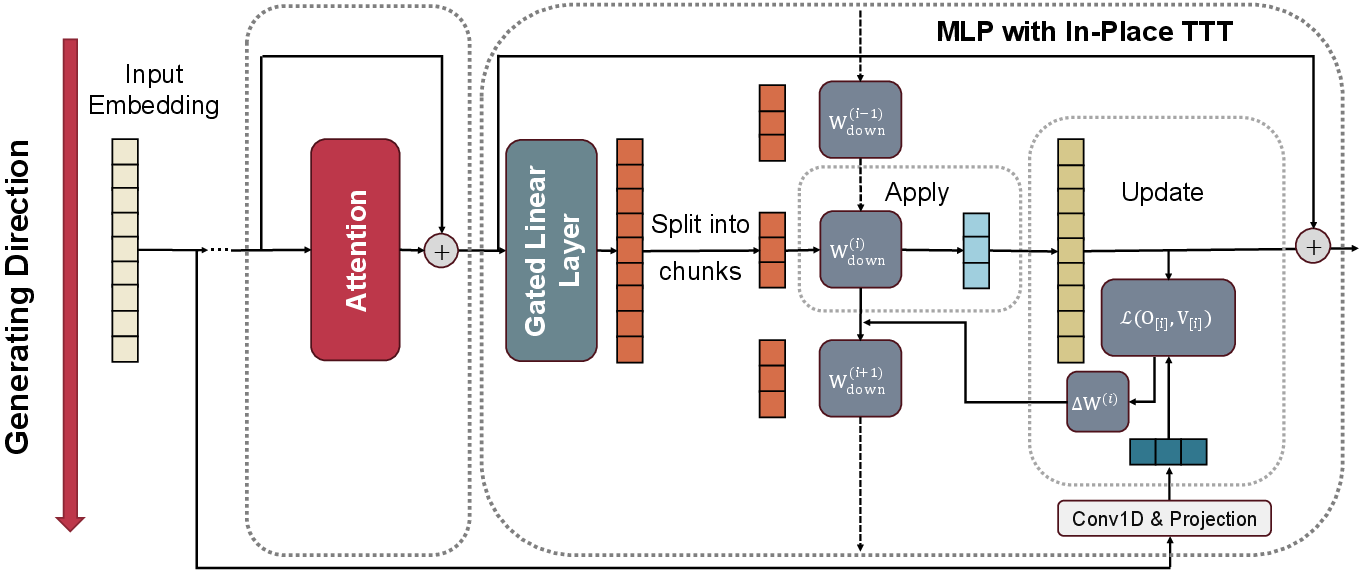
In-Place Test-Time Training
Abstract: The static train then deploy" paradigm fundamentally limits LLMs from dynamically adapting their weights in response to continuous streams of new information inherent in real-world tasks. Test-Time Training (TTT) offers a compelling alternative by updating a subset of model parameters (fast weights) at inference time, yet its potential in the current LLM ecosystem is hindered by critical barriers including architectural incompatibility, computational inefficiency and misaligned fast weight objectives for language modeling. In this work, we introduce In-Place Test-Time Training (In-Place TTT), a framework that seamlessly endows LLMs with Test-Time Training ability. In-Place TTT treats the final projection matrix of the ubiquitous MLP blocks as its adaptable fast weights, enabling adrop-in" enhancement for LLMs without costly retraining from scratch. Furthermore, we replace TTT's generic reconstruction objective with a tailored, theoretically-grounded objective explicitly aligned with the Next-Token-Prediction task governing autoregressive language modeling. This principled objective, combined with an efficient chunk-wise update mechanism, results in a highly scalable algorithm compatible with context parallelism. Extensive experiments validate our framework's effectiveness: as an in-place enhancement, it enables a 4B-parameter model to achieve superior performance on tasks with contexts up to 128k, and when pretrained from scratch, it consistently outperforms competitive TTT-related approaches. Ablation study results further provide deeper insights on our design choices. Collectively, our results establish In-Place TTT as a promising step towards a paradigm of continual learning in LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a way to make LLMs learn and adapt while they are being used, instead of only learning before they’re deployed. The method is called “In-Place Test-Time Training” (In-Place TTT). Think of it like giving an AI a small, quick-to-update notepad it can write on as it reads, so it can remember helpful details from the current text, without rewriting its whole brain.
