Learning, Fast and Slow: Towards LLMs That Adapt Continually
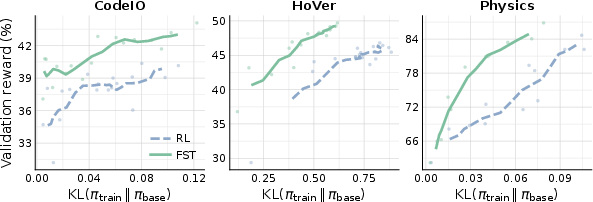
Abstract: LLMs are trained for downstream tasks by updating their parameters (e.g., via RL). However, updating parameters forces them to absorb task-specific information, which can result in catastrophic forgetting and loss of plasticity. In contrast, in-context learning with fixed LLM parameters can cheaply and rapidly adapt to task-specific requirements (e.g., prompt optimization), but cannot by itself typically match the performance gains available through updating LLM parameters. There is no good reason for restricting learning to being in-context or in-weights. Moreover, humans also likely learn at different time scales (e.g., System 1 vs 2). To this end, we introduce a fast-slow learning framework for LLMs, with model parameters as "slow" weights and optimized context as "fast" weights. These fast "weights" can learn from textual feedback to absorb the task-specific information, while allowing slow weights to stay closer to the base model and persist general reasoning behaviors. Fast-Slow Training (FST) is up to 3x more sample-efficient than only slow learning (RL) across reasoning tasks, while consistently reaching a higher performance asymptote. Moreover, FST-trained models remain closer to the base LLM (up to 70% less KL divergence), resulting in less catastrophic forgetting than RL-training. This reduced drift also preserves plasticity: after training on one task, FST trained models adapt more effectively to a subsequent task than parameter-only trained models. In continual learning scenarios, where task domains change on the fly, FST continues to acquire each new task while parameter-only RL stalls.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to train LLMs so they can get better at tasks without forgetting what they already know. The idea is to let the model learn in two speeds at once:
- Slow learning: carefully changing the model’s internal settings (its “weights”).
- Fast learning: quickly improving the text you give the model to guide it (its “prompt” or “context”).
The authors call this approach Fast-Slow Training (FST). It helps the model improve faster, reach higher scores, and stay flexible for future tasks.
What questions did the researchers ask?
They wanted to know:
- Can an LLM learn faster if it improves both its internal settings and its prompts at the same time?
