Why Fine-Tuning Encourages Hallucinations and How to Fix It
Abstract: LLMs are prone to hallucinating factually incorrect statements. A key source of these errors is exposure to new factual information through supervised fine-tuning (SFT), which can increase hallucinations w.r.t. knowledge acquired during pre-training. In this work, we explore whether SFT-induced hallucinations can be mitigated using established tools from the continual learning literature, since they arise as a by-product of knowledge degradation during training. We propose a self-distillation-based SFT method that facilitates effective factual learning while minimizing hallucinations w.r.t. pre-existing knowledge by regularizing output-distribution drift. We also show that, in settings where new knowledge acquisition is unnecessary, suppressing factual plasticity by freezing parameter groups, can preserve task performance while reducing hallucinations. Lastly, we investigate the mechanism behind SFT-induced hallucinations through three hypotheses: capacity limitations, behavior cloning, and localized interference. Our experiments show that a main driver is interference among overlapping semantic representations, and that self-distillation succeeds by mitigating this interference.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper asks a simple question: Why do LLMs sometimes “make stuff up” (hallucinate) more after we fine‑tune them, and how can we stop that? The authors show that fine‑tuning a model on new facts can make it “forget” some of what it already knew, which then shows up as wrong answers. They reframe this as a classic learning problem called the stability–plasticity tradeoff: learning new things (plasticity) can harm old knowledge (stability). They then test and propose two practical fixes that keep old knowledge safe while still letting the model learn.
Key objectives in plain language
The paper set out to:
- Check if fine‑tuning on new facts really causes models to forget old facts (leading to more hallucinations).
- Find ways to fine‑tune that keep the model’s old knowledge intact.
- Figure out what, inside the model, causes this forgetting: is it limited memory, copying behavior, or interference between similar facts?
How they tested it (methods explained simply)
Think of the model like a big library:
- “Pre‑training” stocked the library with lots of books (facts).
- “Fine‑tuning” teaches the librarian how to answer questions in a certain style, and sometimes adds new books.
The authors separated two things that usually get mixed together:
- Learning the task format (how to answer questions nicely), and
- Learning new facts.
To do that, they:
- Used a method called SLiCK to sort questions into “HighlyKnown” (the model already knows the answer) and “Unknown” (the model doesn’t).
- Trained on different mixes:
- Only HighlyKnown questions (teaches the format, no new facts added).
- A mix of HighlyKnown and Unknown questions (teaches format and adds new facts).
- Measured three things at the same time:
- Task learning: How well the model adopts the Q&A style on known facts.
- New fact learning (plasticity): How well it picks up the new facts.
- Old fact stability: Whether answers on held‑out known facts get worse (i.e., forgetting/hallucinating).
They also tried two mitigation strategies:
- Freezing parameter groups: Imagine locking some drawers in the library so they can’t be changed. They compared updating only the “attention” parts versus only the “FFN” (feed‑forward) parts to see which updates cause forgetting.
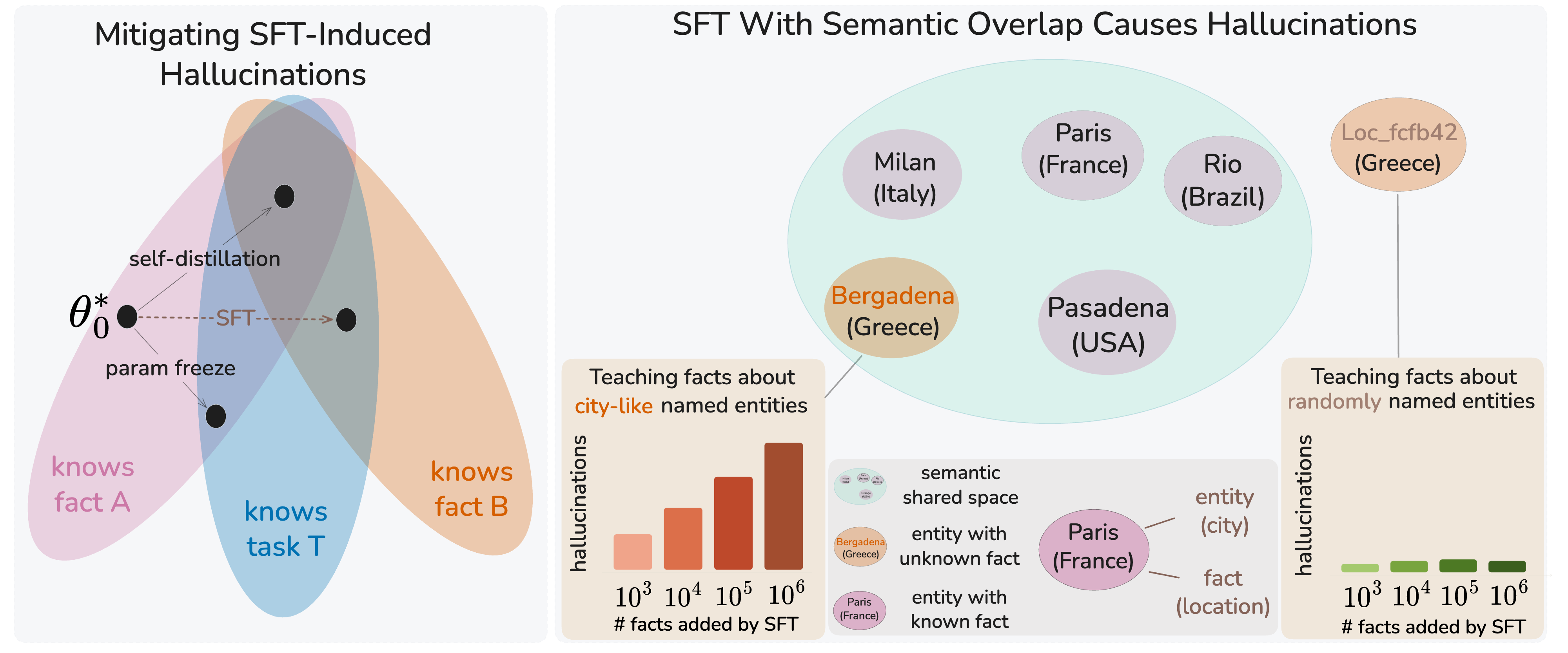
- Self‑distillation: Think of the model as a student who checks with its earlier self (a “teacher snapshot”) to avoid drifting too far from what it used to say. During fine‑tuning, they added a gentle “stay close to your previous outputs” rule so the model learns new facts without overwriting old ones.