What problem are they trying to solve?
Most LLMs follow “train then deploy”: they study a huge amount of data once, then their memory (their “weights”) stays fixed. That makes them good at general knowledge—but not as good at:
- Adapting to new or changing information in long documents
- Keeping track of very long contexts (like reading a 100,000-word book and remembering earlier parts)
- Learning from the current task as it goes, like a person would
Some prior methods tried to fix this by adding special layers that update during use, but those often require rebuilding and retraining the whole model, run slowly, or don’t focus on what LLMs actually need to do—predict the next word.
How does their method work?
Here’s the idea in everyday terms:
- Slow memory vs. fast memory:
- “Slow weights” are the model’s long-term memory learned during pretraining.
- “Fast weights” are a small set of parameters the model can quickly update while it’s reading, like a whiteboard for short-term notes.
- Where do the fast weights live?
- Instead of adding a new fancy module, they reuse something every Transformer already has: the MLP block (a mini calculator inside each layer).
- They keep most of the MLP the same and only allow the final “down projection” (think: the last little mixer) to update during use. This makes it a “drop-in” upgrade—no redesign, no retraining from scratch.
- How does it update while reading?
- The model reads the text in chunks (like pages), not one word at a time. After each chunk, it:
- 1) Uses the current fast weights to process the chunk (apply).
- 2) Updates the fast weights based on what it just read (update).
- This chunk-by-chunk approach runs well on modern hardware (GPUs), because parts can be processed in parallel—like splitting a book into sections for different workers and then combining notes.
- What does the model try to learn during updates?
- Instead of a generic “reconstruct what you just saw” target, they align the updates with what LLMs actually do: Next-Token Prediction.
- In simple terms: while reading, the fast weights learn information that helps guess the next words. They even design the update so it can look slightly ahead within each chunk to create a training target that’s more predictive. This is done with a simple 1D convolution over token embeddings (you can think of it as a tiny filter that summarizes nearby future tokens to create a better teaching signal).
- Is it still efficient and correct?
- Yes. The updates are designed so you can process chunks in parallel and then combine the updates using a fast “prefix sum” (like adding up partial notes from earlier chunks). They also reset the fast weights at document boundaries to avoid mixing unrelated texts.
What did they find?
The researchers tested their method in two ways: as a plug-in to existing models and by training new models from scratch. Here’s what they observed.
- As a “drop-in” upgrade to existing models:
- They added In-Place TTT to an open model (Qwen3-4B) and trained it further on longer sequences.
- It performed better on long-context benchmarks (RULER) especially at very long lengths like 64k, 128k, and even 256k tokens (far longer than normal).
- They saw similar improvements when applying it to other models (like LLaMA-3.1-8B and Qwen3-14B), showing it’s general and easy to integrate.
- When training from scratch:
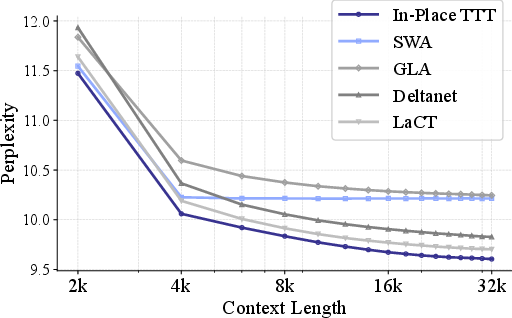
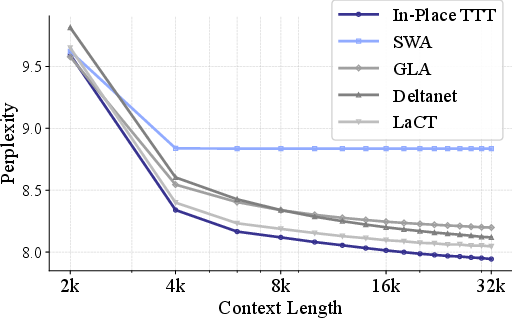
- Compared to other fast-weight or efficient-attention methods, their approach used long contexts more effectively (lower perplexity when more context is available—meaning the model makes better predictions).
