Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering
Abstract: LLM agents are increasingly built less by changing model weights than by reorganizing the runtime around them. Capabilities that earlier systems expected the model to recover internally are now externalized into memory stores, reusable skills, interaction protocols, and the surrounding harness that makes these modules reliable in practice. This paper reviews that shift through the lens of externalization. Drawing on the idea of cognitive artifacts, we argue that agent infrastructure matters not merely because it adds auxiliary components, but because it transforms hard cognitive burdens into forms that the model can solve more reliably. Under this view, memory externalizes state across time, skills externalize procedural expertise, protocols externalize interaction structure, and harness engineering serves as the unification layer that coordinates them into governed execution. We trace a historical progression from weights to context to harness, analyze memory, skills, and protocols as three distinct but coupled forms of externalization, and examine how they interact inside a larger agent system. We further discuss the trade-off between parametric and externalized capability, identify emerging directions such as self-evolving harnesses and shared agent infrastructure, and discuss open challenges in evaluation, governance, and the long-term co-evolution of models and external infrastructure. The result is a systems-level framework for explaining why practical agent progress increasingly depends not only on stronger models, but on better external cognitive infrastructure.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Externalization in LLM Agents — Explained Simply
What this paper is about
This paper looks at how modern AI assistants (called LLM agents) are getting better not just by making the AI brain itself bigger, but by building smart “outside help” around it. The authors call this “externalization,” which means moving hard mental work out of the model and into helpful tools and structures. Think of it like a student who does better not just by getting smarter, but by using a planner, notes, step‑by‑step guides, and clear classroom rules.
They focus on four parts:
- Memory: saving what happened before so the AI doesn’t have to remember everything at once.
- Skills: reusable instructions for how to do tasks correctly.
- Protocols: clear rules for talking to tools and other AIs.
- The Harness: the “operating system” that coordinates memory, skills, and protocols so everything works together.
The big questions the paper asks
The paper tries to answer simple but important questions:
- Why are AI systems improving so much without changing the model’s inner weights?
- What kinds of “outside help” (memory, skills, protocols) make AI agents more reliable?
- How do these parts fit together in a full system (the harness)?
- What trade-offs exist between what the AI keeps inside its head (its weights) and what we put outside?
- Where is this all going next, and what challenges still remain?
How the authors studied this
This is a review paper. That means the authors didn’t run one big experiment; instead, they read and organized many recent research projects to build a clear, simple framework for understanding what’s happening. Their approach:
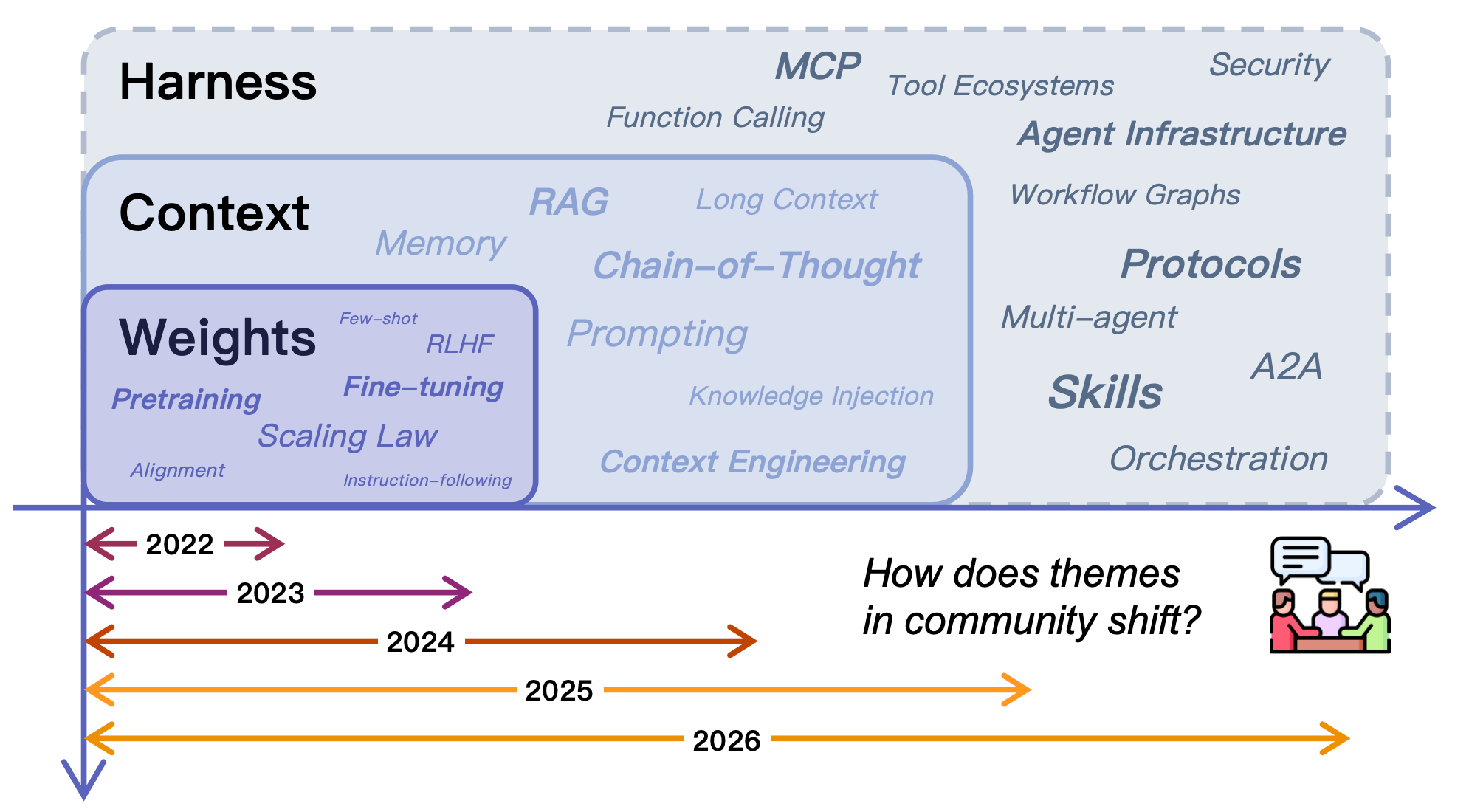
- Map the “shift” in AI design from: 1) Weights (all in the model’s head), 2) to Context (give the model useful information at run time), 3) to Harness (build a whole support system around it).
