LT2: Linear-Time Looped Transformers
Abstract: Looped Transformers (LT) have emerged as a powerful architecture by iterating their layers multiple times before decoding the final token. However, pairing them with full attention retains quadratic complexity, making them computationally expensive and slow. We introduce LT2 (Linear-Time Looped Transformers), a family of looped architectures that replace quadratic softmax attention with subquadratic, linear-time attention. We study two variants: LT2-linear with linear attention and LT2-sparse with sparse attention. We find that looping uniquely synergizes with these variants: it enables iterative memory refinement in linear attention and progressively expands the effective receptive field in sparse attention. We formalize these benefits theoretically and demonstrate consistent empirical gains across controlled recall, state-tracking, and language modeling tasks. We then explore LT2-hybrid, which combines different attention variants in a looped setting. Two variants are especially promising: LT2-hybrid (GDN+DSA), which interleaves linear and sparse attention to maximize efficiency and matches the standard looped transformer's quality at fully linear-time cost; and LT2-hybrid (Full+GDN), which interleaves GDN with a small fraction of full attention layers to maximize quality, surpassing the standard looped transformer in both performance and efficiency. We also show how to convert a pre-trained LT into an LT2-hybrid model. With about 1B tokens of training, our converted model, Ouro-hybrid-1.4B, outperforms industry-level 1B models and is competitive with industry-level 4B models while retaining the speed benefits of linear-time attention. Together, these results show a clear path toward making looped transformers more scalable and advancing efficient, capable small LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a faster way to build and run LLMs called LT2, short for Linear-Time Looped Transformers. The big idea is to keep the smart “looped” part of some modern models (where the model thinks through the text multiple times with shared weights), but replace the slow part of attention with faster versions. This lets the model handle long texts more quickly and with less memory, while keeping or even improving its accuracy.
What questions does the paper try to answer?
- Can we make looped transformers fast enough to handle long inputs without slowing down a lot?
- Can “linear” or “sparse” attention (which are cheaper to compute) work well inside loops?
- Is there a smart way to mix different attention types to get both speed and quality?
- Can we convert an existing looped model to this faster style without retraining everything from scratch?
How does it work? (Methods explained simply)
Think of a transformer like a reading team:
- Attention is the part that lets each word look at other words to figure out what’s important.
