- The paper's main contribution is introducing a parameter-free AAC method that dynamically selects action chunk sizes based on prediction entropy.
- The methodology leverages Gaussian and categorical entropy to adjust chunk lengths, resulting in improved success rates across simulation and real-world tasks.
- Experimental results show enhanced precision, safety, and task generality, with significant improvements on RoboCasa and LIBERO benchmarks.
Adaptive Action Chunking at Inference-time for Vision-Language-Action Models
Introduction
This work addresses the challenge of balancing reactivity and consistency in Vision-Language-Action (VLA) models for robotic manipulation. Prior art predominantly uses fixed inference-time action chunk sizes, leading to significant task-dependent performance variability and hindering policy generality and scalability. The authors identify and rigorously quantify the strong dependence of standard generalist VLA performance (e.g., GR00T N1.5) on the choice of chunk size, especially across diverse manipulation suites. As a corrective, they introduce Adaptive Action Chunking (AAC): a parameter-free test-time algorithm that adaptively sets the chunk size per timestep—without any retraining or model modification—based on the entropy of action predictions.
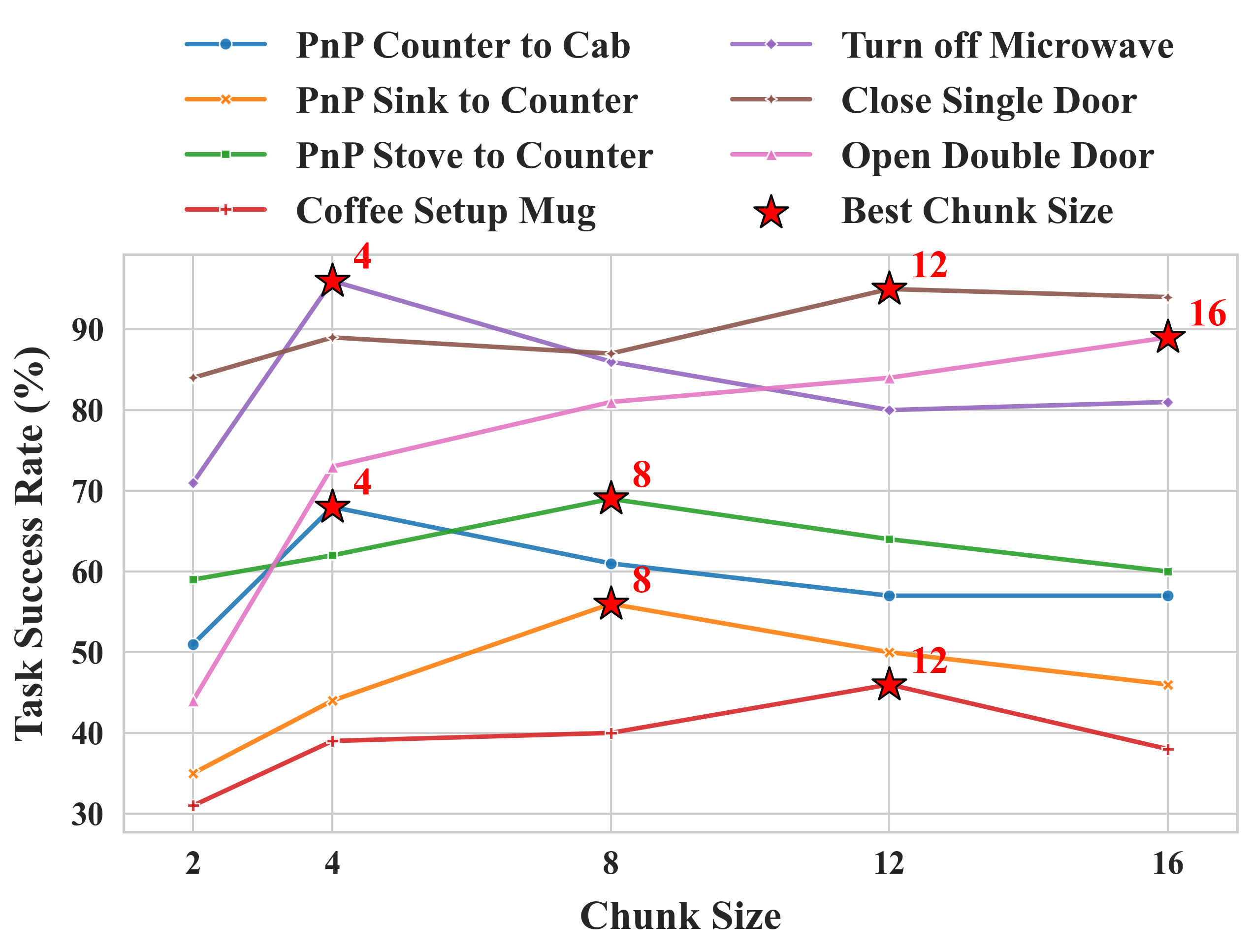
Figure 1: Effects of action chunk sizes—success rates on RoboCasa Kitchen tasks are highly contingent on the chunk size, motivating adaptive chunk selection.
