Poly-EPO: Training Exploratory Reasoning Models
Abstract: Exploration is a cornerstone of learning from experience: it enables agents to find solutions to complex problems, generalize to novel ones, and scale performance with test-time compute. In this paper, we present a framework for post-training LMs that explicitly encourages optimistic exploration and promotes a synergy between exploration and exploitation. The central idea is to train the LM to generate sets of responses that are collectively accurate under the reward function and exploratory in their reasoning strategies. We first develop a general recipe for optimizing LMs with set reinforcement learning (set RL) under arbitrary objective functions, showing how standard RL algorithms can be adapted to this setting through a modification to the advantage computation. We then propose Polychromic Exploratory Policy Optimization (Poly-EPO), which instantiates this framework with an objective that explicitly synergizes exploration and exploitation. Across a range of reasoning benchmarks, we show that Poly-EPO improves generalization, as evidenced by higher pass@$k$ coverage, preserves greater diversity in model generations, and effectively scales with test-time compute.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching AI LLMs to “think” better by exploring different ways to solve problems, not just repeating one familiar way. The authors introduce a training method called Poly‑EPO (short for Polychromic Exploratory Policy Optimization) that encourages a model to try multiple strategies, learn from them, and still aim for correct answers.
“Polychromic” means “many colors,” which is a metaphor for “many different approaches.” The big idea: reward the model for sets of answers that are both accurate and diverse in their reasoning, so it learns to balance trying new ideas (exploration) and using what works (exploitation).
The main questions the paper asks
The authors focus on three simple questions:
- How can we get a model to keep trying promising new strategies—even if they don’t work right away?
- How can we train the model to balance exploring new ideas and getting correct answers, instead of choosing one over the other?
- Can this be done efficiently so it works at large scale on real tasks (like math problems)?
How the method works (in everyday terms)
Think of a class where each student turns in multiple attempts to solve the same problem. Instead of grading each attempt alone, the teacher grades the whole set together, asking: “Did at least some attempts get it right?” and “Do these attempts use different strategies?” Good sets get rewarded. That’s the basic training idea here.
Here are the key pieces, explained simply:
- Training on sets, not single answers (Set RL):
- Usual training gives or withholds points for each answer separately.
- Set Reinforcement Learning (Set RL) scores a group of answers all at once.
- This means a clever but incorrect attempt can still help if it brings a genuinely new idea to the group.
- The polychromic objective (the scoring rule):
- Each set’s score = average correctness of the answers in the set × how different the strategies are across the set.
- Because it uses multiplication, sets need both correctness and diversity to score high. One without the other isn’t enough.
- Measuring “diversity of strategies”:
- The authors use a helper model (an LM‑judge) that looks at all the answers to the same question and groups them by strategy (for example: “solved by factoring,” “solved by using a formula,” “tried an example,” etc.).
- A set gets a higher diversity score if it includes answers from more distinct strategy groups.
- Giving “credit” fairly:
- Every answer in a set shares the same set‑level signal (how well the set did).
- But the method also tracks how often each answer appears in high‑scoring sets. Answers that help sets be both accurate and varied get more “credit,” so the model learns to produce more of those.
- Efficiency tricks:
- Instead of sampling entirely new sets over and over, they take a handful of generated answers for a prompt and form many overlapping sets from that pool. This reduces the number of model calls while still training on lots of sets.
- They plug this “set‑based credit” into standard, well‑known RL training tools, so it remains practical at scale.
Analogy: Imagine a sports team practice. You don’t just reward the single best player every time; you reward lineups (groups) that can both score and try varied tactics. Players who enable new plays—even if they don’t score—still earn a spot because they make the lineup better overall.
