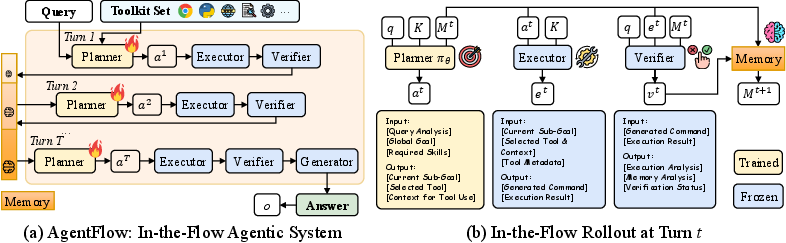
In-the-Flow Agentic System Optimization for Effective Planning and Tool Use
Abstract: Outcome-driven reinforcement learning has advanced reasoning in LLMs, but prevailing tool-augmented approaches train a single, monolithic policy that interleaves thoughts and tool calls under full context; this scales poorly with long horizons and diverse tools and generalizes weakly to new scenarios. Agentic systems offer a promising alternative by decomposing work across specialized modules, yet most remain training-free or rely on offline training decoupled from the live dynamics of multi-turn interaction. We introduce AgentFlow, a trainable, in-the-flow agentic framework that coordinates four modules (planner, executor, verifier, generator) through an evolving memory and directly optimizes its planner inside the multi-turn loop. To train on-policy in live environments, we propose Flow-based Group Refined Policy Optimization (Flow-GRPO), which tackles long-horizon, sparse-reward credit assignment by converting multi-turn optimization into a sequence of tractable single-turn policy updates. It broadcasts a single, verifiable trajectory-level outcome to every turn to align local planner decisions with global success and stabilizes learning with group-normalized advantages. Across ten benchmarks, AgentFlow with a 7B-scale backbone outperforms top-performing baselines with average accuracy gains of 14.9% on search, 14.0% on agentic, 14.5% on mathematical, and 4.1% on scientific tasks, even surpassing larger proprietary models like GPT-4o. Further analyses confirm the benefits of in-the-flow optimization, showing improved planning, enhanced tool-calling reliability, and positive scaling with model size and reasoning turns.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about building a smarter AI “agent” that can plan its steps, use tools like web search or a calculator, check its own work, and then write a clear final answer. The authors introduce a system called AgentFlow. Instead of relying on one big model to do everything at once, AgentFlow is like a team with different roles that work together across several steps. The key idea is to train this team while it’s actually doing tasks (in the flow), so it learns what choices lead to success.
What questions does the paper ask?
- How can we make AI better at long, multi-step problems where you only know if you were right at the very end (like solving a hard math or research question)?
- Can a team of specialized parts (planner, tool user, checker, writer) learn to work together better than one big, do-everything model?
- Is there a way to train this planner directly during real, multi-step tasks so it learns which choices truly matter?
- Will this approach make tool use (like web search or code execution) more reliable and effective?
How does AgentFlow work?
Think of AgentFlow as a small team with a shared notebook that records everything it does. On each turn, the team plans a step, tries it, checks it, updates its notebook, and repeats until it’s ready to give a final answer.
Here are the four roles:
- Planner: Decides the next step, like which sub-goal to tackle and which tool to use (e.g., search the web, run Python).
- Executor: Uses the chosen tool and returns the result.
- Verifier: Checks if the step worked and whether there’s enough info to finish.
- Generator: Writes the final answer once the work is done.
The “shared notebook” (called evolving memory) is a clean, structured record of what happened so far. It keeps the process transparent and makes sure the system doesn’t lose track when tasks get long.
How is it trained? (In everyday terms)
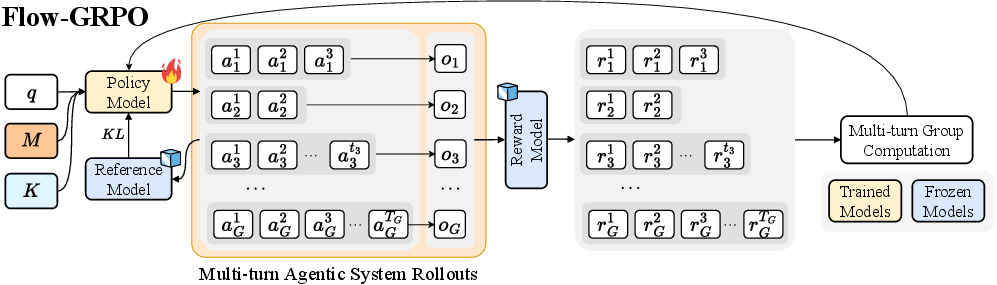
Training happens “in the flow,” meaning the planner learns while actually solving multi-step tasks—not from old transcripts alone. The main trick is a method called Flow-GRPO:
- Real-world practice: The system runs through a task across several turns. It plans steps, calls tools, and updates its notebook, just like it would in real use.
