Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
Abstract: The past few decades have witnessed significant advances in the design of machine learning algorithms, from early studies on task-specific shallow models to more general deep LLMs. Despite showing promising results in tasks that require instant prediction or in-context learning, existing models lack the ability to continually learn and effectively transfer their temporal in-context knowledge to their long-term parameters. Inspired by human learning process, we introduce a ''Sleep'' paradigm that allows the models to continually learn, distill their short-term fragile memories into stable long-term knowledge with replay, and recursively improve themselves with ''Dreaming'' process. In more detail, sleep consists of two stages: (1) Memory Consolidation: an upward distillation process, called Knowledge Seeding, where the memories of a smaller-self are distilled into a larger network to provide more capacity while preserving the knowledge. As a proof of concept, we present a new Generalized Distillation process for {Knowledge Seeding} (i.e., the combination of on-policy distillation with Reinforcement Learning (RL)-based imitation learning); (2) Dreaming: a self-improvement phase, where the model uses RL to generate a curriculum of synthetic data to rehearse new knowledge and refine existing capabilities without human supervision. Our experiments on long-horizon, continual learning, knowledge incorporation, and few-shot generalization tasks support the importance of the sleep stage.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: If people need sleep to turn daily experiences into long‑term memories, do AI LLMs need something like “sleep” too? The authors say yes. They propose a “Sleep” phase for LLMs so they can:
- Move short‑term knowledge (what they just saw in a chat) into long‑term memory (their actual parameters).
- Improve themselves by practicing on their own without human labels.
What questions does it try to answer?
- How can an LLM keep learning over time without constantly retraining from scratch?
- How can it remember new things beyond its short context window?
- How can it avoid “catastrophic forgetting” (losing old skills when learning new ones)?
- Can it safely practice and teach itself during “sleep,” using only its current knowledge?
How does the method work?
The big idea: Treat an LLM’s life like a cycle with two phases.
Active (Wake) time
The model talks to users, reads inputs, and solves tasks. It picks up short‑term hints from the current conversation (this is called “in‑context learning”). But normally, that knowledge disappears when the chat ends.
Sleep time
No new user data is coming in. The model focuses inward to:
- Consolidate memories: turn short‑term lessons into long‑term knowledge.
- Dream: create and solve its own practice problems to get better.
Here’s how each part works, using everyday language.
Memory consolidation: from short‑term to long‑term
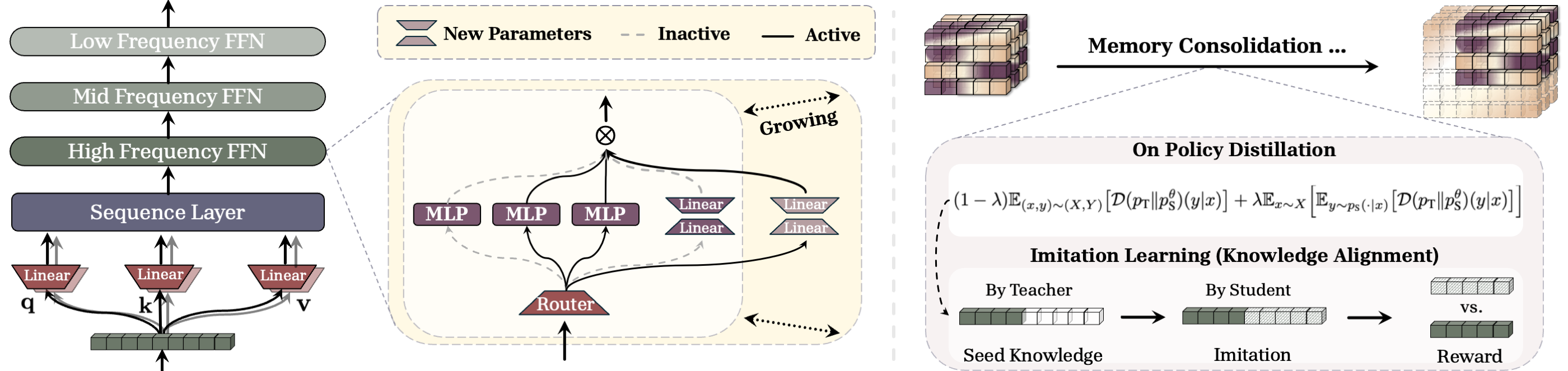
- Think of the model as having “fast layers” and “slow layers.”
