Training-Free Looped Transformers
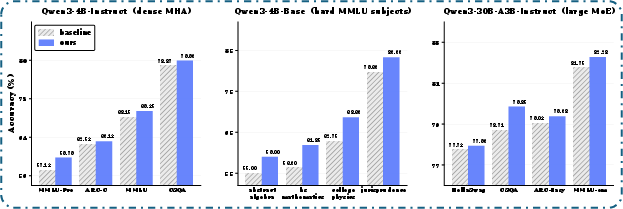
Abstract: We introduce training-free looped transformers, in which a lightweight inference-time wrapper loops a contiguous mid-stack block of layers of a frozen checkpoint without additional fine-tuning, continued training, or architectural changes. Unlike prior looped transformer methods that train with the looped structure end-to-end, we retrofit recurrence onto pretrained models at test time. We show that naive block reapplication usually degrades performance, highlighting the importance of the loop application strategy. Motivated by viewing a pre-norm transformer block as a forward Euler step on an ODE, we instead treat looping as a refinement of the same approximation, replacing one large update with smaller damped sub-steps. Across seven dense, sparse MoE, and MLA+MoE model families, our method improves Qwen3-4B-Instruct by +2.64 pp on MMLU-Pro, Qwen3-30B-A3B-Instruct by +1.14 pp on CommonsenseQA, and Moonlight-16B-A3B-Instruct by +1.20 pp on OpenBookQA.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper shows a way to make many existing LLMs (like Qwen, Llama, and DeepSeek) a bit smarter at test time without retraining them. The trick is to briefly “revisit” a small group of layers in the middle of the model during inference, taking several small correction steps instead of one big jump. This adds a little extra thinking per token, often leading to better answers on knowledge-heavy multiple-choice questions.
The big questions the authors asked
- Can we loop part of a transformer (re-run a small chunk of layers) during inference to improve answers, without changing any model weights or doing extra training?
- If looping helps, what’s the right way to do it so we don’t break the model’s behavior?
- Does this work across many different model types, including normal dense models and Mixture-of-Experts (MoE) models?
How their method works (with everyday analogies)
Think of a transformer as a stack of steps that turn your input into an answer. The authors:
- Pick a short stretch of layers in the middle of the stack (often around 4 layers near the middle).
- During inference, they run that stretch multiple times in a smart way before continuing to the final layers.
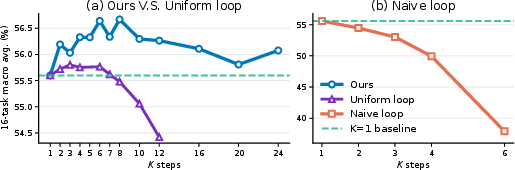
Why “smart”? Because simply repeating the same middle block over and over (naive looping) usually makes performance worse. The model’s later layers are trained to expect the output after one pass, not after several.
Their insight: a transformer layer is like taking one step along a path toward a better representation. If you take one giant step, you might overshoot. If you take several smaller, guided steps, you end up closer to the same destination—but more accurately.
Two key ideas make this safe and effective:
- Smaller sub-steps, not big jumps:
- Instead of “do the whole block again,” they do tiny nudges toward the block’s output each time. Imagine editing an essay: rather than rewriting a whole paragraph multiple times, you make a few small, careful fixes that move it toward the same final version.
- In math-speak, they treat each layer like a “forward Euler” step of an ODE (a way to follow a path in small steps), and they “sub-step” the same time span more finely. You can think of it as walking a distance with several short strides instead of one long, wobbly leap.
- A better update rule (Runge–Kutta):
- They often use a classic “look-before-you-leap” method from numerical math called Runge–Kutta. It samples a few short trial steps, then combines them to make a safer, more accurate move. Everyday analogy: before crossing a stream on stones, you test a few nearby stones to choose the best foothold.
Two looping modes:
- Block-mode: re-run the whole chosen window as a unit several times. Works well on regular dense models.
- Layer-mode: for MoE models (which pick different “experts” per layer), re-run each layer in the window several times before moving to the next. This keeps the same experts engaged each time and avoids “expert thrashing” (where the model keeps switching experts and gets confused).
Where to loop and how much:
- Window location: best results come from looping a small window near the middle of the model (roughly the middle half in depth, not too early and not too late).
- Window size: about 4 layers was a sweet spot in many models.
- Number of repeats: a small number of sub-steps (like 2–3) was often enough; too many can waste time or even hurt.
