A Survey of Vibe Coding with Large Language Models
Abstract: The advancement of LLMs has catalyzed a paradigm shift from code generation assistance to autonomous coding agents, enabling a novel development methodology termed "Vibe Coding" where developers validate AI-generated implementations through outcome observation rather than line-by-line code comprehension. Despite its transformative potential, the effectiveness of this emergent paradigm remains under-explored, with empirical evidence revealing unexpected productivity losses and fundamental challenges in human-AI collaboration. To address this gap, this survey provides the first comprehensive and systematic review of Vibe Coding with LLMs, establishing both theoretical foundations and practical frameworks for this transformative development approach. Drawing from systematic analysis of over 1000 research papers, we survey the entire vibe coding ecosystem, examining critical infrastructure components including LLMs for coding, LLM-based coding agent, development environment of coding agent, and feedback mechanisms. We first introduce Vibe Coding as a formal discipline by formalizing it through a Constrained Markov Decision Process that captures the dynamic triadic relationship among human developers, software projects, and coding agents. Building upon this theoretical foundation, we then synthesize existing practices into five distinct development models: Unconstrained Automation, Iterative Conversational Collaboration, Planning-Driven, Test-Driven, and Context-Enhanced Models, thus providing the first comprehensive taxonomy in this domain. Critically, our analysis reveals that successful Vibe Coding depends not merely on agent capabilities but on systematic context engineering, well-established development environments, and human-agent collaborative development models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
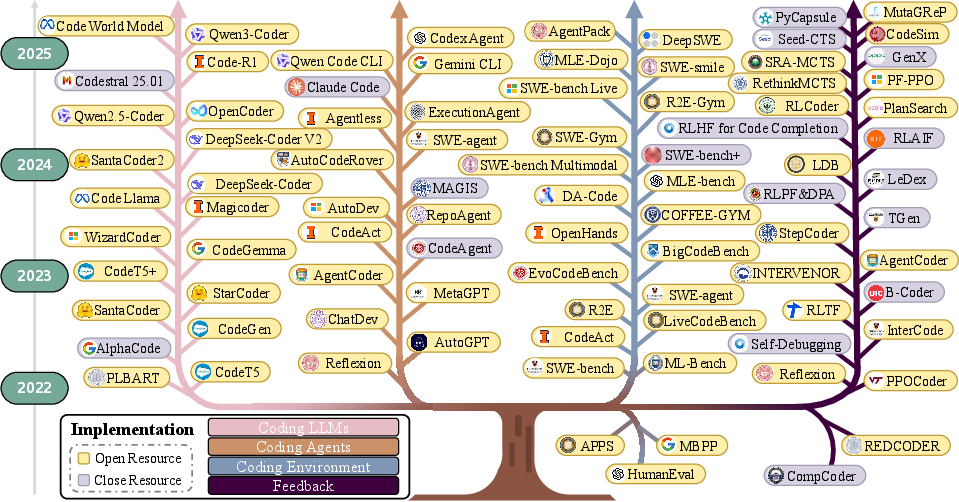
This paper explains a new way of building software with AI called “Vibe Coding.” Instead of humans carefully reading every line of code, developers describe what they want in plain language, let an AI “coding agent” try it, watch what happens, and then give feedback. The paper surveys over 1000 research studies to describe how Vibe Coding works, what tools it needs, and what challenges it faces.
Key objectives and questions
The paper tries to answer simple but important questions:
- What exactly is Vibe Coding, and how does it change how people build software?
- How do AI coding agents work, and what do they need to be successful?
- What kinds of development styles are people using with these agents?
- Why do some teams get great results while others don’t?
- What problems still need to be solved (like security, human-AI teamwork, and practical tools)?
How did the researchers study this?
The authors did a “survey,” which means they read and organized a huge number of papers to build a big-picture view of the field. They also created a simple model to explain how Vibe Coding works:
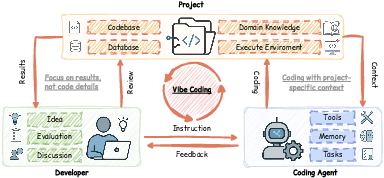
- Imagine a video game:
- The human developer is the player who says the goal and the rules (what to build and what counts as “good”).
- The software project is the game world (the codebase, data, and documents).
- The AI agent is the character that makes moves (writes code, runs tests, fixes errors).
- The system keeps looping: the agent tries something, the developer watches the result, gives feedback, and the agent improves.