- Fast layers change often and act like short‑term memory (quick to learn, quick to forget).
- Slow layers change rarely and act like long‑term memory (stable, more abstract knowledge).
- Before the fast layers get overwritten by new experiences, the model copies their most important lessons into the slower layers. This happens during sleep.
- To store new knowledge without messing up old knowledge, the model “opens new drawers” in the slow layers:
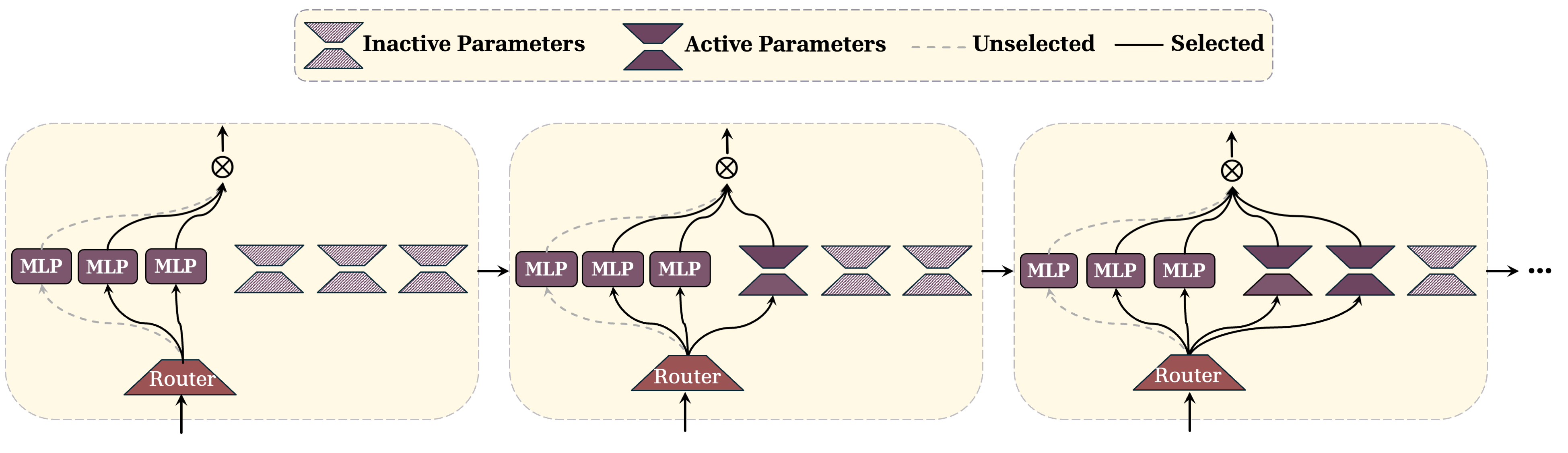
- In technical terms, it “activates” some extra small add‑on pieces (low‑rank experts) inside a Mixture‑of‑Experts (MoE) block. You can imagine MoE as a toolbox with many specialized tools. A “router” picks which tools to use. Adding a new expert is like adding a new tool so you don’t have to reshape an old one.
- Knowledge Seeding (the teaching step):
- A smaller “self” (the part with fast, short‑term memory) teaches a larger “self” (the part with the new drawers). This is a twist on knowledge distillation (a teacher model guides a student model).
- On‑policy distillation: the student practices on its own generated text, but the teacher gives feedback on every token (word piece) to gently steer it toward better answers.
- Imitation learning: the student tries to continue stories like the teacher would. It gets a reward for being semantically similar (meaning is the same) and also for being close at the word level, but not forced to copy exactly. This teaches the student not just facts, but how to sample good continuations.
- After copying, the model can “prune” temporary add‑ons in the faster layers so they’re ready to learn new things next time, similar to how the brain prunes unused connections during sleep.
Key terms explained:
- Catastrophic forgetting: learning new stuff breaks old stuff.
- Distillation: a teacher model shows a student model how to behave.
- On‑policy: the student trains on its own outputs, not just on fixed data.
- MoE (Mixture of Experts): many small specialized parts; a router chooses which ones to use.
- Low‑rank expert: a lightweight add‑on module—like a small drawer—good for adding capacity without breaking the whole system.
