Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers
Abstract: We study implicit reasoning, i.e. the ability to combine knowledge or rules within a single forward pass. While transformer-based LLMs store substantial factual knowledge and rules, they often fail to compose this knowledge for implicit multi-hop reasoning, suggesting a lack of compositional generalization over their parametric knowledge. To address this limitation, we study recurrent-depth transformers, which enables iterative computation over the same transformer layers. We investigate two compositional generalization challenges under the implicit reasoning scenario: systematic generalization, i.e. combining knowledge that is never used for compositions during training, and depth extrapolation, i.e. generalizing from limited reasoning depth (e.g. training on up to 5-hop) to deeper compositions (e.g. 10-hop). Through controlled studies with models trained from scratch, we show that while vanilla transformers struggle with both generalization challenges, recurrent-depth transformers can effectively make such generalization. For systematic generalization, we find that this ability emerges through a three-stage grokking process, transitioning from memorization to in-distribution generalization and finally to systematic generalization, supported by mechanistic analysis. For depth extrapolation, we show that generalization beyond training depth can be unlocked by scaling inference-time recurrence, with more iterations enabling deeper reasoning. We further study how training strategies affect extrapolation, providing guidance on training recurrent-depth transformers, and identify a key limitation, overthinking, where excessive recurrence degrades predictions and limits generalization to very deep compositions.
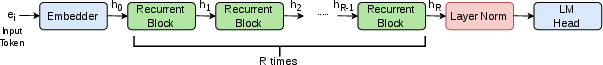
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question: Can we make AI models better at quietly “thinking things through” by letting them reuse the same mental steps more than once? The authors explore a special kind of transformer (a common AI model) that “loops” its own layers multiple times, like going through the same checklist again and again. They show this looping design helps the model combine bits of knowledge to solve multi-step problems it hasn’t exactly seen before.
The big questions the paper asks
- Can a looping transformer learn to combine facts it learned in new ways (called systematic generalization), not just repeat patterns it saw during training?
- Can it handle problems that require more steps than it practiced during training (called depth extrapolation), if we let it “loop” more times while it’s answering?
- How should we train these looping models so they learn best, and what are their limits?
How they studied it (in everyday terms)
Think of a knowledge graph like a map of people and facts, where arrows connect things. For example:
- “Imagine” → performed by → John Lennon
- “John Lennon” → spouse → Yoko Ono
Answering “Who is the spouse of the performer of Imagine?” takes two hops along this map:
- Find the performer of “Imagine” (John Lennon).
- Find John Lennon’s spouse (Yoko Ono).
The researchers built many of these “map-walking” questions, sometimes with more steps (3 hops, 5 hops, 10 hops, etc.). Then they trained two types of models from scratch:
- A standard transformer (“vanilla”) that passes input through its layers once.
- A looping (recurrent-depth) transformer that passes the input through the same layers multiple times, like doing several rounds of thinking.
They tested three kinds of generalization:
- In-distribution: Similar to problems seen in training, but not exactly the same.
- Systematic generalization: Combine facts in new ways never used during training.
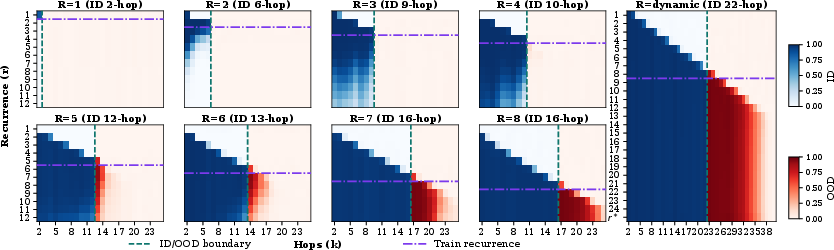
- Depth extrapolation: Solve longer chains (more hops) than the model practiced.
To keep things fair and clear:
- They used synthetic (made-up but controlled) datasets so the results weren’t influenced by messy real-world data.
- They tried different training methods: the number of loops could be fixed for every example, or randomly varied (dynamic), so the model learns to handle different amounts of “thinking.”