- One final score: Instead of guessing which step was “good” or “bad,” the system gets a single, clear score at the end—was the final answer correct or not?
- Fair credit for all steps: That final score is sent back to every step in the process. This is like a sports team reviewing a game: the final win/loss helps every player adjust their choices next time.
- Stable learning: The method compares each attempt to others in the same group (group-normalized advantages), which keeps training steady and avoids wild swings.
Why this helps: Long problems often don’t have obvious step-by-step grades. By using the final result and sharing it with every step, the planner learns which patterns of decisions lead to wins.
What did they find?
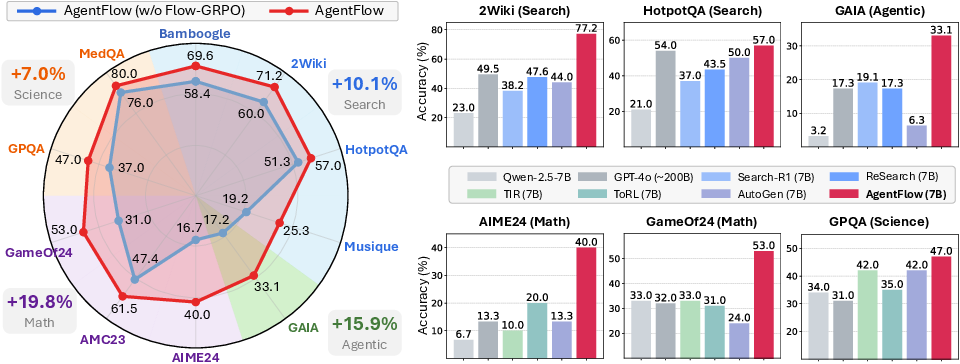
The authors tested AgentFlow on 10 different benchmarks covering:
- Knowledge-heavy search (e.g., answering multi-hop questions across web or Wikipedia)
- “Agentic” tasks (multi-step, tool-using tasks)
- Math reasoning
- Science/medical questions
Key results:
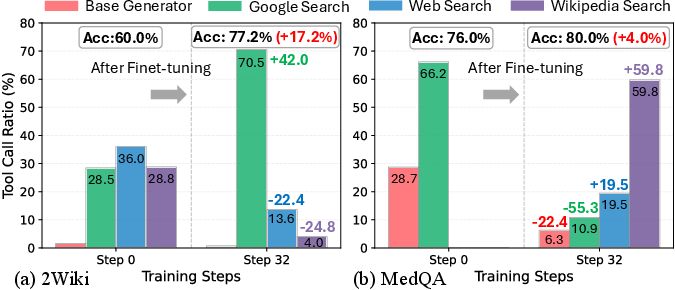
- Big accuracy gains over strong baselines: On average, AgentFlow improved by about 15% on search, 14% on agentic tasks, 15% on math, and 4% on science compared to top competing systems.
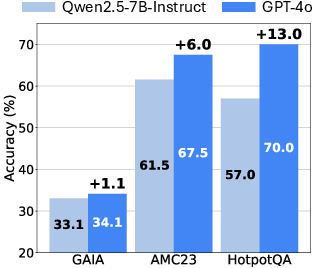
- Small model beats very large model: Using a ~7B-parameter backbone, AgentFlow even outperformed GPT-4o (a ~200B model) on these benchmarks. In short: better training and teamwork beat pure size.
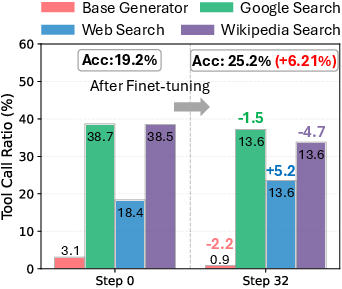
- Smarter tool choices: After training, the planner picked tools more wisely. For broad knowledge tasks, it used general web search more; for specialized tasks like medical questions, it shifted toward focused tools (Wikipedia or page-specific search).