Dreaming: self‑improvement without new labels
- The model creates its own practice problems (“dreams”), tries to solve them, and checks which dreams help it improve.
- It picks the most useful dreams:
- It scores them by how much learning from each one would change its knowledge in the right direction (intuitively, how “educational” a dream is).
- It keeps the top ones and a few random ones to stay diverse.
- It then uses a safe feedback loop:
- Make a temporary copy of itself, fine‑tune that copy a bit on one dream, and see if performance improves on a relevant measure (like accuracy on a task).
- If it improves, that dream gets a positive reward, teaching the model what to generate more of next time.
This lets the model practice and get better even without new human‑labeled data.
What did they find?
The authors tested the sleep idea on several tough settings:
- Class‑incremental learning (learning new categories over time) on CLINC, Banking, and DBpedia datasets.
- Long‑context understanding (keeping track of information spread over long documents).
- Few‑shot learning (doing new tasks with very few examples).
- Incorporating new factual knowledge.
Main takeaways:
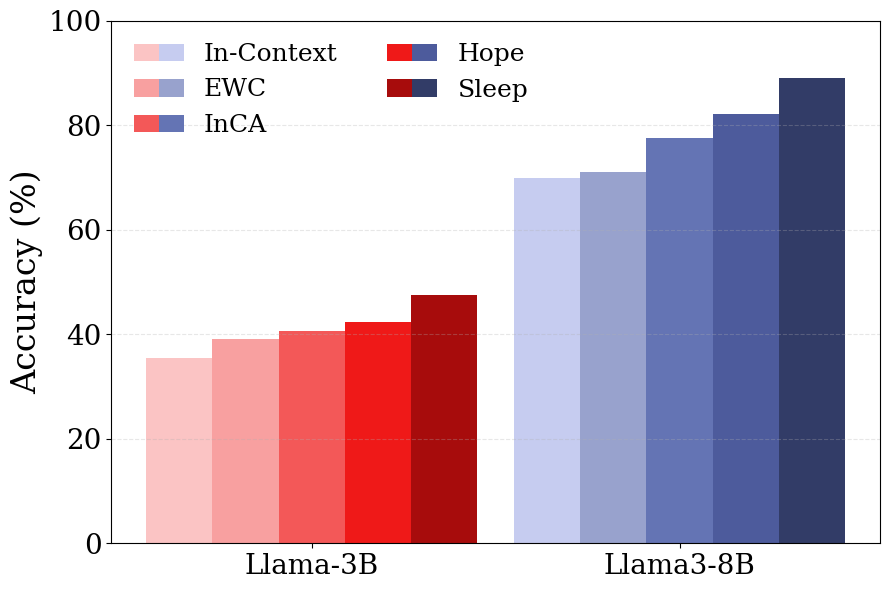
- Sleep helps the model remember new skills without forgetting old ones as much.
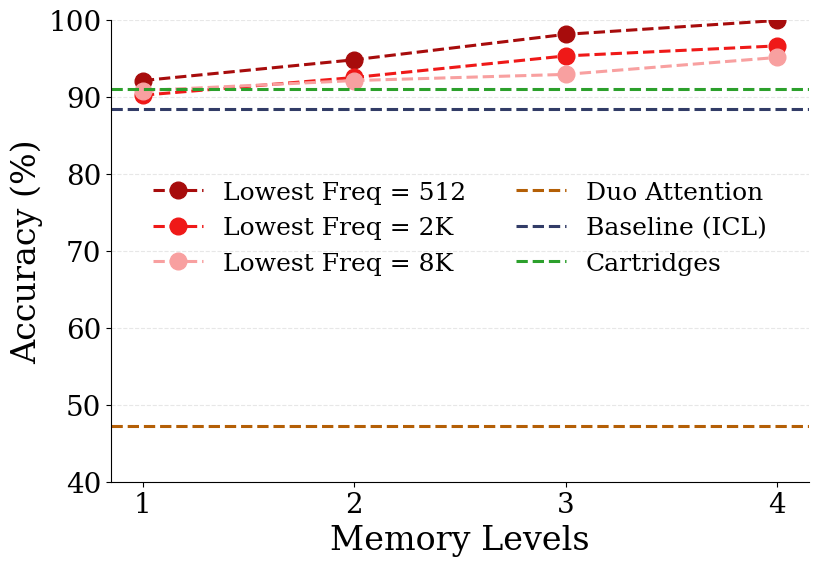
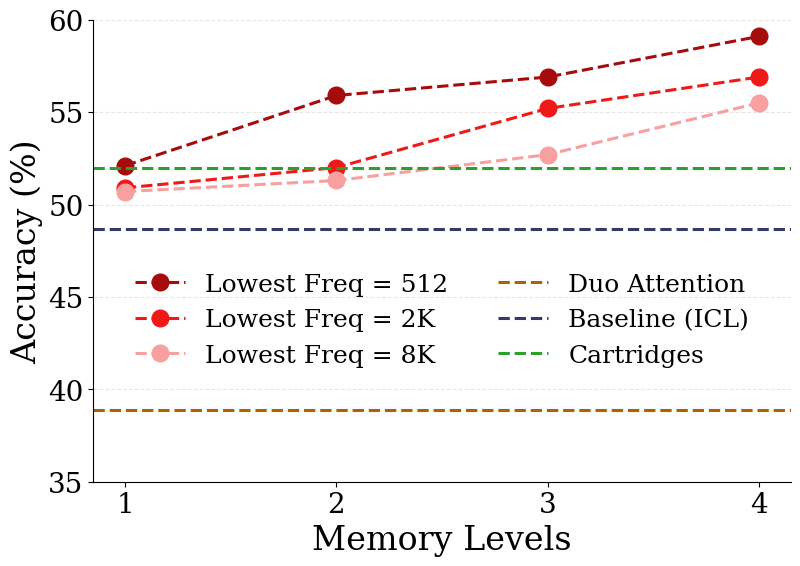
- Memory consolidation (copying from fast to slow layers) boosts long‑context understanding and makes in‑context learning gains “stick” as true knowledge.
- Adding “dreaming” further improves the model by letting it practice on useful, self‑made examples.
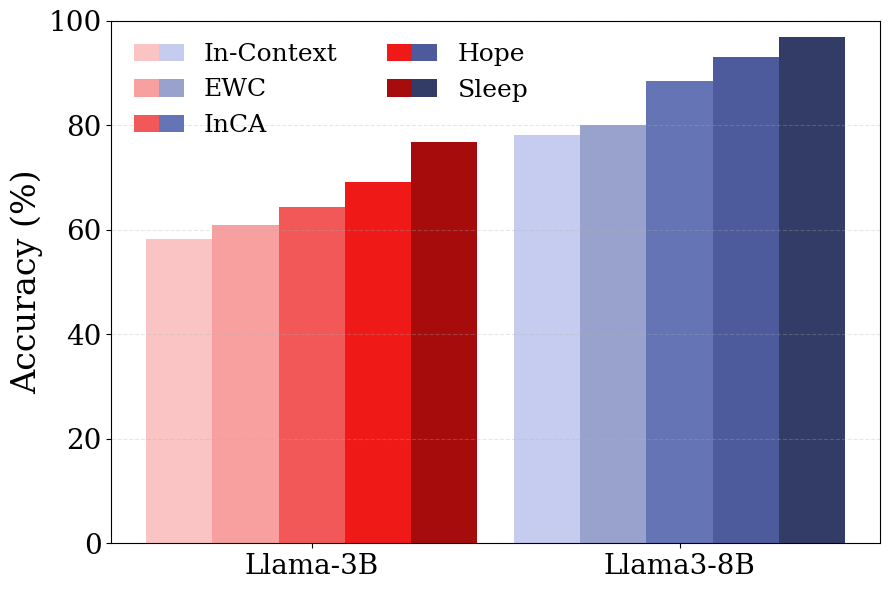
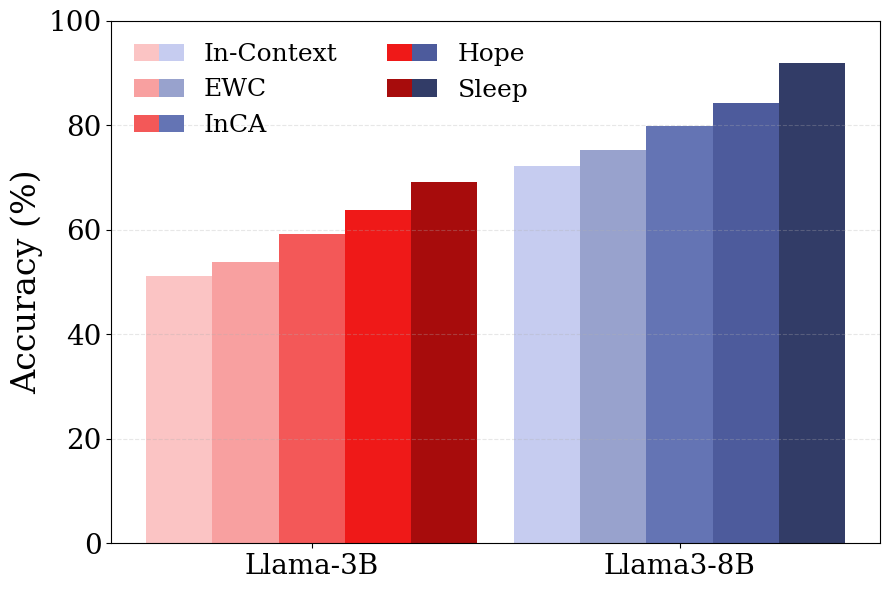
- Their approach outperformed common baselines like:
