Learning to Discover at Test Time
Abstract: How can we use AI to discover a new state of the art for a scientific problem? Prior work in test-time scaling, such as AlphaEvolve, performs search by prompting a frozen LLM. We perform reinforcement learning at test time, so the LLM can continue to train, but now with experience specific to the test problem. This form of continual learning is quite special, because its goal is to produce one great solution rather than many good ones on average, and to solve this very problem rather than generalize to other problems. Therefore, our learning objective and search subroutine are designed to prioritize the most promising solutions. We call this method Test-Time Training to Discover (TTT-Discover). Following prior work, we focus on problems with continuous rewards. We report results for every problem we attempted, across mathematics, GPU kernel engineering, algorithm design, and biology. TTT-Discover sets the new state of the art in almost all of them: (i) Erdős' minimum overlap problem and an autocorrelation inequality; (ii) a GPUMode kernel competition (up to $2\times$ faster than prior art); (iii) past AtCoder algorithm competitions; and (iv) denoising problem in single-cell analysis. Our solutions are reviewed by experts or the organizers. All our results are achieved with an open model, OpenAI gpt-oss-120b, and can be reproduced with our publicly available code, in contrast to previous best results that required closed frontier models. Our test-time training runs are performed using Tinker, an API by Thinking Machines, with a cost of only a few hundred dollars per problem.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Learning to Discover at Test Time — Explained Simply
What is this paper about? (Overview)
Imagine you’re taking a really hard test, but instead of being stuck with what you studied before, you’re allowed to keep learning during the test, using feedback from each attempt to get better answers. That’s the core idea of this paper.
The authors introduce a method called TTT-Discover (Test-Time Training to Discover). It lets an AI model keep training and improving while it’s working on one specific problem, so it can find a single, truly great solution that beats the current best in the world.
What questions are the researchers asking? (Key objectives)
They focus on two simple but powerful questions:
- Can an AI keep learning while it’s trying to solve a single, real problem, and end up discovering a new best-ever solution?
- How should that learning be set up so the AI doesn’t just get “pretty good on average,” but instead focuses on producing one outstanding result?
They test this idea on tough challenges in:
- Mathematics (finding tighter bounds)
- GPU programming (making code run faster on specialized chips)
- Algorithm design (competing on coding contest problems)
- Biology (cleaning noisy data from single cells)
How did they do it? (Methods in plain language)
Most earlier methods ask a frozen AI (one that can’t learn anymore) to try many times and then pick the best result. TTT-Discover does something different: it actually trains the AI during the test on the problem it’s trying to solve.
Here’s the basic loop:
- The AI reads the problem.
- It proposes a solution (like writing code or constructing a math object).
- The solution gets a score (called a “reward”), such as “faster is better” or “smaller error is better.”
- The AI saves this attempt, learns from it, and tries again—aiming to produce an even better solution next time.
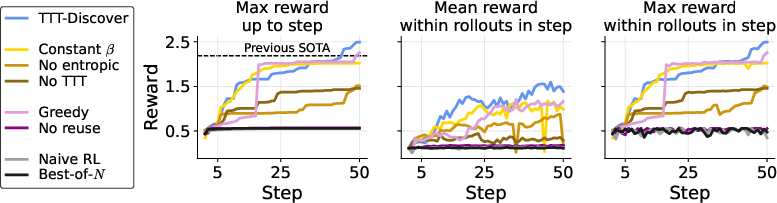
Two key ideas make this work:
- A “best-first” learning goal (entropic objective): Instead of rewarding the AI for being good on average, the method gives extra weight to the best attempts. Think of it like giving bonus points to the one best try in a batch, so the AI learns the tricks that produced that top result.
- Smart reuse of promising ideas (PUCT selection): The AI keeps a “buffer” (a memory) of past solutions. It revisits and improves on promising ones, but still explores new directions. You can think of it like exploring branches of a tree: it favors branches that look good, but it also occasionally tries less-visited branches in case there’s a hidden gem.
A few helpful translations of terms:
- “Policy” = the AI’s strategy for producing the next answer.
- “State” = the current partial or full solution (like a piece of code or a math construction).