They call this setup a “Constrained Markov Decision Process.” In everyday terms, it’s a way to describe decision-making with rules and feedback, just like playing by the rules in a strategy game.
Main findings and why they matter
The paper organizes Vibe Coding into a clear “ecosystem” with four key parts. This helps people see the full picture, not just the AI model:
- LLMs for coding: the brains that can write and understand code.
- Coding agents: the AI workers that plan, remember, use tools, run code, and fix mistakes.
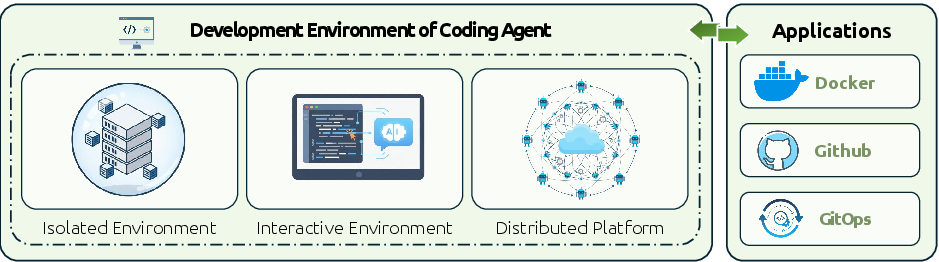
- Development environments: safe places where agents can run code, talk to tools, and work with humans.
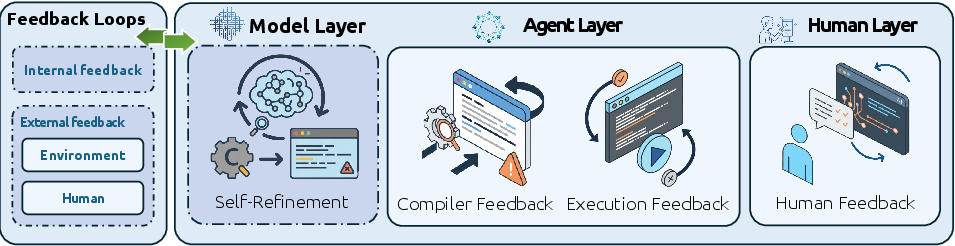
- Feedback mechanisms: ways the system learns if it’s right (compiler errors, test results, human feedback, and self-checking).
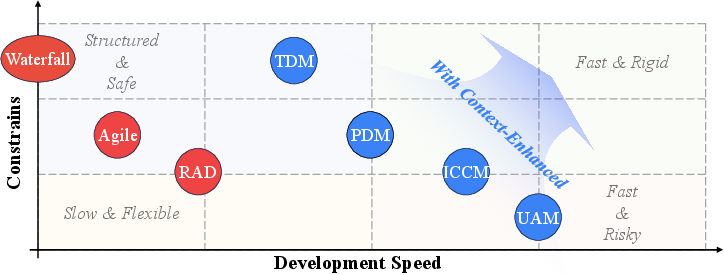
The authors also found five common development models used in practice. These are like different playstyles depending on what the project needs:
- Unconstrained Automation: “Let the agent do most of the work” with minimal human control.
- Iterative Conversational Collaboration: “Talk it out”—humans and agents go back and forth step by step.
- Planning-Driven: The agent makes a plan first, then executes it.
- Test-Driven: Write tests up front, then use them to guide the agent’s coding and fixes.
- Context-Enhanced: Carefully feed the agent the right background info (code, docs, examples) so it doesn’t get confused.
Why this matters:
- Powerful agents alone aren’t enough. Success depends on clear instructions, the right context, good tools, and smart teamwork between humans and AI.
- Surprisingly, some teams reported getting slower when using AI without good structure or clear prompts. This shows that “just add AI” isn’t a guaranteed productivity boost.
- The field is moving fast, but it needs better security, safer environments, and human-centered design to be trustworthy and widely useful.
Implications and potential impact
If done well, Vibe Coding could:
- Give solo developers “team-level” powers. An agent can set up servers, write tests, and fix bugs while the human focuses on ideas and quality.
- Speed up development while keeping quality high, thanks to continuous testing and automated fixes.
- Open software creation to more people. Non-programmers (like doctors, teachers, or designers) can describe what they want in plain language and guide the agent by checking results.
However, the paper also warns that teams need good practices:
- Plan how humans and agents share work.
- Use strong test suites and safe environments.
- Invest in “context engineering” (feeding the agent the right parts of the project).
- Build security and guardrails from the start.
