- The paper introduces DQO, a novel training algorithm that jointly optimizes for semantic diversity and response quality in LLMs using DPPs.
- It employs an embedding-based diversity measure calculated via the determinant of a kernel similarity matrix to promote broad semantic coverage.
- Experimental results show that DQO outperforms reward-only methods on multiple tasks, achieving improved pass@N scores and diverse outputs.
Enhancing Diversity in LLMs via Determinantal Point Processes
Introduction
The paper introduces Diversity Quality Optimization (DQO), a training algorithm for LLMs that directly optimizes for both semantic diversity and output quality using determinantal point processes (DPPs). The motivation stems from the observation that post-training methods such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) often lead to a collapse in output diversity, resulting in models that produce narrow, canonical responses. Existing diversity-promoting methods are typically limited to inference-time interventions or lexical-level regularization, which fail to recover missing semantic modes once the model distribution has collapsed. DQO addresses these limitations by incorporating a principled, embedding-based diversity objective into the training process.
Determinantal Point Processes for Diversity
DQO leverages DPPs to quantify and promote diversity among generated responses. For each prompt, the model samples k responses, embeds them into a semantic space using a pretrained encoder, and computes a kernel-based similarity matrix. The diversity score is defined as the determinant of this matrix, which geometrically corresponds to the volume spanned by the response embeddings. This approach is sensitive to linear independence and penalizes clustering, ensuring that diversity is measured at the group level rather than via pairwise distances. The determinant-based metric robustly captures semantic diversity, forcing the model to explore the full high-dimensional embedding space.
Quality-Diversity Objective and Optimization
The DQO objective augments the standard reward-based optimization with a diversity term:
JDiv(πθ)=Ex,y1:k∼πθ(⋅∣x)[i=1∑kr(x,yi)+αlogdet(Lϕ(y1:k))]
where r(x,yi) is the reward for response yi, α controls the trade-off between quality and diversity, and Lϕ(y1:k) is the kernel similarity matrix of the embeddings. The optimal policy samples groups of responses with probability proportional to the determinant of the reward-augmented Gram matrix, balancing semantic separation and response quality.
To address practical challenges such as numerical instability and high gradient variance, the algorithm regularizes the diversity term by adding an identity matrix to the kernel, ensuring boundedness. Additionally, a leave-one-out (loo) gradient estimator is employed to reduce variance, leveraging the eigenvalue interlacing theorem for theoretical guarantees.
Experimental Results
DQO is evaluated on four tasks: reasoning (GSM8K), summarization (CNN-dailymail), instruction-following (Dolly), and story generation (Common-Gen). The model is compared against baselines trained solely for reward optimization (GRPO for reasoning, PPO for other tasks).
Quality Metrics
DQO consistently matches or exceeds baseline performance on pass@1 and achieves substantial improvements on pass@n for n>1, indicating that the model generates multiple high-quality, diverse responses per prompt.
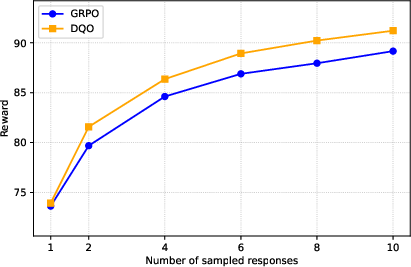
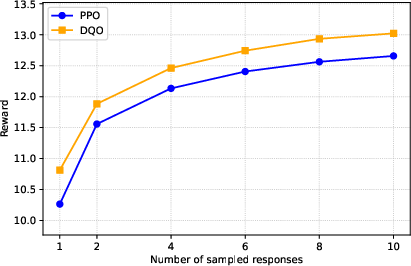
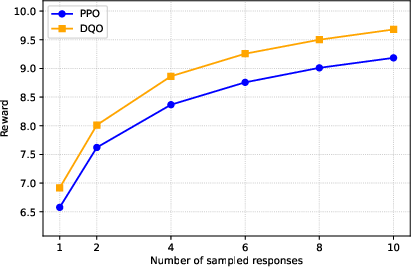
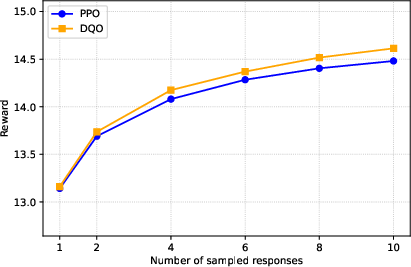
Figure 1: pass@n performance on GSM8K, demonstrating DQO's superior best-of-n quality compared to reward-only baselines.
Diversity Metrics
DQO outperforms baselines across six diversity metrics, including distinct-n, self-BLEU, self-ROUGE, and LLM-as-a-judge scores. Notably, advanced models (GPT-4o-mini) recognize the semantic diversity of DQO-generated outputs, confirming improvements beyond lexical variation.
