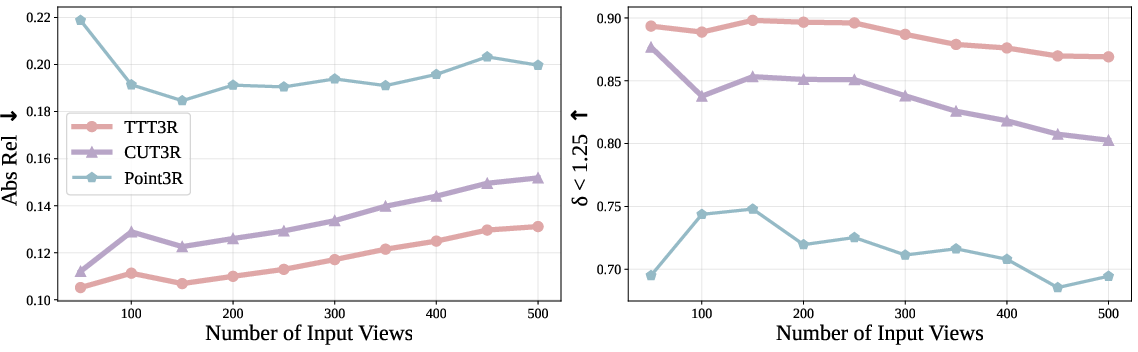
- Absolute Relative Error (Abs Rel): A depth estimation metric measuring the average absolute relative difference between predicted and ground-truth depths. "We adopt standard metrics: absolute relative error (Abs Rel) and (percentage of predicted depths within a 1.25-factor of true depth) ."
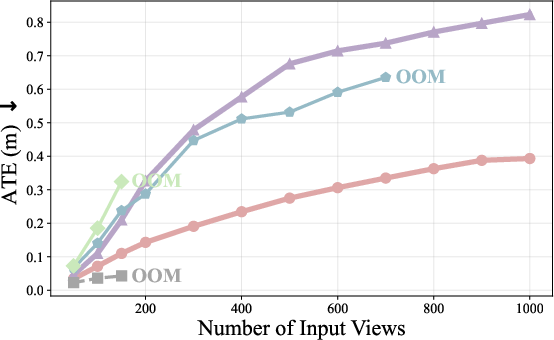
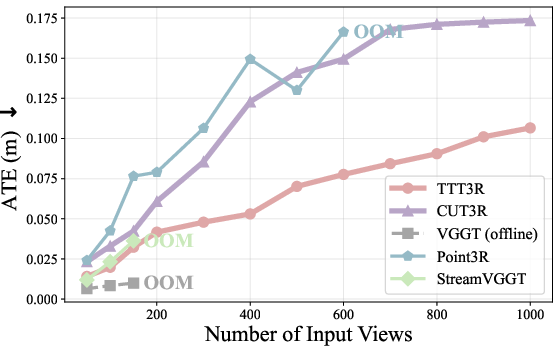
- Absolute Translation Error (ATE): A trajectory metric quantifying translation error of estimated camera poses, typically computed after similarity alignment. "We adopt the standard metric, Absolute Translation Error (ATE), computed after applying Sim(3) alignment~\citep{umeyama} between the estimated and ground-truth camera trajectories."
- Associative memory: A memory mechanism where stored patterns can be retrieved by association; in neural nets, fast weights serve as such memory. "In contrast to the slow weights in neural networksâwhich act as meta-learners~\citep{meta_learning} and are only adjusted during trainingâfast weights are learned to function as associative memory~\citep{associative_memory,hopfield}."
- Associative recall: Retrieving information from memory via association across long contexts. "This perspective provides a principled understanding of state overfitting, suggesting that associative recall~\citep{associative_memory,hopfield} over long contexts, combined with gradient-based updates using adaptive learning rates to balance forgetting and learning~\citep{RetNet,GLA,xlstm,Mamba,Longhorn,DeltaNet,Titans}, can substantially enhance length generalization."
- Bundle Adjustment (BA): A nonlinear optimization that jointly refines camera poses and 3D structure using reprojection errors. "followed by bundle adjustment (BA)~\citep{agarwal2010bundle,triggs2000bundle,Droid,tang2018ba,Vggsfm,acezero} for structure and motion refinement."
- Canonical point cloud: A point cloud represented in a unified global coordinate frame. "and the canonical point cloud $\bP_t \in \mathbb{R}^{W\times H \times 3}$."
- Causal attention: An attention mechanism that restricts each token to attend only to itself and past tokens, enabling streaming. "StreamVGGT~\citep{StreamVGGT} uses a causal attention architecture to model the causal nature of streaming data, which restricts each frame to attend only to itself and preceding tokens, allowing only $\bY_t$ to be updated given $\bX_t$."