- Will this make the model forget less of its general abilities?
- Will the model stay more flexible, so it can keep learning new tasks one after another (continual learning)?
- Can this method reach higher performance than normal training that only changes the model’s weights?
How did they do it? (In simple terms)
Think of training an LLM like studying for school:
- Slow learning is like rewriting parts of your textbook. It’s powerful but risky: if you change too much for one subject, you might mess up what you already knew for others.
- Fast learning is like using sticky notes and checklists you can add or remove anytime. It’s quick, cheap, and task-specific.
Here’s their approach:
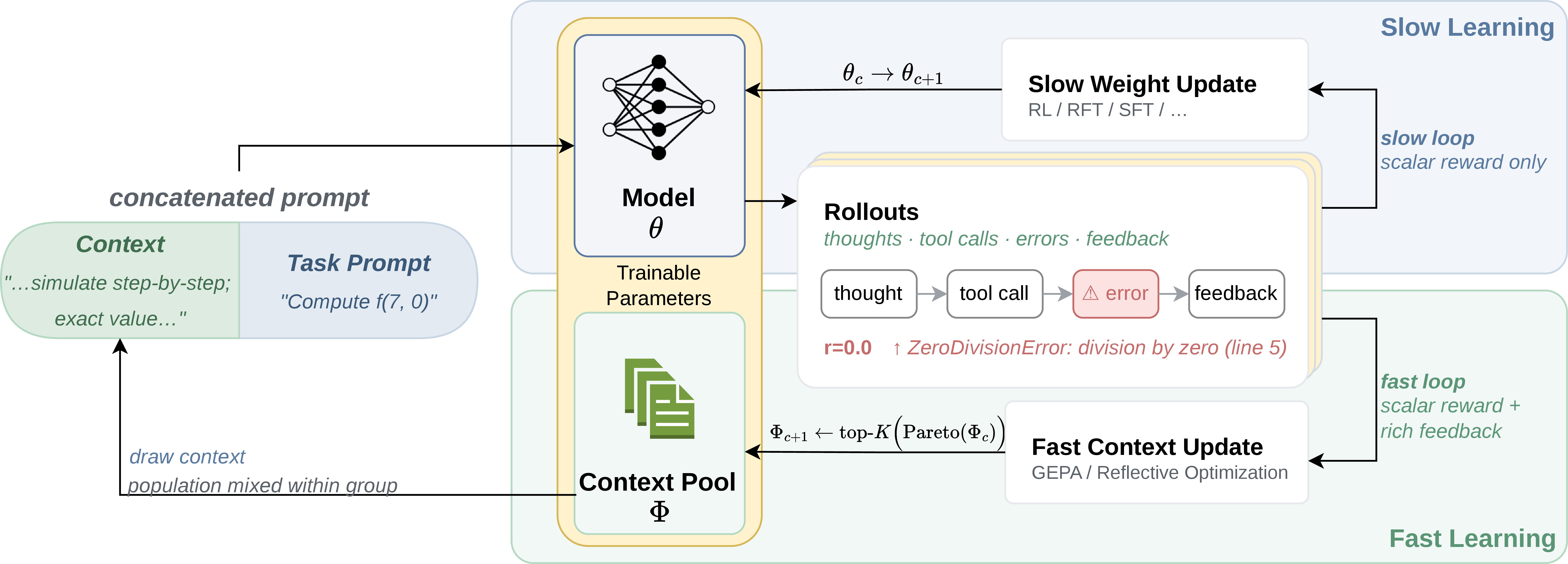
- Slow part (weights): They use reinforcement learning with automatic checks. For example, if the model solves a math problem or writes correct code, it gets a point; if not, it doesn’t. The model slowly updates its internal settings to do better next time.
- Fast part (prompts): They keep a small “team” of different prompts (instructions, examples, scaffolds) that are edited and improved over time. Another helper model reads the model’s attempts, errors, tool calls, and feedback, then suggests small prompt edits. The system keeps a diverse set of the best prompts, because different prompts help with different kinds of problems.
They interleave these two:
- First, they improve the prompt pool (fast).
- Then, they train the model weights using those improved prompts (slow).
- Repeat.
Why keep many prompts instead of just one?
- Because one prompt rarely fits all kinds of problems. A small, diverse set means the model sees many “styles” of guidance, which helps it learn broader skills.
What tasks did they test?
- Coding (predicting program outputs).
- Math problem solving.
- Multi-hop fact checking (deciding if a claim is true using multiple pieces of information).
- Physics multiple-choice questions.
What did they find, and why does it matter?
Here are the main results, explained simply:
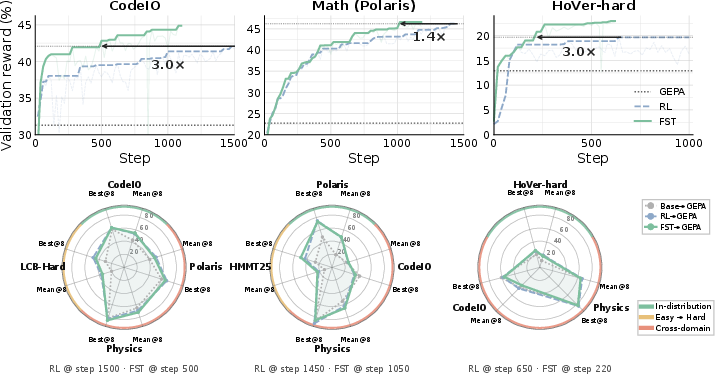
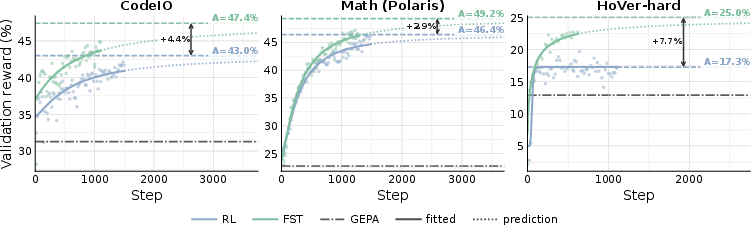
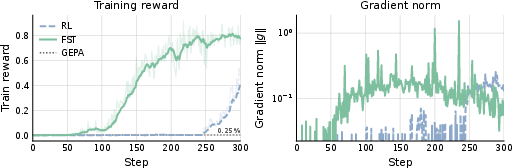
- Learns faster: With the fast+slow method, the model reached the same performance as normal training using up to 3 times fewer tries on some tasks. In a tough puzzle-like task, the fast prompts started helping within about 50 steps, while weight-only training took around 300 steps to budge. Fast learning injects useful hints quickly.