- They also “peeked inside” the model during its loops with a technique like a “logit lens,” which is a way to check what the model is leaning toward predicting at each step.
What they found (and why it matters)
Here are the main results:
- Looping helps the model combine knowledge in new ways:
- Standard transformers struggled to put pieces together in new combinations.
- Looping transformers succeeded at this systematic generalization.
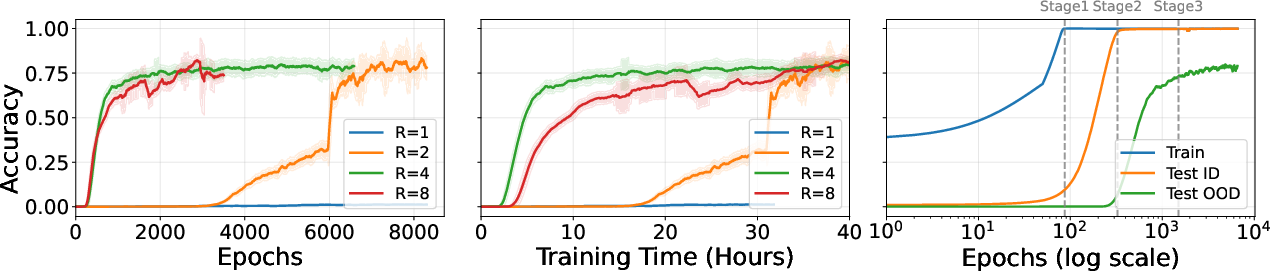
- The model’s learning follows three clear stages (a “grokking” process):
- Memorization: It remembers training examples but doesn’t generalize.
- In-distribution generalization: It starts handling new but similar examples.
- Systematic generalization: It can finally combine facts it never combined during training. This late “click” is like when a student practices for a long time and suddenly everything makes sense.
Letting the model “think longer” at test time unlocks deeper reasoning:
- If the model was trained with some number of loops, giving it more loops while answering lets it solve longer, more complex question chains.
- This only worked well if the model had enough loops during training to learn the basic rule.
- How you train the loops matters:
- Using a dynamic number of loops during training (sometimes few, sometimes many) helps the model generalize better than always using the same fixed number.
- Dynamic training got nearly the same reach as training with a high fixed loop count, but often learned more robustly.
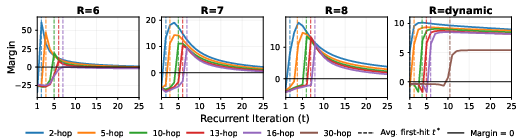
- There’s a limit: overthinking
- If you loop too many times, performance can get worse. The model starts to second-guess itself, like a person who changes the right answer after too much worrying.
- The authors studied this by tracking the model’s confidence and found it often peaks and then declines with too many loops.
- Smarter stopping helps:
- They tried an “adaptive halting” rule to decide when to stop looping. Combining two signals—“Are my answers changing much?” and “Am I confident?”—worked better than using only one. This saved time and reduced overthinking.
Why this is important
- Better reasoning without extra instructions: The looping model can combine its stored knowledge in a single pass (no step-by-step explanations needed), which is useful when we just want a fast, direct answer.
- More flexible models: Letting a model reuse the same mental steps helps it handle new combinations of facts and even tougher problems by simply allowing more “thinking” at answer time.
- Practical training advice: Varying the number of loops during training makes the model more adaptable and less fragile.
- Real-world caution: Just like people, models can overthink. We need good rules to stop them at the right time.
In short, this paper shows that “looping” transformers—reusing the same reasoning steps multiple times—can make AI better at connecting the dots, especially for problems that require chaining facts together. It also gives practical tips for training and using these models while warning about the risk of thinking for too long.
Knowledge Gaps
Below is a single, consolidated list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each point is phrased to be concrete and actionable for future research.
- External validity on real-world data: All results are on synthetic KG tasks with single-token answers; it remains unclear how recurrent-depth transformers (RDTs) perform on natural language, noisy KGs, or real QA benchmarks with multi-token outputs, ambiguity, and spurious paths.