What they found and why it matters
Across math reasoning tests (like AIME‑style problems and other benchmarks), Poly‑EPO:
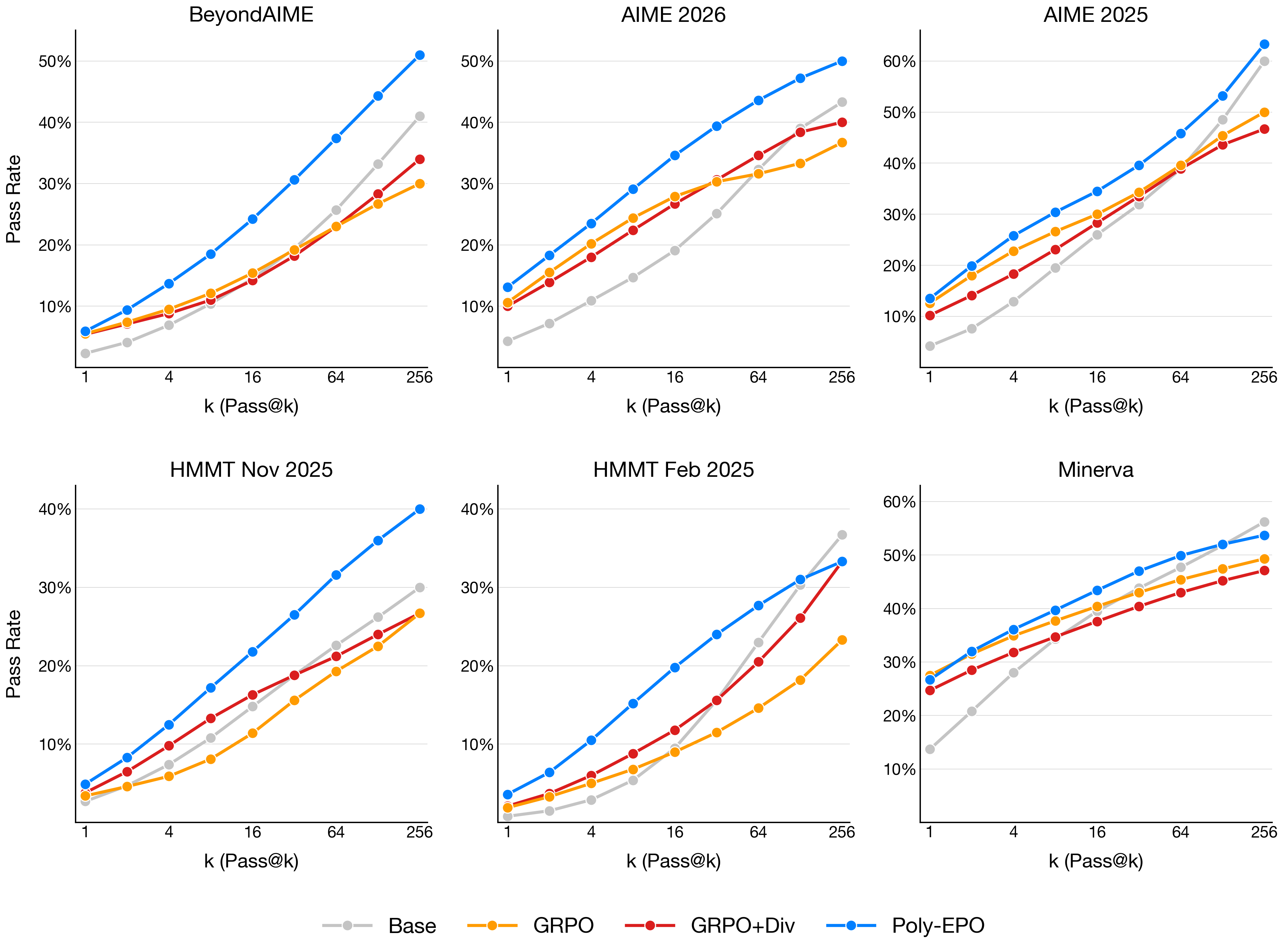
- Improved pass@k performance:
- “pass@k” means: if the model is allowed k tries on a problem, does any try get it right?
- Poly‑EPO achieved higher pass@k, with gains up to about 20% in coverage on some math test sets.
- As k grows (more tries allowed at test time), Poly‑EPO benefits more than standard training, showing it keeps useful variety in its answers.
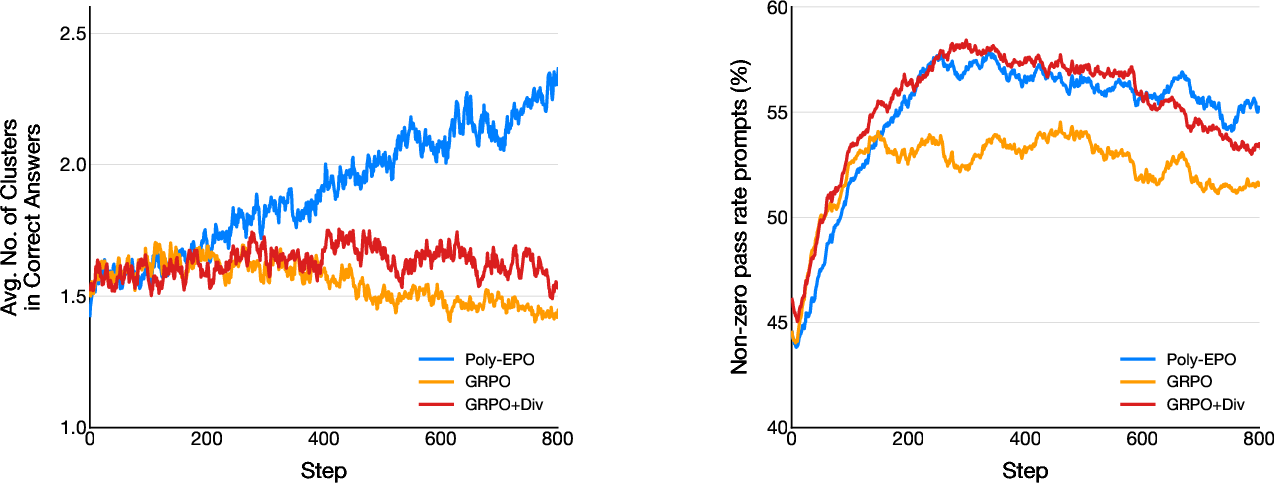
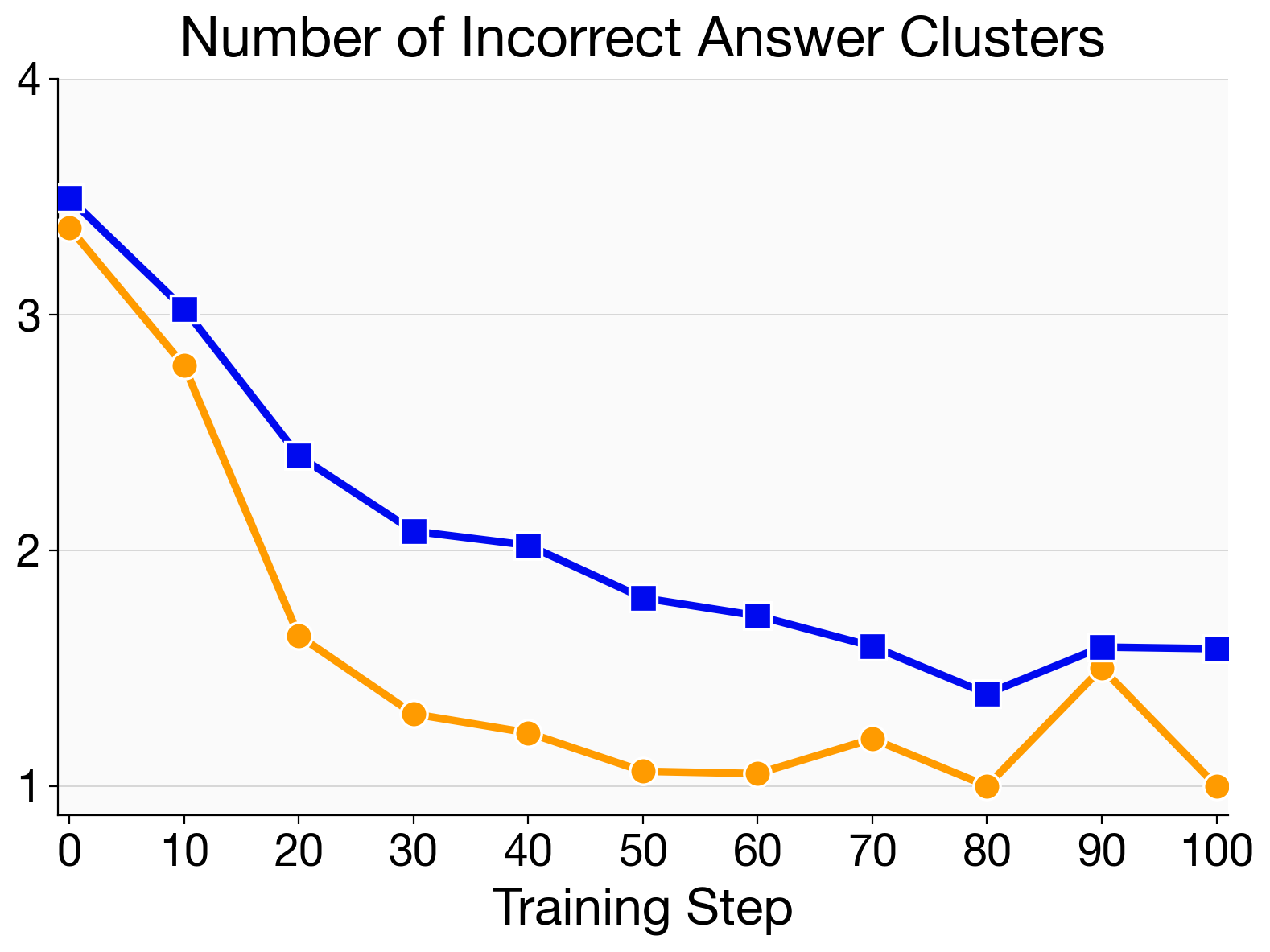
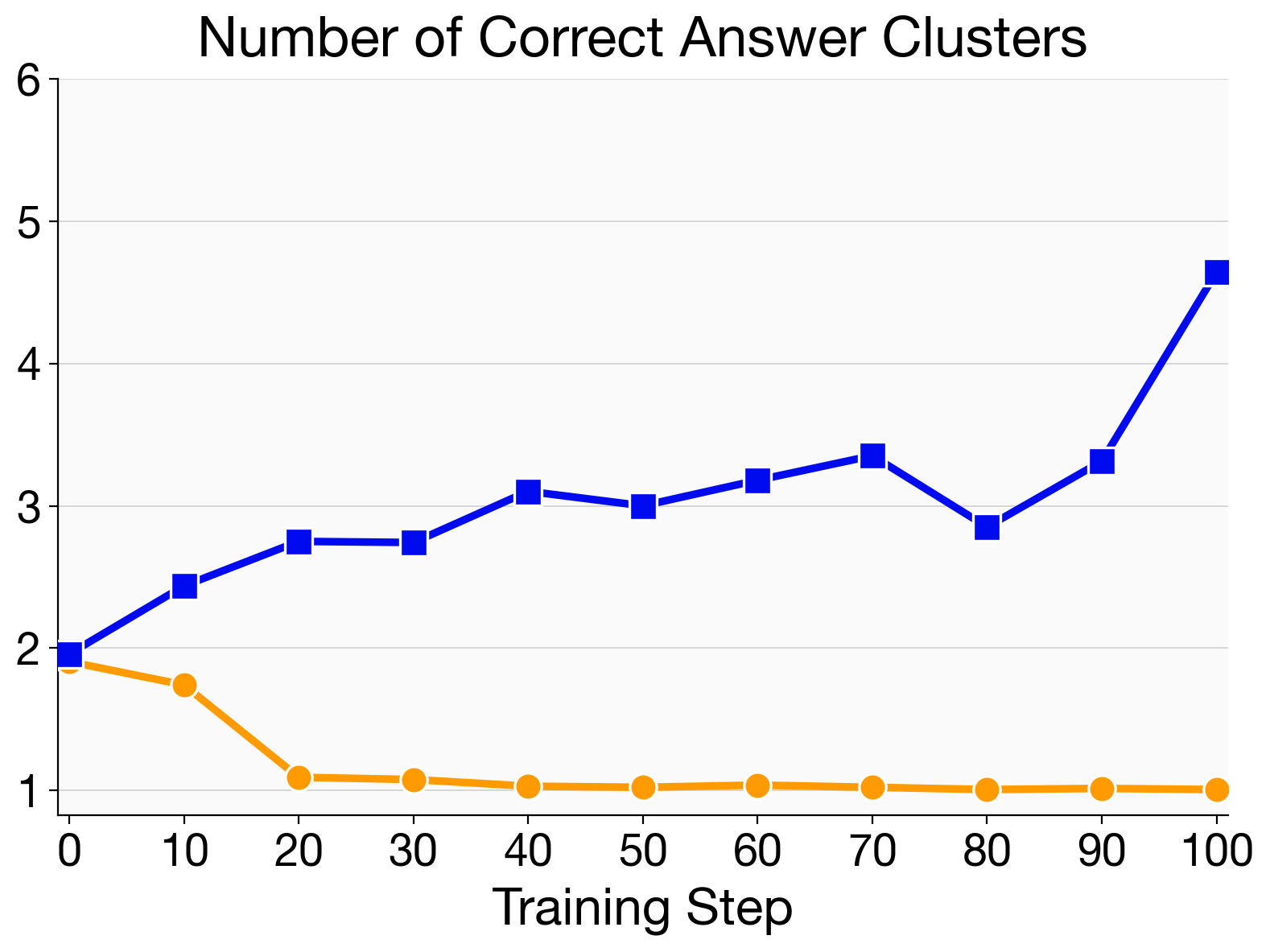
- Preserved and used diversity:
- After standard RL, models often collapse to one narrow style that worked during training (they “play it safe”).
