Fast-weight Product Key Memory
Abstract: Sequence modeling layers in modern LLMs typically face a trade-off between storage capacity and computational efficiency. While Softmax attention offers unbounded storage at prohibitive quadratic costs, linear variants provide efficiency but suffer from limited, fixed-size storage. We propose Fast-weight Product Key Memory (FwPKM), a novel architecture that resolves this tension by transforming the sparse Product Key Memory (PKM) from a static module into a dynamic, "fast-weight" episodic memory. Unlike PKM, FwPKM updates its parameters dynamically at both training and inference time via local chunk-level gradient descent, allowing the model to rapidly memorize and retrieve new key-value pairs from input sequences. Experiments reveal that FwPKM functions as an effective episodic memory that complements the semantic memory of standard modules, yielding significant perplexity reductions on long-context datasets. Notably, in Needle in a Haystack evaluations, FwPKM generalizes to 128K-token contexts despite being trained on only 4K-token sequences.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces a new way for LLMs (like chatbots) to remember things they just read, quickly and efficiently. It’s called Fast-weight Product Key Memory (FwPKM). The goal is to give models a “short-term memory” they can update on the fly while reading long documents, without using too much computing power.
Imagine a model reading a book. Standard attention can remember everything but gets very slow as the book gets longer. Faster methods are quick but can only remember a fixed amount. FwPKM tries to get the best of both worlds: big storage with low cost, plus the ability to write new memories while reading.
Key questions the paper asks
Here are the main questions the paper explores:
- How can a model remember many details from long texts without becoming slow?
- Can we give the model a memory that it can update during reading (not just during training)?
- Does this new memory help the model find important information in very long texts?
