AI Agent Systems: Architectures, Applications, and Evaluation
Abstract: AI agents -- systems that combine foundation models with reasoning, planning, memory, and tool use -- are rapidly becoming a practical interface between natural-language intent and real-world computation. This survey synthesizes the emerging landscape of AI agent architectures across: (i) deliberation and reasoning (e.g., chain-of-thought-style decomposition, self-reflection and verification, and constraint-aware decision making), (ii) planning and control (from reactive policies to hierarchical and multi-step planners), and (iii) tool calling and environment interaction (retrieval, code execution, APIs, and multimodal perception). We organize prior work into a unified taxonomy spanning agent components (policy/LLM core, memory, world models, planners, tool routers, and critics), orchestration patterns (single-agent vs.\ multi-agent; centralized vs.\ decentralized coordination), and deployment settings (offline analysis vs.\ online interactive assistance; safety-critical vs.\ open-ended tasks). We discuss key design trade-offs -- latency vs.\ accuracy, autonomy vs.\ controllability, and capability vs.\ reliability -- and highlight how evaluation is complicated by non-determinism, long-horizon credit assignment, tool and environment variability, and hidden costs such as retries and context growth. Finally, we summarize measurement and benchmarking practices (task suites, human preference and utility metrics, success under constraints, robustness and security) and identify open challenges including verification and guardrails for tool actions, scalable memory and context management, interpretability of agent decisions, and reproducible evaluation under realistic workloads.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language explanation of “AI Agent Systems: Architectures, Applications, and Evaluation”
Overview: What is this paper about?
This paper is a survey, which means it reviews and organizes a lot of recent work to explain the current state of “AI agents.” An AI agent is like a smart helper that can understand what you want in plain language, plan steps to get it done, use apps and tools (like search, code, or web browsers), remember what happened, and double-check its work. The paper shows how these agents are built, how they’re used, and how we should test them to make sure they’re safe and reliable.
Objectives: What questions is the paper trying to answer?
The paper aims to help people make and evaluate AI agents by answering simple but important questions:
- What exactly is an AI agent and what parts does it need to work?
- How do agents think, plan, use tools, and remember things?
- What are the trade-offs, like speed vs accuracy or freedom vs safety?
- Why is testing agents hard, and how can we do it better?
- What big challenges still need solving to make agents trustworthy in real-world tasks?
Methods: How did the authors approach the topic?
Instead of running new experiments, the authors gathered and organized ideas from many existing studies and systems. They:
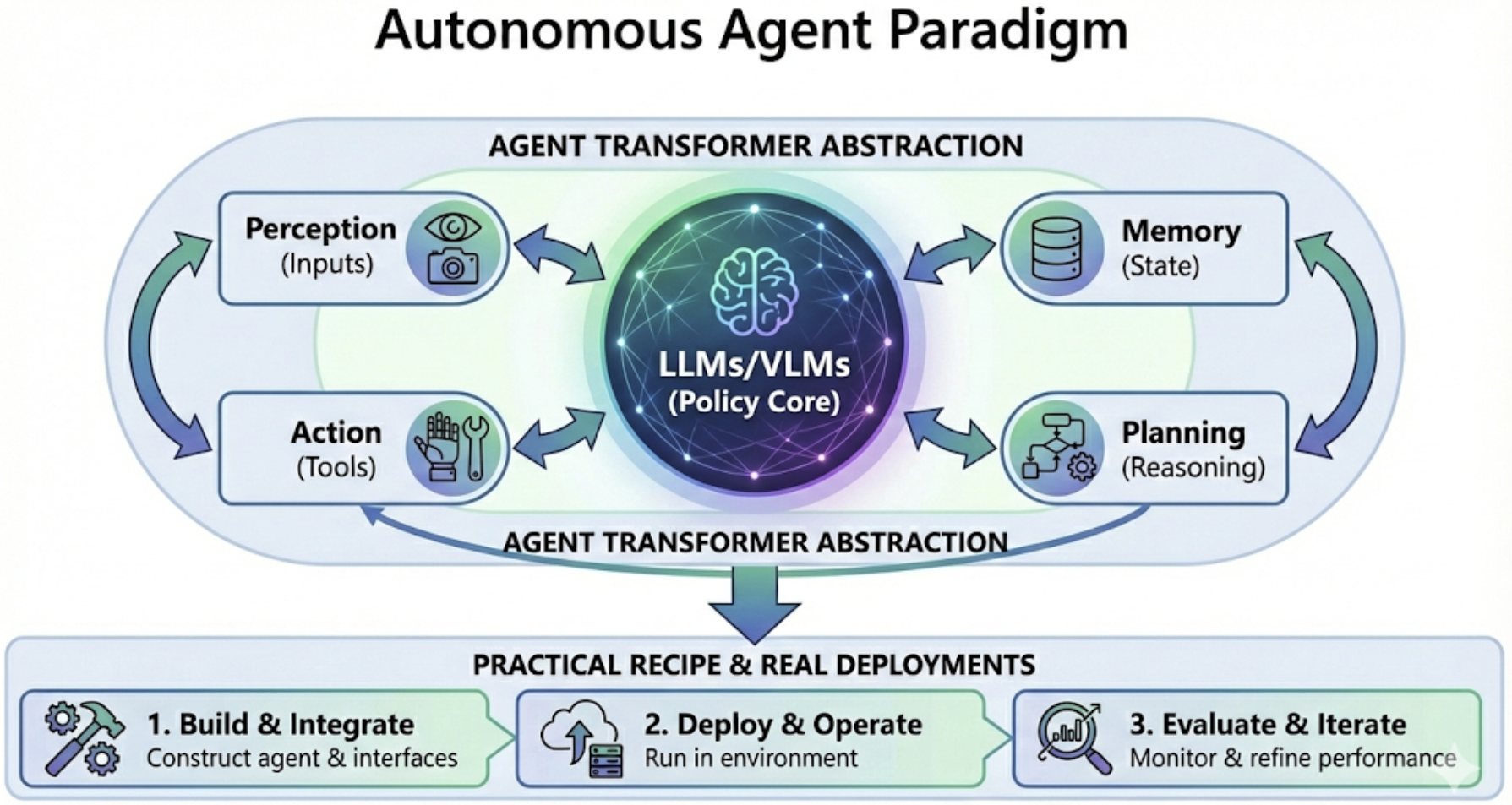
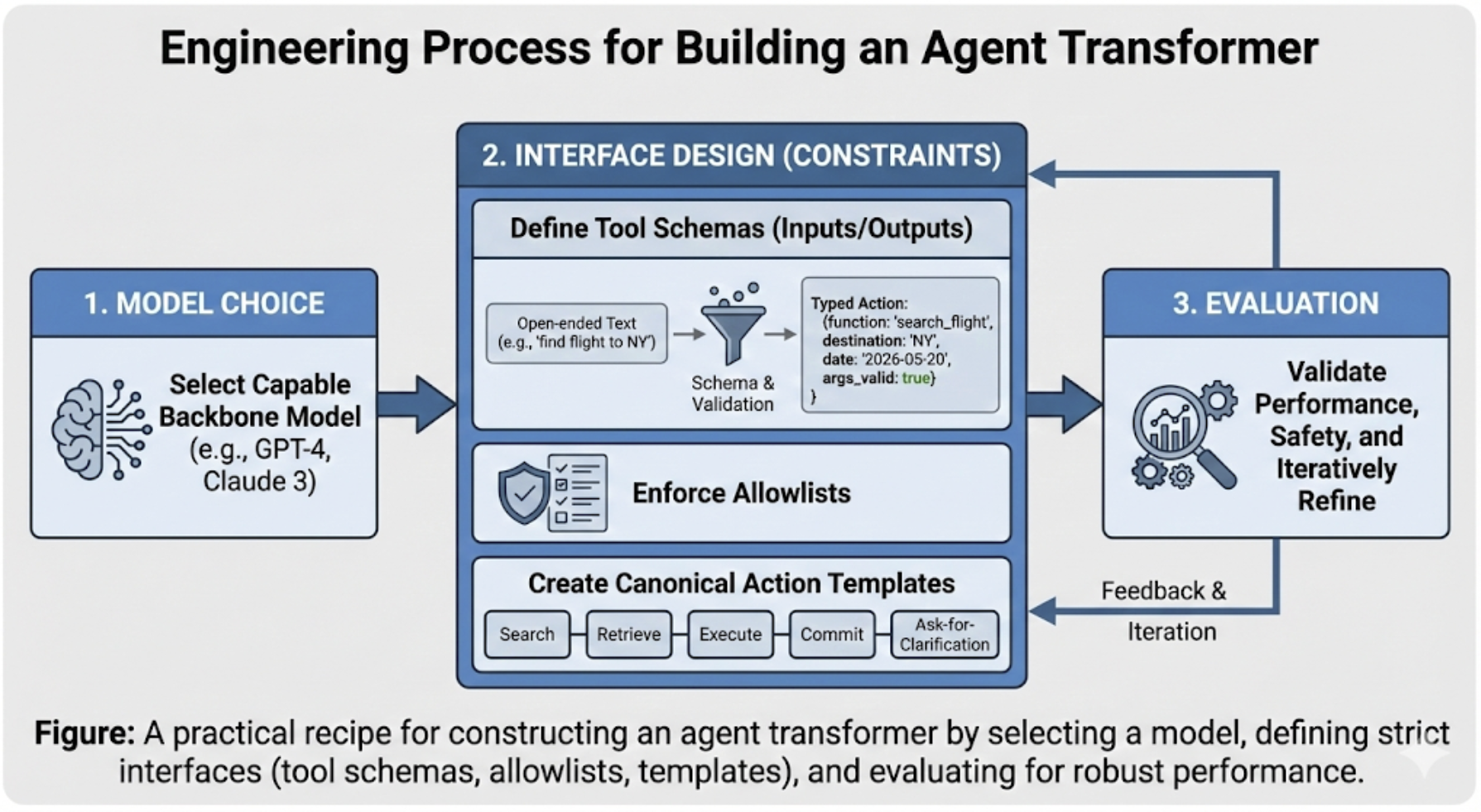
- Created a clear “recipe” for agents, called an “agent transformer,” which is a way to think about an agent’s main parts working together:
- Policy core: the brain (usually an LLM) that makes decisions.