- Looped transformers make several passes over the same text, reusing the same “team rules” each time. That’s like the team rereading the text a few times to refine its understanding, but without hiring more people.
The problem: normal attention gets expensive very fast as text gets longer. If the text length doubles, the cost roughly quadruples. And in a loop, you pay that cost many times.
LT2 fixes this by swapping the heavy attention with lighter options:
- Linear attention: instead of letting every word talk to every other word, it keeps a running summary (“scratchpad”) that gets updated as you read. Cost grows roughly in a straight line with text length.
- Sparse attention: each word only looks at the most relevant nearby or top-ranked words, not all of them. Cost grows much slower.
Looping makes these light attentions smarter:
- For linear attention, each loop can refine the scratchpad in a new way, like adding more layers of notes. After T loops, the scratchpad acts like a richer memory with T “directions” of information instead of just one.
- For sparse attention, each loop lets information travel further. If a single loop can look back over w tokens, T loops effectively reach back Tw tokens. That’s like relaying messages down a line in multiple steps until they reach faraway parts of the text.
The paper explores three LT2 designs:
- LT2-linear: loops with fully linear attention
- LT2-sparse: loops with fully sparse attention
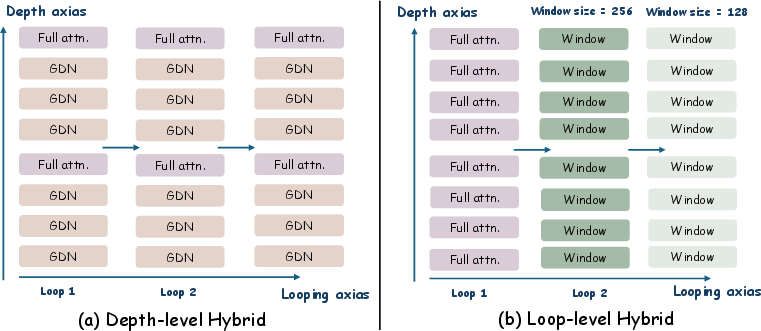
- LT2-hybrid: mixes attention types in clever patterns
Two hybrid designs stand out:
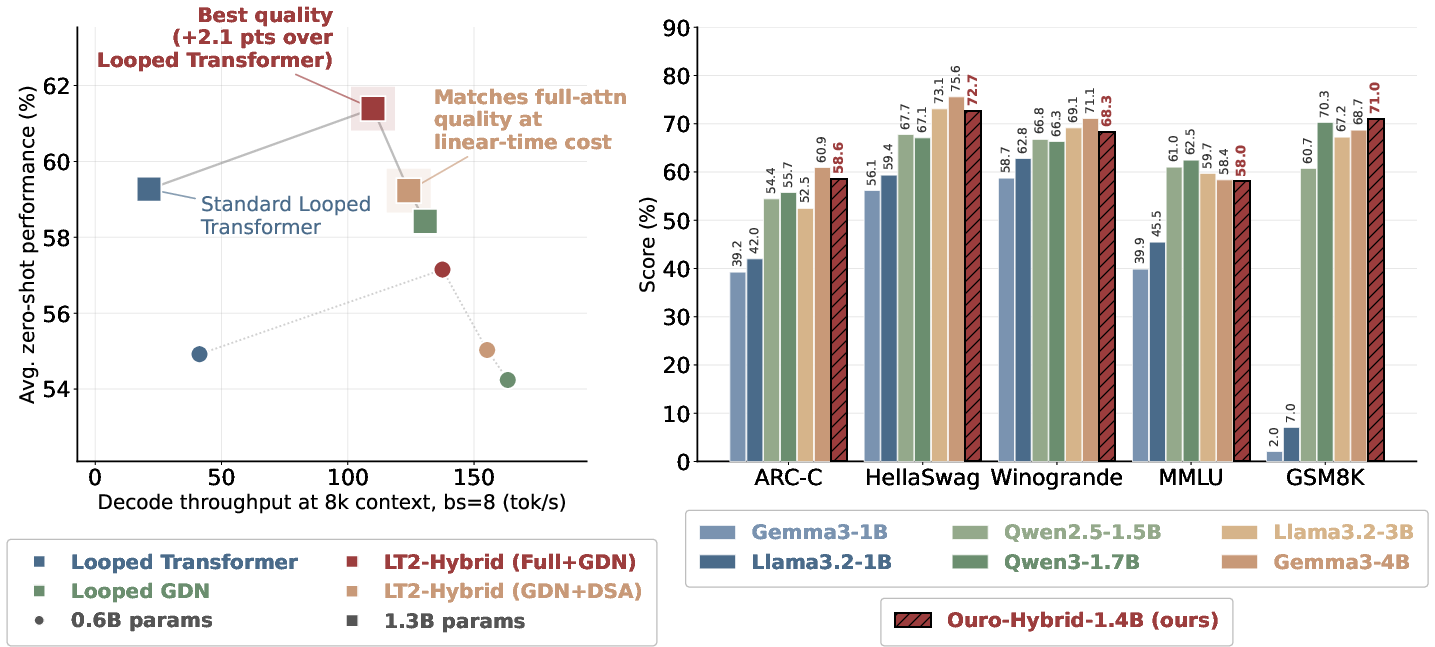
- Hybrid (GDN + DSA): interleaves a strong linear attention (GDN) with a strong sparse attention (DSA). It matches the quality of the standard looped transformer while running at fully linear-time cost.
- Hybrid (Full + GDN): uses mostly GDN plus a small number of full-attention layers. It beats the standard looped transformer on accuracy while still being much faster.
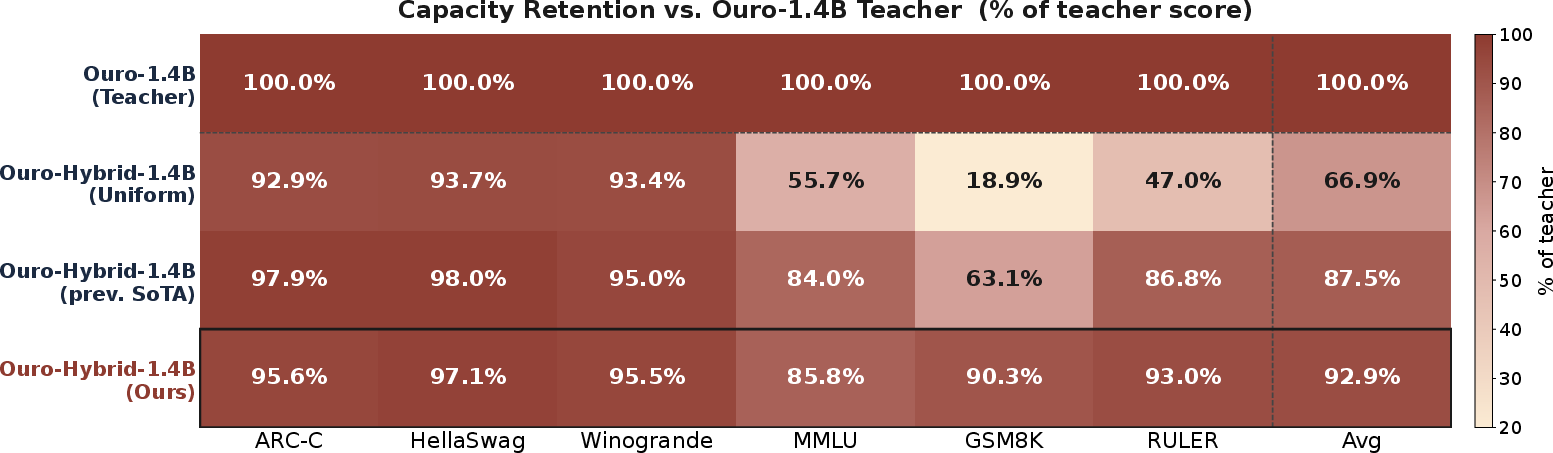
They also show how to convert a trained looped model (called Ouro) into an LT2-hybrid model with only about 1 billion extra training tokens. The converted model, Ouro-hybrid-1.4B, stays fast and competes with bigger industry models.
To make this clearer, here are a few everyday analogies to the technical terms:
- Attention: like scanning a page to find the most useful sentences.
- Linear attention: keeping a running summary instead of rereading the whole page each time.
- Sparse attention: looking only at the most relevant sentences rather than every sentence.
- Looping: rereading the text in several passes to improve the notes, but using the same reading rules each time.
- Hybrid: mixing reading strategies (some passes keep summaries, some do precise lookups).
What did they find and why does it matter?
