GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Abstract: As LLMs become increasingly capable, users expect them to provide not only accurate responses but also behaviors aligned with diverse human preferences across a variety of scenarios. To achieve this, Reinforcement learning (RL) pipelines have begun incorporating multiple rewards, each capturing a distinct preference, to guide models toward these desired behaviors. However, recent work has defaulted to apply Group Relative Policy Optimization (GRPO) under multi-reward setting without examining its suitability. In this paper, we demonstrate that directly applying GRPO to normalize distinct rollout reward combinations causes them to collapse into identical advantage values, reducing the resolution of the training signal and resulting in suboptimal convergence and, in some cases, early training failure. We then introduce Group reward-Decoupled Normalization Policy Optimization (GDPO), a new policy optimization method to resolve these issues by decoupling the normalization of individual rewards, more faithfully preserving their relative differences and enabling more accurate multi-reward optimization, along with substantially improved training stability. We compare GDPO with GRPO across three tasks: tool calling, math reasoning, and coding reasoning, evaluating both correctness metrics (accuracy, bug ratio) and constraint adherence metrics (format, length). Across all settings, GDPO consistently outperforms GRPO, demonstrating its effectiveness and generalizability for multi-reward reinforcement learning optimization.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization”
Overview: What is this paper about?
This paper looks at how to train AI LLMs (like chatbots) to be good at many things at once. For example, a model should be accurate, follow a specific format, keep answers short when needed, and avoid bugs in code. The authors show that a popular training method called GRPO struggles when there are multiple goals. They introduce a new method—GDPO—that handles multiple goals better, leading to more accurate, more stable, and more reliable models.
Objectives: What questions are the researchers trying to answer?
The paper aims to answer three main questions, in simple terms:
- Why does the common training method (GRPO) sometimes fail when we teach a model to optimize several goals at once?
- Can we fix this problem by changing how we combine and normalize the different rewards (scores) the model gets during training?
- Does the new method (GDPO) work better than GRPO across different tasks like using tools, solving math problems, and writing code?
Methods: How did they approach the problem?
Think of training an AI like grading a student’s homework using multiple rules:
- Accuracy (Did they get the right answer?)
- Format (Did they follow the required structure?)