- On a 4B-parameter model, it improved both common-sense tasks and long-context tests.
- Why does their learning objective matter?
- They provide a mathematical explanation showing that their “next-token-aligned” objective directly boosts the score for the correct next word, while the older “reconstruct what you just saw” objective doesn’t help as much with prediction. In plain terms: they taught the fast weights to remember what actually helps with the next word, not just to copy the past.
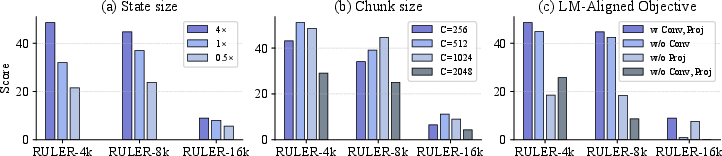
- What design choices mattered?
- Larger “fast memory” (using more layers for updates) helped.
- Medium-to-large chunk sizes (like 512–1024 tokens) worked best—good accuracy and fast speed.
- Both parts of their target design (the small convolution and the projection) were important, especially for very long contexts.
- Is it expensive to run?
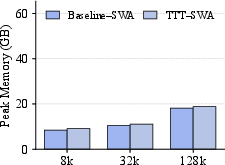
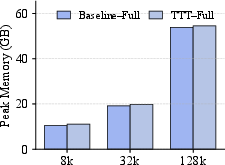
- They report that the added cost in speed and memory is small, so it’s practical.
Why is this important?
- It makes LLMs more “alive” during use:
- The model can adapt as it reads, storing relevant short-term notes, much like you would highlight or jot down reminders while studying.
- It works with existing models:
- Because it only updates a small, already-existing part (the MLP’s final projection), you don’t need to rebuild or retrain the whole model.
- It scales to very long text:
- It helps the model keep useful information over long stretches, which is vital for tasks like reading long documents, following ongoing instructions, or processing streams of information.
- It stays efficient:
- The chunk-wise, parallel-friendly design means it can run fast on modern hardware.
Simple takeaways
- The paper gives LLMs a quick “scratchpad” inside a part they already have, so they can learn from the current text without forgetting what they learned before.
- They align this scratchpad learning with the model’s main goal—predicting the next word—so the updates truly help.
- It works well in practice, improves long-context understanding, and doesn’t slow things down much.
- This moves LLMs closer to continual learning—adapting on the fly as they interact with new information.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-up research.
- Stability and safety of in-place updates
- How to prevent drift, catastrophic interference, or performance collapse when fast weights accumulate many updates within a long document or across heterogeneous segments.
- Mechanisms for gating, normalization, clipping, or regularization of the update rule (e.g., per-layer norms, trust-region constraints) are not explored.
- Forgetting and memory management
- The only forgetting mechanism is a hard reset at document boundaries; no study of continuous decay, recency-weighting, or eviction policies within long streams.
- Policies for persistence across sessions (what to retain, for how long, and how to compress) are not specified.
- Adversarial and privacy risks
- No analysis of adversarial poisoning or prompt injection that could corrupt fast weights at test time.
- Absence of mechanisms for privacy-preserving updates, auditability, or certified erasure of sensitive content stored in fast weights.
- Learning objective design space
- The LM-aligned target uses a Conv1D over embeddings; the kernel width, shape, and dynamic weighting of future tokens are not systematically studied (beyond a coarse ablation).