Cost:
- This adds extra compute at inference because you run part of the model multiple times. No weights are changed, and no retraining is needed.
What they found and why it matters
Main results across many models and tasks:
- On knowledge-heavy multiple-choice benchmarks, this “training-free loop” often gives a clear boost.
- Examples of improvements (absolute percentage points):
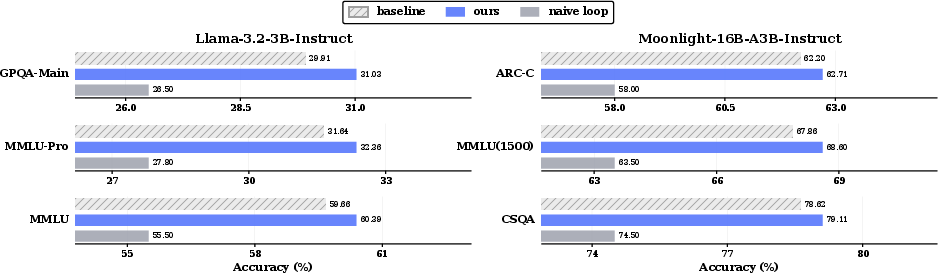
- Qwen3-4B-Instruct: +2.64 on MMLU-Pro, +2.01 on GPQA-Main.
- Qwen1.5-MoE-A2.7B-Chat: +2.30 on ARC-Challenge.
- Moonlight-16B-A3B-Instruct: +1.20 on OpenBookQA.
- Llama-3.2-3B-Instruct: smaller but consistent gains on MMLU and GPQA.
- Broadly, 87% of model-task combinations were positive or neutral under a single out-of-the-box recipe (no tuning per task).
- Crucially, “naive looping” (just repeating the block K times) usually made things worse. The smart, small-step approach fixed that.
Why this is important:
- You can squeeze extra performance out of many existing, public models without retraining them.
- The method is simple to apply, works across different architectures (dense, MoE, standard attention, and MLA), and typically helps on hard, knowledge-focused questions—exactly where small improvements are valuable.
What this could change going forward
- Faster iteration in practice: If you have a frozen model and want a bit more accuracy on tough knowledge tasks, you can wrap it with this looping trick instead of running expensive fine-tuning.
- Better use of test-time compute: This shows that spending a little extra compute inside the model (not just writing longer chain-of-thought outputs) can uncover “latent” reasoning the model already has.
- Guidance for model design: The “depth fraction rule” (loop around the middle) and the difference between block-mode (dense) and layer-mode (MoE) give practical recipes that generalize across architectures.
- Limits and trade-offs: It doesn’t help equally on all tasks or very small, heavily distilled models, and it costs extra inference time. Still, the cost/benefit can be attractive when a few points of accuracy matter.
Plain-language explanations of key terms
- Looping a block of layers: Running the same middle chunk of the model more than once during inference.
- Damped sub-steps: Taking several small nudges toward the same goal instead of one big move. Safer and more precise.
- Runge–Kutta: A classic “test a few small moves, then pick a smart combined move” method from numerical math to avoid overshooting.
- MoE (Mixture-of-Experts): A model where each layer picks a few specialist sub-networks (“experts”) to handle the input. Layer-mode looping keeps the same experts engaged across the repeats to avoid flip-flopping.
- ODE/Euler step (intuition only): Following a path in tiny steps; a transformer layer can be seen as one such step. Doing more but smaller steps can get you to the same place more accurately.
Bottom line
The paper presents a practical, training-free way to let models “think a bit more” inside their own layers. By re-running a small middle section with gentle, well-chosen mini-steps, many models answer hard multiple-choice questions more accurately—often by 1–3 percentage points—without changing any weights or doing extra training. This is a simple, broadly useful boost for real-world use of existing LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unexplored, framed as concrete directions future work could pursue.
- Formal guarantees: Derive conditions (e.g., Lipschitz/contractivity of , bounds on Jacobian spectral radius) under which sub-stepping provably improves approximation to the endpoint and cannot harm downstream layers; extend analysis to attention-specific nonlinearities and pre-norm vs post-norm variants.
- Error control and stability: Develop adaptive step-size control for the loop (local truncation error estimates, embedded RK pairs, line search) to ensure stability across inputs and models instead of fixed and .
- Solver design space: Systematically compare explicit vs implicit integrators (e.g., implicit Euler, trapezoidal rule, BDF, Gauss–Legendre RK), and hybrid fixed-point accelerators with damping; characterize regimes where Anderson/Aitken/heavy-ball help or harm.