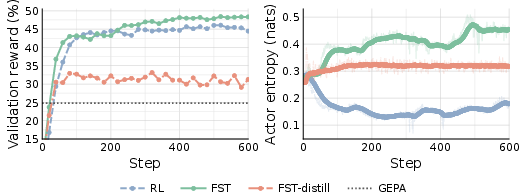
- Reaches higher top scores: Over time, the fast+slow method didn’t just get there faster—it ended up doing better overall than weight-only training on coding, math, and fact-checking.
- Forgets less: The model stayed closer to its original “base” self (it didn’t drift as far). Think of this as not overwriting the textbook too much, because sticky notes (prompts) carry part of the load. This helps preserve general skills.
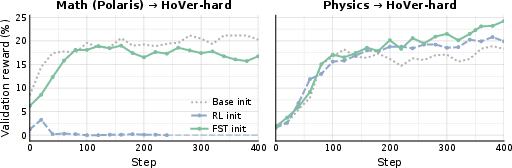
- Stays flexible (keeps plasticity): After training on one task, models trained with fast+slow could still learn a new task well. Models trained only by changing weights sometimes nearly stopped learning the new task. In short, fast+slow keeps the “learning muscles” healthy.
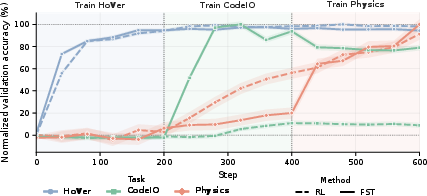
- Handles changing tasks better (continual learning): In a single run that switched tasks every 200 steps (fact-checking → coding → physics), fast+slow kept picking up each new task strongly. Weight-only training got stuck halfway, especially on the second task.
- Why does this work? The fast channel learns from rich text feedback (like “here’s where your reasoning went wrong”), so it can quickly adjust the prompt and provide better guidance. Meanwhile, the slow channel consolidates longer-lasting skills without being forced to absorb every tiny task detail.
What does this mean for the future?
- Training LLMs shouldn’t be “only change the weights” or “only tune the prompt”—doing both together works better. Let the prompt carry quick, task-specific tricks, while the weights focus on stable, general abilities.
- This makes training more sample-efficient (you need fewer tries), reduces harmful forgetting, and keeps the model ready to learn future tasks.
- It’s especially promising for real-world use, where new tasks arrive over time and you don’t want the model to break older skills.
In short, Fast-Slow Training treats prompts like smart, updatable sticky notes and the model weights like the textbook. By improving both at the right pace, the model learns faster, climbs higher, and stays ready for what’s next.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow-on research:
- Scaling behavior: Validate FST across model sizes beyond Qwen3-8B (e.g., 1–3B, 13–70B+) to assess whether sample-efficiency, asymptote gains, and KL reductions persist or change with scale.
- Compute efficiency: Report wall-clock time, FLOPs/tokens, and energy for FST vs RL-only, including the cost of the reflection LM and GEPA cycles; quantify whether sample-efficiency translates to compute-efficiency.
- Hyperparameter sensitivity: Systematically ablate cycle length T, prompt population size K, rollout group size G, anchor set size, and Pareto pruning thresholds to establish robust default settings and sensitivity curves.
- Optimizer generality: Replace CISPO/GRPO with PPO, DPO, SFT, and alternative prompt optimizers (e.g., OPRO, DSPy/MIPROv2, evolutionary variants) to test how method-level choices impact FST’s benefits.