- Tools/APIs: apps the agent can call, like search, code execution, or databases.
- Memory: short-term notes and long-term records the agent keeps.
- Verifiers/critics: checks that make sure actions are safe, correct, and allowed.
- Environment: the place the agent acts (websites, software projects, company systems, or even the physical world with robots).
- Explained the agent’s loop in everyday terms: observe the situation → look up helpful info → propose an action → check if it’s safe and makes sense → do it → update notes and repeat.
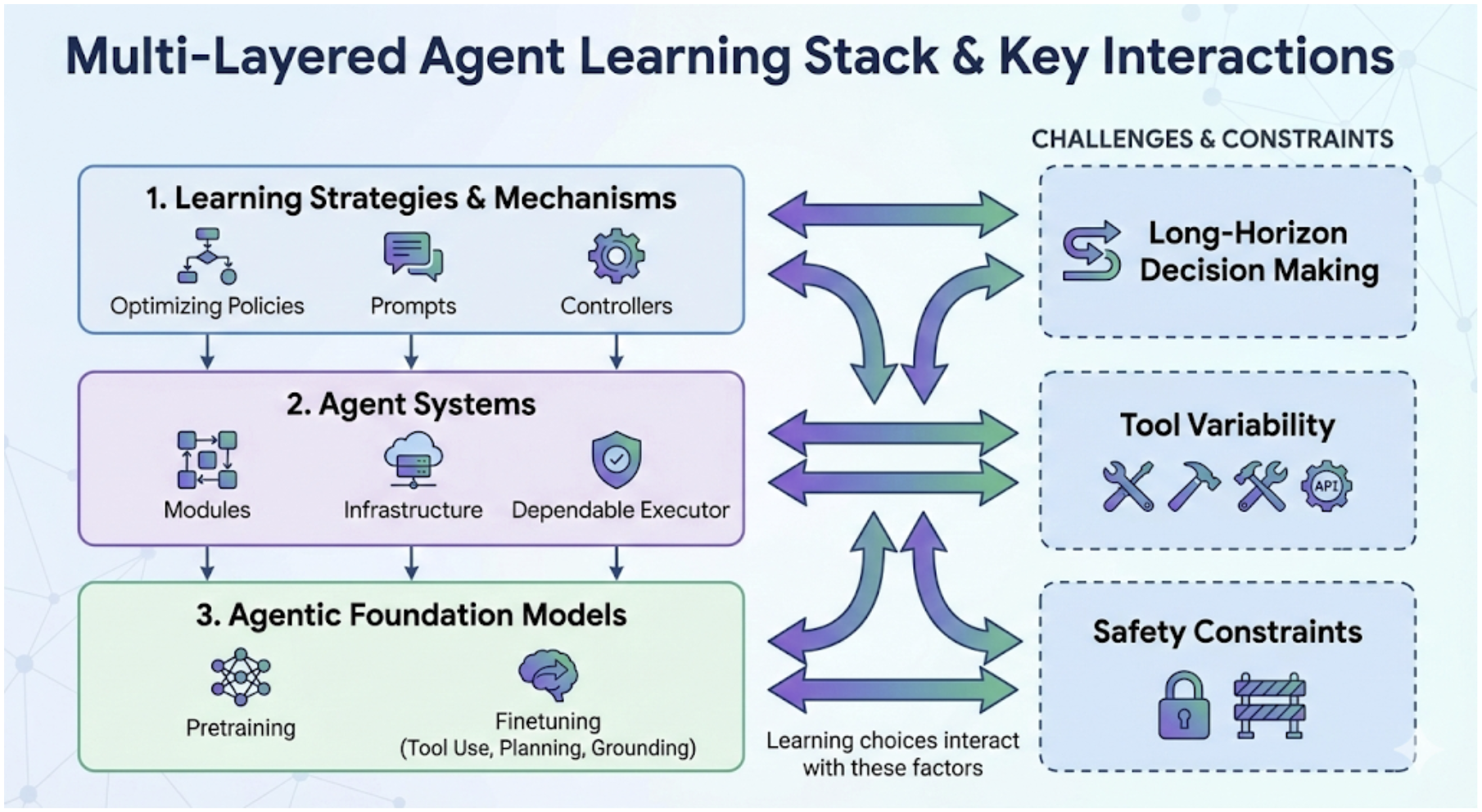
- Reviewed learning strategies in simple language:
- Reinforcement learning (RL): learning by trial, error, and rewards—good for long, multi-step tasks but harder when mistakes are risky.
- Imitation learning (IL): copying good examples—faster to learn safe behavior when there are demos to follow.
- In-context learning: teaching the agent using examples inside the prompt—like giving it a mini manual without retraining.
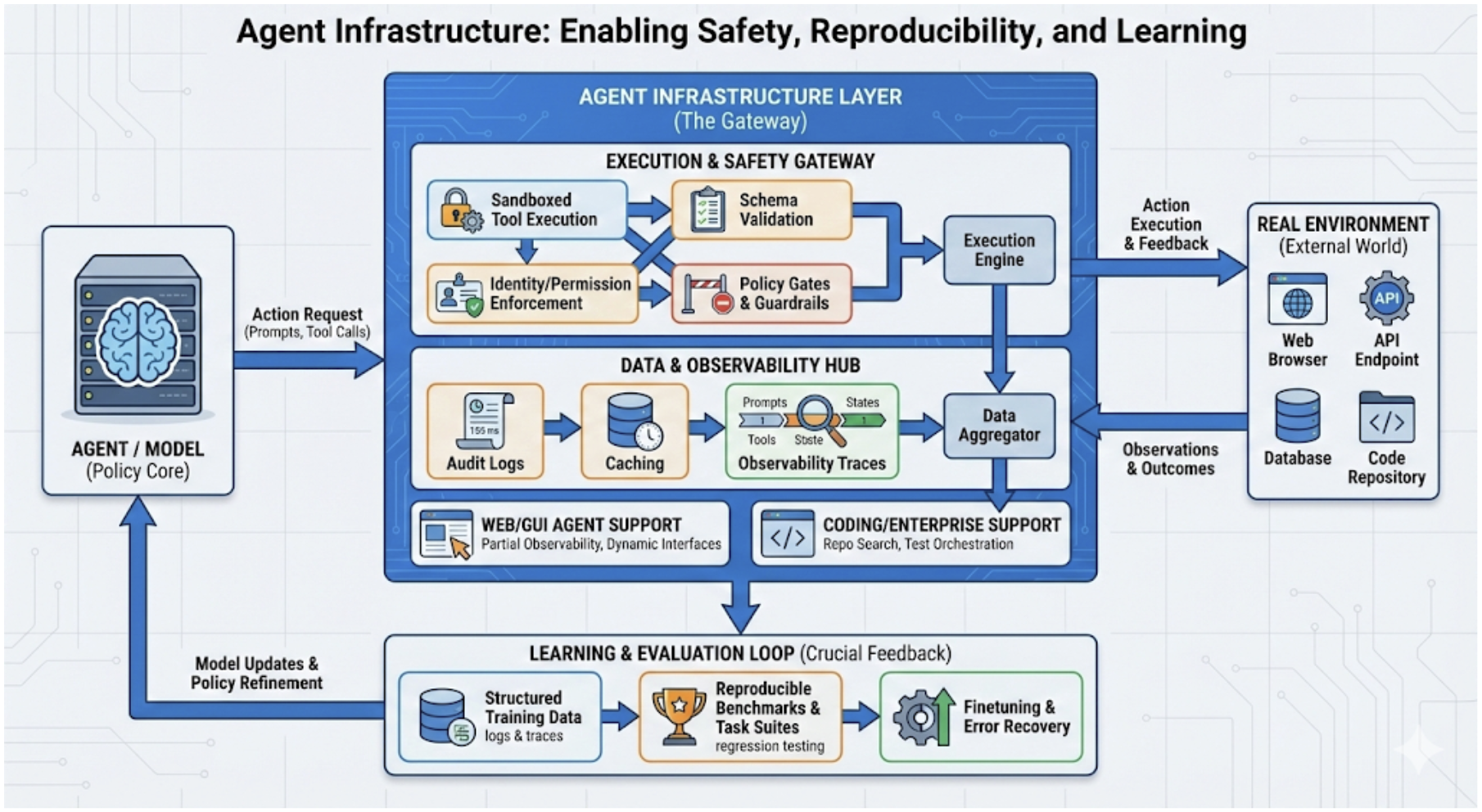
- Covered system engineering and safety, like using strict tool rules, sandboxes for code, permission checks, and detailed logs so actions can be audited.
