- The paper proposes data-efficient protocols for aligning large language models using natural language expert feedback to tackle fuzzy, high-stakes tasks.
- It details an iterated RLHF strategy that leverages both in-context learning and supervised fine-tuning to update proxy reward models effectively.
- Empirical findings reveal that fine-tuning methods yield robust alignment and high data efficiency while mitigating the risks of over-optimization.
Efficient Alignment of LLMs with Online Natural Language Feedback
Problem Motivation and Setting
This work addresses the challenge of aligning LLMs on complex, "fuzzy" tasks—domains where clear, objective, and automated verifiers are unavailable, such as creative writing or empirical research planning. While reinforcement learning with verifiable rewards (RLVR) has produced substantial gains on mathematically or logically scorable problems, many high-stakes applications (e.g., alignment research, policy drafting) are intractable for automated grading and require expensive human expert oversight. The paper develops data-efficient protocols leveraging natural language expert feedback delivered online and investigates how such feedback can be distilled into proxy reward models that can then be used for RL-based policy optimization.
The experimental context is a "sandwiching" setup: a weaker model (Qwen3-8B or Claude Haiku 4.5) is trained as the policy, an equally weak model serves as the proxy reward model, and a much stronger LLM (Claude Opus 4.1/4.5) provides scalar and textual feedback, simulating human expert supervision.
Online Feedback Protocols and Methods
The core innovation is an iterated online RLHF protocol leveraging detailed natural language feedback from the expert to periodically update the reward model:
- RL against the proxy reward is performed until signs of over-optimization (i.e., expert reward stalling or collapsing).
- Fresh expert supervision (long-form feedback + scalar rewards) is collected on a batch of new policy outputs.
- The proxy reward model is updated, either through in-context learning (ICL) with prompt/rubric/shot modifications, or through supervised fine-tuning (SFT) using the newly gathered expert data.
Performance is measured via performance gap recovered (PGR): the fraction of the gap between maximum elicitable expert reward and baseline closed by each protocol, and data efficiency as expert feedback queries per point of performance.
In-Context Learning for Proxy Reward Construction
The ICL protocols involve prompt engineering the reward model with:
- Rubrics: Structured grading criteria distilled from expert traces.
- Few-shot exemplars: Embedding graded examples into the proxy's prompt.
- Per-task prompts: Custom-generated evaluation instructions per task.
The protocol selects proxy prompts with maximal expert-proxy advantage correlation over a held-out validation set and ensembles the top-k prompts.
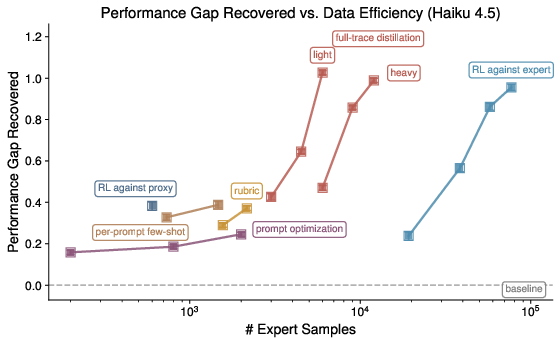
Figure 1: Data efficiency and PGR on Haiku 4.5 for alignment research task; high efficiency but only modest gap recovery for ICL.
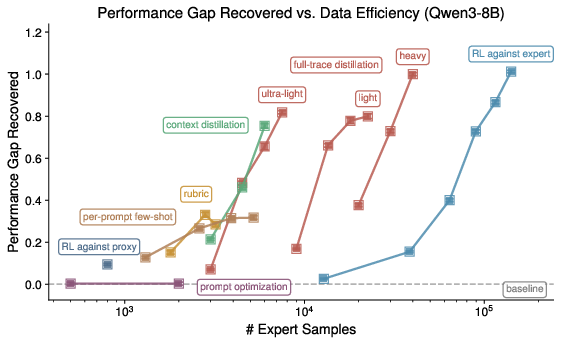
Figure 2: Data efficiency and PGR for Qwen3-8B creative writing; 35% gap recovery with 50x sample efficiency via ICL, but performance plateaus after first prompt realignment.
The effect of increasing prompt sophistication (rubric vs. few-shot) and distribution of samples selected for feedback is systematically explored, but most ICL-based updates result in diminishing returns after the first iteration; further prompt tuning/rubrics do not incrementally boost expert reward.
Supervised Fine-Tuning and Distillation
SFT approaches involve multiple iterations of fine-tuning the proxy reward model on batches of expert-scored examples (with or without full traces) while periodically resuming RL for the policy against the updated reward model.