- Reflection LM dependence: Measure robustness to the proposer’s architecture/size/temperature; identify minimal-capacity reflection LMs that still yield gains and characterize failure modes when reflections are noisy or biased.
- Non-stationarity and stability: Analyze convergence and stability of alternating fast/slow updates (e.g., different interleaving schedules, asynchronous updates); provide diagnostics or theory for when co-optimization destabilizes learning.
- KL attribution: Disentangle prompt vs weight effects by measuring KL to the base with identical prompts across checkpoints or by evaluating KL under a neutral prompt to isolate slow-weight displacement.
- Inference-time protocol: Specify and evaluate how prompts are chosen at deployment (uniform, heuristic, learned router, retrieval); quantify latency, cost, and accuracy trade-offs for single-prompt vs ensemble use.
- Preference/noisy-reward settings: Test FST under RLHF and implicit/learned reward models where rewards are non-verifiable or noisy; assess robustness to reward misspecification and reward hacking.
- Information-theoretic gains: Quantify how much additional signal textual feedback contributes beyond binary rewards (e.g., mutual information estimates, ablations removing feedback), and when it overcomes the “1-bit per episode” limitation.
- Task/domain coverage: Extend evaluation beyond math/code/fact verification to instruction following, open-ended dialogue, safety-critical tasks, multi-modal reasoning, and long-horizon tool use.
- Continual learning at scale: Run longer task sequences with revisits (e.g., 5–10 tasks, multi-epoch interleaving); measure forward/backward transfer, forgetting, and stability over extended horizons.
- Statistical rigor: Report multi-seed variance, confidence intervals, and statistical tests for all headline metrics and asymptote fits; assess reproducibility across datasets and seeds.
- Prompt routing during training: Replace uniform U(Φ) with learned gating or mixture-of-prompts to adapt prompts per instance; evaluate whether routers improve sample-efficiency and asymptotes without increasing KL.
- Prompt pool management: Study growth, pruning, merging, compression, and memory footprint of fast-weight pools over long training; devise criteria to prevent pool bloat while preserving diversity.
- Security and safety: Evaluate susceptibility to adversarial or malicious prompt mutations, toxicity amplification, or undesirable shortcuts induced by optimizing verifiable rewards; develop constraints or vetting for evolved prompts.
- Negative cases: Identify tasks where FST underperforms RL or GEPA alone; characterize conditions (e.g., weak feedback, homogeneous domains) that negate fast-slow benefits.
- Gradient variance and sampling design: Analyze how K and G impact variance of group-relative advantages when mixing prompt-induced and sampling-induced variation; design variance-reduction techniques with controlled compute.
- Trajectory reuse: Develop mechanisms to reuse trajectories across GEPA and RL (e.g., off-policy corrections, reweighting) to reduce duplicate sampling and improve compute-efficiency.
- Robustness to fast-weight mismatch: Stress-test performance when fast prompts are missing, stale, or mismatched at deployment; design graceful degradation or automatic fallback strategies.
- Theory of alternating optimization: Provide guarantees or analyses (e.g., convergence to stationary points of the joint objective, conditions yielding lower-KL solutions) for the co-optimization of θ and Φ.
- Data leakage and contamination: Audit reflection LMs and prompt evolution for potential contamination of validation/test sets; enforce protocols to prevent leakage during GEPA’s anchor/rollout selection.
- Fast-to-slow distillation: Systematically benchmark distillation schedules, objectives (e.g., SDPO vs reverse-KL), and curriculum for transferring fast-weight knowledge into θ; determine when and how much to distill without harming plasticity.
- Integration with programmatic pipelines: Explore FST with structured LM programs (DSPy, tool-augmented chains) rather than free-text prompts; study how fast-weight evolution interacts with program synthesis and tool use.
- Entropy–plasticity link: Causally test whether preserved entropy drives higher plasticity (e.g., controlled entropy-regularization baselines) rather than merely correlating with it.
- Deployment and governance: Design online GEPA variants for streaming updates, define latency/throughput budgets, and establish governance for safe, auditable prompt evolution in production settings.