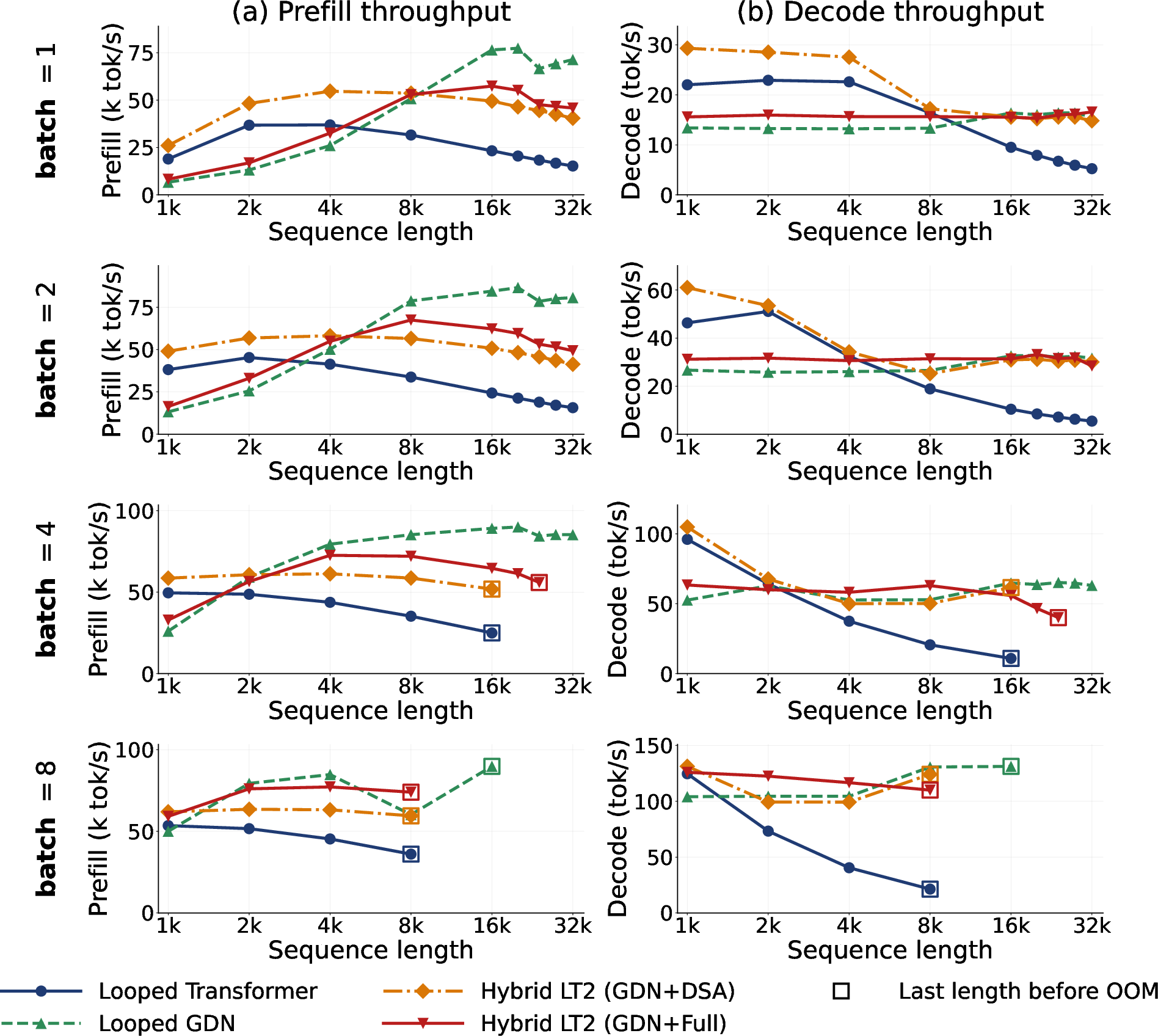
- Speed with long texts: LT2 models keep a steady decoding speed even as the input grows to 32k tokens, while normal looped transformers slow down or run out of memory. The hybrid LT2 models are about 3–6 times faster at long inputs in their tests.
- Quality:
- LT2-linear and LT2-sparse come close to the accuracy of full attention in loops.
- Hybrid (GDN + DSA) matches the standard looped transformer’s accuracy but runs at fully linear-time cost.
- Hybrid (Full + GDN) is the strongest overall, beating the standard looped transformer in average accuracy while still being much faster.
- Best mix ratio: Using a small amount of full attention (about 1 full-attention layer for every 4 GDN layers) gives the best accuracy-speed balance.
- Stability: Some light attentions can be unstable when looped. Attention with “gating” and “delta rules” (like GDN) trains smoothly and keeps activations under control. Sparse attention is stable too, just a bit less expressive. Hybrids combine both strengths.
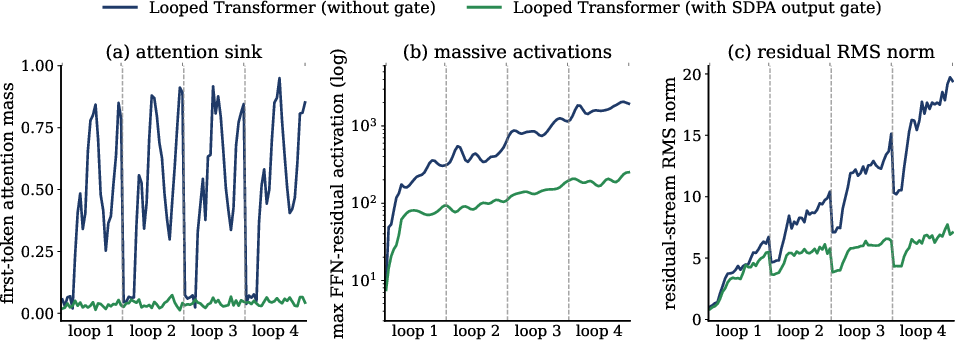
- Fixing “attention sinks”: Sometimes a few tokens grab too much attention and cause problems, especially across loops. A tiny “output gate” after attention reduces this issue and gives small but consistent accuracy gains.
