Looped Diffusion Language Models
Abstract: Masked diffusion models (MDMs) have emerged as a promising alternative to autoregressive models for language modeling, yet the effective design of transformer architectures for MDMs remains underexplored. In this paper, we show that selectively looping the early-middle transformer layers significantly improves both training efficiency and model performance in MDMs. We call this approach LoopMDM(Looped Masked Diffusion Model), which brings two key benefits: looping layers at training-time yields a depth-scaling effect without adding parameters, while varying the number of loops at inference-time enables flexible compute scaling. Despite the simplicity, the results are striking: across multiple pre-training corpora, LoopMDM matches the performance of same-size MDMs with up to 3.3 fewer training FLOPs, while its final performance outperforms them on various reasoning benchmarks, including up to 8.5 points on GSM8K. It even surpasses deeper non-looped MDMs trained with comparable per-step compute, indicating that selective looping is more effective than naive depth scaling. Furthermore, LoopMDM can scale inference-time compute by increasing the number of loops. Adaptively adjusting the number of loops throughout the sampling process further yields additional gains in compute efficiency while maintaining performance. Lastly, with attention analysis, we provide evidence that looping is effective in MDMs by promoting interactions among masked positions. Our code and weights will be publicly released.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Clear, simple explanation of “Looped Diffusion LLMs”
Overview
This paper is about making computer programs that write text (like essays or answers) smarter and more efficient. The authors focus on a newer kind of text model called a masked diffusion LLM (MDM). Their big idea is to “loop” (reuse) a small part of the model several times in a row. This gives the model extra “thinking steps” without adding more parts to it. Doing this makes training cheaper and the final results better—especially on math problems.
What questions did the paper ask?
In simple terms, the paper asked:
- Can we make text models better without making them bigger?
- What if, instead of adding more layers (which adds more parameters), we reuse the same middle layers multiple times—does that help?
- Where in the model should we loop, and how many times, to get the best results for the least training cost?
- Can we also control how much “thinking” the model does when it’s answering a question, so we can trade speed for accuracy when we want?
How did the researchers do it?
First, some quick translations of technical ideas into everyday language:
- LLM: A program that predicts the next words in a sentence or fills in blanks.
- Autoregressive model: Writes one word at a time, left to right.
- Masked diffusion model (MDM): Starts with a sentence full of “blanks” (masks) and repeatedly fills them in a little better each round—like solving a crossword puzzle step by step.
- Transformer layers: Stages in the model’s “assembly line” that process the text.
- Looping a layer: Running the same stage again and again, like going through the same checklist multiple times to refine an answer.
- FLOPs (compute): A rough measure of how much “computer effort” something takes. Fewer FLOPs = cheaper/faster.
What they built:
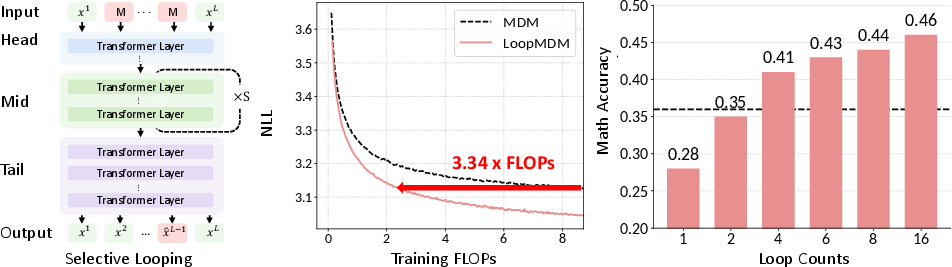
- They split the model into three parts: head (beginning), mid-block (middle), and tail (end).
- They “loop” only a few early-middle layers in the mid-block—reusing them S times in a row with the same weights. The head and tail run once.
- During training, they randomly choose how many loops to use each step (from 1 up to some maximum). This teaches the model to work well with different amounts of looping.
- To be fair, they keep total training effort the same as the baseline model (no looping) by training fewer steps when looping adds extra work per step.
- They tested different loop positions (early, middle, late), different numbers of looped layers, and different maximum loop counts to find what works best.