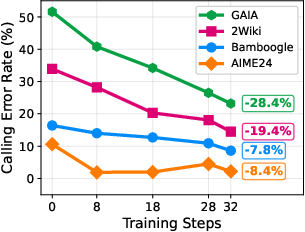
- Fewer tool mistakes: Tool-calling errors (like wrong arguments or formats) dropped a lot—up to 28.4% in one benchmark—making the system more reliable.
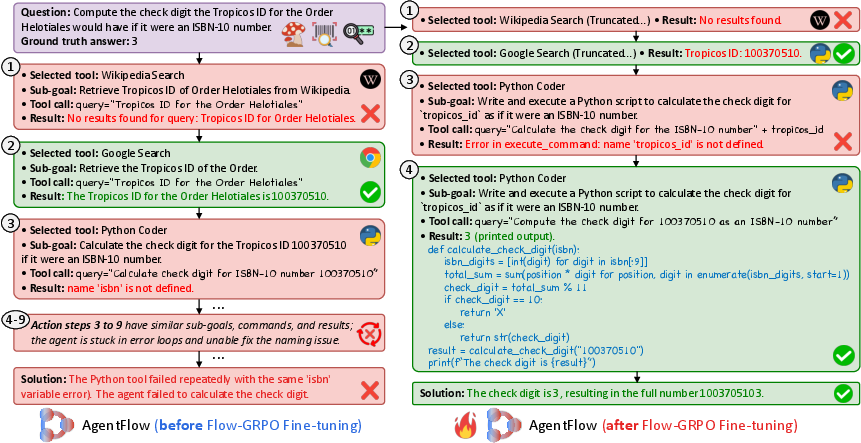
- Training in the flow matters: Simply copying a stronger planner’s past behavior (supervised fine-tuning) actually hurt performance. Training with Flow-GRPO, which learns from live, multi-step attempts and final outcomes, gave large gains.
- Scales well: Using bigger backbone models and allowing more turns both improved results. As the allowed number of steps grew, the system used them thoughtfully to dig deeper and answer better.
Why does this matter?
- More reliable problem-solving: The system plans better, chooses tools more wisely, and checks itself, which makes it more trustworthy for complex tasks—like research, study help, data analysis, and coding.
- Efficiency over size: Instead of just making models bigger, AgentFlow shows that smart training and good teamwork among specialized parts can outperform much larger systems. This could reduce costs and energy use.
- Transparent and controllable: The shared notebook makes the reasoning process easier to inspect and guide, which is useful for safety, auditing, and education.
- General-purpose framework: The approach can adapt to new tools and tasks, making it a flexible foundation for future AI assistants that need to think across many steps.
In short, AgentFlow teaches an AI to work like a well-coordinated team that learns from real practice: plan carefully, use the right tools, check progress, and write clear answers. This in-the-flow training turns final success into lessons for every step, leading to strong, reliable performance on tough, multi-step problems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper that future work could address.
- Reliance on a proprietary LLM-as-judge (GPT-4o) for rewards and evaluation is not audited for bias, robustness, or replicability; the system’s sensitivity to the choice of judge and potential reward hacking is unquantified.
- The final-outcome reward is binary and broadcast to every turn, offering no partial credit or structured intermediate signals; it is unclear how this affects sample efficiency and the ability to learn nuanced multi-step behaviors.
- No ablation or sensitivity analysis of group-normalized advantages (e.g., group size G, std-smoothing when variance is near-zero, clipping/β schedules) is provided, leaving stability guarantees empirical and under-specified.
- The “multi-turn to single-turn” optimization equivalence is claimed but not substantiated in the presented text (proof relegated to the appendix); assumptions and boundary conditions for this equivalence remain unclear.
- Only the planner is trained; co-training (or alternating training) of executor, verifier, and generator is unexplored, leaving open whether joint or staged optimization would yield larger gains or introduce instability.
- The verifier is a frozen LLM producing a binary signal; its accuracy, false positive/negative rates, and impact on premature termination or infinite loops are not evaluated, nor is learned verification or hybrid programmatic verification tested.
- The memory update function is deterministic and hand-designed; its schema, scalability, potential information loss, and robustness to noisy/conflicting tool outputs are not analyzed or learned.