- “Reward” = the score that says how good the solution is (e.g., faster runtime, higher accuracy).
- “Reinforcement learning” (RL) = learning from trial and error using rewards.
They run this for multiple rounds (for example, 50 steps) and generate many attempts each step, continuously updating the model to become more effective at this one problem.
What did they find? (Main results and why they matter)
Across different fields, TTT-Discover found new state-of-the-art (SOTA) results or matched the best known ones—often beating both expert humans and previous AI systems that didn’t learn during the test. Highlights include:
- Mathematics:
- Erdős’ Minimum Overlap Problem: Improved the best known upper bound from 0.380924 to 0.380876 (lower is better). That’s a meaningful tightening in a long-standing problem.
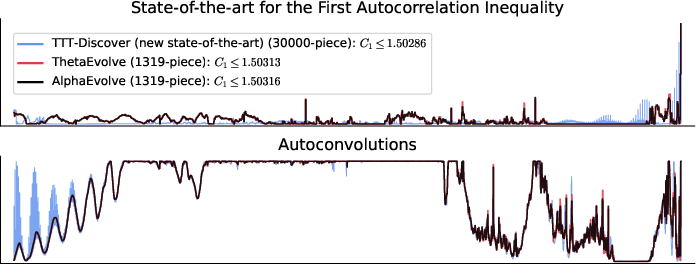
- First Autocorrelation Inequality: Improved the best known upper bound to about 1.50287 (lower is better), beating recent AI approaches that used powerful closed models.
- These are real mathematical advances: small numerical improvements in such problems often rule out entire lines of previous reasoning and push the knowledge frontier forward.
- GPU Kernel Engineering (making code faster on GPUs):
- Triangular Matrix Multiplication (TriMul): Produced kernels up to about 2× faster than previous top entries on some GPUs, and beat the best human submissions across multiple GPU types.
- This matters because faster kernels speed up many AI and scientific computations.
- Algorithm Design:
- On a past AtCoder heuristic contest, TTT-Discover achieved a higher score than previous AI systems using similar compute budgets.
- Biology (single-cell data denoising):
- Improved denoising quality (higher score is better), suggesting the method can help in scientific data analysis, not just coding or math.
Other important notes:
- They used an open model (gpt-oss-120b) rather than closed “frontier” models.
- The experiments were cost-efficient: on the order of a few hundred dollars per problem.
Why does this matter? (Implications and impact)
This work shows a shift in how we can use AI for discovery:
- Instead of relying only on a model’s past training, we can let it keep learning from the specific problem we want to solve—right at test time.
- By aiming for the single best solution (not just good average performance), AI can tackle discovery-style tasks where one breakthrough matters more than many okay attempts.
- This approach can accelerate progress in math, programming, algorithms, and biology—especially in places where even small improvements are valuable.
- Because it works with open models and modest budgets, more researchers and teams could use it to push the state of the art in their fields.
In short, TTT-Discover is like letting the AI “study while taking the test”—and when the goal is to find one brilliant answer, that strategy can make a real difference.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper, framed to enable targeted follow-up research.
- Theoretical guarantees for the entropic objective: No formal analysis of convergence, stability, or regret is provided for test-time RL with the entropic objective, especially with adaptive per-state β and KL penalties.
- Principled β scheduling: The adaptive β(s) selection by constraining KL is described only in the appendix; there is no evaluation of alternative schedules, target KL choices, or theory guiding β’s dynamics across training.
- Role of value estimation: The method uses advantage shaping without a learned value function; it is unclear whether actor-critic baselines, advantage estimation, or critic-based risk-sensitive objectives could improve stability and sample efficiency.
- One-step environment abstraction: Treating problems as single-timestep MDPs with “effective horizon via reuse” is not validated against multi-step RL formulations; the trade-offs between explicit multi-step planning vs. reuse remain unquantified.
- PUCT design choices: Using max-reward children in Q(s) instead of mean is motivated but not theoretically or empirically ablated; effects on overestimation, premature exploitation, and robustness to noisy reward are unknown.