- Adaptive halting and scheduling: Learn or infer per-input/per-token decisions for K, , window width, and location (e.g., using residual norms, tuned-lens entropy, Jacobian norms, or gating entropy) rather than using a single static recipe.
- Automatic window selection: Replace the depth-fraction heuristic with data-driven or analytic selection of loop layers; explore non-contiguous or multi-window looping and per-layer nonuniform .
- MoE routing details: Clarify and evaluate whether layer-mode truly “pins” expert routing across (e.g., freeze gates vs recompute); study alternatives (gate temperature control, EMA of gate logits, routing noise suppression) and their effects on load balancing, utilization, and quality.
- Compute–quality Pareto: Quantify end-to-end latency, throughput, memory footprint, and energy across hardware stacks (consumer GPUs, CPUs, accelerators) versus accuracy gains; provide Pareto curves and budget-aware policies.
- KV-cache semantics: Precisely specify cache handling within loop iterations during autoregressive decoding (reuse vs recompute keys/values, attention mask implications) and evaluate downstream impacts on speed and correctness under beam search and sampling.
- Generative tasks: Test on open-ended generation (summarization, long-form QA), code (e.g., HumanEval), and math reasoning (GSM8K/MATH) to determine whether gains extend beyond multiple-choice scoring.
- Long-context behavior: Assess effects on length generalization, retrieval over long contexts, streaming/chunked decoding, and models with rotary/ALiBi/MLA attention; does looping help or harm long-range recall?
- Calibration and hallucination: Measure changes in calibration (ECE/Brier), factuality/hallucination, TruthfulQA-style safety beyond single data points, and whether looping alters refusal/harms under RLHF alignment.
- Distillation regime failures: Diagnose why small distilled checkpoints degrade on some knowledge-MC tasks; identify predictive indicators (e.g., residual growth, spectral radius, norm explosion) and design safeguards to auto-disable looping when risky.
- Quantization robustness: Evaluate performance and stability under 8-bit/4-bit weight and activation quantization; determine whether repeated sub-steps amplify quantization noise and how to mitigate it.
- Very large models and modalities: Test at larger scales (>70B), encoder–decoder models, and multimodal backbones; verify whether the depth-fraction rule and layer-mode MoE guidance generalize.
- Mechanistic effects: Probe how looping changes intermediate representations (attention patterns, feature circuits, tuned-lens trajectories), and whether it selectively amplifies knowledge-bearing features vs noise.
- Interaction with inference-time reasoning: Study compatibility and synergy with CoT/self-consistency/RAG/tool-use; determine whether looping reduces the number of samples needed or improves vote aggregation.
- Training-light variants: Explore light adaptation (e.g., tiny adapters, LoRA on looped layers, learned / policies) to enhance gains while retaining most training-free benefits.
- Safety and distribution shift: Evaluate robustness to adversarial prompts, jailbreak attempts, and domain shifts; investigate whether looping inadvertently weakens safety filters learned during post-training.
- Implementation portability: Validate reproducibility across inference frameworks (vLLM/TensorRT/ONNX), backends (Flash/SDPA/MLA kernels), and batching regimes; document engineering constraints for production deployment.
- Resource constraints: Characterize memory pressure induced by repeated middle-block activations on smaller GPUs; propose memory-saving variants (activation rematerialization, checkpointing within loop).
- Step-size heterogeneity: Test per-layer or per-head heterogeneous step sizes and damping schedules within the loop window to reduce compute while retaining quality.
- Theoretical model of the depth-fraction rule: Move beyond empirical observation to a theory connecting head specialization, redundancy, and the optimal looping band across scales and training curricula.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed today with frozen open-weight LLM checkpoints, using the paper’s training-free loop wrapper (mid-layer reapplication with Runge–Kutta-style sub-stepping). Each item includes sector fit, potential tools/workflows, and feasibility notes.
- LLM serving quality knob for knowledge-heavy QA (Industry: software/cloud AI, enterprise AI)
- Use case: Add a “refinement” mode to existing serving stacks (e.g., customer support, knowledge bases, enterprise QA) to gain ~+1–3 percentage points on knowledge-heavy multiple-choice and factual QA without retraining.
- Tools/workflows: Implement mid-stack looping with K-stage Runge–Kutta in vLLM, Text Generation Inference (TGI), TensorRT-LLM, or custom PyTorch/HF Transformers servers; expose loop parameters (window, K, mode) as inference-time flags.