- Training limits the rollout to three turns for efficiency; how this horizon mismatch affects generalization to longer inference horizons (e.g., 7–10 turns) is not analyzed beyond coarse performance trends.
- The effect of averaging advantages across tokens and turns (per-action and per-token normalization) on incentives to produce longer/shorter plans or verbose actions is not examined; dilution of credit across long actions may bias behavior.
- Exploration strategy is fixed (temperature=0.5) without entropy bonuses or adaptive exploration schedules; the trade-offs between exploration and convergence are not studied.
- Asynchronous or parallel tool calls and scheduling are not supported (tools are synchronous with a 500s timeout); the impact of parallelization on performance, latency, and credit assignment is untested.
- Latency, throughput, and cost (tool/API calls, judge calls, rollouts) are not reported; practical deployment trade-offs versus monolithic models are unclear.
- The system’s robustness to tool/API failures, rate limits, timeouts, and drifting web content is not analyzed; no fault-tolerance, retry, or backoff policies are learned or evaluated.
- Generalization to unseen tools and APIs (zero-shot tool onboarding, dynamic capabilities, changing metadata) is not evaluated; how the planner adapts to new tool affordances is an open question.
- Tool-calling “error rate” reductions are reported without a formal taxonomy (syntax vs. semantic vs. API-parameter errors); error attribution and its causal link to task accuracy remain under-specified.
- The toolset is limited (web search, Wikipedia, web page, Python, base LLM); integration with non-LLM programmatic verifiers, databases, planners, or domain-specific systems (e.g., calculators, theorem provers) is untested.
- Safety and security risks (prompt injection during browsing, data exfiltration, harmful tool actions) are not addressed; no adversarial or red-team evaluations are provided.
- Evaluation uses an LLM judge for tasks where exact-match or programmatic checks exist (e.g., math); discrepancies between LLM-judged and exact metrics are not reported, risking metric gaming.
- Potential training–evaluation contamination (web-based tasks, overlapping content) and distribution shift (live web dynamics) are not systematically controlled or audited.
- Statistical significance (CIs, hypothesis tests) is missing; reporting average accuracy across three trials lacks uncertainty quantification and ablations on variance sources.
- Baseline parity is unclear in places (e.g., Base vs. Instruct models, tool access, training budgets for ToRL); fairness and matched compute/data comparisons are not fully documented.
- Claims of outperforming GPT-4o may reflect judge/model coupling or evaluation protocol differences; cross-judge evaluations (e.g., exact-match, multiple judges) are absent.
- The approach is text-only and excludes multimodal inputs; applicability to vision-and-language tasks or tool use involving images, tables, and diagrams is not evaluated.
- Cross-lingual robustness (non-English queries, localized tools) is untested; the planner’s ability to choose language-appropriate tools remains unknown.
- Memory growth is described as “bounded,” but quantitative scaling curves and memory compaction/forgetting strategies are not provided; how memory size affects context quality and latency is unclear.
- Termination policy (binary verifier) might end episodes prematurely or too late; learning a separate stopping policy or cost-sensitive stopping is not explored.
- Outcome-driven tuning appears to shorten responses; the trade-off between brevity and completeness (e.g., missing rationales needed for evaluation or auditability) is not measured or explicitly optimized.
- No study of alternative credit-assignment baselines (e.g., counterfactual baselines, per-turn hindsight relabeling, Shapley or COMA-style credits) is presented to compare with reward broadcasting.
- Scaling results are limited to 3B and 7B backbones for AgentFlow; behavior at 14B/70B+ with in-the-flow RL (compute, stability, gains) is unknown.
- Training data is a mix of Search-R1 and DeepMath; domain coverage breadth, data efficiency, and transfer to unrelated domains (e.g., programming competitions, legal reasoning) are not tested.
- The planner’s memory retrieval policy (what to retrieve from Mt) seems implicit; learning selective retrieval and memory editing policies is not explored.
- Hyperparameter schedules (KL β, PPO clip ε, max token length 2048) are fixed; sensitivity analyses and principled tuning (e.g., trust region size vs. stability) are missing.
- Using a proprietary judge during training may hinder reproducibility; alternatives (open-source judges, multi-judge aggregation, calibration) are not evaluated.
- The verifier and generator are frozen; mismatches between planner intent and downstream modules (execution fidelity, answer formatting) are not mitigated by coordinated objectives or interface contracts.