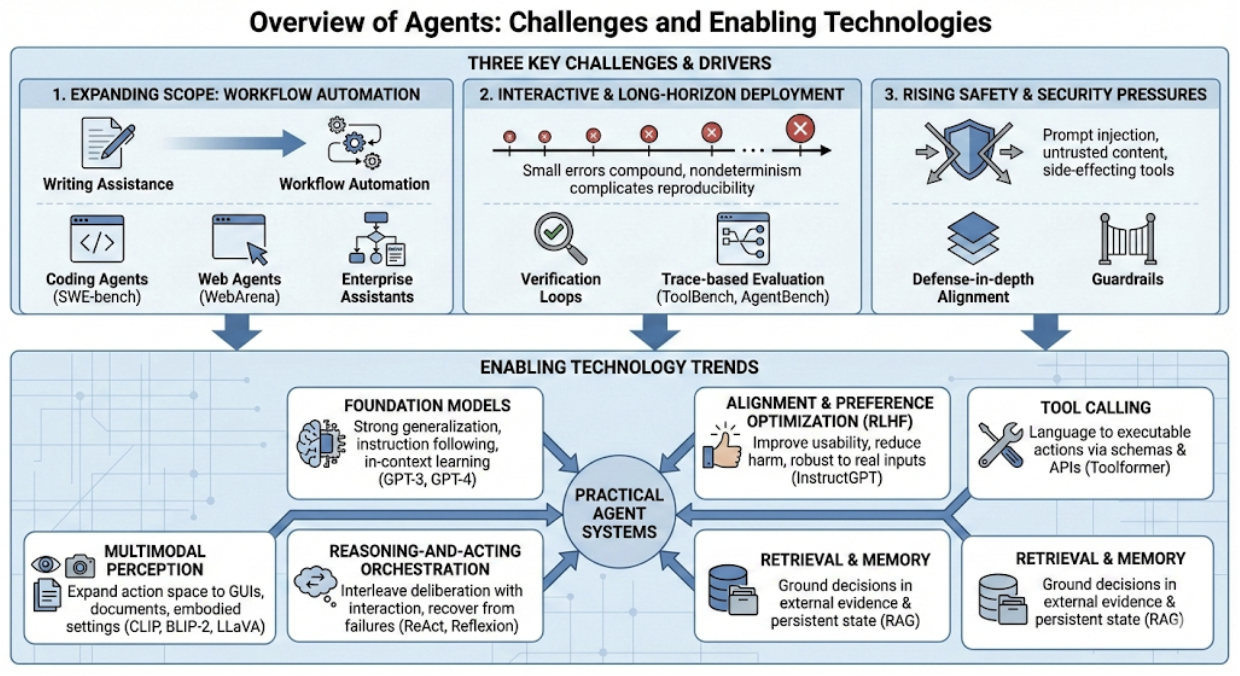
- Summarized how people test agents with realistic benchmarks (WebArena for the web, SWE-bench for code, ToolBench for tools), not just simple question answering.
Main findings: What did they learn and why does it matter?
The survey’s main takeaways include:
- A unified way to describe agents: the “agent transformer” shows how planning, tools, memory, and safety checks fit together into a repeatable loop.
- Practical design patterns:
- Use retrieval (RAG) to ground decisions in real evidence instead of guesses.
- Use tool schemas (clear input/output rules) so actions are structured and can be validated automatically.
- Interleave reasoning and action (ReAct) to produce traceable steps you can inspect and replay.
- Add critics, reflection, or search (like trying multiple plans and picking the best) when the task is hard or risky.
- Separate planning from execution: a planner sets the plan and rules; an executor performs actions under tighter permissions.
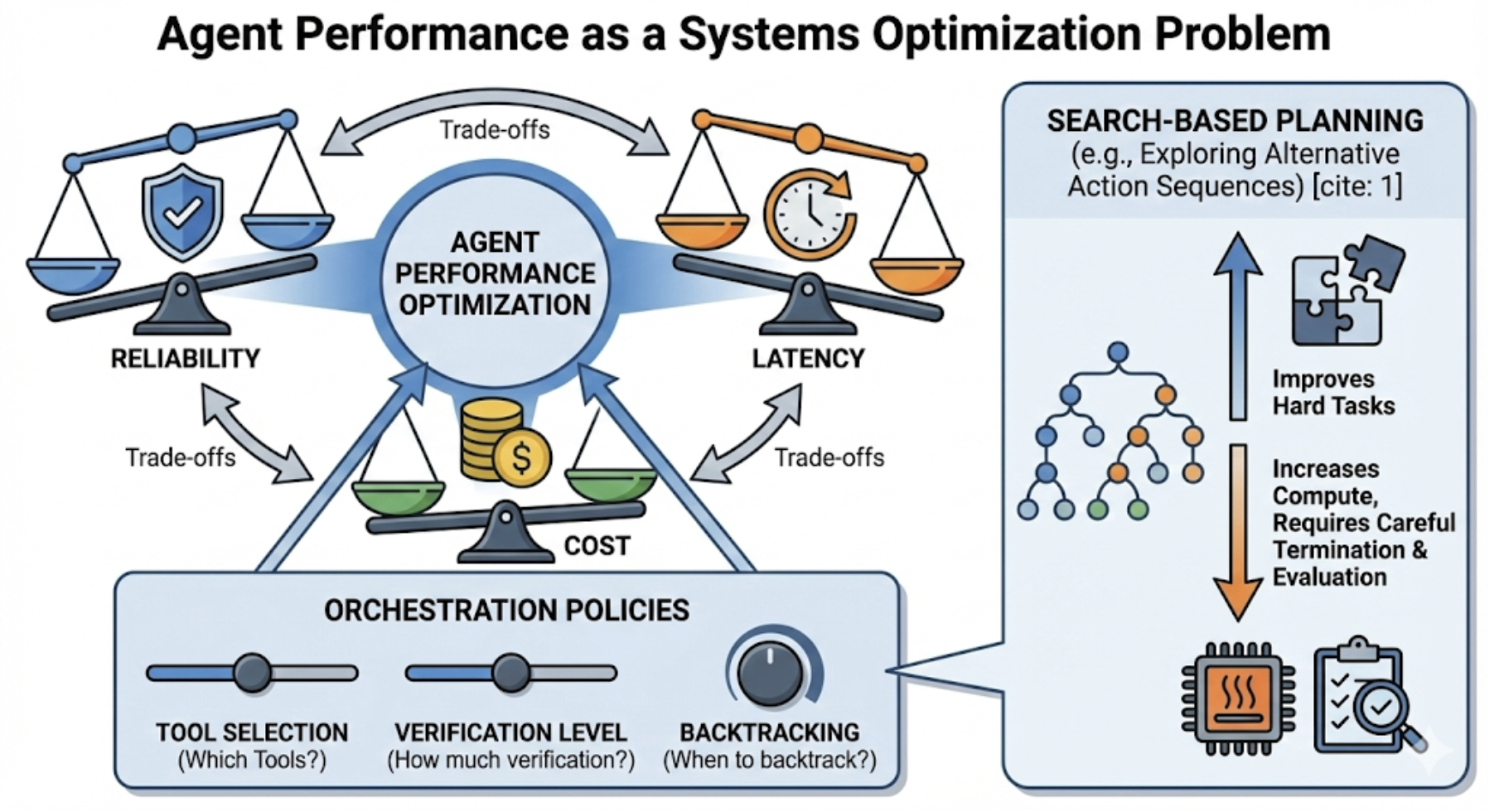
- Honest trade-offs:
- Speed vs accuracy: thinking more and checking more slows the agent but reduces mistakes.
- Autonomy vs control: giving the agent freedom increases capability but needs stronger guardrails.
- Capability vs reliability: being able to do more isn’t helpful if it fails unpredictably.
- Why testing agents is hard:
- Randomness and changing environments mean results can vary.
- Long tasks cause small errors to snowball.
- Tool failures and hidden costs (like retries or growing context) affect real performance.
- Safety challenges:
- Prompt injection (malicious instructions hidden in content) can trick agents.
- Side-effecting tools (like sending emails, making payments, or changing code) need strict checks before running.
Implications: What does this mean for the future?
If builders follow these best practices—strong tool rules, evidence-based decisions, careful verification, and realistic testing—agents will become more reliable and safer in real jobs. That could mean better coding assistants that fix issues end-to-end, web agents that navigate real sites, enterprise helpers that automate multi-step workflows, and even robots that act carefully in the physical world.
However, big challenges remain:
- Verifying tool actions to prevent harm.
- Managing memory so it’s helpful, secure, and doesn’t become messy or too expensive.
- Making agent decisions easier to understand and audit.
- Testing agents in realistic conditions so results are reproducible.
In short, this paper gives a clear map of how to build and judge AI agents today, helping the field move from “chatting” to reliably “doing” things in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues the paper identifies or implies, focusing on what remains missing, uncertain, or unexplored and phrased to be actionable for future research.