- Plain in‑context learning (no consolidation),
- Regularization methods to prevent forgetting (like EWC),
- External learners that try to help from outside,
- And even their own earlier multi‑level method without explicit distillation.
Why this matters:
- The model becomes less “static” and more “lifelong,” updating itself safely and efficiently.
- It avoids the huge cost of re‑pretraining on massive datasets just to stay up‑to‑date.
Why is this important?
- More like human learning: This brings AI closer to how people learn—short‑term experiences during the day, then “sleep” to stabilize and connect ideas.
- Lifelong assistants: Imagine a personal AI that keeps improving day by day, remembers new facts, and doesn’t forget old skills.
- Safer, cheaper updates: Instead of expensive, risky retraining, the model can schedule regular “sleep” to store what it learned and practice on its own.
- Stronger generalization: By abstracting knowledge into slow layers and practicing with dreams, the model becomes better at handling long documents, new topics, and few‑shot tasks.
Simple caution:
- Synthetic practice must be managed carefully so the model doesn’t “drift” or reinforce mistakes.
- Sleep still uses compute time, so scheduling and efficiency matter.
Bottom line
The paper argues that LLMs need a “sleep cycle.” During sleep, they consolidate short‑term lessons into long‑term memory (without overwriting old knowledge) and they dream—generating smart practice to improve themselves. This makes LLMs more adaptable, more stable, and more human‑like learners, pointing toward AI that can keep learning throughout its lifetime.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide future research.
- Sleep scheduling and triggers