- How does this memory work together with the model’s regular “knowledge” learned during training?
How FwPKM works (in everyday terms)
To explain the method, think of a model as a student with two kinds of memory:
- Slow weights: like long-term knowledge learned from textbooks. These don’t change while the student is taking a test.
- Fast weights: like sticky notes the student writes while reading the test questions. These can be updated immediately.
FwPKM is a fast, sparse memory built on top of a method called Product Key Memory (PKM). Here’s how it works:
What is PKM?
- PKM is like a giant locker room of “memory slots.”
- Each slot has a “key” (like a label) and a “value” (like a note).
- When the model sees a new piece of text (a “query”), it looks up the most relevant slots, takes their values, and uses them to help predict the next word.
- PKM gets speed by splitting the keys into two halves and searching each half separately, then combining the results. It’s like having two smaller address books instead of one giant one.
What makes FwPKM different?
- Standard PKM only learns during training (slow weights). FwPKM can update during reading and answering (fast weights).
- As the model reads a chunk of text, it writes fresh key-value pairs into memory so it can retrieve them later. This is like taking notes while you read.
- It uses a simple update rule (a form of gradient descent with mean squared error) that basically says: “Make the memory’s current output match the target value.” With the right settings, one step can “rewrite” a slot to exactly store what’s needed.
Extra design choices that help
- Addressing loss (marginal entropy): This encourages the model to use many different slots, not just a few favorites. Think of it as spreading notes across many lockers so nothing gets too crowded.
- IDW scoring (Inverse Distance Weighting): Instead of just picking keys with the biggest dot product, it prefers keys that are “close” to the query in space. This helps organize keys like cluster centers for common patterns.
- Lookahead values: The model pairs each current “key” with the next token’s “value.” That helps predict what’s coming next.