- Explain how each type of externalization changes the problem into an easier one for the AI, using everyday thinking tools as an analogy (like lists, maps, and checklists).
- Show how memory, skills, and protocols interact inside the harness and where they can conflict or support each other.
- Highlight open problems and future directions.
A helpful analogy: Imagine a kid doing a big science project.
- Weights = what’s already in their brain.
- Context = a carefully prepared study sheet they read while working.
- Memory = a notebook of past experiments and results they can look up later.
- Skills = a laminated “how to run an experiment safely” checklist.
- Protocols = class rules for borrowing lab equipment and sharing results.
- Harness = the whole lab setup: whiteboard, folders, schedule, safety rules, and a teacher who keeps everything organized.
What they found and why it matters
Here are the main takeaways, in plain language:
- Bigger models aren’t the only path to better AI. Many of the biggest gains now come from building the right support system around the model.
- Externalization turns hard problems into easier ones:
- Memory turns “remember everything” into “recognize and retrieve what you need.” That’s like using a notebook so you don’t rely on memory alone.
- Skills turn “make it up every time” into “assemble from proven steps.” That’s like following a recipe instead of guessing.
- Protocols turn “messy, fragile tool use” into “clean, dependable connections.” That’s like using standard plugs and rules so everything fits and works.
- The Harness coordinates it all. It manages:
- What gets saved and retrieved,
- Which skills to apply and when,
- How to talk to tools and other agents,
- How to check outputs, handle errors, and stay within rules.
- These parts interact:
- Memory and skills compete for limited attention: too much retrieved info can crowd out important steps, and loading too many skills can bloat the prompt.
- Skills produce traces (logs) that become future memory.
- Protocols make tool use safer but also constrain how capabilities are packaged and called.
- The harness must balance these trade-offs for reliability.
- There’s a key trade-off between “inside the model” and “outside help”:
- Inside (weights) is fast and general but hard to update or audit.
- Outside (externalization) is flexible, inspectable, and personalized but adds complexity and needs good design.
- Future directions and open challenges:
- Self-improving harnesses that adapt memory, skills, and protocols over time.
- Shared infrastructure so different agents can cooperate more easily.
- Better evaluation methods for long, real-world tasks.
- Governance: permissions, safety, privacy, and oversight for what agents can access and do.
Why this is important
This research says something simple but powerful: to build trustworthy AI assistants, don’t just make the AI smarter—make its environment smarter. With good memory, clear skills, and strong protocols, an AI can:
- Stay consistent over long tasks,
- Follow rules and workflows reliably,
- Use tools safely and effectively,
- Personalize to users without retraining the whole model,
- Be easier to debug, audit, and improve.
In short, the future of practical AI looks less like a single giant brain and more like a well-organized team: a capable thinker (the model) working inside a strong system (the harness) with notes (memory), playbooks (skills), and clear handshakes (protocols). This shift could make AI agents more dependable at school, work, research, coding, customer support, and beyond—while also making them easier to control and trust.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper articulates a systems-level framework for externalization (memory, skills, protocols, harness) but leaves several critical questions unresolved that future research could address:
- Quantifying externalization benefits: lack of standardized, task- and system-level benchmarks and ablation protocols that isolate the causal contribution of memory vs skills vs protocols vs harness to reliability, efficiency, and safety across long-horizon tasks.
- Parametric vs externalized capability trade-offs: absence of decision frameworks that predict when to fine-tune weights (or use larger contexts) versus externalize (memory/skills/protocols), given constraints on latency, cost, privacy, stability, and change frequency of knowledge.
- Formalizing representational transformation: no operational definition or measurable surrogate for the “recall→recognition” and “generation→composition” shifts; need quantitative metrics linking representational changes to error rates and variance reduction.
- Retrieval quality under long horizons: insufficient methods for guaranteeing high-recall, high-precision retrieval from large, heterogeneous memory stores without distracting noise; need robust indexing, negative retrieval safeguards, and calibration signals.
- Memory lifecycle criteria: unclear, actionable policies for when and how to promote episodic traces to semantic knowledge, consolidate/abstract, compress, or forget; need algorithms with provable stability and bounded drift.
- Robustness to memory noise and poisoning: lack of defenses against adversarial or accidental contamination of memory (e.g., prompt injection residues, tool-output poisoning), including detection, quarantine, rollback, and provenance verification.
- Personalized memory governance: unresolved privacy-preserving mechanisms (e.g., differential privacy, encryption, on-device stores, consent management) for user-specific memory; handling Right-to-be-Forgotten and preference drift at scale.
- Multi-tenant/shared memory control: missing OS-like primitives for access control, quota management, conflict resolution, and consistency models when multiple agents read/write shared state concurrently.
- State abstraction beyond code-centric domains: the “file-centric” state abstraction (e.g., InfiAgent) is compelling for software tasks but untested for other domains (embodied agents, enterprise workflows, scientific discovery); need generalized, domain-agnostic state models.