- No explicit cost-aware or latency-aware objective is used; optimizing for accuracy under compute/network budgets (multi-objective RL) remains open.
- Ethical considerations of web content usage (licensing, attribution, PII handling) and data governance are not discussed.
Practical Applications
Overview
The paper introduces AgentFlow, a trainable agentic framework that coordinates four specialized modules (planner, executor, verifier, generator) via an evolving memory and optimizes the planner in-the-flow using Flow-GRPO—an on-policy reinforcement learning algorithm that converts multi-turn optimization into tractable single-turn updates by broadcasting a single final-outcome reward across turns. The system demonstrates significant gains in search, agentic, mathematical, and scientific reasoning, with improved tool selection and reduced tool-calling errors. Below are practical applications derived from these findings, organized by deployment horizon and linked to relevant sectors, tools, and workflows, along with assumptions and dependencies that affect feasibility.
Immediate Applications
- Enterprise research copilots and knowledge synthesis (Software, Enterprise Productivity, Legal, Consulting)
- What: Deploy an agentic research assistant that plans multi-turn queries, invokes web/Wikipedia search, retrieves internal docs, executes code for analytics, verifies evidence, and generates consolidated answers with citations.
- Tools/Workflow: Planner (Flow-GRPO-tuned) orchestrating Google/Wikipedia search, internal KB queries, Python executor; verifier ensures source sufficiency and correctness; memory provides transparent, auditable trace of decisions.
- Assumptions/Dependencies: Access to reliable search/enterprise APIs; defensible LLM-as-judge or programmatic reward rubric; privacy/PII compliance for internal data; GPU capacity for training or use pre-tuned planner; human-in-the-loop for high-stakes outputs.
- Customer support triage and resolution (Software, Customer Experience)
- What: Multi-turn agent that classifies tickets, queries knowledge bases, calls support APIs (e.g., password resets, refunds), verifies resolution criteria, and drafts responses.
- Tools/Workflow: Planner selects KB search, ticketing system tool, diagnostic scripts; verifier checks resolution status; generator crafts customer-facing messages; evolving memory records steps for audit.
- Assumptions/Dependencies: API connectors to CRM/helpdesk; reward signals (e.g., resolution success, CSAT proxies); guardrails and role-based access; deterministic tool outputs reduce variance in training.
- Data analysis and reproducible automation (Software, Data Science)
- What: Agent that plans analyses, writes and executes Python/R code, validates intermediate results, and produces concise reports.
- Tools/Workflow: Python executor, data connectors (SQL/CSV); verifier checks runtime success and sanity checks; memory captures parameters, code, and outputs for reproducibility; planner tuned with Flow-GRPO for correctness-focused strategies.
- Assumptions/Dependencies: Secure code execution sandboxes; programmatic reward definitions (tests, metric thresholds); governance to prevent unsafe code; dataset access permissions.
- DevOps and incident response runbooks (Software, IT Operations)
- What: Automate multi-step diagnostics and recovery workflows with verified checks (e.g., log searches, service restarts, health probes).
- Tools/Workflow: Planner orchestrates CLI/API calls; verifier ensures health criteria; memory provides step-by-step trace; generator summarizes incident timeline and rationale.
- Assumptions/Dependencies: Secure tooling access (K8s/Cloud APIs); robust reward signals (SLO restoration); strong guardrails to prevent destructive actions; mandatory human approval for impactful steps.
- Scientific and medical literature search assistants (Healthcare, Pharma R&D, Academia)
- What: Assist clinicians and researchers with domain-specific retrieval, summarization, and cross-verification of evidence for queries (non-diagnostic).
- Tools/Workflow: Planner prioritizes specialized sources (PubMed, guidelines) over general search; verifier checks source sufficiency; generator creates patient-friendly or technical summaries with citations.
- Assumptions/Dependencies: Strict non-diagnostic use; institutional access to databases; bias-aware LLM-as-judge or structured reward rules; privacy and regulatory compliance (HIPAA/GDPR).
- Math tutoring and grading support (Education)
- What: Interactive tutor that plans solution paths, invokes computation tools, verifies intermediate steps, and provides step-by-step explanations; grader that verifies correctness and flags reasoning gaps.
- Tools/Workflow: Python/math engines; verifier for numeric/semantic equivalence; memory preserves student progress and errors; generator provides constructive feedback.