- They evaluated on language datasets (like OpenWebText, LM1B, FineWeb-Edu), benchmarks that measure prediction quality (perplexity/NLL; lower is better), general tasks (like question answering), and math word problems (GSM8K).
They also ran two insightful studies:
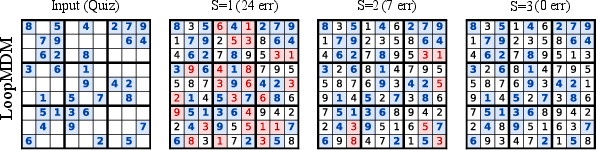
- Sudoku with a fixed left-to-right filling order (harder) to see if looping helps enforce global consistency (no contradictions).
- Attention analysis to see whether masked positions “talk to” each other more when looping increases.
What did they find, and why is it important?
Here are the main takeaways:
- Looping boosts quality while cutting training cost:
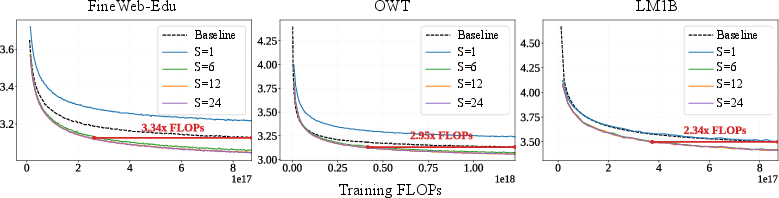
- With smart, selective looping (just a few early-middle layers), the model matched the baseline’s performance using up to about 3.3× fewer training FLOPs.
- It also improved several metrics (lower perplexity, better accuracy) on many datasets.
- Better at math reasoning:
- On GSM8K (math word problems), looping improved accuracy by up to +8.5 points compared to the same-sized non-looped model.
- It even beat deeper (taller) models that used similar per-step compute, showing looping is more than just “fake extra depth”—it’s effective reuse of reasoning steps.
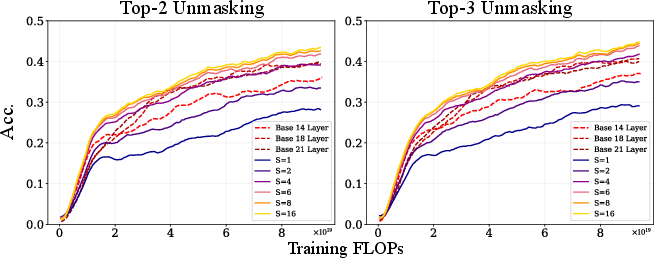
- Test-time flexibility: more loops = better answers
- You can choose the number of loops at inference time. Spending more loops is like letting the model think longer; accuracy goes up steadily as you add loops.
- Smart “adaptive” looping saves time with almost no loss:
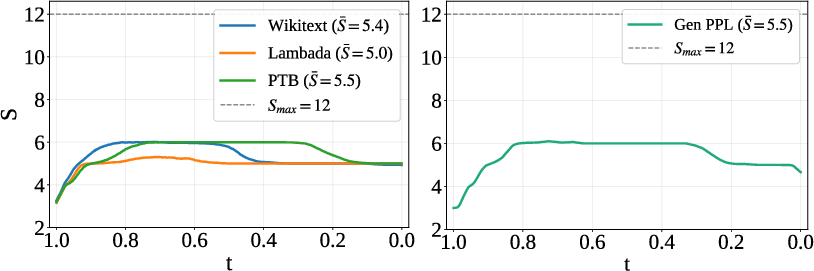
- The authors added a simple rule: stop looping when the hidden state stops changing much (i.e., when more polishing doesn’t help).
- This cut the average loops from 12 down to about 5 while almost keeping the same performance.
