Vector Policy Optimization: Training for Diversity Improves Test-Time Search
Abstract: LLMs must now generalize out of the box to novel environments and work inside inference-scaling search procedures, such as AlphaEvolve, that select rollouts with a variety of task-specific reward functions. Unfortunately, the standard paradigm of LLM post-training optimizes a pre-specified scalar reward, often leading current LLMs to produce low-entropy response distributions and thus to struggle at displaying the diversity that inference-time search will require. We propose Vector Policy Optimization (VPO), an RL algorithm that explicitly trains policies to anticipate diverse downstream reward functions and to produce diverse solutions. VPO exploits that rewards are often vector-valued in practice, like per-test-case correctness in code generation or, say, multiple different user personas or reward models. VPO is essentially a drop-in replacement for the GRPO advantage estimator, but it trains the LLM to output a set of solutions where individual solutions specialize to different trade-offs in the vector reward space. Across four tasks, VPO matches or beats the strongest scalar RL baselines on test-time search (e.g. pass@k and best@k), with the gap widening as the search budget grows. For evolutionary search, VPO models unlock problems that GRPO models cannot solve at all. As test-time search becomes more standardized, optimizing for diversity may need to become the default post-training objective.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI LLMs to give not just one “best” answer, but a small set of different, high‑quality answers that cover different good ideas. The authors show that training for diversity helps the model work better with search methods at test time (like trying multiple answers and picking the best one). Their method is called Vector Policy Optimization (VPO).
What questions did the paper ask?
- If we know we’ll pick the best answer from several tries at test time, should we train models to produce a variety of strong answers instead of pushing them toward a single style?
- Many tasks have several scoring parts (for example, code that must pass many test cases). Can we train models to specialize different answers for different scoring parts so the set covers more possibilities?
How did they approach it?
The problem with usual training
Most current training methods (a popular one they reference is called GRPO) push a model to maximize a single score. That often makes the model very confident about one kind of answer and less willing to produce truly different alternatives. When you later ask for many samples, you get near‑duplicates, so trying more doesn’t help much.
Think of it like a talent show where the judges care about singing, dancing, and stage presence. If your coach only trains you for singing, all your routines look similar. If you get three tries, they’ll still be three singing‑heavy routines.
The main idea: Vector Policy Optimization (VPO)
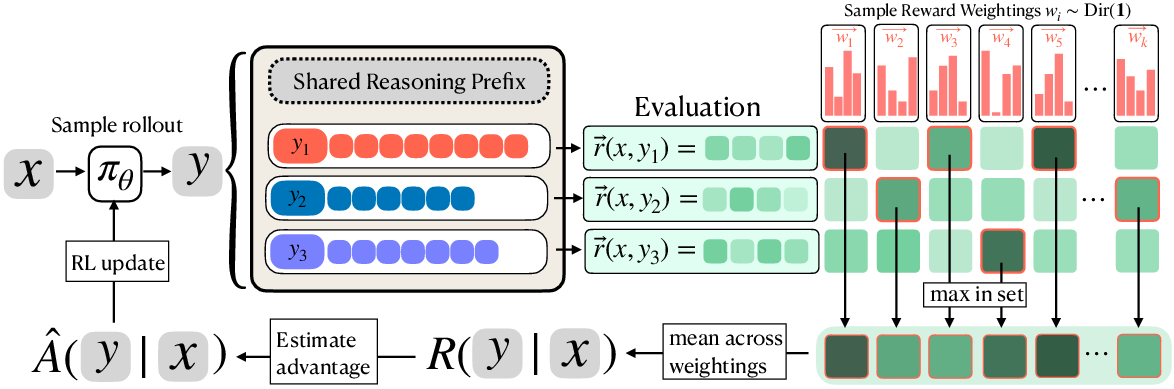
Instead of one score, VPO treats the reward as a vector—a list of several scores (like per‑test‑case correctness in coding, per‑step success in reasoning, or different parts of a tool call). Then, during training, VPO repeatedly changes how much each part matters (like spinning a dial that says “today, test case #3 matters more” or “this time, step #2 is key”). The model is rewarded for producing a small set of answers where different answers shine under different dial settings.
Analogy: You rehearse three routines. One is great at singing, one at dancing, one at stage presence. No matter what the judges care about that day, at least one of your routines fits.
How it works in practice
VPO has two simple parts:
- Multi‑answer chains: For each question, the model writes several answers in one go (separated by a special token). Each new answer can “see” the earlier ones, so it can try something different on purpose.
- Random priorities: For scoring, VPO samples random weightings over the reward parts and asks, “Under this weighting, which of the model’s answers is best?” The model gets rewarded for sets that have a winner under many different weightings. This pushes the set to cover different useful trade‑offs.