- Normalization: It scales target values so updates are stable.
- Gating: A switch that decides how much to rely on FwPKM versus the model’s regular output. If the current token really needs recent memory, the gate turns up FwPKM’s contribution.
A helpful analogy for Top-k and product keys
- Top-k: When searching the lockers, the model only opens the top few that look most promising, not all of them.
- Product keys: It finds the top few in two smaller lists first, then combines them to find the best pairs—like looking up a person by first name and last name separately to narrow the search quickly.
What did the experiments show?
Here are the most important results and why they matter:
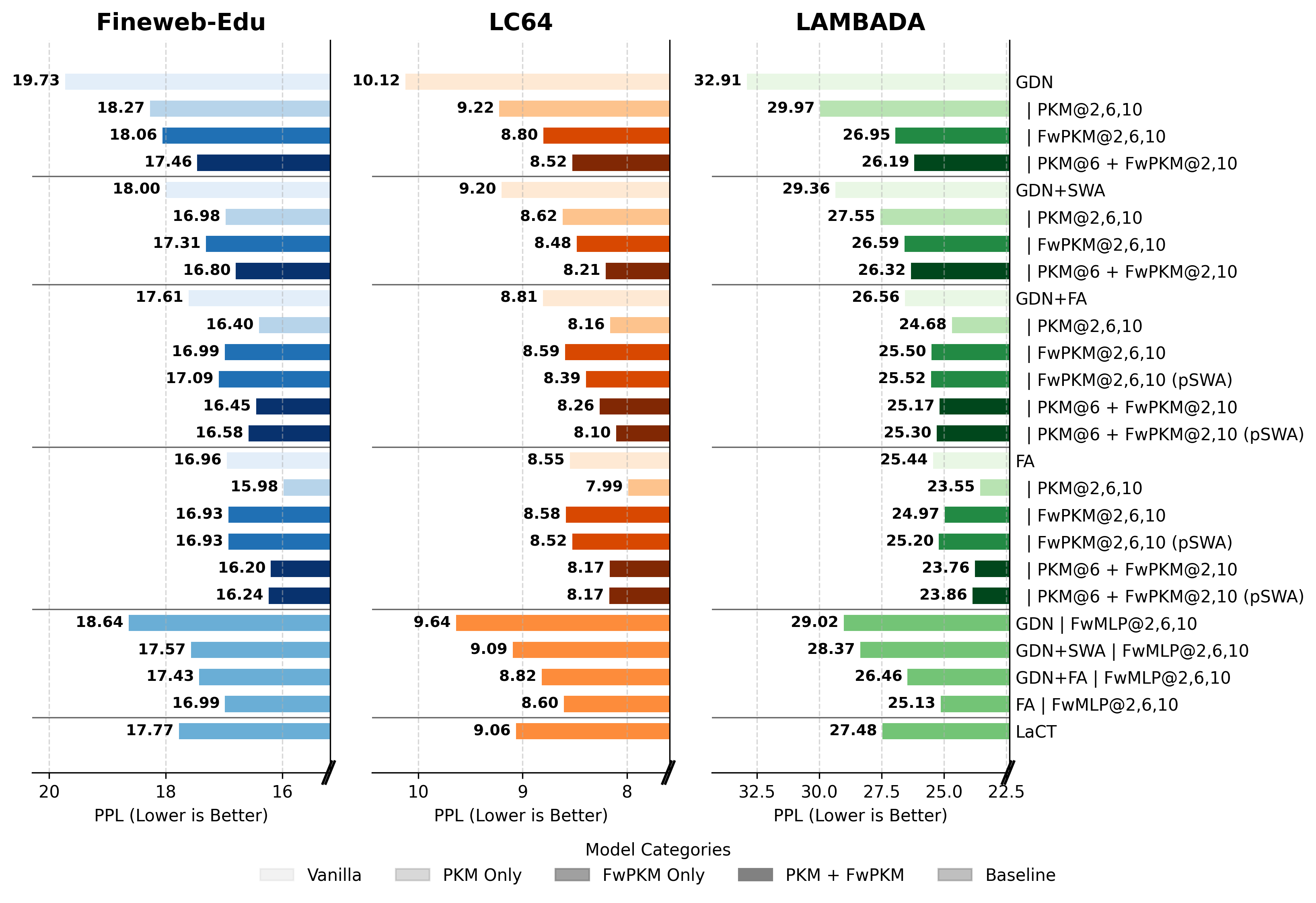
- FwPKM helps a lot on long contexts. On datasets with long documents, models with FwPKM had lower perplexity (meaning they were less “surprised” and made better predictions).
- PKM and FwPKM are complementary. PKM acts like long-term “semantic” memory (general facts), while FwPKM acts like “episodic” memory (specific details from the current reading). Using both improves performance more than either alone.
- If full attention is unlimited, models often ignore FwPKM. When full attention can see everything, the gate shifts away from using FwPKM. But if you limit attention’s reach during training (using a sliding window), the model learns to use FwPKM more.
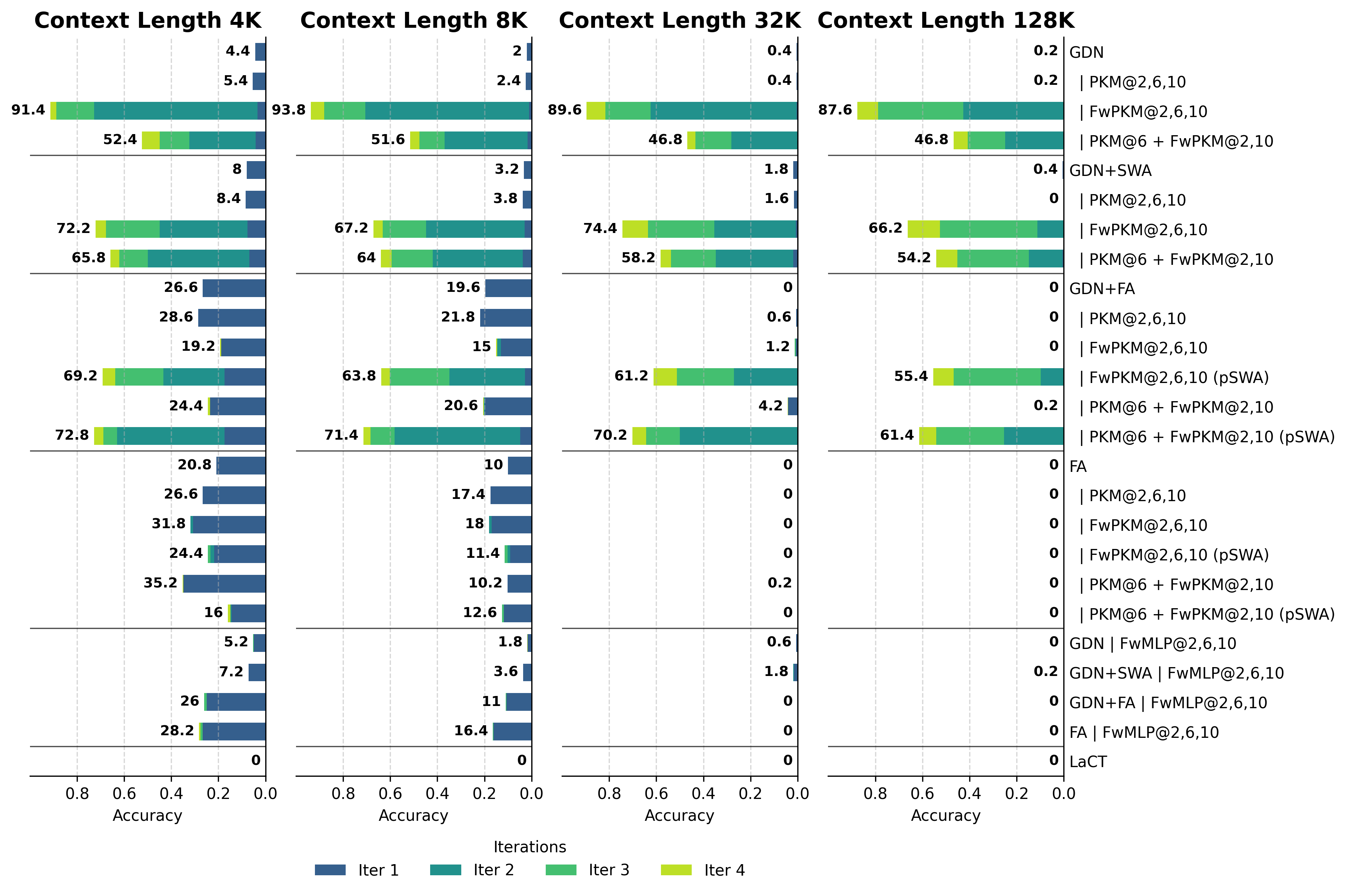
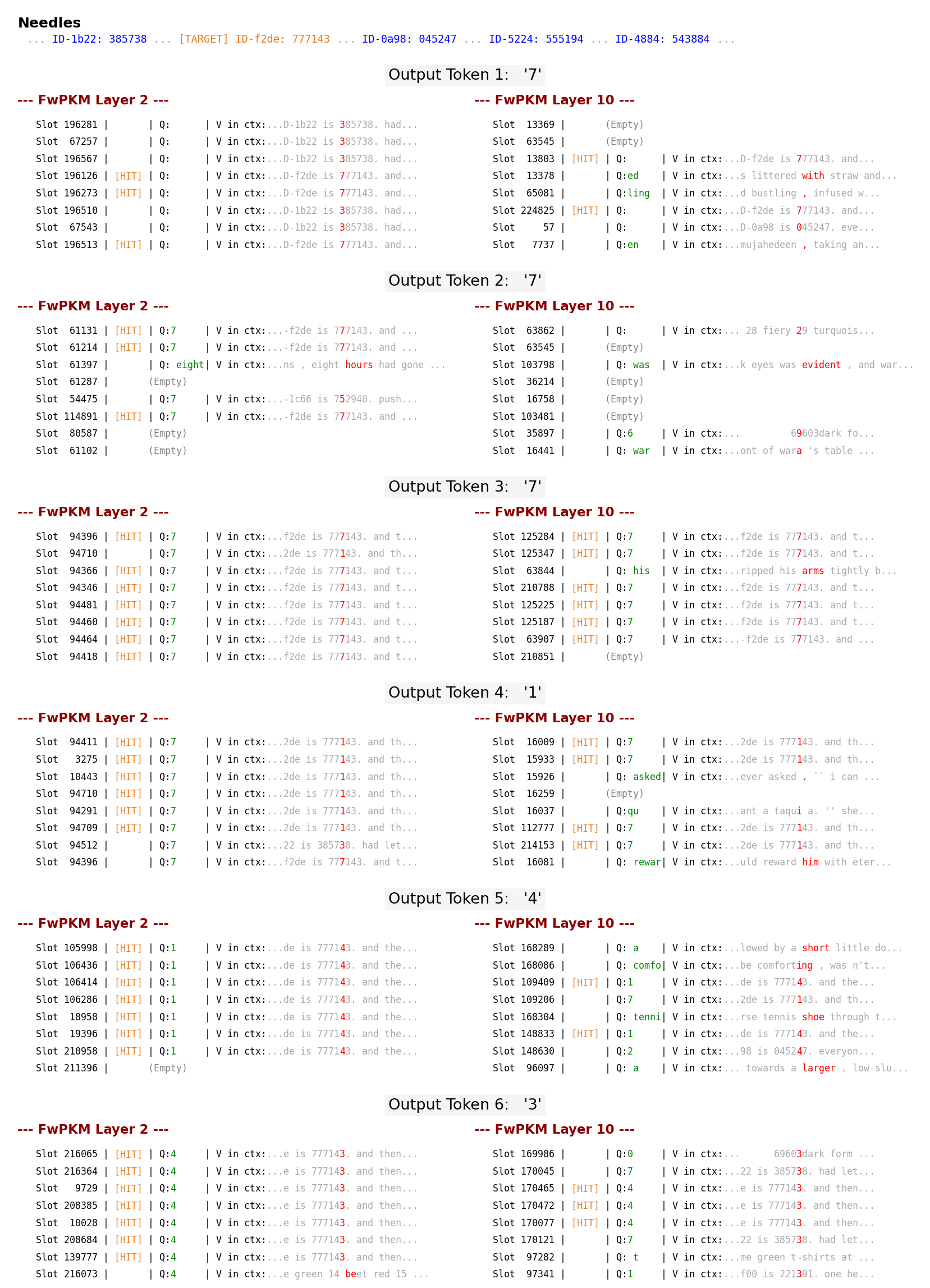
- Needle in a Haystack (NIAH) tests: FwPKM can find small facts buried in huge texts. Even when trained on 4K-token sequences, it successfully retrieves needles in contexts as long as 128K tokens. That means it generalizes far beyond its training length.
- Iterative memorization helps. If the model rereads the same context multiple times (2–4 passes), accuracy jumps a lot. This shows test-time updating is working: each pass sharpens the memory.
- Longer texts need more passes. As context grows from 4K to 128K tokens, more rereads are helpful to ensure the right facts are memorized and retrieved.
