- The paper introduces a fast-slow recurrent model that interleaves rapid latent updates with slower external observations, enabling efficient long-horizon sequence extrapolation.
- The paper demonstrates superior out-of-distribution performance on tasks like Dyck language prediction, maze navigation, and reinforcement learning compared to standard sequence models.
- The paper highlights that weight-shared latent recurrence fosters interpretable, self-organizing state representations, ensuring durable memory consolidation over time.
Fast-Slow Recurrence for Long-Horizon Sequential Modeling
Introduction and Context
The paper "Thinking While Listening: Fast-Slow Recurrence for Long-Horizon Sequential Modeling" (2604.01577) introduces Fast Slow Recurrent Models (FSRMs)—a neural architecture designed to address fundamental limitations of canonical sequence models (LSTM, SSM, Transformer, and their iterative variants) in reasoning over long-horizon, variable-length input streams. The motivation arises from the empirical and theoretical understanding that human cognition integrates rapidly evolving internal (latent) reasoning with slower, irregular observational updates, a mechanism that modern deep sequence models do not emulate effectively. Recent attempts at latent recurrent modeling have shown iterative latent updates can self-organize and cluster internal representations, but existing frameworks do not enable scalable, continuous integration of novel observations through time, a necessity for tasks demanding selective extraction and durable retention of relevant information over long horizons.
FSRMs extend latent recurrent models by incorporating an interleaved fast/slow dynamical process: inner recurrent latent updates progress T times per observation, while external inputs are fed on a slower timescale. This reinterpretation enables continuous latent-state evolution, robust information tracking, and stable consolidation of abstract state, without reinitializing the latent state upon each new input. The architecture is benchmarked on algorithmic reasoning tasks (Dyck language), mazes, and partially observable RL domains, demonstrating significant gains in out-of-distribution (OOD) generalization, sequence extrapolation, and long-horizon coherence compared to contemporary sequence modeling baselines.
Model Architecture and Methodology
FSRM reformulates sequential latent reasoning as a coupled dynamical system—one component for external observations, and a faster-evolving recurrent latent process. At time step t, the encoded observation C(t) is updated only every T steps (i.e., per new observation), while the latent state X(t) receives T iterative updates through a weight-shared module F. Crucially, the latent state is never reset, ensuring that both historical and incoming information persist and are integrated without context length growth.
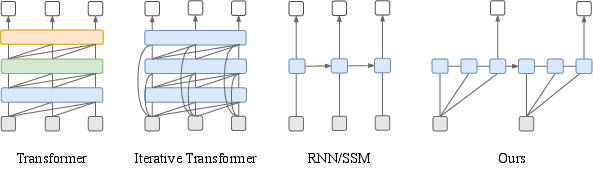
Figure 1: Architectural comparison showing that FSRM performs multiple recurrent latent updates within each slow observation interval, unlike ordinary Transformers or RNNs.
The core update rule can be succinctly described as:
C(t)=Encoder(Os),s=⌊t/T⌋ X(t+1)=Π(X(t)+γF(X(t),C(t);θ))
where Π is projection (unit normalization), γ is the step-size, and t0 implements a vector field (usually attention-driven, as instantiated with AKOrN, but compatible with Transformer or LSTM cells as ablations). The model is trained end-to-end such that outputs are read from the latent after the fast process at multiples of t1 steps (i.e., after each new observation).
By enabling multiple internal updates per external observation, FSRM dynamically organizes the latent state, supporting features such as:
- Continuous, fixed-size compression of context (no context growth, unlike vanilla Transformers/Autoregressive Latent Models)
- Temporal abstraction and long-horizon dependency retention
- Robust OOD generalization, enabled by recurrent latent consolidation and weight sharing in the fast loop
Experimental Evaluation
FSRM is evaluated on three axes: supervised symbolic algorithmic reasoning (Dyck language prediction), sequence-to-sequence maze solving, and reinforcement learning in partially observable environments (MiniGrid). The architecture is compared to strong sequence-modeling baselines (LSTM, SSM/S5, Mamba, Transformer, Looped Transformer, CTM).
The Dyck-t2 task (matching parenthesis prediction) is a stringent test of hierarchical memory and compositionality. FSRM is trained only on strings up to 40 tokens, but evaluated on sequences exceeding t3 tokens. Compared to frontier LLMs (prompted with Dyck's generation algorithm), FSRM maintains t490% token accuracy far beyond its training regime, while LLM performance collapses rapidly with increased context.