In short, VPO trains the model to produce a small “team” of answers, each specializing in different strengths, so picking the best at test time works better.
What did they test on?
They tried VPO on four very different tasks that naturally have multiple scoring parts:
- Maze navigation (collect items, avoid hazards, and reach the exit)
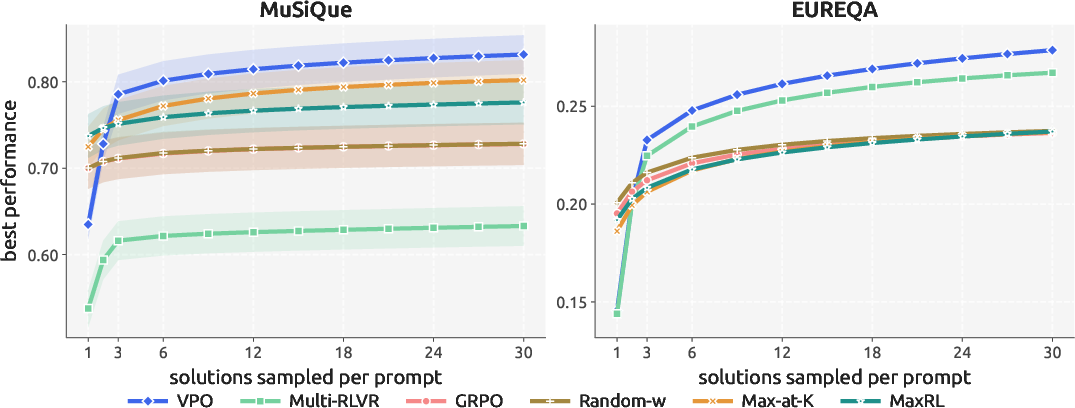
- MuSiQue (multi‑hop reading and answering)
- EUREQA (5‑step chain reasoning with five entities)
- ToolRL (calling tools correctly: right format, right tool, right arguments)
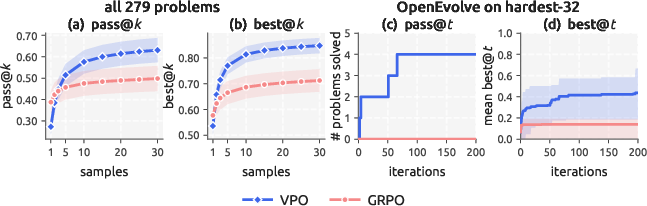
They also ran a case study on LiveCodeBench (competitive coding) and plugged the models into more advanced search like evolutionary methods (similar to AlphaEvolve/OpenEvolve).
What did they find?
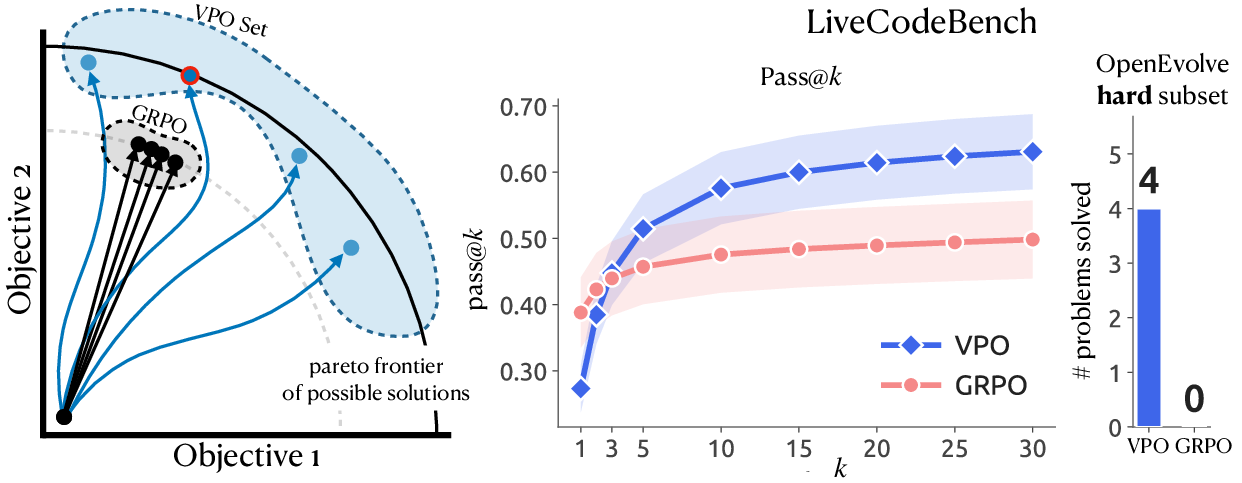
