- The paper shows that standard RL-finetuning with GRPO leads to a collapse in reasoning diversity, limiting exploration and resulting in local optima.
- It proposes MUPO, which clusters reasoning responses and applies local policy gradients with a diversity reward to maintain multiple solution pathways.
- Experimental results demonstrate that MUPO-trained models achieve up to 6% higher acc@4 on multimodal benchmarks, reflecting robust divergent reasoning.
Incentivizing Divergent Reasoning in Vision-LLMs via Multi-Group Policy Optimization
Introduction
This paper, "All Roads Lead to Rome: Incentivizing Divergent Thinking in Vision-LLMs" (2604.00479), addresses a key limitation in Reinforcement Learning (RL)-based post-training of Vision-LLMs (VLMs)—the tendency to collapse reasoning diversity. The authors systematically analyze behavioral differences between RL-finetuned models (notably trained with Group Relative Policy Optimization, GRPO) and their base counterparts. They find that while RL-finetuned models exhibit deeper single-path reasoning and higher acc@1, they rapidly lose their inherent divergent thinking ability, resulting in local optima and constrained problem-solving breadth. To tackle this, the authors propose Multi-Group Policy Optimization (MUPO), a method explicitly designed to preserve and foster divergent reasoning across multiple solution pathways. The resulting MUPO-trained VLMs achieve substantial improvements in both accuracy and the diversity of reasoning, establishing new state-of-the-art results across a suite of multimodal reasoning benchmarks.
Behavior of RL-Finetuned vs. Base Vision-LLMs
A central empirical finding is that RL-finetuned VLMs, exemplified by Vision-R1, predominantly converge on a narrow, optimized strategy for a given task (convergent thinking), while base models such as Qwen2.5-VL maintain broader reasoning trajectories (divergent thinking). When evaluated on MathVerse and MathVista, base models could often solve examples missed by RL-finetuned models, particularly under parallel test-time sampling (k>1), owing to exploration of alternative reasoning strategies.

Figure 1: Representative failure cases of RL-finetuned (Vision-R1) models, where base models provide more diverse and successful reasoning paths.
The study further introduces the acc@k metric (the accuracy if at least one of k sampled answers is correct), quantifying the effect of reasoning diversity on model performance. With higher k, base models consistently surpass RL-finetuned models; the advantage of RL models in acc@1 does not translate to superior acc@4, indicating restricted test-time scaling capability.

Figure 2: Impact of reasoning diversity on acc@k; higher diversity correlates strongly with improved acc@4, especially in base models.
Analysis of Diversity Collapse in GRPO Training
To rigorously dissect the origin of this diversity deficit, the authors study the training dynamics of GRPO. They measure pairwise cosine distances between reasoning trajectories (using Qwen3-Embedding representations) and observe a precipitous early drop in diversity—"diversity collapse". Even with limited exposure to training data (first 20 steps), models prematurely converge on a few favored paths, optimizing primarily for local maxima and neglecting broader search.
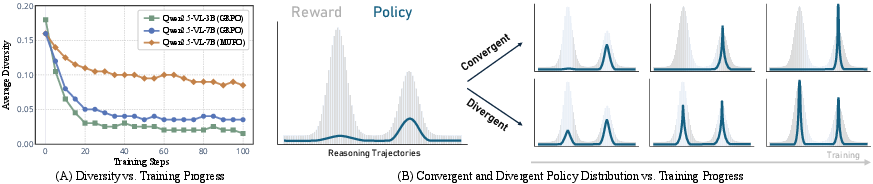
Figure 3: Diversity collapse during GRPO training—a rapid loss of reasoning diversity and a sharpening of the policy distribution toward a dominant mode.
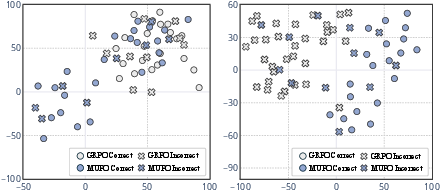
Visualization in embedding space via t-SNE highlights that RL-finetuned models cluster solutions tightly, in contrast to the dispersed (multimodal) solution structure of base models.
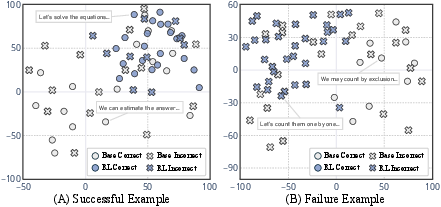
Figure 4: t-SNE projections show dense clusters for RL-finetuned models and diverse regions for base models, reflecting the divergent vs. convergent thinking dichotomy.
These results underscore a crucial theoretical issue: GRPO's on-policy optimization paradigm encourages exploitation at the expense of exploration, which limits both the breadth of generalization and test-time scalability.
Multi-Group Policy Optimization (MUPO) for Divergent Reasoning
To counteract diversity collapse, the authors introduce Multi-Group Policy Optimization (MUPO), architecturally a drop-in replacement for GRPO but optimized to preserve divergent thinking. In MUPO, responses are clustered into K groups per training example based on their reasoning embeddings, with each group representing a coherent reasoning mode. Gradient estimates and policy objectives are computed locally for each group, rather than globally. Crucially, a diversity reward—proportional to the separation in embedding space across groups—is incorporated, with annealing to prevent over-regularization or reward hacking.
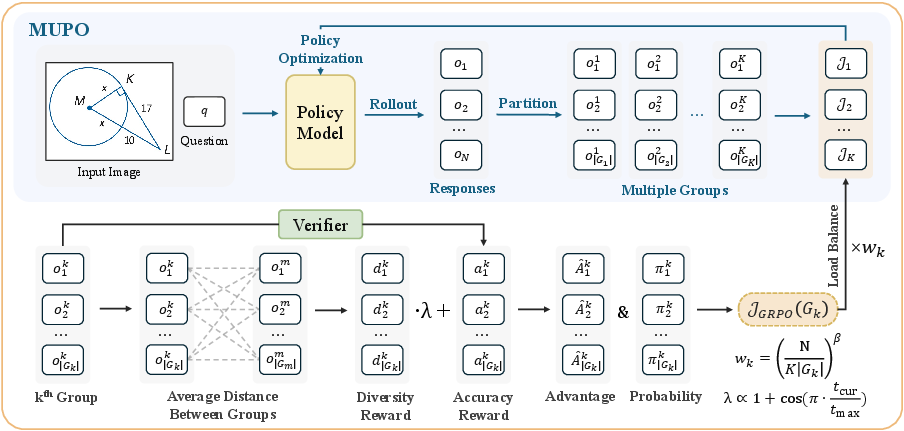
Figure 5: The MUPO pipeline—responses are partitioned into groups representing distinct reasoning trajectories, each group optimized with local advantages and inter-group diversity reward.
Empirical ablations demonstrate that the choice of group number K and diversity reward weights are critical: increasing K initially improves accuracy and diversity but eventually saturates.
Experimental Results
The MUPO-Thinker models, trained with the proposed MUPO algorithm, set new benchmarks on mathematical and general-purpose multimodal reasoning datasets. Notably:
Qualitative comparison on spatial reasoning tasks demonstrates that MUPO-trained models select contextually-adaptive strategies (e.g., combining geometric estimation with reference object reasoning), in contrast to the rigid reasoning chains of GRPO.