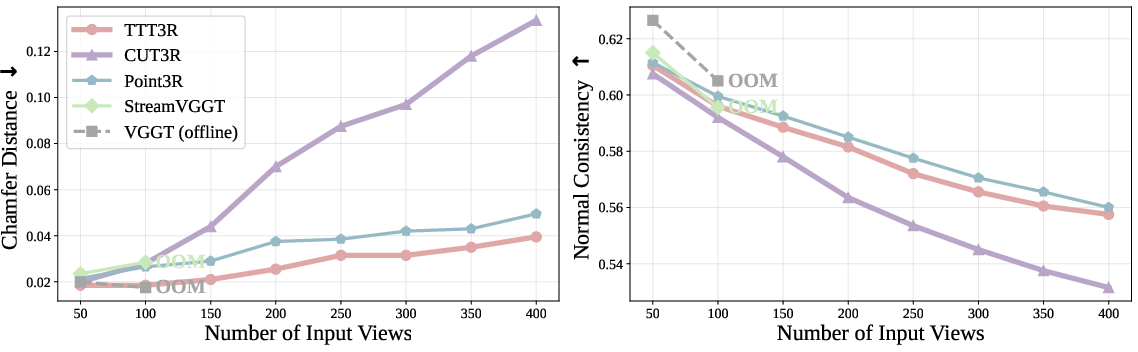
- Chamfer distance: A symmetric measure of distance between two point sets, used to evaluate 3D reconstruction accuracy and completeness. "As in prior work~\citep{Feat2GS,spann3r,cut3r}, we use chamfer distance and normal consistency as evaluation metrics."
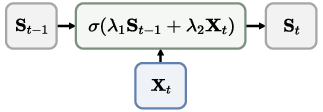
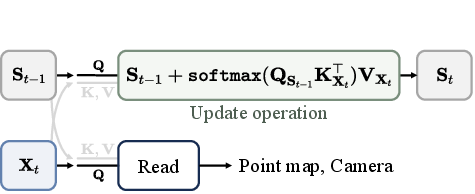
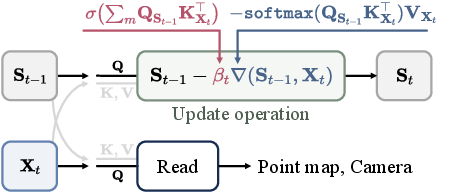
- Confidence-aware learning rate: A learning rate scaled by alignment confidence between memory and the current observation to gate updates. "TTT3R makes online state updates by balancing the retention of historical information ${\bS_{t-1}$ with a confidence-aware learning rate ."
- Confidence-guided state update: Updating the model’s state using confidence measures to modulate the update size. "our reformulation from a test-time training perspective introduces a confidence-guided state update, where alignment confidence between memory and observations serves as per-token learning rates."
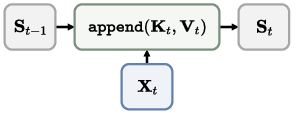
- Cross-attention: Attention where queries from one sequence attend to keys/values from another sequence. "For RNN-based methods~\citep{spann3r,MUSt3R,LONG3R,Point3R,cut3r}, each incoming frame interacts with the state via one-to-one cross-attention"
- DPT head: A Dense Prediction Transformer-based output head used for dense map predictions (e.g., depth). "such as linear layers with pixel shuffle~\citep{pixelshuffle} and a DPT head~\citep{dpt}."
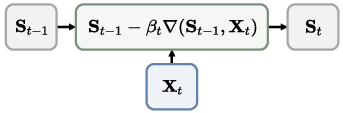
- Fast weights: Rapidly changing state parameters updated at test time to capture in-context information. "We treat the state $\bS_{t}$ as a fast weight updated via gradient descent"
- Flash attention: An efficient attention algorithm that reduces memory bandwidth and improves speed for Transformer attention. "such as KV-cache compression~\citep{KVcache} and flash attention~\citep{Flashattention}"
- FLOPs utilization: The effective use of available floating-point operation capacity during model execution. "whereas simply extending the sequence length during training leads to extremely low FLOPs utilization."
- Frames per second (FPS): A measure of runtime speed indicating how many frames are processed per second. "reporting two metrics: frames per second (FPS) and peak GPU memory usage (GB)."
- Full attention: Global all-to-all self-attention where every token attends to all tokens, incurring quadratic cost. "relying on the full attention~\citep{attention} causes a quadratic increase in computational and memory cost, and results in an offline process that requires re-running inference over all images whenever a new frame arrives."
- Gated attention: Attention modulated by gates that control the flow or magnitude of updates. "This learning rate can act as a soft gate in gated attention, incorporating it into the attention output allows for better long-context extrapolation~\citep{GatedAttention}."
- Gated Linear Attention: A linear-attention variant that applies token-wise gates to control state updates. "a per-token function $\beta_t=\sigma \left(\ell_{\beta}\left(\bX_t\right)\right) \in \mathbb{R}^{n \times 1}$ in Gated Linear Attention~\citep{GLA}, which enables token-wise adaptive learning rates across all state tokens."