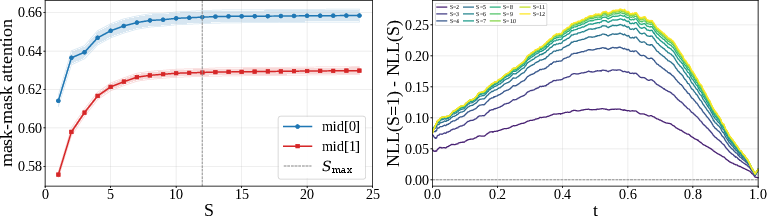
- Why looping works (insight):
- Looping increases interactions between masked positions. In plain words, the model gets better at letting the “unknown parts” of the sentence coordinate with each other before finalizing an answer.
- In Sudoku (with a strict left-to-right order), more loops fixed global contradictions and turned wrong puzzles into correct ones.
- The gains mostly happen at middle steps of the diffusion process—when the puzzle has enough clues to think productively but isn’t fully decided yet.
Why this matters:
- Training big models is expensive. Looping improves results without adding new parameters, making training more cost-effective.
- You can “pay” for more thinking only when you need it (e.g., harder questions), which is practical and efficient.
- It helps on reasoning-heavy tasks—not just memorizing facts—making models more reliable problem-solvers.
What could this change?
- Smarter scaling: Instead of always making models bigger, we can reuse parts more cleverly. That saves money and energy while improving quality.
- Flexible AI “thinking time”: Apps can choose fast answers for easy questions and slower, more careful answers for hard ones, just by adjusting loop counts.
- Better reasoning: Since looping especially helps with globally consistent thinking (like math or logic), it could improve assistants for tutoring, coding, planning, and scientific writing.
- Future directions: The results suggest there’s more to gain from designing the model’s “thinking process” (like where and how to loop) than just stacking more layers. Expect more research on adaptive loops, better loop placement, and combining looping with other reasoning techniques.
In one sentence: Reusing a small part of a diffusion-based LLM multiple times lets it “think things through” more deeply, bringing better results for less training cost—and you can dial up or down the thinking at test time to match the task.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research:
- Scaling to large models: Effectiveness and efficiency of LoopMDM at billion-parameter scales and with substantially larger training corpora are untested; compute–quality scaling laws with looping remain unknown.
- Long-context behavior: Impact of looping on models with much longer context windows (e.g., 8k–32k tokens), including memory, stability, and quality at long range, is not evaluated.
- Fair compute comparison vs autoregressive baselines: No matched-compute comparisons against strong AR models (including looped AR transformers and non-looped ARMs), leaving open whether LoopMDM’s gains persist across paradigms.
- Loops vs denoising steps trade-off: The paper shows improvements for different denoising step budgets and loop counts but does not provide a compute-normalized frontier comparing “more loops per step” versus “more denoising steps” for the same FLOPs.
- Principled loop placement: Loop positions are chosen via empirical ablation; no general method (e.g., learned placement, differentiable search, or proxy metrics) is proposed to select where and how many layers to loop across architectures/sizes.
- Convergence and theory: There is no formal analysis of the mid-block as an iterative operator (e.g., contractivity, fixed-point convergence, stability across timesteps), nor proofs of monotonic improvement with S.
- Generalization beyond training Smax: While S>Smax helps, limits of generalization, conditions under which extrapolated looping degrades, and safeguards against over-iteration are not established.
- Training schedule for S: Only uniform sampling S∼U{1,…,Smax} is studied; curricula, bias toward larger S, timestep-dependent S sampling, or learned S schedules are unexplored.
- Failure modes at high Smax: Ablations show degradation with large Smax, but mechanisms (over-smoothing, drift, instability) and mitigation strategies (gating, normalization tweaks, learned halting) are not analyzed.
- Interaction with noise schedules: Benefits may depend on αt schedule; the effect of alternative schedules (cosine/linear/learned schedules) on loop efficacy is not dissected.
- Unmasking strategies: The interplay between loop counts and unmasking order (e.g., progressive, lookahead, verifier-guided) is not jointly optimized or systematically evaluated.
- Adaptive loop control: The proposed stop rule uses a global relative hidden-state change threshold; sensitivity to ε, per-layer/per-timestep/per-token thresholds, or learned controllers (e.g., ACT-style halting) remain open.
- Per-position halting: Per-token or per-span adaptive loop counts (heterogeneous halting within a sequence) could further improve compute–quality trade-offs, but are not explored.