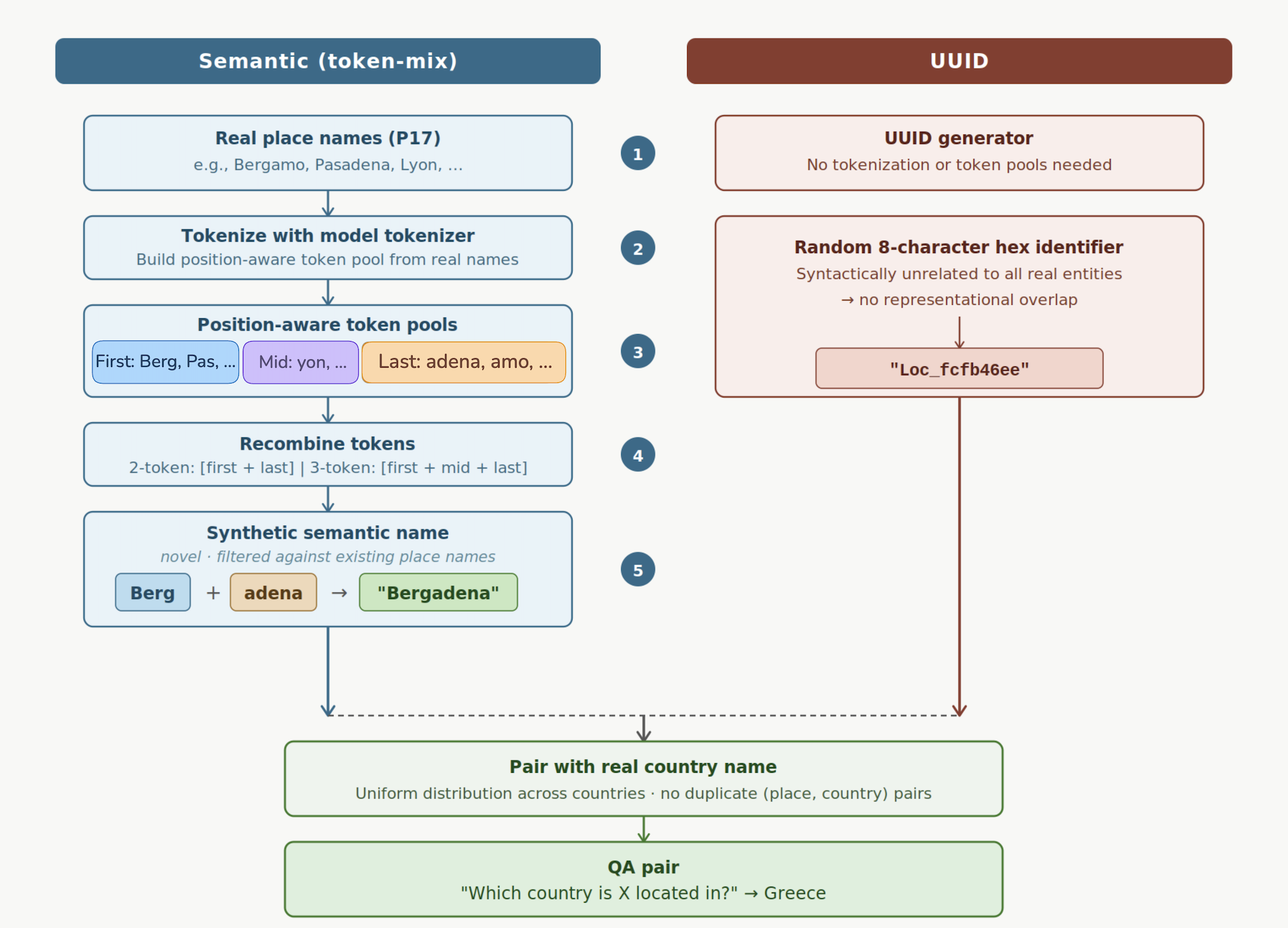
Finally, to uncover the cause of forgetting, they ran a controlled experiment with synthetic facts:
- Some new “locations” had name‑like labels (e.g., “Bergadena”), which sound similar to real places.
- Others used random ID‑style labels (e.g., “Loc_fcfb46”), which share no resemblance with real names.
- They added from 1,000 up to 1,000,000 such facts and watched when and how the model started forgetting old facts.
- They also measured “representation drift” (like checking if books got moved around on the shelves inside the model): how much the model’s internal representation of known entities shifted during training.