- Length (Did they keep it short enough?)
- Bugs (Does their code run without errors?)
In reinforcement learning (RL), the model tries different answers (called “rollouts”), and we score each answer with multiple rewards, one for each goal. The model learns by comparing how good each answer is relative to others. That “how much better than average” signal is called the “advantage.”
Here’s the key difference between the two methods:
- GRPO (the old way): It adds up all the rewards into one total score, then normalizes that score within the group. This can cause different reward combinations to “collapse” into the same advantage values, blurring important differences. For example, an answer that gets 2 points by satisfying two goals can look the same (after normalization) as an answer that gets 1 point by satisfying just one goal. That confuses the learning process.
- GDPO (the new way): It first normalizes each reward separately (accuracy, format, length, etc.), then sums those normalized values, and finally does a light batch-wide normalization to keep numbers stable. This keeps the differences between goals clear, so the model learns the right lessons. In everyday terms: instead of mixing all the grades before scaling, GDPO scales each subject’s grade first (math, English, science), then combines them. That keeps each subject’s contribution visible.
They tested GDPO vs. GRPO on:
- Tool calling: Make the model call external tools correctly and follow a strict output format.
- Math reasoning: Solve tough math problems while keeping the response within a token length limit.
- Coding reasoning: Write code that passes tests, stays within length limits, and avoids bugs.
They used several open-source models (like Qwen and DeepSeek), standard RL training tools, and public benchmarks. They also tried a GRPO variant that removes one normalization step (“without std”) to see if that helps—it didn’t.
Findings: What did they discover, and why does it matter?
Across all tasks, GDPO performed better and trained more stably than GRPO.
Highlights:
- Tool calling:
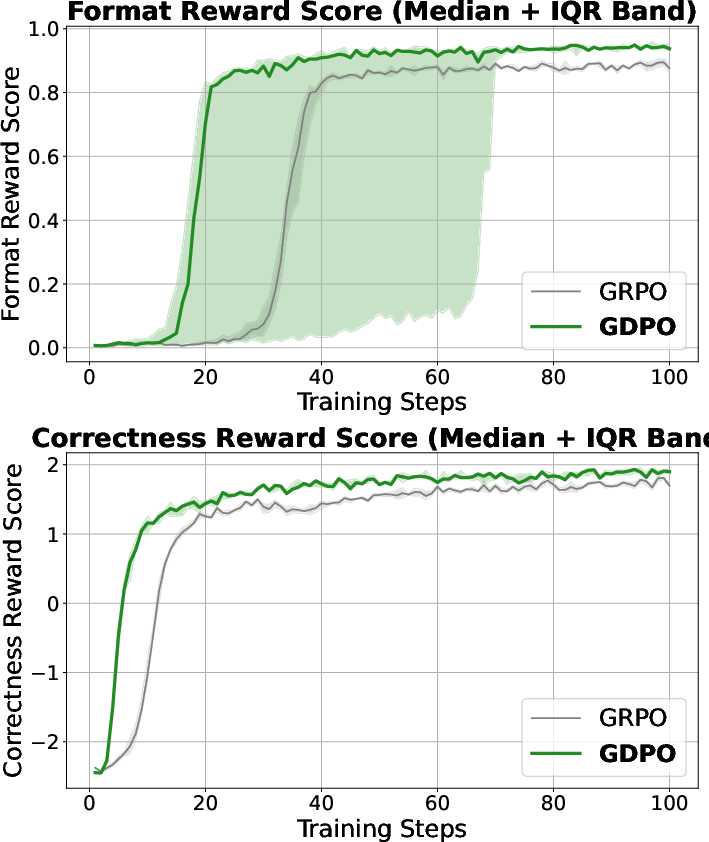
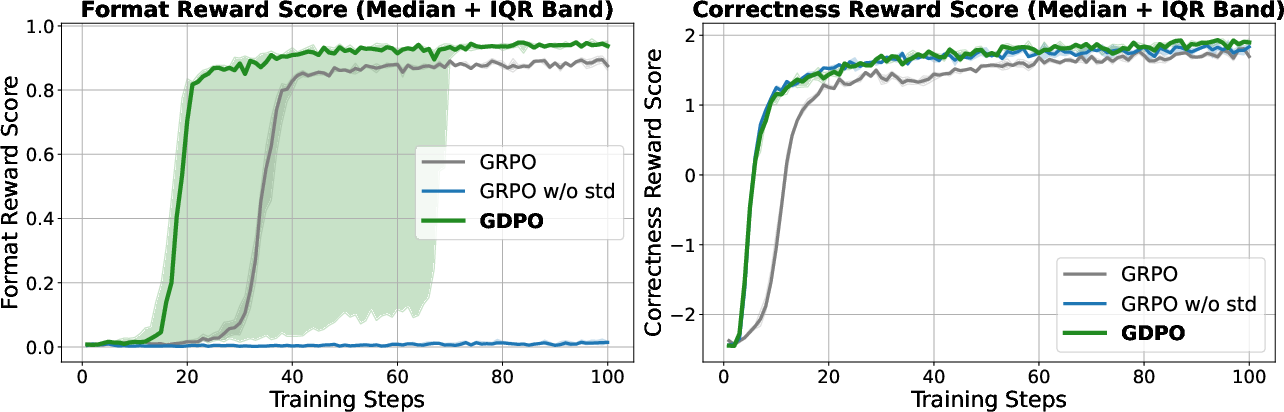
- GDPO improved both accuracy and format compliance compared to GRPO.
- On one model (Qwen2.5-Instruct-1.5B), GDPO increased average accuracy by about 2.7% and correct format ratio by over 4%.
- A GRPO variant that removed a normalization term achieved zero correct format—meaning it failed at learning the required structure.
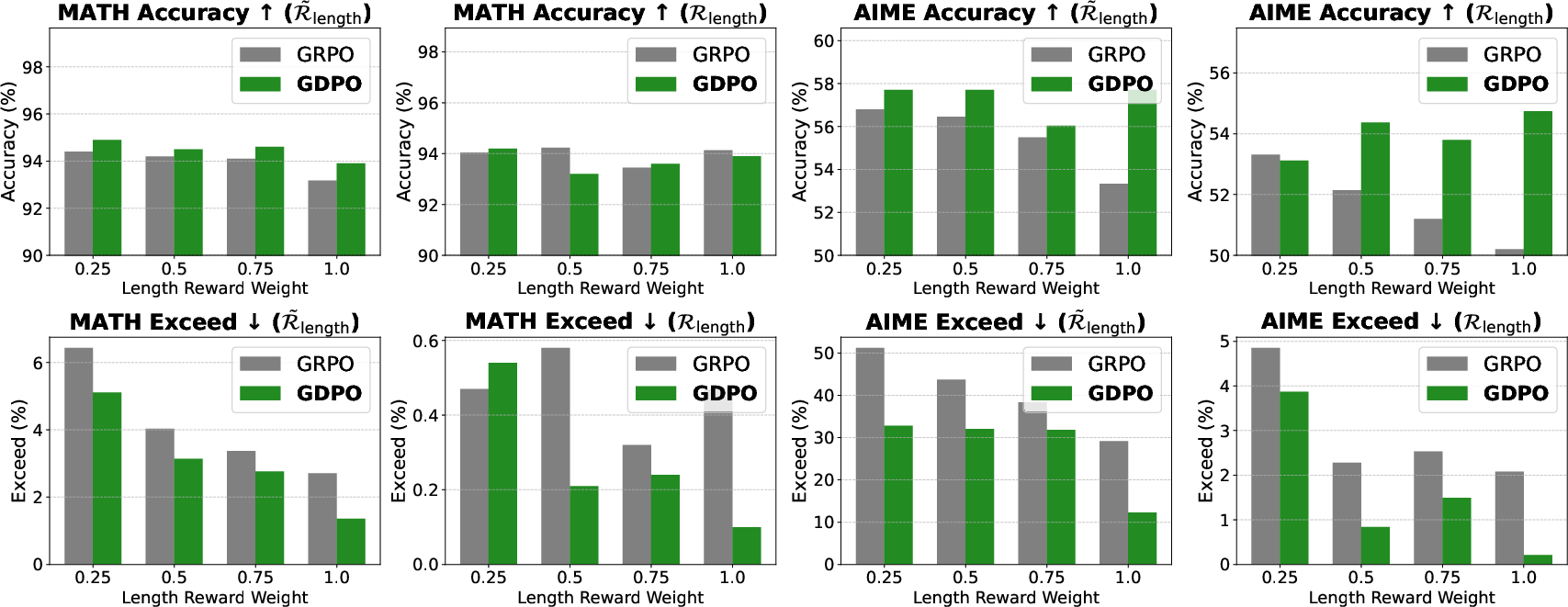
- Math reasoning:
- GDPO reduced the number of overlong answers dramatically (large drops in length violations).
- It often improved accuracy at the same time. For example, on the AIME math benchmark, GDPO achieved up to around 6.3% higher accuracy on one model and around 2.3% higher accuracy on another, while keeping more responses within the length limit.