- Optimization stability: Effects of looping on gradient flow (vanishing/exploding), need for special regularization, gradient clipping, dropout policies across iterations, or normalization schemes are not studied.
- Activation and memory costs: Real memory footprint and activation checkpointing trade-offs with looping (training and inference) are not quantified; wall-clock speed and throughput versus FLOPs are unknown.
- Hardware efficiency: Kernel-level efficiency, KV reuse, attention caching across loop iterations, and opportunities for operator fusion to reduce practical latency are not investigated.
- Robustness and calibration: Impact of looping on calibration, uncertainty estimates, robustness to distribution shift/noisy inputs, and adversarial perturbations is not evaluated.
- Safety and bias: No assessment of toxicity, bias, or harmful content propensity; how looping affects safety characteristics is unknown.
- Multilingual/code domains: Experiments are monolingual English on web/news/science and math; transfer to multilingual settings, code generation, and domain-specific corpora is untested.
- Richer reasoning benchmarks: Beyond GSM8K/TinyGSM and Sudoku, performance on harder math and symbolic reasoning (e.g., MATH, GSM-Plus, ProofWriter) and logical constraints is not reported.
- Long-form generation quality: Human evaluations (coherence, factuality, faithfulness), discourse structure, and document-level consistency under looping are not assessed.
- Combination with deeper networks: Whether looping and additional non-shared depth are complementary (and how to co-allocate depth vs loops under fixed compute) remains open.
- Alternative parameter sharing: Comparisons to other sharing schemes inside MDMs (e.g., ALBERT-style cross-layer sharing, Universal Transformer recurrence with halting) under matched compute are missing.
- Architectural generality: Results are for diffusion transformers with RoPE; applicability to other backbones (state spaces, hybrids), different normalizations, or attention variants is unknown.
- Tokenization/vocabulary effects: Influence of tokenizer choices, larger vocabularies, and morphologically rich languages on loop effectiveness is not analyzed.
- Data scaling dynamics: How looping shifts data–compute trade-offs (e.g., fewer tokens but more per-token compute) and the resulting scaling exponents are not characterized.
- Joint budgeting of loops and unmasking/steps: A principled framework to co-optimize denoising steps, unmasking schedules, and loop counts for a fixed inference budget is absent.
- Learn-to-loop objectives: Training objectives that explicitly encourage fixed-point behavior or stability across iterations (e.g., consistency losses between successive loops) are not explored.
- Theoretical “masked workspace” claim: The k-Clique example is a proof sketch; a rigorous treatment (assumptions, compute bounds, limits) and empirical validation on real tasks are incomplete.
- Reproducibility at scale: Full hyperparameter details and results across many seeds/sizes for ablations (loop placement, Smax, nm) are referenced to appendices; robustness across seeds and datasets at larger scales needs confirmation.
Practical Applications
Immediate Applications
Below are actionable ways to apply the paper’s findings today, organized as concise use cases with sector links and feasibility notes.
- Dynamic quality/latency knobs for text generation services (software, cloud/AI platforms)
- What: Expose the loop count S as a runtime parameter to scale quality up or down per request without changing model weights.
- Why: The paper shows monotonic performance gains with higher S and strong results even beyond the trained S_max; adaptive early stopping reduces average loops from ~12 to ~5 with minimal quality loss.
- Tools/products/workflows:
- An inference SDK with an “S knob” (bronze/silver/gold tiers), plus an adaptive loop controller that stops when hidden-state change falls below a threshold.
- MLOps support to route high-S requests to batch/offline queues and low-S to real-time endpoints.
- Assumptions/dependencies: Requires a masked diffusion LLM (MDM) implementation with shared mid-block weights and hooks to measure hidden-state deltas; service must tolerate variable per-request compute and latency.
- Compute-efficient MDM pretraining and fine-tuning (industry/academia; model training)
- What: Replace non-looped MDMs with LoopMDM to match NLL at up to ~3.3× fewer training FLOPs, or to improve final quality at matched total compute.