- Assumptions/dependencies: Access to model internals (open-weight checkpoints, not black-box APIs), added compute/latency overhead of roughly (loop-window-size) × (K−1) forward passes; strongest gains on knowledge-heavy MC tasks; follow paper’s defaults (mid-4-layer window around 45–60% depth; block-mode for dense, layer-mode for MoE).
- Cost-effective “last-mile” lift versus fine-tuning (Industry: consulting, MLOps, platform providers)
- Use case: Offer a deployment-time upgrade path for clients who cannot train or re-train models (compliance, compute limits) but need measurable accuracy gains on standardized tests, quizzes, or domain QA.
- Tools/workflows: Provide a wrapper library (“LoopRefine”) that instruments any HF model class with a parametric loop window and solver; deliver A/B testing dashboards to tune latency vs. quality.
- Assumptions/dependencies: Compute budget increases; rollback plan for small/distilled models where gains can be neutral/negative; model must be pre-norm transformer.
- Dynamic per-request compute scaling (Industry: inference orchestration, cloud cost optimization)
- Use case: Turn on looping only when a request looks “hard” (e.g., low logit margin/entropy on the next token, or task classifier predicts knowledge-heavy MC).
- Tools/workflows: Add an adaptive controller in the inference server that inspects early logits and toggles looping; maintain SLAs by capping K or window size under load.
- Assumptions/dependencies: Confidence heuristics already exist; modest serving logic changes; needs telemetry (latency, token throughput) and guardrails for tail latency.
- Safe MoE deployment with layer-mode iteration (Industry: companies deploying MoE models)
- Use case: Stabilize expert routing by looping each MoE layer K times (layer-mode) instead of looping a block (block-mode), avoiding routing thrash and improving quality on ARC/CSQA/OBQA.
- Tools/workflows: Extend MoE kernels to reuse gating decisions across sub-steps; expose mode toggles per model family in serving config.
- Assumptions/dependencies: Access to and control over routing/gating; must pin per-layer gating across iterations; layer-mode is the default for MoE as per the paper.
- Education and testing products (“Exam mode”) (Sector: education/edtech)
- Use case: Improve performance on practice exams (MMLU/MMLU-Pro-like), placement tests, and quiz generation/solving without model retraining.
- Tools/workflows: Add a toggle in tutoring apps (LM Studio/Ollama-like front ends) for “Exam mode (looped mid-layers)”; pre-set K and window using the depth-fraction rule.
- Assumptions/dependencies: Local/open models used in the app; expect increased latency; best for MC-style assessments.
- Enterprise knowledge assistants with RAG (Industry: knowledge management, search)
- Use case: Apply looping on the generation step when answering factual questions over retrieved documents; treat the loop as a frozen-context knowledge refiner.
- Tools/workflows: Integrate with LangChain/LlamaIndex pipelines; apply looping only on specific tool calls (e.g., after retrieval or on final synthesis).
- Assumptions/dependencies: Gains strongest for MC-like questions; long-form generation may see smaller effect; ensure KV-cache handling matches the wrapper (as per paper’s ablation robustness).
- Benchmarking and model gating (Academia/industry eval teams)
- Use case: Use the wrapper as a baseline “inference-time compute scaling” knob when comparing checkpoints; report with and without looping to understand headroom without training.
- Tools/workflows: Extend lm-eval-harness or internal harnesses with loop parameters and automatic window placement via the depth-fraction rule; log per-task deltas and latency trade-offs.
- Assumptions/dependencies: Transparent reporting to avoid confounding evals; consistent prompts across conditions.
- Interpretability and diagnostics via ODE sub-stepping (Academia/research)
- Use case: Probe residual dynamics by sub-stepping per layer/block and inspecting residual fields, fixed-point behavior, or contraction properties.
- Tools/workflows: Wrap layers to export intermediate y_i, k_i (Runge–Kutta stages); visualize trajectory stability across K and positions.
- Assumptions/dependencies: Access to forward graph; results most meaningful for pre-norm stacks.
- Compliance and procurement for public-sector tests (Policy/public sector)
- Use case: Improve standardized-test-like accuracy for pilot deployments without retraining (useful where training is restricted).
- Tools/workflows: Add a documented, training-free refinement mode with fixed parameters for auditability; publish latency/energy costs and deltas on public benchmarks.
- Assumptions/dependencies: Open-weight models permitted; clear disclosure that accuracy gains come from inference-time compute, not training data changes.
- “Turbo QA” in consumer apps (Daily life)
- Use case: Toggle a “more accurate” but slower mode for tricky factual questions in personal assistants or local LLM apps.