Distinctive SFT strategies include:
- Full-trace distillation: The proxy model is trained to replicate the entire expert feedback process, not just scalar scores.
- Scalar-only regression: The proxy is trained solely to match expert numeric scores, discarding free-text justification.
- Context distillation: The proxy is conditioned on richer expert context, including partial traces and explanations.
SFT-based protocols robustly achieve high alignment and avoid catastrophic over-optimization, especially when training is initialized with a sufficiently large, diverse set of expert-labeled samples.
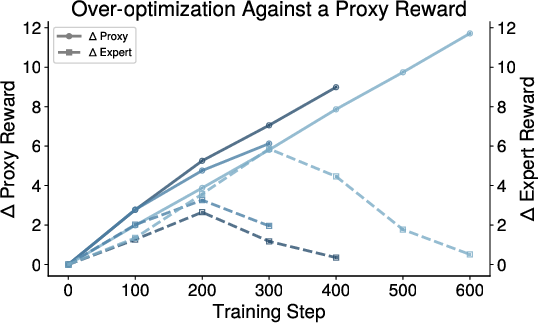
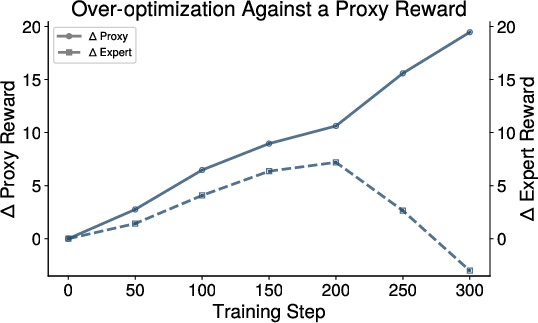
Figure 3: Sample SFT run demonstrating robust expert-proxy reward alignment across RL and SFT iterations.
Empirical Results
Data Efficiency and Alignment
Empirical results establish strong claims about data efficiency and alignment:
- ICL-based protocols can close up to 35% of the performance gap with up to 50x fewer expert samples on Qwen3-8B and 30x fewer on Haiku 4.5, but plateau early.
- SFT-based methods achieve 80–100% of the performance gap, with 3–20x fewer expert feedback queries compared to fully supervised expert RL. Full-trace distillation and context-rich feedback are crucial; scalar-only reward modeling is brittle and susceptible to fast over-optimization.
- Reward alignment (expert-proxy advantage correlation) is predictive: prompts/proxy models with higher alignment lead to more robust RL progress and reduced likelihood of over-optimization.
- Data selection strategies (variance or disagreement-based sampling) did not yield better proxy alignment than random feedback selection.
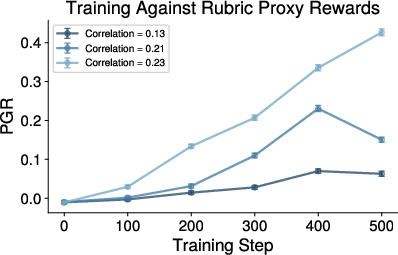
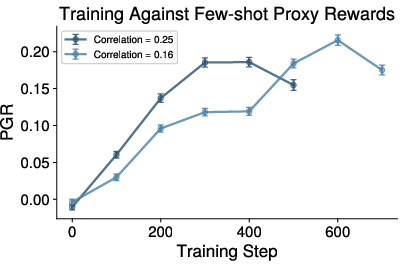
Figure 4: Examples of rubric-based proxy reward models constructed for ICL alignment.