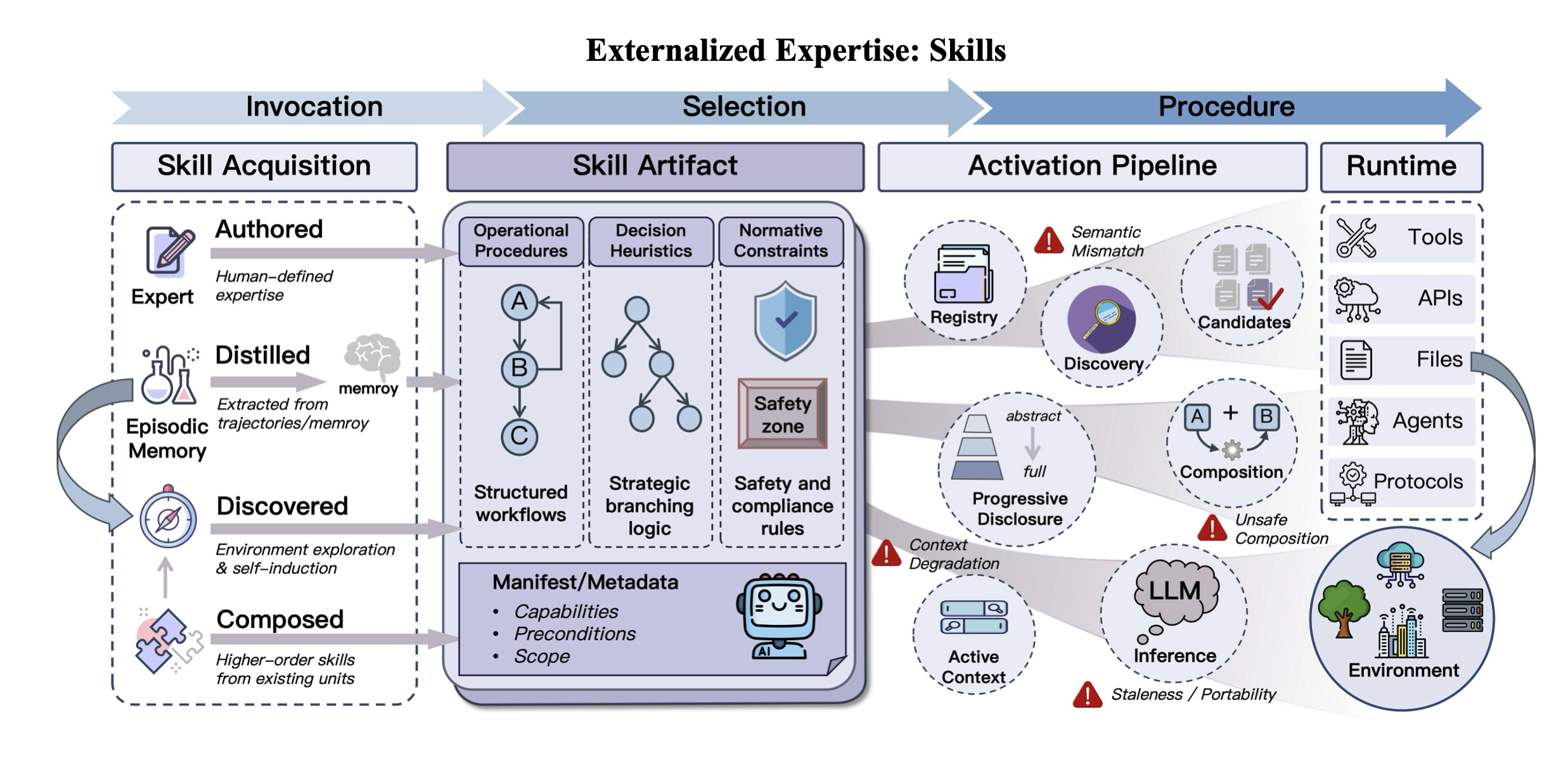
- Memory–skill boundary and promotion: unclear criteria for promoting repeated procedural patterns from memory into reusable skills; need automatic discovery, validation, and packaging pipelines from traces to skill artifacts.
- Skill packaging and versioning: lack of standards for skill interfaces, provenance, semantic versioning, deprecation, and backward compatibility to avoid drift and dependency hell in large skill ecosystems.
- Automatic skill induction and evaluation: need methods to learn skills from execution traces (including credit assignment), certify them (test harnesses, formal specs), and quantify cross-task reusability and domain transfer.
- Runtime skill selection and composition: insufficient policies and learning methods for dynamic skill routing, conflict resolution among overlapping skills, and safe composition with LLM reasoning loops under resource budgets.
- Skill-marketplace dynamics: open questions about discovery, ranking, reputation, pricing, and security of third-party skills; need anti-malware scanning, sandboxing, and attestation for contributed capabilities.
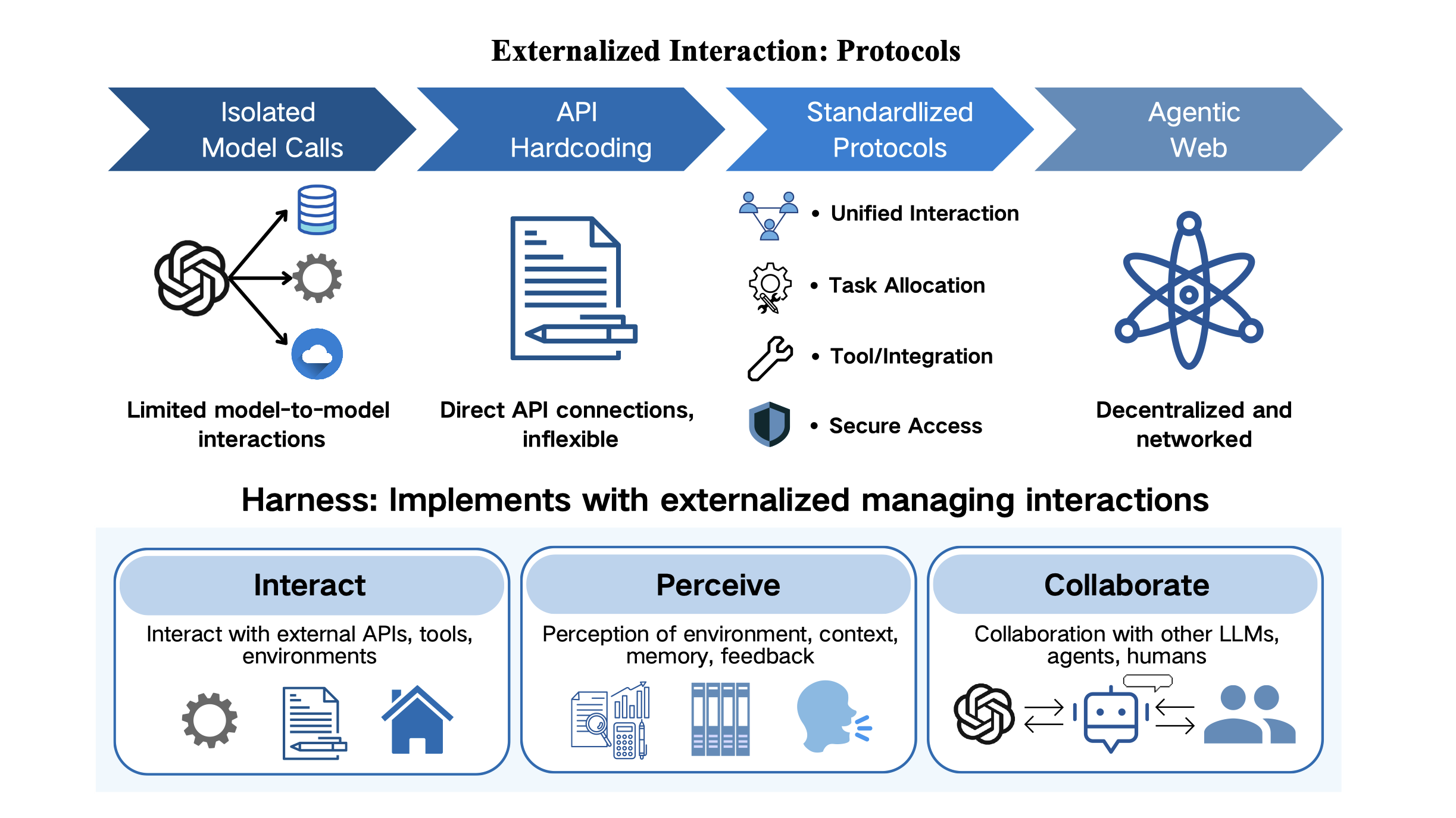
- Protocol standardization and evolution: no convergence on interoperable, versioned schemas (e.g., MCP vs A2A) with clear migration paths, schema evolution policies, and backward compatibility guarantees.
- Formal verification of protocol compliance: lack of specification languages and automated checkers to verify that agents and tools adhere to contracts, including failure modes, timeouts, and permission constraints.
- Secure interaction and identity: unresolved end-to-end authentication, authorization, key management, and least-privilege design for protocolized tool and agent interactions; need audit trails and tamper-evident logs.
- Latency and overhead of protocols: limited understanding of the performance costs introduced by protocol layers and strategies to amortize or batch interactions without sacrificing safety and observability.
- Adversarial and misaligned agents: insufficient models and defenses for protocol-level exploitation (e.g., collusion, data leakage, policy evasion) in open agent–agent ecosystems; need trust and reputation schemes.
- Harness policy learning: absence of data-driven methods (e.g., RL, bandits) to optimize harness control policies for retrieval, skill invocation, and protocol routing under multi-objective constraints (quality, cost, latency, risk).
- Guardrails and governance metrics: no standardized measures of harness-level safety (coverage of checks, false positive/negative rates, recovery effectiveness), nor methods to prove or simulate policy compliance.
- Observability and debugging at scale: lack of common trace schemas, causality-aware logging, and reproducible replays that connect model decisions to memory/skill/protocol events for effective diagnosis.
- Cost and scalability models: missing system-level models that predict and optimize token costs, storage growth, retrieval latency, and energy use across externalization choices; need SLO-aware resource allocation.