- Alternatives to the inner-product loss (e.g., contrastive, InfoNCE, cross-entropy with teacher signals, multi-task targets) and their impact on predictive utility are not evaluated.
- Using deeper hidden states (vs. input embeddings) as targets for richer semantics is not explored.
- Optimizer and scheduling choices
- Only a simple one-step gradient update is considered; no comparison with alternative optimizers (e.g., Adam, momentum, second-order approximations), adaptive learning rates, or per-layer schedules.
- Sensitivity to learning-rate magnitude, normalization of Z/V, and update frequency is not characterized.
- Placement and parameterization of fast weights
- Fast weights are limited to MLP W_down; the trade-offs of adapting other parameters (e.g., attention projections, residual adapters, low-rank updates, or selective layers) remain unexplored.
- Layer selection strategies (early vs. middle vs. late layers; contiguous vs. sparse selection) beyond counting “number of layers” are not analyzed.
- Theoretical coverage and robustness
- Theory is confined to a single-block induction-head setting with strong assumptions (orthogonal embeddings, alignment); extension to multi-layer, multi-head Transformers with realistic correlations is open.
- No capacity analysis of W_down as a memory (interference, overwriting, recall accuracy vs. state size) or convergence/stability guarantees under repeated updates.
- Effects of chunk-wise updates and multi-token targets on theoretical properties are not treated.
- Chunking mechanics and boundary effects
- Only non-overlapping chunks are considered; the impact of overlapping or adaptive chunking on performance/latency remains unknown.
- Boundary truncation under causal padding (targets near chunk ends) and its effect on long-range credit assignment are not quantified.
- Decoding-time behavior
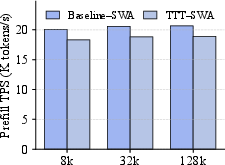
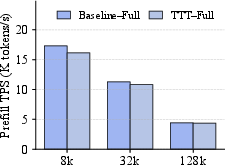
- Evaluation emphasizes prefill; latency/throughput impact during autoregressive decoding (token-by-token) and interaction with KV-cache reuse are not reported.
- Compatibility with decoding strategies (beam search, speculative decoding, streaming generation) is not assessed.
- Scalability and systems aspects
- Results are limited to up to 14B (drop-in) and 4B (from-scratch) models; behavior at 70B+ and ultra-long contexts (≥1M tokens) is unknown.
- Numerical stability and deterministic equivalence of prefix-scan updates across many devices, mixed precision (BF16/FP8), and large context-parallel world sizes are not examined.
- Quantization-aware deployment (INT8/4 weights and activations) with in-place updates is not addressed.
- Interactions with other long-context methods
- Synergy/conflicts with attention variants (MQA/GQA, FlashAttention-3, sparse patterns), state-space models (e.g., Mamba), or memory-augmented models are not empirically studied.
- Integration with retrieval-augmented generation (RAG) and whether fast weights complement or obviate retrieval remains open.
- Generalization breadth
- Limited downstream coverage: primarily RULER and a few commonsense tasks; broader long-context suites (e.g., LONG-ARENA, SCROLLS, GovReport, NarrativeQA, NeedleBench) and real-world workflows are missing.
- Domain and language robustness (code, math, scientific text, multilingual settings) is untested.
- Instruction tuning and alignment
- Effects on instruction-tuned/RLHF models (capability drift, safety guardrails, refusal behavior) are not measured.
- Mitigations if test-time adaptation degrades alignment or safety are unspecified.
- Hyperparameter robustness and auto-tuning
- No systematic sensitivity analysis for chunk size, number/location of adapted layers, conv kernel width, learning rate, or reset frequency across tasks and domains.
- Procedures for automatic hyperparameter selection under hardware and latency constraints are not provided.
- Long-horizon continual learning scenarios
- The work resets state at document boundaries; realistic continuous streams without clear boundaries (e.g., session-based assistants, evolving projects) are not evaluated.