- Interaction with pretraining: The study trains from scratch; how recurrence interacts with pretrained LLMs’ layerwise knowledge (e.g., retrofitting recurrence into existing checkpoints) and how it affects perplexity, factual recall, and downstream tasks is not evaluated.
- Scope of reasoning types: Experiments focus on compositional (multi-hop) reasoning; whether the findings extend to other reasoning families (comparison, arithmetic, algorithmic reasoning, program induction) is not tested.
- Dataset scale and topology: KGs are relatively small with fixed out-degree and a permutation constraint; the impact of larger graphs, varied degree distributions, cycles, contradictions, and long-tail/rare relations on systematic generalization and extrapolation is unknown.
- OOD split design: Systematic generalization is induced by holding out 5% of atomic facts from compositions; sensitivity to different OOD partitions (e.g., unseen relations/entities, varying OOD ratios, topology-targeted holds) is not explored.
- Length vs depth: While the paper distinguishes depth from length, it does not test long input sequences; how recurrence interacts with length generalization and long-context stability remains open.
- Architectural variants untested: The simple loop excludes input injection, gated halting (e.g., ACT/Universal Transformer), or middle-looping; whether these mechanisms alleviate overthinking and/or further improve generalization is unresolved.
- Positional encoding choices: APE is used for 2-hop and NoPE for multi-hop; the tradeoffs and generality of these choices (e.g., RoPE, ALiBi) on systematic generalization and depth extrapolation are not systematically compared.
- Layer depth (L) vs recurrence (R): All core results use L=4; the capacity–generalization trade-off when varying L while holding effective depth (L×R) or FLOPs constant is unmeasured.
- Parameter sharing granularity: The work fully shares block parameters; partial sharing, layer tying patterns, or hybrid architectures (some shared, some unique layers) and their impact on reasoning vs memorization are not investigated.
- Initialization dependence: Zero-initialization stabilizes training, but its effect on generalization and convergence vs alternative schemes (e.g., μParam, FixUp variants, scaled residuals) is not ablated.
- Supervision only at final token: The model is trained to predict only the final tail token; whether auxiliary supervision on intermediate bridge entities or multi-position losses accelerates grokking or reduces overthinking is not examined.
- Mechanistic understanding beyond logit lens: Analysis focuses on logits; deeper circuit-level interpretability (e.g., attention head roles, MLP features, shared-weight reuse patterns across iterations) is not provided, especially for multi-hop extrapolation.
- Data efficiency and scaling laws: The paper cites prior exponential data growth for vanilla transformers but does not measure how recurrence changes sample complexity with hop depth; empirical scaling laws for data vs depth under RDTs are missing.
- Non-monotonic gains with larger R: Learnable recursion depth does not increase monotonically with training-time iterations (e.g., R=7 and R=8 saturate similarly); the causes (optimization, initialization, capacity, curriculum effects) are not analyzed.
- Curriculum sensitivity: Results depend on a threshold-based hop curriculum; the effect of alternative curricula (e.g., interleaving, self-paced, anti-curricula), different thresholds, or curriculum-free training is not studied.
- Dynamic iteration sampling: Dynamic R is sampled from a clipped Poisson; sensitivity to λ, clipping bounds, and alternative sampling distributions (e.g., uniform, geometric) and their effects on both ID and OOD generalization remain unexplored.
- Overthinking remains unresolved: Although identified and partially mitigated via inference-time halting, the paper does not offer a principled training-time solution to prevent margin decay (e.g., regularizers, early-exit training, stability constraints, or learned halting).
- Halting criteria robustness: The proposed KL+entropy halting rule is heuristic; its calibration, sensitivity to thresholds, cross-task robustness, and comparison to alternatives (e.g., logit margin, hidden-state distance, external verifiers) are not thoroughly evaluated.
- Compute–accuracy trade-offs: Inference-time iteration scaling increases compute; systematic measurements of accuracy vs latency/FLOPs and cost–benefit curves under practical constraints are not provided.
- Stability under large iteration budgets: Zero-init is intended to support unbounded unrolling, but empirical stability (gradients, activations, numerical drift) for very large R and very deep compositions is not charted.