- Formal semantics and guarantees for agent transformers: specify operational semantics (risk tiers, validator roles, reversibility), define safety properties, and prove invariants (e.g., no side-effecting actions without prior validation).
- Quantitative characterization of key trade-offs (latency vs. accuracy, autonomy vs. controllability, capability vs. reliability): design controlled experiments and standardized ablation protocols that isolate each axis across diverse tasks.
- Reproducible evaluation under nondeterminism and environment/tool variability: establish protocols for trace completeness, environment snapshots, tool version pinning, deterministic mocks, seed control, and failure taxonomy reporting.
- Standardized cost accounting: define metrics and reporting requirements for hidden costs (retries, self-consistency runs, tree search, context growth, tool latency) and cost–quality curves under explicit budgets.
- End-to-end guardrails for tool actions: develop formal policy-as-code checks, precondition/postcondition validation, static/dynamic analysis of tool effects, and provable gating mechanisms for irreversible operations.
- Robust defenses against prompt injection and retrieval poisoning: create red-teaming suites targeting tool-use manipulation, define trust boundaries for retrieved content, and evaluate multi-layer mitigations (schema hardening, content provenance, filters).
- Scalable memory design: specify architectures and algorithms for long-term/episodic/semantic memory that address summarization drift, contradiction resolution, forgetting policies, privacy controls, and attack surfaces via memory updates.
- Memory consistency and conflict handling: devise mechanisms to detect and resolve inconsistencies between stored state and new observations, with formal reconciliation and provenance tracking.
- Interpretability of agent decisions: build methods to expose, audit, and score intermediate plans, evidence bindings, and tool arguments (e.g., causal/provenance graphs, explanation faithfulness metrics).
- Reliability and calibration of critics/verifiers: benchmark verifier coverage and false-negative rates, establish adversarial tests, and develop meta-verification (verifiers for verifiers) and escalation policies when critic confidence is low.
- Learning signals for tool-rich agents: operationalize offline RL, constrained/safe RL, and preference optimization on logged trajectories; define reward functions aligned with real outcomes, safety violations, and constraint satisfaction.
- Long-horizon credit assignment: propose algorithms and instrumentation for attributing success/failure to specific steps (retrieval, planning, tool calls) and use them to guide finetuning and system-level improvements.
- Data flywheel governance: standardize trace logging schemas (prompts, tools, arguments, outputs, outcomes), define privacy-preserving curation pipelines, and release open, consented datasets for agent learning.
- Tool schema standardization and evolution: design typed action languages, versioning and deprecation policies, cross-tool composition semantics, and backward-compatible interfaces resilient to vendor/API changes.
- Automatic test-time compute allocation: develop controllers that predict uncertainty/risk and decide when to trigger self-consistency, search, or verification, with learning/evaluation of the cost–benefit frontier.
- Multi-agent coordination protocols: formalize role handoffs (planner/executor/reviewer), consensus/resolution strategies under disagreement, messaging schemas, concurrency control, and metrics for coordination overhead vs. reliability gains.
- Benchmark coverage and realism: extend suites to safety-critical, enterprise, and highly variable GUI tasks; measure robustness to layout/tool failures; separate perception vs. planning errors; and report human intervention rates.
- Embodied agent integration: quantify the impact of LLM/VLM latency on real-time control, establish safe handoff interfaces to classical/RL controllers, and develop sim-to-real protocols with failure mode categorization.
- Human-in-the-loop escalation: define thresholds and UI patterns for approvals, measure operator workload and trust calibration, and learn from human corrections to update policies and verifiers.
- Governance, compliance, and auditability: specify identity/permission models, immutable audit logs, policy compliance metrics, and procedures for incident response and post-mortem replay under real workloads.
- Provenance and evidence binding: enforce and evaluate that outputs are trace-backed by verifiable tool results; create standardized “evidence contracts” and penalties for unsupported claims.
- World-modeling for agents: investigate learned environment models (predictive state, uncertainty estimates) that improve planning reliability and enable lookahead without excessive tool calls.
- Generalization and transfer in tool learning: measure how agents adapt to newly added tools, define few-shot tool-use benchmarks, and study cross-domain transfer without retraining.
- Multimodal robustness: evaluate VLM-driven GUI/document perception under real variability (OCR errors, layout shifts) and quantify downstream action reliability and safety impacts.
- Security of memory and tool outputs: design integrity checks to prevent memory poisoning and tool-output tampering; assess resilience to cross-step contamination within long traces.