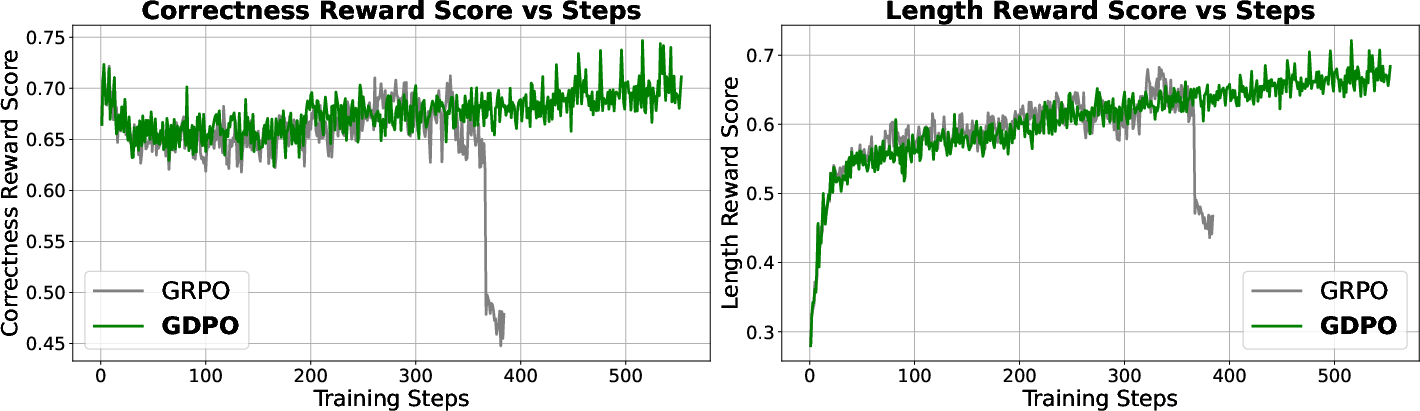
- GRPO sometimes became unstable during training (correctness scores fell after a while), while GDPO kept improving.
- Coding reasoning:
- With three rewards (pass rate, length, bug ratio), GDPO again outperformed GRPO, showing it scales to more complex multi-goal setups.
They also studied how to handle different priorities among rewards:
- If you simply reduce the weight of an “easy” reward (like length), the model may still chase it because it’s easy to satisfy.
- A better trick is “conditioning”: only give the length reward if the answer is correct. That forces the model to focus on correctness first. Combined with GDPO, this led to more predictable and better trade-offs (higher accuracy with reasonable length control).
Why this matters: In real-world systems, we rarely want just one behavior. We want models that are correct, brief, safe, well-formatted, and reliable. GDPO helps us train for all those goals at once without losing the signal that tells the model what matters.
Implications: What could this research change?
- Better multi-objective training: GDPO gives clearer, richer learning signals when optimizing several rewards, making training more stable and effective.
- Stronger alignment with human preferences: It’s easier to teach models to balance accuracy with rules like format and length.
- Practical improvements: Models trained with GDPO are more likely to be correct, follow instructions, and behave predictably, which is crucial for tools, coding assistants, and math solvers.
- Open-source impact: The authors released implementations (HF-TRL, verl, Nemo-RL), so others can adopt GDPO in their training pipelines.
- Policy design: The paper shows that smart reward design (like conditioning easy rewards on hard ones) combined with GDPO makes it much easier to reflect real-world priorities.
In short, GDPO helps AI learn multiple things at once without getting confused, making it a strong replacement for GRPO in multi-reward reinforcement learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Lack of formal theory: No convergence guarantees, regret bounds, or variance analyses are provided for GDPO; it remains unclear under what conditions GDPO provably improves stability or sample efficiency over GRPO in multi-reward settings.
- Advantage diversity vs. learning efficacy: The paper uses “number of distinct advantage groups” as a proxy for signal expressiveness, but does not establish a causal link to downstream performance or quantify when increased diversity helps or hurts learning.
- Sensitivity to reward distributions: GDPO’s per-reward normalization assumes finite variance and sufficient within-group diversity; the method’s behavior when rewards are highly skewed, sparse, degenerate (std ≈ 0), or heavy-tailed is not characterized.
- Batch-wise normalization design: The impact of batch-wise advantage normalization (e.g., choice of epsilon, normalization statistic, stability under non-stationary reward mixtures) is not analyzed, nor compared to alternatives (median/MAD normalization, rank-based scaling).
- Clip threshold interaction: The interplay between GDPO’s advantage scaling and the clipping threshold in GRPO-style objectives (e.g., gradient saturation, bias) is not studied; optimal clipping schedules for multi-reward training remain open.
- Model size and architecture generalization: Results focus on specific mid-sized LLMs (Qwen2.5 1.5B/3B, DeepSeek-R1 1.5B/7B, Qwen3-4B); it is unknown whether GDPO scales similarly to larger models (e.g., 70B, 100B+) or across architectures with different inductive biases.
- Domain breadth: Evaluation spans tool calling, math, and coding; generalization to other multi-preference tasks (e.g., safety, factuality, responsiveness, multilingual alignment, dialog politeness) is not demonstrated.
- Baseline coverage: Comparisons are limited to GRPO and GRPO w/o std; GDPO is not benchmarked against multi-objective RL baselines (e.g., PPO with scalarized rewards, constrained RL via Lagrange multipliers, Pareto RL, reward-weighted regression, value-based baselines).
- Value-model integration: The paper does not explore whether combining GDPO with a learned value baseline (to reduce variance) further improves stability or sample efficiency relative to purely group-relative updates.
- Off-policy applicability: It remains unclear whether GDPO can be adapted to off-policy settings, replay buffers, or importance sampling without introducing bias or instability.