- Co-evolution of models and harness: unclear training protocols to make base models “externalization-aware” (e.g., retrieval- and protocol-sensitive pretraining/finetuning) and to jointly optimize with the harness end-to-end.
- Compatibility under model updates: strategies are missing to prevent regressions when the base model changes (interface stability, capability drift) and to migrate skills/memory/protocols safely across versions.
- Multimodal externalization: limited treatment of memory, skills, and protocols for multimodal inputs/outputs (vision, audio, sensor data) and real-time constraints in embodied or interactive settings.
- Cross-lingual/cultural personalization: open questions on representing and retrieving user memory and skills across languages and cultures while maintaining fairness, privacy, and performance parity.
- Legal/IP and provenance: unresolved frameworks for ownership, licensing, and attribution of externalized knowledge and skills (including trace-derived artifacts), and for enforcing usage restrictions.
- Empirical validation of the externalization thesis: paucity of controlled, cross-system studies comparing “weights-only,” “context-heavy,” and “harnessed” agents on identical tasks with matched compute and data to substantiate the claimed reliability gains.
- Failure modes of externalization: underexplored risks where externalization increases brittleness (e.g., dependency chains, stale artifacts, protocol outages); need resilience patterns (circuit breakers, fallbacks, degraded modes).
- Open-world and infinite-horizon evaluation: need benchmarks and methodologies for unbounded tasks with evolving goals and environments, including resumption, recovery from partial failures, and long-term policy stability.
- Security of external stores and channels: missing end-to-end threat models and mitigations (encryption, enclaves, network isolation) for memory stores, skill registries, and protocol buses in adversarial settings.
- Human factors in harness design: insufficient evidence on how developers author, manage, and debug externalized artifacts; need UX studies and tools that reduce cognitive load and improve trust calibration for end users.
These gaps provide a concrete agenda for advancing the science and engineering of externalized LLM agents beyond the current conceptual framework.
Practical Applications
Below is a distilled set of practical, real‑world applications that follow from the paper’s framework of externalization for LLM agents—memory (state across time), skills (procedural expertise), protocols (interaction structure), and the harness that unifies them. Each item lists sectors, likely tools/workflows/products, and key assumptions/dependencies.
Immediate Applications
- Externalized coding assistants with reliable, resumable workflows (software)
- What: Deploy harnessed coding agents that persist project state (files, tests, repo structure), reuse skill docs (coding conventions, PR templates), and call tools via protocols (lint, build, CI) to implement features, run tests, and open PRs reliably.