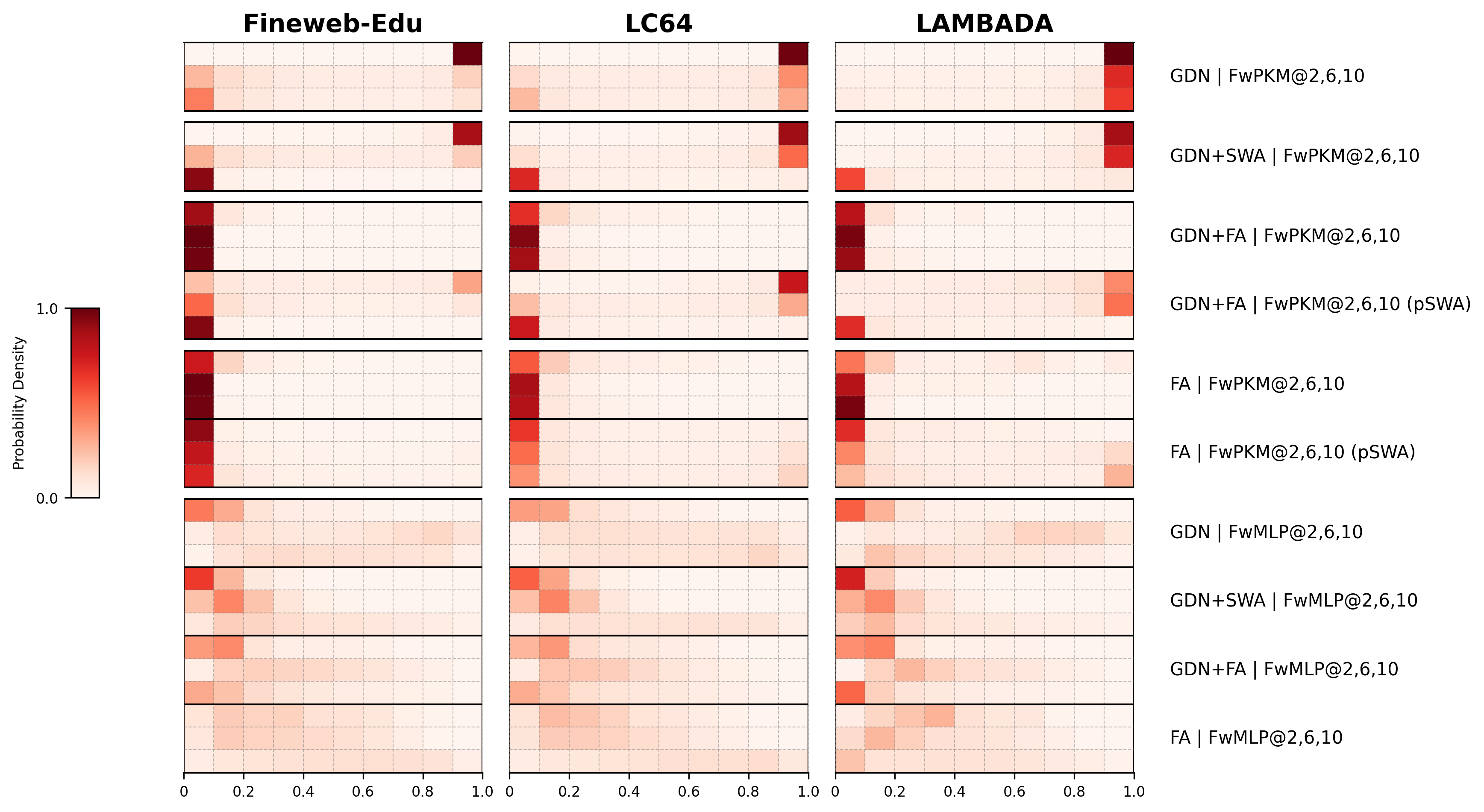
- It’s interpretable. Because memory slots are explicitly written and read, you can inspect which tokens were stored and see whether the model actually retrieved the right ones.
- Cost trade-offs. PKM/FwPKM are light in floating-point operations (FLOPs) but currently slower in practice (FLOPS) due to less mature kernels. Better engineering could make them faster.
Why this matters
- Better long-document reading: Models can remember specific details across thousands of tokens without slowing down too much, which is great for research papers, legal documents, books, or codebases.
- More adaptive agents: Because FwPKM can write memory during inference, it’s useful for personalized assistants that need to remember what you just told them.
- Working together: The paper suggests a future where different memory types are combined—fast episodic memory for current context, slow semantic memory for general knowledge, and attention for fine-grained linking—creating stronger, more flexible LLMs.
- Practical next steps: To make this widely usable, faster implementations of sparse memory updates are needed. There’s also room to improve when and how often memory is updated, and how different memory layers interact.
In short, FwPKM teaches LLMs how to take useful notes while they read, store them efficiently, and use them to answer questions later—even in very long contexts. It complements what the model already knows and makes it much better at handling long, detailed texts.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains uncertain, missing, or unexplored in the paper, framed to guide concrete next steps for future research.
- Fast-weight retention policy is unspecified: when and how to reset, decay, or consolidate FwPKM across documents/sessions to avoid stale information, interference, or privacy leakage.
- No quantitative capacity analysis: how many unique associations can be reliably stored/retrieved as a function of N, k, heads, D, and write frequency; collision rates and effective slot utilization over long runs remain unmeasured.
- Lack of formal interference/forgetting analysis: how concurrent or sequential writes (especially with 1/N_read averaging) degrade previously stored information; trade-offs between write strength and retention.