In short, this survey gives both a map of the current landscape and a practical guide for using AI coding agents responsibly. It shows that the future of software isn’t just “AI writes code,” but “humans and AI work together”—with clear goals, smart feedback, and the right tools to make ideas real.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper’s treatment of Vibe Coding with LLMs.
- Formalization validity: The Constrained MDP formalization is not empirically validated; mapping real development artifacts to concrete state, action, transition, and reward definitions remains unspecified and needs experimental grounding across diverse projects.
- Reward design: The paper does not define operational reward functions that capture multi-objective software quality (correctness, performance, security, maintainability); methods to combine or trade off these objectives are absent.
- Context orchestration algorithms: While “optimal context engineering” is framed as an objective, no concrete retrieval, filtering, ranking, or budgeting algorithms (nor their complexity or approximation guarantees) are proposed or benchmarked for large repositories.
- Theoretical guarantees: There are no convergence guarantees or bounds for the iterative human-agent loop (e.g., conditions under which refinement terminates, bounds on cycles, or regret analyses under constrained contexts).
- Model-to-practice mapping: The triadic “human-project-agent” components lack standardized schemas for instrumentation and logging to enable reproducible measurements of interactions and outcomes in real environments.
- Development model selection: The taxonomy of five development models is not accompanied by decision criteria (task characteristics, codebase size, risk profile) or comparative evidence that guides when to use each model.
- Benchmarking gaps: There is no Vibe Coding-specific benchmark that captures requirement evolution, environment setup, long-horizon tasks, and outcome-driven validation beyond pass/fail unit tests (e.g., repository-level, multi-iteration workflows).
- Metrics design: The survey does not propose standardized metrics for Vibe Coding (e.g., agent cycles to acceptance, human time vs. agent time, context-token budget, test stability, rollout reproducibility, maintainability indices).
- Productivity and UX evidence: Human-factor claims (e.g., observed productivity losses) lack standardized protocols and measures (cognitive load, trust calibration, effort distribution, error oversight), and no controlled studies compare development models.
- Feedback interplay: The relative effectiveness, sequencing, and weighting of compiler, execution, human, and self-refinement feedback are not studied; there is no framework for conflict resolution among heterogeneous signals.
- Test-driven dynamics: The paper does not examine how test quality, flakiness, and coverage influence agent behavior; methods for LLM-assisted test generation that avoid “teaching to the test” remain under-specified.
- Multi-agent coordination: Protocols for role assignment, consensus, conflict resolution, and token/cost budgeting in multi-agent coding remain unstandardized and untested at scale.
- Memory safety and consistency: Agent memory mechanisms lack guidelines for preventing stale or contradictory context, ensuring provenance, and enforcing retention policies (privacy, compliance); no consistency models are proposed.
- Tool reliability: Function calling and tool integration do not include systematic error classification, recovery strategies, or self-calibration protocols for unreliable external tools and APIs.
- Environment drift: The survey does not address how agents detect and adapt to environment changes (dependencies, OS differences, CI/CD pipelines), nor standards for sandboxing and reproducibility across platforms.
- Cost and energy efficiency: There is no analysis of latency, throughput, compute cost, or energy footprint of agent workflows; cost-aware planning and caching strategies are not explored.
- Security threat modeling: A comprehensive threat model (prompt injection, dependency supply chain attacks, exfiltration via tools, privilege escalation) and systematically evaluated defenses (isolation, policy enforcement, attestations) are missing.
- Governance and accountability: The paper does not specify audit logging, review workflows, acceptance criteria, rollback mechanisms, or assignment of responsibility for agent-made changes in regulated contexts.
- Licensing and compliance: Code license compatibility, attribution, and legal risks from training data and generated code (including synthetic rewriting) are not analyzed or operationalized in agent toolchains.
- Silent failures and subtle bugs: Detection strategies for non-crashing, semantic bugs and performance regressions are unaddressed; risk scoring and triage methods for agent outputs remain open.
- Domain generalization: The survey does not assess Vibe Coding performance in specialized domains (embedded, real-time, safety-critical, hardware description languages, GPU kernels) or propose domain adaptation protocols.
- Maintainability trade-offs: Long-term code health implications of agent-generated code (style drift, technical debt, documentation gaps) are unmeasured; refactoring policies and maintainability metrics are absent.
- Data quality auditing: Pipeline-level auditing for training corpora (duplication, contamination, license provenance, domain coverage) and for synthetic instruction/preference data is not standardized or evaluated.
- Long-context strategies: No comparative study of retrieval vs. extended-context models for large repositories; chunking, linking, and code-aware segmentation strategies lack empirical guidance.
