- The paper introduces a VAE-based latent space formulation for high-frequency action chunking, reducing jerk and quantization errors critical for precise robotic control.
- It demonstrates that training in latent space with the Reuse-then-Refine (RTR) strategy significantly enhances trajectory continuity and minimizes execution stalls.
- Empirical evaluations in tasks like cucumber peeling and whiteboard writing confirm improved safety, higher success rates, and lower latency compared to discrete methods.
Learning High-Frequency Continuous Action Chunks in Latent Space: A Technical Analysis
Problem Statement and Motivation
This work systematically addresses a core limitation in current action chunking strategies for high-frequency robotic control. While action chunking—employed in recent vision--language--action (VLA) policies such as OpenVLA-OFT and PI0.5—has yielded substantial improvements at moderate action frequencies, the efficacy of chunked policies deteriorates at high frequencies (e.g., 60Hz). Empirical evidence reveals that policies trained directly in high-frequency action space suffer from poor trajectory smoothness and low precision, particularly due to the high temporal information density and increased quantization errors inherent to discretization—most notably in token-based methods (Figure 1, Figure 2). Contrastingly, high-frequency actions are compelling for robotic manipulation as they preserve fine-grained motion details and maintain stable actuator velocities, mitigating the stop-and-go artifacts induced by low-frequency command horizons (Figure 3).
To surmount the learning complexity of high-frequency control, the study shifts from direct action space regression to a VAE-based latent space formulation. High-frequency action chunks are temporally compressed via a VAE encoder, mapping chunked commands onto a regularized latent manifold. Policy learning is then performed in this low-dimensional, continuous latent space, followed by reconstruction of action chunks through the VAE decoder. This formulation regularizes local motion patterns and suppresses high-frequency noise while preserving trajectory fidelity (Figure 4, Figure 1).
Quantitative trajectory and action deviation metrics unequivocally support this strategy: for representative policies (Diffusion Policy, OpenVLA-OFT, PI0.5), training in the latent space decreases jerk and deviation metrics across all axes, and considerably reduces quantization-induced artifacts present in discrete policies (see Table 1 of the original paper; also demonstrated in Figure 1 and Figure 5).
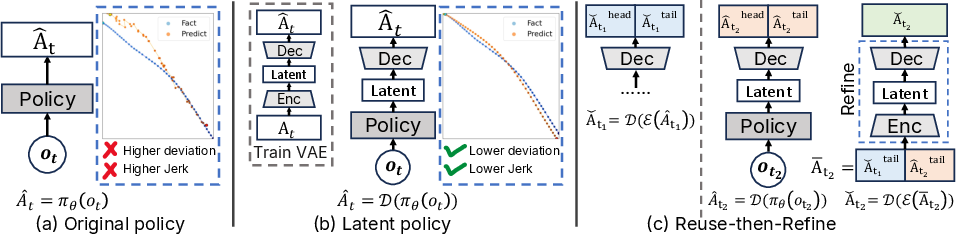
Figure 4: Policy architectures for high-frequency control in the action space (Original), latent space (Latent), and with Reuse-then-Refine (RTR) for robust asynchronous inference.
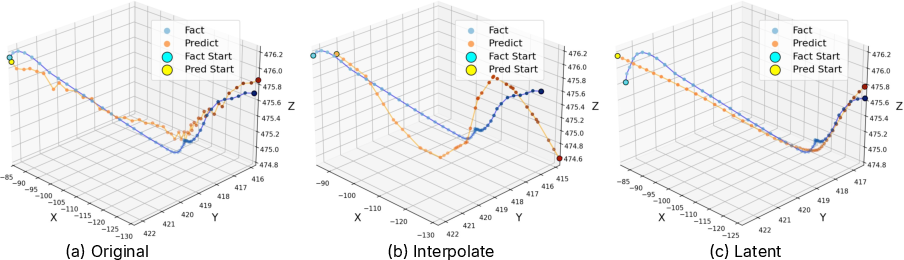
Figure 1: Action-chunk trajectory comparisons, highlighting reduced jitter and increased precision for latent-space training.