- Metrics capturing continual improvement vs. forgetting over multi-session timelines are absent.
- Failure modes and calibration
- No study of when In-Place TTT harms performance (spurious correlations, noisy contexts), nor of probability calibration and hallucination propensity after adaptation.
- Energy and cost analysis
- Although prefill overhead is “negligible” for reported settings, there is no end-to-end cost/energy analysis at scale, including communication overheads of prefix-scan and storage of per-layer updates.
- Training–inference mismatch
- “Drop-in” benefits are demonstrated after continual training; zero-shot deployment without any additional training is not evaluated.
- Meta-training to explicitly shape slow weights for better test-time adaptation (outer-loop optimization) is not investigated.
Practical Applications
Immediate Applications
Below are concrete, near-term use cases that can be deployed using the paper’s “drop-in” In-Place TTT design (adapting the MLP “W_down” at inference with chunk-wise updates and a Next-Token-Prediction–aligned objective). Each item lists sector(s), potential tools/products/workflows, and key assumptions/dependencies.
- [Industry] Long-document and contract analytics copilots
- Description: More accurate question answering, summarization, and cross-reference tracking across 32k–128k-token documents (e.g., contracts, technical manuals, SOPs), with improved extrapolation to even longer files.
- Sectors: Legal, enterprise software, professional services.
- Tools/Workflows: “Session Memory Adapter” that updates
W_downper document chunk; document-boundary reset; context-parallel inference for multi-GPU throughput. - Assumptions/Dependencies: Access to the model’s MLP layers to enable in-place updates; inference stack supporting chunk-wise prefix-scan; careful learning-rate/chunk-size tuning.
- [Industry] Customer-support session copilots
- Description: Adapt per conversation to evolving context across long chat sessions (tickets, CRM notes, historical threads), without retraining.
- Sectors: Customer support, CX platforms, CRM vendors.
- Tools/Workflows: Middleware that maintains per-session fast weights; automatic reset at session end; dashboards to visualize session-state drift.
- Assumptions/Dependencies: Deterministic reset to avoid cross-customer leakage; safety review of session-adapted behavior.
- [Industry] Codebase-aware AI assistants
- Description: On-the-fly adaptation to large repositories (monorepos, multi-service code) for more accurate navigation, test generation, and refactoring suggestions as the assistant reads files progressively.
- Sectors: Software/DevTools.
- Tools/Workflows: IDE plugin that updates fast weights while streaming repo content; chunk sizes 512–1024 for throughput; “Fast-Weight Reset Manager” on branch/file boundaries.
- Assumptions/Dependencies: Model access at inference; repo privacy controls; CI/CD integration to clear ephemeral state.
- [Industry] Log and telemetry analysis
- Description: Stream-adaptive anomaly detection, root-cause narratives, and timeline reconstruction over very long log sequences without exploding context costs.
- Sectors: Observability, cybersecurity, SRE.
- Tools/Workflows: “Streaming TTT Engine” that updates per log window; summaries exported to SIEM/SOC tools.
- Assumptions/Dependencies: Stable chunked ingestion; careful boundary handling across services; monitoring for drift.
- [Industry] Meeting, email, and knowledge workflow assistants
- Description: Session-level memory for long meetings and multi-day email threads; better recall of decisions, action items, and references without storing massive contexts.
- Sectors: Productivity, collaboration.
- Tools/Workflows: Calendar/email plugins that apply-then-update per chunk; per-thread state; optional export of distilled notes.
- Assumptions/Dependencies: Privacy-preserving in-memory fast weights; bounded lifetime of session memory.
- [Healthcare] Longitudinal EHR and clinical note summarization
- Description: Improved synthesis across long patient histories, imaging reports, and labs within a single session.
- Sectors: Healthcare providers, health IT.
- Tools/Workflows: Clinical summarization pipelines that adapt weights per patient timeline; reset at patient boundary.