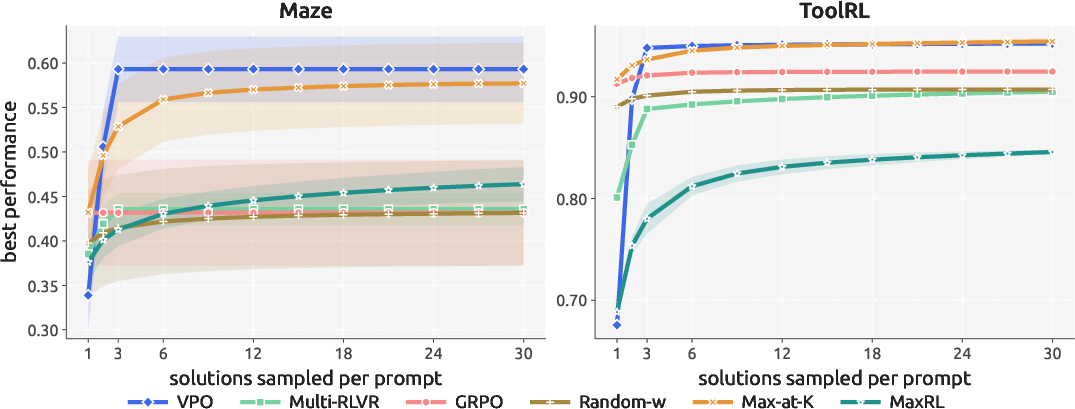
- VPO usually matched or beat strong methods that optimized a single score when you’re allowed to try multiple answers and pick the best (often called best@k or pass@k).
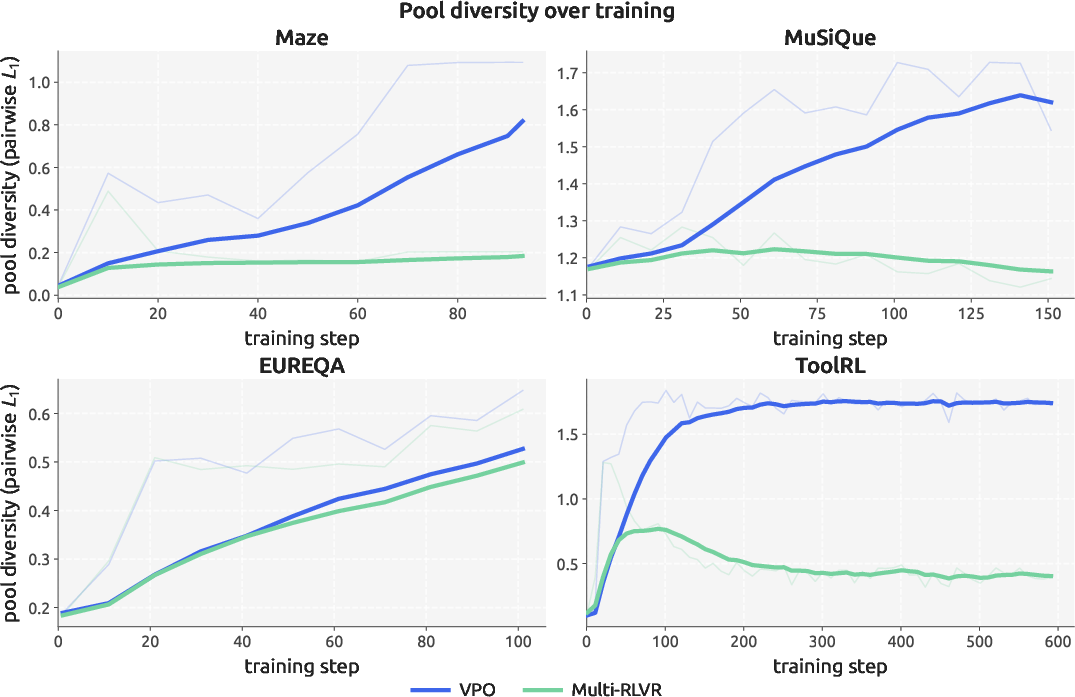
- As you allow more attempts (larger k), VPO keeps improving, while standard methods level off quickly. That’s because VPO’s answers are different in meaningful ways, not just in wording.
- In the coding case study, VPO overtook the standard method once multiple tries were allowed and even helped an evolutionary search solve problems the standard method couldn’t crack at all.
- Trade‑off: if you only allow one attempt (k=1), the single‑score method can do a bit better because it’s trained to commit to one answer. VPO is designed for settings where you can generate and then select among multiple answers.