Practical Applications
Immediate Applications
The following items are deployable today using the architectures, orchestration patterns, and evaluation practices synthesized in the paper.
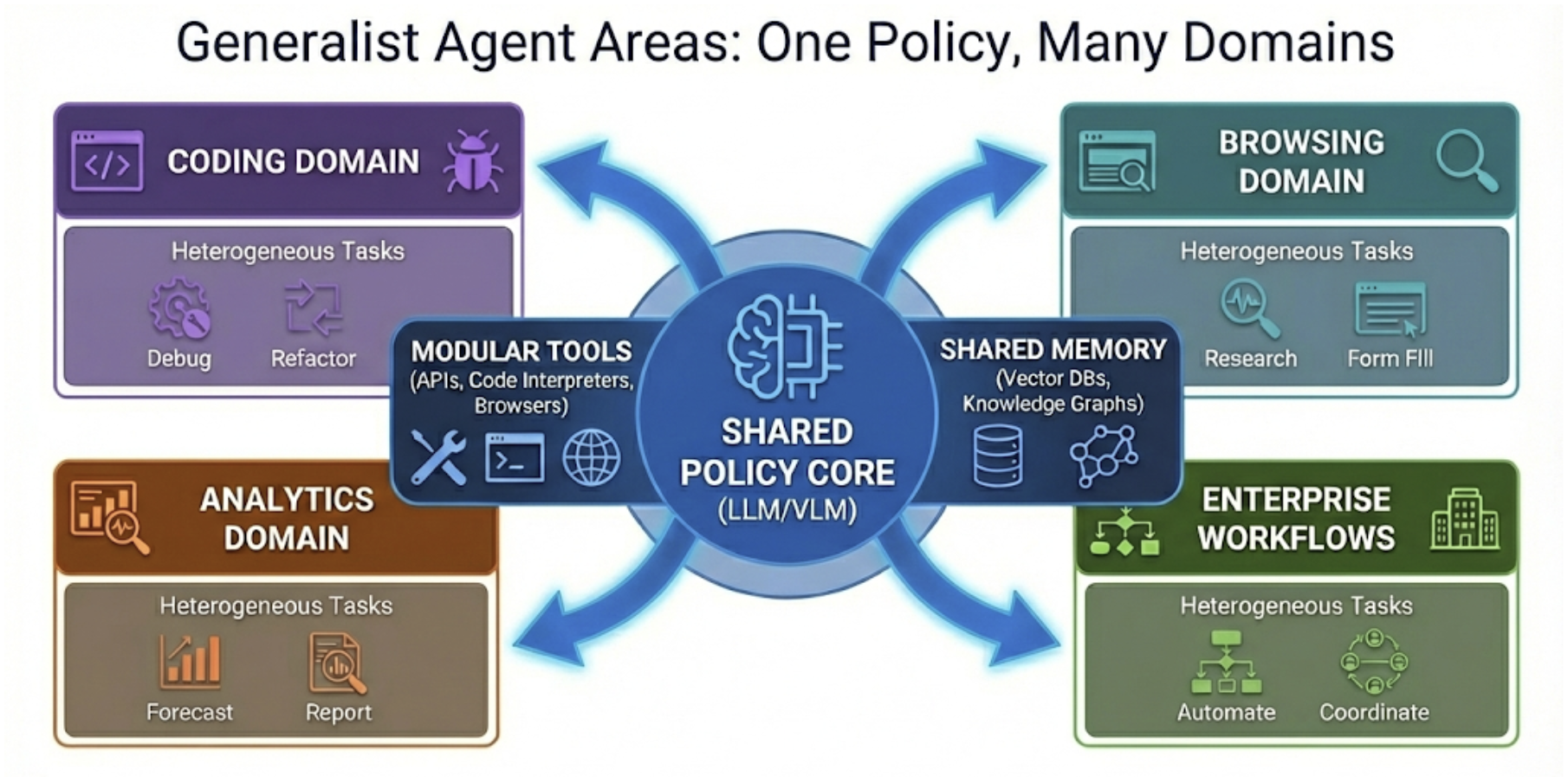
- Enterprise workflow automation across back-office operations
- Sectors: finance, insurance, HR, procurement, logistics
- What: Agents that translate natural-language requests into end-to-end workflows (retrieve→plan→act→verify), e.g., invoice matching, claim validation, vendor onboarding, policy lookups, compliance checks
- Tools/products/workflows: MRKL-style tool routing with strict schemas; ReAct loops for evidence-backed actions; policy-as-code gates for approvals; audit-ready traces
- Assumptions/dependencies: Stable APIs to ERP/CRM systems, permissioning/identity, sandboxed execution for side-effecting tools, retrieval grounded in trusted corpora, human-in-the-loop for high-impact steps
- End-to-end coding assistants for bug triage and PR creation
- Sectors: software, DevOps, SaaS
- What: Agents that search repositories, run tests, propose patches, and open pull requests with verification and rollback
- Tools/products/workflows: Repository search + code execution sandbox; test harness orchestration; planner/executor separation; critic/reviewer agents; SWE-bench-style regression suites
- Assumptions/dependencies: Deterministic CI environment, guardrails around write permissions (branching, approvals), trace logging for reproducibility, cost budgets for multi-step deliberation
- Web RPA enhanced by LLM/VLM agents for browsing and form completion
- Sectors: e-commerce ops, government portals, healthcare admin, travel
- What: Agents that navigate variable sites, extract evidence, fill forms, and verify submissions under dynamic UI changes
- Tools/products/workflows: VLM-based screen understanding (OCR/layout parsing); browser automation APIs; ReAct with tool calls; WebArena-style evaluation to harden against variability
- Assumptions/dependencies: Defense-in-depth against prompt injection from web content, robust locator strategies, sandboxed browsing, rate limiting and error recovery
- Evidence-grounded knowledge assistants (RAG) for regulated workflows
- Sectors: legal, healthcare compliance, finance risk, enterprise IT
- What: Assistants that bind responses to citations and track decision provenance across long contexts
- Tools/products/workflows: Retrieval pipelines with allowlisted sources; memory summarization to control context growth; critics that check claims against tools/evidence
- Assumptions/dependencies: Curated corpora with metadata, access controls, schema validation for tool arguments, versioned prompts and regression tests
- Customer support triage and ticket resolution
- Sectors: SaaS, telecom, retail
- What: Agents that classify cases, retrieve KB articles, draft responses, create/update tickets, and schedule follow-ups
- Tools/products/workflows: MRKL routing to CRM, knowledge-base, messaging APIs; planner/executor split with approval steps; preference-tuned refusal/safety behaviors
- Assumptions/dependencies: API access to CRM/ITSM, alignment guards to avoid unsafe actions, cost-aware orchestration for peak loads, audit logs for compliance
- Data-analysis copilot with plan–execute–verify loops
- Sectors: BI/analytics, research, finance analytics
- What: Notebook-style agents that propose analysis plans, run code in sandboxes, check results, and produce validated reports
- Tools/products/workflows: Code execution tool with resource quotas; tree-search over candidate analyses; self-consistency on key computations
- Assumptions/dependencies: Secure sandboxing, dataset access policies, caching and summarization to manage context growth, clear success criteria
- Multi-agent content workflows (planner–author–reviewer)
- Sectors: marketing, documentation, education
- What: Role-separated agents that generate content, cross-check claims, and enforce style and compliance before publication
- Tools/products/workflows: Planner agent emits structured briefs; author agent produces drafts grounded in retrieval; reviewer agent flags violations using critics/verifiers
- Assumptions/dependencies: Token/latency budgets for coordination, versioned traces for auditability, well-specified review checklists, allowlisted sources
- GUI automation of legacy applications via screen-reading VLMs
- Sectors: banking ops, healthcare admin, government records
- What: Agents that operate desktop apps by interpreting screenshots/forms and performing repetitive tasks
- Tools/products/workflows: VLM perception combined with deterministic UI tools (OCR/layout parsers); behavior-tree fallbacks for timing-sensitive steps
- Assumptions/dependencies: Stable capture interfaces, strict action gating for writes, resilience to layout changes, privacy controls for sensitive screens
- Agent evaluation and observability pipelines
- Sectors: industry engineering, academia
- What: Trace-first infrastructure for reproducible evaluation, regression testing, and continuous improvement across tool-rich tasks
- Tools/products/workflows: Task suites (WebArena, SWE-bench, ToolBench, AgentBench); full trace logging (prompts, tool calls, outcomes); success/cost/latency/safety metrics dashboards
- Assumptions/dependencies: Standardized environments and seeds, storage/PII governance for logs, policy-compliant replay, organization-wide benchmark adoption