- Tools/workflows: UI toggle tied to K and window; default presets per model family; optionally auto-triggered by low answer confidence.
- Assumptions/dependencies: User tolerance for latency; works best with open models on local hardware.
Long-Term Applications
These opportunities require further research, engineering, or ecosystem support (e.g., compilers, schedulers, or broader task validation).
- Compiler-level graph support for looped segments (Industry: systems, ML compilers)
- Use case: Fuse loop windows and sub-steps into single optimized kernels to mitigate the extra forward-pass overhead (e.g., TensorRT-LLM/ONNX/Triton codegen).
- Dependencies: Kernel and memory-planning work to reuse activations across sub-steps; KV-cache compatibility; benchmarking on long sequences.
- Adaptive per-token/per-layer loop controllers (Industry/academia)
- Use case: Learn a policy that decides K, window position, and mode on the fly based on uncertainty, residual norms, or routing stability.
- Dependencies: Policy training or bandit/RL; safety constraints to prevent regressions; explainability for production toggling.
- Generalization to other modalities and tasks (Academia/industry)
- Use case: Apply training-free looping to vision transformers, speech transformers, code LLMs, and long-form reasoning; test beyond MC tasks.
- Dependencies: Empirical validation of gains on generative writing, coding benchmarks, and multi-modal QA; adaptation of window rules for different backbones.
- RAG-aware looping and cross-encoder reranking (Industry: search/retrieval)
- Use case: Use looping for cross-encoder rerankers or within retrieval-augmented generators to improve factual grounding and answer selection.
- Dependencies: Integration with retriever/reranker latency budgets; sensitivity analysis on noisy retrieved contexts.
- Safety and robustness auditing under extra inference-time compute (Policy/industry)
- Use case: Evaluate how looping affects hallucinations, calibration, toxicity, and jailbreak susceptibility; certify safe configurations.
- Dependencies: Extensive red-teaming; calibration and reliability metrics; possible mode-specific safeguards (e.g., cap K on sensitive topics).
- Training–inference co-design (Academia/industry research)
- Use case: Train models that explicitly anticipate loop-time sub-stepping (e.g., regularize mid-layers for stable residual fields, MoE routers stable across reapplication).
- Dependencies: Training compute; architectural changes (e.g., gating invariances), and ablations to separate training vs. inference contributions.
- Automated depth-fraction selection for new architectures (Industry/academia)
- Use case: Build a small calibration routine that identifies the optimal loop window and K from a tiny validation set for arbitrary backbones.
- Dependencies: Few-shot calibration tasks; tooling in serving stacks; guardrails to avoid overfitting and ensure leakage-free evaluations.
- Energy/latency–quality co-optimization (Industry: MLOps, sustainability)
- Use case: Jointly optimize K, window, batch size, and quantization to keep energy and latency within budgets while delivering measured accuracy gains.
- Dependencies: Telemetry and optimizers; potential need for specialized caches and quantized looping that preserve quality.
- Auditable “compute uplift” procurement standard (Policy)
- Use case: Define a standard reporting template where agencies record baseline vs. looped performance, along with compute and cost deltas, to inform procurement without hidden training changes.
- Dependencies: Coordination among vendors; reproducible configs and seeds; third-party verification.
- Library and ecosystem standardization
- Use case: First-class support in HF Transformers, vLLM, and lm-eval-harness for looped inference with documented defaults (e.g., K=2–3, mid-4-layer window, mode by backbone).
- Dependencies: Community consensus and maintenance; extensive CI across popular checkpoints and MoE variants.
Notes on feasibility and assumptions (cross-cutting):
- Applicability: Most robust on pre-norm transformers and knowledge-heavy multiple-choice tasks; less predictable for small/distilled models or free-form generation.
- Compute/latency: Expect a measurable increase proportional to loop span and K; use adaptive controllers to contain tail latency.
- MoE specifics: Use layer-mode to pin gating across sub-steps; block-mode can thrash routing.
- Access: Requires open-weight checkpoints or vendor support; cannot be applied to black-box API models without provider integration.
- Stability: Favor mid-depth windows (~45–60% fractional depth) and narrow spans (~4 layers) per the paper’s depth-fraction rule; test per model family before wide rollout.