Main findings and why they matter
Here are the highlights:
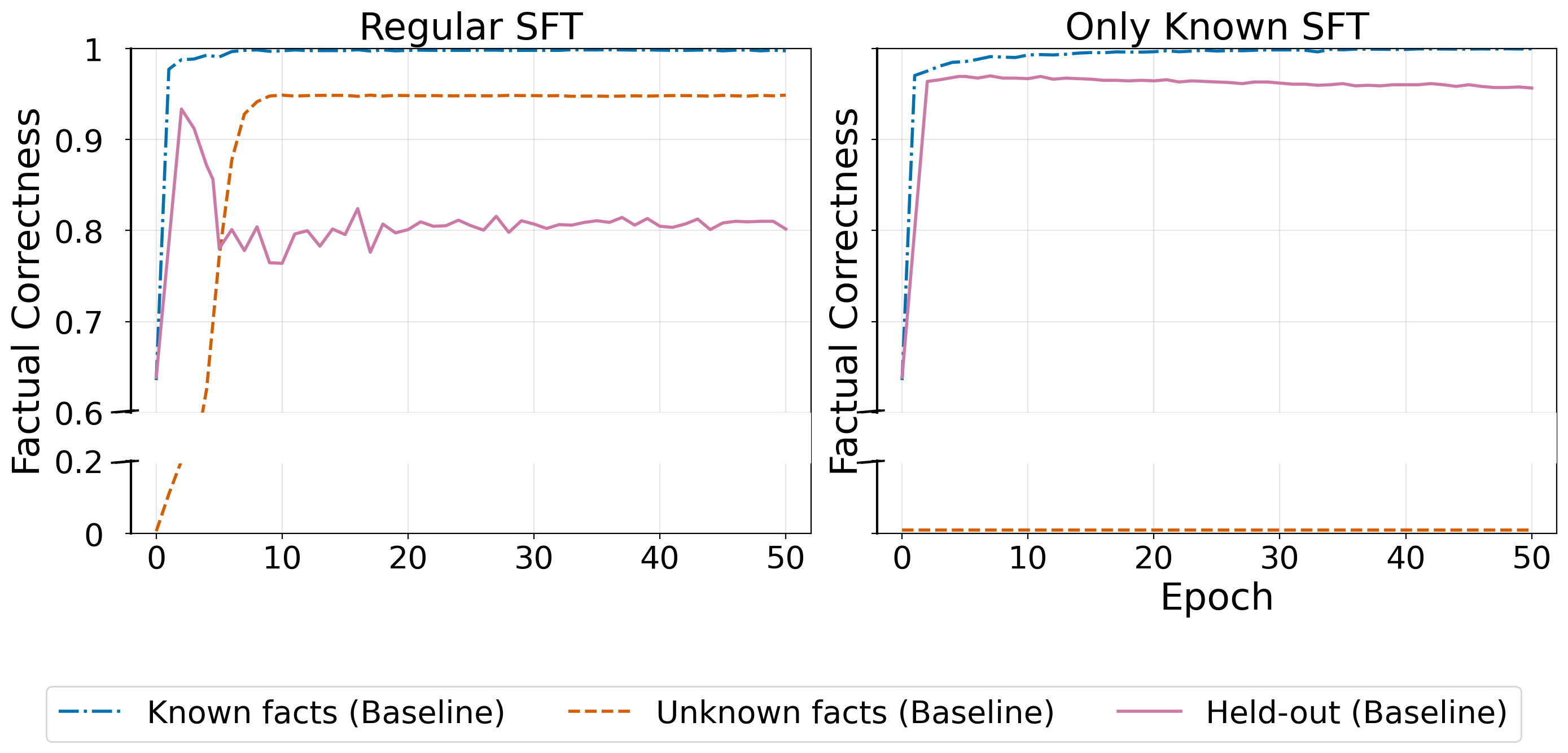
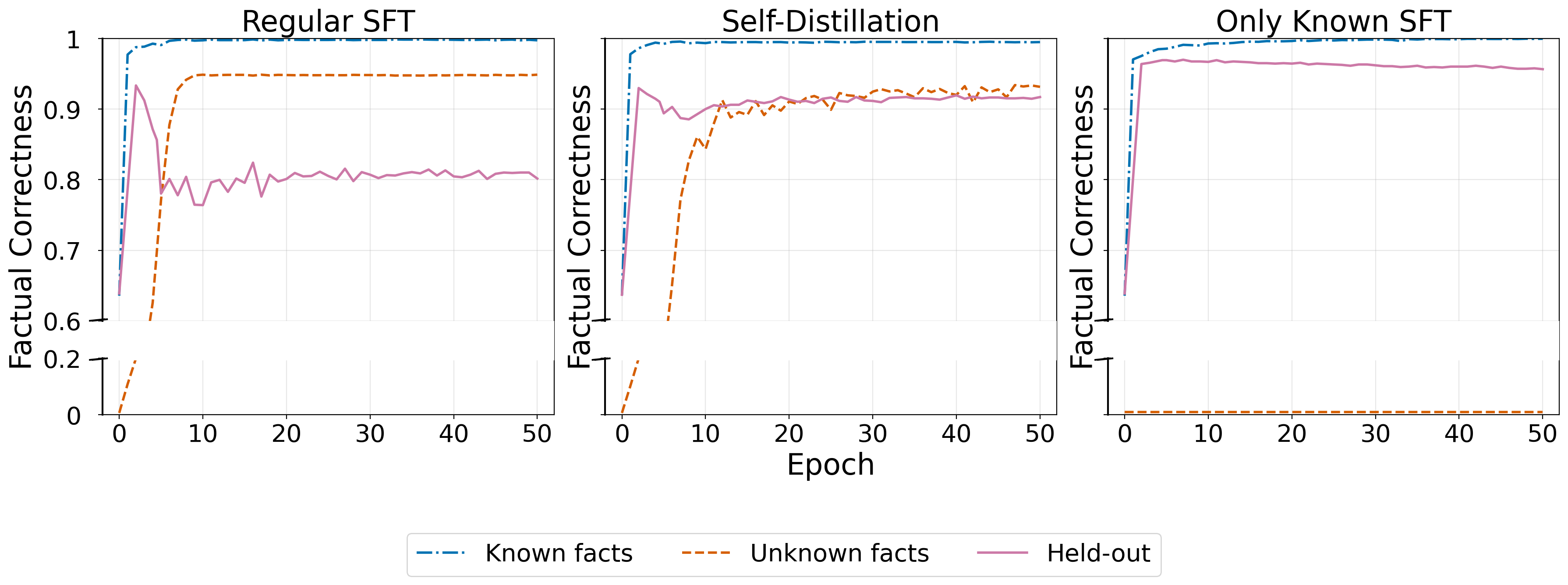
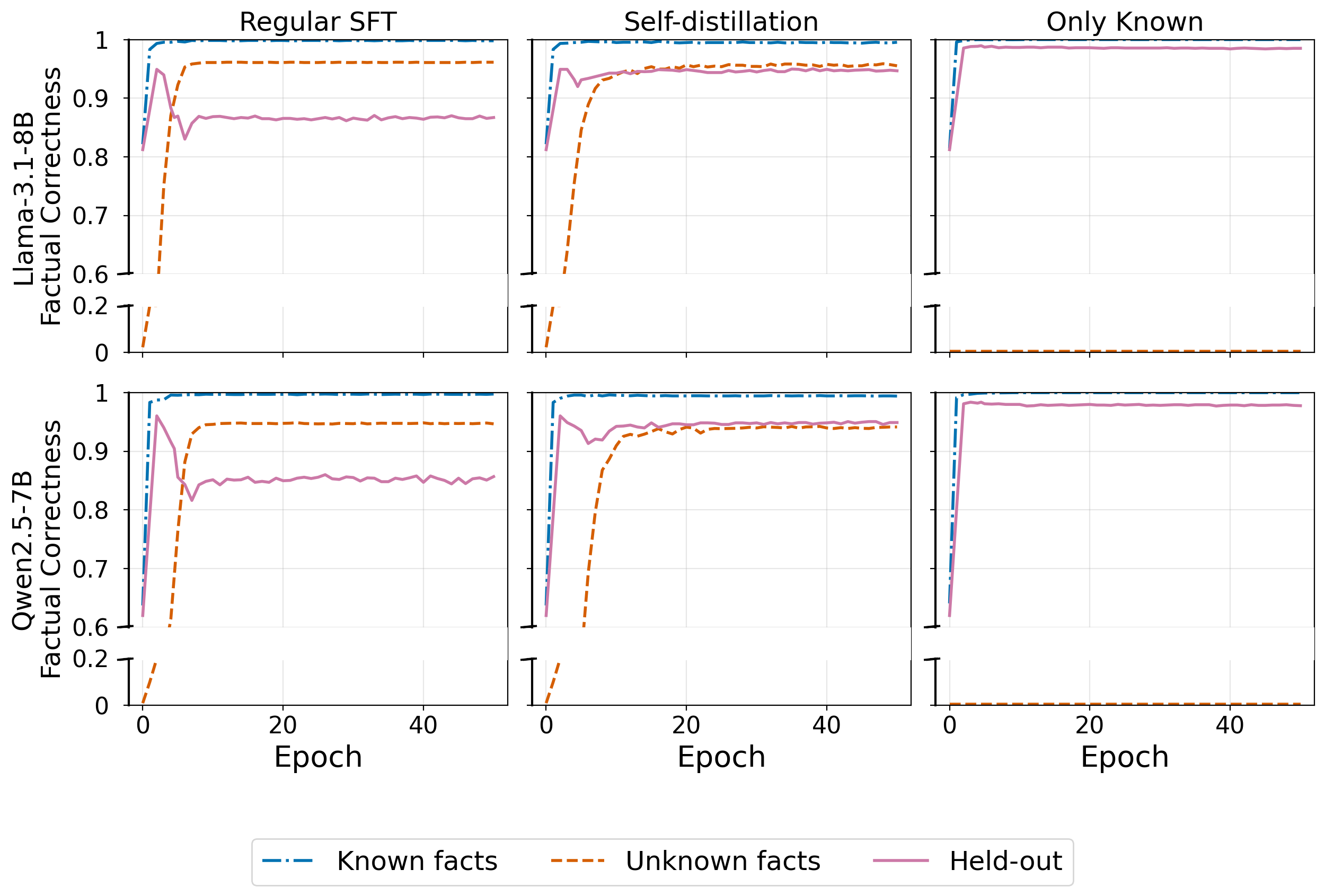
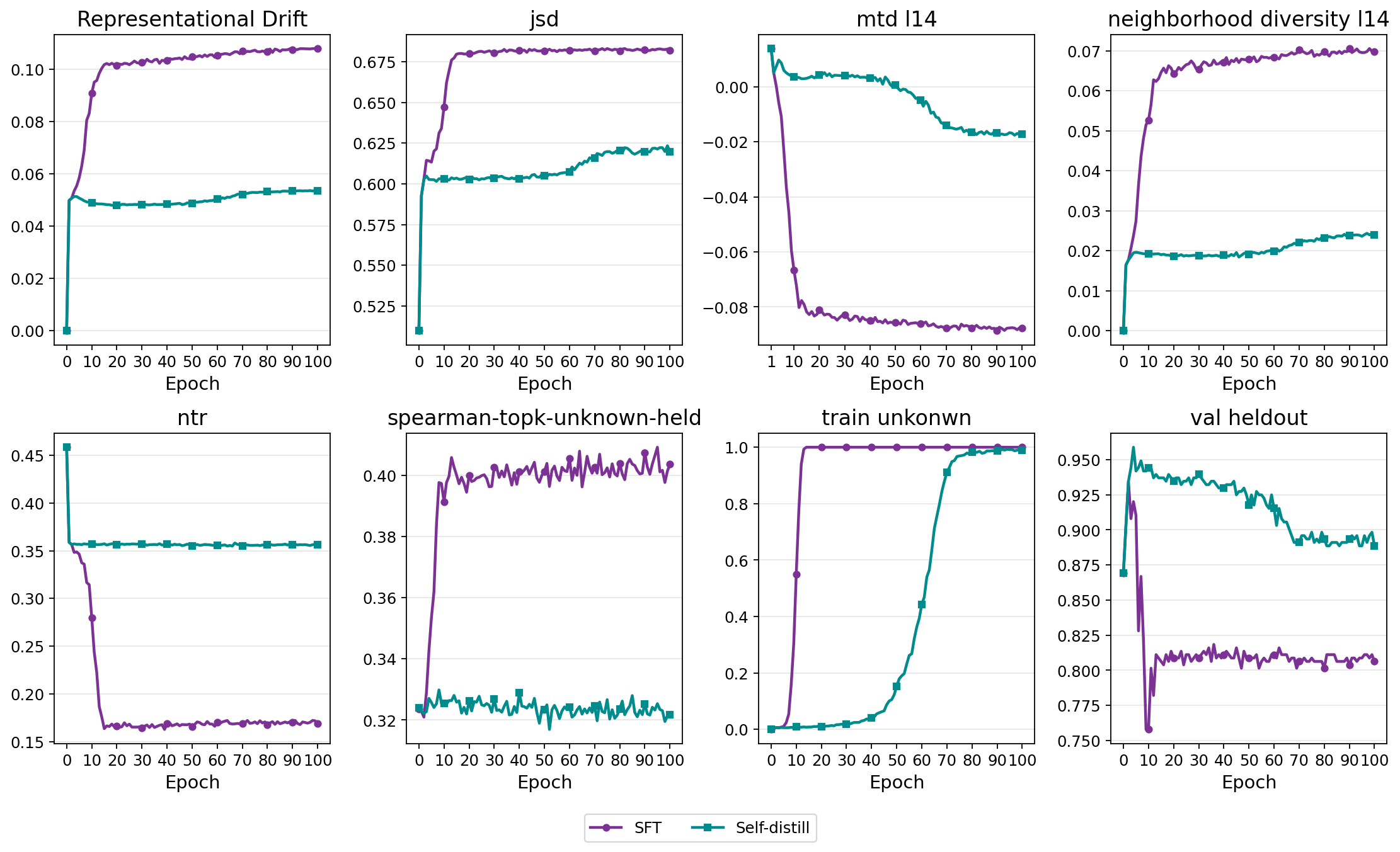
- Learning new facts triggers forgetting of old facts (and thus more hallucinations):
- When trained on both known and new facts, the model learned the new facts but its accuracy on previously known facts dropped by about 15%.
- When trained only on known facts (no new facts), accuracy on old facts stayed stable. So the problem isn’t fine‑tuning itself—it’s the addition of new facts.
- Freezing certain parts can prevent new facts from overwriting old ones:
- Updating only attention layers: the model learned the Q&A format but barely picked up new facts, and old knowledge remained safe (few hallucinations).
- Updating only FFN layers behaved like standard fine‑tuning: the model learned new facts but also forgot more old ones.
- This is useful when you want to adapt how the model answers without injecting new factual content (e.g., safety tuning or private-domain formatting).
- Self‑distillation lets the model learn new facts without much forgetting:
- With a “stay close to your past answers” constraint, the model learned new facts at a similar speed but the drop on old facts shrank from ~15% to ~3%.
- This is great when you do want to inject new knowledge but keep the old knowledge intact.
- The main cause of forgetting is interference between similar facts, not just limited capacity or blind behavior copying:
- Adding millions of random‑ID facts barely caused forgetting.