- Policy-oriented compliance patterns for agent deployments
- Sectors: regulators, compliance, risk
- What: Operational guardrails such as schema validation, allowlists/denylists for tools, tiered permissions by action risk, evidence-bound decisions
- Tools/products/workflows: Policy-as-code gates integrated in orchestration; human confirmation for irreversible actions; audit trails with provenance
- Assumptions/dependencies: Clear risk taxonomy for actions, integration with identity/permissions, organization-specific compliance requirements, ongoing red-teaming
Long-Term Applications
The following items are promising but require further research, scaling, or development in reliability, safety, memory, or evaluation before broad deployment.
- Autonomous enterprise ops (AIOps) with minimal human supervision
- Sectors: cloud/SRE, fintech ops, large IT estates
- What: Agents that diagnose incidents, apply remediations, deploy changes, and manage rollbacks end-to-end
- Tools/products/workflows: Planner/executor with strong verifiers; constrained RL for safe remediation policies; policy-as-code guardrails; reproducible playbooks learned from traces
- Assumptions/dependencies: High-reliability verification for irreversible actions, robust offline logs for learning, formal safety constraints, organizational acceptance and liability frameworks
- Healthcare administrative and clinical agents
- Sectors: healthcare providers, payers
- What: Agents that handle prior authorization, coding/billing, and eventually decision support with tool actions (orders/referrals)
- Tools/products/workflows: Evidence-grounded RAG over medical corpora; multi-tier approvals; critics for safety violations; integration with EHR APIs
- Assumptions/dependencies: Clinical validation trials, regulatory approval, rigorous alignment to avoid unsafe recommendations, provenance and auditability, de-identification/privacy
- Household and warehouse robotics with language-driven planners
- Sectors: consumer robotics, logistics
- What: Embodied agents that map intents to physical skills (navigate, pick/place, assemble) under safety envelopes
- Tools/products/workflows: Hierarchical LLM/VLM planner; RL/IL controllers; perception-as-tools (mapping, grasp planners); ReAct-style verification before execution
- Assumptions/dependencies: Reliable multimodal perception, sim-to-real transfer, safe RL under constraints, certification and safety standards for human environments
- Autonomous financial agents for trading, compliance, and payments
- Sectors: finance, payments
- What: Agents that execute trades, reconcile accounts, file regulatory reports, and initiate payments with risk-aware gating
- Tools/products/workflows: Typed financial tool schemas; multi-step verification and human confirmation; constrained optimization under policy limits
- Assumptions/dependencies: Strong defenses against manipulation, robust monitoring, legal/regulatory clarity, thorough backtesting under distribution shift
- Scalable, attack-resistant memory systems for long-horizon agents
- Sectors: platform providers, enterprise AI
- What: Episodic/semantic/procedural memory with summarization, consistency checks, and injection-resistant retrieval
- Tools/products/workflows: Memory policies (versioning, decay, conflict resolution); critics verifying claims; secure retrieval pipelines
- Assumptions/dependencies: New memory architectures, evaluation protocols for consistency/robustness, tooling for privacy and governance
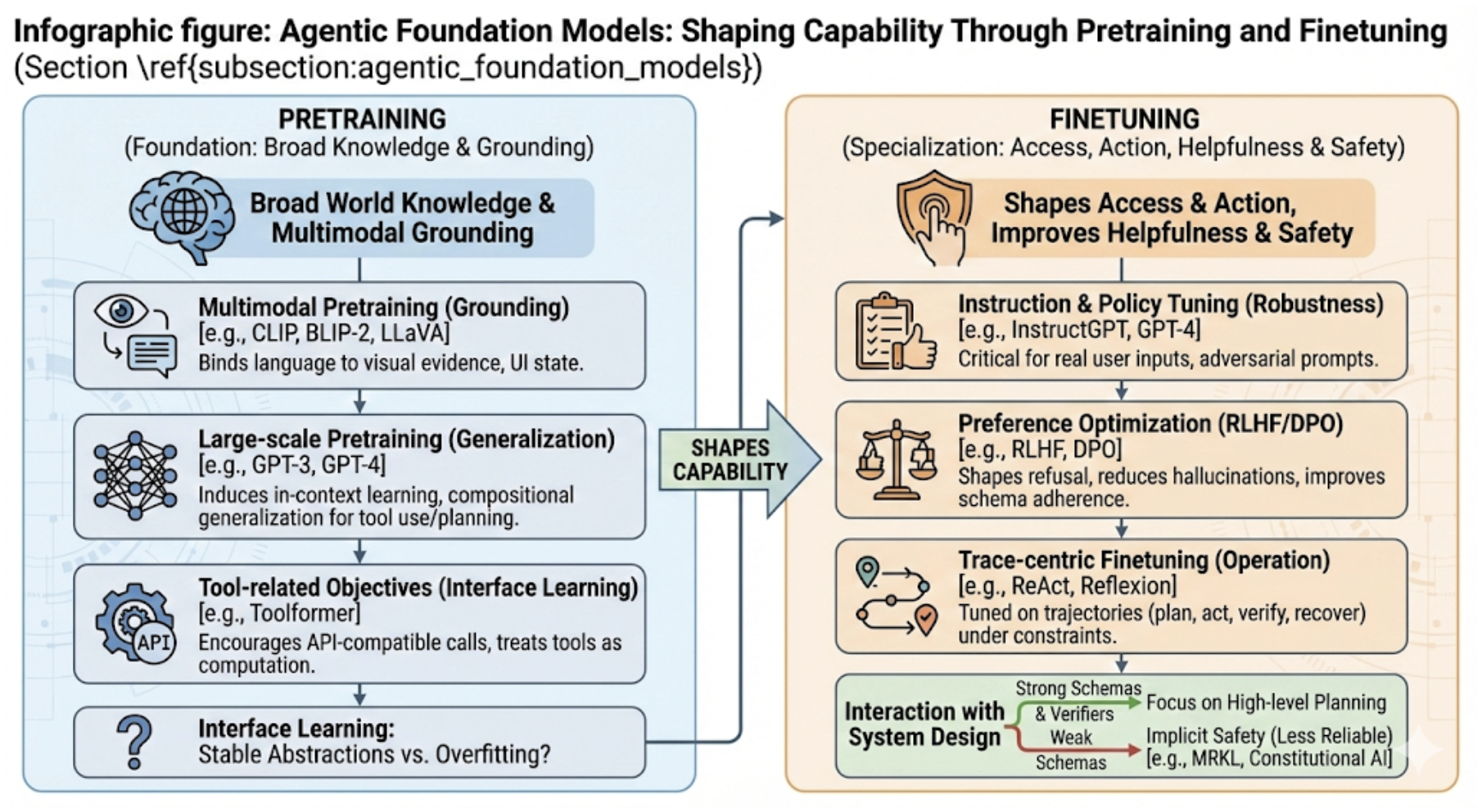
- Agentic foundation models with native tool-use objectives
- Sectors: AI platforms, research labs
- What: Pretraining/finetuning regimes that treat tool calling, planning, and verification as first-class objectives
- Tools/products/workflows: Toolformer-style data generation; trace-centric finetuning; multi-agent curriculum learning; alignment tuned for side-effecting actions
- Assumptions/dependencies: Large-scale high-quality interaction traces, standardized tool schemas, compute budgets for test-time search, robust safety training
- Networked multi-agent organizations (planner–executor–reviewer–auditor ecosystems)
- Sectors: large enterprises, complex programs, research collaborations
- What: Decentralized agent teams with explicit handoffs, cross-checking, and specialization
- Tools/products/workflows: Messaging protocols, artifact-based handoffs (plans, checklists, traces), coordination heuristics to control latency/cost
- Assumptions/dependencies: Scalable coordination, conflict-resolution strategies, cost-aware orchestration, organizational governance and accountability
- Standardized, regulator-endorsed agent evaluation and audit frameworks
- Sectors: policy/regulation, industry consortia, academia
- What: Benchmarks and reporting standards capturing tool-use correctness, safety violations, robustness to variability, and hidden costs
- Tools/products/workflows: Trace completeness requirements, reproducible workloads, red-teaming suites, safety scorecards
- Assumptions/dependencies: Multi-stakeholder consensus, open evaluation infrastructure, sector-specific compliance mappings, continuous updating as tools/environments evolve
- Human–AI teaming patterns for high-risk operations
- Sectors: aviation maintenance, energy operations, healthcare procedures