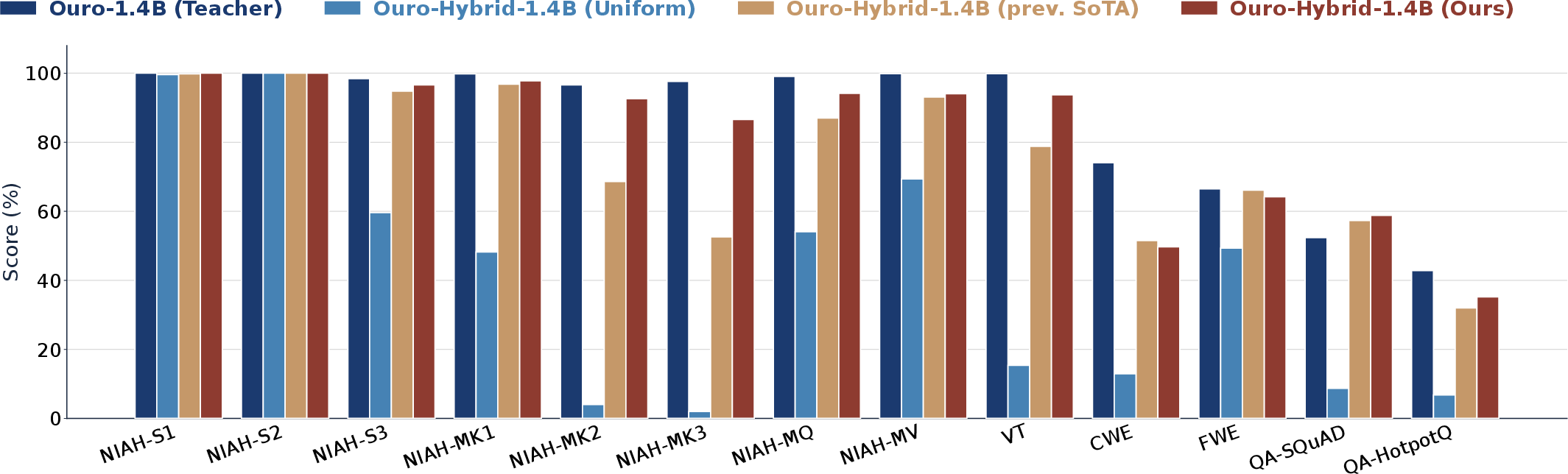
- Real tasks: On language understanding, recall, and synthetic state-tracking tasks, LT2 models not only keep up but sometimes surpass the full-attention looped transformer, especially when loop count is higher and texts are longer.
- Easy conversion: They turned a pretrained looped model into an LT2-hybrid model with limited extra training, keeping speed benefits and competitive accuracy versus bigger models.
Why is this important? (Implications)
- Longer context, lower cost: LT2 makes it practical to handle very long inputs without huge slowdowns or memory limits. That’s great for applications like reading long documents, code bases, or conversations.
- Smaller, stronger models: Mixing linear and sparse attention inside loops lets smaller models punch above their weight, saving compute without sacrificing much accuracy.
- Easier adoption: You don’t need to retrain your models from scratch to get these benefits. You can convert existing looped transformers to LT2-hybrids with a moderate amount of extra training.
- A path to scalable reasoning: Looping turns extra compute into extra “thinking depth” without adding parameters. LT2 shows how to keep this advantage while also scaling to long contexts efficiently.
In short, LT2 shows that looped transformers can be both smart and fast: by combining looping with linear and sparse attention, we get models that reason deeply, read far, and stay affordable to train and serve.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes LT2 (Linear-Time Looped Transformers) with linear, sparse, and hybrid attention inside weight-shared loops, and evaluates at 0.6B–1.3B parameters on FineWeb-Edu and several benchmarks. The following open issues remain unaddressed or insufficiently explored:
- Loop count vs. performance/efficiency trade-offs
- No systematic scaling study of loop iterations T beyond T=4 for language modeling; unclear how accuracy, latency per token, and efficiency evolve as T increases at fixed parameters and compute.
- No guidelines on optimal T for a given sequence length L, sparse window w, or task class (e.g., reasoning vs. retrieval).
- No analysis of diminishing returns or overfitting/instability as T grows.
- Theory-to-practice gaps in DPLR expressivity gains
- The “rank-T” memory gain for DPLR linear attention assumes loop-wise diversity (e.g., orthogonal keys); practical mechanisms ensuring sufficient diversity across loops (e.g., loop embeddings, per-loop gates, or parameter perturbations) are not analyzed or validated.
- Absent empirical diagnostics measuring key-vector diversity across loops and its correlation with performance and state-tracking capability.
- No robustness analysis under finite precision: how numerical errors and quantization affect rank growth and memory erasure/addition over multiple loops.
- Receptive-field expansion for sparse attention
- The O(Tw) receptive-field expansion is shown for sliding windows; no theoretical or empirical extension to top-k schemes (NSA/DSA) where index selection can be discontinuous or error-prone.
- Lack of error-propagation analysis across loops for sparse/top-k attention: how indexing mistakes accumulate or self-correct when information is “hopped” across windows/loops.
- No ablation on the minimal T or w required to achieve specific effective context lengths on realistic tasks.
- Hybrid design space incompletely explored
- Hybridization was studied at a fixed T and limited patterns; missing: per-head or per-token mixer selection, adaptive mixer switching conditioned on content, or learning the hybrid schedule.
- No exploration of mixed granularity within a loop (e.g., sparse in lower layers, linear in upper layers) at different T, nor of joint schedules that co-optimize depth- and loop-level mixing.
- The “random sample + majority vote” hybrid is promising but computationally expensive; no attempt to approximate its benefits with cheaper ensembling or stochastic routing.
- SDPA output gate and looped softmax attention
- The gate improves stability and accuracy, but the additional compute/latency cost and potential calibration effects are not quantified.
- Not analyzed: interaction between SDPA gating and the per-loop residual gate, and whether similar gating is useful for sparse softmax blocks (NSA/DSA) under extreme long-context settings.