Real-Time Execution and Asynchronous Inference
Conventional chunked action policies, when deployed for long-horizon tasks, require frequent inference updates. Asynchronous inference, a prevalent scheme to hide policy evaluation latency, typically introduces discontinuities at chunk boundaries—leading to rollbacks and jerk due to temporal misalignment (Figure 6). The authors introduce a training-free strategy, Reuse-then-Refine (RTR), which concatenates recently executed (overlapping) and newly generated actions, then refines this joint segment using the pre-trained VAE. RTR ensures continuity and smooth transitions between successive action chunks, especially under asynchronous execution.
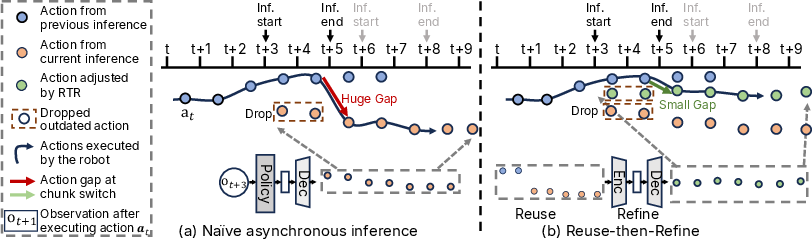
Figure 6: RTR improves chunk-level boundary continuity by refining concatenated legacy and new action segments, suppressing discontinuities under asynchronous execution.
Numerical evaluations demonstrate that RTR reduces jerk, overlap discrepancy, and boundary gap in all policies compared to baseline and alternative inpainting-based chunk continuity methods such as RT-C (Table 3 of the paper, Figure 7). This continuity translates into fewer execution stalls and lower end-to-end task latency on real hardware.

Figure 7: Online whiteboard writing under asynchronous control shows marked reduction in jerk and rollbacks with RTR, outperforming RT-C in continuity.
Empirical Evaluation
Three real-world contact-rich tasks—cucumber peeling, vase wiping, and whiteboard writing—validate the superior trajectory smoothness, chunk-to-chunk continuity, and task efficacy of the latent-space and RTR strategy across model backbones (Diffusion Policy, OpenVLA-OFT, PI0.5). Notably:
Analysis of Latent Compression and Alternative Methods
A series of ablations investigates the choice of latent model (VAE vs. VQ-VAE) and temporal downsampling ratio, observing that moderate compression with VAE yields optimal smoothness/precision trade-offs (Figure 8–10). Excessive compression degrades both, and vector quantization (VQ-VAE) is consistently outperformed by continuous latent spaces in terms of deviation.
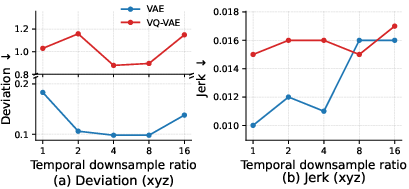
Figure 8: Deviation and jerk as a function of downsampling ratio for VAE and VQ-VAE.
Moreover, the policy demonstrates robust generalization in simulation (LIBERO benchmarks) and negligible VAE reconstruction error (sub-millimeter), indicating that the latent bottleneck does not undermine long-horizon planning or nuanced manipulation.
Theoretical and Practical Implications
The latent-space chunking strategy, jointly with RTR, constitutes a robust execution paradigm for real-world high-frequency control. The approach delivers measurable improvements in smoothness, continuity, and safety-aligned adherence—benefits crucial for autonomous manipulation in contact-rich settings and safe operation under actuator constraints. The findings highlight that representation learning, coupled with inference-time continuity, is essential for scaling VLA-based robotics to real-time and safety-critical applications.
From a theoretical standpoint, the combination of VAE-based temporal abstraction and inference-time refinement represents a co-design of representation and system execution, enabling efficient approximation of complex, densely-sampled trajectories without succumbing to high-frequency error propagation or excessive quantization artifacts.
Future Directions
Scalability to even higher frequencies (90Hz, 120Hz) and other sensor modalities, as well as generalization of RTR-like strategies to other policy representations (e.g., pure action space), constitute natural extensions. Further research might also consider hierarchical compression schemes or Gated Latent Models to adaptively balance compression with control granularity, and alternative latent regularization objectives tailored to dynamic system smoothness.
Conclusion
The study demonstrates that high-frequency action chunking, when shifted into a regularized latent space and paired with inference-time continuity refinement (RTR), tangibly advances the state-of-the-art in real-world robotic policy execution. The framework robustly mitigates precision loss, jerk, and execution stalls endemic to previous action chunk policies, establishing actionable design principles for temporally-dense learning and deployment of VLA-based robotic systems.