- Assumptions/Dependencies: Strict PHI isolation; auditable resets; regulatory review for adaptive inference.
- [Finance] Research and compliance reviews over long filings
- Description: Higher-accuracy tracing of entities and obligations across 10-Ks, prospectuses, and regulatory rules spanning large contexts.
- Sectors: Asset management, banking, regtech.
- Tools/Workflows: “Long-Filing Analyzer” with In-Place TTT; cross-document threading through controlled resets.
- Assumptions/Dependencies: Legal/compliance sign-off; transparent logs of adaptation steps for audit.
- [Academia] Long-context literature review and systematic evidence synthesis
- Description: Better extraction of methods/results across many papers or very long textbooks/monographs in one session.
- Sectors: Research, education.
- Tools/Workflows: Paper-ingestion scripts that update fast weights per chunk; export of distilled, citation-linked notes.
- Assumptions/Dependencies: Reproducibility via logged seeds/hyperparameters; reset between corpora.
- [Academia/Industry] Cheaper evaluation and pretraining research at mid-scale
- Description: Replace specialized TTT layers with in-place MLP adaptation to study long-context use without retraining from scratch.
- Sectors: ML research, foundation model teams.
- Tools/Workflows: PyTorch/JAX runtime patch that toggles fast-weight updates on existing checkpoints; ablation suite for state size/chunk size.
- Assumptions/Dependencies: Open weights or internal access; support for context-parallel prefix-scan.
- [Daily life] Personal reading assistants for long PDFs
- Description: Adaptive comprehension and Q&A over long books/manuals during a single reading session, with automatic state reset on new documents.
- Sectors: Consumer apps.
- Tools/Workflows: Mobile/desktop reader app with “session memory mode”; chunked ingestion (512–1024) for efficiency.
- Assumptions/Dependencies: On-device or private inference; clear UX for session scope and resets.
Long-Term Applications
These applications require further research, scaling, or productization (e.g., broader safety guarantees, objective generalization beyond pure language modeling, or tighter systems integration).
- [Industry] Continual-learning enterprise copilots with stable, regulated memory
- Description: Multi-session, department-level “memories” that persist across days/weeks (beyond session-level), with governance, auditing, and retention policies.
- Sectors: Enterprise software, knowledge management.
- Tools/Workflows: Memory tiers (ephemeral session, short-term project, long-term org); policy-driven reset/decay; compliance dashboards.
- Assumptions/Dependencies: Robust catastrophe-avoidance (no stale bias accumulation), strong auditability of weight deltas, and formal privacy guarantees.
- [Industry/Robotics] On-device, low-latency adaptive instruction following
- Description: Edge assistants that adapt to user/task idiosyncrasies in real time (e.g., robots or wearables processing continuous instructions).
- Sectors: Robotics, IoT, AR.
- Tools/Workflows: Hardware-aware kernels exploiting prefix-scan; mixed-precision updates; battery-conscious chunk scheduling.
- Assumptions/Dependencies: Efficient on-device inference; safe adaptation under distribution shift; robustness under resource constraints.
- [Healthcare] Adaptive clinical decision support with multi-session personalization
- Description: Patient- or clinician-aware assistants that carry forward relevant context over multiple encounters (e.g., workflows, terminology).
- Sectors: Healthcare IT, digital health.
- Tools/Workflows: Federated or enclave-based fast-weight states; controlled decay and consent-aware persistence.
- Assumptions/Dependencies: Regulatory approval; rigorous safety validation to prevent harmful drift; clear consent/audit trails.
- [Finance] Online market narratives and risk monitoring with streaming adaptation
- Description: Continuous synthesis across news, filings, and time-series for risk signals, with adaptive focus as conditions change.
- Sectors: Trading, risk, compliance.
- Tools/Workflows: Multi-modal TTT (text + time-series/features); hierarchical chunking; alerting pipelines.