- Rollout group size sensitivity: Although advantage-group counts are reported vs. G, the empirical effect of group size on training speed, variance, and final performance is not systematically studied.
- Number of rewards scaling: The impact of optimizing many rewards (e.g., >5–10 objectives) on compute, gradient interference, and advantage stability is not analyzed; practical limits and mitigation strategies are unknown.
- Reward type coverage: Most demonstrations use binary or small-range scalar rewards; GDPO’s behavior with continuous, composite, or learned (e.g., RM-based) rewards, and with non-additive aggregations (min/max lexicographic), is not evaluated.
- Credit assignment granularity: The effect of GDPO on token-level vs. sequence-level credit assignment (especially for long-horizon reasoning) is not dissected; the role of DAPO token-mean loss is not isolated via ablation.
- KL penalty usage: The KL-divergence term is omitted “for clarity,” but its practical role in experiments is unclear; how GDPO interacts with KL constraints (tuning, schedules) and prevents policy drift is not addressed.
- Hyperparameter robustness: There is no sensitivity study for key knobs (epsilon in batch normalization, reward weights, rollout count, batch size, max length, temperature/top-p at inference), leaving reproducibility and robustness uncertain.
- Conditioned rewards generality: Conditioning “easier” rewards on “harder” ones improves priority alignment, but the approach depends on thresholds and binary correctness; how to set thresholds, handle graded correctness, or avoid brittle gating is unresolved.
- Dynamic priority scheduling: The paper does not explore adaptive reward-weight schedules or curriculum strategies that react to training progress or difficulty imbalances in multi-reward optimization.
- Conflict quantification: No metric is provided to quantify the conflict between objectives (e.g., gradient cosine similarity) or to diagnose and mitigate gradient interference under GDPO.
- Exploration effects: Per-reward normalization and batch-wise scaling may dampen or distort exploration incentives; the impact on diversity of rollouts and avoidance of local minima is not analyzed.
- Stability failure modes: While GDPO reduces collapse observed with GRPO, failure cases for GDPO (e.g., degenerate rewards, zero-variance groups, extreme conflicts) and safeguards (fallback strategies) are not systematically documented.
- Evaluation protocol dependence: The influence of inference parameters (temperature/top-p, max tokens), extraction heuristics (answer parsing, format checks), and benchmark-specific idiosyncrasies on reported gains is not quantified.
- Statistical significance: Improvements are reported as averages across five runs with IQR plots, but formal statistical significance tests and confidence intervals for key metrics are absent.
- Computational footprint: The compute and memory overhead of GDPO (per-reward normalization, larger rollout groups) vs. GRPO is not measured; sample efficiency and cost-benefit trade-offs are unclear.
- Safety and bias alignment: Multi-reward optimization for safety, fairness, or bias mitigation is mentioned as motivation but not empirically tested; how GDPO manages trade-offs in sensitive objectives remains open.
- Real-world deployment: The paper does not evaluate robustness to distribution shifts (e.g., unseen tools/APIs, ambiguous math problems), or the reliability of GDPO-trained models under noisy or adversarial reward signals.
- Alternative normalization schemes: Other decoupling strategies (e.g., whitening across rewards, Pareto-aware normalization, per-reward rank transforms) are not compared; it is unknown if simpler variants could match GDPO’s gains.
- Threshold and weighting guidelines: Practical recipes for choosing reward weights and conditioning thresholds (beyond case-specific tuning) are not provided, limiting ease of adoption across tasks.
Practical Applications
Overview
This paper introduces GDPO, a policy optimization method for multi-reward reinforcement learning that decouples normalization per reward before aggregation, followed by batch-wise advantage normalization. Compared to GRPO, GDPO preserves finer distinctions across heterogeneous rewards, provides more expressive training signals, and improves convergence and stability. Demonstrations span tool calling (correctness + format), mathematical reasoning (accuracy + length constraints), and coding (pass rate + bug ratio + length). The paper also provides actionable guidance on reward prioritization via weighting versus conditional gating to address “easy reward dominance.”
Below are practical applications grouped by deployment time horizon, with sectors, potential tools or workflows, and key assumptions or dependencies noted.
Immediate Applications
These can be deployed now using the provided implementations (HF-TRL, verl, Nemo-RL) and existing RLHF/RLAIF pipelines.
- Stronger multi-objective alignment for enterprise LLMs — sectors: software, customer support, finance, legal, healthcare
- Tools/workflows: Replace GRPO with GDPO in RLHF/RLAIF phases; use decoupled normalization; add batch-wise advantage normalization; monitor correctness, format, and efficiency metrics.
- Assumptions/dependencies: Access to multi-reward definitions (e.g., helpfulness, safety, coherence), reward model(s)/heuristics, compute resources, KL regularization configuration.
- Reliable tool/function calling agents — sectors: software, RPA, DevOps, data engineering, CRM automation
- Tools/products: “GDPO Agent Trainer” that optimizes both tool-call correctness and output format; integrates with function-call benchmarks (e.g., BFCL), tool schemas, execution logs.
- Assumptions/dependencies: Ground-truth tool-call datasets or synthetic labels; well-defined format rewards; instrumented tool runtimes to verify name/parameter/content correctness.
- Concise and accurate math reasoning systems — sectors: education, edtech, test prep, research support
- Tools/workflows: Adopt dual rewards (correctness + length); use conditional length reward to prevent early collapse and prioritize correctness; deploy to tutoring and auto-grading systems.
- Assumptions/dependencies: High-quality math datasets with verified answers; chosen length limits aligned to UX; robust answer extraction; inference limits for long contexts.