- Robustness to noise/distractors: The synthetic tasks are clean; effects of noisy facts, distractor edges, contradictory rules, and adversarial perturbations on systematic generalization/extrapolation are unknown.
- Calibration and confidence: While logit margins are analyzed, prediction calibration, confidence reliability across iterations, and the risk of confident errors under overthinking are not assessed.
- Comparisons with alternative test-time scaling: The paper does not compare recurrence to other test-time compute methods (self-consistency, multi-sampling, MCTS/Tree-of-Thoughts) for implicit reasoning with a fixed compute budget.
- Multi-task and mixed-objective training: How training RDTs on mixed reasoning tasks or combining implicit and explicit (CoT) objectives affects generalization and overthinking is not addressed.
- Security and failure modes: Overthinking suggests performance can degrade with excessive steps; the vulnerability to pathological prompts or compute-budget attacks that force harmful iteration counts is not examined.
Practical Applications
Below is an overview of practical, real-world applications that follow from the paper’s findings and methods on recurrent-depth (looped) transformers for implicit (single-pass) multi-hop reasoning. Each item links to sectors, suggests tools/products/workflows, and notes assumptions or dependencies that may affect feasibility.
Immediate Applications
- Robust multi-hop knowledge-base QA and enterprise search
- Sectors: software, enterprise IT, customer support
- Tools/products/workflows:
- Replace/augment QA backends with looped-transformer heads that can compose known facts without explicit chain-of-thought.
- Offer an inference-time “reasoning depth” knob (iterations R) per query to trade off latency vs. depth.
- Use adaptive halting (KL+entropy) to stop when confident, cutting cost/latency.
- Assumptions/dependencies:
- Transfer from synthetic to natural language/enterprise corpora requires careful fine-tuning.
- Mapping free-text to entity/relation tokens or structured representations is needed.
- Overthinking must be monitored; thresholds for halting require validation per domain.
- Compliance and rule-chaining assistants (implicit rule composition)
- Sectors: finance (AML/KYC), legal (policy cross-references), healthcare admin (coverage rules)
- Tools/products/workflows:
- Use looped transformers to compose rules stored as parametric knowledge for queries like “Does transaction X violate rule set Y?” or “Which clauses apply if…?”
- Dynamic recurrence to handle unfamiliar combinations (systematic generalization).
- Assumptions/dependencies:
- Requires curated rule corpora encoded in model parameters; provenance and auditability are critical.
- Regulatory compliance demands robust validation and human oversight.
- Potential trade-offs with memorization/perplexity must be managed.
- Cost-/latency-aware LLM APIs with an inference-time compute “reasoning knob”
- Sectors: cloud AI platforms, MLOps
- Tools/products/workflows:
- Add an API parameter for recurrence iterations and an “auto” mode using KL+entropy-based halting.
- Offer service-level tiers (e.g., fast/standard/thorough) that map to iteration budgets.
- Assumptions/dependencies:
- Requires architecture changes (shared block recurrence) and halting control; may not be drop-in for all existing LLMs.
- Overthinking can reduce quality past a point; monitoring/logging needed.
- On-device assistants that adapt compute to task complexity
- Sectors: consumer tech, mobile, IoT
- Tools/products/workflows:
- Deploy small looped models with adaptive halting to balance quality, latency, and battery.
- UI affordance to let users select “quick answer” vs “think more.”
- Assumptions/dependencies:
- Needs careful quantization and memory footprint control.
- Domain transfer from synthetic tasks to consumer QA; local safety filters.
- Training recipes for reasoning robustness in smaller/focused models
- Sectors: academia, industry ML teams
- Tools/products/workflows:
- Adopt paper’s training practices: dynamic recurrence sampling, zero-initialized projections for stability, NoPE for better generalization, and hop-based curriculum.
- Use logit-lens style diagnostics and margin tracking to detect grokking stages and overthinking.
- Assumptions/dependencies:
- Recipes proven on controlled tasks; best practices for large-scale pretraining still require empirical validation.
- Some techniques (e.g., NoPE) may interact with downstream tasks differently.