- Tools/workflows: SWE-Agent/OpenHands-like harnesses; LangGraph/AutoGen orchestration; MCP/A2A-style tool protocols; file-centric state snapshots; CI/CD approvals.
- Assumptions/dependencies: High-quality repo indexing and retrieval; robust sandboxing; comprehensive test suites; version control/CI integration; cost control for long sessions.
- Enterprise knowledge assistants with managed memory tiers (software, enterprise IT)
- What: RAG + hierarchical memory for semantic KBs, episodic logs of prior queries, and personalized memory per team/user to answer questions, draft docs, and follow SOPs.
- Tools/workflows: GraphRAG/MemoryBank-like stores; Mem0/MemOS-style tiering (hot/cold, consolidation, forgetting); SSO/RBAC; approval loops for sensitive actions.
- Assumptions/dependencies: Clean, accessible corpora; retrieval quality; privacy/PII governance; schema/versioning of tools; observability and audit trails.
- Customer support copilots grounded in SOP skills and ticket memory (customer operations)
- What: Encode support playbooks as reusable skills; maintain episodic ticket histories and user preferences; protocolize CRM/knowledge-base access for faster, consistent resolutions.
- Tools/workflows: Skill docs/registries; CRM API schemas under MCP/A2A; reflection logs (e.g., Reflexion-style) for failure recovery; supervisor approval checkpoints.
- Assumptions/dependencies: Curated SOPs; CRM/tool reliability; human-in-the-loop policies; rate limits and privacy controls.
- Deep-research and due-diligence agents with auditable traces (research, legal, finance)
- What: Harnesses that browse, cite, and persist evidence; episodic memory of exploration paths; semantic memory for domain facts; approvals for report generation.
- Tools/workflows: “Deep Research”-style pipelines; browser/tool protocols; citation tracking; snapshotting of state and sources.
- Assumptions/dependencies: Access policies for web/data; anti-hallucination via retrieval; organizational sign-off; time/cost budgets.
- Personalized tutoring and coaching with cross-session memory (education, HR/L&D)
- What: Tutors that store learner goals, misconceptions, and progress as personalized memory; load skills for curricula and formative assessment; protocolize LMS integration.
- Tools/workflows: Personalized memory cards/profiles; skills as lesson plans/problem-solving heuristics; LMS APIs; mastery-based workflows.
- Assumptions/dependencies: Consent and compliance (FERPA/GDPR); bias/quality monitoring; content alignment with standards.
- Clinical and administrative assistants with governed integration (healthcare—non-diagnostic)
- What: Protocolized EHR/appointment interactions; memory of patient preferences and prior encounters; skills encoding clinical workflows/checklists; mandatory approvals.
- Tools/workflows: CDS hooks-like protocols; auditable memory logs; skill checklists; role-based approvals.
- Assumptions/dependencies: HIPAA/PHI compliance; integration with EHR vendors; strict guardrails; medical oversight.
- Robotic process automation driven by skills and protocols (operations, back office)
- What: Replace fragile prompt chains with explicit skills (forms, reconciliation, reporting) and protocolized APIs; memory for state checkpoints and error recovery.
- Tools/workflows: Skill catalogs; API schemas under MCP/A2A; file-centric state snapshots for resumability; fallbacks and retries.
- Assumptions/dependencies: Stable API contracts; exception handling; audit requirements; change management.
- Harness engineering as a product capability (platforms, AI devtools)
- What: Provide turnkey harness components—memory tiering, protocol adapters, evaluators, approval loops, sandboxes, and test harnesses—to accelerate reliable agent deployment.
- Tools/workflows: Observability dashboards; memory orchestration (extraction, consolidation, forgetting); evaluation pipelines; permissioned protocol gateways.
- Assumptions/dependencies: Vendor/tool ecosystem support; org processes for approvals; metrics for harness-level reliability.
- Internal protocol standardization for agent-tool interop (policy/IT governance)
- What: Adopt MCP/A2A-like interaction contracts for discovery, invocation, and permissions across internal tools to reduce glue code and improve auditability.
- Tools/workflows: Protocol registries; schema governance; token/credential policy; cross-team integration playbooks.
- Assumptions/dependencies: Cross-vendor support or internal gateways; security posture; training/devrel for teams.
- Daily-life personal assistants with continuity (consumer)
- What: Assistants that remember preferences, ongoing tasks, and documents; use protocols for home/work apps; store episodic logs for “resume where you left off.”
- Tools/workflows: Personalized memory stores and consent UX; file-centric state on device/cloud; smart-home/service APIs.
- Assumptions/dependencies: Privacy controls; device/app API access; cost-effective local/edge caching; user trust.
Long-Term Applications
- Self-evolving harnesses with adaptive memory and skill promotion (software platforms)
- What: Memory systems that learn retrieval/control policies (RL/MoE), automatically distill episodic traces into semantic knowledge, and promote stable patterns into reusable skills.
- Tools/products: “Skill lifecycle managers”; adaptive memory controllers; automated skill registries with provenance.
- Assumptions/dependencies: Reliable feedback signals; robust evals; safety/rollback; compute/storage budgets.
- Cross-vendor protocol ecosystems and marketplaces (software, platforms)
- What: Widely adopted, secure agent-agent and agent-tool protocols enabling portable skills/tools and interoperable multi-agent workflows across clouds and devices.
- Tools/products: Public skill/tool registries; verification/certification services; protocol gateways.
- Assumptions/dependencies: Standards bodies or de facto convergence; security and sandboxing; economic incentives for adoption.
- Organizational “Agent OS” for state, skills, and governance (enterprise IT)
- What: A managed layer that treats memory as shared, governed state; orchestrates multi-agent workflows; enforces permissions and audit across departments.
- Tools/products: Centralized memory fabric; policy engines; orchestration planners; org-wide observability.
- Assumptions/dependencies: IdM/RBAC maturity; data cataloging/lineage; compliance integration; change management.
- Regulated-domain copilots with formalized workflows (healthcare, finance, legal)
- What: Harnesses that combine protocolized interactions, auditable memory, and validated skills for clinical pathways, compliance checks, and legal drafting with certification regimes.