Why this matters: Many real systems already try several model outputs and then choose. VPO trains models specifically for that reality, so search at test time becomes much more effective.
Why it matters
- Better use of test‑time search: If your system will try many answers and pick the best, you want those answers to be genuinely different and strong along different dimensions. VPO gives you that.
- Fits real tasks: Many problems are naturally multi‑part (code must pass many tests; multi‑step reasoning; tool use requires format and content correctness). VPO uses this structure instead of flattening it into one number.
- Simple to adopt: Conceptually, VPO is a drop‑in change to the usual reinforcement learning step that computes the training signal. You keep the rest of your training pipeline.
Limitations and when it might not help
- If your task truly has just one meaningful score (not several parts), VPO’s advantage shrinks.
- If you only ever take one shot at test time, standard training may be better.
- In some rare cases, the multiple scores might all point in the same direction (they’re nearly the same). Then diversity across them doesn’t add much.
Takeaway
If you plan to pick the best answer from several attempts, train your model to produce a variety of strong, specialized answers. VPO does exactly that by treating the reward as multiple parts and rewarding sets of answers that cover different trade‑offs. The result: better performance when you actually search and select at test time, especially on harder problems and with more advanced search methods.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved and could guide follow-up research.
- Theory and guarantees
- No formal analysis of the VPO objective R(S) (expected max over random scalarizations): convergence properties, optimality conditions, and when it provably improves best@k versus scalar RL remain uncharacterized.
- Unclear sample complexity and gradient variance of the Monte Carlo estimator (finite K weight samples and G rollouts), and how these affect stability/efficiency.
- Sensitivity to reward-scalarization choices
- No ablation on the Dirichlet prior over weights (α, non-uniform priors, correlated priors, or task-specific priors aligned with deployment w*); unclear how to choose α to control exploration–exploitation and pass@1 vs pass@k trade-offs.
- Lack of analysis when deployment selection differs from training’s scalarization family (e.g., non-linear or lexicographic selection at test time).
- Credit assignment within multi-answer chains
- The set-level advantage is applied uniformly to all tokens in a rollout; no exploration of per-candidate or per-weight credit assignment (e.g., gating gradients only through candidates that achieve the max under specific w, token-level weighting, or counterfactual credit assignment).
- No study of positional effects within the multi-answer chain (do later candidates specialize more, does order bias diversity, should order be randomized?).
- Hyperparameters and compute–efficiency trade-offs
- No systematic ablation of m (answers per chain), K (number of weight samples), G (rollouts per group), decoding parameters, or chain length on diversity, best@k, and compute cost.
- Unequal training compute is only partially addressed on one task; no principled compute-normalized comparison across all tasks (tokens, FLOPs, wall-time, memory), nor inference-time latency/throughput analysis for multi-answer generation.
- Robustness to reward misspecification and noise
- No experiments with noisy, biased, or adversarial reward components (e.g., imperfect verifiers, partial test coverage, or learned reward models), and how VPO’s random weightings interact with such noise.
- Not evaluated on RLHF-style settings with multiple preference heads; unclear how VPO behaves with learned, drifting, or correlated reward components.
- Applicability when vector rewards are unavailable
- VPO presumes access to a vector reward; no methods are provided to learn/decompose scalar rewards into meaningful components (e.g., unsupervised/latent factorization, multi-head reward modeling) or to operate with proxy vectors.
- Measurement of diversity and Pareto coverage
- Reward-space L1 distance is a coarse proxy; no use of Pareto-hypervolume, coverage, dominance counts, or quality–diversity metrics to confirm frontier coverage or quality–diversity trade-offs.
- No analysis of whether VPO overproduces extreme corner solutions at the expense of balanced solutions relevant to w*.
- Generality across RL algorithms
- Although claimed to be a drop-in advantage estimator, VPO is only tested with GRPO; compatibility and gains with other RLHF/RL variants (PPO-style RLHF, RPO/DPO-like objectives, off-policy or actor–critic methods) are untested.
- Interplay with search procedures
- Limited evaluations beyond simple best@k and one evolutionary method; no tests with beam search, MCTS/ToT, particle filters, reranker/verifier cascades, or dynamic-budget search to assess synergy and failure modes.
- No study of mismatch between training reward components and the selection signals used by downstream search (e.g., reranker-only, verifier-only, or multi-stage selection).
- Scaling and external validity
- Results are on small-to-mid models (1.7B–8B, one 7B coder) and relatively small evaluation splits (e.g., ToolRL n=80); lack of large-scale model and dataset validation, confidence intervals, and significance tests across all tasks.