- Absent theoretical guarantees for “one-step rewriting”: stability, convergence, and error bounds of lr=1.0, 0.5·MSE updates under repeated writes and unbounded target scales (no gradient clipping).
- Key learning driven only by marginal entropy: no retrieval-driven gradients to keys during MSE updates (Top-k is non-differentiable here); unclear if entropy-only addressing optimally aligns key layouts with queries for downstream prediction.
- IDW scoring design space underexplored: sensitivity to ε, dimensionality effects, normalization choices, and comparisons to cosine/temperature-scaled dot-product or learned similarity metrics.
- Top-k/head configuration not systematically explored: performance/usage under multi-head, larger k, adaptive k, or routing constraints; interaction with addressing entropy loss at different sparsity levels.
- Gating behavior lacks principled regularization: how to prevent trivial suppression (as seen with full attention), encourage selective but reliable use, or impose sparsity/entropy constraints on g_t.
- Write arbitration is simplistic: averaging by 1/N_read may blunt important writes; alternative conflict-resolution and write-allocation mechanisms (e.g., priority, reservation, LRU, or competitive learning) are not tested.
- Chunk size/update frequency trade-offs are open: how C and the frequency of fast updates affect compute, stability, and memory fidelity in streaming and batched settings.
- Iterative memorization practicality: NIAH gains rely on multiple passes; strategies to detect when to re-read, amortize the cost, or approximate multi-pass consolidation in real-world latency constraints are not addressed.
- Streaming/online deployment details unclear: with t→t+1 lookahead targets, how to update FwPKM in true streaming where “next” tokens are not yet available; alternatives to lookahead targets at inference time remain unexplored.
- Safety/privacy risks from inference-time writes: how to prevent storing sensitive user data, poisoning, or adversarial imprinting given unbounded targets and no clipping; need for write filters, quotas, or auditing tools.
- Limited evaluation scope: no benchmarks on instruction following, reasoning, code, tool-use, or retrieval-augmented generation to test whether episodic memory improves broader capabilities beyond PPL and NIAH.
- Missing comparisons to strong long-context baselines: no direct head-to-head with SSMs (e.g., Mamba2) or advanced hybrid/landmark attention systems under identical training budgets and parameter counts.
- Parameter-controlled baselines are incomplete: FwPKM adds many parameters; capacity vs. architecture effects are not disentangled against equally parameterized alternatives (e.g., scaled MLP/attention).
- Limited scale study: results on ~112M–520M parameter models; unclear how FwPKM scales to multi-billion-parameter LLMs and whether gains persist or diminish at scale.
- Interaction with full attention is unresolved: with unrestricted FA, FwPKM is ignored; beyond pSWA, what curriculum, scheduling, or architectural constraints elicit complementary use without hurting FA’s strengths?
- Kernel and systems efficiency gap: PKM/FwPKM FLOPs are low but FLOPS and throughput are poor; need specialized kernels for sparse Top-k product-key lookup and in-place fast-weight updates (forward and backward).
- Memory footprint and device placement: how to store and shard large V, K1, K2 banks across GPUs/TPUs, synchronize updates in distributed inference, and manage cache locality are not addressed.
- Fast-weight optimizer space is narrow: only plain GD with lr=1.0; effects of momentum/Adam, weight normalization, second-order updates, or closed-form/least-squares writes (test-time regression) are not explored.
- Local objective choice is limited: only z-scored MSE with t→t+1 pairing is used; contrastive/InfoNCE, multi-step lookahead, prefix-aware targets, or denoising objectives could improve robustness but are untested.
- Retention across documents is not quantified: the paper claims cross-context carry-over but does not measure how long or how reliably memory persists across many chunks/documents without explicit resets.
- Addressing collapse metrics missing: although marginal entropy is introduced, empirical slot-usage distributions, per-slot read/write counts, and entropy trajectories across training are not reported.
- Error diagnostics are anecdotal: interpretability case studies show prefix mismatch errors, but there is no systematic breakdown of failure modes, false positives/negatives, or hit-at-k across layers/lengths.
- Interaction with KV cache and standard attention caches: how FwPKM complements or replaces caches, and whether combined strategies reduce memory or latency, is not evaluated.
- Write-scale and stability: “no gradient clipping” may improve adaptation but risks instability/outliers; quantitative analysis of outlier writes, saturation, or drift is missing.
- Consolidation into slow weights is open: mechanisms to distill or periodically merge episodic fast weights into slow PKM/FFN (nested learning) are suggested but not implemented or evaluated.
- Robustness and OOD generalization: how FwPKM behaves under domain shift, noisy inputs, or adversarial prompts; whether gating correctly suppresses harmful memorization is unknown.
- Hyperparameter sensitivity: lack of ablations for k, √N, D_V, D_K, learning rates for keys vs. values, entropy loss weight, and gating-loss weighting on stability and performance.
- Applicability beyond text: extension to multimodal inputs (vision, audio) and cross-modal episodic bindings is not explored.
- Deployment policies: procedures for memory scoping (per-user, per-session), retention time, export/import across sessions, and compliance auditing are unspecified.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating FwPKM into existing language-model workflows and infrastructure. They leverage FwPKM’s dynamic, chunk-level fast-weight updates, large sparse memory, interpretability, and generalization to long contexts.
- Bold-use-case: Session-ephemeral memory for enterprise assistants (software, enterprise)
- What: Let chatbots/copilots load long documents (policies, specs, runbooks) in a few passes, “write” them into FwPKM, and then answer many queries without re-scanning or re-retrieving the full text.
