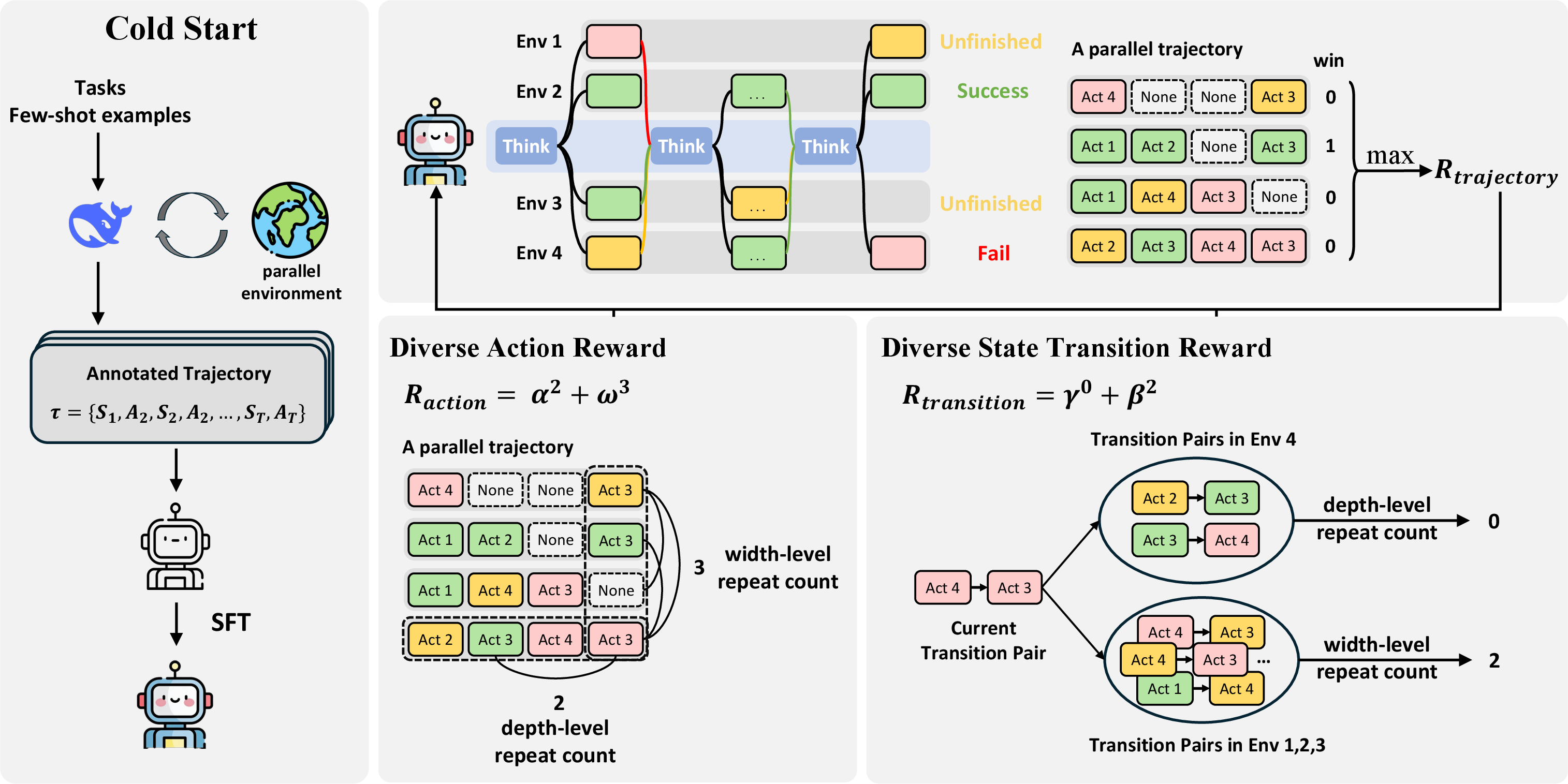
- The paper introduces DPEPO, a parallel exploration framework that uses hierarchical RL and diversity rewards to enhance LLM agent performance.
- It combines supervised fine-tuning with detailed step-level reward shaping to reduce token usage and accelerate convergence compared to sequential methods.
- Empirical results on ALFWorld and ScienceWorld demonstrate significant gains in success rates and efficiency, with scalable improvements as model size increases.