- Reuse hyperparameters and buffer dynamics: No sensitivity analysis for c (exploration coefficient), buffer size, duplicate handling, descendant counting, or the prior P(s); their effect on diversity and discovery rate is untested.
- State vs. state-action reuse: The paper largely emphasizes state reuse; it does not study whether incorporating past actions (thinking tokens, intermediate artifacts) in training or prompting improves performance or causes context-window issues.
- Sensitivity to training hyperparameters: There are no ablations for LoRA rank, learning rate, batch size, number of steps, groups per batch, KL penalty λ, or sampling temperature; robustness to hyperparameters is unknown.
- Compute scaling and returns: Beyond one budget (50×512), there is no scaling law for discovery probability vs. compute; comparative efficiency vs. Best-of-N and evolutionary methods across budgets is not established.
- Generalization across GPU architectures: Kernels were trained/evaluated primarily on H100/H200 and then reported on A100/B200/MI300X; systematic cross-architecture generalization and transfer are not quantified or guaranteed.
- Torch.compile reliance for MLA: The MLA-Decode improvements largely come from torch.compile rather than Triton; how to reliably steer toward Triton-based fine-grained kernels (and whether they can surpass compile-based gains) is unexplored.
- Robustness to benchmark harnesses: Runtime evaluations are remote (Modal) and leaderboards vary by hardware; reproducibility across measurement harnesses, drivers, and compiler versions is not systematically tested.
- Fairness of baselines with context constraints: OpenEvolve rollouts often truncated due to prompt growth and context limits; no controlled baseline where prompts are normalized across methods to isolate algorithmic differences.
- Reward shaping choices: Continuous reward formulations (e.g., 1/bound for minimization, bound for maximization) are task-specific and not ablated; their impact on training dynamics and stability is unknown.
- Applicability to sparse/binary rewards: The method is only evaluated on continuous rewards; its effectiveness on sparse/binary success signals (e.g., theorem proving, code correctness) and pass@k objectives is not assessed.
- Valid/invalid action rates: The fraction of invalid code, timeouts, and sandbox failures (especially in math with 10-minute limits and in kernel compilation) is not reported; how invalid actions affect training remains unclear.
- Security and sandboxing: Executing model-generated code presents safety risks; the paper does not detail sandbox isolation, resource limits, or mitigation of potential malicious or runaway code behaviors.
- Post-training model integrity: Test-time LoRA finetuning on a single problem may cause catastrophic forgetting or undesirable specialization; the extent of capability drift and reversibility (merging/detaching adapters) is not evaluated.
- Policy artifact utility: The approach optimizes for the single best solution rather than a robust policy; the downstream utility of the trained policy (e.g., for follow-up problems or related variants) is not measured.
- When training beats search: Aside from select tasks, there is no systematic characterization of the regimes where TTT-Discover outperforms Best-of-N or evolutionary search (problem properties, reward smoothness, action validity rates).
- Exploration vs. exploitation balance: PUCT’s prior P(s) and max-based Q(s) may bias toward already-good states; strategies to preserve diversity, avoid mode collapse, and recover from early over-exploitation are not analyzed.
- Context-window constraints: Token forcing and 26k prompt+thinking token caps may truncate reasoning; the effect of context length on discovery rate and whether dynamic token allocation improves outcomes are untested.
- AtCoder evaluation details: The paper reports improved scores but does not detail generalization to held-out seeds, robustness across instances, or compliance with contest constraints in retrospective evaluation.
- Biology denoising validity: The denoising improvement (e.g., MSE=0.71) lacks dataset details, baselines beyond prior art, cross-validation, statistical significance, and assessment across multiple datasets or noise regimes.
- Mathematical certificate rigor: Very large step functions (e.g., 30k or 600 pieces) are computationally verified, but their asymptotic tightness, sensitivity to discretization/grid resolution, and rounding error robustness are not probed.
- Interpretability of discovered constructions: The paper does not analyze why asymmetric constructions emerged (Erdős), whether simpler constructions exist, or what mathematical insights the numeric certificates reveal.
- Reproducibility outside Tinker: Results depend on Tinker’s RL infrastructure and gpt-oss-120b availability; portability of runs to other serving stacks and open-source RL toolchains is not demonstrated.