- Tools/products: Domain-specific skill libraries; attestations and audit frameworks; model-agnostic safety layers.
- Assumptions/dependencies: Regulatory guidance for “agent harnesses”; validation datasets; liability frameworks; rigorous post-deployment monitoring.
- Autonomous, long-horizon project agents (software, R&D, operations)
- What: Agents that run for weeks/months using file-centric state, hierarchical memory, and governed protocols to coordinate sub-agents and resume across interruptions.
- Tools/products: Infinite-horizon planners; state snapshot/versioning services; multi-agent schedulers.
- Assumptions/dependencies: Robust planning/replanning; cost/latency management; organizational trust and oversight.
- Public-sector, transparent harnesses for citizen services (government/policy)
- What: Inspectable, standardized harnesses with persistent memory and strict protocols to deliver auditable citizen-facing services and share skills across agencies.
- Tools/products: Open protocol stacks; portable, redacted memory layers; cross-agency skill registries.
- Assumptions/dependencies: Procurement/IT modernization; privacy/records law alignment; inter-agency interoperability.
- Edge/embedded agent stacks with secure, on-device memory (devices, IoT)
- What: Local harnesses with memory/protocol modules that work offline/intermittently and sync securely, preserving personalized memory in secure enclaves.
- Tools/products: Compressed models; secure memory managers; local protocol brokers.
- Assumptions/dependencies: Hardware acceleration; privacy-preserving sync; model distillation/quantization.
- Harness-level evaluation and certification ecosystems (academia, standards, QA)
- What: Benchmarks and metrics focused on memory retrieval quality, skill adherence, protocol compliance, and governance effectiveness—not just model accuracy.
- Tools/products: Open datasets of execution traces; harness testbeds; certification checklists for deployment readiness.
- Assumptions/dependencies: Community consensus on metrics; data-sharing frameworks; funding for shared infrastructure.
- Policy-driven safety automation at the harness layer (policy, safety engineering)
- What: Policy engines integrated with memory and protocols to enforce approvals, constraints, and audit, with formal verification for critical protocols.
- Tools/products: Policy languages; verifiable protocol compilers; incident response integrations.
- Assumptions/dependencies: Formal methods adoption; mapping organizational policies to machine-readable rules; governance buy-in.
- Collaborative human–AI skill ecosystems (education, enterprise learning)
- What: Social processes and tools for capturing expert procedures as skills, validating them in harnessed environments, and sharing/updating them across teams or communities.
- Tools/products: Skill authoring/validation platforms; reputation and provenance tracking; community registries.
- Assumptions/dependencies: Incentives for contribution; IP/licensing models; quality moderation.
These applications leverage the paper’s central insight: reliable agency depends on shifting burdens from model weights into external memory, skills, and protocols coordinated by a robust harness. Feasibility hinges on retrieval quality, protocol adoption, privacy/security, human-in-the-loop governance, and cost-effective infrastructure.
Glossary
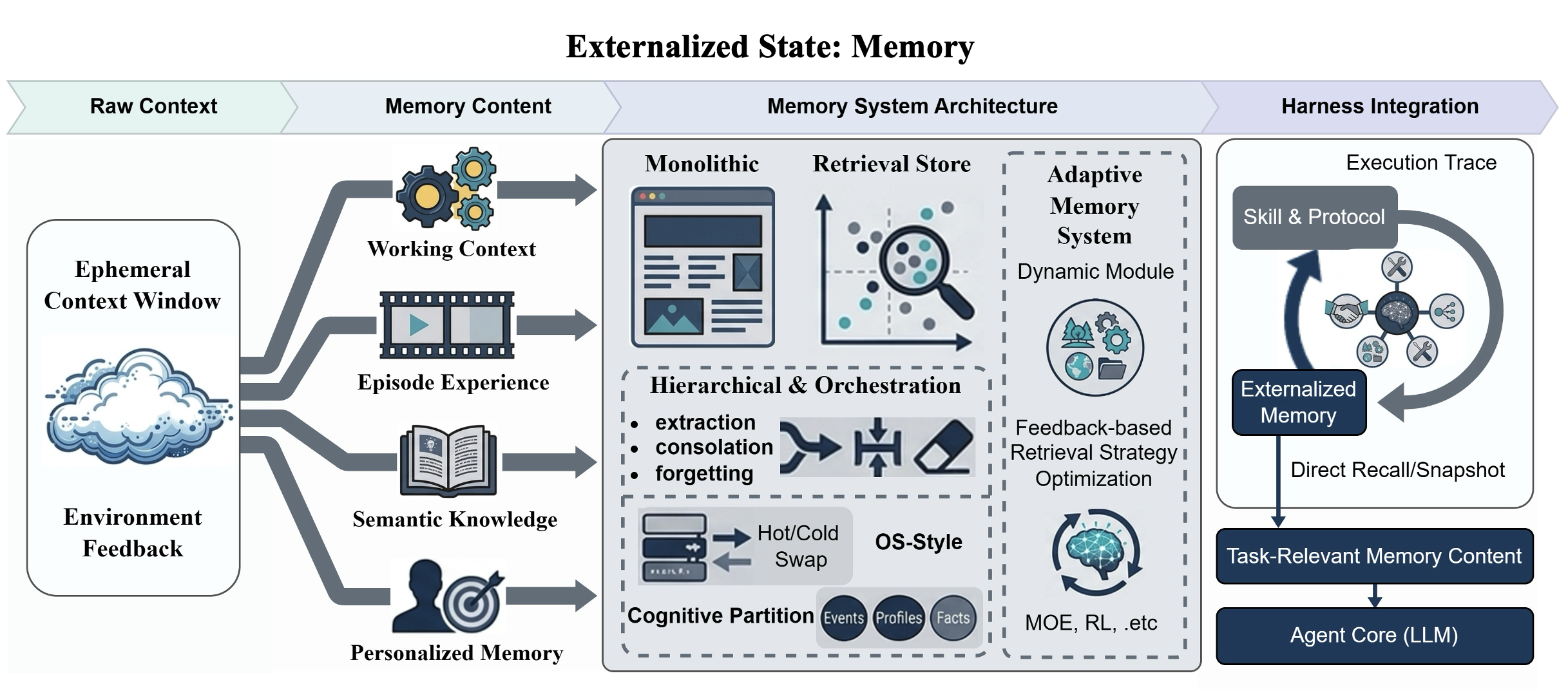
- Adaptive memory systems: Memory architectures that adjust modules, routing, or retrieval policies during operation based on feedback or experience. "Adaptive memory systems go further by making modules, routing decisions, or retrieval strategies responsive to experience."