Diverse Parallel Exploration Policy Optimization for LLM Agents: Technical Summary
Motivation and Limitations of Sequential Exploration
Traditional LLM-based agents operate under the ReAct paradigm, alternating between reasoning and action selection within a single environment at each timestep. This sequential execution constrains the agent's exploration capabilities, producing a narrow, linear trajectory that limits environmental understanding and biases decision-making. While naive multi-sampling of trajectories per task nominally increases exploration entropy, it fails to foster genuine behavioral diversity and isolates experiences across trajectories, yielding inefficiencies in both token consumption and runtime.
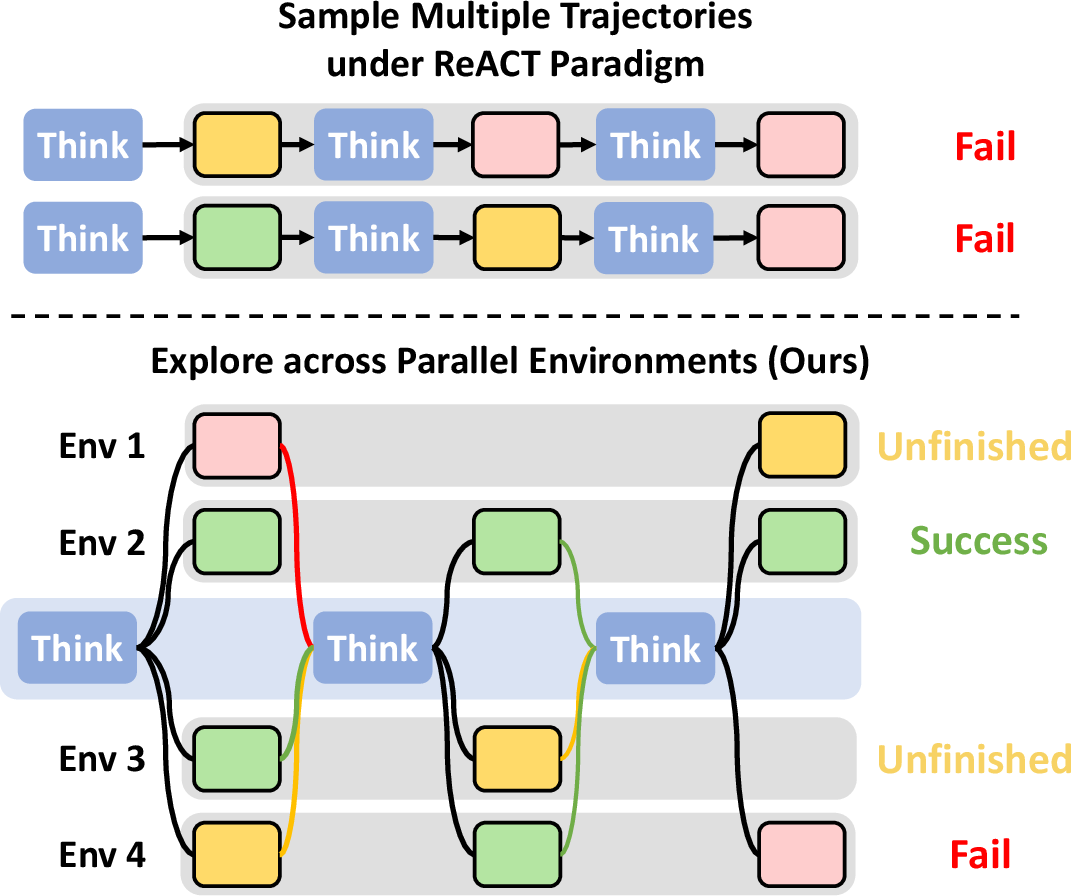
Figure 1: ReAct-based agents form restricted environmental cognitions, whereas DPEPO enables broad, multi-environment parallel exploration for holistic understanding.
DPEPO: Parallel Exploration Policy Optimization Framework
Paradigm Shift: Parallelized Agent-Environment Interaction
DPEPO introduces a parallel interaction paradigm, allowing agents to simultaneously engage with multiple (K) instances of an environment derived from identical initial state distributions. At each step, the subset of environments for interaction (Et′) is dynamically selected, maximizing both coverage and quality of state-action sequences. The resultant trajectory encapsulates parallelized states and actions τ={(St,At)}t=1T, supporting concurrent exploration and shared experience accumulation.