- Graph/sequence analytics for multi-hop patterns
- Sectors: e-commerce (recommendations), fraud detection, supply chain
- Tools/products/workflows:
- Treat multi-step paths (user→item→… or transactions) as token sequences; use looped transformers to infer multi-hop links or flags.
- Control hop-depth at inference by increasing iterations rather than retraining deeper models.
- Assumptions/dependencies:
- Often competes with GNNs; comparative evaluation needed.
- Requires robust tokenization/serialization of graph paths and high-quality parametric knowledge.
- Production safeguards against overthinking
- Sectors: MLOps, reliability engineering
- Tools/products/workflows:
- Implement “overthinking monitors” (e.g., logit margin peak detection) to prevent iteration beyond the confidence peak.
- Failover policies (e.g., reduce iterations, trigger retrieval, or handoff to a verifier).
- Assumptions/dependencies:
- Extra instrumentation and calibration of thresholds; may be task-specific.
- Some cases may benefit from input injection or gated halting not explored here.
- Academic benchmarks and teaching aids for compositional reasoning
- Sectors: academia, AI education
- Tools/products/workflows:
- Use the paper’s synthetic KG tasks and grokking dynamics as lab modules for studying compositional generalization.
- Integrate logit-lens analyses for interpretability exercises.
- Assumptions/dependencies:
- Requires careful curation to avoid shortcut learning and ensure reproducibility.
Long-Term Applications
- Recurrent-depth architectures in frontier LLMs for robust compositional generalization
- Sectors: cloud AI, general-purpose LLMs
- Tools/products/workflows:
- “Looped LLM” product lines with weight-sharing across depth and dynamic halting built-in.
- Training regimes that mix standard pretraining with hop-based curricula to improve systematic generalization without chain-of-thought.
- Assumptions/dependencies:
- Scaling studies needed to understand trade-offs (reasoning vs memorization/perplexity).
- Integration into massive pretraining pipelines and optimizer/initialization tuning.
- High-stakes reasoning (clinical decision support, legal analysis, scientific discovery)
- Sectors: healthcare, law, R&D
- Tools/products/workflows:
- Implicit multi-hop composition over guidelines or literature with adjustable compute per case and strict halting/policy controls.
- Hybrid systems pairing looped transformers with retrieval and verifiers for safety.
- Assumptions/dependencies:
- Regulatory approval requires interpretability, provenance, calibration, and post-hoc verification.
- Extensive domain adaptation and rigorous evaluation.
- Autonomous agents and robotics with iterative latent planning
- Sectors: robotics, logistics, manufacturing
- Tools/products/workflows:
- Use recurrence iterations as a planning horizon knob; stop when plan confidence stabilizes (KL+entropy).
- Combine with model-based control or world models for deeper extrapolation when needed.
- Assumptions/dependencies:
- Requires strong grounding to perception/action; overthinking mitigation and reliable halting are critical.
- Safety constraints on iterative planning must be formally validated.
- Compute governance and markets for “reasoning-level” SLAs
- Sectors: policy, cloud economics, sustainability
- Tools/products/workflows:
- SLA standards specifying max iterations/energy budgets per request.
- Dynamic pricing tied to iterations; green-AI reporting keyed to halting behavior.
- Assumptions/dependencies:
- Standardization efforts and third-party audits; user education.
- Fairness/access concerns if higher reasoning levels cost more.
- Hybrid neurosymbolic systems: differentiable rule engines
- Sectors: enterprise IT, databases/knowledge graphs
- Tools/products/workflows:
- Compile rule languages (e.g., Datalog) or KG path queries to looped-transformer programs that iterate the same block.
- Use inference-time iteration as a compact, learned alternative to explicit multi-step pipelines.
- Assumptions/dependencies:
- Correctness and reliability compared to symbolic systems must be proven or verified.
- Tooling for rule-to-model compilation and debugging is needed.
- Auto-curricula and training monitors for generalized reasoning
- Sectors: academia, AI training platforms
- Tools/products/workflows:
- Automated hop/complexity curricula with thresholds that trigger stage progression.
- Grokking dashboards using logit lens and margin curves to detect “phase transitions” and prevent over-training.
- Assumptions/dependencies:
- Requires scalable generation of complexity-graded tasks in natural domains.