- Why: The paper reports consistent test-NLL, perplexity, and downstream gains, especially with selective looping in early–middle layers.
- Tools/products/workflows:
- Training recipes: stochastic loop counts during training (sample S∈{1…S_max}), loop only 1–3 early–middle layers, moderate S_max.
- Compute budgeting: train for proportionally fewer steps to keep total FLOPs matched.
- Assumptions/dependencies: Gains depend critically on loop placement (early–middle), small looped block size, and moderate S_max; may need ablations to tune for each architecture/dataset.
- Reasoning-heavy assistants where global consistency matters (education, software)
- What: Use LoopMDM for math word problem solvers and structured reasoning tasks (e.g., student-facing math tutors, code completion with dependency checks).
- Why: Up to +8.5 points on GSM8K; Sudoku experiment shows looping enables within-step global consistency under constrained generation orders.
- Tools/products/workflows:
- Math tutoring/chat workflows that increase S for hard questions or uncertain segments; automatic “refinement passes” before finalizing answers.
- IDE integrations for code synthesis that allocate more loops when dependency checks fail or compile errors are detected.
- Assumptions/dependencies: Strongest gains demonstrated on math/constraint tasks; generality to all reasoning forms should be validated per use case; latency rises with S.
- Constrained document and data generation with self-consistency passes (enterprise productivity, finance, healthcare)
- What: Improve cross-section consistency in drafts (e.g., financial summaries, policy memos, clinical notes) by adding loop-based refinement passes before commit.
- Why: Mask-to-mask interactions increase with S, supporting global consistency and iterative correction before decoding.
- Tools/products/workflows:
- Drafting assistants that re-mask uncertain spans and run extra loops to harmonize terminology, figures, and references.
- Workflow trigger: escalate loop count when the system detects cross-references or discrepancies.
- Assumptions/dependencies: Requires an MDM-based generator or hybrid pipeline that leverages masked positions; domain-specific constraints (compliance, medical accuracy) still require verification layers.
- Heterogeneous deployment with one model across devices (edge/cloud; platform engineering)
- What: Ship a single parameter budget and adjust S per device or context (mobile vs. server) to meet power/latency budgets.
- Why: Parameter count is fixed while effective depth scales with loops, enabling flexible test-time compute without model variants.
- Tools/products/workflows:
- Policy engine that maps device class and SLA to loop budgets; dynamic adaptation under thermal or battery constraints.
- Assumptions/dependencies: Real-time SLAs must be respected; additional compute may be constrained on-device; requires efficient kernel support for repeated shared-layer execution.
- Faster experimental cycles for research labs and small teams (academia/startups)
- What: Achieve baseline NLL/quality with fewer training FLOPs for rapid iteration; run ablations on loop placement/size to maximize efficiency.
- Why: The paper shows matched or better performance under reduced total training compute.
- Tools/products/workflows:
- Open-source LoopMDM modules (PyTorch/JAX) with a “LayerLooper” wrapper for early–middle blocks; evaluation scripts that sweep S and report FLOPs/quality curves.
- Assumptions/dependencies: Benefits demonstrated at ~125–170M parameters; empirical validation needed at larger scales and longer contexts.
- Energy and cost reduction initiatives (cross-sector; sustainability/ESG)
- What: Use LoopMDM in training pipelines to reduce energy usage and cost per model milestone.
- Why: Up to ~3.3× fewer training FLOPs to reach comparable NLL; adaptive inference lowers average compute.
- Tools/products/workflows:
- Cost dashboards that report savings vs. non-looped baselines; green-AI disclosures that include test-time compute scaling policies.
- Assumptions/dependencies: Energy/FLOP-to-dollar conversion depends on infrastructure; may require retraining to realize benefits in legacy stacks.
Long-Term Applications
These opportunities build on the paper’s methods and insights but require additional research, scaling, or engineering.
- Large-scale and long-context applications with adaptive loop allocation (enterprise content, legal/scientific authoring)
- What: Extend adaptive loop scheduling across timesteps and sections for long documents; allocate higher S where coherence and citation integrity are critical.