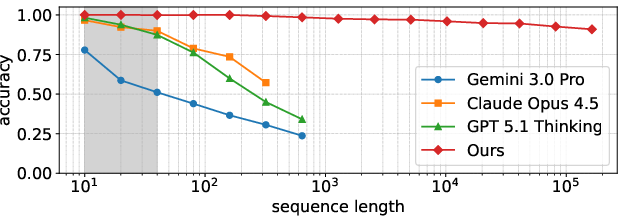
Figure 2: Token-wise accuracy versus sequence length on Dyck-(30,5). FSRM sustains high accuracy orders of magnitude beyond the context length used in training, surpassing LLMs even when they access the rule as prompt.
FSRM also displays strong OOD behavior on regular Dyck runs (periodic, maximally challenging input sequences), consistently predicting the unresolved bracket type with high fidelity where baselines fail.
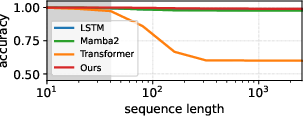
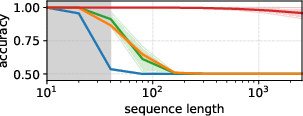
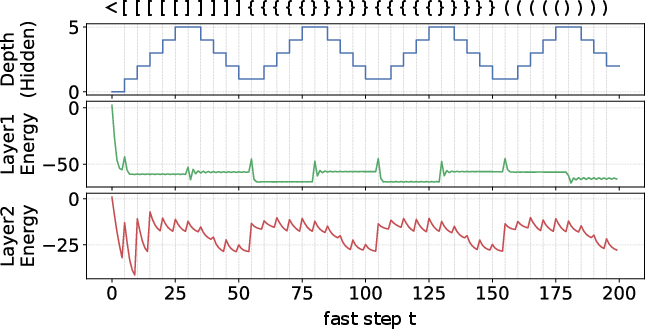
Figure 3: FSRM maintains near-perfect accuracy on both ID and OOD Dyck sequences, while LSTM/Transformer/Mamba-2 degrade to chance as sequence length increases.
Analysis of the latent state's principal components shows that FSRM forms structured manifolds corresponding to stack depth and bracket grouping, while energy-like metrics provide interpretable signatures of information consolidation.
Egocentric Maze Solving
In the sequence-to-sequence maze task, the model must infer the shortest path given a stream of 7×7 egocentric observations gathered as a navigator explores unseen mazes. FSRM is trained on small t5 mazes and evaluated on held-out, upscaled t6 mazes, enforcing strong generalization.
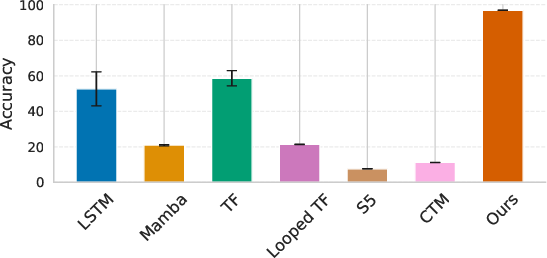
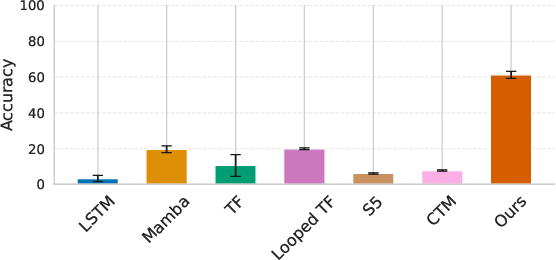
Figure 4: ID maze example illustrating the nature of the input stream and path-finding supervision.
FSRM not only nearly saturates accuracy in-distribution but also sustains t760% exact-match accuracy on large OOD mazes, while all baselines regress to chance. Increasing the number of fast inner-loop recurrent steps t8 during training produces monotonic OOD improvements, and experiments confirm that recurrence/weight sharing in the fast loop is essential—non-recurrent stacks with the same or greater depth do not generalize as well.
Reinforcement Learning (MiniGrid)
On MiniGrid navigation tasks (DoorKey, LavaCrossing, MultiRoom), where the agent receives sparse reward and operates with partial observations, FSRM-based policies exhibit equal or superior zero-shot generalization when trained only on simple maps and tested on more complex ones.