- No study of whether gating reduces attention-sink issues in instruction-tuned or RLHF models, or impacts factual calibration and uncertainty estimation.
- Per-loop residual gate (ρτ) and optimization dynamics
- The paper introduces a zero-initialized, per-loop residual gate but does not ablate its necessity, learned values, or impact on stability and generalization.
- Missing gradients/activation analyses to explain how ρτ modulates effective depth, gradient flow, and sink propagation across loops.
- Training-time compute and memory
- The study reports inference prefill/decode throughput and OOM limits on a single H100; there is no measurement of training throughput, activation memory, or end-to-end wall-clock efficiency across variants.
- No multi-GPU/node scaling results or discussion of data/model/pipeline parallelism overheads for looped models vs. baselines.
- Absent energy/efficiency comparisons (e.g., tokens/Joule) and kernel/hardware portability beyond NVIDIA/H100 (e.g., A100, AMD, TPU).
- Long-context performance beyond 32k and across tasks
- Evaluation tops out at 32k context; no evidence for 64k–1M-token behavior or extrapolation beyond train lengths for LT2 and hybrids.
- The long-context retrieval section is incomplete; comprehensive assessments on LongBench/RULER/InfiniteBench, multi-needle tasks, and information-dense retrieval are missing.
- Task coverage and generalization
- Benchmarks focus on zero-shot general NLP; there is limited coverage of math/coding (e.g., GSM8K/MATH/HumanEval), multilingual, reasoning-heavy suites (BBH/AGIEval), or instruction-following.
- No evaluation of post-training (SFT, DPO, RLHF), robustness (adversarial prompts, perturbations), or factuality/calibration under long context.
- Data scaling and compute-optimality
- Models are trained on 100B tokens at non-optimal Chinchilla ratios (4×–8×); it is unknown whether the observed Pareto gains persist under compute-optimal budgets and larger datasets.
- No scaling laws with respect to parameter count, data tokens, and T to confirm asymptotic behavior of LT2 vs. baselines.
- Conversion (distillation) from full-attention LT to LT2
- The Ouro→LT2 conversion is highlighted in the abstract but details are missing: training objective(s), regularizers (e.g., state matching), data composition, and ablations on token budget and loss terms.
- Generality of the conversion: does it work for other architectures, tokenizer differences, or instruction-tuned teachers? How do compression and forgetting trade off?
- Stability and efficiency of conversion at larger scales (>1.3B), and whether conversion preserves long-context capabilities learned by the teacher.
- Sparse attention memory footprint
- DSA/NSA retain full KV caches for indexing; memory savings are smaller than linear attention and can OOM at high batch×length. A quantitative analysis of memory-time trade-offs for DSA vs. pure linear attention is missing.
- No exploration of compressed KV or learned memory for indexing to reduce O(Ld) cache while retaining DSA’s accuracy.
- Latency and user-facing decoding
- Loops increase per-token compute; while throughput is reported, user-facing tail latency and jitter (especially at small batch sizes) are not.
- No comparison to non-looped hybrids at matched quality to quantify the latency penalty of looping for interactive applications.
- Sequence-length adaptive computation
- Adaptive Computation Time (ACT) is deferred to the appendix with no main-text results; how halting policies interact with sparse/linear mixers, stability, and quality is an open question.
- Missing: policies that adapt T per-token or per-layer at inference to trade accuracy for speed under latency constraints.
- Robustness and failure modes
- Attention sinks and massive activations are diagnosed for softmax blocks; analogous failure modes for linear mixers (e.g., state explosion, drift, catastrophic forgetting) under long horizons are not analyzed.
- No study of error accumulation across loops for stateful linear mixers under distribution shift (e.g., domain or length extrapolation).
- Architectural and implementation details
- Positional encoding and its compatibility with looping (e.g., RoPE drift across loops) are not ablated for long-context extrapolation.
- Kernel availability and reproducibility: fused GDN and DSA “lightning indexer” may be hardware- or vendor-specific; open-source kernel maturity and portability are unclear.
- Quantization and low-precision (FP8/INT8) readiness with loops and linear-state updates are not evaluated.
- Fairness of comparisons
- Baseline selection (“industry-level 1B–4B”) lacks explicit model lists, pretraining corpora, and training budgets; comparability may be confounded by data quality and token counts.
- Variants are matched by parameter count, but not all are matched by training compute/FLOPs; the effect on “Pareto frontier” claims is not disentangled.
- Limits of the synthetic state-tracking + recall task
- Only a single synthetic programmatic task is used; broader algorithmic generalization (e.g., stack/queue emulation, formal languages beyond transpositions) is not explored to validate the claimed expressivity gains.
- No per-loop interpretability or mechanistic probing to confirm that loops implement the hypothesized rank-T memory updates or multi-hop sparse propagation.
- Applicability beyond autoregressive LM
- Encoder–decoder or bidirectional settings, multimodal inputs, and streaming speech are not evaluated; it is unclear how LT2’s benefits translate to those regimes.
- No assessment of retrieval-augmented generation or external-memory integration with LT2 loops.
These gaps suggest concrete next steps: (1) multi-scale T×L×w×data scaling studies with latency/energy reporting, (2) principled loop-diversity mechanisms and diagnostics, (3) rigorous long-context evaluations (≥128k tokens) including top-k sparse variants, (4) detailed, reproducible conversion/distillation protocols, and (5) broader task coverage (reasoning, code, multilingual, instruction tuning) and robustness analyses.
Practical Applications
Immediate Applications
The following items describe real-world uses that can be deployed now, mapping the paper’s findings to concrete products, workflows, and sectors. Each item ends with assumptions/dependencies that may affect feasibility.