- Adding many name‑like facts (that resemble real entities) caused much more forgetting—even at smaller scales.
- Inside the model, the “representations” of old entities moved a lot more when the new facts used name‑like labels. Self‑distillation reduced this movement, which matched the drop in hallucinations.
- This means the problem is localized “bumping” in the model’s semantic neighborhoods: updating info about a new, similar‑sounding entity can jostle old, nearby knowledge.
What this means going forward (implications)
- Treat hallucinations after fine‑tuning as a forgetting problem:
- It’s not inevitable. It happens when new facts disrupt nearby, similar knowledge.
- Pick the right strategy for your goal:
- If you don’t want the model to absorb new facts (just teach it style or safety), freeze the parts that tend to store facts (e.g., avoid updating FFNs). This preserves old knowledge and reduces hallucinations.
- If you do want to add new facts, use self‑distillation. It keeps the model’s answers close to its earlier self and prevents harmful drift, cutting forgetting dramatically.
- Be careful about data that resembles existing entities:
- New facts with names that look like real names are more likely to cause interference. If possible, use less confusable labels or apply stronger preservation techniques (like self‑distillation).
- Big picture:
- Fine‑tuning doesn’t have to make hallucinations worse. With the right tools, we can keep old knowledge stable while adding new knowledge. Future work should treat “factual stability” as a first‑class goal during fine‑tuning, borrowing ideas from continual learning to make models more reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored, framed to guide follow‑up research.