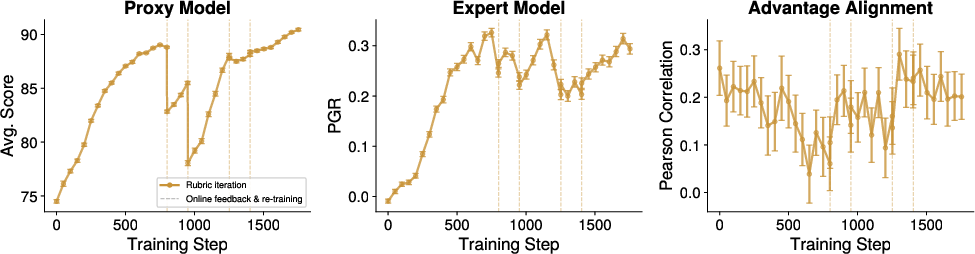
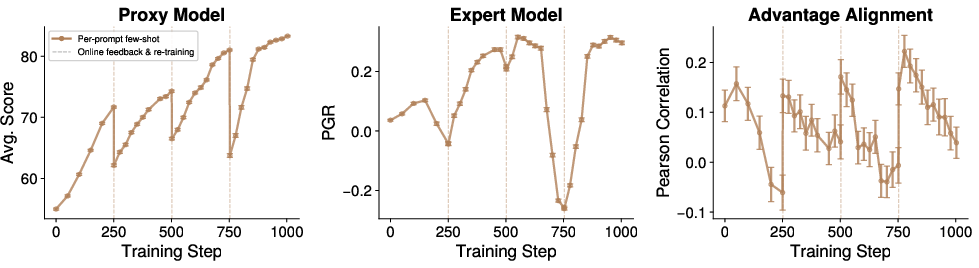
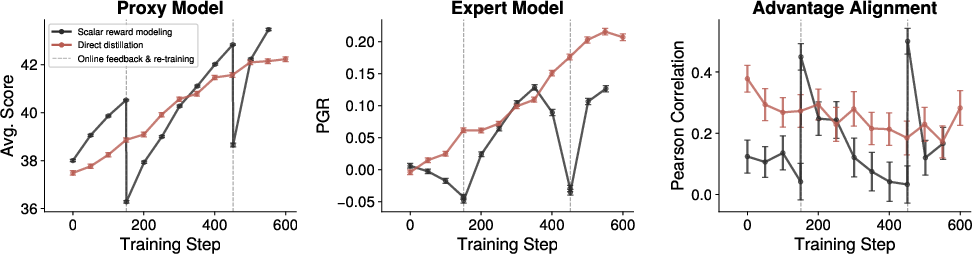
Figure 5: Successive rubric iterations hit a proxy saturation point, with little extra expert reward gained despite proxy improvements, indicating diminishing returns in ICL realignments.
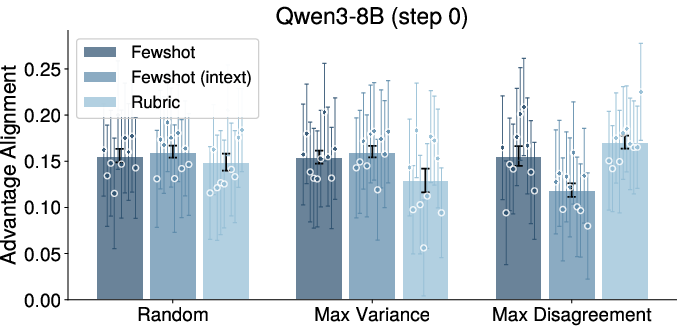
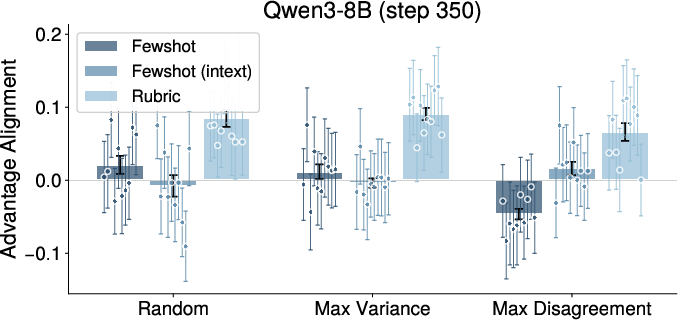
Figure 6: Reward alignment after RL and realignment iterations; proxy-expert agreement nearly always fails to recover initial alignment after full RL cycles.
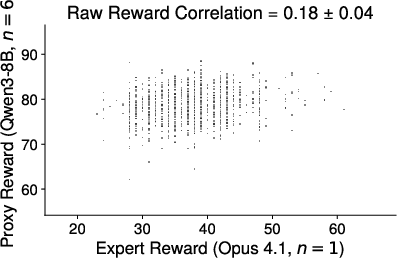
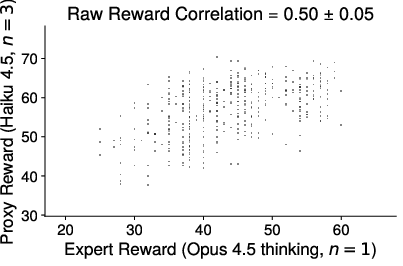
Figure 7: Additional Qwen3-8B training dynamics under different protocols.
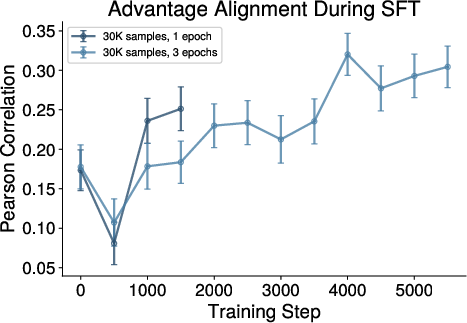
Figure 8: SFT full-trace distillation initially lowers then increases expert-proxy alignment, underscoring the need for large-scale, multi-epoch training for robust alignment.