- Assumptions/Dependencies: Clear verifiable rewards (correctness, rubric alignment); LMS integration; content filtering and age-appropriate safeguards; avoid full automation for summative assessments.
- Compliance and policy document checks (Legal/Compliance, Public Sector)
- What: Agent that extracts obligations from policies/regulations, cross-checks internal procedures, and flags compliance gaps with verifiable references.
- Tools/Workflow: Planner navigates legal repositories and internal policy tools; verifier ensures coverage and citation sufficiency; generator produces audit-ready reports; memory enables traceability.
- Assumptions/Dependencies: Access to up-to-date legal databases; conservative reward rubrics; human legal review; organizational governance; localization for jurisdictional differences.
- Market and competitive intelligence (Finance, Marketing)
- What: Multi-source aggregation and synthesis of market trends, competitor features, and pricing with cited evidence.
- Tools/Workflow: Web/Wikipedia search, company filings parsers, Python for metrics; verifier enforces source diversity and timeliness; generator produces briefings.
- Assumptions/Dependencies: Source reliability and licensing; potential use of programmatic judges (e.g., citation/completeness heuristics); conflict-of-interest policies; human sanity checks.
- Personal digital research assistant (Daily Life)
- What: Travel planning, product comparisons, budgeting—multi-step planning with verified sources, structured itineraries, and concise summaries.
- Tools/Workflow: Web search, map/booking APIs, spreadsheet calculations via Python executor; verifier for price/date constraints; memory as itinerary/log.
- Assumptions/Dependencies: API availability; transparency about affiliate content; reward proxies (constraint satisfaction); user review before purchase.
Long-Term Applications
- Autonomous enterprise orchestration across tool ecosystems (Software, Operations)
- What: “Digital employees” coordinating cross-department workflows (procurement-to-pay, onboarding) with adaptive planning, verified checkpoints, and auditable memory traces.
- Tools/Workflow: Planner orchestrates microservices/APIs; verifier enforces compliance gates; Flow-GRPO tuned on end-to-end outcomes (cycle time, error rates); memory supports governance and root cause analysis.
- Assumptions/Dependencies: Standardized tool schemas; robust reward engineering for multi-metric objectives; extensive guardrails and approvals; cultural adoption and accountability structures.
- Scientific discovery and lab automation (Biotech, Materials Science)
- What: Agents that design experiments, call simulation/analysis tools, control instruments, verify results, and iteratively refine hypotheses.
- Tools/Workflow: Integrations with ELNs/LIMS, instrument APIs, simulators; verifier combines statistical checks with domain rules; memory captures protocols and results for reproducibility; Flow-GRPO trained on experimental success criteria.
- Assumptions/Dependencies: Hardware integration and safety; rigorous programmatic rewards beyond LLM-as-judge; expert oversight; data provenance and IP management.
- Policy impact modeling and legislative analysis (Public Sector)
- What: Agents that assemble evidence, run impact simulations (econometrics, microsimulation), verify model assumptions, and generate stakeholder-ready briefs.
- Tools/Workflow: Planner orchestrates dataset retrieval and simulation tools; verifier checks model validity and coverage; memory ensures transparent audit trails; RL tuned on policy evaluation outcomes.
- Assumptions/Dependencies: Access to high-quality data; model governance; ethical review and fairness constraints; avoidance of policy automation without democratic oversight.
- Robotics task planning with verified tool/sensor feedback (Robotics, Manufacturing, Logistics)
- What: Transfer AgentFlow’s planning-verifier loop to higher-level robot task planning, where tools map to skills and verifier uses sensor data to gate progression.
- Tools/Workflow: Planner selects skills/sequences; executor runs motion/control primitives; verifier checks sensor-based success; memory tracks task state and failures; RL rewards derived from task completion and safety metrics.
- Assumptions/Dependencies: Reliable perception and control stacks; safety certifications; simulation-to-real transfer; specialized reward shaping and latency constraints.
- Grid management and energy operations (Energy)
- What: Agentic planning over simulation tools for demand forecasting, maintenance scheduling, and contingency analysis with verified safety constraints.
- Tools/Workflow: Integrations with power flow simulators and SCADA; verifier enforces operational limits; memory provides auditable scenarios; RL optimized for reliability and cost objectives.
- Assumptions/Dependencies: Mission-critical safety; regulatory compliance; deterministic programmatic rewards; human-in-the-loop operations.
