- The paper proposes Adaptive Q-Chunking, which dynamically selects action chunk lengths using normalized advantage comparisons for balanced progress and precision.
- It employs a multi-scale critic architecture with z-score normalization to correct variance and mitigate discount-scale mismatches.
- Empirical results across manipulation benchmarks demonstrate significant improvements in success rates for both free-space and contact-rich tasks.
Adaptive Q-Chunking for Offline-to-Online Reinforcement Learning: A Technical Overview
Motivation and Problem Setting
This paper addresses a core challenge in offline-to-online reinforcement learning (RL): the trade-off inherent in action chunking. Conventional RL approaches struggle with long-horizon, sparse-reward manipulation problems due to slow credit assignment and unreliable exploration. Action chunking—committing to multi-step open-loop action sequences—mitigates these issues by accelerating value propagation and inducing temporally coherent exploration. However, existing chunked RL methods employ a fixed chunk size, which is suboptimal. Free-space phases of manipulation favor long chunks for rapid progress, while contact-rich phases require short chunks for precise, reactive control.
The paper demonstrates that naive adaptive selection—simply choosing chunk length via direct comparison of value functions trained for different chunk sizes—suffers from discount scale mismatch and high-variance estimation, leading either to degenerate policies (always selecting the shortest chunk) or noise-driven decisions.
The Adaptive Q-Chunking (AQC) Framework
AQC overcomes these limitations via per-scale advantage comparison. The central contribution is an adaptive chunk selection mechanism based on the normalized advantage of each chunk size k, defined as (Qk(s,at:t+k)−Vk(s))/γk. By comparing each candidate chunk’s value to an on-policy baseline for the same chunk length, and discount-normalizing, this approach yields a meaningful, scale-invariant selection criterion. The selection process is robust to zero-value regions, where otherwise noise would dominate, defaulting to longer chunks when no significant advantage is present.

Figure 1: Schematic pipeline of Adaptive Q-Chunking, showing joint training of multi-horizon critics and adaptive selection via per-scale advantages.
AQC maintains a set of critics for different chunk sizes K={k1,...,h}, all jointly trained such that shorter-horizon critics bootstrap from a common long-horizon value function. The behavioral policy is parameterized as a conditional flow-matching model, enabling efficient sampling of temporally coherent action sequences.
At each decision point, AQC samples N candidate action chunks (of length h) from the behavior policy. For each chunk and each chunk length k≤h, it evaluates the discount-normalized, baseline-subtracted advantage. Scores are z-score-normalized within each chunk length to correct for variance differences across horizons, and the best (chunk size, action) pair is selected for open-loop execution.
Numerical Results and Empirical Comparison
AQC exhibits strong numerical performance across diverse manipulation benchmarks:
- OGBench: AQC achieves higher online success rates than both single-scale chunking (QC) and decoupled chunking (DQC) baselines, with the gap most pronounced in longer-horizon, combinatorially hard domains such as multi-cube rearrangement.
- Robomimic: On contact-rich tasks, AQC matches or surpasses prior methods, with its adaptivity crucial for phases requiring rapid feedback control.
- Large-scale VLAs: Adding AQC as a value-based selection mechanism on top of GR00T N1.6, a strong multi-task vision-language-action model, leads to substantial gains over behavioral cloning and non-adaptive chunked critics, as shown on RoboCasa-GR1 tasks.
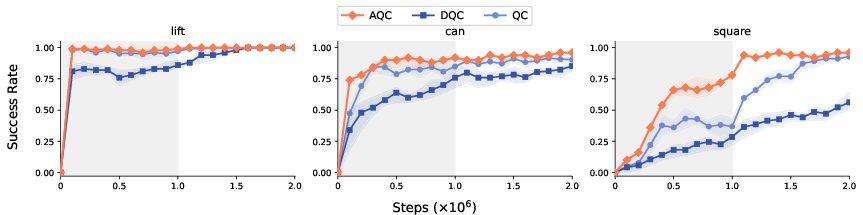
Figure 2: Robomimic tasks—success rates versus environment steps; AQC achieves faster and higher final success rates, particularly on the most challenging tasks.