Practical Applications
Overview
This paper proposes Fast-Slow Training (FST): a joint optimization paradigm where slow weights (LLM parameters) are updated with RL under verifiable rewards (RLVR), while fast weights are an evolving population of textual contexts/prompts optimized via reflective evolution (GEPA). Empirically, FST delivers 1.4–3× higher data efficiency, higher asymptotic performance, up to 70% lower KL drift from the base model (reduced catastrophic forgetting), stronger plasticity for subsequent tasks, and superior continual-learning behavior. These properties enable concrete applications that either improve current post-training pipelines or unlock new capabilities in settings that require ongoing, low-risk adaptation.
Below are actionable applications, grouped by time-to-deploy and mapped to sectors, with likely tools/workflows and feasibility notes.
Immediate Applications
The following applications can be deployed now by augmenting existing RLHF/RLVR pipelines, enterprise LLM ops, and agentic systems with a fast-text context channel and KL-aware training/monitoring.
- Software engineering (code generation, code review, CI/CD)
- FST post-training for code models using unit/integration tests as verifiable rewards; GEPA maintains a Pareto set of prompts specialized to bug-fixing, refactoring, and style compliance; lower KL drift reduces regressions when rolling out new skills.
- Tools/workflows: “FST Trainer” plugin for existing RL frameworks (e.g., TRLX/ScaleRL-like recipes), prompt-population manager, test-suite-driven reward harness.
- Assumptions/dependencies: robust test coverage; reflection LM for prompt evolution; sandboxed execution.
- Production prompt-rotation/selection across the GEPA frontier to target different codebases or languages without retuning weights.
- Tools/workflows: prompt router that picks or ensembles among top-K prompts by repository or ticket type.
- Assumptions/dependencies: telemetry to map tasks to prompt niches; caching for latency.
- Education (math and science tutors, automated graders)
- Fast adaptation to student misconceptions via textual feedback; the tutor evolves a prompt pool (hints, Socratic scaffolds) while keeping weights stable for safety/consistency.
- Tools/workflows: GEPA on per-class anchor sets; verifiable rewards from autograders; KL-to-base dashboards to constrain drift.
- Assumptions/dependencies: reliable correctness checkers for exercises; content moderation of evolved prompts.
- Customer support and CX ops
- Multi-product assistants with per-product prompt niches that evolve from ticket outcomes and QA rubrics, while parameters stay close to a base-aligned model.
- Tools/workflows: outcome-based rewards (CSAT, resolution verification); Pareto prompt population per product/locale; rollback by prompt deactivation.
- Assumptions/dependencies: proxy verifiable rewards (e.g., form-field validation, policy-match checks); careful handling of noisy human feedback.
- Finance (compliance assistants, report drafting)
- Rapid incorporation of policy/handbook updates as fast prompts; lower parameter drift helps sustain compliance and auditability.
- Tools/workflows: change-management pipeline that converts policy deltas into candidate prompt mutations; pre-deployment KL and plasticity checks.
- Assumptions/dependencies: policy-to-prompt curation; strict logging for audit; guardrails around reflection LM outputs.
- Healthcare (clinical QA, admin workflows)
- Hospital- or department-specific SOPs encoded as fast prompts; base weights remain closer to safety-aligned checkpoint.
- Tools/workflows: local GEPA cycles on curated anchor sets; verifiable rewards where feasible (e.g., structured form completion), human-in-the-loop gates for clinical claims.
- Assumptions/dependencies: regulated deployment constraints; limited scope to administrative tasks unless high-quality verifiers exist.
- Enterprise knowledge and RAG systems
- Continual knowledge updates handled by evolving fast prompts (retrieval instructions, chain-of-thought patterns) instead of frequent finetunes; reduces downtime and cost.
- Tools/workflows: prompt population specialized per corpus segment; entropy/KL monitoring; automatic fallback to base prompt when drift risk is detected.
- Assumptions/dependencies: reliable retrieval verifiers (e.g., answer-supported-by-citations checks).
- Safety and governance
- KL-to-base caps as a production guardrail: adopt FST to reach target gains within bounded drift; use plasticity probes as release criteria.
- Tools/workflows: training-time KL dashboards, entropy monitors, plasticity probe harness (fine-tune-on-new-task smoke test).
- Assumptions/dependencies: base policy as reference-of-record; operational thresholds for drift and entropy.