- Poly‑EPO maintains a spread of different solution strategies, which makes techniques like majority voting or verification at test time more effective.
- Scaled with test‑time compute:
- The more attempts you let the model make at test time, the more Poly‑EPO gains. That’s exactly what you want when using extra compute (e.g., sampling multiple solutions and checking them).
Why this is important:
- Many problems (math, coding, planning) can be solved in several valid ways. A model that knows multiple strategies generalizes better to new, tricky problems.
- Encouraging “optimistic exploration” helps the model keep improving—trying promising approaches even before they start paying off—without endless hand‑tuning of exploration bonuses.
What this could mean going forward
- Better generalization: Models trained this way are more likely to handle new or unusual problems because they practice solving tasks in different ways.
- Stronger test‑time tools: Methods like sampling many answers and verifying them work best when those answers are truly different—Poly‑EPO helps deliver that.
- Practical adoption: Because the method plugs into common RL training and uses an existing “judge” to group strategies, it can fit into current training pipelines.
In short, Poly‑EPO teaches models to be curious and competent at the same time—trying new ideas while aiming for correct solutions. This blend makes them more reliable and powerful on hard reasoning tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide future research:
- Theoretical guarantees are not provided for convergence, stability, or sample complexity of the proposed set-RL estimator when plugged into PPO/GRPO; no bounds on variance or conditions under which learning is stable are given.