- Safer, policy-compliant assistants with format guarantees — sectors: healthcare, finance, legal, social platforms
- Tools/products: Multi-reward alignment bundles combining safety, compliance, and formatting; decoupled normalization prevents reward signal collapse when mixing heterogeneous objectives.
- Assumptions/dependencies: Measurable safety/compliance signals; calibrated reward models; domain-specific red-teaming; audit trails.
- Code assistants with balanced correctness, quality, and efficiency — sectors: software engineering, QA
- Tools/workflows: Multi-reward RL with pass@k, bug ratio, and response-length constraints; integrate test runners and static analyzers as reward signals.
- Assumptions/dependencies: Test suites and harnesses; static analysis tooling; precise bug-detection criteria; representative coding datasets.
- Priority-aware reward design (weighting vs conditional gating) — sectors: AI platforms, MLOps
- Tools/products: Reward design playbooks and templates; “conditional reward gating” to enforce priorities (e.g., grant length reward only if correctness ≥ threshold).
- Assumptions/dependencies: Accurate difficulty assessment across objectives; avoidance of reward hacking; policy for threshold selection and monitoring.
- Training stability monitors and dashboards — sectors: MLOps, AI ops
- Tools/workflows: Track distinct advantage group counts, batch-wise max response length, per-reward trajectories; alert on collapse patterns common under GRPO.
- Assumptions/dependencies: Logging hooks in RL pipeline; analytics to compute advantage diversity and violation metrics; intervention policies.
- Drop-in upgrade path for existing GRPO pipelines — sectors: all using RLHF/RLAIF
- Tools/workflows: Swap GRPO with GDPO in HF-TRL/verl/Nemo-RL recipes; retain value-free optimization; re-tune clipping and KL coefficients minimally.
- Assumptions/dependencies: Compatibility with current training stacks; minor hyperparameter re-tuning; validation on target tasks.
- Benchmarking and evaluation enhancements — sectors: academia, benchmarking orgs
- Tools/workflows: Add multi-dimensional metrics (e.g., format adherence + correctness + efficiency); track exceed-length ratios and maximum lengths to capture worst-case violations.
- Assumptions/dependencies: Standardized schemas and scorers; reproducible inference configs; dataset curation.
- Consumer-facing assistants with predictable formatting and brevity — sectors: daily life, productivity apps
- Tools/products: Email/drafting assistants trained to balance correctness, brevity, and template adherence; improved reliability for structured outputs (forms, schedules).
- Assumptions/dependencies: Clear format definitions; rewardable behaviors (e.g., tag-based templates); user-acceptable brevity thresholds.
Long-Term Applications
These require further research, scaling, domain adaptation, or regulatory engagement.
- Multi-objective RL in robotics and autonomy — sectors: robotics, autonomous systems
- Tools/workflows: Apply GDPO to balance task performance, safety, energy efficiency, and comfort; decoupled normalization for heterogeneous sensor-derived rewards.
- Assumptions/dependencies: Accurate reward shaping in continuous control; safety validation; sim-to-real transfer; robust logging in physical environments.
- Healthcare decision support balancing accuracy, explainability, brevity, and safety — sectors: healthcare
- Tools/products: Clinical assistants aligned to multi-constraint objectives (e.g., correct diagnosis, concise summaries, explicit rationale).
- Assumptions/dependencies: High-quality labeled data; medically validated reward models; explainability standards; regulatory approvals (HIPAA, FDA).
- Financial advisory and trading assistants with profit, risk, and compliance constraints — sectors: finance
- Tools/workflows: Multi-reward policies for P&L, drawdown, compliance violations, latency/cost; use conditional gating to prioritize risk/compliance over profit.
- Assumptions/dependencies: Reliable simulators or live data; strict guardrails; auditability; model risk governance.
- Generalist autonomous agents optimizing correctness, cost, latency, and tool reliability — sectors: software, cloud, operations
- Tools/products: Cost-aware reward modules; orchestration stacks where GDPO balances multi-tool usage and SLAs.
- Assumptions/dependencies: Detailed cost/latency instrumentation; tool ecosystems; continuous evaluation pipelines; failure recovery strategies.
- Education: personalized tutors optimizing correctness, brevity, Socratic style, and engagement — sectors: education
- Tools/workflows: Reward models for pedagogical quality; conditional gating to ensure correctness before style/engagement rewards.
- Assumptions/dependencies: Pedagogy metrics; longitudinal learning outcomes; privacy and safety compliance.
- Policy and governance frameworks for multi-dimensional AI alignment — sectors: public policy, standards bodies
- Tools/products: Standardized multi-reward alignment protocols; reporting on safety/fairness/format/efficiency trade-offs; conformance tests.
- Assumptions/dependencies: Consensus on metrics; interoperability across vendors; regulatory oversight; public datasets.
- Edge/on-device RL for resource-constrained assistants — sectors: mobile, embedded, IoT
- Tools/workflows: Optimize length/latency/accuracy with GDPO under strict resource budgets; consider partial decoupling for low-memory regimes.
- Assumptions/dependencies: Efficient RL or distillation pipelines; hardware constraints; privacy-preserving training.
- Multi-objective alignment for scientific assistants — sectors: research, pharma, materials
- Tools/products: Balancing factuality, citation integrity, hypothesis clarity, and brevity; conditional rewards for correctness before stylistic objectives.
- Assumptions/dependencies: Domain-specific verification tools; curated corpora; responsible use policies.
- Industry-wide benchmarks and datasets for multi-reward RL — sectors: academia, benchmarking consortia
- Tools/workflows: Expanded leaderboards with multi-reward tasks (tool-calling, math, coding, safety); standardized reward schemas; advantage diversity metrics.