- Potential task-specific tuning and significant compute.
- Halting controllers and architectures that reduce overthinking
- Sectors: research, model architecture design
- Tools/products/workflows:
- Learned halting modules, gated halting, input injection, or middle-looping to stabilize late-iteration behavior.
- Training objectives that penalize post-peak confidence decay.
- Assumptions/dependencies:
- Requires new benchmarks and supervision signals; stability proofs or empirical evidence at scale.
- Edge–cloud co-inference with progressive iteration offload
- Sectors: mobile/cloud, telecommunications
- Tools/products/workflows:
- Execute early iterations locally and offload deeper loops to the cloud when needed, governed by latency/energy constraints.
- Privacy-aware partitioning; bandwidth-aware halting.
- Assumptions/dependencies:
- Robust scheduling, privacy/security guarantees, and seamless model state transfer.
- Education technology with compositional tutors
- Sectors: education
- Tools/products/workflows:
- Tutors that adapt reasoning depth to student proficiency, composing concepts implicitly and stopping when confidence is adequate.
- Item generation and grading that generalize to unseen combinations.
- Assumptions/dependencies:
- Domain adaptation and tight pedagogy alignment; guardrails for correctness and bias.
Notes on cross-cutting assumptions from the paper’s scope:
- Evidence is based on controlled synthetic tasks and models trained from scratch; transfer to large-scale, natural language settings is promising but not guaranteed.
- Overthinking is a real limitation; while adaptive halting with KL+entropy helps, further architectural advances (e.g., input injection, gated halting) may be required for very deep reasoning.
- Dynamic recurrence during training improves generalization and inference-time scaling but complicates training pipelines.
- Zero-initialization of certain projections and NoPE improved stability/generalization in this work; effectiveness should be re-validated when ported to different model families or tasks.
Glossary
- Absolute position embeddings (APE): A positional encoding scheme that assigns a fixed positional index to each token. "Absolute position embeddings (APE) \citep{NIPS2017_3f5ee243} are used as positional embeddings in this setup."
- Adaptive halting: A stopping rule that terminates recurrence based on convergence/confidence of the output distribution. "Comparison of adaptive halting based on KL-divergence and entropy (ours) versus KL-divergence alone"
- Auto-regressive decoder-only model: A LLM that predicts the next token conditioned only on previous tokens, without an encoder. "we use an auto-regressive decoder-only model to predict the final tail entity ."
- Bridge entity: The intermediate entity that connects multi-hop facts and must be resolved before the final answer. "we measure at each effective depth the accuracy of predicting the bridge entity at the position"
- Causal attention: An attention mask that prevents positions from attending to future tokens to preserve autoregressive order. "where denotes the causal attention and padding masks."
- Chain-of-thought (CoT): Explicit, step-by-step natural language reasoning traces used during inference or training. "without explicit chain-of-thought (CoT) \citep{wei2022chain}"
- Compositional generalization: The ability to recombine known components (facts or rules) in novel ways not seen during training. "we investigate two compositional generalization challenges under the implicit reasoning scenario"
- Curriculum training: A training strategy that introduces tasks from easy to hard to facilitate learning. "learning -hop tasks generally requires training the model with an easy-to-hard curriculum over hop depth ()"
- Depth extrapolation: Generalizing to reasoning depths (hops) beyond those observed during training. "and depth extrapolation, i.e.\ generalizing from limited reasoning depth (e.g.\ training on up to 5-hop) to deeper compositions (e.g.\ 10-hop)."
- Dynamic iteration: Sampling the number of recurrent iterations per batch to vary compute during training. "The dynamic iteration strategy samples the number of recurrent iterations independently for each training batch."
- Dynamic recurrence: Using a variable number of recurrent passes during training to improve generalization. "We do not use dynamic recurrence in this setting"
- Effective depth: The total unrolled depth produced by reapplying the same block multiple times. "yielding an effective rolled-out depth of layers."