- Error taxonomy: A standardized taxonomy for agent coding errors (specification misunderstanding, context misuse, tool misuse, environment misconfiguration) and associated mitigation playbooks is missing.
- Human-in-the-loop protocols: Best practices for prompt structuring, context curation, and oversight cadence are not codified into repeatable operating procedures with empirical validation.
- Outcome-based validation: The paper does not operationalize “result-oriented review” (what outcomes to measure, acceptable variance, validation pipelines) beyond unit tests.
- Reproducibility controls: Methods to achieve deterministic agent outputs (seed control, environment snapshotting, fixed tool versions) and auditability are not proposed.
- Lifecycle integration: CI/CD and DevOps integration patterns (gating policies, automated rollbacks, staged deploys with agent participation) are not addressed.
- Educational scaffolding: Training curricula or onboarding frameworks for developers transitioning to Vibe Coding (skills, pitfalls, mental models) are not provided or evaluated.
- Ethical use and misuse: Guardrails for misuse (mass code generation of insecure patterns, automated exploitation, plagiarism) and societal impacts are not analyzed with concrete mitigation strategies.
- Evaluation transparency: Many referenced systems are reported via heterogeneous metrics; a transparent, unified evaluation protocol with open datasets, seeds, and logs is not established.
- Cross-organizational adoption: Organizational readiness, policy changes, and socio-technical factors for adopting Vibe Coding at scale remain unexplored; case studies and longitudinal evidence are absent.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed today by leveraging the survey’s formalization (triadic human–project–agent CM-DP), the five development models (Unconstrained Automation, Iterative Conversational Collaboration, Planning-Driven, Test-Driven, Context-Enhanced), and the ecosystem of tools (e.g., OpenHands, AutoGen, MetaGPT, AgentCoder, TestGen-LLM, ProjectTest, Git Context Controller, AutoSafeCoder).
- Software engineering: repository-level bug triage and patching
- What: Use coding agents to localize faults, propose patches, run tests, and open PRs on existing repos (SWE-bench-style tasks).
- Best-fit models: Test-Driven + Context-Enhanced (RAG over repo + automated tests).
- Tools/workflows: OpenHands, AutoCodeRover, Agentless; issue-to-PR pipelines with CI.
- Sector: Software/DevOps.
- Assumptions/dependencies: Adequate unit/integration tests; sandboxed execution; CI gatekeeping; secrets isolation; human-in-the-loop code review.
- Continuous test generation and coverage boosting in CI/CD
- What: Auto-generate missing unit/property tests, regenerate flaky tests, and enforce failing-first red/green cycles.
- Best-fit models: Test-Driven.
- Tools/workflows: TestGen-LLM, ProjectTest, TypeTest, Execution feedback loops; GitHub Actions/GitLab CI.
- Sector: Software Quality Engineering.
- Assumptions/dependencies: Clear acceptance criteria; stable CI infrastructure; test data management; deterministic environments.
- Context-aware code assistance via Git-aware retrieval
- What: RAG pipelines retrieve relevant files/issues/docs for precise code edits and refactors.
- Best-fit models: Context-Enhanced + Iterative Conversational.
- Tools/workflows: Git Context Controller, CodeRAG, MemoryBank; IDE integrations (LSP, Cursor/VS Code).
- Sector: Software development.
- Assumptions/dependencies: Accurate repo indexing; permissions + data governance; long-context LLMs or chunking strategies.
- Planning-driven scaffolding for new microservices
- What: Generate project skeletons, API contracts, tests, and deployment manifests from high-level specs.
- Best-fit models: Planning-Driven + Test-Driven.
- Tools/workflows: MetaGPT, ChatDev, CrewAI, TOSCA/TosKer for deployment descriptors.
- Sector: Software/Cloud/DevOps.
- Assumptions/dependencies: Organizational templates/standards (linting, security baselines); IaC and container runtime availability.
- Conversational pair programming in IDEs (agent-in-the-loop)
- What: Iterative “vibe” loops to add features, debug, and refactor without line-by-line human reading.
- Best-fit models: Iterative Conversational Collaboration.
- Tools/workflows: LSP-based IDEs, Cursor, code review bots; Self-Refine/Reflexion loops.
- Sector: Software development; Education.
- Assumptions/dependencies: Logging/audit of agent actions; coding conventions; code ownership policies.
- Automated code review and documentation drift repair
- What: Multi-agent reviewer/commenter that enforces checklists, generates review suggestions, and updates docs to match code.