Figure 7: Qualitative analysis—MUPO-trained models adapt solution strategy to contextual cues, enabling effective handling of complex questions.
The training dynamics plot reveals that accuracy steadily increases as diversity reward follows a rise-fall-plateau pattern, indicating a controlled transition from exploration to exploitation.
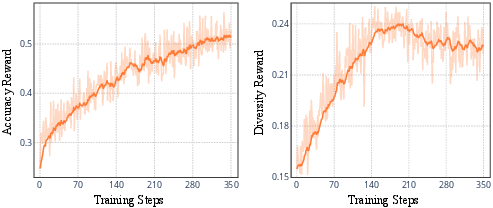
Figure 8: Learning curves of accuracy and diversity reward, evidencing MUPO’s balanced exploration-exploitation trade-off.
Ablations on reward weight demonstrate optimal trade-offs at intermediate values; excessive emphasis on diversity impairs overall accuracy, while insufficient reward leads back to convergence on unimodal solutions.
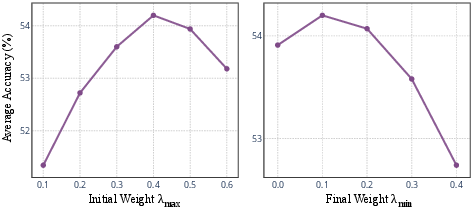
Figure 9: Sensitivity analysis of diversity reward weights on average benchmark accuracy.
Implications and Future Directions
This work exposes a core limitation of standard RL post-training (e.g., GRPO, PPO) for VLMs—namely, its failure to maintain or elicit divergent thinking necessary for strong test-time scaling and robust generalization. By formalizing and evaluating divergent reasoning and introducing MUPO, the authors provide the field with both metrics and algorithmic tools to explicitly control the exploration-exploitation spectrum during RL training. Practically, this enables the design of VLMs with stronger parallel sampling ability and improved robustness, critical for deployment in safety-sensitive or open-ended applications. Theoretically, the results invite further investigation of diversity preservation mechanisms—potentially via more advanced clustering, representation learning, and meta-RL paradigms—and their integration into larger-scale RLHF pipelines.
Future work may address scaling properties of MUPO under resource constraints, optimal design of group partitioning criteria, and diversity-reward calibration for tasks with varying solution structure complexity.
Conclusion
This paper rigorously demonstrates that RL-finetuning with GRPO induces a detrimental collapse of reasoning diversity in VLMs, restricting the range of solution strategies and test-time scaling potential. The proposed MUPO algorithm overcomes this by enforcing multimodal optimization, leading to significant advancements in both accuracy and solution breadth on established benchmarks. The insights and methodologies contributed provide a foundation for more robust, flexible, and capable multimodal AI systems, with direct implications for future research in RL-based model alignment and reasoning optimization.