- The LiveCodeBench case study uses one epoch and a single dataset; broader evidence on diverse code suites and alternative evolution frameworks is missing.
- Pass@1 vs pass@k trade-offs
- VPO’s degradation in pass@1 is only shown for one code setup; the extent of this trade-off, and techniques to mitigate it (e.g., annealing α toward w*, curriculum over scalarization entropy), are not explored.
- Handling collinearity among reward components
- When components are near-collinear (e.g., UltraFeedback), VPO underperforms scalars; no mechanism to detect collinearity online or adapt (e.g., orthogonalization, PCA whitening of reward heads, adaptive α to reduce unnecessary exploration).
- Safety, alignment, and constraints
- Random scalarization can underweight safety/harms components during training; there is no safety analysis, constraints, or guardrail-aware weight sampling.
- No study of how to ensure certain objectives (e.g., safety/format) are never de-emphasized (e.g., minimum-weight constraints or lexicographic rules).
- Goal-conditioned alternatives
- The negative Maze result for goal-conditioned GRPO is narrow; no exploration of stronger conditioning mechanisms (formatting, adapters, soft prompts), architectural changes, or training curricula that might make preference-conditioned policies viable.
- Domain shift in reward structure
- Unclear robustness when the set, number, or semantics of reward components change between training and deployment (e.g., new test cases, added constraints, new preference axes).
- Text-level diversity and duplication
- Only reward-space diversity is reported; no systematic analysis of text-level diversity, novelty, or duplication within multi-answer chains and across samples, and their relationship to search efficacy.
- Long-horizon and agentic settings
- Limited tests on multi-step tool use; no evaluation on long-horizon, interleaved feedback settings (planning, interaction loops) where vector rewards evolve over time and credit assignment is harder.
- Practical integration and reproducibility
- Missing details on open-sourcing code/checkpoints, full seeds/CI, and standardized compute accounting to enable reproducible and fair cross-method comparisons.
Practical Applications
Practical Applications of Vector Policy Optimization (VPO)
VPO is a drop-in replacement for scalar RL post-training estimators (e.g., GRPO) that explicitly trains LLMs to produce reward-diverse sets of competent solutions. It leverages vector-valued rewards and multi-answer chains so inference-time search (best-of-k, evolutionary methods like AlphaEvolve/OpenEvolve) can exploit this diversity. Empirically, VPO improves best@k and unlocks harder problems for search while often sacrificing pass@1. Applications are strongest where (a) verifiers or multi-criteria reward models already exist, and (b) evaluation selects from multiple candidates.
Below are actionable use cases grouped by near-term deployability versus longer-horizon potential. Each item includes sectors, product/workflow ideas, and key dependencies/assumptions.
Immediate Applications
These can be deployed today when a verifier or multi-criteria scorer is available and an inference-time search loop is acceptable.
- Software engineering: test-driven code generation and repair
- Sectors: Software, DevTools
- What to build:
- VPO-augmented code assistant that returns a diverse patch bundle per request, prioritized by unit-test coverage and static checks.
- CI “Auto-Fix” bot that proposes 3–5 distinct repair strategies (e.g., fast fix vs. refactor vs. performance-optimized) and runs tests/lint to auto-select.
- VPO + OpenEvolve/AlphaEvolve for hard coding tasks; integrate as a search-backend for existing IDE copilots.
- Workflow integration: Generate m solutions per prompt; evaluate via tests/lints; select best@k automatically or present top-2 to developer.
- Assumptions/Dependencies: Reliable unit tests/static analyzers; acceptance of higher inference compute/latency; reward components (per-test-case pass, style/perf checks) not collinear; willingness to trade pass@1 for pass@k.
- Data engineering and analytics: SQL and pipeline synthesis
- Sectors: Data platforms, BI, ETL
- What to build:
- “Diverse SQL” assistant producing multiple queries that trade off strictness vs. recall, different joins/filters; validated by schema/type checks and sample-set metrics.
- DAG/config synthesis with variant proposals validated by compile-time checks and dry-runs.
- Workflow integration: Return 3–5 candidates; auto-run explain/validate; pick best; log diversity metrics.
- Assumptions/Dependencies: Schema validators, execution sandboxes, per-metric scores (accuracy, coverage, cost).
- Tool-use and API orchestration
- Sectors: Agent frameworks, Customer ops, RPA
- What to build:
- Function-calling agent that outputs a set of candidate tool calls with structurally valid arguments; select via structural/F1 scoring (as in ToolRL) and downstream outcome checks.
- Multi-step tool plans: produce diverse plan variants (fewer calls vs. safer calls vs. richer context) scored per criterion (cost, latency, expected success).