- MLOps for continual training
- Turn static “train-then-prompt-tune” pipelines into interleaved FST cycles; compute-efficient learning from textual feedback beyond binary rewards.
- Tools/workflows: scheduler that pre-fetches lookahead batches, alternates GEPA and RL updates; artifact store for prompt populations; A/B harness for prompt frontier variants.
- Assumptions/dependencies: orchestration that supports alternating loops; prompt safety linting.
- Academia and benchmarking
- Lower-cost RLVR experiments (1.4–3× fewer rollouts) and new evaluation axes (KL-to-base, plasticity, continual-learning stages) as standard reporting.
- Tools/workflows: public leaderboards that include displacement/plasticity metrics; open-source FST baselines on code/math/fact-checking tasks.
- Assumptions/dependencies: availability of verifiers and reflection LMs; consistent logging.
- Daily life/personal productivity
- Personal assistants that learn routines via evolving “fast notes” (prompt fragments) while preserving a stable writing/decision style from the base model.
- Tools/workflows: per-user prompt population with easy rollback; on-device cache where possible.
- Assumptions/dependencies: opt-in data; privacy-preserving prompt evolution.
Long-Term Applications
These require further research, scaling, or productization (e.g., multi-modal extension, robust verifiers, stronger safety tooling, or standardization of plasticity/entropy governance).
- Lifelong learning agents in dynamic domains
- Autonomous agents that continuously absorb new sub-tasks via fast prompts while consolidating stable skills in slow weights; suitable for operations centers, complex workflows, and evolving playbooks.
- Potential products: “LLM Autopilot” with streaming FST; task-shift detectors that trigger GEPA cycles; per-task prompt niches.
- Dependencies: reliable task-change detection; scalable reflection; long-horizon verifiers; drift-aware safety interlocks.
- Federated and multi-tenant adaptation
- Cross-organization fast-weight aggregation (prompt deltas) instead of weight sharing; lowers privacy and IP risks versus parameter exchange.
- Potential products: federated prompt hub with differential privacy; tenant-isolated prompt populations; centralized base model with local fast layers.
- Dependencies: privacy-preserving reflection; standard formats for prompt diffs; governance on prompt provenance.
- Safety-critical copilots (healthcare, aviation, energy)
- “Drift-bounded” assistants where new SOPs/regulations integrate first as prompts; only carefully verified behaviors migrate to weights.
- Potential products: staged promotion pipeline (fast → shadow → slow); fail-safe reversion by dropping prompts; audit trails of evolution steps.
- Dependencies: high-fidelity verifiers; regulatory acceptance of fast-weight changes; formal prompt linting and red-teaming.
- Regulatory policy and standards
- Plasticity and KL-displacement as reportable KPIs in model cards and procurement; guidelines favoring low-drift training for safety-critical use.
- Potential outcomes: compliance checklists for continual-learning readiness; sector standards on drift caps and plasticity probes.
- Dependencies: consensus metrics; third-party audits; reproducible probes.
- Personalized education at scale
- Per-learner fast-weight profiles that evolve curricula, hints, and assessment strategies without touching shared parameters; easier unlearning/portability.
- Potential products: student prompt profiles; cross-course transfer of prompt niches; teacher dashboards for prompt lineage.
- Dependencies: richer verifiers for open-ended tasks; privacy and fairness audits; content safety in reflective mutations.
- Scientific discovery assistants
- Lab agents that evolve protocols/hypotheses as fast prompts from experimental logs, with occasional slow-weight consolidation of general techniques.
- Potential products: hypothesis-evolution workbench; lab-specific prompt niches; provenance-linked experiment trees.
- Dependencies: structured lab verifiers; rigorous uncertainty handling; data governance.
- Robotics and multi-modal reasoning
- High-level planners adapted via fast textual policies (task descriptions, tool schemas) while perception/control policies remain stable.
- Potential products: instruction-evolution layer on top of multi-modal LLMs; GEPA extended to action-language hybrids.
- Dependencies: multi-modal verifiable rewards; safety assurance; sim-to-real transfer tooling.
- Marketplaces for prompt populations
- Curated, domain-specific fast-weight libraries (e.g., tax law, cybersecurity response, SAP customizations) with provenance and performance labels.
- Potential products: prompt-frontier registries; compatibility tests vs base models; license and security scanning.