- The gradient estimator is described as “unbiased up to a scaling factor” (with an unspecified constant M) but later noted as “biased because of a missing scaling factor,” creating an inconsistency; the exact scaling, its dependence on N, n, K, and how to incorporate it into optimization are not clarified.
- The choice and sensitivity of hyperparameters N (number of rollouts per prompt), n (set size), and K (number of sets evaluated) are not systematically studied; no guidance or empirical ablation is provided on how these affect bias/variance, compute cost, and performance.
- Computational overhead of constructing and scoring up to K = C(N, n) sets per prompt is not quantified; practical limits, batching strategies, and throughput on realistic training clusters are not reported.
- The baseline b for variance reduction is the average of set scores from the same sampled sets; alternative control variates or lower-variance baselines are not explored, and the impact of this choice on gradient variance is not measured.
- The estimator’s dependence on combinatorial set construction (U-statistics) assumes i.i.d. samples; the impact of common LM-side couplings (e.g., shared decoding cache, temperature scheduling, length bias) on the i.i.d. assumption is not analyzed.
- The LM-judge used for clustering is treated as an oracle; reliability, robustness, and error modes of judge-based clustering (misclustering, sensitivity to prompt phrasing, self-consistency across batches) are not quantified.
- Domain transferability of the LM-judge clustering rubric is untested; whether the same judge generalizes to non-math domains (e.g., code generation, logical proofs, instruction following) remains unknown.
- The risk that models “game” the diversity metric by producing surface-level differences that the judge mistakes for distinct strategies is acknowledged implicitly but not addressed experimentally (no adversarial or stress tests of the judge).
- The diversity measure d(x, y1:n) is coarse (fraction of distinct judge clusters) and zeros the set score if only one cluster is present (I(|U| > 1)); this gating can lead to vanishing gradients early in training when diversity is low—no mitigations or bootstrapping strategies are proposed.
- No ablations compare the chosen multiplicative objective (average reward × diversity) against alternative forms (e.g., geometric mean, soft-min, capped product, concave transforms) that could reduce brittleness when either factor is near zero.
- The claimed “covariance” synergy term is theoretically motivated but not empirically measured; there is no direct diagnostic demonstrating that Poly‑EPO increases positive reward–diversity covariance over training.
- Comparisons are limited to GRPO and a single reward-shaping baseline; no head-to-head evaluation against pass@k-aware objectives, inference-optimized policy training, or other exploration-centric LM post-training methods is provided.
- The relationship between training-time set size n and inference-time budget k (e.g., for pass@k or majority voting) is not characterized; it is unclear whether optimal n should match, exceed, or be independent of the target k.
- Token-level credit assignment is simplified by giving every token the same per-sequence advantage; whether finer-grained token-level or step-level credit could further improve reasoning exploration is left unexplored.
- Off-policy or replay-based variants are not considered; it is unclear how the set-RL update could be combined with experience replay, dataset aggregation, or offline RLHF pipelines.
- Safety implications of incentivizing exploration are not discussed; how to prevent exploratory generations from increasing harmful, unsafe, or policy-violating outputs is unaddressed.
- The approach assumes verifiable or easily judged rewards; applicability to non-verifiable tasks (where reliable external reward/verification is weak or absent) and how to integrate preference models or human feedback with set objectives are open questions.
- Sensitivity to the choice and scale of the LM-judge (e.g., smaller vs larger judges, instruction-tuned vs base) is not evaluated; compute overhead for running the judge at scale is not reported.
- Robustness to reward noise, spurious formatting hacks, or chain-of-thought artifacts that may inflate reward or perceived diversity is not studied.
- The effect of duplicate or near-duplicate generations among the N rollouts on set construction, diversity scores, and gradient variance is not analyzed.
- Reproducibility details are sparse (e.g., seeds, hardware, run times); key implementation details (e.g., the judge prompt and rubric referenced in the appendix) are not included in the main text for independent verification.
- Reported results focus on pass@k; no evidence is provided on whether Poly‑EPO preserves or improves pass@1 (greedy) performance, nor on calibration and confidence under single-sample decoding.
- The approach’s impact on different families of tasks (coding, multi-step planning, theorem proving beyond math competitions) is untested; generality claims across domains remain unsubstantiated.
- Alternative diversity estimators (e.g., representation-space clustering, edit-distance on derivations, AST-/proof-graph–based measures) are not benchmarked against the LM-judge, leaving the choice of diversity metric underexplored.
- No analysis is given on how noisy or inconsistent clustering labels propagate into the gradient (e.g., bias in the marginal set advantage due to systematic judge errors).
- The unspecified scaling factor M in Proposition 1 is not derived or estimated in practice; guidance on learning-rate adjustments to absorb M is not provided.
- Theoretical claims rely on symmetry of f and independence across samples; edge cases where sets include repeated generations or where f is non-symmetric (e.g., order-aware ensembles) are not covered.