- Importance sampling corrections: The sampler/learner mismatch correction is mentioned but not detailed; bias, variance, and the effect of single on-policy gradient step per batch remain unquantified.
- Off-policy training and replay: The method takes one gradient step per batch with no off-policy updates; whether replay, prioritized sampling, or multi-step updates improve discovery rates is open.
- Combining RL with evolutionary operators: The paper does not explore hybridizing TTT-Discover with mutation/crossover or diversity-preserving heuristics; potential gains and conflicts are unknown.
- Failure mode taxonomy: There is no analysis of failure cases (e.g., stalled training, converging to near-SOTA but not surpassing, brittle kernels) or diagnostics to guide intervention.
- Domain coverage beyond continuous rewards: Extending TTT-Discover to theorem proving, program synthesis with strict constraints, or experimental design with noisy outcomes is not evaluated.
- Evaluation metrics for “significance” of discovery: The paper uses reward improvement (R(s) − R*) but does not propose domain-aware significance metrics (e.g., bounds tightening with theoretical impact, kernel speed vs. memory/bandwidth trade-offs).
- Ethical and compliance considerations: Running code and submitting kernels to leaderboards may raise compliance or attribution issues; protocols for ownership, reproducibility, and disclosure are not discussed.
- Adaptive compute allocation: The system samples a fixed number of rollouts per selected state; strategies to allocate more compute to promising states or dynamically reweight groups over training are not explored.
- Impact of initial buffer seeding: For math, buffers initialized with random states; the relative benefits of seeding with known-good constructions vs. random vs. heuristic seeds are not studied.
- Cross-task transfer: Whether adapters trained on one problem help related problems (e.g., other inequalities or kernels) or harm them is an open question.
- Practical guidance for deployment: There is no recipe for choosing between TTT-Discover, Best-of-N, and evolutionary search given a new problem’s characteristics and constraints.
Practical Applications
Immediate Applications
These applications can be deployed now with the paper’s method (TTT-Discover), given a computable, continuous reward signal and a safe execution harness.
- GPU kernel auto-optimization for production workloads
- Sectors: software/ML systems, semiconductors, cloud
- What it does: Uses TTT-Discover to discover faster kernels for target GPUs (e.g., H100/A100/B200/MI300X), yielding >15–50% speedups in reported tasks (TriMul) without closed models.
- Potential tools/products/workflows:
- “Optimize kernel” CI/CD job that runs TTT-Discover on critical ops before release
- PyTorch/Triton plugin that wraps kernels with a test-time training pass
- GPUMode-like benchmarking harness and Modal-like evaluator for consistent timing
- Assumptions/dependencies:
- Correctness tests must be available; deterministic, high-SNR runtime measurements on target hardware
- Safe sandboxed code execution; long-context LLM access; small compute budget ($100s/task)
- Triton/CUDA/ROCm toolchains and stable driver/firmware on evaluation nodes
- Algorithmic performance tuning for batch systems and coding tasks
- Sectors: software infrastructure, competitive programming, operations research
- What it does: Improves algorithmic heuristics and implementations against objective test suites (e.g., AtCoder historical tasks), focusing on “one task, one breakthrough.”
- Potential tools/products/workflows:
- Internal “one-problem optimizer” for job schedulers, sort/merge pipelines, graph routines
- Auto-tuning step in build pipelines that outputs a candidate patch + benchmarks
- Assumptions/dependencies:
- Clear scoring harness and fast, repeatable evaluation
- Guardrails for timeouts and resource limits
- Bioinformatics pipeline auto-tuning (e.g., single-cell denoising)
- Sectors: healthcare/life sciences, pharma R&D
- What it does: Runs TTT-Discover over analysis code to improve continuous metrics (e.g., MSE for denoising), with demonstrated gains over prior baselines.