- Assumptions/dependencies: Community buy-in; reproducible evaluation suites; sustained maintenance.
- Automated reward engineering platforms — sectors: AI tooling
- Tools/products: Systems that suggest reward weights vs conditional gating; simulate advantage group diversity under GDPO; auto-tune per-reward normalization.
- Assumptions/dependencies: Meta-evaluation loops; guardrails against reward hacking; scalable training and validation infrastructure.
- Compliance-first vertical assistants — sectors: legal, healthcare, finance
- Tools/workflows: Conditional reward structures that strictly gate secondary objectives (brevity, style) on compliance/safety correctness; GDPO ensures signal fidelity across objectives.
- Assumptions/dependencies: Formal compliance criteria; reliable detection models; audit logs; certification pathways.
Each long-term application benefits from GDPO’s core property: preserving distinctions across heterogeneous rewards to produce stable, accurate multi-objective optimization. Feasibility depends on high-fidelity reward signals, robust evaluation, domain adaptation, and governance structures to manage trade-offs in sensitive contexts.
Glossary
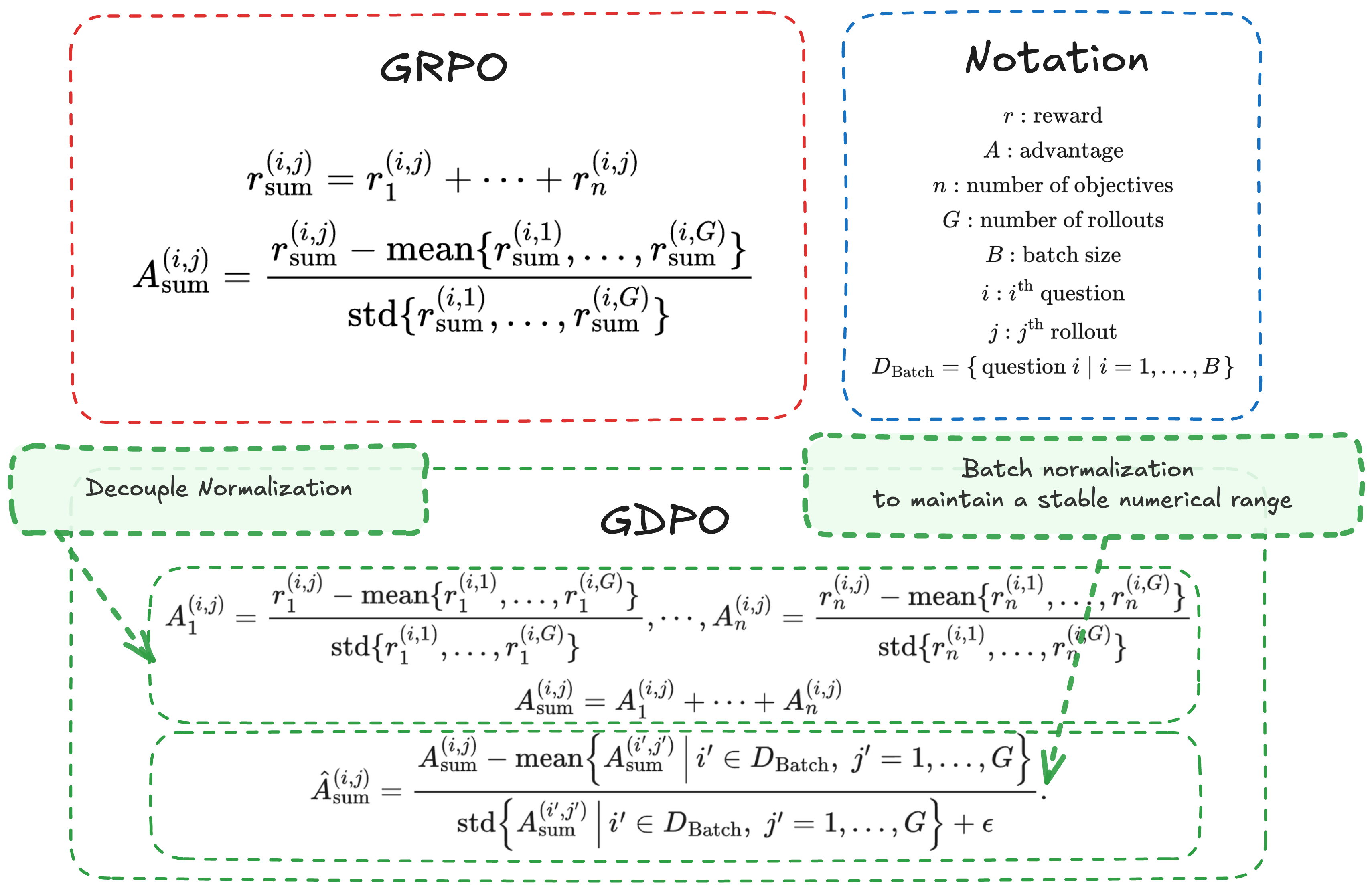
- Advantage: In reinforcement learning, a measure of how much better an action or token is compared to a baseline in its context. "The overall advantage used for policy updates is then obtained by first summing the normalized advantages across all objectives:"
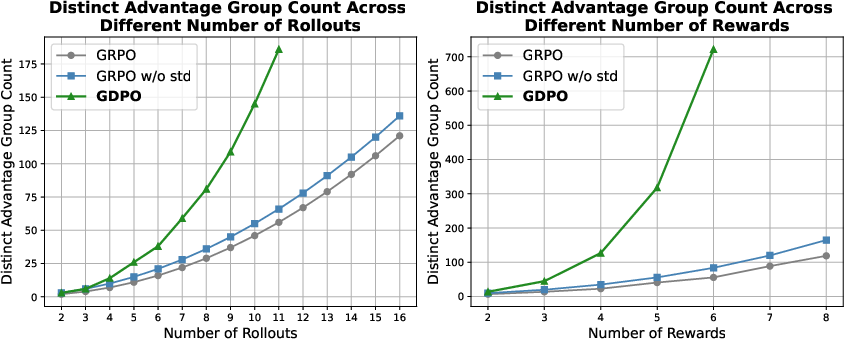
- Advantage granularity: The fineness with which distinct advantage values differentiate reward or rollout combinations. "where GDPO exhibits progressively larger advantage granularity as the objective count grows."