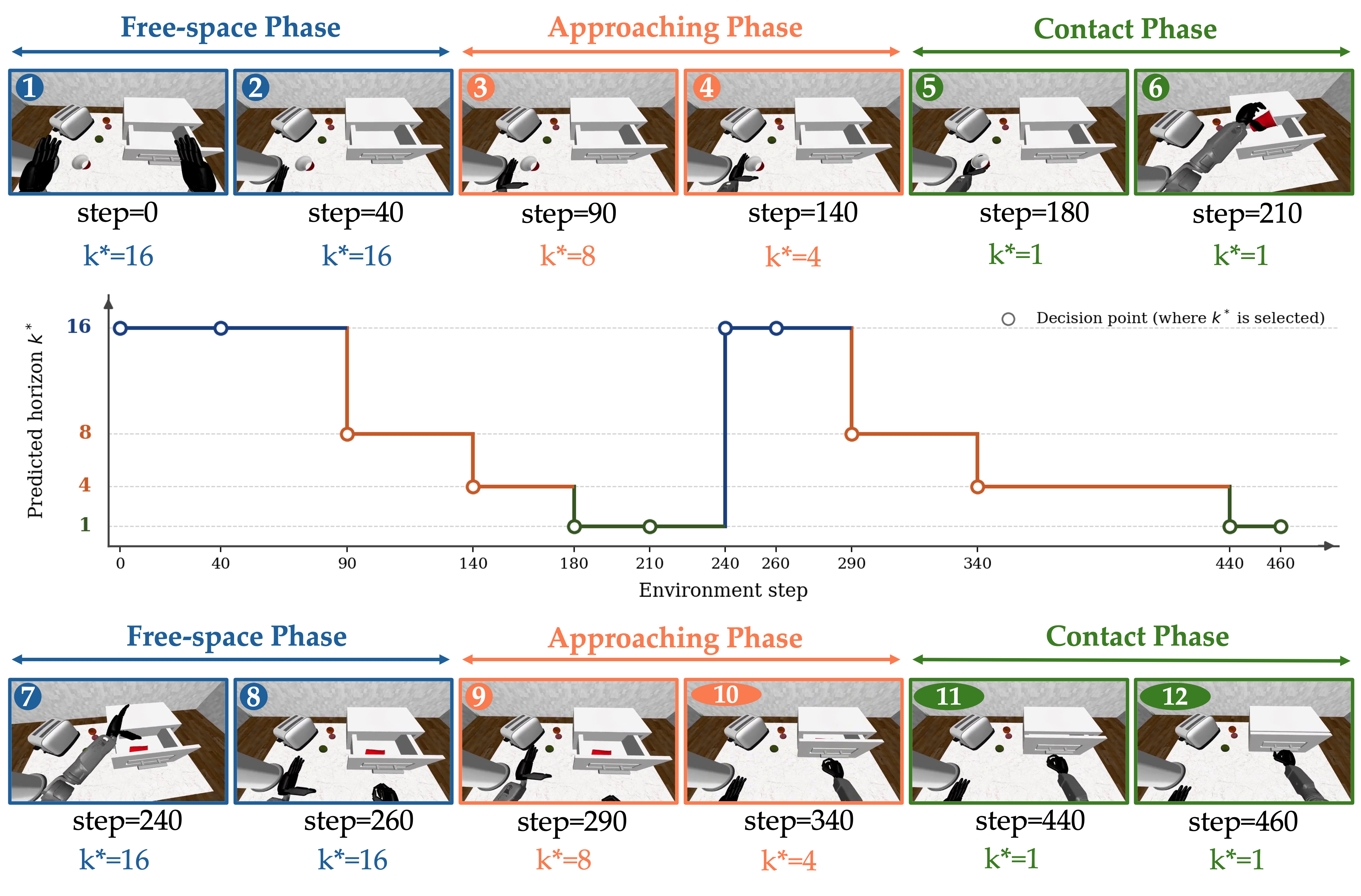
Figure 3: Qualitative rollout—AQC automatically adapts chunk length, using long chunks for free-space movement and short ones near contacts, demonstrating phase-appropriate horizon selection.