- Best-fit models: Planning-Driven + Context-Enhanced.
- Tools/workflows: AutoGen multi-agent patterns; Doc2Agent; PR comment bots; API diffs with RAIT/Seeker.
- Sector: Software engineering.
- Assumptions/dependencies: Review guidelines as prompts/policies; repo-level RAG; protected branches and required checks.
- API migration and large-scale refactoring assistance
- What: Identify deprecated APIs, generate safe replacements, and run/refine tests.
- Best-fit models: Planning-Driven + Test-Driven.
- Tools/workflows: RAIT, Code search + spectrum-based localization; automated PR batching by subsystem.
- Sector: Software modernization.
- Assumptions/dependencies: Up-to-date dependency graph; reliable test harness; staged rollouts.
- DevSecOps: security scanning with auto-remediation proposals
- What: Integrate static/dynamic scanning and propose patches; run in isolated sandboxes before PRs.
- Best-fit models: Test-Driven + Context-Enhanced.
- Tools/workflows: AutoSafeCoder, Secure SDLC checklists; isolated runtimes; policy-as-code gates.
- Sector: Security/Compliance.
- Assumptions/dependencies: Vulnerability feeds; SBOM availability; secrets handling; human approval for merges.
- On-call runbooks as executable agent workflows
- What: Incident bots that parse alerts, run diagnostics, apply safe fixes, and file postmortems.
- Best-fit models: Planning-Driven + Iterative Conversational.
- Tools/workflows: OpenHands for terminal actions; MCP/Toolformer-style function calling; structured SOP prompts.
- Sector: SRE/Operations.
- Assumptions/dependencies: Least-privilege credentials; rollback mechanisms; guardrail policies; audit trails.
- Performance tuning suggestions from execution feedback
- What: Agents profile hot paths, propose optimizations, generate microbenchmarks, and validate speedups.
- Best-fit models: Execution Feedback + Test-Driven.
- Tools/workflows: PerfCodeGen; benchmark harnesses; A/B in CI; canary deployments.
- Sector: Software performance engineering.
- Assumptions/dependencies: Representative workloads; safe performance counters; no regression to correctness.
- Data and analytics: auto-validated SQL and data checks
- What: Generate SQL/ETL with schema-aware validation and tests; detect data quality issues.
- Best-fit models: Test-Driven + Context-Enhanced.
- Tools/workflows: SQLucid; type/schema retrieval; dbt tests; CI on data pipelines.
- Sector: Analytics/BI/Finance/Healthcare.
- Assumptions/dependencies: Reliable schema metadata; non-production data sandboxes; governance for PHI/PII.
- Education: agent-supported labs and grading in sandboxes
- What: Students interact with agents to build/repair code; automated grading via execution-based benchmarks.
- Best-fit models: Iterative Conversational + Test-Driven.
- Tools/workflows: InterCode, SandboxEval, SWE-bench subsets; per-student isolated runtime.
- Sector: Education/EdTech.
- Assumptions/dependencies: Academic integrity policies; visible provenance of AI support; reproducible sandboxes.
- Research: reproducible agent evaluations and ablations
- What: Run agent studies with standard environments, feedback channels, and metrics.
- Best-fit models: Any (as experimental variables).
- Tools/workflows: SWE-bench, SandboxEval; AutoGen orchestration; clear prompts/policies.
- Sector: Academia/ML systems.
- Assumptions/dependencies: Fixed datasets; versioned prompts; hardware budget for repeated runs.
- Policy/compliance operations for AI-assisted coding
- What: Institute guardrails: sandboxing, action logging, code provenance tags, and license checks for training/eval data.
- Best-fit models: Test-Driven (policy-as-tests).
- Tools/workflows: The Stack-derived curation pipelines; commit provenance labeling; Secure SDLC gates.
- Sector: Policy/Compliance/Legal.
- Assumptions/dependencies: Organizational buy-in; legal guidance on IP/licensing; change management.
- No-/low-code productivity for domain experts
- What: Build internal tools, forms, dashboards, or automation scripts with intent-first conversational workflows.
- Best-fit models: Iterative Conversational + Planning-Driven.
- Tools/workflows: ChatDev/MetaGPT starter templates; agent-scaffolded UIs/DB schemas; guided test harnesses.
- Sector: Line-of-business apps (marketing, HR, operations), Daily life.
- Assumptions/dependencies: Role-based access; guardrails to prevent data exfiltration; curated component libraries.
Long-Term Applications
These require further research, scaling, formal assurance, or organizational/policy development before broad deployment.