- Potential tools/products/workflows:
- Notebook extension for scRNA-seq pipelines that proposes improved code versions with validation plots
- CI step for production bioinformatics pipelines that triggers when a metric regresses
- Assumptions/dependencies:
- Evaluation metric must correlate with downstream biological utility; data governance/privacy controls
- Sandboxed execution, environment capture (conda/docker) for reproducibility
- Mathematical construction search assistant (certificate-driven discovery)
- Sectors: academia (math/combinatorics/analysis), cryptography, coding theory
- What it does: Searches for step-function or sequence constructions that certify tighter bounds, with verifiable outputs (e.g., improved Erdős minimum overlap and autocorrelation bounds).
- Potential tools/products/workflows:
- Jupyter/Lab plugin that runs TTT-Discover and auto-validates certificates
- Artifact packages with step functions, autocorrelation plots, and verification scripts for publication
- Assumptions/dependencies:
- Well-defined, executable validators; timeouts for long-running code; numeric stability controls
- Compiler/ML framework auto-tuning extension
- Sectors: compilers (TVM, OpenXLA), DL frameworks (PyTorch, TensorRT), HPC
- What it does: Applies TTT-Discover to tiling/scheduling/memory layouts or fused kernels with continuous performance rewards.
- Potential tools/products/workflows:
- “Risk-seeking” search mode in AutoTVM/Ansor powered by the entropic objective + PUCT reuse
- Per-op LoRA adapters trained on-demand and cached per hardware SKU
- Assumptions/dependencies:
- Stable perf counters; correctness suites; integration with existing autotuners’ cost models
- Reproducible leaderboard and evaluation harnesses
- Sectors: benchmarking platforms, open science
- What it does: Standardizes discovery claims via open code, buffers, and seeds; provides SOTA-at-test-time runs using open models (gpt-oss-120b) and modest budgets.
- Potential tools/products/workflows:
- “Discovery runner” that logs prompts, buffers, PUCT choices, and validation artifacts
- Journal/venue companion artifacts that reproduce claims in a few hours on rented GPUs
- Assumptions/dependencies:
- Stable APIs (e.g., Tinker), consistent hardware, and public evaluation harnesses
- Education and training aids for optimization and search
- Sectors: education, upskilling
- What it does: Demonstrates exploration–exploitation, risk-seeking objectives, and reuse strategies on concrete tasks students can validate.
- Potential tools/products/workflows:
- Course modules with ready-made environments (math bounds, kernel toy ops) and report templates
- Assumptions/dependencies:
- Classroom-safe sandboxes; small compute allocations; curated tasks with fast evals
Long-Term Applications
These require additional research, scaling, domain constraints, or regulatory/safety maturity before reliable deployment.
- Autonomous scientific discovery agents with formal verification
- Sectors: academia, formal methods, cryptography
- What it would do: Move from constructive numerical certificates to full machine-checked proofs by coupling TTT-Discover with proof assistants (e.g., Lean/Isabelle) as reward/validation backends.
- Dependencies:
- Tight integration with proof checkers; reward shaping beyond continuous proxies; stronger safety/robustness to avoid spurious “discoveries”
- Task-specific model, optimizer, or training-recipe design
- Sectors: ML research, MLOps
- What it would do: Discover architectures, schedulers, or loss curricula tuned to a single deployment task with continuous eval signals (e.g., latency–accuracy).
- Dependencies:
- Reliable multi-objective rewards; prevention of overfitting to eval harness; efficient hardware-in-the-loop training
- Hardware–software co-design and chip-level microkernel discovery
- Sectors: semiconductors, EDA, HPC
- What it would do: Jointly optimize microkernels, dataflows, and memory hierarchies for emerging accelerators using simulators or FPGA prototypes as reward oracles.
- Dependencies:
- Fast-accurate simulators; expensive evaluations amortized via surrogate models; IP and toolchain access
- Robotics and control: single-task policy refinement on real systems
- Sectors: robotics, industrial automation
- What it would do: Risk-seeking refinement for a specific manipulation or locomotion task with continuous feedback (through sim first, then real).
- Dependencies:
- Safe exploration, sim-to-real transfer, safety monitors; dense and truthful reward functions
- Energy and operations optimization in dynamic environments
- Sectors: energy, logistics, cloud scheduling
- What it would do: Discover better dispatch/scheduling heuristics for a specific plant, grid segment, or data center under continuous KPIs (cost, latency, carbon).