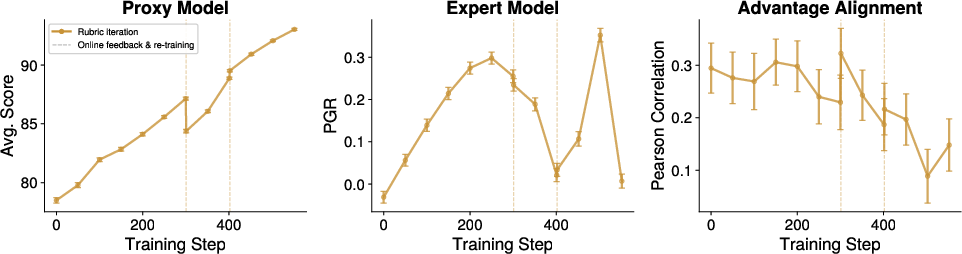
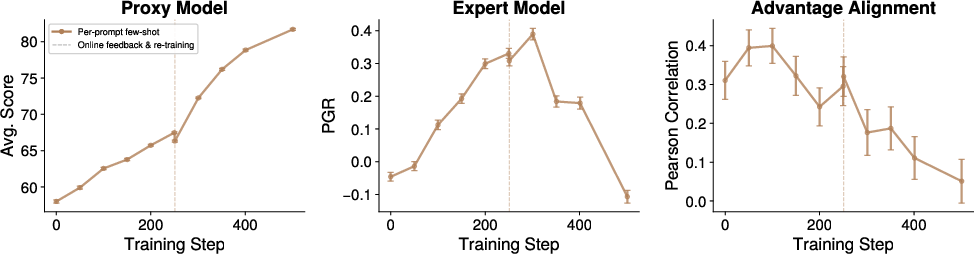
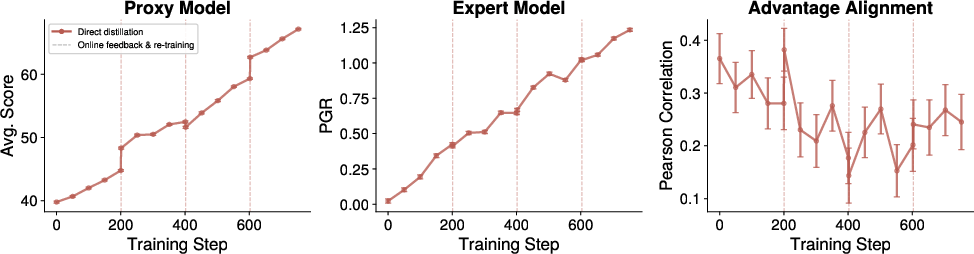
Figure 9: RL with proxy update via iterative rubric generation.
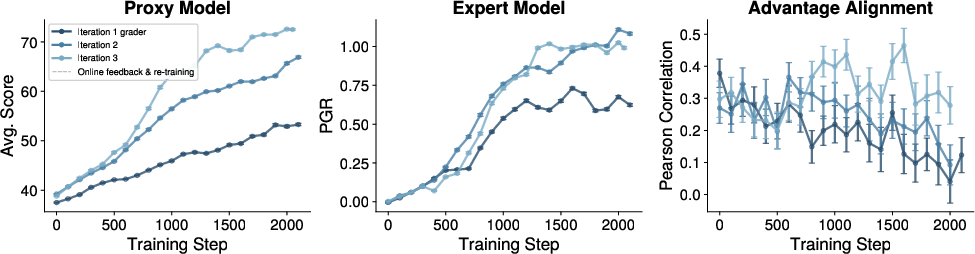
Figure 10: Training from scratch with proxy models from successive distillation iterations confirms improved downstream reward alignment.