- Autonomous repository evolution with minimal oversight
- What: Agents that monitor issues, plan roadmaps, implement features, and maintain tests.
- Best-fit models: Planning-Driven + Context-Enhanced + Test-Driven (combined).
- Tools/workflows: Multi-agent role systems (MetaGPT/CrewAI), long-term memory, scheduling/orchestration.
- Sector: Software engineering at scale.
- Assumptions/dependencies: Robust alignment, reliable long-context memory, strong safety/audit controls, mature evaluation metrics.
- Safety-/mission-critical code synthesis with formal verification
- What: Integrate compilers, model checkers, and proof tools into vibe loops for provably correct code.
- Best-fit models: Test-Driven + Compiler/Execution Feedback.
- Tools/workflows: Verified toolchains; property-based specs; proof-carrying code pipelines.
- Sector: Healthcare devices, Automotive/Avionics, Energy/Industrial control.
- Assumptions/dependencies: Formal specs; certification pathways; liability frameworks; very low defect tolerance.
- Org-scale multi-agent SDLC orchestration (from product to ops)
- What: Product-manager, architect, developer, QA, SecOps agents coordinating across portfolios.
- Best-fit models: Planning-Driven + Agent Collaboration.
- Tools/workflows: AutoGen/CrewAI/MetaGPT with resource managers; enterprise tool mesh (MCP/ScaleMCP).
- Sector: Large enterprises, software platforms.
- Assumptions/dependencies: Interoperable tool APIs; governance of cross-agent communication; programmatic budgets/quotas.
- Self-improving agents learning from production telemetry
- What: Agents that mine logs and user feedback to auto-generate tests and patches, closing quality gaps continuously.
- Best-fit models: Self-Refinement + Execution Feedback.
- Tools/workflows: Reflexion/Self-Refine-class loops; telemetry-to-test generation; rollout safeties.
- Sector: Consumer SaaS, Mobile, Web platforms.
- Assumptions/dependencies: Privacy-preserving data capture; drift detection; safe canaries; rollback strategies.
- Massive cross-repo refactoring and dependency upgrades
- What: Consistent API and policy changes across thousands of services with automated validation.
- Best-fit models: Planning-Driven + Test-Driven.
- Tools/workflows: Hierarchical planning; staged migration waves; batch PR creation and merge queues.
- Sector: Big tech monorepos/microservices estates.
- Assumptions/dependencies: Uniform test baselines; dependency graphs; change risk modeling.
- Sector-specific agentic SDLCs with regulatory constraints
- What: Finance risk-model code, healthcare EHR integrations, energy SCADA adapters built with compliance-first agents.
- Best-fit models: Context-Enhanced (domain knowledge) + Test-Driven.
- Tools/workflows: Domain RAG over standards (HIPAA, SOX); test policies as constraints; audit-by-design.
- Sector: Finance, Healthcare, Energy.
- Assumptions/dependencies: Domain corpora; regulator-accepted evidences; compliance automation.
- Standardized function-calling and tool ecosystems
- What: Interoperable tool schemas enabling portable agent workflows across vendors and edges.
- Best-fit models: Action Execution (function calling) + Planning-Driven.
- Tools/workflows: MCP/ScaleMCP-like standards; marketplace of validated tools.
- Sector: Software, Robotics, Enterprise automation.
- Assumptions/dependencies: Open standards; tool certification; security isolation by default.
- Privacy-preserving on-device developer agents
- What: Tiny agents that match server capabilities locally for sensitive codebases.
- Best-fit models: Iterative Conversational + Context-Enhanced (local RAG).
- Tools/workflows: TinyAgent-class models; efficient indexing; secure enclaves.
- Sector: Defense, IP-sensitive industries; Daily life (local automation).
- Assumptions/dependencies: Hardware acceleration; efficient long-context; energy constraints.
- Automated security patch management at ecosystem scale
- What: Continuous ingestion of CVEs, impact analysis, patch authoring, and staged rollout across fleets.
- Best-fit models: Planning-Driven + Test-Driven + Execution Feedback.
- Tools/workflows: Vulnerability C2; simulated exploit tests; compliance gates; enterprise orchestration.
- Sector: Security/Platform engineering.
- Assumptions/dependencies: Legal approvals for automated changes; accurate impact modeling; emergency brake controls.
- Education at scale: curricula around vibe coding
- What: Studio-style courses where students manage agents; evaluation by execution and reflective reports.
- Best-fit models: Iterative Conversational + Test-Driven + Self-Refinement.