- Assumptions/Dependencies: Extension of LM-aligned objective beyond pure NTP; robust guardrails against spurious correlations.
- [Policy/Government] Legislative and regulatory drafting assistants for mega-documents
- Description: Adaptive, clause-aware assistants able to track references and implications across very long bills/codes and generate impact analyses.
- Sectors: Public sector, think tanks.
- Tools/Workflows: Secure, air-gapped inference with session-scoped weights; citation-grounded generation; lineage tracking of updates.
- Assumptions/Dependencies: Strict data governance; verifiable provenance; reproducible “frozen” outputs for records.
- [Academia] Test-time training for multi-modal and task-general LMs
- Description: Generalizing the LM-aligned objective to program synthesis, tool-use, and multi-modal tokens (vision, audio).
- Sectors: ML research, AI labs.
- Tools/Workflows: Objective libraries that plug in task-aligned targets (beyond reconstruction); per-modality chunk schedulers.
- Assumptions/Dependencies: New theory/benchmarks for non-text modalities; careful causal padding across modalities.
- [Security] Adaptive threat-hunting copilots over streaming data lakes
- Description: Long-horizon pattern detection across logs, emails, binaries; on-the-fly focus on emerging IOCs/TTPs.
- Sectors: Cybersecurity.
- Tools/Workflows: Secure enclaves for weight updates; joint use with RAG over threat intel; drift monitoring and rollback.
- Assumptions/Dependencies: Strong adversarial robustness; auditable adaptation; sandboxed execution.
- [Ecosystem] Inference platforms with first-class “fast-weight adapters”
- Description: Managed services exposing session-adaptive inference as a primitive (fast-weight state as an API resource).
- Sectors: Cloud/ML platforms.
- Tools/Workflows: APIs to create/update/reset session state; autoscaling of context-parallel kernels; cost controls via chunk tuning.
- Assumptions/Dependencies: Model vendor support for exposing MLP internals; standardized logging/metrics for adaptation quality.
Cross-cutting assumptions and dependencies
- Model access: Must be able to modify the MLP “W_down” matrix at inference; closed models may not allow this.
- Runtime support: Context-parallel prefix-scan and chunk-wise updates (ideally C=512–1024) in the inference stack.
- Objective alignment: The proposed LM-aligned target is tailored to NTP; for other tasks/modalities, targets and padding must be re-designed.
- Safety and governance: Clear session boundaries and resets to prevent context leakage; monitoring for drift and unexpected behavior.
- Performance tuning: Learning rate/state size/chunk size materially affect stability and gains; needs per-model/setting calibration.
- Cost/latency: While overhead is small in the paper’s results, real deployments must validate throughput/memory under production loads and hardware.
Glossary
- 1D Convolution: A convolutional operation applied along the sequence dimension to mix nearby token features. "is the 1D Convolution operator"
- Ablation studies: Systematic experiments that remove or vary components to evaluate their impact on performance. "Ablation study results further provide deeper insights on our design choices."
- Architectural incompatibility: A mismatch with standard LLM architectures that prevents seamless integration or warm-starting from pretrained checkpoints. "which resolves architectural incompatibility via an in-place design that repurposes existing MLP blocks"
- Approximate Orthogonality of Embeddings: An assumption that different token embeddings are nearly orthogonal, used to simplify theoretical analysis. "Approximate Orthogonality of Embeddings: For any two distinct tokens"
- Associative nature: The property that the grouping of operations does not affect the result, enabling parallel prefix computations. "The associative nature of our update rule"
- Autoregressive language modeling: Modeling where each token is predicted based on preceding context in a left-to-right manner. "aligned with the Next-Token-Prediction task governing autoregressive language modeling."
- Causal padding: Padding applied to ensure no future information leaks into convolutions or updates, preserving causality. "we apply causal padding to the 1D convolution"
- Causal semantics: The requirement that model computations use only past information, not future tokens. "preserving the strict causal semantics of an auto-regressive update."