- The synthetic “infinite-strategy” experiments are mentioned but not described in the excerpt; details on setup, metrics, and outcomes are needed to judge how Poly‑EPO behaves with unbounded strategy spaces.
- Interactions with test-time compute techniques beyond majority voting (e.g., verifier-guided sampling, tree search, re-ranking) are not explored; whether Poly‑EPO complements or replaces these methods is unclear.
- The effect of the set baseline being computed per-prompt (vs. cross-prompt) on optimization dynamics is not analyzed; potential coupling across prompts via global baselines is not evaluated.
- There is no discussion of fairness or bias introduced by judge-driven clustering (e.g., systematically under-recognizing uncommon but valid strategies), nor of methods to audit or correct such biases.
- Practical guidance for selecting n, N, and the cluster granularity (number of clusters) to target specific pass@k budgets is not provided; automatic adaptation of these hyperparameters during training remains open.
- No measurement of “true strategy diversity” (e.g., functional or proof-equivalence checks) is provided to validate that the judge’s cluster diversity corresponds to distinct underlying reasoning strategies.
Practical Applications
Immediate Applications
The paper introduces Poly-EPO—a scalable “set RL” post-training framework and a polychromic objective that explicitly balances accuracy and diversity of reasoning—plus a practical LM-judge clustering workflow. These can be applied today in domains where rewards are verifiable or strong proxy verifiers exist and where diversity improves pass@k or aggregation.
- Software engineering (code assistants and code search)
- What: Fine-tune code LMs with Poly-EPO to generate diverse algorithmic approaches and bug-fix strategies, improving pass@k and majority-vote/verification success in coding tasks.
- Tools/workflows: “Strategy palette” UI that shows clustered solution strategies; CI bots that sample N candidates, cluster by approach, unit-test, and select; GRPO/PPO pipelines with the marginal set advantage.
- Assumptions/dependencies: Availability of reliable unit tests or static analyzers; LM-judge can cluster by strategy (e.g., algorithmic pattern, data structure); added training-time compute (N>n rollouts per prompt).
- Education (math tutoring and assessment)
- What: Tutors that present multiple solution paths (e.g., algebraic vs. geometric proofs) per problem, improving learning and metacognition.
- Tools/workflows: “Explain-with-Alternatives” mode; pass@k-aware grading; formative feedback using clustered reasoning types.
- Assumptions/dependencies: Verifiable answer checking; judge prompt tuned to group by reasoning rather than style; safeguards for pedagogical quality.
- Analytics, BI, and decision support (low-risk internal settings)
- What: Generate alternative analytical approaches/hypotheses (e.g., different feature engineering or model selection pipelines) and select via holdout metrics.
- Tools/workflows: Batch sampling + clustering → multiple candidate analyses → automated evaluation/selection.
- Assumptions/dependencies: Clear, quantitative reward metrics (e.g., validation accuracy); compute budget for multi-candidate evaluation.
- Retrieval-augmented generation (RAG) and question answering
- What: Improve answer robustness by sampling diverse reasoning paths and evidence chains, then aggregating (self-consistency/verification).
- Tools/workflows: ToT/CoT agents that maintain diversity across branches; clustering-based deduplication before aggregation.
- Assumptions/dependencies: Calibrated verifiers (citation checkers, fact-checking); judge must cluster by reasoning/evidence, not stylistic surface form.
- Agent frameworks (planning and test-time compute)
- What: Increase effectiveness of ToT/beam search by training for diversity that is synergistic with accuracy, boosting downstream aggregator performance.
- Tools/workflows: Integrate Poly-EPO into agentic pipelines as a fine-tuning stage; portfolio-style branching with cluster-aware pruning.
- Assumptions/dependencies: Aggregation/verifier modules; compute budget for sampling multiple branches; judge reliability.
- RLHF/RLVR training pipelines (platform capability)
- What: Drop-in replacement for per-sample advantages with marginal set advantages to reduce mode collapse and tune-free exploration.
- Tools/workflows: “Set-RL optimizer” module for PPO/GRPO; U-statistics-based gradient estimator; dashboards monitoring diversity and pass@k coverage.
- Assumptions/dependencies: N>n rollouts per prompt; LM-judge microservice; alignment with existing logging and evaluation infra.
- Evaluation and QA (model auditing and regression testing)
- What: Quantify reasoning diversity and pass@k coverage during training; detect diversity collapse after RL fine-tuning.
- Tools/workflows: “Diversity judge” service; cluster-aware pass@k and coverage metrics by task; alerts on diversity drift.
- Assumptions/dependencies: Stable clustering rubric and exemplars; acceptable overhead for clustering at eval scale.
- Legal/knowledge work (drafting multiple argumentation lines)
- What: Produce clustered, distinct argument strategies or contract clauses to aid human experts in selection and synthesis.
- Tools/workflows: Draft N variants → cluster by legal theory/structure → human-in-the-loop review.