- Tools/workflows: Standardized sandboxes; benchmarks (SWE-bench); plagiarism-resistant assessment.
- Sector: Academia/EdTech.
- Assumptions/dependencies: Pedagogical standards; assessment validity; accessibility.
- Policy and certification for AI-generated code
- What: Labels for AI-authored diffs, audit requirements, SBOM extensions, and certification regimes.
- Best-fit models: Test-Driven (policy-as-tests) integrated with CM-DP constraints.
- Tools/workflows: Provenance tags; audit logs of agent actions; license/compliance scanners.
- Sector: Policy/Regulatory.
- Assumptions/dependencies: Harmonized international standards; enforcement mechanisms; industry consortia.
- Human-centered agent UX and governance dashboards
- What: Role-aware interfaces exposing intent, context, constraints, and reversible plans to reduce cognitive overhead.
- Best-fit models: Iterative Conversational + Planning-Driven.
- Tools/workflows: MultiMind/PairBuddy-style UIs; decision logs; capability scoping controls.
- Sector: Product/DevTools.
- Assumptions/dependencies: Usability research; explainability features; org policy alignment.
- Verified multi-modal agent systems (code + UI + data)
- What: Agents that reason across code, GUIs, and datasets with formal guardrails and task proofs.
- Best-fit models: Planning-Driven + Execution/Compiler Feedback.
- Tools/workflows: Multimodal LLMs; UI automation + sandboxed OS agents; formal specs for cross-modal tasks.
- Sector: Robotics, Healthcare IT, Enterprise apps.
- Assumptions/dependencies: Robust multimodal reasoning; secure GUI automation; formal verification maturity.
- Economic and workforce transition programs
- What: Reskilling for vibe coding workflows, new roles (agent wrangler, context engineer), and AI-driven SDLC practices.
- Best-fit models: Organizational adoption of Iterative Conversational + Test-Driven governance.
- Tools/workflows: Training curricula; competency frameworks; change management toolkits.
- Sector: Policy/Workforce development.
- Assumptions/dependencies: Public-private partnerships; funding; measurable outcome tracking.
In practice, the survey’s key insight—that success depends as much on context engineering, robust environments, and human-agent collaboration models as on raw model capability—implies that even “Immediate Applications” should be implemented with explicit constraints, sandboxes, tests, and governance. “Long-Term Applications” become feasible as foundations mature: longer/more reliable context, standardized tool ecosystems, formal methods integration, and clear regulatory frameworks.
Glossary
- Alignment (outer and inner alignment): Research and methods to ensure model behavior matches intended objectives; outer alignment concerns specified goals, inner alignment concerns the model’s learned optimization. "Alignment research categorizes methods into outer and inner alignment with adversarial considerations, while exploring training-free alignment and personalized alignment techniques"
- Auto-regressive generation: A sequence modeling approach where each token is generated conditioned on previously generated tokens. "the Agent generates code sequence Y = (y_1, \ldots, y_T) in an auto-regressive manner"
- Chain-of-Thought (CoT): A prompting technique that encourages models to produce step-by-step reasoning to improve problem solving. "Chain-of-Thought (CoT) reasoning has proven particularly effective"
- Constrained Markov Decision Process (Constrained MDP): A decision-making framework like an MDP but with explicit constraints on policies or costs. "a Constrained Markov Decision Process"
- Context engineering: The systematic construction, retrieval, filtering, and ranking of contextual information to optimize LLM outputs. "Effective human-AI collaboration demands systematic prompt engineering and context engineering"
- Direct Preference Optimization (DPO): An RL-free method that optimizes models directly from pairwise preference data to align outputs with desired choices. "DPO emerges as an reinforcement learning RL-free alternative to RLHF"
- Edge deployment: Running models or agents on local or edge devices to reduce latency and reliance on centralized infrastructure. "enable edge deployment with compact models matching large model capabilities locally"
- Execution feedback: Information from running code (e.g., tests, runtime logs) used to guide refinement or learning. "execution feedback obtained from running o_k in environment \mathcal{E}"