- External validity beyond closed-book entity-centric QA: Do the findings hold for long-form generation, summarization, multi-hop reasoning, code, math, or tool-augmented tasks where hallucinations arise via different pathways?
- Model scale and regime dependence: Are the plasticity–stability dynamics and mitigations unchanged for larger, instruction-tuned, or RLHF/DPO-tuned frontier models (e.g., ≥70B) with different inductive biases and calibration properties?
- Cross-lingual and domain generalization: Does overlap-driven interference behave similarly for non-English entities and in specialized domains (biomed, legal) with different tokenization statistics and entity distributions?
- Sequential SFT and continual updates: How do hallucinations accumulate across multiple fine-tuning rounds (e.g., domain adaptation → instruction tuning → preference optimization), and can self-distillation remain effective over long sequences?
- Alternative continual-learning methods: How do replay buffers, parameter isolation (e.g., adapters, dynamic expansion), EWC/Fisher penalties, orthogonal gradient projection, trust-region KL constraints, or EMA teachers compare to self-distillation on forgetting vs. plasticity?
- Distillation design choices: What is the impact of teacher selection (snapshot vs. EMA, earlier vs. later epochs), temperature/λ schedules, token-level masking (e.g., entity tokens only), or online teacher updates on the stability–plasticity trade-off?