AAC leverages the intuition that high-entropy action predictions reflect uncertainty, recommending short, frequent replanning, while low-entropy, high-certainty phases benefit from longer horizon execution for efficient and consistent trajectories. The method is validated via extensive empirical evaluation on RoboCasa and LIBERO (simulation) as well as multiple real-world tasks.
Methodology
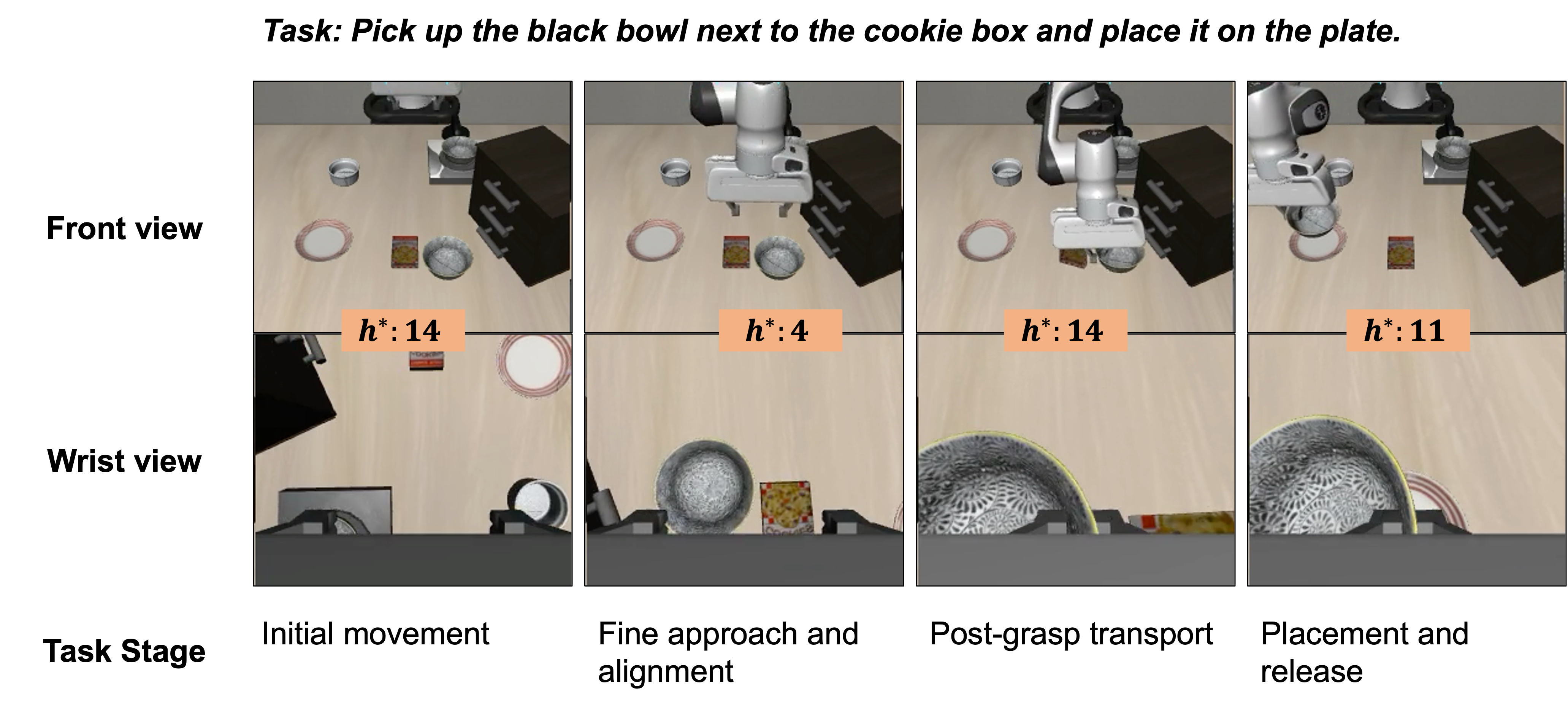
GR00T N1.5, adopted as the baseline, combines a frozen Vision-LLM (VLM) with a Diffusion Transformer (DiT) action head, trained via flow-matching on action chunks. At inference, prior procedures fix chunk size, whereas AAC dynamically selects the optimal chunk size at each step. For each robot embodiment and action type (continuous: translation, rotation; discrete: gripper), action entropy is estimated by sampling candidate action chunks. For continuous DoFs, Gaussian differential entropy is used; for discrete variables, categorical entropy is computed. Multiple chunk sizes h (up to horizon H) are considered per timestep by aggregating sampled entropies; the algorithm selects the chunk size h∗ maximizing the differential in average entropy (subject to a minimum-move constraint), thus localizing a temporal “elbow point” beyond which additional chunk length yields diminishing returns in action certainty.