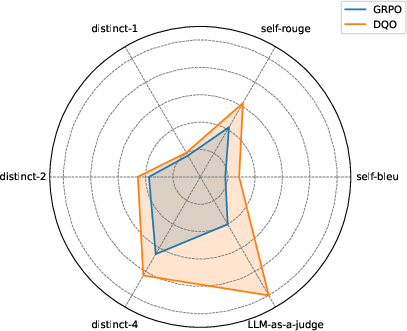
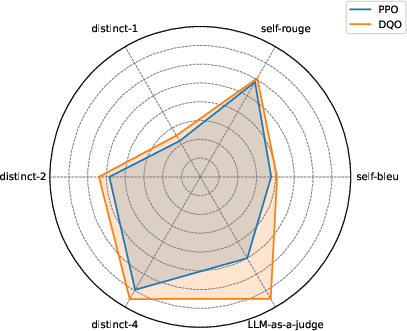
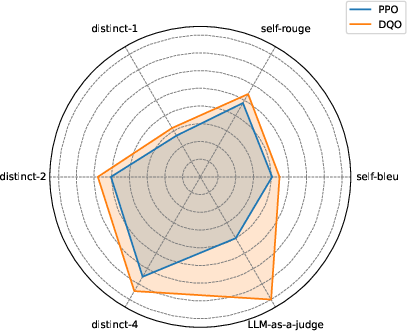
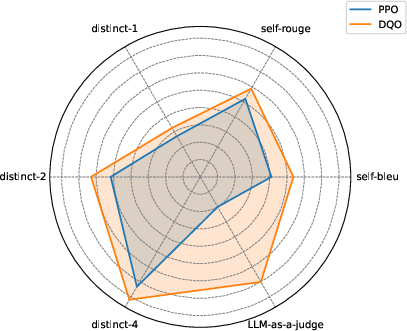
Figure 2: Diversity metrics on GSM8K, showing DQO's consistent advantage over reward-only training.
Pareto Frontier Analysis
DQO achieves Pareto-optimal trade-offs between quality and diversity across varying training steps and sampling temperatures, consistently occupying the upper-right region of the quality-diversity space relative to baselines.
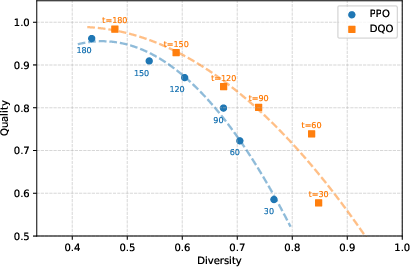
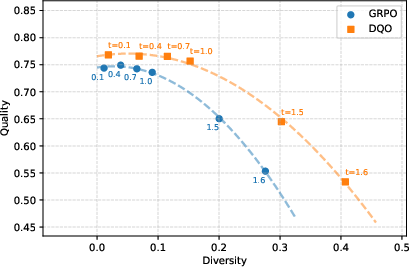
Figure 3: Pareto frontiers for quality and diversity on Gen and GSM8K, illustrating DQO's robust balance across training and inference settings.
Hyperparameter Ablation
Increasing α (diversity weight) and k (number of sampled responses) enhances diversity but can reduce pass@1 if set excessively high. DQO demonstrates robust improvements over baselines across a wide range of hyperparameters, with pass@10 remaining stable even as diversity increases. Larger k incurs additional computational cost but further promotes diversity.
Implementation Considerations
- Embedding Model Selection: The quality of semantic diversity depends on the embedding model used. Sentence-transformers/all-MiniLM-L6-v2 is employed, but task-specific or adaptive embeddings may yield further improvements.
- Reward Model: DQO relies on reward models that evaluate the entire response, mitigating reward hacking observed with outcome-based rewards.
- Computational Overhead: Sampling multiple responses per prompt and computing determinants increases training cost, especially for large k.
- Numerical Stability: Regularization via identity matrix addition is essential for stable optimization.
- Deployment: DQO is compatible with standard RL-based post-training pipelines and can be integrated with existing reward models and embedding encoders.
Limitations and Future Directions
DQO's reliance on pretrained embeddings introduces sensitivity to embedding quality and alignment with task semantics. Outcome-based rewards remain vulnerable to reward hacking, suggesting the need for more robust reward modeling. Future work may explore adaptive or task-specific diversity metrics, integration with preference-based RL, and scalable determinant computation for large k.
Conclusion
DQO provides a principled framework for jointly optimizing semantic diversity and response quality in LLMs via DPPs. Extensive experiments demonstrate that DQO substantially enhances diversity without sacrificing quality, outperforming reward-only baselines across multiple tasks and metrics. The approach is robust to hyperparameter choices and offers clear geometric and probabilistic interpretations. Limitations related to reward modeling and embedding selection highlight promising avenues for further research in diversity-aware LLM training.