- Advanced financial research and compliance automation (Finance)
- What: Agents conducting multi-stage due diligence, backtesting strategies, verifying compliance (e.g., AML/KYC), and producing audit-ready narratives.
- Tools/Workflow: Data feeds/APIs, backtesting engines, compliance rule checkers; verifier requires deterministic checks; memory ensures traceability; RL tuned on real outcomes (alpha, risk-adjusted returns, audit findings).
- Assumptions/Dependencies: Strict regulatory oversight; conflict-of-interest and risk management; robust backtesting to avoid overfitting; human supervision.
- Personalized adaptive learning systems (Education)
- What: End-to-end curriculum agents that plan lessons, invoke tools (simulators, calculators), verify learning outcomes, and adapt content based on performance.
- Tools/Workflow: LMS integrations, assessment engines; verifier based on mastery criteria; memory for longitudinal learning profiles; RL tuned on learning gains and retention.
- Assumptions/Dependencies: Privacy (COPPA, FERPA, GDPR); instructional design oversight; fairness and accessibility; robust outcome measurement.
- Sector-specific agent marketplaces and tool schemas (Cross-industry)
- What: Ecosystem of plug-and-play tools with standardized metadata for agentic orchestration, enabling reusable workflows across domains.
- Tools/Workflow: Tool registries, schema standards, memory trace viewers, reward evaluators; Flow-GRPO as a managed training service; policy dashboards.
- Assumptions/Dependencies: Community adoption of schemas; security and sandboxing standards; governance over reward definitions; interoperability across vendors.
- Safety-critical reward engineering and judge replacement
- What: Replace LLM-as-judge with deterministic, multi-signal programmatic judges (tests, constraints, citations) to enable training in sensitive domains.
- Tools/Workflow: Rule engines, formal verification, unit/integration tests; group-normalized advantages with multi-signal rewards; continuous evaluation pipelines.
- Assumptions/Dependencies: Domain-specific formalization; development of robust test suites; potential reduction in flexibility vs. LLM judges; expert-defined constraints.
- Organizational memory and living knowledge bases
- What: Use evolving memory traces to build structured organizational knowledge graphs and process maps that update automatically from agent interactions.
- Tools/Workflow: Memory-to-graph pipelines; verifier curates entries; generator produces views tailored to roles; RL encourages high-quality updates.
- Assumptions/Dependencies: Data quality controls; privacy and retention policies; change management; semantic alignment across departments.
Cross-cutting dependencies and assumptions
- Verifiable rewards: Immediate success hinges on tasks with clear, checkable outcomes (numeric correctness, citation sufficiency, constraint satisfaction). Long-term applications require robust, programmatic judges.
- Tool reliability and access: Stable APIs (search, KBs, simulators), rate limits, latency, and cost impact training and deployment; sandboxed code execution is essential.
- Safety and governance: Human-in-the-loop oversight is mandatory for high-stakes domains; auditability via memory traces supports compliance and accountability.
- Compute and scalability: On-policy training in live environments requires GPU resources and careful optimization (KL regularization, clipping, group-normalized advantages); turn budgets and model scale affect performance and cost.
- Generalization: While AgentFlow improves adaptability, unseen tools/tasks may still require schema alignment, prompt engineering, and iterative fine-tuning; monitoring and continuous evaluation mitigate drift.
Glossary
- Agentic systems: Multi-module AI frameworks where specialized components coordinate via shared memory and communication to solve complex tasks. "Agentic systems offer a promising alternative by decomposing work across specialized modules, yet most remain training-free or rely on offline training decoupled from the live dynamics of multi-turn interaction."
- Credit assignment: The RL problem of determining which decisions across a sequence contributed to the final outcome, especially when rewards are sparse and delayed. "Flow-based Group Refined Policy Optimization (Flow-GRPO), which tackles long-horizon, sparse-reward credit assignment by converting multi-turn optimization into a sequence of tractable single-turn policy updates."
- Distribution shift: A change in the state or data distribution between training and deployment that can degrade model performance. "This decoupling prevents real-time coordination with the executor, verifier, and solution generator, induces distribution shift between training and deployment, and provides limited guidance about which intermediate decisions truly matter."