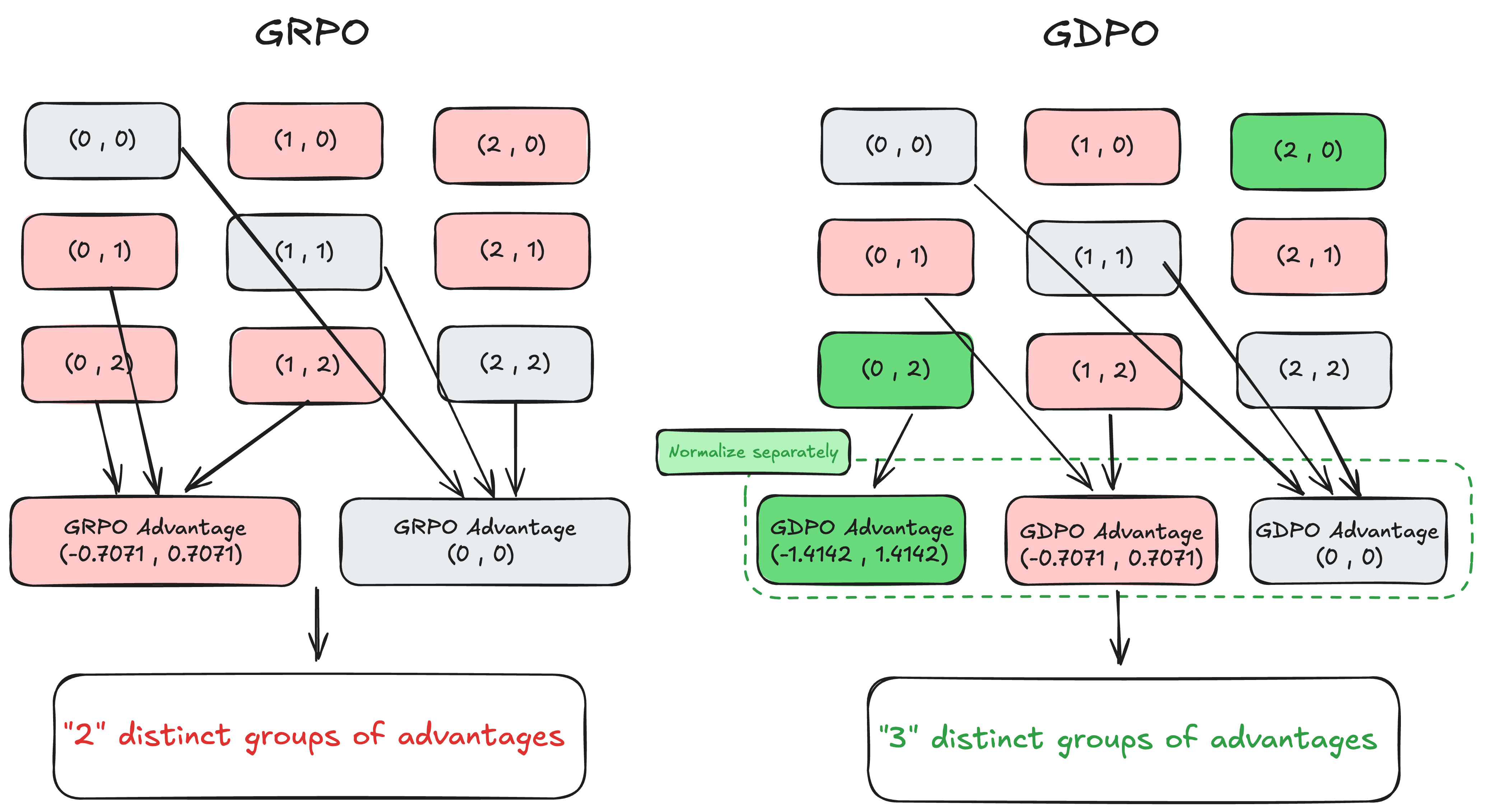
- Advantage groups: Sets of responses that receive identical normalized advantage values after normalization. "GDPO consistently preserve a substantially larger number of distinct advantage groups compared to GRPO and GRPO w/o std."
- Aggregated reward: The combined reward from multiple objectives for a rollout or response. "the aggregated reward for the -th response is computed as the sum of each objective’s reward:"
- Batch-wise advantage normalization: Normalizing computed advantages across the entire batch to stabilize scale. "which performs group-wise normalization per reward and then applies batch-wise advantage normalization to preserve a stable numerical range independent of reward count and improve update stability."
- Berkeley Function Call Leaderboard (BFCL-v3): A comprehensive benchmark for evaluating tool/function calling capabilities. "We evaluate the trained models on the Berkeley Function Call Leaderboard (BFCL-v3)~\cite{patilberkeley}, a comprehensive benchmark..."
- Bug ratio: The proportion of generated code samples that contain bugs. "evaluating both correctness metrics (accuracy, bug ratio) and constraint adherence metrics (format, length)."