- How should “sleep” be triggered in practice (time-based, data-driven drift detectors, performance regressions, or resource-aware triggers)?
- What duration, cadence, and ordering of NREM-like (consolidation) vs REM-like (dreaming) phases optimize stability–plasticity trade-offs?
- Consolidation scope and policy
- How to decide which layers/blocks to consolidate at each sleep step when multiple higher-frequency modules are due for consolidation simultaneously?
- How to set and adapt update frequencies and chunk sizes Cℓ over time to match non-stationary data streams?
- Parameter growth and capacity management
- The approach accumulates new (low-rank/MoE) experts each sleep cycle; what budgeted strategy governs expert growth to prevent unbounded parameter, memory, and inference-latency increase?
- What principled criteria (e.g., importance, redundancy, influence functions) should trigger expert pruning, merging, or compression, and when to fold low-rank deltas back into base weights?
- How to quantify and guarantee that “knowledge moved” to lower-frequency blocks before resetting earlier low-rank parameters (e.g., transfer-fidelity metrics beyond downstream accuracy)?
- Architectural generality
- The method assumes MoE-style expandable MLPs; how can memory consolidation and growth be realized in dense MLPs, attention blocks, SSMs/RNNs, or KV-state components?
- How to maintain router stability and load-balancing when adding experts (avoiding expert under-/over-use, collapse, or routing oscillations)?
- Distillation objective design
- The “Generalized KD + imitation learning” objective introduces λ, α, divergence D/F choices, γ, and distance thresholds (z0). What are principled ways (or automated procedures) to set/tune these hyperparameters and analyze sensitivity?