- Compute/latency budget: What are the training-time and memory overheads of self-distillation relative to simpler constraints, and how do they scale with model size and dataset size?
- Side effects beyond accuracy: How do freezing and self-distillation affect calibration, uncertainty, refusal behavior, harmful content, bias amplification, and output diversity?
- Interaction with retrieval: Does representational interference persist or diminish in RAG settings, and does forgetting harm retrieval conditioning (e.g., alignment between retrieved passages and generation)?
- Robustness to label noise and spurious correlations: Are interference and mitigations stable when injected “facts” contain noise, ambiguity, or conflicting evidence across sources?
- Sensitivity to data curriculum and mixing: How do sampling ratios (Known/Unknown), curriculum pacing, batching, and example ordering modulate forgetting and interference?
- Optimizer and hyperparameter dependence: Are the conclusions robust across optimizers (AdamW vs. Adafactor), learning-rate schedules, batch sizes, and regularization strengths?
- Parameter-group granularity: Beyond attention vs. FFN, which specific subcomponents (e.g., embeddings, layer norms, q/k/v/o projections, FFN gates, positional encodings) drive factual plasticity vs. stability, and can finer-grained freezing or low-rank updates improve the trade-off?
- Mechanistic localization: Which layers/heads/neurons exhibit the strongest representational drift during interference, and can neuron-/head-level constraints or routing avoid corrupting factual neighborhoods?
- Representation similarity vs. surface-form overlap: The paper varies surface forms (name-like vs. UUID) but does not quantify embedding-space similarity; does forgetting correlate more tightly with token-, subword-, or contextual-embedding proximity than with string form?
- Tokenization artifacts: Are results driven by subword segmentation (e.g., shared morphemes) rather than semantic overlap per se? Controls with equal token counts/frequencies and synthetic tokens with controlled segmentation are needed.
- Relation and fact type coverage: Do effects replicate across more relations (beyond P17 Location→Country), multi-value facts, temporal facts, commonsense, procedural, or causal knowledge?
- Persistence and relearning: After forgetting, can the model quickly recover held-out facts with minimal training, and does self-distillation ease recovery (i.e., was knowledge masked vs. erased)?
- Long-term drift and stability: How stable are mitigations under prolonged training (more epochs) and larger knowledge injections (>1M facts) without catastrophic plasticity loss?
- Causal evidence for interference: Hidden-state drift is a proxy; can gradient attributions, Fisher overlap, or causal circuit interventions directly demonstrate that updates to new entities perturb specific preexisting entities?
- Targeted constraints: Would constraining logits only on entity tokens or trust-region constraints on entity spans suffice, reducing distillation costs while preserving effectiveness?
- Interaction with adapters and LoRA: Can isolating new facts in adapters/LoRA while freezing base weights achieve similar stability without sacrificing plasticity, and how does this compare to distillation?
- Evaluation breadth and metrics: Exact-match accuracy misses near-synonyms and partial credit; does the observed forgetting persist under semantic matching, human evaluation, or contradiction detection?
- Statistical rigor: What are confidence intervals, variance across seeds/splits, and sensitivity to SLiCK misclassification of “Known/Unknown,” especially for Maybe/WeaklyKnown items that were filtered?
- Safety and privacy use cases: The paper motivates privacy/alignment scenarios but does not test whether freezing or distillation reliably prevent undesired memorization of sensitive facts while maintaining task performance.
- Curriculum for minimizing interference: Can scheduling new facts by low embedding similarity to held-out facts (or by spaced repetition) reduce interference while maintaining learning speed?
- Theory of interference scaling: Can a predictive model connect capacity, representational overlap, and update magnitudes to expected forgetting, enabling principled hyperparameter choices?
- Layerwise drift profiling: Only a middle layer is analyzed; how does drift evolve layer-by-layer, and do early vs. late layers differentially mediate interference and mitigation?
- Generalization to multimodal LLMs: Do analogous interference patterns arise when learning new visual entities/names, and does self-distillation curb cross-modal forgetting?
- Open-source tooling and reproducibility: Clearer release of data generation code (synthetic keys), seeds, and configurations would allow precise replication and ablation of the reported effects.
Practical Applications
Immediate Applications
The paper offers concrete practices that can be applied today to reduce fine-tuning–induced hallucinations by managing the stability–plasticity tradeoff and mitigating representational interference.