- Evolving memory: A structured, deterministic record that updates each turn to track the reasoning process, tool results, and verifier signals. "Four modules (\text{planner}, \text{executor}, \text{verifier}, \text{generator}) coordinate via a shared evolving memory and toolset , given a query ."
- Flow-based Group Refined Policy Optimization (Flow-GRPO): An on-policy, outcome-driven RL algorithm that broadcasts a single trajectory-level reward to each turn and stabilizes updates with group-normalized advantages. "We introduce Flow-based Group Refined Policy Optimization (Flow-GRPO, Figure~\ref{fig:flow-grpo}), an on-policy algorithm designed for this setting."
- Group Relative Policy Optimization (GRPO): A policy optimization method that normalizes advantages across sampled responses and uses clipping to encourage high-reward outputs. "Algorithms like Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath} implement this by sampling groups of responses, normalizing advantages by their rewards, and updating the policy with a clipped objective to encourage high-reward outputs."
- Group-normalized advantages: An advantage normalization technique computed across a group of rollouts to reduce variance and stabilize training. "It broadcasts a single, verifiable trajectory-level outcome to every turn to align local planner decisions with global success and stabilizes learning with group-normalized advantages."
- Importance ratio: The likelihood ratio between the current and old policy for a specific token, used in PPO-style updates to correct for policy changes. "is the token-level importance ratio for the -th token of ,"
- In-the-flow learning: Training the planner inside the live multi-turn system so updates are based on the actual states, tool outcomes, and verifier signals encountered during execution. "We optimize the planner in the flow of execution."
- Kullback–Leibler (KL) divergence: A measure of difference between two distributions used to regularize the policy toward a reference model. "and controls KL regularization."
- LLM-as-judge: Using a LLM to evaluate outputs and assign verifiable rewards based on semantic or numeric correctness. "assigned by an LLM-as-judge rubric for semantic, numeric, and option-level equivalence"
- Markov Decision Process (MDP): A formal model for sequential decision-making with states, actions, transitions, and rewards. "We formalize AgentFlow's problem-solving process as a multi-turn Markov Decision Process (MDP)."
- Monolithic policy: A single model/policy that interleaves reasoning and tool calls under full context, rather than decomposing functionality across specialized modules. "prevailing tool-augmented approaches train a single, monolithic policy that interleaves thoughts and tool calls under full context;"
- Off-policy: Training using data or trajectories generated by a different behavior policy than the one being optimized. "these off-policy approaches are decoupled from live dynamics and learn poorly from downstream successes or failures."
- On-policy: Training on trajectories generated by the current policy, aligning learning with the live system dynamics. "To train on-policy in live environments, we propose Flow-based Group Refined Policy Optimization (Flow-GRPO)"
- Outcome-based reward: A reward signal based on the correctness of the final output rather than intermediate steps. "This paradigm fine-tunes a LLM to maximize an outcome-based reward while remaining close to a reference policy."
- Policy collapse: Degeneration of a policy (e.g., becoming overly deterministic or trivial) that can occur during aggressive optimization without proper regularization. "a reference model to prevent policy collapse,"
- Proximal Policy Optimization (PPO) clipping parameter: The ε parameter that bounds the policy update via clipping to stabilize training. " is the PPO clipping parameter,"
- Reference policy: A fixed or slowly changing policy used for KL regularization to prevent the current policy from drifting too far. "to a fixed reference policy ."
- Sparse rewards: Rewards provided infrequently (often only at the end of a trajectory), making credit assignment across many steps difficult. "We target tool-integrated agentic systems operating under long-horizon tasks with sparse rewards."
- Supervised fine-tuning (SFT): Training a model to imitate labeled trajectories or behaviors using supervised learning objectives. "Offline SFT leads to performance collapse, while in-the-flow RL is crucial."
- Tool-integrated reasoning (TIR): Extending LLM reasoning with external tool calls for retrieval or computation, trained with verifiable rewards. "Tool-integrated reasoning (TIR) extends reinforcement learning with verifiable rewards to learn when and how to call tools by interleaving reasoning (e.g., > ) with tool invocations (e.g., <tool\_call>) under full context"
Trajectory: The sequence of states, actions, and tool observations produced during multi-turn interaction. "The resulting trajectory is a sequence of model generations and tool observations: "
- Verifier signal: A binary signal indicating whether an execution result is valid or the system has enough information to terminate. "producing a binary verification signal ."
Collections
Sign up for free to add this paper to one or more collections.