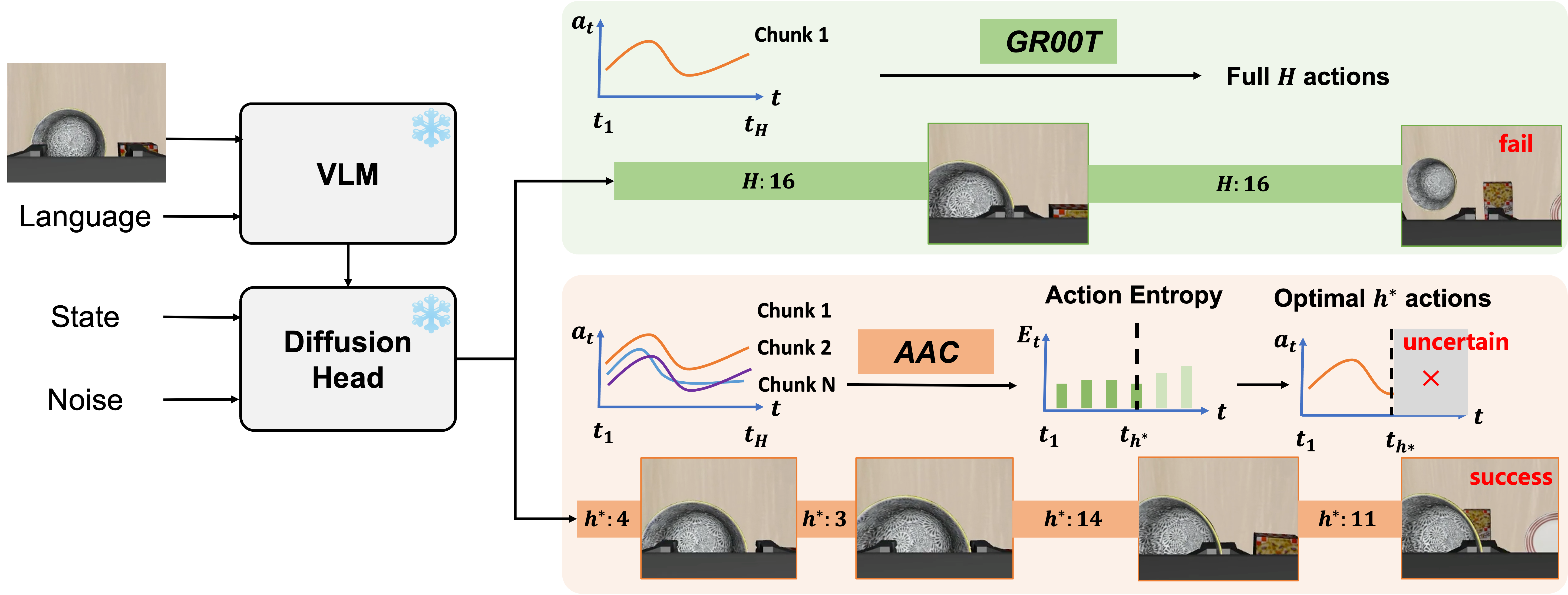
Figure 2: Overview of AAC—inference-time adaptation of chunk size via real-time action entropy computation without any model changes.