- Dependencies:
- High-fidelity simulators or digital twins; robust online evaluation; guardrails for constraint violations
- Finance: strategy discovery with strict risk and compliance constraints
- Sectors: finance
- What it would do: Seek rare, high-payoff strategies for a specific market microstructure using risk-adjusted continuous rewards.
- Dependencies:
- Out-of-sample validation, transaction cost modeling, regulatory compliance; robust overfitting controls
- Personalized education: one-learner optimization of learning paths
- Sectors: education/edtech
- What it would do: Discover optimal sequences of content/interventions for a single learner under continuous learning-gain signals.
- Dependencies:
- Reliable measurement of progress; privacy; ethical safeguards; drift-aware reward definitions
- Drug and material design with expensive oracles
- Sectors: biotech, materials
- What it would do: Use docking/simulation/wet-lab surrogates as continuous rewards to discover promising candidates for a specific target or property.
- Dependencies:
- Expensive, noisy evaluators; strong uncertainty quantification; experiment budgeting and active learning integration
Cross-cutting assumptions and dependencies (affect both categories)
- Continuous, computable, and trustworthy rewards: The method excels when the objective can be evaluated frequently and reliably (latency, bound tightness, MSE, score).
- Safe, sandboxed execution: Especially for code-generating domains; resource limits and timeouts are essential.
- Compute and context: Access to long-context LLMs, lightweight adaptation (e.g., LoRA), and modest but nontrivial compute budgets; caching of per-problem adapters is beneficial.
- Evaluation fidelity and transfer: Measured gains must reflect deployment conditions (hardware parity, data distributions); beware of overfitting to the harness.
- Governance and reproducibility: Open artifacts (buffers, seeds, validators), licensing compliance for models/toolchains, and transparent reporting of costs and hardware.
Glossary
- Additive combinatorics: A field studying the additive structure of sets and functions. "Autocorrelation inequalities are motivated by additive combinatorics~\cite{barnard2020three}."
- Adam: A popular stochastic optimizer combining momentum and adaptive learning rates. "using Adam with softmax parameterization"
- AlphaEvolve: An evolutionary search framework that guides LLMs via curated prompts and reuse buffers. "evolutionary search methods, such as AlphaEvolve, store past attempts"
- AtCoder: A competitive programming platform hosting algorithm contests. "past AtCoder algorithm competitions"
- Autoconvolution: Convolution of a function with itself, often used to analyze correlations. "their autoconvolutions."
- Autocorrelation inequalities: Inequalities bounding the size or norms of autoconvolutions under constraints on the original function. "Autocorrelation inequalities are motivated by additive combinatorics~\cite{barnard2020three}."
- Best-of-N: A search strategy that samples many independent solutions and keeps the best. "The simplest search method, known as Best-of-, samples i.i.d. rollouts from :"
- Circle packing: The optimization problem of placing non-overlapping circles to maximize a criterion (e.g., total radii) in a region. "In Circle packing, the goal is to maximize the sum of radii of non-overlapping circles packed inside a unit square."
- Combinatorial number theory: The study of discrete structures and integer sequences with combinatorial methods. "This is a classic problem in combinatorial number theory, posed by ErdÅs in 1955"
- cuBLAS: NVIDIA’s GPU-accelerated BLAS library for high-performance linear algebra. "delegate the computation to cuBLAS/rocBLAS"
- Delta distribution: A probability mass concentrated at a single point (Dirac delta in discrete form). "where is a delta distribution with mass only on the initial state ."
- Entropic objective: A risk-seeking objective that exponentially weights rewards to emphasize high-reward outcomes. "We define the entropic objective that favors the maximum reward actions:"
- ErdÅs' Minimum Overlap Problem: A problem on partitioning integers into two sets minimizing the maximal difference count. "We improve the upper bound on ErdÅs' Minimum Overlap Problem to $0.380876$"
- Evolutionary search: Heuristic search inspired by evolution (mutation, crossover, fitness), often reusing states and actions. "state-action reuse as evolutionary search"
- FFT: Fast Fourier Transform, an algorithm to compute discrete Fourier transforms efficiently. "FFT-accelerated gradient descent"
- FP16: Half-precision (16-bit) floating point format used to accelerate GPU computations. "convert the inputs to FP16"
- GPUMODE: A community and benchmarking platform for GPU kernel development and competitions. "GPUMODE is an open community for kernel development that also hosts competitions for domain experts."