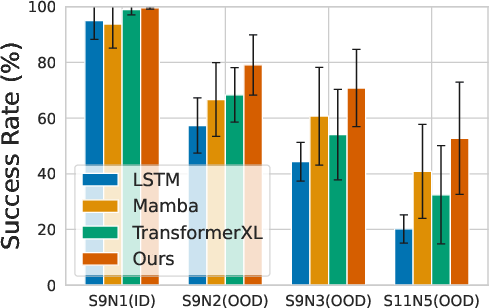
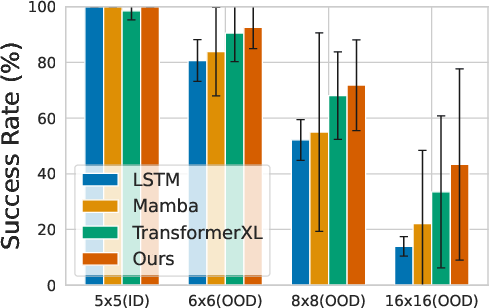
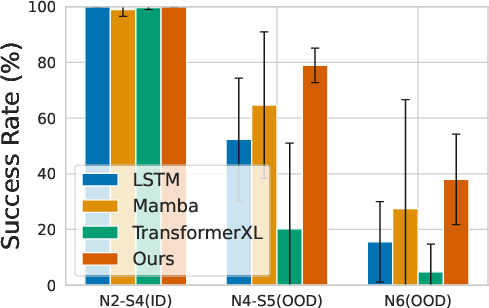
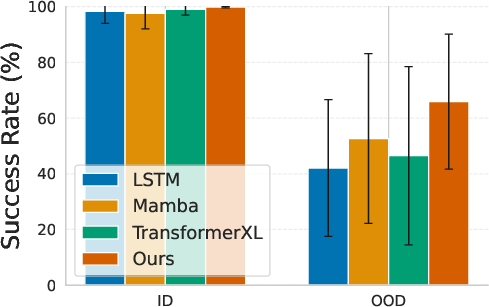
Figure 5: FSRM matches or exceeds baseline success rates on all MiniGrid RL tasks, demonstrating robust sequence modeling for policy learning.
Visualization of the latent state’s trajectory (via PCA) and the associated energy traces show that structurally meaningful event clusters and “frustration signals” emerge unsupervised, mapping to semantically important actions such as key pickups or door opening.

Figure 6: Latent state trajectories cluster episode-defining events (e.g., key pickup, door open), reflecting unsupervised structure formation.
Key Findings and Claims
- FSRM achieves strong systematic generalization and length extrapolation on hierarchical symbolic tasks (Dyck), maintaining high accuracy up to 10,000× the context length seen in training and outperforming frontier LLMs even when the LLMs are explicitly prompted with the ground-truth algorithm.
- Latent recurrence with weight sharing is crucial: OOD generalization degrades significantly if recurrence in the fast loop is replaced by a stack of unshared layers with equivalent depth.
- Latent structure is self-organizing, interpretable, and robust: The architecture induces energy minima and manifold-structured state-space trajectories aligned with logical task structure, observable across algorithmic reasoning and RL domains.
- Practical cost: FSRM incurs higher inference compute proportional to t9 (number of latent recurrences per observation), but this is partly a framework limitation—better kernel-level parallelization may alleviate some of the overhead.
Theoretical and Practical Implications
From a theoretical perspective, FSRM supports the hypothesis that separating observation and internal reasoning dynamics, and updating latent representations recurrently at a higher frequency than external input, enables neural models to consolidate and retain task-relevant information across long horizons. This supports more faithful simulation of event and state abstraction, as in human working memory architectures.
Practically, the architecture's robust OOD performance in both algorithmic and RL tasks, and its immunity to context size, make it a promising approach for sequence modeling applications where historic context must be both efficiently summarized and not forgotten—potentially including program execution, planning, temporal abstraction in policy learning, and compositional reasoning. The compression of arbitrarily long sequence history into fixed-size latents offers tractable paths to memory-efficient "long-context" AI.
Limitations and Future Perspectives
The approach has clear limitations: evaluation is constrained to synthetic/small-scale domains; inference speed is lower than SSMs or highly-optimized LLMs due to nested recurrence (which might be mitigated by recursion-friendly parallelization). Gradient instability stemming from repeated layer/weight reuse remains an open challenge, as with traditional RNNs.
As a future direction, scalability to more complex modalities—language, video, or real-world robotics—remains to be validated. Innovations in architectural design, initialization schemes, and training algorithms (e.g., parallel RNNs or equilibrium models) are likely required to stabilize and accelerate recurrent, coupled fast-slow sequence models.
Conclusion
FSRM contributes a novel computational paradigm for sequence modeling under long-horizon, open-ended conditions by coupling fast latent recurrence with slower observational dynamics. The architecture substantially improves generalization, extrapolation, and interpretability in tasks demanding durable memory and dynamic abstraction, outperforming current SSMs, LSTMs, and Transformers in both OOD and long-sequence regimes.
The results establish coupled fast-slow latent recurrence as a robust mechanism for long-horizon sequential inference and open several avenues for neural architectures that more closely mimic human-like state tracking and memory. Further exploration in real-world settings and efficiency optimization will determine the model’s practical adoption in next-generation AI systems.