Training Protocol
DPEPO employs a two-stage optimization pipeline:
Reward Structure
- Parallel Trajectory-Level Success Reward: Binary signal awarded if any environment completes the goal. Facilitates outcome-level supervision.
- Step-Level Rewards:
- Diverse Action Reward: Penalizes intra- and inter-environment action repetitions at each step, maximizing behavioral entropy.
- Diverse State Transition Reward: Discourages redundant state-action transitions both within and across parallel environments, promoting breadth and novelty in exploration.
Group-relative advantage estimation, adapted from GRPO, enables policy credit assignment at multiple granularities—trajectory and step—optimizing for both high-level success and fine-grained exploration diversity.
Empirical Evaluation
On ALFWorld and ScienceWorld, DPEPO achieves state-of-the-art success rates (98.2% and 61.4%, respectively), outperforming baselines including GRPO, GiGPO, RLVMR, and SPEAR. DPEPO demonstrates robust generalization on unseen task splits, maintaining efficiency despite its parallel paradigm.
Scaling Analysis
Success rate and average steps exhibit monotonic improvements with increasing model size. Even minimal DPEPO variants surpass strong RL baselines in both efficacy and efficiency. This scaling behavior persists across Qwen2.5 and Qwen3 model families.
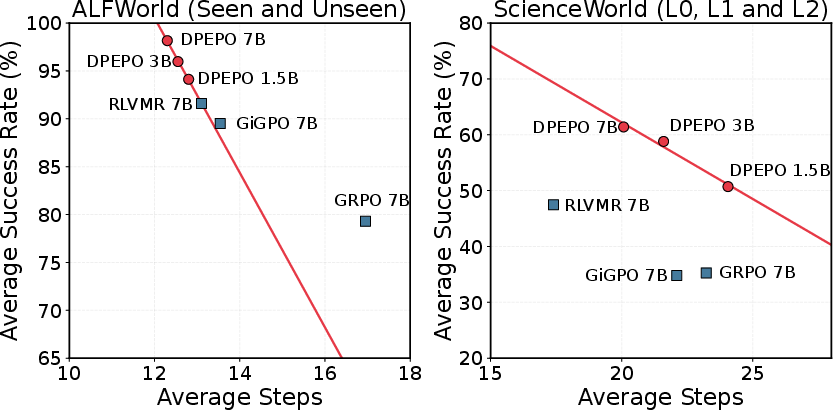
Figure 3: DPEPO maintains high success rates with improved average step efficiency as model size increases.
Parallel Environment Impact
Increasing the number of exploration environments (K) yields further performance gains. DPEPO's token budget growth is sublinear with respect to K, unlike GiGPO's, highlighting superior sample and token efficiency.
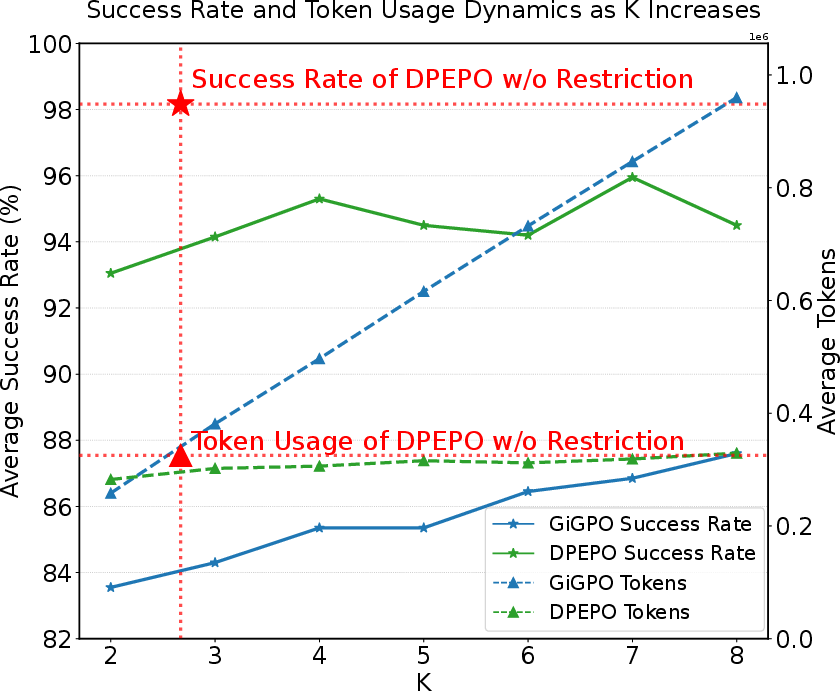
Figure 4: DPEPO achieves higher success rates than GiGPO for equivalent K, with more efficient token usage as parallelism increases.