- GRPO: A reinforcement learning algorithm related to PPO for policy optimization. "such as PPO or GRPO~\cite{schulman2017proximal, guo2025deepseek}"
- Importance sampling: A technique to correct gradient estimates when sampling and training distributions differ. "apply importance sampling ratio correction to the gradients due to the sampler/learner mismatch in the RL infrastructure"
- KL divergence: A measure of how one probability distribution diverges from a reference distribution. "by constraining the KL divergence of the induced policy;"
- KL penalty: A regularizer penalizing deviation from a reference policy to stabilize training. "we also shape advantages with a KL penalty:"
- Linear programming (LP): Optimization of a linear objective subject to linear constraints. "the policy mostly used linear programming~(LP)"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning method for large models. "We use LoRA~\cite{hu2022lora} with rank $32$."
- Markov Decision Process (MDP): A formal model of decisions with states, actions, transitions, and rewards. "a Markov Decision Process (\S\ref{sec:discovery})"
- Multi-head Latent Attention (MLA): An attention mechanism variant used in efficient inference stacks. "DeepSeek MLA (Multi-head Latent Attention), a key component in DeepSeek's inference stack"
- Off-policy: Learning from data generated by a different policy than the one being updated. "We do not take any off-policy steps"
- Out-of-distribution generalization: A model’s ability to perform well on data not drawn from its training distribution. "And out-of-distribution generalization is no easier for AI than for humans"
- pass@k: A metric measuring the probability that at least one of k generated solutions succeeds. "to maximize the pass@k performance"
- PPO: Proximal Policy Optimization, a popular RL algorithm for stable policy gradients. "such as PPO or GRPO~\cite{schulman2017proximal, guo2025deepseek}"
- PUCT: A selection rule combining value estimates, priors, and exploration bonuses (used in tree search). "We select initial states using a PUCT-inspired rule"
- Reinforcement learning (RL): Learning to make sequential decisions by maximizing cumulative reward. "We perform reinforcement learning at test time"
- rocBLAS: AMD’s GPU-accelerated BLAS library for high-performance linear algebra. "delegate the computation to cuBLAS/rocBLAS"
- Sequential least squares programming: A constrained optimization method for nonlinear problems. "then refine positions and radii using sequential least squares programming with boundary and pairwise non-overlap constraints."
- Simulated annealing: A probabilistic optimization technique that explores solutions via temperature-controlled randomness. "simulated annealing"
- Single-cell analysis: Computational analysis of data measured at single-cell resolution, often noisy. "denoising problem in single-cell analysis."
- State-action reuse: Reusing both previous states and actions (and derived context) to seed new attempts. "State-action reuse: \quad"
- State reuse: Reusing promising previous states to extend search horizons and exploit progress. "One technique to address this opposite concern is state reuse"
- Test-time scaling: Increasing compute or search at inference time to improve solution quality. "Prior work in test-time scaling, such as AlphaEvolve"
- Test-Time Training to Discover (TTT-Discover): The paper’s method that trains the LLM during testing to find a single best solution. "We call this method Test-Time Training to Discover (TTT-Discover)."
- Thinking tokens: Reasoning text generated before final code or answers to guide solution generation. "a valid action contains a piece of code and optionally some thinking tokens."
- Tinker: An API/platform used to run test-time training and sampling at scale. "Tinker, an API by Thinking Machines"
- Token forcing: Forcing the model to emit specific tokens (e.g., end-of-thought) to control output length/format. "We enforce this by token forcing the model to generate its final response."
- Triangular matrix multiplication (TriMul): A matrix multiplication variant where one operand is triangular. "TriMul (triangular matrix multiplication), a core primitive in AlphaFold's architecture"
- Triton: A GPU programming language for custom high-performance kernels. "written in Triton~\cite{tillet2019triton}"
Collections
Sign up for free to add this paper to one or more collections.