- Assumptions/dependencies: Human oversight; no automated reward—selection by experts; guardrails for hallucinations and compliance.
- Cybersecurity (hypothesis generation and red teaming)
- What: Explore multiple attack-path or mitigation hypotheses to broaden coverage in scenario testing.
- Tools/workflows: Sandbox-based verification; cluster by TTP/kill-chain phase; automated triage of unique ideas.
- Assumptions/dependencies: Strict containment and ethics/safety; verifiers for exploit feasibility; limited to internal use.
- Search/query expansion (enterprise search)
- What: Generate diverse query reformulations and reasoning trails to improve recall and disambiguation.
- Tools/workflows: Multi-query generation → cluster by semantic intent → rank/merge; measure via retrieval metrics.
- Assumptions/dependencies: Retrieval rewards as proxy verifiers; judge tuned to intent-level clustering.
Long-Term Applications
The same core ideas—set-level objectives and diversity–accuracy synergy—extend to higher-stakes domains or sequential tasks once verification, safety, and scalability improve.
- Healthcare decision support (differential diagnoses and care plans)
- What: Generate diverse, clustered differentials and workups, then filter via clinical guidelines and risk models.
- Potential tools: “Portfolio-of-diagnoses” copilots; cluster-aware triage assistants.
- Assumptions/dependencies: Clinician-in-the-loop oversight; validated clinical verifiers; regulatory compliance (HIPAA, MDR); robust safety constraints.
- Finance and risk management (scenario generation and stress testing)
- What: Explore diverse market/regulatory scenarios and hedging strategies, selecting via backtesting or simulators.
- Potential tools: “Scenario sets” module for risk engines; cluster-aware portfolio optimizers.
- Assumptions/dependencies: High-fidelity simulators/backtest frameworks; governance and model risk management; avoiding pro-cyclicality.
- Scientific discovery and AutoML/AutoScience
- What: Propose clustered hypotheses, experimental designs, or model families; select via lab automation or validation metrics.
- Potential tools: Hypothesis generator with diversity–accuracy synergy; automated experimental design assistants.
- Assumptions/dependencies: Reliable lab or simulation verifiers; domain-specific LM-judges; data provenance and reproducibility.
- Formal reasoning and theorem proving
- What: Improve exploration of proof strategies and tactics diversity; integrate with proof assistants for verification.
- Potential tools: “Poly-proof” search in Lean/Coq/Isabelle integrations; cluster-aware tactic portfolios.
- Assumptions/dependencies: Tight integration with proof checkers; computation for large-scale set sampling; benchmark coverage.
- Robotics and autonomous systems (planning with multiple strategies)
- What: Train planners to propose diverse, high-reward plan families (e.g., different grasps/routes) and select via cost models.
- Potential tools: Diversity-aware MPC planners; set-RL policy modules for sampling candidate plans.
- Assumptions/dependencies: Extension from single-turn to sequential set RL; real-time compute; safety certification.
- Energy systems and infrastructure planning
- What: Generate diverse grid expansion/dispatch scenarios and resilience plans; select via power-flow and reliability simulators.
- Potential tools: “Scenario sets” assistant for ISOs/TSOs; cluster-aware planning dashboards.
- Assumptions/dependencies: Accurate simulators; stakeholder constraints; regulatory oversight.
- Public policy design and governance analysis
- What: Produce clustered policy options (mechanism designs, regulatory levers) and assess via causal or agent-based models.
- Potential tools: Policy-portfolio assistants; deliberation support with clustered rationales.
- Assumptions/dependencies: Valid causal evaluators; transparency and bias auditing; human deliberation as final arbiter.
- Multi-agent and organizational decision-making
- What: Coordinate agent portfolios that cover complementary strategies, improving robustness to uncertainty.
- Potential tools: Set-RL coordination libraries; diversity-aware agent ensembles.
- Assumptions/dependencies: Theoretical extensions to multi-agent set objectives; compute and communication overhead.
- Safety, auditing, and standards
- What: Establish exploration–exploitation metrics (e.g., diversity of reasoning clusters vs. accuracy) as audit signals to detect mode collapse or reward hacking.
- Potential tools: “Exploration dashboards” for auditors; standardized cluster-based diversity metrics.
- Assumptions/dependencies: Agreement on taxonomies and rubrics; robust, attack-resistant judges; standard-setting processes.
- Developer platforms and training infrastructure
- What: Productize “Polychromic Optimization” as an SDK: a set-RL advantage module, LM-judge microservice, and diversity dashboards for RLHF/RLVR.
- Potential tools: Cloud services for set construction, clustering, and optimization; pass@k-centric training recipes.
- Assumptions/dependencies: Cost-effective training at scale; integration with diverse model families; privacy/security of data and logs.
Cross-cutting Assumptions and Dependencies
- Verifiers and rewards: Best suited to tasks with verifiable rewards (tests, proofs, simulators). High-stakes domains require high-precision verifiers and human oversight.