- What: Protocols where agents propose plans, gather evidence, and assist execution while humans retain approval over irreversible steps
- Tools/products/workflows: Planner/executor separation; graded risk gating; explainability via evidence-bound traces; simulation-based training
- Assumptions/dependencies: Verified interpretability of decisions, human factors research, liability and audit frameworks, domain certification
- Secure, end-to-end defenses against prompt injection and tool-chain attacks
- Sectors: all tool-rich deployments
- What: Defense-in-depth spanning retrieval, tool outputs, schema validation, and action gating beyond text-only moderation
- Tools/products/workflows: Content sanitizers, allowlisted tool routers, verifiers for arguments/results, isolation/sandbox strategies
- Assumptions/dependencies: Mature threat models for agents, standardized security testing, integration with enterprise security posture, continuous monitoring and incident response
These applications leverage the paper’s core insights: make tools and verifiers first-class interfaces, adopt evidence-backed ReAct-style execution, separate planning from execution for controllability, treat evaluation and trace completeness as system requirements, and enforce policy-as-code guardrails for safety and governance.
Glossary
- Agent transformer: A transformer-based agent architecture with explicit interfaces to memory, tools, verifiers, and environment. "We define an agent transformer as a transformer-based policy model embedded in a structured control loop with explicit interfaces to (i) observations from an environment, (ii) memory (short-term working context and long-term state), (iii) tools with typed schemas, and (iv) verifiers/critics that check proposals before side effects occur."
- AgentBench: A benchmark suite for evaluating agents on realistic tool-use and long-horizon tasks. "Evaluate with realistic suites such as WebArena, SWE-bench, ToolBench, and AgentBench to expose tool-use brittleness and reproducibility gaps"
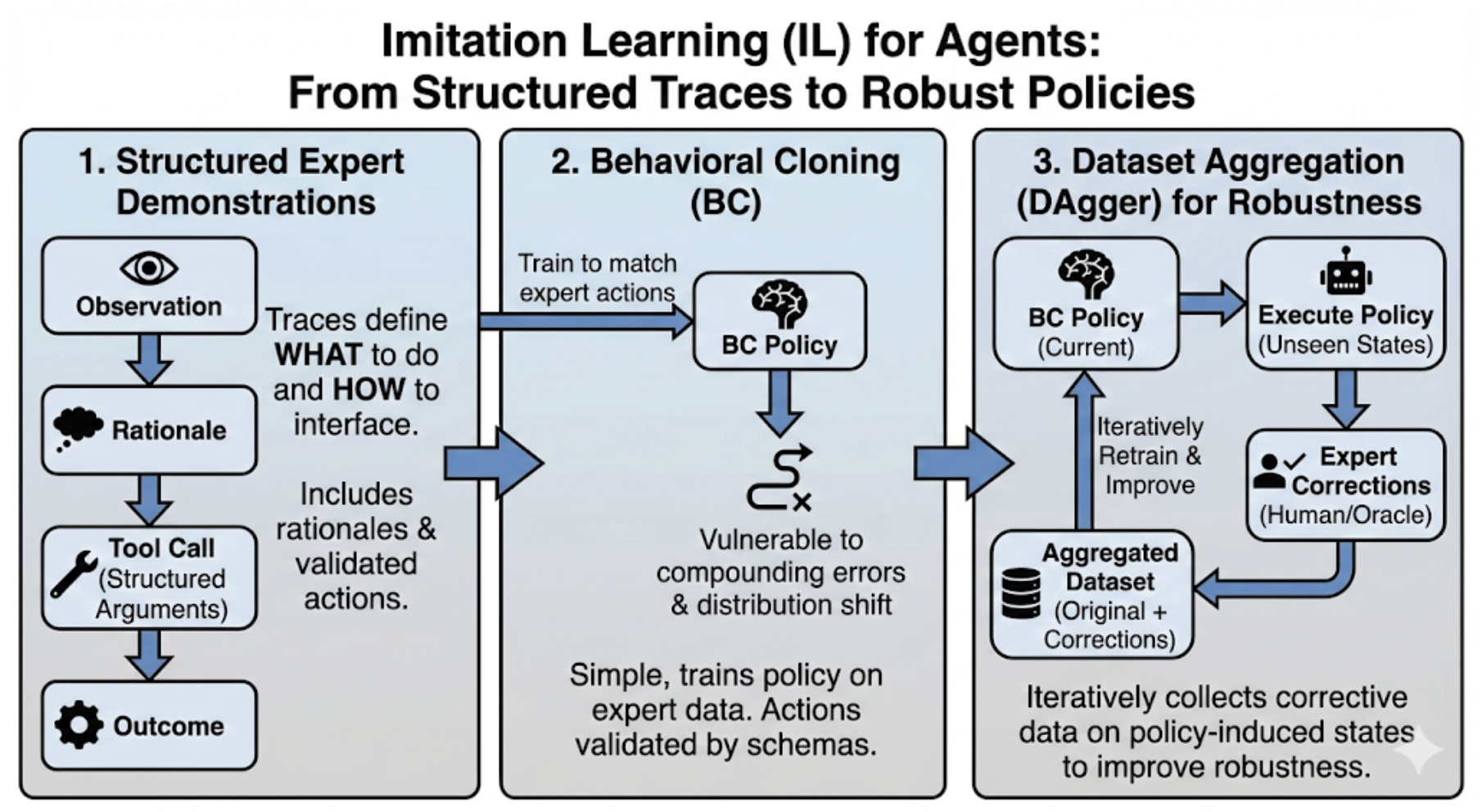
- Behavioral cloning: An imitation learning method that trains a policy to mimic expert actions. "The simplest form, behavioral cloning, trains a policy to match expert actions,"
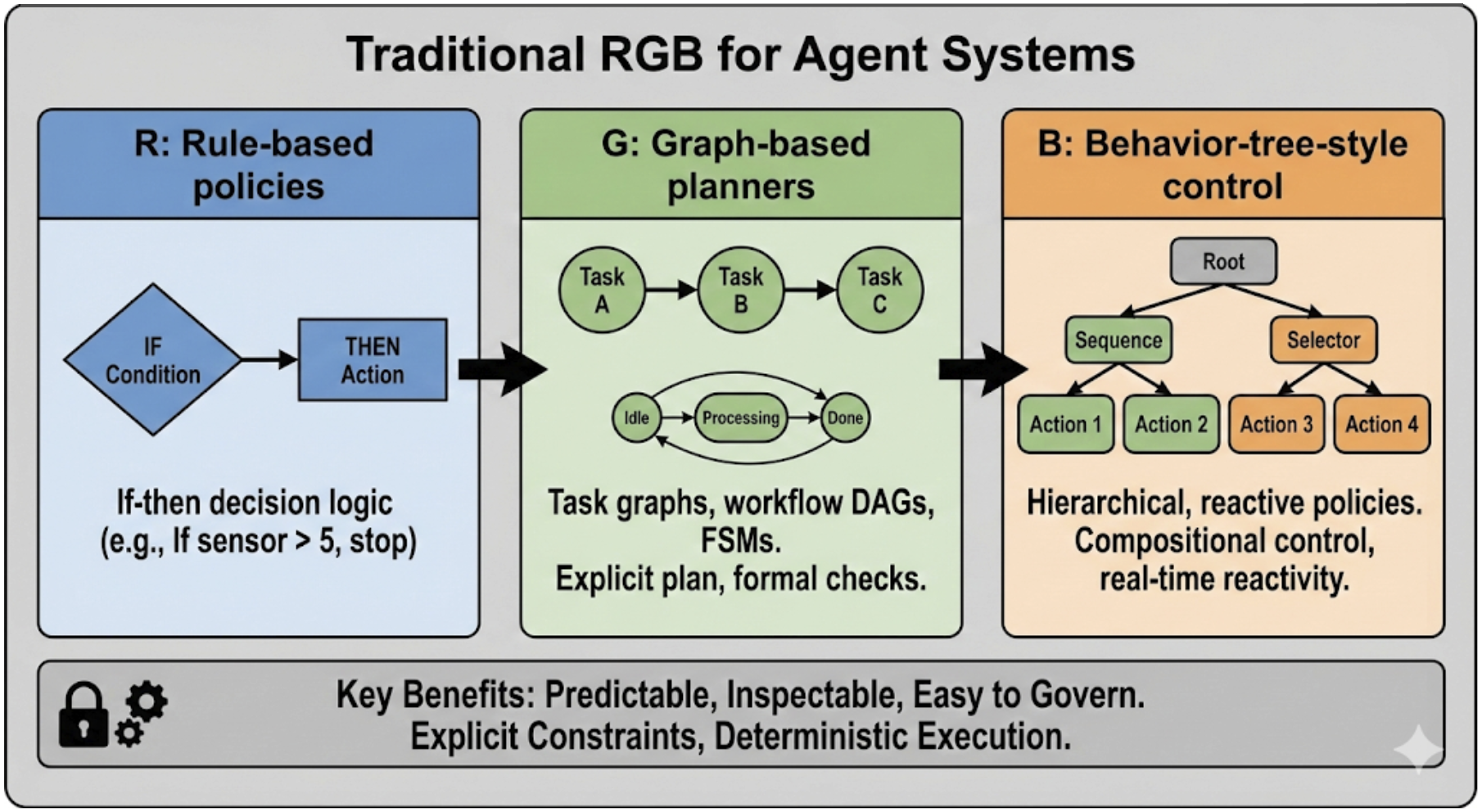
- Behavior trees: Hierarchical, reactive control structures often used in robotics and games. "Behavior trees in particular provide compositional control and real-time reactivity, making them attractive for robotics and games where strict timing and safety envelopes must be enforced"
- Budgeted controller: A control policy that operates under explicit resource limits (time, tokens, tool calls). "the latest framing is to interpret the loop as a risk-aware, budgeted controller:"
- Chain-of-thought prompting: A prompting technique that elicits step-by-step reasoning traces. "Chain-of-thought prompting improves multi-step reasoning and decomposition, which directly translates to better planning and tool selection in agents"
- Constrained/safe RL: Reinforcement learning that enforces safety or constraints during optimization. "This motivates safer and more data-efficient regimes such as offline RL and constrained/safe RL, where the agent is optimized from logged trajectories and policy constraints bound undesirable actions"
- DAgger: A dataset aggregation algorithm that collects corrective demonstrations to mitigate compounding errors. "Dataset aggregation methods such as DAgger address this by iteratively collecting corrective demonstrations on states induced by the learned policy, improving robustness under distribution shift"
- Direct Preference Optimization (DPO): A preference-based alignment method that directly optimizes policies from preference data. "constitution-style policy feedback and direct preference optimization provide alternative alignment mechanisms that are often easier to operationalize"
- GAIL: Generative Adversarial Imitation Learning, which matches expert behavior distributions without explicit rewards. "For example, GAIL learns policies by matching expert behavior distributions without explicitly specifying rewards,"
- Hierarchical RL (options): Reinforcement learning with temporal abstractions (options) to learn reusable sub-policies. "Hierarchical RL (e.g., options) is especially relevant to agents because it provides a learning substrate for reusable skills, temporal abstraction, and planner--controller decompositions"
- Imitation Learning (IL): Learning policies by mimicking expert demonstrations rather than optimizing explicit rewards. "IL provides a pragmatic route to competent behavior when expert demonstrations (human traces, scripted policies, or curated tool trajectories) are available."
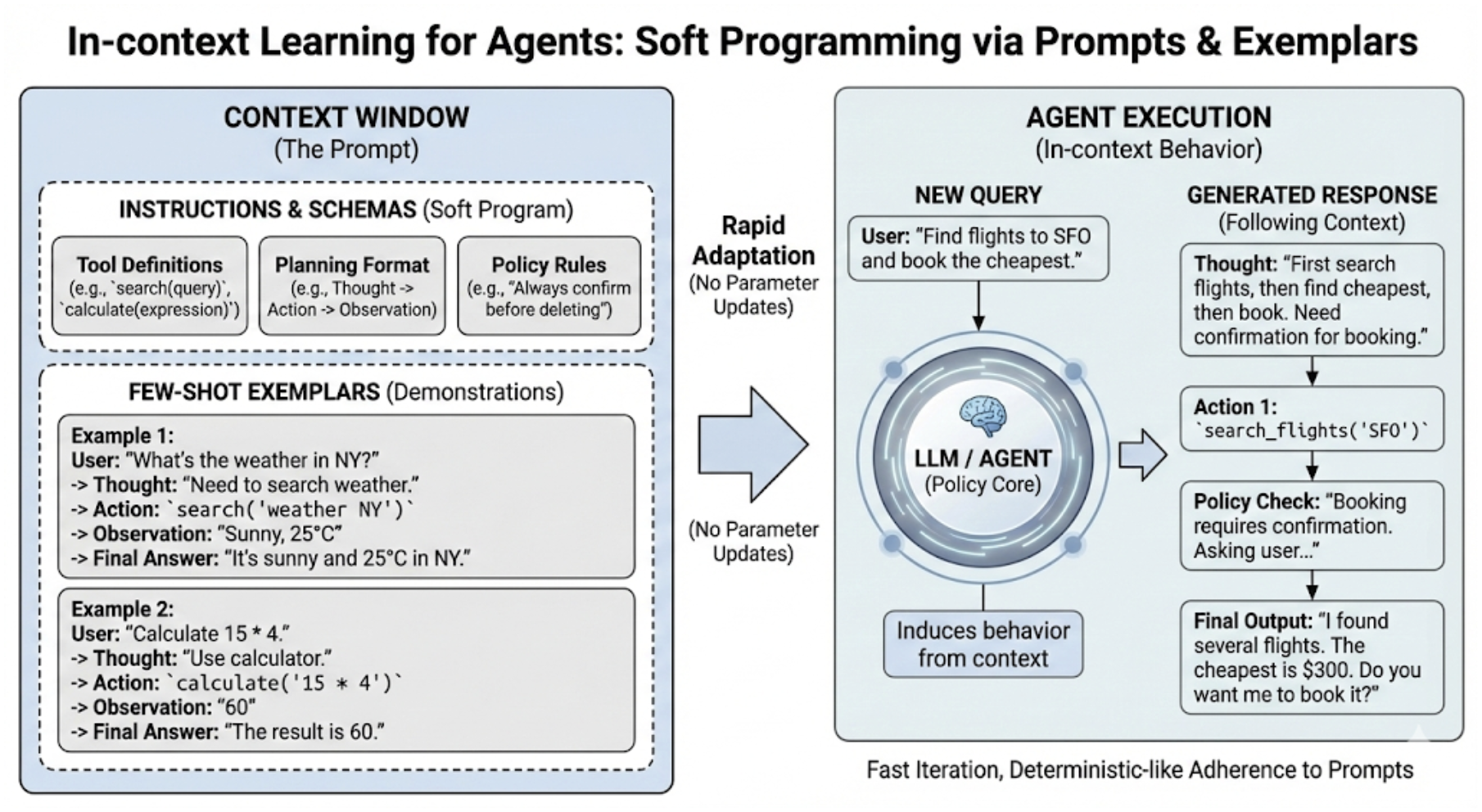
- In-context learning: Adapting behavior from examples in the prompt without parameter updates. "In-context learning enables rapid task adaptation via prompting and exemplars without parameter updates."
- Inverse RL: Inferring an underlying reward function from expert behavior. "Beyond direct imitation, inverse RL and adversarial imitation aim to infer objectives or match expert occupancy measures."
- Long-horizon credit assignment: Attributing outcomes to actions over long sequences, a core evaluation/optimization challenge. "evaluation is complicated by non-determinism, long-horizon credit assignment, tool and environment variability, and hidden costs such as retries and context growth."