- Entropy: A measure of uncertainty in the model’s output distribution; lower entropy indicates higher confidence. "we additionally incorporate the entropy of the output distribution, "
- Feed-forward blocks: The transformer’s position-wise multilayer perceptron sublayers. "the output projection matrices (c_proj) of both the multi-head attention and feed-forward blocks"
- Grokking: A delayed transition from memorization to generalization after extensive training. "this ability emerges through a three-stage grokking process"
- Inductive bias: Architectural predispositions that shape what solutions a model tends to learn. "looped versions of transformer models of the same effective depth have a greater inductive bias towards reasoning"
- In-distribution generalization: Generalizing to unseen examples drawn from the same distribution as the training data. "In the second stage, in-distribution generalization emerges after prolonged training beyond memorization"
- Inference-time compute: The amount of computation allocated during inference, such as the number of recurrent iterations. "as inference-time compute (i.e., recurrent iterations) increases."
- Iso-FLOP: A comparison setting where models are matched by floating-point operation count to control for compute. "an iso-FLOP 8-layer vanilla transformer"
- Jacobian: The matrix of partial derivatives mapping inputs to outputs; stability here refers to small sensitivity to perturbations. "ensures that the input-output Jacobian remains stable even when the model is unrolled to a large number of recurrent iterations."
- KL divergence: Kullback–Leibler divergence; a measure of difference between two probability distributions. "measured by ."
- Knowledge graph (KG): A directed graph of entities and relations encoding factual triples. "Our implicit reasoning task relies on a directed knowledge graph (KG)"
- Layer normalization: A normalization applied to activations within a layer to stabilize training. "The final representation is passed through a final layer normalization"
- Length generalization: The ability to generalize to longer input sequences than those seen during training. "recurrent-depth transformers improve length generalization"
- Logit lens: A technique that maps intermediate activations to output logits to interpret internal computations. "We use the logit lens technique"
- Logit margin: The difference between the logit of the correct answer and the strongest competing logit, measuring confidence. "we analyze the logit margin, defined as the difference between the logit of the correct entity and that of the strongest competing token"
- Looped transformer: A transformer where the same block is applied iteratively, sharing weights across passes. "we use a simple looped transformer similar to \citet{saunshireasoning}"
- Mechanistic analysis: Probing and interpreting internal circuits/activations to explain model behavior. "supported by mechanistic analysis."
- Middle looping: A design where recurrence is applied to a middle portion of the layer stack rather than the whole model. "without design elements such as input injection, gated halting, and middle looping."
- No positional embeddings (NoPE): Operating without explicit positional encodings. "Here we use no positional embeddings (NoPE) \citep{kazemnejad2023impact, wang2024length}"
- Overthinking: Performance degradation from excessive iterations that distort initially correct predictions. "we identify a key limitation, overthinking, where excessive recurrence degrades predictions and limits generalization"
- Parametric knowledge: Information stored in model parameters rather than external memory or context. "a lack of compositional generalization over their parametric knowledge."
- Permutation constraint: A structural constraint that permutes mappings to prevent shortcut memorization. "We additionally impose a permutation constraint on the knowledge graph to avoid learning shortcut solutions"
- Poisson distribution: A discrete distribution used here to sample the number of recurrent iterations. "for the dynamic model we sample "
- Recurrent-depth transformer: An architecture that reuses the same transformer layers across multiple depth-wise iterations. "Such models, known as recurrent-depth transformers or looped transformers"
- Systematic generalization: Recombining known components to solve cases never seen in composed form during training. "systematic generalization, i.e.\ combining knowledge that is never used for compositions during training"
- Tied weights: Sharing parameters across different parts of the model, e.g., input embeddings and output head. "The embedding layer and LLM head (LM Head) have tied weights."
- Unrolling: Interpreting repeated applications of a recurrent block as a deeper computation graph. "this initialization supports stable optimization under unbounded unrolling of the recurrent iterations."
- Weight sharing: Reusing the same parameters across iterations or layers to encourage consistent computation. "systematic generalization in the 2-hop task already emerges from weight sharing under fixed recurrence."
- Zero-initialization: Initializing certain parameters to zero to stabilize early training dynamics. "We adopt a zero-initialization strategy to stabilize training under repeated application of shared weights."
Collections
Sign up for free to add this paper to one or more collections.