Ablations and Component Analyses
Comprehensive ablations affirm that both the advantage-based selection criterion and the use of per-scale baselines are critical—naive Q-value or discount-corrected comparisons fail, especially on long-horizon domains. The multi-scale critic architecture, with all critics bootstrapped from the shared long-horizon value, provides superior value error propagation compared to 1-step or per-scale value baselines, as shown empirically and corroborated by theoretical analysis.
Z-score normalization of advantage scores across chunk sizes is found essential for preventing high-variance critics from dominating selection.
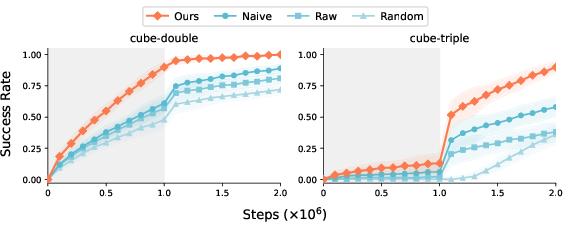
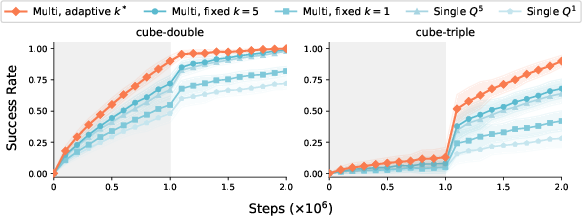
Figure 4: Selection criterion ablation—without the per-scale advantage baseline, policies collapse to always selecting k=1.
Theoretical Properties
AQC is supported by strong theoretical guarantees:
- The advantage selector enjoys noise immunity, ensuring random (rather than systematically biased) actions in low-information states.
- The value function of the AQC policy strictly dominates any fixed-chunk or naive n-step policy under natural advantage-separability conditions.
- The multi-scale, hierarchy-aware critic structure inherently regularizes the entire family of critics, with shorter horizons benefiting from improved long-horizon value approximations.
- For arbitrarily defined sets K of chunk sizes, AQC’s regret and suboptimality bounds scale favorably with the minimum chunk length and average advantage gaps.
Implications and Future Directions
Practically, AQC eliminates the need for heuristic tuning of chunk lengths and adapts seamlessly to varying phase demands in long-horizon manipulation—a key bottleneck in robust robotic policies. Its modular design enables integration atop large-scale VLA models, leveraging value-based RL after standard supervised pretraining.
Theoretically, the work refines our understanding of multi-horizon value function comparison, advocating for advantage-based criteria whenever value functions are learned for heterogeneous abstraction levels or time scales. The explicit separation of scale and baseline cleanly decouples estimation bias from selection propensity.
Looking forward, this framework points to several extensions. Continuous chunk size selection, end-to-end learned horizon policies, and hybrid integration with closed-loop (reactive) low-level controllers during contact phases are all viable directions suggested by the limitations section. Advanced architectures for shared-weight, multi-horizon critics also promise improved scalability as the number of candidate horizons increases.
Conclusion
Adaptive Q-Chunking provides a principled, theoretically grounded, and empirically robust approach to adaptive temporal abstraction in offline-to-online RL. It integrates per-scale advantage criteria, multi-horizon critic hierarchies, and variance-corrected selection to generate policies that dynamically trade off between efficiency and reactivity. The resulting framework sets a new performance bar across long-horizon robotic manipulation benchmarks and opens new avenues for generalization in value-based control for both classical agents and modern multimodal, multi-task models.