- Tools/products/workflows:
- “Iterative read” API: a two-stage pipeline (memorize context → answer questions).
- Session state that persists fast weights per conversation; configurable memory reset.
- Gating-aware prompting to encourage FwPKM usage when attention is restricted (pSWA-like training trick).
- Assumptions/dependencies: Needs support for multi-pass reading (latency budget); server must retain fast weights per session; restrict full attention during training or inference to incentivize gating; current kernels for sparse Top-k and IDW are less optimized than attention and may limit throughput.
- Bold-use-case: Long-document QA and summarization (education, media, legal)
- What: Accurate question answering and summarization over 32K–128K-token materials (textbooks, whitepapers, filings) by memorizing in chunks and querying episodic memory.
- Tools/products/workflows:
- Reader mode that runs 2–4 passes on the source to boost NIAH-style retrieval accuracy.
- Memory budget controls (Top-k, chunk size) to trade off latency vs fidelity.
- Assumptions/dependencies: Multi-pass increases latency; performance depends on high gating when attention is limited; trained on 4K contexts but generalizes—verify on target domains.
- Bold-use-case: Codebase-scale copilots (software engineering)
- What: Load large repositories or logs in multiple passes; remember symbols, call graphs, and variable bindings; answer cross-file questions and generate consistent patches.
- Tools/products/workflows:
- “Memory-first” repo ingest step that writes key-value pairs by directory/module.
- On-demand re-memorization of hot modules; value residuals aid generation quality.
- Assumptions/dependencies: Tokenization of code and chunking strategy matter; iterative passes add latency; need session-level fast-weight persistence.
- Bold-use-case: RAG accelerator and cache (software)
- What: Use RAG for first retrieval, then write the fetched passages into FwPKM so subsequent turns don’t re-query the vector DB/search for the same context.
- Tools/products/workflows:
- “Micro-RAG cache” layer: vector DB → FwPKM write → subsequent queries served from fast memory.
- Memory inspector that shows which slots store which passages.
- Assumptions/dependencies: RAG quality still bounds performance; slot allocation must avoid collapse (entropy-based addressing helps); cache invalidation and erasure policies needed.
- Bold-use-case: Meeting/transcript analytics over multi-hour sessions (enterprise productivity)
- What: Summarize, track action items, and answer granular questions across long transcripts without quadratic attention costs.
- Tools/products/workflows:
- Live streaming with periodic chunk updates and lookahead values to improve next-token prediction.
- Iterative post-processing pass to consolidate minutes before Q&A.
- Assumptions/dependencies: Real-time budgets constrain number of passes; microphone/ASR errors can propagate—normalize targets (z-scoring) improves stability.
- Bold-use-case: On-device personal assistants with privacy-preserving session memory (daily life)
- What: Local models memorize long emails, notes, itineraries within a session; avoid cloud storage while enabling strong context recall.
- Tools/products/workflows:
- Mobile/edge deployment with a session fast-weight store and a “wipe memory” UI.
- Configurable gating to avoid writing sensitive tokens.
- Assumptions/dependencies: Edge compute constraints; sparse-kernel efficiency not yet at FlashAttention speed; clear UX for memory control.
- Bold-use-case: Interpretable memory inspection and audit (policy, compliance, safety)
- What: Trace which tokens were written and read from memory to justify an answer (slot-level provenance).
- Tools/products/workflows:
- “Memory Inspector” panel showing Top-k slots, their query/value tokens, and [HIT] markers.
- Compliance logs for regulated settings (finance, healthcare, legal).
- Assumptions/dependencies: Interpretation fidelity depends on implementation; must manage PII in memory slots; policy for retention/erasure.
- Bold-use-case: Research toolkit for episodic vs semantic memory (academia)
- What: Study gating behavior, marginal-entropy addressing, IDW vs dot-product scoring, and test-time optimization dynamics in long-context modeling.
- Tools/products/workflows:
- Open-source FwPKM layer for PyTorch/JAX; NIAH-style evaluation harness with multi-iteration support.
- Benchmarks for memory usage, slot diversity, and write conflicts.
- Assumptions/dependencies: Reproducibility requires fixed chunking and seeds; datasets must reflect cross-chunk dependencies (e.g., LC64).
Long-Term Applications
These applications require further research, scaling, systems work (efficient kernels), or policy frameworks but are enabled by FwPKM’s fast, sparse, high-capacity episodic memory.
- Bold-use-case: Persistent personalization across sessions with safety controls (software, consumer, enterprise)
- What: Agents that learn user preferences, glossaries, and workflows over weeks by retaining and distilling fast-weight memories.
- Potential products:
- Hierarchical “memory tiers” (ephemeral → day-level → month-level) with controlled consolidation.
- Policy-managed memory (opt-in, audit, right-to-be-forgotten).
- Assumptions/dependencies: Governance and safety for persistent updates; robust retention/decay rules beyond chunk-level SGD; consent and privacy frameworks.
- Bold-use-case: Hybrid memory stacks at scale (foundation models)
- What: Architectures combining linear/softmax attention, slow-weight PKM (semantic), and fast-weight FwPKM (episodic) for state-of-the-art long-context reasoning.
- Potential products:
- “Memory OS” that schedules which layer to use, how many passes, and where to write; auto-tuning chunk sizes and Top-k.
- Nested Learning with varying update frequencies and capacities.
- Assumptions/dependencies: Training curricula to balance memories; kernel-level optimizations for sparse Top-k, Cartesian-product search, and IDW distance.
- Bold-use-case: Hardware and kernel acceleration for fast sparse memory updates (semiconductors, systems)
- What: Specialized kernels/ASIC support for Top-k selection, IDW scoring, and sparse writes to large value matrices.