- Judge quality: Diversity depends on an LM-judge that clusters by reasoning strategy, not style. Prompting, rubrics, and few-shot examples are critical to avoid “gaming.”
- Compute and latency: Poly-EPO needs N independent rollouts per prompt (N>n) and clustering; training-time costs increase, though inference may save compute via higher pass@k.
- Generalization: Paper results are on 4B-scale math models; scaling to larger models and other domains may require tuning N, n, judge prompts, and infrastructure.
- Governance and risk: For regulated sectors (healthcare, finance), deployments require compliance, auditability, and clear human-in-the-loop processes.
Glossary
- Advantage function: The signal in policy gradient methods that measures how much better a sampled action (or generation) is relative to a baseline; used to weight log-probability gradients. "our algorithm's advantage function incorporates the covariance between average reward and diversity of strategies across sets."
- Baseline (set-level baseline): A variance-reduction term subtracted from the set-level objective so that updates depend on relative, not absolute, scores. "where is a set-level baseline."
- CISPO: A standard RL-style post-training algorithm for LLMs referenced alongside GRPO; the paper adopts its sampling pattern though not detailing it. "such as GRPO and CISPO."
- Covariance: A statistical measure capturing how two quantities vary together; here used to quantify synergy between reward and diversity in sets. "captures how the presence of generation affects the covariance between reward and diversity across sets containing ."
- Generator--verifier gap: The observation that verifying or judging solutions (e.g., clustering reasoning strategies) can be easier than generating them, enabling auxiliary judges to guide training. "which allows our method to exploit the generator--verifier gap."
- GRPO: A standard RL algorithm for LMs used as a baseline and adapted within the set-RL framework in this work. "such as GRPO"
- LM-judge: A LLM used as a judge to semantically cluster generations by reasoning strategy for diversity estimation. "a LLM judge (LM-judge) to cluster"
- Logit shift: The change in the log-probability (logit) of a generation after one gradient update, analyzable to understand optimization dynamics. "the logit shift looks as follows:"
- Majority voting: A test-time compute technique that aggregates multiple generations by selecting the most common answer. "under majority voting."
- Marginal set advantage: The per-generation credit in set RL, defined as the contribution of a generation to the expected set objective relative to the average set score. "We define the marginal set advantage"
- Markov decision process (MDP): The standard formalism for sequential decision making characterized by states, actions, transitions, rewards, and a discount factor. "A Markov decision process (MDP) is specified by"
- Monte Carlo estimate: An empirical estimator obtained by random sampling, used here to approximate gradients or set scores. "a Monte Carlo estimate"
- pass@: A coverage metric denoting whether at least one of k generations correctly solves a task; also used to describe objectives and evaluation. "pass@ coverage"
- pass@ objective: A set-level objective that scores a set positive if any generation in the set is correct. "consider the pass@ objective"
- Policy gradient: A method that computes gradients of expected reward with respect to policy parameters via log-probability weighting. "We can use the policy gradient"
- Polychromic Exploratory Policy Optimization (Poly-EPO): The proposed algorithm that optimizes a set-level objective coupling reward and diversity to synergize exploration and exploitation. "we propose Polychromic Exploratory Policy Optimization (Poly-EPO)"
- Polychromic objective: A set-level objective defined as the product of average reward and diversity of reasoning strategies within a set. "We use the polychromic objective"
- PPO: Proximal Policy Optimization, a widely used on-policy RL algorithm adapted here to operate with set-level advantages. "such as PPO"
- Reward shaping: The practice of modifying the reward with auxiliary terms (e.g., exploration bonuses) to guide learning. "through reward shaping"
- RLVR (Reinforcement Learning with Verifiable Rewards): An LM training setting where rewards can be programmatically verified, often in single-turn generation tasks. "reinforcement learning with verifiable rewards (RLVR)"
- Score-function identity: A technique (REINFORCE) for turning gradients of expectations into expectations of gradients of log-probabilities times a score. "Using the score-function identity to the joint density"
- Set reinforcement learning (set RL): A framework that assigns rewards to sets of sampled generations, coupling them with a shared learning signal. "Set reinforcement learning (set RL) is a framework"
- Softmax distribution: The parametrization of the policy as a softmax over logits, enabling analysis of logit shifts under updates. "as a softmax distribution."
- U-statistic estimator: An unbiased estimator constructed from combinations of samples (e.g., all subsets), used here for set-RL gradient estimation. "a U-statistic estimator of the set RL gradient"
- UCB bonus: An exploration bonus from Upper Confidence Bound methods, cited as one way to encourage exploration in reward shaping. "UCB bonus"
- Variance-reduction baseline: A baseline term designed to reduce gradient variance without introducing bias, here computed over set scores. "We construct a variance-reduction baseline"
Collections
Sign up for free to add this paper to one or more collections.