Ablations and Behavioral Dynamics
Reward component ablations confirm the joint necessity of Diverse Action Reward and Diverse State Transition Reward: removal of either significantly degrades exploration diversity and solution efficiency. Visualization of exploration metrics substantiates a reduction in action/transition repetitions and greater coverage in parallel trajectories with full reward shaping.
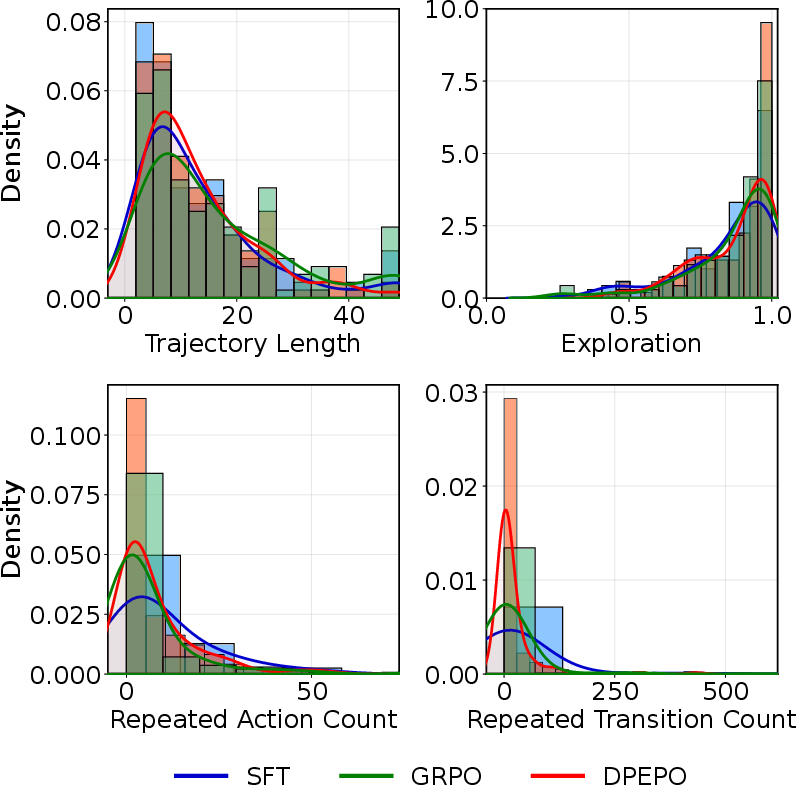
Figure 5: DPEPO variants exhibit differing exploration dynamics; full variant yields maximal diversity and minimal repetition rates.
Efficiency and Resource Utilization
Despite broader exploration, DPEPO's inference and training trajectory lengths are shorter and its time-to-SOTA is substantially reduced compared to sequential and multi-sampling baselines. Parallel execution amortizes inference latency, and sample quality boosts training convergence.