- Why: The paper shows loop benefits concentrate at intermediate timesteps and that adaptive stopping preserves performance with ~2× fewer loops.
- Dependencies/assumptions: Needs validation on long contexts and domain-specific metrics (factuality, citation correctness); efficient scheduling and caching for long sequences.
- Robustness and hallucination mitigation via iterative refinement (RAG/tool-use pipelines; healthcare, finance, policy)
- What: Couple LoopMDM with retrieval and verification to re-mask and refine uncertain spans, potentially reducing hallucinations.
- Why: Increased mask-to-mask interaction and within-step refinement could help reconcile evidence under constraints.
- Dependencies/assumptions: Evidence for reduced hallucinations is not established in this paper; requires integration with verifiers and domain audits.
- Planning and control in tokenized action spaces (robotics, operations research)
- What: Apply selective looping to masked diffusion planners for discrete action sequences (e.g., high-level plans), using masks as workspace to enforce global constraints.
- Why: Sudoku and theoretical “masks as workspace” suggest stronger global consistency in constrained problems.
- Dependencies/assumptions: Requires adaptation to action-token distributions and task-specific constraints; real-time control may limit loop budgets.
- Compiler/runtime and hardware co-design for looped execution (systems, semiconductors)
- What: Optimize repeated execution of shared mid-blocks with kernel fusion, caching, and memory locality; expose loop counts natively in inference engines.
- Why: Test-time scaling with loops will benefit from reduced overhead and better throughput on GPUs/NPUs.
- Dependencies/assumptions: Needs collaboration with framework and accelerator vendors; benefits increase with model scale and loop counts.
- Generalization to multimodal discrete diffusion (vision–language, speech)
- What: Use selective looping in masked diffusion architectures for captioning, VQA, or token-based audio tasks where cross-token consistency matters.
- Why: Mechanism is modality-agnostic at the architectural level; iterative refinement and shared mid-blocks may transfer.
- Dependencies/assumptions: Requires robust multimodal tokenizers and training objectives; performance and stability must be validated.
- Adaptive, learned loop policies (AutoCompute allocation; MLOps)
- What: Learn per-timestep/position loop budgets (or stopping criteria) that optimize quality-per-FLOP, potentially via RL or meta-learning.
- Why: The paper’s heuristic thresholding is effective; learned policies could exploit richer signals (uncertainty, gradient norms).
- Dependencies/assumptions: Needs reliable proxies for quality and on-the-fly policy inference without large overhead.
- Standards and policy for compute reporting and “test-time scaling” (governance, transparency)
- What: Establish guidelines that report both training and inference compute when loops are used to scale quality, enabling fair model comparisons and sustainability claims.
- Why: Looping shifts part of “capacity” to test time; transparent reporting aids procurement and regulatory assessment.
- Dependencies/assumptions: Requires community/consortium adoption; alignment with emerging AI transparency standards.
- Cross-paradigm integration with autoregressive models (foundation models)
- What: Explore hybrid systems where MDMs with looping perform refinement over AR outputs, or where selective looping principles inform AR layer reuse.
- Why: Prior AR looped-transformer work exists, but this paper’s selective early–middle looping insights could yield better AR test-time scaling.
- Dependencies/assumptions: Non-trivial engineering and empirical validation; unclear how benefits translate across paradigms.
- Constraint-aware generators for forms, tables, and schedules (enterprise ops, public sector)
- What: Use masks as explicit workspace to fill structured artifacts under hard constraints (e.g., compliance forms, roster schedules) with iterative consistency checks.
- Why: Paper’s theory and Sudoku evidence support globally constrained inference with masks plus loops.
- Dependencies/assumptions: Requires high-precision constraint encoders and verifiers; domain approval cycles (compliance, unions, regulations) may be lengthy.
Glossary
- Adaptive looping: An inference-time technique that dynamically adjusts the number of loop iterations based on model signals to trade compute for quality. "Adaptive looping preserves performance while substantially reducing the average loop count."