- Workflow integration: Multi-answer chains per step; programmatic validators; best@k or short evolutionary refinements.
- Assumptions/Dependencies: Robust structure validators, API simulators/sandboxes, multi-criterion scoring.
- Retrieval-augmented multi-hop QA with citations
- Sectors: Knowledge management, Search
- What to build:
- “Cite-then-answer” assistant that emits multiple answer chains, each with different supporting paragraphs; select by per-hop citation correctness and final-answer F1 (akin to MuSiQue).
- Workflow integration: Produce m chains; score hops and answer; pick best; optionally return top-2 for transparency.
- Assumptions/Dependencies: Passage recall quality; per-hop correctness heuristics; gold or proxy F1 metrics.
- Creative operations with compliance constraints
- Sectors: Marketing, Product, Legal/compliance
- What to build:
- Ad/UX copy generator producing Pareto-diverse drafts balancing engagement, brand tone, regulatory compliance; select via multi-criteria reward model (style, clarity, policy risk).
- Workflow integration: Generate variants; automatic red-line/compliance checks; re-rank by composite weights; human-in-the-loop pick.
- Assumptions/Dependencies: Reliable reward models per criterion; agreement on weightings; audit logging.
- Safety evaluation and red teaming
- Sectors: AI safety, Trust & Safety
- What to build:
- Diversity-seeking red-team generator that spans safety objectives (toxicity, jailbreak likelihood, policy-specific risks) to produce a broad threat surface for evaluation.
- Workflow integration: Generate m adversarial prompts/responses; score by multi-criteria harm models; select hardest cases for triage.
- Assumptions/Dependencies: Calibrated safety reward models; careful governance; robust logging.
- Education: multi-path tutoring and solution exploration
- Sectors: EdTech
- What to build:
- Tutor that presents multiple solution paths (algebraic vs. geometric reasoning; with/without hints) and selects one matching a rubric (correctness, step clarity, citation of principles).
- Workflow integration: Show top-2 diverse explanations; teacher dashboard shows reward-space diversity to personalize instruction.
- Assumptions/Dependencies: Per-step rubrics/graders; acceptance of multiple drafts; compute budget per query.
- Formal methods and theorem proving
- Sectors: Academia, Verification, Critical systems
- What to build:
- Proof-assistant helper (Lean/Isabelle/Coq) producing diverse proof attempts/lemmas; select via proof checker and auxiliary metrics (proof length, readability hints).
- Workflow integration: Generate m proofs; check; keep best; optionally evolve with rewrite mutations.
- Assumptions/Dependencies: Fast checkers; structured partial credit (per-subgoal solved) to form vector rewards.
- RLHF and preference modeling with interpretable criteria
- Sectors: AI alignment, Platform policy
- What to build:
- RLHF pipelines using interpretable, per-criterion reward models (helpfulness, harmlessness, honesty) so VPO learns sets spanning the Pareto front; test-time selection tunes to deployment weights.
- Workflow integration: Replace scalar advantage estimator with VPO; monitor reward-space diversity; inference uses best-of-k under deployment weights.
- Assumptions/Dependencies: Decomposed preference models; non-collinear criteria; governance to set weights.
- MLOps and evaluation analytics
- Sectors: ML Platform
- What to build:
- Training/eval dashboards that track reward-space diversity and best@k curves; alerts when diversity collapses post-RL.
- Workflow integration: Add diversity metrics to regression tests; gate deployment on best@k improvements rather than pass@1 alone.
- Assumptions/Dependencies: Multi-criteria reward logging; cost budget for k>1 sampling.
Long-Term Applications
These will benefit from further research, scalable verifiers/simulators, regulatory approval, and integration into higher-stakes workflows.
- Clinical decision support with multi-criteria evaluation
- Sectors: Healthcare
- What to build:
- Systems that propose diverse care plans balancing efficacy, risk, cost, patient preference, and guidelines; select with evidence-based scoring and clinician oversight.
- Assumptions/Dependencies: Clinically validated vector rewards; strong simulators/decision-support models; regulatory approval; rigorous safety guarantees.
- Robotics and embodied agents
- Sectors: Robotics, Manufacturing, Logistics
- What to build:
- Task planners that output diverse action sequences trading off safety, energy, task time, and wear; simulators score candidates; search refines.
- Assumptions/Dependencies: High-fidelity sims; reliable per-objective instrumentation; real-world transfer; latency constraints.
- Finance: portfolio construction and strategy exploration
- Sectors: Finance, WealthTech
- What to build:
- Advisors producing diversified strategy sets along the efficient frontier (risk, return, liquidity, ESG); selection tailored to client weights.