- KV-cache: A cache of attention keys and values used to avoid recomputation and store context across steps. "such as KV-cache compression~\citep{KVcache}"
- Length generalization: The capability of a model to maintain performance on sequences longer than those used for training. "However, their performance degrades significantly when applied beyond the training context length, revealing limited length generalization."
- Linear attention: Attention that replaces softmax with inner products to enable linear-time updates and constant memory. "linear attention equally compresses all key value pairs into its finite-sized state, resulting in performance degradation as the sequence length increases."
- Loop closure: Recognizing previously seen views to correct drift and maintain global consistency during reconstruction. "TTT3R mitigates catastrophic forgetting and facilitates online loop closure."
- Meta-learner: A higher-level model whose parameters guide the adaptation of fast weights during inference. "These slow weights are learned from training datasets and act as a meta-learner, enabling the fast weight to serve as an associative memory."
- Normal consistency: A metric evaluating how consistent surface normals are between reconstructed and ground-truth geometry. "we use chamfer distance and normal consistency as evaluation metrics."
- Online learning: A learning paradigm where updates occur sequentially as new data arrives, without offline retraining. "framing their designs as an online learning problem."
- Out-of-memory (OOM): A condition where available GPU memory is exhausted during computation. "OOM denotes the method out-of-memory beyond this point."
- Per-token learning rate: A learning rate assigned individually to each state token to enable adaptive, confidence-based updates. "where alignment confidence between memory and observations serves as per-token learning rates."
- Perspective-n-Point (PnP): An algorithm to estimate camera pose from 2D-3D correspondences. "The camera pose $\bT_t$ and the camera intrinsic $\bC_t$, can either be solved from pixel-aligned 3D pointmaps using the PnP~\citep{epnp} and Weiszfeld~\citep{weiszfeld} algorithms"
- Pixel-aligned pointmaps: Dense per-pixel 3D points aligned with image coordinates, enabling pose and geometry estimation. "recent advances~\citep{dust3r,VGGT,zhang2025advances} successfully map sequences of images into pixel-aligned pointmaps~\citep{dsac,acezero}."
- Pixel shuffle: An upsampling operation that rearranges channels into spatial dimensions for dense predictions. "such as linear layers with pixel shuffle~\citep{pixelshuffle}"
- Sim(3) alignment: Aligning trajectories or point sets with a similarity transform (scale, rotation, translation). "computed after applying Sim(3) alignment~\citep{umeyama} between the estimated and ground-truth camera trajectories."
- Simultaneous Localization and Mapping (SLAM): A paradigm that estimates camera trajectory while building a map of the environment. "Simultaneous Localization and Mapping (SLAM)~\citep{newcombe2011dtam,mur2015orb,davison2007monoslam,engel2014lsd,CasualSAM,MegaSaM} have long been the foundation for 3D structure reconstruction and camera pose estimation."
- Slow weights: The fixed model parameters at inference time that guide test-time adaptation of fast weights. "where the learning rate and the gradient are predicted by the frozen slow weights."
- State forgetting: Loss of earlier information in a fixed-size state as new data arrives, harming long-context performance. "identifying correlations with state overfitting~\citep{Longssm}, state forgetting~\citep{StuffedMamba,Repeat}, and unexplored state distributions~\citep{Length_Generalization}."
- State overfitting: When a model’s state becomes overly specialized to training contexts, reducing generalization to longer sequences. "identifying correlations with state overfitting~\citep{Longssm}, state forgetting~\citep{StuffedMamba,Repeat}, and unexplored state distributions~\citep{Length_Generalization}."
- Structure-from-Motion (SfM): Recovering 3D structure and camera motion from image sequences. "Structure-from-Motion (SfM)~\citep{pollefeys1999self,pollefeys2004visual,snavely2008modeling,agarwal2011building,Schoenberger2016CVPR,snavely2006photo,Robust-CVD} and Simultaneous Localization and Mapping (SLAM)~\citep{newcombe2011dtam,mur2015orb,davison2007monoslam,engel2014lsd,CasualSAM,MegaSaM} have long been the foundation for 3D structure reconstruction and camera pose estimation."
- Test-Time Training (TTT): Updating fast weights or model components during inference to adapt to the current context. "Test-Time Training (TTT)~\citep{ttt} introduces fast weights~\citep{fast_weight} as rapidly adaptable states that are updated during both training and inference to dynamically capture context."
- Truncated Backpropagation Through Time (TBTT): Training technique that backpropagates through a limited sequence length to improve efficiency and stability. "employing Truncated Backpropagation Through Time (TBTT)~\citep{sutskever2013training,williams1990efficient,Length_Generalization} have been proposed to improve length generalization."
- Weiszfeld algorithm: An iterative method for computing the geometric median, used here for camera parameter estimation. "The camera pose $\bT_t$ and the camera intrinsic $\bC_t$, can either be solved from pixel-aligned 3D pointmaps using the PnP~\citep{epnp} and Weiszfeld~\citep{weiszfeld} algorithms"
Collections
Sign up for free to add this paper to one or more collections.