- Dependencies: standard interfaces for prompt populations; IP and safety vetting.
- Unlearning and incident response
- Rapid rollback/removal of harmful adaptations by disabling prompt niches; later, selective slow-weight unlearning if needed.
- Potential products: “fast unlearn” buttons; prompt quarantine; diff-based RCA (root-cause analysis) of behavioral drift.
- Dependencies: robust tracing from behavior → prompt niche; isolation tests; change management.
- Cost-optimized training and adaptation budgets
- Formal schedulers that allocate adaptation to fast vs slow channels based on marginal reward per token, KL cost, and safety constraints.
- Potential products: adaptation-budget optimizers; SLAs defined in terms of reward/compute/drift.
- Dependencies: reliable cost/reward instrumentation; policy knobs for risk and performance.
- Evaluation and governance ecosystems
- Community benchmarks for continual learning, plasticity, and asymptote; standardized “task-stream” evaluations with interleaved GEPA/RL phases.
- Potential products: open suites for CodeIO/Math/HoVer-style task streams; dashboards integrating reward, KL, entropy, and plasticity curves.
- Dependencies: shared verifiers; reproducible seeds and reflection models; dataset licenses.
- Consumer assistants with per-identity fast layers
- Long-lived, privacy-preserving personalizations where preferences/skills live in fast prompts, portable across base model upgrades.
- Potential products: profile-exportable fast-weight bundles; on-device evolution for low bandwidth.
- Dependencies: local reflection options; encrypted prompt stores; UX for consent and control.
Cross-cutting assumptions and dependencies
- Verifiable rewards or high-quality proxies are essential for the RLVR slow loop; textual feedback quality governs fast-loop gains.
- A competent, controllable reflection model is needed for safe/effective GEPA; prompt mutation must be safety-linted and auditable.
- Operational support for interleaved training (scheduling, caching, logging), plus KL/entropy/plasticity monitoring and release gates.
- Data governance and privacy: evolved prompts may encode sensitive patterns; per-tenant isolation and provenance tracking are necessary.
- Inference-time constraints: attaching and routing among multiple prompts adds latency; caching and prompt compaction may be required.
- Domain coverage: prompt frontier diversity depends on anchor-set representativeness; bias in anchors can limit specialization or cause regressions.
In sum, FST’s central innovations—co-evolving prompt populations with RL under verifiable rewards, bounded drift, and preserved plasticity—translate into immediately deployable gains in cost, safety, and adaptability for current LLM systems, while laying a practical path toward lifelong learning agents and drift-governed AI in safety-critical domains.
Glossary
- Anchor set: A fixed subset of problems used to evaluate and evolve prompts during prompt optimization. "as the anchor set"
- Automatic verifier: A programmatic checker that assigns reward by verifying correctness of model outputs. "The reward r(x, y) ∈ [0, 1] is given by an automatic verifier on (x, y)"
- Base policy: The original (pre-trained) model policy used as a reference for measuring drift. "lower KL to the base policy"
- Catastrophic forgetting: When adapting to new tasks degrades performance on previously learned abilities. "can result in catastrophic forgetting and loss of plasticity"
- CISPO: A truncated importance-sampling REINFORCE objective used for RL updates in LLMs. "the truncated importance-sampling REINFORCE objective cispo"
- Continual learning: Training that must keep acquiring new tasks over time without losing the ability to learn further tasks. "In continual learning scenarios, where task domains change on the fly"
- DPO: Direct Preference Optimization, a preference-based method for training LLMs without an explicit reward model. "such as PPO, DPO, GRPO, and CISPO"
- Entropy (output entropy): A measure of the uncertainty/diversity of the model’s output distribution; lower entropy often indicates over-specialization. "reducing entropy"
- Entropy collapse: Excessive reduction of output entropy during training, leading to less diverse outputs. "higher entropy than the entropy-collapsed RL-baseline"
- Fast weights: Quickly changeable components (here, textual context/prompts) that carry task-specific adaptations without altering model parameters. "fast weights (textual scaffolds)"
- Fast-Slow Training (FST): A training paradigm that jointly optimizes slow parametric weights and fast textual weights. "Fast-Slow Training (\methodname{}) is up to more sample-efficient"