- Clipping threshold: The bound used in clipped policy objectives to limit update magnitude. "and denotes the clipping threshold."
- Code pass rate: The fraction of generated code that successfully passes tests or evaluation criteria. "code pass rate and bug ratio."
- Conditioned length reward: A reward given only when both the length constraint and correctness are satisfied. "we replace the original length reward $\mathcal{R}_{\text{length}$ with a conditioned length reward defined as:"
- DAPO: A GRPO-related variant used in RL fine-tuning pipelines. "Recent advancements such as Group Relative Policy Optimization (GRPO)~\citep{guo2025deepseek} and its variants, including DAPO~\citep{yu2025dapo} and Reinforce++-Baseline~\citep{hu2025reinforce++}, have emerged as widely adopted reinforcement learning algorithms due to their efficiency and simplicity."
- Dynamic sampling: A training strategy that varies sampling settings during RL to stabilize or improve learning. "Following the DLER setup~\cite{liu2025dler}, we incorporate dynamic sampling, higher clipping thresholds, and the token-mean loss from DAPO~\cite{yu2025dapo}..."
- Format compliance: Adherence to required output structure and formatting constraints. "attains both higher correctness and format compliance than GRPO on the tool-calling task."
- GDPO: Group reward-Decoupled Normalization Policy Optimization; a method that decouples normalization per reward before aggregation. "We then introduce Group reward-Decoupled Normalization Policy Optimization (GDPO), a new policy optimization method..."
- GRPO: Group Relative Policy Optimization; a RL algorithm using group-relative advantage without a value model. "Recent advancements such as Group Relative Policy Optimization (GRPO)~\citep{guo2025deepseek} and its variants..."
- Group-relative advantage: Advantage computed relative to other rollouts within the same group (question). "The group-relative advantage for the -th response is then obtained by normalizing the group-level aggregated rewards:"
- Group-wise normalization: Normalization performed over the rollouts for each question (group). "GDPO decouples this process by performing group-wise normalization of each reward separately before aggregation."
- Interquartile range (IQR): A robust dispersion measure capturing the middle 50% of values. "Median and IQR reward curves over five runs of Qwen2.5-Instruct-1.5B tool-calling RL..."
- KL-divergence: A regularization term penalizing divergence from the old policy during RL fine-tuning. "For clarity, we omit the KL-divergence loss term in this formulation."
- Length constraint: A limit on response length imposed during training or evaluation to encourage efficiency. "We consider a mathematical reasoning task that optimizes two implicitly competing rewards: accuracy and adherence to a length constraint."
- Length-exceeding ratio (Exceed): The percentage of outputs that violate the predefined length limit. "and report the average pass@1 score and the average length-exceeding ratio, denoted Exceed, which measures the percentage of model responses that exceed the predefined length limit of 4000 tokens."
- Multi-reward RL optimization: Optimizing with multiple reward signals simultaneously to align models with diverse preferences. "a better alternative to GRPO for multi-reward RL optimization."
- Pass@1: An accuracy metric indicating whether the first sampled solution solves the problem. "we generate 16 samples and report the average pass@1 score"
- Policy optimization objective: The objective function used to update the policy parameters in RL. "The corresponding multi-reward GRPO optimization objective can then be expressed as:"
- Policy updates: Parameter updates to the policy guided by advantages and objectives. "In contrast to Proximal Policy Optimization (PPO)~\cite{schulman2017proximal}, GRPO eliminates the need for a value model by leveraging group-relative advantage estimation for policy updates."
- Proximal Policy Optimization (PPO): A popular on-policy RL algorithm employing clipped objectives and value baselines. "In contrast to Proximal Policy Optimization (PPO)~\cite{schulman2017proximal}, GRPO eliminates the need for a value model..."
- Reinforce++-Baseline: A GRPO-related RL variant used in LLM training. "and its variants, including DAPO~\citep{yu2025dapo} and Reinforce++-Baseline~\citep{hu2025reinforce++}, have emerged as widely adopted reinforcement learning algorithms..."
- Reward collapse: A phenomenon where normalization maps diverse reward combinations to identical advantages, degrading learning signal. "GRPO's propensity for reward signal collapse in multi-reward RL"
- Reward hacking: Model behavior that exploits easier rewards rather than the intended objectives. "some recent works~\cite{liu2025laser,liu2025dler} address such reward hacking by conditioning easier rewards on more difficult rewards."
- Reward weights: Scalars applied to individual rewards to encode objective priorities. "It is common practice to assign different weights to each reward to encode different priorities among objectives..."
- Rollouts: Multiple sampled responses from the current policy for the same prompt/question. "Consider a scenario where we generate two rollouts for each question for calculating the group-relative advantage..."
- Standard deviation normalization: Division by group standard deviation during normalization to scale advantages. "removes the standard deviation normalization term from Eq.~\ref{eq:grpo_advantage}"
- Token-mean loss: A loss formulation averaging token-level objectives (from DAPO) for RL fine-tuning. "we incorporate dynamic sampling, higher clipping thresholds, and the token-mean loss from DAPO~\cite{yu2025dapo}"
- Tool calling: An LLM task involving invoking external tools/functions within the reasoning process. "We compare GDPO with GRPO on the tool calling task..."
- Top-p (top-p sampling): Nucleus sampling parameter controlling the probability mass of tokens considered during generation. "a sampling temperature of 0.6, = 0.95"
- Value model: A learned baseline estimating expected return to reduce variance in policy gradients. "GRPO eliminates the need for a value model by leveraging group-relative advantage estimation..."
- vLLM: An LLM inference engine used as backend for evaluation. "All evaluations are conducted using vLLM as the inference backend..."
Collections
Sign up for free to add this paper to one or more collections.