- Safer task-format adaptation by freezing FFN (update only attention)
- Sectors: software, enterprise AI, healthcare, finance, public sector, education
- Tools/workflows: configure full-parameter SFT to freeze FFN layers and train only attention (or place LoRA adapters only on attention projections) when the goal is instruction/style adaptation (alignment) rather than knowledge injection; use standard supervised losses
- Assumptions/dependencies: access to model weights or adapter targeting; may suppress new fact acquisition (intended); tested on 1.5B–8B non-reasoning LLMs—validate on larger/reasoning models before deployment
- Knowledge updates with reduced forgetting via self-distillation (Learning without Forgetting)
- Sectors: enterprise knowledge management (support, legal ops), healthcare guidelines, finance (policy/manual updates), consumer assistants
- Tools/workflows: two-loss SFT objective combining task loss with KL regularization to a frozen “teacher” snapshot (e.g., after 1 epoch on Known-only data), with temperature τ≈0.5 and λ≈1 as starting points; maintain throughput by caching teacher logits
- Assumptions/dependencies: extra compute for teacher forward passes; hyperparameter tuning needed; verified on EntityQuestions QA—extend evaluation to downstream generation tasks
- Two-stage fine-tuning curriculum to separate task learning from factual updates
- Sectors: most industries deploying adapted LLMs
- Tools/workflows: Stage 1—“Known-only” SFT to learn task format (collect or detect high-confidence-known items); snapshot becomes teacher; Stage 2—SFT on Known+Unknown with self-distillation; monitor held-out known facts
- Assumptions/dependencies: requires identifying “Known” vs “Unknown” items; if SLiCK is unavailable, approximate with confidence heuristics or retrieval-backed checks
- LoRA targeting strategy to reduce drift
- Sectors: MLOps, platform teams fine-tuning OSS LLMs
- Tools/workflows: apply LoRA adapters only to attention layers for alignment/task-format tuning; for factual updates, combine LoRA (FFN+attention) with self-distillation
- Assumptions/dependencies: adapter support; trade-offs in capacity and convergence; validate on your data
- Dataset linting for surface-form overlap to prevent interference
- Sectors: data engineering for LLM fine-tunes across domains
- Tools/workflows: “similarity linter” that flags new entity names with high lexical/embedding similarity to known entities; if high overlap, either (i) rename to unique tokens (e.g., internal IDs), (ii) strengthen distillation/regularization, or (iii) route to retrieval instead of parametric injection
- Assumptions/dependencies: access to embedding models; potential UX trade-offs if names are altered; best for internal KBs or intermediate representations
- Pseudonymization/UUIDs for sensitive entities during SFT
- Sectors: healthcare, finance, HR, legal (privacy + stability)
- Tools/workflows: replace PII or sensitive entity names with stable UUID-like identifiers during fine-tuning; maintain a secure mapping layer to render surface forms at inference
- Assumptions/dependencies: pipeline to remap identifiers; risk of domain shift if final usage requires natural names; best for internal/structured workflows
- Factual stability monitoring in MLOps
- Sectors: regulated industries; any team practicing continuous model updates
- Tools/workflows: add “held-out known facts” checks and acceptance thresholds to CI/CD; track a “factual stability score” (e.g., accuracy on held-out known facts vs peak); optionally add representational drift monitors (cosine drift on entity-token hidden states) when weights are accessible
- Assumptions/dependencies: requires curated held-out known sets or synthetic surrogates; hidden-state metrics require model access; thresholds must be calibrated
- Evaluation protocol that separates task learning from factual stability
- Sectors: academia, industry evaluation teams
- Tools/workflows: adopt a SLiCK-like pipeline to tag dataset items as HighlyKnown vs Unknown; report (i) task-format learning (Known), (ii) factual plasticity (Unknown), and (iii) factual stability (Held-out Known) in all fine-tuning reports
- Assumptions/dependencies: compute for prompting-based classification; domain adaptation may require custom tagging logic
- Prefer retrieval or tool-use for knowledge injection
- Sectors: product teams adding fast-changing facts (news, prices, policies)
- Tools/workflows: for large volumes of new facts—especially with entity names similar to existing ones—prioritize RAG/tool-use; restrict SFT to task-format alignment or use self-distillation when parametric updates are essential
- Assumptions/dependencies: high-quality retrievers/corpus; orchestration complexity; latency budgets
- Developer best practices for small-scale/custom fine-tunes
- Sectors: SMEs, individual developers
- Tools/workflows: avoid training on synthetic name-like entities; use unique tags or IDs for internal terms; if using off-the-shelf fine-tuning services with LoRA, target attention only for alignment tasks; add a small held-out quiz of known facts to detect regressions post-tuning
- Assumptions/dependencies: limited control with closed APIs; small eval sets must be carefully curated
Long-Term Applications
These opportunities build on the paper’s insights but require additional research, scaling, or engineering before broad deployment.
- Interference-aware optimizers and schedulers
- Sectors: model providers, MLOps platforms
- Tools/products: optimizers that dynamically constrain gradients on tokens/entities with high overlap to protected knowledge; schedule stronger distillation when interference risk spikes
- Assumptions/dependencies: reliable online detection of overlap and protected spans; instrumentation access; careful trade-off with plasticity
- Factual stability regularization suites (“Factual Stability Kit”)
- Sectors: AI platforms, open-source toolchains
- Tools/products: turnkey libraries offering self-distillation, drift monitors, entity-overlap linting, and evaluation harnesses; CI integrations for “stability gates”
- Assumptions/dependencies: standard interfaces for different model families; maintenance of teacher snapshots/logits at scale
- Interference graphs for safe knowledge injection
- Sectors: knowledge engineering, enterprise AI
- Tools/products: build “interference graphs” mapping semantic neighborhoods of entities; plan updates to minimize cross-entity interference (e.g., batch updates by low-overlap groups)
- Assumptions/dependencies: scalable neighborhood construction; evolving vocabularies; proprietary data constraints
- Continual learning for on-device/edge LLMs
- Sectors: robotics, wearables, embedded systems
- Tools/products: self-distillation–based online learning that updates local facts while guarding global knowledge; compressed “teacher-on-chip” approximations
- Assumptions/dependencies: compute/memory constraints; privacy-preserving logging; robust fallback when confidence is low
- Standardized “factual stability” certification for regulated deployments
- Sectors: healthcare, finance, government
- Tools/policy: regulatory guidance requiring stability tests (held-out known performance, drift thresholds) after each model update; audit logs of teacher snapshots and distillation configs
- Assumptions/dependencies: consensus test suites; sector-specific known-fact panels; enforcement mechanisms
- Entity aliasing and canonicalization frameworks
- Sectors: enterprises with proprietary taxonomies
- Tools/products: pipelines that canonicalize internal entities to unique tokens for training and remap to human-readable names at runtime; reduce interference and support privacy