- Fitness (prompt fitness): The expected reward of a prompt on a given instance, used to guide prompt evolution. "the fitness of a prompt on instance x is its expected reward"
- Frozen reflection LM: A fixed LLM used to generate critiques and propose prompt mutations during reflective optimization. "a frozen reflection LM"
- GEPA: Reflective Prompt Evolution, an evolutionary method that uses reflections to mutate and select prompts. "We optimize the fast weights φ using GEPA, a reflective evolutionary procedure"
- GRPO: A policy-gradient variant used for RL fine-tuning of LLMs under verifiable rewards. "such as PPO and GRPO"
- Group-relative advantages: Advantage estimates computed by comparing rewards within a group of rollouts for the same instance. "from which group-relative advantages are computed"
- Importance ratio: The per-token ratio between current and behavior policies used in importance-sampled policy gradients. "is the per-token importance ratio between the current and behavior policies"
- In-context learning: Adapting behavior via prompts and context without updating model parameters. "in-context learning with fixed LLM parameters can cheaply and rapidly adapt"
- KL divergence: A measure of how much the trained policy diverges from the base policy; used to track displacement. "up to 70% less KL divergence"
- KL-minimal solutions: Solutions preferred by on-policy RL that minimize divergence from the base distribution for a given reward. "on-policy RL is already biased toward KL-minimal solutions"
- Lookahead batch: A pre-fetched union of upcoming RL batches used as the anchor set for prompt evolution within a cycle. "denote their union by the lookahead batch 𝓛_c"
- On-policy distillation (reverse-KL): Distilling behavior from a teacher (prompt-conditioned) policy into a student by minimizing reverse KL on student-generated rollouts. "the reverse-KL on-policy distillation loss"
- On-policy reinforcement learning: RL where data is collected from the current policy, often leading to specific biases like KL-minimal solutions. "on-policy RL is already biased toward KL-minimal solutions"
- Out-of-distribution generalization: The model’s ability to perform on tasks or domains different from those seen in training. "hurting out-of-distribution generalization"
- Pareto frontier: A set of prompts that are non-dominated across multiple criteria, preserving complementary specializations. "GEPA retains a Pareto frontier of complementary prompts"
- Plasticity loss: Degradation of a model’s capacity to learn new tasks after extensive post-training. "known as plasticity loss"
- Policy-gradient methods: RL algorithms that optimize policies via gradient ascent on expected reward. "policy-gradient methods such as PPO and GRPO"
- PPO: Proximal Policy Optimization, a stable policy-gradient algorithm widely used in RL fine-tuning. "such as PPO, DPO, GRPO, and CISPO"
- Prompt optimization: Automated search or learning methods that improve prompts to steer model behavior without changing weights. "automated prompt-optimization methods"
- Prompt population: A maintained set of diverse candidate prompts used during training to expose the policy to varied conditioning. "maintains a population of textual prompts"
- Reflective prompt evolution: Using model-generated reflections/criticisms to propose and evolve better prompts. "a reflective evolutionary procedure"
- Reinforcement learning with verifiable rewards (RLVR): RL setup where rewards are computed by an automatic verifier of outputs. "We instantiate this idea in RLVR"
- Reverse KL: The KL divergence KL(student || teacher) used in distillation that encourages mode-seeking alignment. "reverse-KL on-policy distillation loss"
- Rollouts: Trajectories or sampled outputs generated by the policy for training and evaluation. "uses rollouts to elicit natural-language critiques"
- SFT (Supervised finetuning): Adapting a model on labeled input-output pairs before or alongside RL. "adapted through supervised finetuning (SFT) or reinforcement learning (RL)"
- Stop-gradient operator: An operation that prevents gradients from flowing through a term during backpropagation. "sg(·) is the stop-gradient operator"
- Token-level KL: KL divergence computed at each generation step/token to assess distributional shift. "we compute token-level KL from the base"
- Truncation threshold: A cap applied to importance ratios to reduce variance in importance-sampled policy gradients. "τ is a truncation threshold"
- Verifiable rewards: Rewards derived from automatic checking of correctness rather than human preferences. "frequently under verifiable rewards"
Collections
Sign up for free to add this paper to one or more collections.