- Approval loops: Governed checkpoints where an agent’s actions or outputs require explicit approval before proceeding. "evaluators, test harnesses, and approval loops"
- Chain-of-thought: A prompting technique that asks models to generate intermediate reasoning steps to improve problem solving. "chain-of-thought decomposition, and self-consistency traces all changed how the same model performed on the same underlying task"
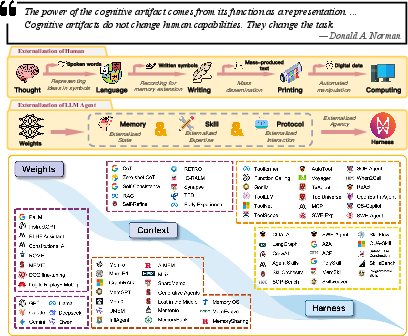
- Cognitive artifacts: External structures or tools that transform the representation of tasks to reduce cognitive burden. "This perspective has a natural theoretical anchor in the idea of cognitive artifacts"
- Context window: The finite token limit of text a LLM can attend to in a single inference. "Its context window is finite and session memory is weak or absent, creating a continuity problem that memory externalization addresses."
- Direct Preference Optimization (DPO): An alignment method that optimizes model outputs directly from preference pairs without a separate reward model. "direct preference optimization further simplified this alignment stage by eliminating the need for a separate reward model"
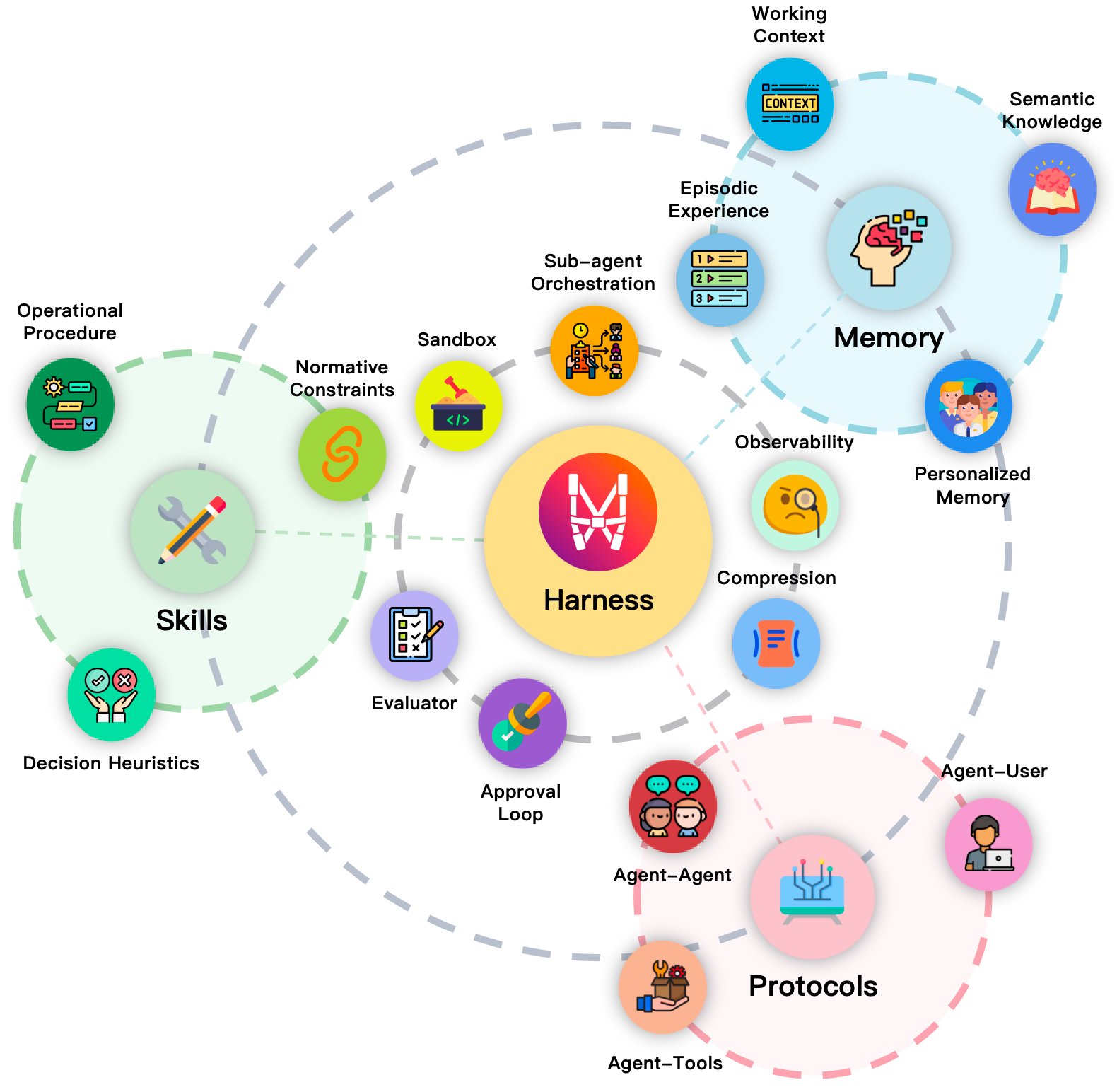
- Episodic experience: Stored records of past runs—decisions, tool calls, outcomes—that can be retrieved as precedents. "Episodic experience records what happened in prior runs: decision points, tool calls, failures, outcomes, and reflections."