- Software and AI infrastructure (serving platforms, model providers)
- Drop-in long-context serving with LT2-hybrid (GDN+DSA) to replace full-attention looped transformers for 8k–32k tokens, achieving 3–5× higher decode throughput and flat throughput vs. context length. Tools/workflow: adopt the LT2 GitHub implementation, load the Ouro-hybrid-1.4B checkpoint, or convert existing looped models using the paper’s conversion recipe (~1B token continued training). Assumptions/Dependencies: fused kernels for GDN and a sparse top-k indexer (DSA/NSA or equivalent), integration into inference servers (e.g., FlashAttention fallback not required for linear-time paths), CUDA/Triton support, scheduling for T loop steps.
- Cost and capacity optimization for multi-tenant inference. Replace per-layer KV cache growth with small, fixed-size linear states to push batch size and prevent OOM at long contexts. Tools/workflow: memory planner that budgets per-layer recurrent state; autoscaling based on flat decode cost. Assumptions/Dependencies: GPU memory profiling; DSA still maintains KV cache for selection, so hybrid choices matter; licensing/implementation of sparse indexers.
- Enterprise knowledge management and search (legal tech, consulting, pharma/regulatory)
- Long-document QA/summarization without heavy RAG orchestration. Use LT2-hybrid (GDN+DSA) to directly process 32k token briefs, contracts, clinical protocols, and regulatory filings. Tools/workflow: plug into LangChain/LlamaIndex pipelines; reduce chunking/round-trips; cache only small linear states. Assumptions/Dependencies: domain adaptation (LoRA/PEFT), evaluation for citation faithfulness, sparse indexer tuned for domain structure.
- Contact centers and ASR analytics (software, CX)
- Streaming call summarization and state tracking across multi-hour transcripts using LT2-linear (GDN) to maintain conversational state while reading long audio transcripts. Tools/workflow: ASR front-end + LT2 summarizer; extraction of intents, actions, commitments. Assumptions/Dependencies: streaming tokenizer alignment; gating enabled to prevent drift/attention sinks; latency budgets managed by loop count T.
- Healthcare (providers, health IT, medtech)
- EHR timeline summarization and discharge note drafting from long, heterogeneous patient histories on on-prem GPUs. Tools/workflow: fine-tune 1–2B LT2-hybrid models on de-identified notes; integrate with clinical viewers for “explain-while-scroll.” Assumptions/Dependencies: strict privacy controls; medical QA validation; domain tokenization; clinical evaluation sign-off.
- Finance (asset management, research, compliance)
- Earnings-call and 10-K summarization; cross-document risk tagging with long spans; transaction-log anomaly triage using linear-time streaming state. Tools/workflow: batch summarization at 32k; incident investigation assistant that scans weeks of logs in-session. Assumptions/Dependencies: on-prem deployment; compliance approval; backtesting; reliability under distribution shift.
- Cybersecurity and observability (SIEM, AIOps)
- Real-time triage over high-volume logs using LT2-linear to keep bounded recurrent state and expand coverage through loops (compute-into-context). Tools/workflow: connector for JSON/telemetry tokenization; alert grouping and root-cause hypotheses. Assumptions/Dependencies: schema variability; stable fused kernels on production GPUs; alerting thresholds.
- Robotics and edge AI (manufacturing, drones, consumer devices)
- On-device small LMs for planning and instruction-following with limited memory footprint using LT2-linear or LT2-hybrid (Full+GDN at a 1:4 ratio) for better reasoning at fixed memory. Tools/workflow: quantized 1B-class LT2 on Jetson/embedded GPUs; loop count T tuned to latency. Assumptions/Dependencies: kernel availability on ARM/embedded; quantization-aware fine-tuning; thermal/power constraints.
- Education and productivity (edtech, office suites)
- Personal tutors and document assistants that can read entire chapters or long email threads locally, avoiding cloud costs and OOM. Tools/workflow: desktop/mobile apps embedding LT2-hybrid checkpoints; “read-all-then-answer” mode for long PDFs or threads. Assumptions/Dependencies: 4/8-bit quantization; device GPU/NPUs; prompt safety filters.
- Software engineering (devtools, code intelligence)
- Long-context code review and refactoring across large diffs with flat decode cost. Tools/workflow: IDE plugin using LT2-hybrid with sparse indexer for exact reference lines + linear mixer for global compression. Assumptions/Dependencies: tokenizer suited for code; sparse top-k indexer tuned to code anchors; side-channel access to repository context.
- Research and academia (ML systems, theory, NLP)
- Training-stability improvements via SDPA output gate in looped and standard transformers to suppress attention sinks and activation spikes. Tools/workflow: add head-wise sigmoid gate post-SDPA; monitor first-token mass, residual RMS, and gradient norms as in the paper’s diagnostics. Assumptions/Dependencies: minor model surgery and re-training/fine-tuning; ablation to maintain parameter parity.
- Expressivity studies and benchmarks using the paper’s DPLR rank-T and Tw receptive-field analyses. Tools/workflow: release of synthetic state-tracking+recall tasks; comparison suites for loop counts and mixer families. Assumptions/Dependencies: reproducible kernels; matched training budgets.
- Migration and conversion services (vendors, platform teams)
- Convert existing looped transformers into LT2-hybrid with ~1B token continued training to keep quality and gain linear-time efficiency (as in Ouro-hybrid-1.4B). Tools/workflow: distill-and-tune pipeline; eval harness for zero-shot benchmarks; rollout guardrails. Assumptions/Dependencies: access to training corpus; compute budget; license compatibility; monitoring throughput/quality deltas.
- Retrieval-augmented generation (RAG) optimization (software, search)
- “Internal retrieval” hybrid: use DSA to select exact KV positions while GDN compresses global context, reducing external RAG calls. Tools/workflow: prompt-constrained top-w internal selection; smaller vector-store queries; fewer tool calls. Assumptions/Dependencies: indexer latency; window w tuning vs. loop count T; evaluation for hallucination/citation.