The resulting scheme yields temporally varying chunk lengths within episodes, matching fine/high-frequency refinements to uncertain periods and committing to longer open-loop sub-trajectories when the model is confident. The policy thereby adapts to task structure and online uncertainty.
Experimental Results
Simulation Benchmarks
AAC is evaluated on 24 RoboCasa Kitchen manipulation tasks and four LIBERO suites. Success rates with vanilla GR00T N1.5 (fixed h=16), as well as several fixed h controls, are compared to AAC. The following quantitative trends are established:
AAC consistently outperforms all fixed-size counterparts, with the most substantial benefit manifested on tasks with substantial phase-based complexity and variable temporal structure.
Qualitative and Analytical Evaluation
Chunk size heatmaps and timestepped distribution analyses confirm that AAC learns to allocate large chunks to high-level (e.g., transport) macro-actions, reducing chunk length for precise, critical interaction phases, such as grasp initiation or constrained in-hand manipulation.
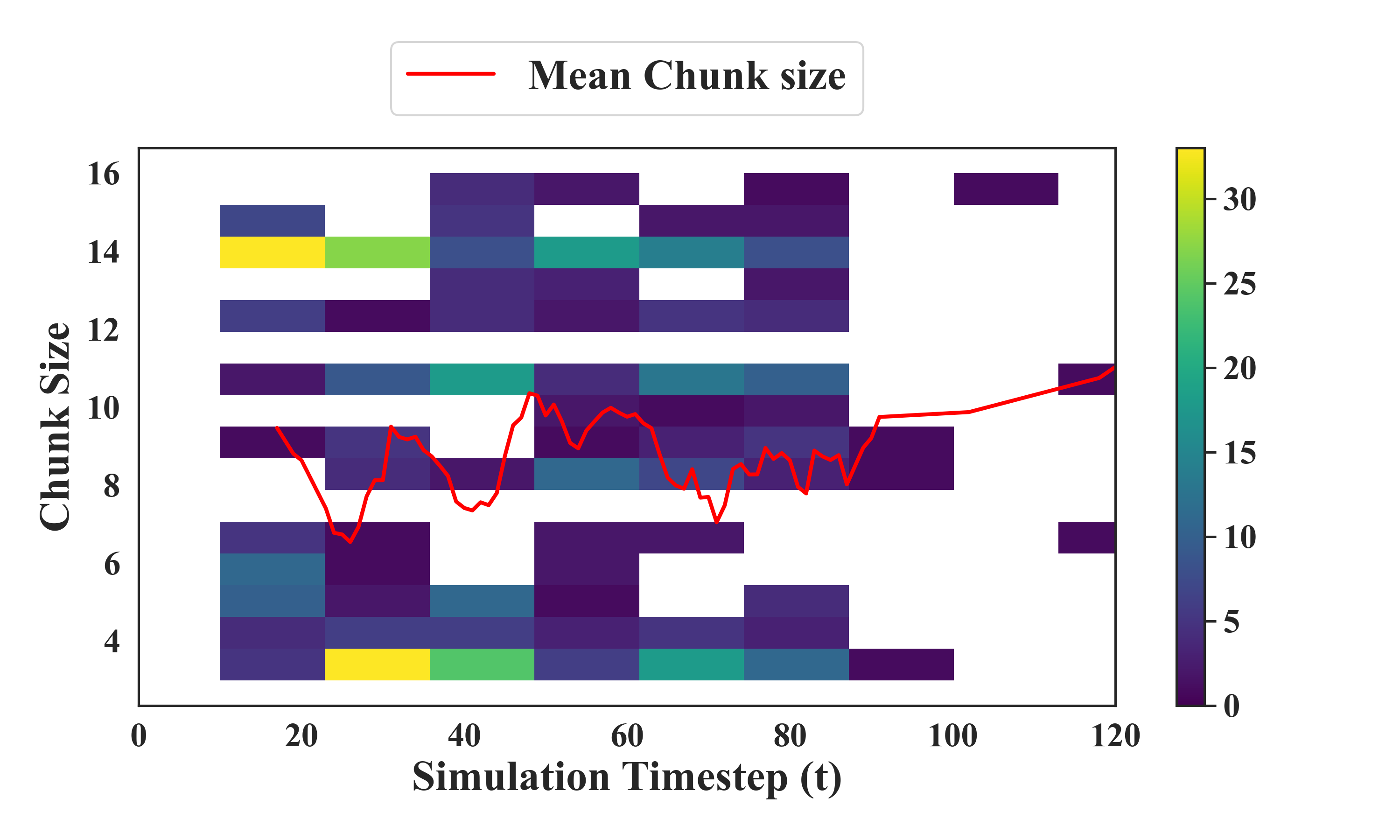
Figure 4: Distribution of chunk size decisions on a representative LIBERO-Spatial task reveals an adaptive, bi-modal phasing in chunk selection, with pronounced reduction near manipulation-critical timesteps.