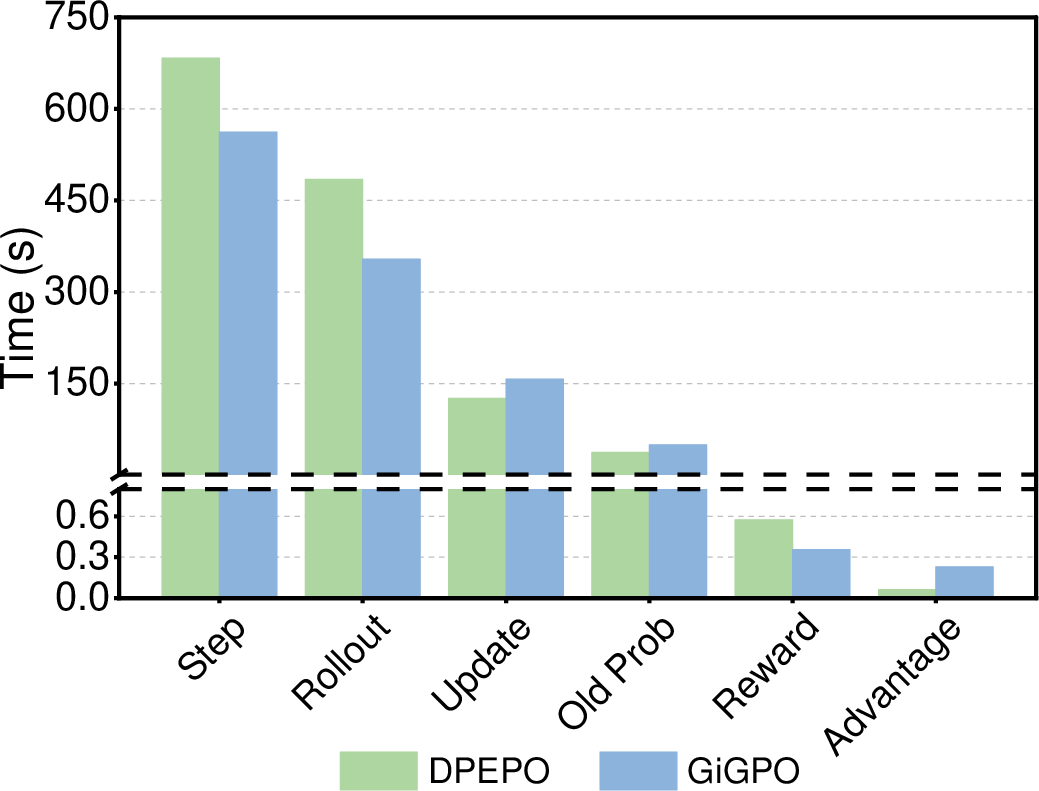
Figure 6: Main step-wise training components in DPEPO show only marginal time increase due to parallelism.
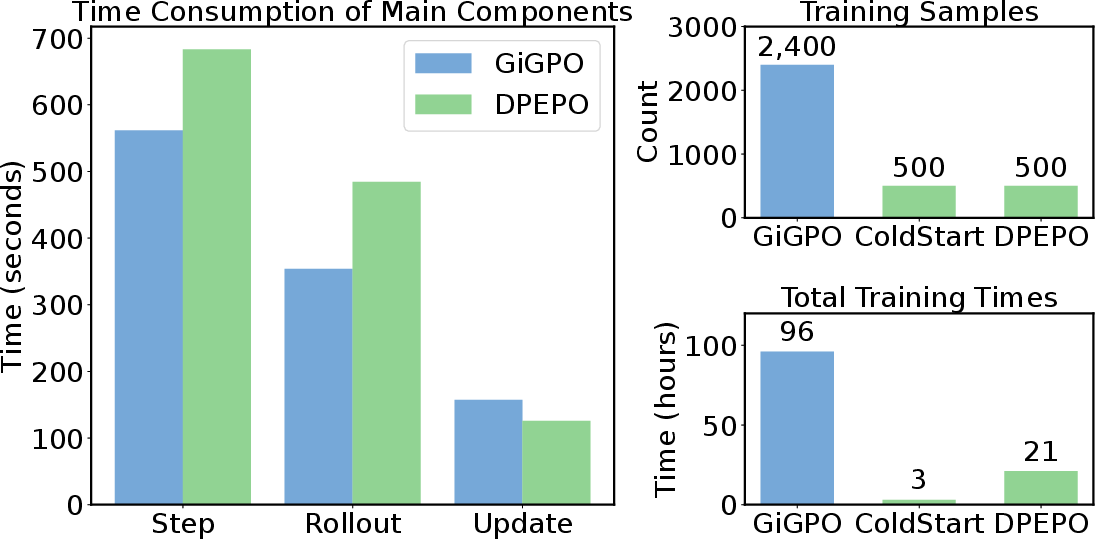
Figure 7: DPEPO converges in less than 24 hours (500 RL samples), four times faster than GiGPO.
Additional Analyses
DPEPO maintains stable exploration behavior due to implicit context length constraints and diversity-driven step rewards, preventing reward hacking or excessive environment proliferation. Strong baseline comparisons further validate its superiority even against advanced exploration and imitation learning methods (e.g., MCTS+DPO).