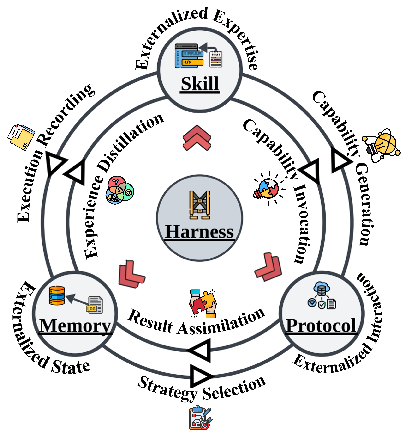
- Externalization: Shifting cognitive burdens from internal model computation into persistent external structures. "This paper reviews that shift through the lens of externalization."
- File-centric state abstraction: Representing task state primarily through the file system so the agent reads curated snapshots rather than long histories. "Frameworks such as InfiAgent propose a file-centric state abstraction, advocating for the file system as the sole authoritative record of task state"
- Harness engineering: The discipline of designing the runtime infrastructure that orchestrates memory, skills, and protocols around the model. "harness engineering serves as the unification layer that coordinates them into governed execution."
- Hierarchical memory and orchestration: A memory approach that manages extraction, consolidation, and retrieval through layered policies and controllers. "Once flat retrieval proves insufficient, systems move to hierarchical memory and orchestration."
- Knowledge editing: Techniques for updating specific facts or behaviors in a model’s parameters without full retraining. "Updating a single fact—say, the current head of state of a country—requires retraining, knowledge editing, or patching through additional alignment layers"
- Lost in the middle phenomenon: A degradation where models attend less to information placed in the middle of long inputs. "the “lost in the middle” phenomenon shows that models attend unevenly across long inputs"
- Machine-readable contracts: Formal interface specifications that structure how agents interact with tools, services, or other agents. "protocols define explicit machine-readable contracts for discovery, invocation, delegation, and permission management."
- Memory systems: Components that persist, organize, and retrieve state across time to support continuity in agent behavior. "Memory systems externalize state across time."
- Mixture-of-Experts (MoE): A model routing technique that selects among expert subnetworks/components for a given input. "uses mixture-of-experts gating to route queries dynamically"
- Non-parametric reinforcement learning: RL methods that adapt policies without modifying model parameters (e.g., learning retrieval policies externally). "MemRL updates retrieval behavior through non-parametric reinforcement learning."
- Observability: Instrumentation and monitoring that make an agent’s internal state and behaviors inspectable for debugging and governance. "constraints, observability, feedback loops, and control points."
- OS-style hot/cold swapping: Managing memory by moving frequently used items to fast-access storage and less-used items to slower tiers. "with extraction, consolidation, forgetting, and OS-style hot/cold swapping"
- Parametric knowledge: Information encoded directly in a model’s weights, as opposed to externally retrieved or provided at runtime. "from parametric knowledge and prompting toward harness-level infrastructure"
- Personalized memory: Persistent, user-specific state capturing preferences, habits, and cross-session context. "Personalized memory tracks stable information about particular users, teams, or environments: preferences, habits, recurring constraints, and prior interactions."
- Protocol standardization: The process of unifying interaction schemas so tools and agents interoperate reliably. "Protocol standardization can improve interoperability while constraining how capabilities are packaged and invoked."
- Protocols: Defined interaction structures that govern discovery, invocation, delegation, and permissions among agents and tools. "Protocols externalize interaction structure."
- ReAct: A prompting/agent pattern that interleaves reasoning traces with tool use actions in a single loop. "ReAct interleaved reasoning traces with tool actions in a single generation loop"
- Representational transformation: Reframing tasks via external structures so that they are easier for the agent to solve (e.g., recall to recognition). "The power of an artifact therefore lies in representational transformation: it restructures the problem so that the agent can solve it more reliably with the competencies it already has"
- Retrieval-augmented generation (RAG): Supplying external documents at query time to inform model outputs without modifying weights. "Retrieval-augmented generation (RAG) introduced a more systematic form of externalization"
- Retrieval store: An external database/index from which relevant memories or documents are fetched into context as needed. "This “context plus retrieval store” pattern underlies most practical memory systems"
- Sandboxing: Executing code or actions in a restricted environment to contain side effects and enforce safety. "Operational elements such as sandboxing, observability, compression, evaluation, approval loops, and sub-agent orchestration mediate the interaction"
- Scaling laws: Empirical relationships linking model size, data, and loss that guide expectations about model performance. "Scaling laws revealed predictable relationships between parameter count, data volume, and loss"
- Self-consistency: A decoding strategy that samples multiple reasoning traces and selects the most consistent answer. "chain-of-thought decomposition, and self-consistency traces all changed how the same model performed"
- Self-Refine: An iterative prompting method where a model critiques and revises its own outputs across turns. "Self-Refine introduced iterative self-critique, demonstrating that models could improve their own outputs through multi-turn prompting loops"
- Skill systems: Repositories of reusable procedures, best practices, and operating guidance that the agent composes rather than generates from scratch. "Skill systems externalize procedural expertise."
- Spreading activation: A graph-based retrieval mechanism that propagates relevance across connected memory nodes. "SYNAPSE uses spreading activation over a unified episodic-semantic graph to recover less local forms of relevance."
- Tool registries: Catalogs of available tools/services with standardized interfaces for discovery and invocation by agents. "external memory stores, tool registries, protocol definitions, sandboxes, sub-agent orchestration, compression pipelines, evaluators, test harnesses, and approval loops"
- Tree of Thoughts: A reasoning framework that explores multiple intermediate solution paths through deliberate search. "Tree of Thoughts generalized chain-of-thought into deliberate search over intermediate reasoning states"
- Working context: The live, rapidly changing state of a current task (files, variables, partial plans) required for immediate continuation. "Working context is the live intermediate state of the current task: open files, temporary variables, active hypotheses, partial plans, and execution checkpoints."
Collections
Sign up for free to add this paper to one or more collections.