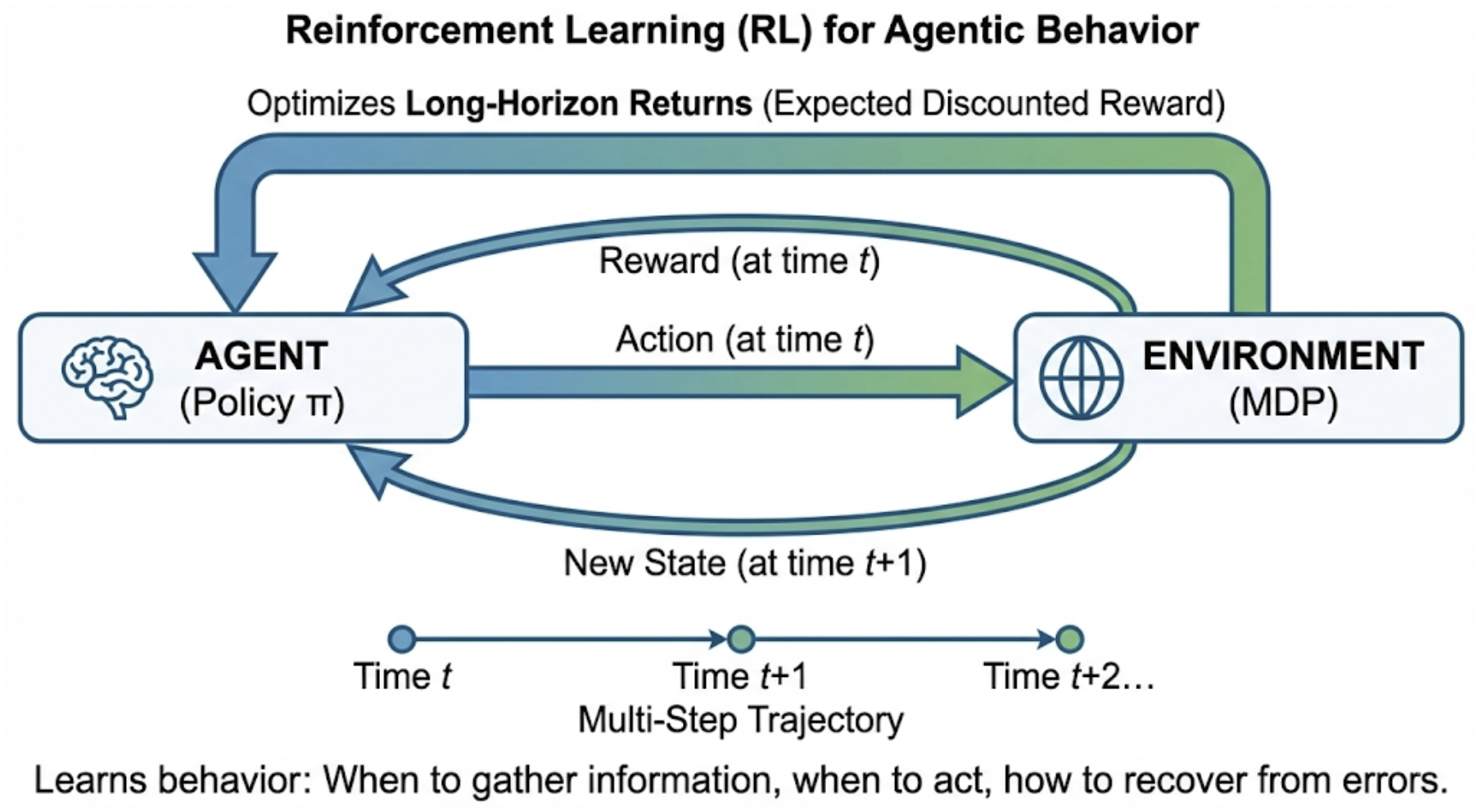
- Markov decision process (MDP): A formal model of sequential decision making with states, actions, transitions, and rewards. "typically formalized as a Markov decision process with a policy that maximizes expected discounted reward"
- MRKL: A modular routing paradigm that delegates to specialized tools via structured interfaces. "MRKL-style systems route tasks to specialized tools, separating language understanding from deterministic components and improving governability"
- Multi-agent frameworks: Systems where multiple agents/roles coordinate via messages to solve tasks. "Finally, multi-agent frameworks implement the same abstraction with multiple policies that communicate via messages, enabling specialization and cross-checking at the cost of coordination complexity"
- Occupancy measures: Distributions over state-action occurrences induced by a policy, often matched in imitation learning. "match expert occupancy measures."
- Offline RL: Reinforcement learning from logged data without online interaction. "This motivates safer and more data-efficient regimes such as offline RL and constrained/safe RL,"
- Operational semantics: The formal meaning of system behavior, here defined by verification rules over actions. "verifiers are not optional add-ons but define the operational semantics of the agent:"
- Policy-as-code: Encoding governance and compliance constraints as executable policies. "policy-as-code gates for compliance."
- Prompt injection: Adversarial instructions embedded in inputs or retrieved text that subvert model behavior. "prompt injection, untrusted retrieved content, and side-effecting tools require defense-in-depth alignment and guardrails beyond the final response"
- ReAct: A reasoning-and-acting loop that alternates deliberation with tool calls, producing evidence-backed traces. "ReAct formalizes the interleaving of reasoning and acting by alternating between deliberation tokens and tool calls, improving grounding and enabling evidence-backed traces"
- Reinforcement Learning (RL): Optimizing policies to maximize expected cumulative reward via interaction. "RL is a natural fit for agentic behavior because it directly optimizes long-horizon returns under interaction, typically formalized as a Markov decision process with a policy that maximizes expected discounted reward"
- Retrieval-augmented generation (RAG): Augmenting generation with external retrieval to ground outputs in evidence. "Retrieval-augmented generation grounds the policy in external evidence by making retrieval a first-class tool and memory operation"
- RLHF: Reinforcement Learning from Human Feedback for aligning model behavior with preferences. "Alignment and preference optimization (e.g., RLHF) improve usability and reduce harmful behavior, making agents more robust under real user inputs"
- Sandboxing: Isolating code or tool execution to limit side effects and improve safety. "Finally, deployment increasingly depends on operational discipline: caching and summarization to control context growth, sandboxing for code and web actions, and policy-as-code gates for compliance."
- Schema validation: Checking that structured tool-call arguments conform to specified schemas before execution. "Similarly, schema validation and sandboxing turn an open-ended 'action' into a constrained interface, improving reliability and reducing catastrophic failures when models hallucinate tool arguments"
- Self-consistency: Sampling multiple reasoning paths and aggregating to improve reliability. "Self-consistency and related sampling-based methods further stabilize in-context behaviors by aggregating multiple reasoning paths,"
- Side-effecting actions: Operations that change external state and thus carry risk if executed incorrectly. "side-effecting actions require stronger constraints than text-only moderation"
- Sim-to-real gap: Performance loss when policies trained or tested in simulation transfer to the real world. "sim-to-real gaps undermine plans that look feasible in simulation"
- Test-time compute scaling: Increasing inference-time deliberation (search, reruns) to boost reliability without retraining. "This connects directly to test-time compute scaling: self-consistency, reranking, backtracking, and tree-style search can improve reliability without retraining,"
- Tool calling: Invoking external tools/APIs from within an agent to perform actions. "Tool calling turns language into executable actions via schemas and APIs"
- Tool routers: Components that route tasks/queries to appropriate tools based on intent and schema. "We organize prior work into a unified taxonomy spanning agent components (policy/LLM core, memory, world models, planners, tool routers, and critics),"
- Toolformer: A method for self-supervised tool-use learning from synthetic traces. "Tool-use learning can be bootstrapped from synthetic traces or self-supervision (Toolformer-style), reducing the need for brittle prompt engineering"
- Trace completeness: Capturing full trajectories (prompts, tool calls, outputs) to enable auditing and reproducibility. "nondeterminism (sampling, tool variability) makes evaluation and debugging difficult without standardized protocols and trace completeness"
- Tree-of-Thoughts: A search-based deliberation method that explores multiple reasoning/action branches. "Search-based deliberation (Tree-of-Thoughts) treats planning as exploring a space of action candidates, trading compute for reliability"
- Verbal reinforcement: Using natural-language feedback/reflection as a learning signal. "Variants such as ``verbal reinforcement'' (reflection-based self-improvement) adapt the idea of learning from feedback to language-agent loops"
- Verifiers/critics: Modules that check proposed actions for correctness, safety, or policy compliance. "verifiers/critics that check proposals before side effects occur."
- Vision-LLMs (VLMs): Models that jointly process images and text to ground decisions in visual context. "Vision-LLMs (VLMs) extend this paradigm by grounding decisions in images, screens, documents, and embodied observations."
- WebArena: An interactive web benchmark for evaluating web agents. "Evaluate with realistic suites such as WebArena, SWE-bench, ToolBench, and AgentBench to expose tool-use brittleness and reproducibility gaps"
- World models: Internal models of environment dynamics used to predict and plan. "agent components (policy/LLM core, memory, world models, planners, tool routers, and critics)"
Collections
Sign up for free to add this paper to one or more collections.