Glossary
- Aitken Δ2: A sequence-acceleration method that extrapolates a fixed-point iteration to speed up convergence, often applied per coordinate. Example: "Aitken Δ2"
- Anderson acceleration: A fixed-point acceleration technique that combines past iterates and residuals to extrapolate a better next iterate. Example: "including Anderson acceleration, heavy-ball, Aitken acceleration"
- Autonomous ODE: An ordinary differential equation where the derivative depends only on the current state, not explicitly on time. Example: "on the autonomous ODE"
- bfloat16: A 16-bit floating-point format with an 8-bit exponent and 7-bit mantissa, widely used to speed up training/inference while preserving dynamic range. Example: "with bfloat16 weights and SDPA attention"
- Block-mode: A looping strategy where an entire contiguous block of layers is reapplied as a single unit for K iterations. Example: "Block-mode iterates the whole window times"
- Butcher tableau: A tabular specification of coefficients defining a Runge–Kutta integrator. Example: "specified by a Butcher tableau"
- Deep Equilibrium models: Architectures that compute predictions by finding the fixed point of a (possibly implicit) layer, instead of unrolling many explicit layers. Example: "Deep Equilibrium models"
- Fixed-point accelerators: Methods designed to speed up convergence of fixed-point iterations by leveraging past iterates or residuals (e.g., Anderson, heavy-ball). Example: "Fixed-point accelerators"
- Forward Euler (step): A first-order numerical integration method that advances the solution using the current derivative scaled by a step size. Example: "exactly one forward Euler step at "
- Gating network: The component in a Mixture-of-Experts layer that selects which experts to activate based on the current hidden state. Example: "the gating network of every MoE layer in the window"
- Heavy-ball: A momentum-based acceleration method for fixed-point or optimization iterations that adds a weighted difference of recent iterates. Example: "Heavy-ball ()"
- Heun (RK2): A second-order Runge–Kutta method (also known as the improved Euler method) that averages slope estimates to achieve higher accuracy than Euler. Example: "Heun (RK2)"
- KV-cache: Cached key and value tensors from attention computations used to speed up autoregressive decoding by reusing past attention context. Example: "KV-cache and decode-time handling"
- Layer-mode: A looping strategy that re-applies each layer in a loop window K times before moving on to the next layer, stabilizing MoE routing. Example: "Layer-mode iterates each window layer times before passing on"
- Mixture-of-Experts (MoE): An architecture in which a gating mechanism dynamically routes inputs to a subset of specialized expert networks. Example: "For mixture-of-experts (MoE) layers"
- Multi-head Latent Attention (MLA): A variant of attention that operates in a latent space to reduce compute or memory while retaining multi-head structure. Example: "Multi-head Latent Attention (MLA)"
- Numerical integration: Computational methods for approximating solutions to differential equations by discretizing time and advancing the state. Example: "numerical integration methods for an ODE that transformers implicitly approximate"
- Picard acceleration: A family of techniques that accelerate fixed-point (Picard) iterations, often by extrapolation or mixing strategies like Anderson. Example: "Picard acceleration via Anderson"
- Pre-norm transformer: A transformer architecture where layer normalization is applied before attention and MLP sublayers in each block. Example: "viewing a pre-norm transformer block as a forward Euler step"
- Quadrature rule: A weighted-sum rule for approximating integrals; in RK methods, it determines how stage derivatives are combined. Example: "a RK method with a front-loaded quadrature rule"
- Residual field: The vector field defined by the difference between a layer/block output and its input, treated as the derivative in an ODE view. Example: "we define the window residual field"
- Residual ODE: An ODE whose dynamics are given by the residual field of a layer/block, framing layer application as an integration step. Example: "per-block residual ODE"
- Residual stream: The main hidden-state pathway in a transformer that carries information across layers and receives residual updates. Example: "maps a residual stream of shape to itself"
- Runge--Kutta (RK): A family of higher-order explicit integration methods that combine multiple slope evaluations within a step. Example: "explicit Runge--Kutta integrator"
- SDPA attention: Scaled Dot-Product Attention; the standard attention mechanism using scaled query-key dot products. Example: "with bfloat16 weights and SDPA attention"
- Steffensen safeguard: A stability measure for Aitken/Steffensen-type accelerations that limits step size to prevent divergence. Example: "the Steffensen safeguard clips "
- Telescoping (unrolled chain): A simplification technique where sequential residual updates collapse into a sum due to cancellation across steps. Example: "telescoping the unrolled chain"
- Universal Transformers: Models that share parameters across layers and allow adaptive recurrence, effectively looping a single block. Example: "Universal Transformers"
Collections
Sign up for free to add this paper to one or more collections.