- Chunk-wise update mechanism: Updating model parameters in blocks (chunks) of tokens to improve efficiency while maintaining causality. "an efficient chunk-wise update mechanism"
- Context leakage: Unintended sharing of information across separate sequences or documents. "to prevent context leakage across independent sequences."
- Context Parallelism (CP): A parallelism strategy that partitions long sequences into chunks processed concurrently with prefix-scan style aggregation. "fully compatible with Context Parallelism (CP)"
- Context window: The maximum sequence length a model can effectively process or attend to. "its effectiveness is tethered to the model's context window,"
- Continual learning: The ability of a system to learn continuously from a stream of data without separate training phases. "a promising step towards a paradigm of continual learning in LLMs."
- Delta rule: A simple gradient-like update rule widely used in linear attention and state-space models to enable efficient learning. "the delta rule has emerged as a popular design choice"
- Drop-in enhancement: A module or method that can be integrated into existing models without architectural changes or costly retraining. "enabling a 'drop-in' enhancement for LLMs"
- Fast weights: A small, rapidly updated subset of parameters that act as a dynamic memory at inference time. "called fast weights"
- Gated Linear Attention (GLA): A linear-time attention variant that uses gating to control information flow. "Gated Linear Attention (GLA)"
- Gated MLP: A feed-forward network architecture with gating (e.g., GLU/SiLU gates) that modulates activations. "the widely used gated MLP architecture"
- Induction head: An attention mechanism pattern that learns to copy or continue sequences by matching repeated keys. "the canonical induction head setting"
- Key-Query Alignment: An assumption that internal representations associated with matching tokens (key and query) are aligned. "Key-Query Alignment: The intermediate activations"
- Key-value memory: A memory-like mechanism that associates keys with values, enabling retrieval based on matching keys. "can also be viewed as a form of key-value memory"
- Language Modeling-Aligned (LM-Aligned) objective: A learning objective tailored to improve next-token prediction rather than generic reconstruction. "we introduce our Language Modeling-Aligned objective"
- Linear attention: An attention mechanism with linear time and memory complexity achieved via kernelization or recurrence. "such as linear attention"
- Multi-Token Prediction: Training or inference that predicts multiple future tokens jointly to capture richer predictive signals. "Multi-Token Prediction in advanced LLMs"
- Next-Token Prediction (NTP): The standard autoregressive language modeling objective of predicting the immediate next token. "aligned with the Next-Token Prediction (NTP) goal"
- Parallel scan algorithm: A parallel algorithm (e.g., prefix scan) that aggregates sequential updates across chunks efficiently. "relying on a parallel scan algorithm"
- Prefix sum: The cumulative sum of a sequence of updates, often computed in parallel to aggregate chunk-wise changes. "a single prefix sum"
- Rotary Position Embeddings (RoPE): A positional encoding technique that rotates embeddings to encode relative positions. "We adapt the model's Rotary Position Embeddings using YaRN"
- Sliding Window Perplexity: A diagnostic that measures perplexity on a fixed block while varying preceding context length to assess context usage. "Sliding Window Perplexity"
- Sliding-Window Attention (SWA): An attention pattern that restricts attention to a fixed-size local window for efficiency. "standard Transformer with sliding window attention (SWA)"
- State-Space Models (SSMs): Sequence models that maintain a compact latent state evolving over time, enabling linear-time processing. "State-Space Models (SSMs)"
- Test-Time Training (TTT): Updating a subset of model parameters during inference to adapt to new inputs on the fly. "Test-Time Training (TTT) offers a compelling alternative"
- Warm start: Initializing training or adaptation from a pretrained checkpoint rather than random initialization. "it can warm start from a pretrained checkpoint."
- YaRN: A method for extending RoPE-based position encodings to longer contexts via scaling and interpolation. "We adapt the model's Rotary Position Embeddings using YaRN"
Collections
Sign up for free to add this paper to one or more collections.