- Assumptions/dependencies: consistency across teams/systems; UX impacts; multilingual coverage
- Editing-at-scale with interference-aware planning
- Sectors: search, virtual assistants, e-commerce catalogs
- Tools/products: large-scale knowledge editing that prioritizes low-overlap updates and activates stronger regularization for high-overlap batches; mixed RAG/SFT routing
- Assumptions/dependencies: accurate overlap estimates; orchestration across retrieval and SFT; monitoring to prevent regressions
- Alignment methods that preserve factual stability
- Sectors: foundation model providers, safety research
- Tools/products: combine RLHF/DPO with self-distillation objectives or output-distribution constraints to prevent factual drift during alignment
- Assumptions/dependencies: interaction with preference optimization; careful tuning to avoid over-regularization of beneficial behaviors
- Benchmarking and research extensions
- Sectors: academia, standards bodies
- Tools/products: multilingual and cross-domain datasets that disentangle task learning from factual stability; benchmarks capturing interference effects and mitigation efficacy
- Assumptions/dependencies: community adoption; reproducibility across model sizes and families; extensions beyond QA to long-form generation
- Sector-specific continual updates with guarantees
- Sectors: healthcare (clinical guidelines), finance (regulatory changes), law (statute updates)
- Tools/products: pipelines that schedule periodic small updates with self-distillation, interference checks, and acceptance thresholds; provide documented “stability deltas” per release
- Assumptions/dependencies: access to authoritative “Known” panels; governance processes; integration with change management systems
- Retrieval–parametric hybrid strategies
- Sectors: news/media, real-time analytics, scientific assistants
- Tools/products: policies that keep rapidly changing facts in retrieval while parameterizing only stable, low-overlap knowledge; self-distillation guards both regimes
- Assumptions/dependencies: high-quality retrievers; freshness/consistency guarantees; cost models for dual infrastructure
These applications rely on the paper’s core findings: (i) SFT-induced hallucinations often stem from representational interference, especially when new facts share surface-form similarity with known entities; (ii) freezing FFN (training attention only) supports task adaptation with minimal factual drift; and (iii) self-distillation regularizes output distribution drift to preserve prior knowledge while still acquiring new facts. Adopting these practices can reduce induced hallucinations from ~15% to ~3% in settings similar to those tested, with validation recommended for specific domains and model scales.
Glossary
- behavior cloning: A training effect where models imitate observed outputs, potentially producing answers regardless of knowledge boundaries. "behavior cloning derived by SFT"
- catastrophic forgetting: Abrupt loss or degradation of previously learned knowledge when learning new information. "catastrophic forgetting over parametric factual knowledge"
- closed-book QA: Question answering without external retrieval, relying only on the model’s internal (parametric) knowledge. "in closed-book QA"
- continual learning: A paradigm where models learn from sequential tasks/data while balancing retention of old knowledge and acquisition of new knowledge. "In continual learning, forgetting typically arises"
- cosine distance: A similarity measure based on the angle between two vectors, often used to compare representations. "cosine distance captures directional shifts in representation space"
- distillation loss: A regularization term that encourages a student model’s output distribution to match a teacher’s outputs. "The distillation loss penalizes divergence between the output distributions"
- EntityQuestions: An entity-centric QA dataset built from relational facts (e.g., from Wikipedia/Wikidata) used to evaluate factual knowledge. "We use the EntityQuestions dataset"
- feed-forward network (FFN): The position-wise multilayer perceptron sublayers in Transformers that contribute to storing and transforming information. "Training only the FFN closely tracks standard SFT"
- few-shot prompting: Providing a small number of example Q–A pairs in the prompt to condition model behavior. "under multiple randomized few-shot prompting configurations"
- hidden-state drift: The change in internal representations (hidden states) over training, used to assess representational stability. "We track hidden-state drift for held-out entities throughout training"
- ℓ2 regularization: A penalty on the squared magnitude of parameters (or their deviation from a reference) to constrain updates. "and regularization toward "
- logits: Pre-softmax scores produced by a model for each token/class, which determine output probabilities after softmax. "the logits at token position "
- next-token prediction loss: The standard cross-entropy objective for language modeling that predicts the next token in a sequence. "the standard next-token prediction loss"
- non-reasoning LLMs: LLMs evaluated without explicit reasoning or chain-of-thought mechanisms. "several non-reasoning LLMs"
- output-distribution drift: Changes in the model’s output probability distribution over training, potentially reflecting knowledge drift. "output-distribution drift."
- parameter freezing: Keeping a subset of model parameters fixed during fine-tuning to preserve certain behaviors or knowledge. "freezing parameter groups"
- parameter space: The high-dimensional space of all model parameters where training trajectories and forgetting are analyzed. "factual forgetting in parameter space"
- representational interference: Detrimental interactions where updates for new information perturb existing representations, causing forgetting. "representational interference during fine-tuning"
- representational overlap: Shared or nearby internal representations between different entities/facts that can lead to interference. "representational overlap as a primary driver"
- semantic keys: Synthetic, name-like entity identifiers designed to share surface form with known entities, increasing overlap. "semantic keys, formed by recombining tokens from real location names"
- self-distillation: A technique where the model regularizes against its own earlier outputs (teacher snapshots) to reduce forgetting. "we apply self-distillation"
- SLiCK: A method to classify a model’s prior knowledge of facts into categories (e.g., HighlyKnown, Unknown) before training. "We apply the SLiCK method"
- stabilityâplasticity tradeoff: The balance between preserving existing knowledge (stability) and acquiring new knowledge (plasticity). "stabilityâplasticity tradeoff"
- student model: The model being optimized during distillation to align with a fixed teacher while learning new data. "the student model being fine-tuned"
- supervised fine-tuning (SFT): Adapting a pretrained model on labeled data for downstream tasks or updated knowledge. "supervised fine-tuning (SFT)"
- teacher model: A frozen snapshot of the model that provides soft targets for distillation during further training. "the parameters of a frozen teacher model"
- temperature parameter: A scalar controlling the softness of the softmax distribution, used in distillation to emphasize less likely tokens. "temperature parameter"
- UUID-style identifiers: Random, non-semantic strings used as entity keys that minimize representational overlap with known entities. "random UUID-style identifiers"
Collections
Sign up for free to add this paper to one or more collections.