- Adaptive unmasking: A decoding strategy that chooses which masked tokens to reveal based on difficulty or confidence rather than a fixed order. "MDMs can solve Sudoku near-perfectly when using adaptive unmasking orders that resolve easier cells first"
- Autoregressive models (ARMs): Models that generate tokens sequentially by conditioning on previously generated tokens. "Masked diffusion models (MDMs) have emerged as a competitive alternative to autoregressive models (ARMs) for language modeling."
- Categorical distribution: A probability distribution over discrete outcomes (tokens) parameterized by class probabilities. "We use to denote a categorical distribution parameterized by probabilities over the vocabulary."
- Denoising network: The model component that predicts clean tokens from noisy or masked inputs during the diffusion reverse process. "a denoising network predicts the clean-token distribution at every masked position."
- Denoising steps: Iterative stages in diffusion sampling where the model refines predictions from high to low noise. "MDMs already perform iterative computation across denoising steps."
- FLOPs: A compute measure counting the number of floating-point operations used during training or inference. "LoopMDM matches the performance of same-size MDMs with up to fewer training FLOPs"
- Generative perplexity: A metric evaluating the quality of generated text by measuring how well the model’s distribution aligns with sampled sequences. "Generative perplexity () across sampling steps."
- Indicator function: A function that is 1 if a condition holds and 0 otherwise, used to mask losses or operations on specific positions. "where denotes the indicator function"
- LM head: The output projection layer that converts hidden states into per-position token distributions. "the tail includes an LM head that maps the final hidden states to per-position token distributions."
- Loop count: The number of times a shared mid-block is applied within a single forward pass, controlling compute at train/test time. "producing monotonic gains as loop counts increases at inference time."
- Looped architectures: Networks that repeatedly apply a shared block to trade depth for repeated computation without increasing parameters. "Looped architectures apply a shared block repeatedly to convert depth into loops at a fixed parameter cost."
- Looped transformer: A transformer variant where certain layers are shared and iteratively reapplied to enable compute scaling. "A natural candidate from the AR literature is the looped transformer"
- LoopMDM: The proposed looped masked diffusion model that selectively loops early–middle layers to improve efficiency and performance. "We introduce Looped Masked Diffusion Model (LoopMDM), an architecture that integrates looping into the denoising network"
- Mask token: A special token indicating positions to be predicted or refined during diffusion. "the vocabulary augmented with a mask token "
- Mask-to-mask attention: Attention interactions where masked positions attend to other masked positions, facilitating joint refinement. "we measure mask-to-mask attention at two mid-block layers"
- Masked diffusion models (MDMs): Diffusion-based LLMs that iteratively denoise masked tokens to generate text. "Masked diffusion models (MDMs) have emerged as a competitive alternative to autoregressive models (ARMs) for language modeling."
- Negative evidence lower bound (NELBO): The training objective (negative ELBO) minimized by diffusion models to maximize likelihood under the generative process. "The model is trained by minimizing the negative evidence lower bound (NELBO):"
- Negative log-likelihood (NLL): A likelihood-based metric (lower is better) commonly used to evaluate model fit on held-out text. "test negative log-likelihood (NLL)"
- Per-step training FLOPs: The compute cost for a single training forward/backward pass, used to match training budgets across models. "deeper MDMs whose per-step training FLOPs match those of LoopMDM."
- Point mass: A distribution concentrated at a single value, used to express exact (non-random) token retention or masking. "We use to denote the point mass at ."
- Qwen2-style attention: An attention configuration inspired by the Qwen2 models, specifying architecture and hyperparameters for the attention mechanism. "with Qwen2-style attention"
- Rotary positional encoding: A method for encoding positional information by rotating query/key vectors, preserving attention structure across positions. "with rotary positional encoding and adaptive layer normalization"
- Test-time compute scaling: Increasing computational effort during inference (e.g., more loops) to improve performance without changing parameters. "Looping has been explored in ARMs as a form of test-time compute scaling."
- Top-2/Top-3 unmasking: Decoding heuristics where the model commits the most confident 2 or 3 tokens per step to accelerate or stabilize generation. "We evaluate accuracy with Top-2 and Top-3 unmasking under maximum token-wise probability."
Collections
Sign up for free to add this paper to one or more collections.