Scalability analysis shows that AAC generalizes to multiple VLA backbones (e.g., π0.5); sample efficiency saturates rapidly (20 action samples suffice); computational overhead is negligible for moderate batch sizes. Robustness experiments on out-of-distribution (OOD) position perturbation subsets (LIBERO-Pro) show retained gains, especially in higher-uncertainty conditions.
Real-world Deployment
AAC is deployed on a physical 7-DoF arm for three manipulation tasks, outperforming GR00T by 15% absolute success rate across tasks (e.g., 70%→90% for banana pick-and-place). Notably, in OOD and high-precision tasks (e.g., unseen emergency button positions), AAC demonstrates superior generalization and markedly reduces hardware collision rates by suppressing high-entropy/unsafe actions.

Figure 5: Real-world robotic execution trajectories using AAC across pick-and-place, button pressing, and long-horizon sequences.

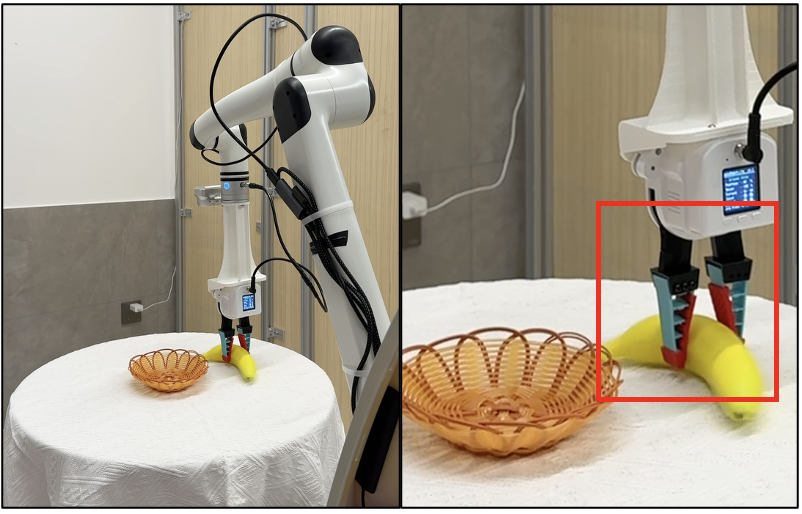
Figure 6: Comparison of execution—baseline GR00T collides with tabletop during banana placement, AAC filters uncertain actions and avoids collision, yielding a precise, safe trajectory.
Theoretical Implications and Future Directions
The AAC method shows that dynamic adaptation based on action entropy is orthogonal to model and training pipeline, directly addressable at the inference layer. This decouples sample-efficient policy optimization from physical closed-loop performance constraints, promising a general recipe for bridging simulation-to-reality and robustness gaps in large pretrained VLA policies. The empirical evidence that dynamic chunking improves not only average but also tail-case safety and task generality supports future incorporation of uncertainty-driven action horizon policies in broader classes of world-model and LfD systems.
The method’s generality—applicability to multiple robot morphologies, action formats, and underlying backbone architectures—suggests a direction for future standardized chunk adaptation modules in generalist multitask and deployment environments. Integrating adaptive chunking with explicit uncertainty quantification (beyond entropy), as well as hierarchical or event-driven temporal policies, are promising future research directions.
Conclusion
AAC establishes that online, entropy-driven action chunking at inference is a critical lever for improving manipulation performance and safety in VLA models. The method’s efficacy across simulation and real-robot benchmarks, its computational efficiency, and its compatibility with large-scale pretrained policies highlight its utility as a practical, theory-grounded augmentation for future vision-language-action systems.