Scaling analysis on Qwen3 reaffirms predictable and monotonic improvement with model size.
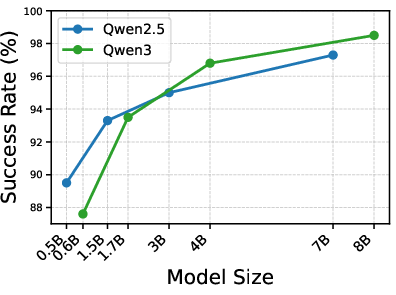
Figure 8: Qwen3 scaling experiments confirm DPEPO's generalization and performance consistency.
DPEPO adapts prompting for efficient context compression, reducing token budgets by over seven-fold while preserving historical information richness, a necessity for multi-environment rollouts.
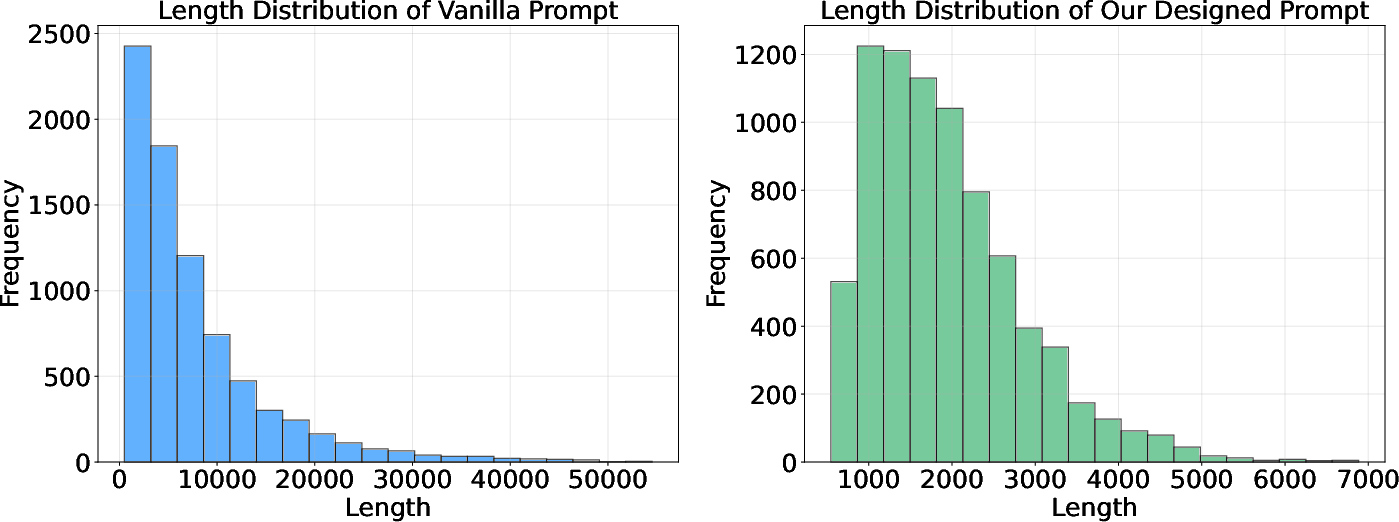
Figure 9: Context length distribution—DPEPO's designed prompt achieves substantial compression versus vanilla prompt.
Implications and Future Directions
DPEPO's paradigm unlocks holistic environment cognition for LLM agents and significantly raises the ceiling for autonomous agent performance. Practically, it is highly applicable to domains where parallel environment creation is tractable—code agent sandboxes, multi-tool and GUI systems, web information seeking, and parallel simulation scenarios. Theoretically, it demonstrates the value of diversity-driven RL reward shaping and parallel data collection for scaling agentic reasoning and action.
Challenges in real-world embodied parallelization remain, but training on multiple distinct tasks or environments offers a path forward. Further exploration of parallel exploration mechanisms and reward shaping in more complex, real-world settings is warranted.
Conclusion
DPEPO fundamentally enhances LLM agent training by extending exploration from sequential to structured parallel domains. Joint step- and trajectory-level diversity rewards foster comprehensive environmental understanding, yielding superior task success and efficiency across benchmarks. The paradigm’s scalability, efficiency, and diversity incentives provide a robust foundation for future advances in agentic policy optimization and autonomous system design.