- Sustainability and cost (cross-sector operations)
- Immediate carbon and cost reductions by shrinking FLOPs and KV-cache memory for long-context inference. Tools/workflow: emissions tracking dashboards that compare LT vs. LT2-hybrid at equal quality; procurement checklists favoring subquadratic attention. Assumptions/Dependencies: emissions measurement; comparable benchmark tasks; stakeholder buy-in.
Long-Term Applications
These uses need additional research, scaling, or ecosystem development but are enabled by the paper’s methods and theoretical insights.
- Million-token and beyond context processing (software, scientific computing)
- Scale loops T and/or hierarchical loop schedules to turn “compute into context” (effective receptive field ~Tw), enabling whole-repository code understanding or multi-document scientific synthesis. Tools/workflow: curriculum schedules for loop counts; hierarchical sparse windows. Assumptions/Dependencies: stability at larger T; new kernels to amortize loop overhead; evaluation datasets at 100k–1M tokens.
- Adaptive computation time (ACT) for loops (platforms, interactive apps)
- Token-wise dynamic loop counts trading latency for quality on-the-fly (stop looping early when confident). Tools/workflow: ACT controllers; per-token confidence heads; scheduler integration. Assumptions/Dependencies: training with ACT loss; careful calibration; real-time serving policies.
- Multimodal long-sequence models (media, autonomous systems)
- Linear/sparse looped architectures for video and audio streams (hours) enabling continuous captioning, meeting analysis, and multimodal reasoning. Tools/workflow: modality-specific tokenization; cross-attention hybrids for sparse visual anchors + linear audio state. Assumptions/Dependencies: kernel support for multimodal blocks; datasets; synchronization across modalities.
- On-device foundation models at scale (mobile, XR, automotive)
- 1–4B LT2-hybrid models running privately on consumer hardware with long-context personal memory. Tools/workflow: NPU/GPU kernel ports for GDN/DSA; quantization and sparsity-aware compilation; state checkpointing. Assumptions/Dependencies: mobile hardware support; energy budgets; background scheduling; privacy UX.
- Healthcare decision support over lifetime records (health systems, payers)
- Cohort and patient-level reasoning over years of notes, labs, and imaging reports with verifiable retrieval and compact memory. Tools/workflow: clinical adapters; structured retrieval heads; audit trails. Assumptions/Dependencies: rigorous clinical validation and regulation; robust de-identification; bias and safety monitoring.
- Market surveillance and high-frequency risk analytics (finance, regulators)
- Continuous stateful monitoring across long event streams with bounded memory, integrating sparse “exact lookbacks” for compliance triggers. Tools/workflow: exchange feed adapters; hybrid internal retrieval; probabilistic alerting. Assumptions/Dependencies: ultra-low-latency kernels; certification; stress testing.
- Cyber-physical planning and lifelong agents (robotics, smart infrastructure)
- Agents that maintain compact recurrent memory across missions, with occasional sparse “global re-reads” for precise recall. Tools/workflow: loop-scheduled planning; safety supervisors; memory hygiene routines. Assumptions/Dependencies: safety certification; catastrophic-forgetting mitigation; robust reset policies.
- Compiler- and AutoML-driven hybrid design (ML tooling)
- Automated search over mixer ratios, depth vs. loop placement, and loop-level schedules, guided by latency/quality targets. Tools/workflow: cost models; kernel-aware NAS; schedule compilers. Assumptions/Dependencies: accurate performance predictors; standardized kernels across hardware.
- Hardware and systems co-design (semiconductors, cloud)
- NIC/DRAM controllers and GPU instructions optimized for gated DPLR updates and sparse top-k KV reads, reducing memory bandwidth pressure. Tools/workflow: ISA extensions; on-device indexers; memory residency policies for linear states. Assumptions/Dependencies: vendor roadmaps; standardization across frameworks; ROI vs. general-purpose accelerators.
- Theory and benchmarks (academia)
- Formal bounds and practical tests for rank-T DPLR expressivity and loop-induced receptive-field expansion; robust stability criteria for looped blocks. Tools/workflow: open benchmarks spanning recall + state-tracking; activation/sink diagnostics. Assumptions/Dependencies: community adoption; consistent training budgets.
- Public policy and procurement (government, NGOs)
- Guidelines prioritizing subquadratic, loop-friendly architectures to meet carbon and cost targets in public-sector AI deployments; privacy-by-design via on-device long-context models. Tools/workflow: evaluation rubrics; lifecycle emissions accounting; interoperability profiles. Assumptions/Dependencies: policy consensus; standardized reporting; vendor compliance.
- Secure continual assistants (consumer, enterprise)
- Long-lived personal or team assistants that keep private, compact state locally, with controllable sparse re-attention to historical context. Tools/workflow: per-user encrypted state; retention policies; explainable retrieval logs. Assumptions/Dependencies: security audits; user consent and governance; drift/forgetting controls.
Notes on Cross-Cutting Assumptions and Dependencies
- Kernel availability and maturity: GDN/Delta-style DPLR updates and sparse top-k indexers (e.g., DSA) need efficient CUDA/Triton kernels across major GPUs/NPUs.
- Stability features: SDPA output gating should be enabled in any softmax-containing loop to suppress attention sinks; training recipes need to maintain parameter parity when adding gates.
- Hardware specifics: Reported speedups are on H100 (80 GB); benefits typically persist on A100/consumer GPUs but require re-validation.
- Model scale and quality: The paper demonstrates parity/superiority at 0.6B–1.3B with T=4; extrapolation to larger models or different T requires tuning of hybrid ratios (1:4 is a strong baseline).