- Assumptions/Dependencies: Robust backtesting/risk models; compliance; live data quality; governance over objective weights.
- Energy systems and scheduling
- Sectors: Energy, Utilities
- What to build:
- Dispatch/scheduling assistants generating candidate schedules across cost, emissions, reliability; grid simulators or digital twins evaluate and select.
- Assumptions/Dependencies: Accurate simulators; real-time constraints; safety-critical validation; multi-stakeholder weighting.
- Scientific discovery and automated experimentation
- Sectors: R&D, Pharma, Materials
- What to build:
- Hypothesis/design generators producing diverse candidates (e.g., synthetic routes, protein designs) scored by multi-objective predictors (yield, toxicity, novelty); search loops refine.
- Assumptions/Dependencies: Trustworthy surrogate models/lab automation; IP and safety governance; feedback latency handling.
- Autonomous software agents and self-healing systems
- Sectors: DevOps, Cloud
- What to build:
- Long-running agents that continuously evolve fixes/features via evolutionary search; VPO-trained models seed diverse, high-quality proposals for each iteration.
- Assumptions/Dependencies: Safe sandboxes; rollbacks; strong observability; cost controls.
- Public policy and urban planning assistants
- Sectors: Government, NGOs
- What to build:
- Systems drafting policy options that explicitly trade off equity, cost, impact, feasibility; human committees select from Pareto-diverse drafts.
- Assumptions/Dependencies: Transparent, audited reward models; participatory governance; bias assessments.
- Legal research and argument generation
- Sectors: LegalTech
- What to build:
- Tools proposing diverse argument lines (precedent strength, novelty, readability, risk) with automated citation checks; selection by legal teams.
- Assumptions/Dependencies: High-precision citation/precedent validators; ethical guidelines; liability considerations.
- Personalized assistants for long-horizon planning
- Sectors: Consumer apps
- What to build:
- Travel/fitness/education planners offering multiple plans along user-tunable weights (cost/time/experience/safety); background search refines choices.
- Assumptions/Dependencies: Reliable scoring of plans; user preference elicitation; compute for multi-candidate search.
- Multi-agent strategy discovery
- Sectors: Games, Market design
- What to build:
- VPO-trained agents that maintain diverse strategies optimal under different payoff weightings; tournaments or meta-search select/evolve equilibria.
- Assumptions/Dependencies: Stable multi-agent sims; safety/anti-collusion controls; clear objective decompositions.
Cross-Cutting Notes on Feasibility and Trade-offs
- Where VPO shines:
- Tasks with verifiable, decomposable rewards (e.g., per-test-case code, per-hop citation correctness, tool-call structure and content scores).
- Settings that already use or can adopt inference-time search (best-of-k, evolutionary loops).
- Problems with genuine trade-offs (non-collinear reward components, a broad Pareto front).
- Dependencies and assumptions:
- Requires vector-valued reward instrumentation or interpretable multi-criterion reward models; gains shrink when components are near-collinear or only a scalar reward is available.
- Increased inference-time compute/latency to sample k>1; engineering needed to amortize costs (e.g., m-answer chains share context).
- VPO typically reduces pass@1 while improving pass/best@k; use when multi-sample selection is acceptable.
- Reliable verifiers/simulators are critical in high-stakes domains (healthcare, energy, finance, robotics) and may need regulatory approval.
- Integration tips:
- Start by swapping GRPO’s advantage estimator with VPO in existing RLHF/RLAIF pipelines where vector rewards are available.
- Expose best@k and reward-space diversity metrics in eval dashboards; use diversity collapse as a regression signal.
- Pair with search-time procedures (best-of-N, self-consistency, ToT, evolutionary methods) to realize the full benefit.
Glossary
- Advantage estimator: A function that estimates how much better an action is than a baseline, used to compute policy-gradient updates. "VPO is essentially a drop-in replacement for the GRPO advantage estimator,"
- AlphaEvolve: An evolutionary test-time search procedure that iteratively refines candidate solutions produced by a LLM. "inference-scaling search procedures, such as AlphaEvolve,"
- ArmoRM-5: A specific learned reward model used to score LLM outputs across multiple dimensions. "under ArmoRM-5 reward model"
- Autoregressive rollout: Generating tokens sequentially so each token conditions on the previously generated context during a single model run. "within a single autoregressive rollout."
- Best-of- sampling: Inference strategy where multiple samples are drawn and the highest-scoring one is chosen. "Best-of- sampling"
- best@: Evaluation metric that takes the maximum (scalarized) reward among sampled candidates. "VPO consistently improves best@ relative to scalar baselines."