- Potential products:
- CUDA/ROCm kernels for FwPKM; fused ops for addressing, softmax, and writes.
- Hardware primitives for on-chip episodic memory blocks.
- Assumptions/dependencies: Vendor investment; standardization of FwPKM APIs; cost-benefit vs attention accelerators.
- Bold-use-case: Clinical timeline modeling and care-plan assistants (healthcare)
- What: Episodic memory over multi-year EHR narratives to answer context-heavy queries (e.g., medication changes across years).
- Potential products:
- “Visit-mode” episodic memory (session-bound) plus opt-in longitudinal tier with strict audit/consent.
- Memory inspector for clinical provenance.
- Assumptions/dependencies: Regulatory validation (HIPAA/GDPR), robust de-identification, safety and accuracy across modalities; domain fine-tuning and clinical trials.
- Bold-use-case: Risk, audit, and surveillance over long event streams (finance, security)
- What: Track sequences of trades, communications, and alerts across long horizons; provide transparent memory traces for regulators.
- Potential products:
- Episodic monitors that memorize escalations and exceptions; queryable memory logs.
- Explainable alerts via slot-level retrieval provenance.
- Assumptions/dependencies: High-precision recall requirements; strict governance on memory retention and erasure; integration with existing compliance systems.
- Bold-use-case: Legal discovery and procurement analysis at million-token scale (legal, public sector)
- What: Multi-pass ingestion of corpora; on-demand retrieval with interpretable slot traces in court-ready formats.
- Potential products:
- “Memorize then litigate” workflow tooling; configurable iteration counts to reach target retrieval accuracy.
- Assumptions/dependencies: Validation on domain-specific benchmarks; throughput constraints without optimized kernels.
- Bold-use-case: Long-horizon robot task memory and map-like episodic recall (robotics)
- What: Robots maintain task-specific bindings and environment facts across long missions without quadratic attention.
- Potential products:
- Multi-pass world-model updates during idle cycles; episodic slots for landmarks and plans.
- Assumptions/dependencies: Extension to multimodal inputs (vision/audio); real-time constraints; safety under distribution shift.
- Bold-use-case: Grid and industrial time-series assistants (energy, manufacturing)
- What: Memorize rare events, outages, and maintenance logs across long histories for forecasting and root-cause analysis.
- Potential products:
- Hybrid models that combine FwPKM episodic buffers with SSMs/linear attention for continuous streams.
- Assumptions/dependencies: Adaptation to numeric/time-series tokenization; retraining; rigorous evaluation vs established forecasting baselines.
- Bold-use-case: Micro-RAG replacement for certain workloads (software)
- What: For closed-corpus tasks, replace repeated retrieval calls with FwPKM writes and slot-level retrieval at inference time.
- Potential products:
- Inference servers with “memory-first” mode; cost savings from fewer external lookups.
- Assumptions/dependencies: Corpus size and change rate; memory capacity and slot usage (avoid collapse via marginal entropy); warm-up passes.
- Bold-use-case: Standards and policy for test-time learning and memory governance (policy, standards bodies)
- What: Define disclosure, consent, retention, and erasure requirements for models that update parameters during inference.
- Potential products:
- “Episodic memory policy profiles” that vendors can certify against (e.g., session-only vs persistent).
- Audit schemas for slot-level logs.
- Assumptions/dependencies: Multi-stakeholder consensus; mapping technical controls (gating, erasure) to legal obligations.
Notes on feasibility and dependencies across applications
- Systems efficiency: Current FwPKM FLOPS are lower than attention due to less optimized kernels; production use benefits from dedicated sparse kernels.
- Training choices: To encourage use of FwPKM, restrict attention during training (e.g., probabilistic sliding window) and tune chunk sizes/Top-k.
- Latency vs accuracy: Iterative passes markedly improve retrieval (as shown in NIAH), but add latency; provide user-visible “memorization budget” controls.
- Safety and privacy: Test-time updates imply stateful inference; require explicit controls for memory scoping (session-only by default), auditing, and erasure.
- Generalization: Although FwPKM trained on 4K sequences generalizes to 128K in NIAH, domain validation is needed for target tasks (clinical, legal, finance).
- Interpretability: Slot-level tracing is a differentiator but must be engineered to be reliable, privacy-preserving, and comprehensible to end users.
Glossary
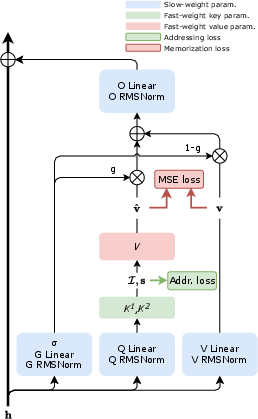
- Addressing loss: An auxiliary objective that maximizes marginal entropy to encourage uniform average access across memory slots. "We compute the marginal distribution \bar{p} representing the average slot usage over the chunk and define the addressing loss as the marginal entropy of \bar{p} ∈ ℝ{√N}:"
- Associative memory: A system that stores key-value bindings to enable retrieval and memorization over sequences. "The most successful architectures today can be fundamentally understood as forms of associative memory, characterized by their ability to maintain key-value associations, execute retrieval, and perform memorization."
- Cartesian grid: The 2D arrangement of PKM slots formed by the product of two sub-key sets. "The memory slots are arranged in a Cartesian grid of size √N × √N, and the slot at index (i,j) corresponds to the interaction between the i-th sub-key from K1 and the j-th sub-key from K2."