- Sparse indexer behavior: DSA/NSA involve KV maintenance and selection heuristics; quality depends on w and latency of indexer; fallback to full attention for safety-critical paths may be required.
- Data and evaluation: Domain performance requires fine-tuning and rigorous evaluation (especially in healthcare/finance/legal); long-context datasets and metrics must match target use.
Glossary
- Adaptive computation time: A mechanism that allows models to dynamically decide how many computation steps to apply per input. Example: "we discuss adaptive computation time in the Appendix~\ref{app:act}"
- Attention FLOPs: The number of floating-point operations used by attention, a key measure of compute cost. Example: "Attention FLOPs and inference cache memory vs.\ sequence length"
- Attention sink: A pathology where a few tokens capture disproportionate attention mass, degrading performance. Example: "in particular, the attention sink"
- Chinchilla compute-optimal scaling: A scaling law prescribing parameter/token budgets for efficient training. Example: "Token budgets are relative to Chinchilla compute-optimal scaling"
- Decode throughput: The rate at which tokens are generated during inference. Example: "higher decode throughput"
- Delta rule: An update rule that constrains how much the recurrent memory changes at each step. Example: "the delta rule, which bounds updates to the recurrent memory."
- DeltaNet: A linear attention variant that updates a low-rank memory using a delta-style rule. Example: "Looped DeltaNet"
- Diagonal gate: A per-dimension multiplicative gate controlling memory retention in linear attention. Example: "is a diagonal gate"
- Diagonal-plus-low-rank (DPLR): A class of state updates combining diagonal scaling with a low-rank correction. Example: "a diagonal-plus-low-rank (DPLR) linear-attention block"
- DSA: A dynamic sparse attention mechanism that selects top‑w keys/values via a fast indexer. Example: "Looped DSA"
- Effective depth: The depth a looped model achieves after repeating shared layers multiple times. Example: "yielding effective depth "
- Effective receptive field: The portion of the sequence that can influence a position after multiple loops or layers. Example: "progressively expands the effective receptive field"
- FlashAttention-2: An optimized attention kernel that speeds up softmax attention by better memory usage. Example: "with FlashAttention-2~\citep{dao2023flashattention2fasterattentionbetter} for softmax attention"
- Fused chunkwise kernel: A fused GPU kernel that processes attention/state updates in chunks for efficiency. Example: "a fused chunkwise kernel"
- GDN: A gated DPLR linear attention mixer combining data-dependent gating with delta-style updates. Example: "Looped GDN"
- HBM: High Bandwidth Memory, the on-GPU memory whose capacity limits sequence length/batch size. Example: "exhausting $80$\,GB of HBM"
- HGRN2: A gated recurrent network variant used as a linear attention mixer. Example: "Looped HGRN2"
- KDA: A linear attention mixer that combines diagonal gating with delta-style low-rank updates. Example: "Looped KDA"
- KV cache: Cached keys and values stored during autoregressive decoding to avoid recomputing attention. Example: "KV cache keeps growing"
- Lightning indexer: A fast top‑w selection mechanism used to pick relevant key/value positions in sparse attention. Example: "top- via lightning indexer"
- Linear attention: Attention mechanisms with linear-time complexity using recurrent or kernelized updates instead of full softmax. Example: "LT2-linear with linear attention"
- Looped Transformer (LT): A transformer that reuses the same block(s) across multiple iterations to increase effective depth. Example: "Looped Transformers (LT) have emerged as a powerful architecture"
- Mamba2: A state-space/linear attention family member used as a subquadratic token mixer. Example: "Looped Mamba2"
- Massive activations: Extremely large intermediate activations that can harm stability and training dynamics. Example: "massive activations~\citep{sun2024massiveactivationslargelanguage}"
- Multi-head self-attention (MHA): The standard transformer token-mixing mechanism using multiple attention heads. Example: "multi-head self-attention (we omit pre-norm for brevity)"
- Pareto frontier: The curve of optimal trade-offs (e.g., performance vs. efficiency) where no dimension can be improved without worsening another. Example: "new Pareto frontier"
- Per-channel learned gate: A learned vector gate applied per hidden dimension across loop iterations to stabilize updates. Example: "a zero-initialized, per-channel learned gate"
- Perplexity (PPL): A standard language modeling metric measuring how well a model predicts text; lower is better. Example: "9.72 vs.\ 9.87 PPL"
- Prefill: The initial forward pass through the input context before autoregressive decoding begins. Example: "We measure prefill and decode throughput"
- RetNet: A retention-based linear attention variant with gated forgetting over time. Example: "Looped RetNet"
- RoPE: Rotary positional embeddings, a method for encoding token positions via rotations in feature space. Example: "RoPE"
- Scaled Dot-Product Attention (SDPA): The standard softmax attention computation using scaled dot-products of queries and keys. Example: "Scaled Dot-Product Attention (SDPA)"
- SDPA output gate: A learned gate applied after SDPA to mitigate attention sinks and stabilize training. Example: "the SDPA output gate"
- Sliding-window attention (SWA): Sparse attention restricted to a local window around each position. Example: "SWA-512"
- Sparse attention: Attention mechanisms that compute over a subset of tokens to reduce complexity. Example: "sparse attention"
- Subquadratic token mixer: Any token-mixing mechanism with less than quadratic time in sequence length (e.g., linear or sparse attention). Example: "subquadratic token-mixing primitives"
- Top‑k selection: Selecting the k most relevant past positions for attention to reduce compute and memory. Example: "top- KV reads"
- Weight-shared recurrence: Reusing the same layer parameters across multiple iterations to trade compute for depth. Example: "scaling depth via weight-shared recurrence"
- Zero-shot: Evaluation without task-specific fine-tuning, measuring generalization from pretraining alone. Example: "avg.\ zero-shot"
Collections
Sign up for free to add this paper to one or more collections.