- Dirichlet distribution: A probability distribution over the simplex, used here to randomize weight vectors for scalarizing vector rewards. ""
- Evolutionary search: Optimization method that iteratively mutates and selects candidate solutions, often wrapping an LLM in an outer loop. "complex evolutionary methods like AlphaEvolve"
- GDPO: A GRPO variant that normalizes advantages per reward dimension to avoid domination by high-variance components. "GDPO addresses this by normalizing the advantage per reward dimension before aggregating."
- Goal-conditioned policy: A policy that takes a target preference vector (e.g., reward weights) as input and aims to optimize according to it. "we train a goal-conditioned GRPO policy"
- GRPO: A policy-gradient RL algorithm used for LLM post-training that aggregates rewards into a scalar objective. "Policy gradient methods like GRPO drive the policy toward a narrow set of high-probability responses"
- In-context exploration: Using the model’s own previously generated candidates within the same context to steer subsequent generations toward diverse alternatives. "Multi-Answer Chains as In-Context Exploration"
- Inference-time search: Procedures applied at evaluation to select among multiple generated candidates to maximize performance. "The situation changes once inference-time search is introduced."
- Lexicase selection: An evolutionary selection method that preserves individuals excelling on different subsets of objectives rather than a single aggregate score. "lexicase selection in evolutionary computation"
- Max-at- Training: A training objective that directly optimizes the maximum reward achievable among samples drawn from the policy. "Max-at- Training"
- MaxRL: A search-aware RL objective that uses extra sampling during training to better approximate maximizing over successful rollouts. "MaxRL is another search-aware RL objective"
- Monte-Carlo reward: An empirical estimate of an expected reward computed by averaging over sampled quantities. "The per-rollout Monte-Carlo reward is"
- Multi-answer rollout: Generating multiple candidate completions in a single sequence so later answers can condition on earlier ones. "Multi-RLVR, which combines multi-answer rollouts with a fixed scalar reward"
- Multi-objective RL: Reinforcement learning with vector-valued rewards and trade-offs across multiple objectives instead of a single scalar. "multi-objective RL"
- Multi-RLVR: A method that trains LLMs to emit multiple answers per prompt while optimizing a fixed scalar reward. "Multi-RLVR, which combines multi-answer rollouts with a fixed scalar reward"
- OpenEvolve: An open-source evolutionary coding agent that performs iterative test-time search over LLM-generated code solutions. "inside the OpenEvolve search loop"
- Pareto frontier: The set of solutions that are not dominated across objectives—improving one objective would worsen another. "covering the Pareto frontier rather than converging to a single point on it"
- Particle filtering: A sequential Monte Carlo method for approximate inference using weighted samples (“particles”). "particle filtering"
- pass@: Coding metric that checks if any of generated programs passes all unit tests. "pass@"
- Policy gradient methods: RL algorithms that update a policy in the direction of the gradient of expected return. "Policy gradient methods like GRPO drive the policy toward a narrow set of high-probability responses"
- Reward model: A learned function that assigns scalar scores to model outputs to guide training or selection. "multiple different user personas or reward models."
- Reward scalarization: Converting vector rewards into a single scalar by applying a weight vector. "we replace the fixed scalarization prevalent in RL post training with a distribution over scalarizations."
- Reward diversity: Maintaining candidates that are each optimal under different weightings of reward components. "We call this property reward diversity."
- Self-consistency: An inference strategy that aggregates or selects among multiple generated reasoning paths to improve reliability. "self-consistency"
- Simplex: The set of non-negative vectors that sum to one, representing all possible convex weightings of objectives. "over the simplex "
- Stochastic decoding: Randomized generation (e.g., sampling) from a model’s output distribution. "diversity arises only from stochastic decoding"
- Stochastic scalarization: Randomizing reward-weight vectors during training to explore diverse trade-offs across objectives. "stochastic reward scalarizations"
- Tree-of-Thoughts: A search framework that expands and evaluates multiple intermediate reasoning branches before selecting a final answer. "Tree-of-Thoughts"
- UltraFeedback: A benchmark/dataset providing multi-dimensional human feedback for evaluating or training LLMs. "the UltraFeedback under ArmoRM-5 reward model"
- Vector Policy Optimization (VPO): An RL algorithm that trains LLMs to produce sets of solutions specialized to different reward trade-offs via stochastic scalarization and multi-answer generation. "We propose Vector Policy Optimization (VPO)"
- Vector-valued reward: A reward represented as a vector of components capturing different aspects of solution quality. "rewards are often vector-valued in practice"
Collections
Sign up for free to add this paper to one or more collections.