- Channel mixer: A module that mixes features within a single token representation rather than across time. "Channel Mixer. Mixes features within a single token representation."
- Chunk-level gradient descent: Local optimization steps performed per input chunk to update fast weights online. "FwPKM updates its parameters dynamically at both training and inference time via local chunk-level gradient descent"
- Episodic memory: Short-term, context-specific storage that retains information from the current input window. "FwPKM functions as an effective episodic memory that complements the semantic memory of standard modules, yielding significant perplexity reductions on long-context datasets."
- Fast weights: Parameters that are updated dynamically with each new input to encode transient, context-specific information. "The concept of 'fast weights' addresses this problem by introducing a set of parameters that change dynamically according to every new input."
- FLOPs: A measure of computation counting floating-point operations; often paired with FLOPS to assess efficiency. "In particular, we report FLOPs (Floating Point Operations) to measure the required computation as well as FLOPS (Floating Point Operations Per Second), which is FLOPs divided by running time (in seconds)"
- Full Attention (FA): Unrestricted softmax attention over the entire sequence context. "FA: Full Attention at all layers"
- Gated DeltaNet (GDN): A linear-attention-style token mixer with gating mechanisms for efficiency. "GDN: Gated DeltaNets at all 12 layers"
- Gating: A learned scalar that interpolates between FwPKM output and a residual pathway, controlling reliance on episodic memory. "we devise a gating mechanism to give the model the freedom of determining how much information is extracted from FwPKM outputs."
- Inverse distance weight (IDW) score: A similarity metric based on negative log distances that encourages keys to become cluster centroids. "Inverse distance weight (IDW) score is an alternative to dot-product score that produces a different key layout."
- Key-value memory: A memory with separate key and value matrices where queries retrieve values via similarity to keys. "A standard key-value memory consists of a key matrix K ∈ ℝ{N × D_K} and a value matrix V ∈ ℝ{N × D_V}, where N represents the number of memory slots and D_{K,V} are the hidden dimensions."
- LaCT: A TTT-style baseline model using sliding window attention and fast-weight MLPs with momentum-based updates. "In addition, we use LaCT as the second baseline."
- Lookahead value: A target construction that associates a token’s query with the next token’s value to aid next-token prediction. "we pair queries with lookahead values when applying chunk-level updates."
- Marginal entropy maximization: A training strategy that raises the entropy of average slot usage to prevent collapse in sparse memories. "We counteract FwPKM's memory collapsing by optimizing an auxiliary addressing objective based on marginal entropy maximization."
- Memory collapsing: The failure mode where sparse memories overuse a small subset of slots, reducing effective capacity. "Sparse memory suffers from 'memory collapsing' where the model learns to utilize only a small number of memory slots."
- Mixture-of-Experts Feed-Forward Network (MoE-FFN): A sparse FFN architecture that routes inputs to expert subnetworks. "FFN, MoE-FFN, PKM"
- Needle in a Haystack (NIAH): An evaluation that tests retrieval of specific key-value facts embedded in long contexts. "We conduct Needle in a Haystack (NIAH) evaluation to further verify FwPKM's functionality as episodic memory."
- Perplexity (PPL): A standard language-modeling metric measuring how well a model predicts test data. "We evaluate perplexity (PPL) on three distinct datasets to assess different memory capabilities"
- Product Key Memory (PKM): A sparse key-value memory that factorizes keys into sub-keys to enable efficient large-scale retrieval. "Product Key Memory (PKM) is an architecture that elegantly satisfies the first three properties."
- RMSNorm: Root Mean Square normalization that scales inputs without centering, used before linear projections. "we feed hidden state h_t to an RMS normalization and a linear layer to compute a scalar value:"
- Semantic memory: Long-term storage of general, dataset-wide knowledge captured in slow weights. "Long-term (Semantic). Stores dataset-wide facts and general rules (e.g., world knowledge)."
- Sliding Window Attention (SWA): Attention restricted to a fixed-size window to limit long-range computation. "Sliding Window Attention (SWA, window size 512)"
- Slow weights: Parameters trained offline over large datasets and kept fixed during inference. "In standard neural networks, knowledge is stored in 'slow weights' — parameters φ that are optimized over a massive training dataset but frozen after training."
- Softmax attention: Quadratic-cost attention mechanism with unbounded storage via full pairwise interactions. "Standard softmax attention acts as an associative memory with unbounded storage, yet its computational cost becomes increasingly prohibitive as the sequence length grows."
- Test-Time Training (TTT): Updating model parameters during inference via local objectives to adapt to current inputs. "Recent works like Test-Time Training (TTT) demonstrate that a fast-weight module can be implemented as a neural model f(·; θ) and its parameters are updated by minimizing an MSE objective"
- Token mixer: A module that mixes information across time steps rather than within-token features. "Token Mixer. Mixes information across time steps (sequence positions)."
- Top-k operation: A sparsity mechanism that selects the highest-scoring memory slots for retrieval. "A common approach to learning a large memory without sacrificing computation efficiency is to exploit sparsity via a Top-k operation"
- Ultra Sparse Memory: A family of sparse memory models extending PKM with more expressive keys and enhancements. "Ultra Sparse Memory is a line of work that extends the PKM architecture with more expressive keys and other improvements."
- Value residual: A residual pathway from the value projection to the output that ensures gradients reach slow-weight value projections. "We add a residual connection from the output of the value projection layer to the output of FwPKM"
- Z-score normalization: Feature-wise standardization of targets to zero mean and unit variance for stability. "We also found it useful to z-score normalize target values on the feature dimension."
Collections
Sign up for free to add this paper to one or more collections.