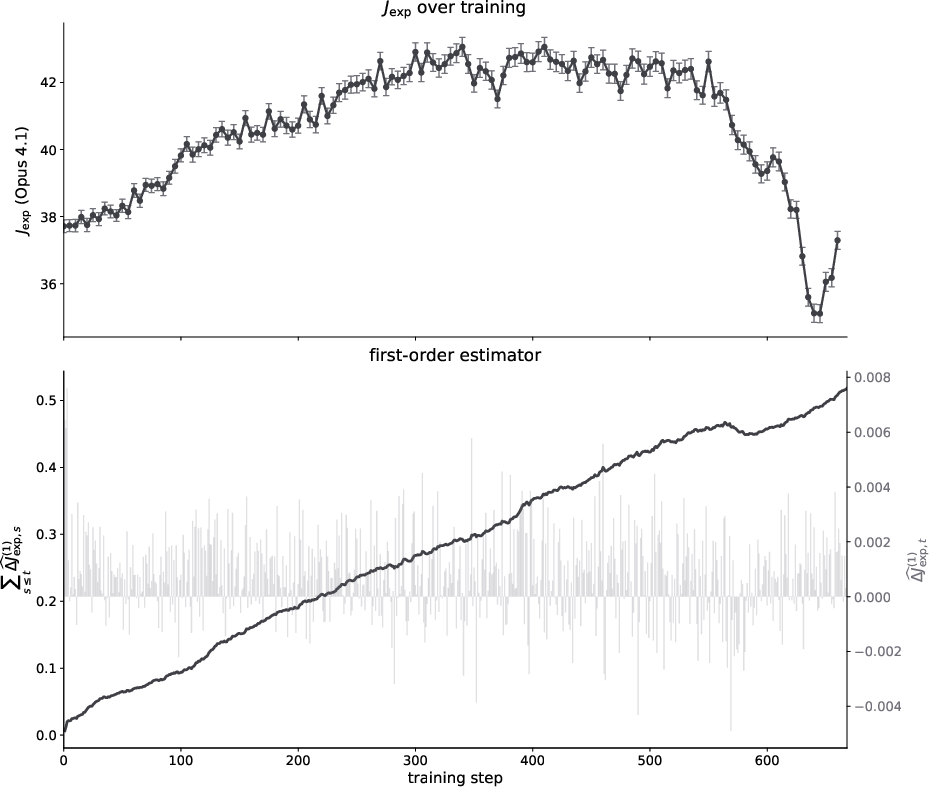
Figure 11: First-order reward estimators underpredict the magnitude of observed expert reward decreases during proxy over-optimization.
Implications and Theoretical Insights
This study demonstrates that detailed, natural language expert feedback—when iteratively incorporated using data-efficient distillation or ICL—is a viable path to scalable, robust oversight for open-ended LLM tasks. Key theoretical and practical takeaways:
- Only in-weight (fine-tuning) updates provide reliable performance at high data efficiency; prompt-based proxy realignment hits expressive and robustness limitations after a handful of iterations.
- Scalar-only reward modeling is fundamentally less robust than reward modeling leveraging full free-text rationales; future methods should exploit richer feedback channels.
- Proxy over-optimization remains a core risk, with diminishing alignment between proxy and expert rewards on out-of-distribution policy samples over time; this necessitates active monitoring and re-anchoring of proxies to the true expert reward signal.
- Alignment diagnostics such as advantage correlation furnish actionable signals for proxy selection, protocol choice, and early termination criteria in RL.
- There is a critical difference in alignment protocol effectiveness as a function of model capability: more capable prox(ies) (e.g., Haiku 4.5) were less amenable to further ICL-based improvements over their well-engineered baseline prompts compared to less capable ones (Qwen3-8B), hinting that alignment strategies must be tailored to the starting capability of the proxy.
Future Directions
This work prompts several avenues for further research:
- Generalization to human experts and scalability: All experiments use LLMs as stand-ins for human experts; transitioning these techniques to crowdsourced or domain-specialist human raters (with real-world label noise and cost) is crucial.
- Richer, structured feedback modeling: Methods to exploit not only long-form feedback but also structured explanations, counterfactuals, or criticality analyses—in both proxy and RL policy models—may further enhance alignment and robustness.
- Reward hacking and proxy gaming analysis: As policies grow in capability, adversarial learning and causal testing of proxy reward robustness is needed to pre-empt emergent reward exploitation.
- Beyond sandwiching: Deploying these methods in non-sandwiched regimes with strong policies and weak or distributed supervision is an open question for scalable algorithmic oversight.
Conclusion
Efficiently aligning LLMs on fuzzy, high-value tasks with online natural language expert feedback is feasible at high data efficiency, provided protocols leverage fine-tuned proxy reward models anchored in rich, full-trace textual feedback and iteratively corrected via expert oversight. While prompt-based (ICL) updates are cheap and can provide quick initial improvements, they lack robustness for long-horizon optimization. Continuous proxy re-anchoring and careful alignment diagnostics are required for robust RL under weak, fallible proxies. These findings elucidate the practical mechanics, risks, and benefits of online feedback-driven alignment—and lay groundwork for scalable oversight in domains where expert judgment remains the gold standard.