- Fill-in-the-middle objectives: Training objectives where the model infers a missing middle segment of code given surrounding context. "with fill-in-the-middle objectives and PII redaction"
- Function calling: A mechanism for LLMs to invoke external tools or APIs via structured calls. "Function calling frameworks teach LLMs to self-supervise tool use with simple APIs requiring minimal demonstrations"
- Group Relative Policy Optimization (GRPO): A reinforcement learning method that optimizes policies using relative advantages computed across groups. "Group Relative Policy Optimization with compiler feedback to achieve competitive performance"
- In-context learning: Using prompts and examples at inference time to adapt model behavior without updating parameters. "Prompt engineering and in-context learning have emerged as fundamental techniques"
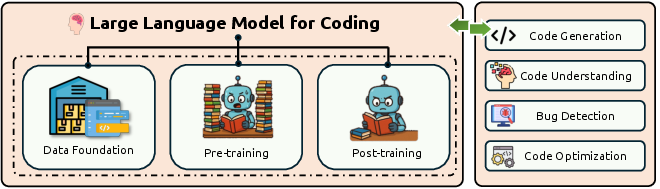
- Instruction tuning: Fine-tuning models on instruction-following datasets to improve adherence to user directives. "Instruction tuning and supervised fine-tuning methodologies are reviewed covering dataset construction and training strategies"
- Language Server Protocol (LSP): A standardized protocol that connects editors/IDEs to language-specific tooling (e.g., completion, diagnostics). "Language server protocol"
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning technique that adds low-rank matrices to adapt large models with minimal additional parameters. "Low-Rank Adaptation (LoRA)"
- Monte Carlo Tree Search (MCTS): A search algorithm that explores decision trees via random sampling to guide planning. "integrate Monte Carlo Tree Search with external feedback for deliberate problem-solving"
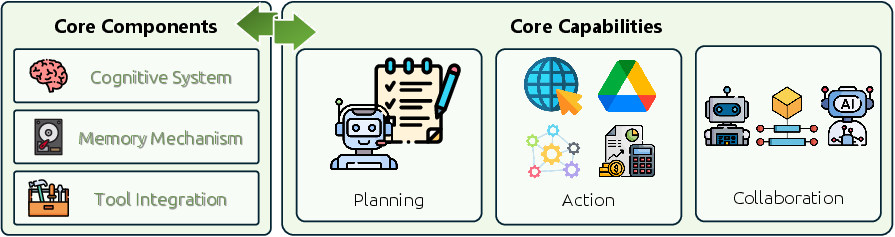
- Multi-agent systems: Architectures where multiple agents coordinate and communicate to solve complex tasks collaboratively. "Multi-agent systems are examined covering agent profiling, communication protocols, and collaborative workflows across complex task-solving scenarios"
- Parameter-efficient methods: Techniques to adapt large models using a small number of additional parameters (e.g., LoRA, adapters). "parameter-efficient methods including Low-Rank Adaptation (LoRA) and adapters"
- PII redaction: The removal or masking of personally identifiable information from datasets to protect privacy. "PII redaction"
- Proximal Policy Optimization (PPO): A popular policy gradient RL algorithm that stabilizes training via clipped objectives. "Execution-based methods leverage PPO with compiler feedback for real-time refinement"
- Repository-level pretraining: Pretraining on entire code repositories (including issues and documentation) to improve long-context code understanding. "Foundation models for code employ repository-level pretraining with extended context windows"
- Retrieval-Augmented Generation (RAG): Augmenting generation by retrieving relevant external knowledge or context at inference time. "tool use with Retrieval-Augmented Generation (RAG) and feedback learning"
- Reinforcement Learning from AI Feedback (RLAIF): Alignment via RL that uses feedback provided by AI models rather than humans. "Reinforcement Learning from Human Feedback (RLHF), Reinforcement Learning from AI Feedback (RLAIF), and Direct Preference Optimization (DPO)"
- Reinforcement Learning from Human Feedback (RLHF): Alignment via RL using human preference signals to steer model outputs. "Reinforcement Learning from Human Feedback (RLHF)"
- Spectrum-based fault localization: Debugging technique that ranks code elements by their correlation with failing versus passing tests. "spectrum-based fault localization"
- Test-driven development (TDD): A methodology where tests are written before code, guiding implementation through incremental passes. "investigate test-driven development principles"
- Triadic relationship: The three-way interaction framework among human developers, software projects, and coding agents underpinning Vibe Coding. "a dynamic triadic relationship among human developers, software projects, and Coding Agents"
- Unit test feedback: Signals from unit test execution used to improve code generation or RL training. "using unit test feedback"
- Vibe Coding: A development paradigm where developers validate AI-generated implementations via outcome observation rather than line-by-line code review. "we define Vibe Coding as an engineering methodology for software development grounded in LLMs"
- Zero-shot-CoT: Prompting that elicits chain-of-thought reasoning without providing few-shot exemplars. "Zero-shot-CoT"
Collections
Sign up for free to add this paper to one or more collections.