- What are the effects of different divergences (e.g., KL, JS, reverse-KL, contrastive, reward-weighted KL) and temperature scaling on consolidation quality and stability?
- On-policy distillation avoids backprop through sampling; how does this bias the estimator, and under what conditions does it converge to a good solution with an over-parameterized student?
- Teacher–student asymmetry and error propagation
- The student is larger than the teacher; how to prevent overfitting to teacher idiosyncrasies or amplifying teacher errors during upward distillation without external evidence?
- What mechanisms can detect and correct accumulated teacher bias or hallucinations, given the “no external data” constraint in sleep?
- Dream generation quality, coverage, and safety
- How to ensure dream data are diverse, representative, and non-degenerate (prevent mode collapse), beyond injecting a random expert during sampling? What diversity metrics or coverage guarantees apply?
- What safeguards prevent self-reinforcing errors/hallucinations and alignment drift across repeated dreaming cycles (e.g., calibration checks, veto models, red-teamers, toxicity/jailbreak filters)?
- How to formally define and measure “novel synthesis” of knowledge in dreams versus mere replays or paraphrases of internal patterns?
- Reward modeling for imitation and self-improvement
- The semantic reward relies on a frozen reward model; how is it trained, validated, and calibrated across domains, and how robust is it to distribution shift?
- How to design task-agnostic proxies when τ(·) is unavailable or costly, and how to choose τ in a purely offline “no external data” sleep?
- What are sample-efficiency, stability, and convergence properties of ReSTEM in this setting, and does it outperform simpler bandit-style selection?
- Stability–plasticity analysis
- No formal guarantees on catastrophic forgetting bounds, stability of alternating consolidation/dreaming, or convergence of the combined dynamics; can we derive theoretical guarantees or sufficient conditions?
- How should the stability–plasticity balance be optimized jointly via update frequencies, consolidation strength (α, λ), and growth/pruning schedules?
- Continual learning at scale and over long horizons
- Longitudinal evidence is missing: how does performance evolve over many months/tasks with recurring or adversarially shifting distributions? What are the forgetting curves and re-learning dynamics?
- How does the method compare against strong replay-based, parameter-isolation, orthogonal-gradient, or retrieval-augmented continual learning baselines under non-stationary streams?
- Empirical coverage and ablations
- Evaluations are limited (small models, primarily classification and a few long-context tasks); missing are code, math, tool use, dialogue, multimodal, and knowledge-refresh/injection benchmarks.
- Required ablations: SKS vs. KD-only vs. RL-only; effect of freezing vs. partial unfreezing; with/without random-expert injection; low-rank dimension sweeps; router regularization; different consolidation schedules.
- Missing head-to-head compute-normalized comparisons and energy reporting for sleep phases (wall-clock, tokens processed, TPU/GPU hours) and the cost–benefit frontier of sleep frequency.
- Triggering, detection, and monitoring
- What online signals should trigger sleep (e.g., drift detectors, uncertainty, surprise, calibration errors), and how to monitor for harmful model-state changes introduced during sleep?
- Which diagnostics can verify that consolidation improves abstraction and that dreaming improves competence without regressing safety or calibration?
- Integration with broader LLM stacks
- How does Sleep interact with retrieval-augmented generation, external memory stores, tool use, and agent planning loops? Where should consolidation act (params vs. memories vs. indices)?
- How to coordinate sleep-time updates with production deployment, versioning, rollback, and evaluation pipelines?
- Inference-time efficiency and latency
- As experts accumulate, how does routing cost, cache size, and latency change at inference? Can constrained routing (top-1, budgeted expert activation) retain accuracy post-consolidation?
- What is the impact on KV-cache size and context-window memory when consolidations alter effective capacity or activation patterns?
- Privacy and compliance
- Do dreams inadvertently reconstruct or expose private training data? Can differential privacy or auditing be integrated into sleep-time generation and consolidation?
- How to log, audit, and govern self-modifications for compliance and reproducibility?
- Reproducibility and implementation detail
- Detailed settings are missing for chunk sizes Cℓ, routing temperatures, learning rates per frequency, masking/activation mechanics, and pruning policy; open-sourcing code/configs would enable replication.
- Framework-level feasibility of “pre-allocating but masking” large dormant parameters at scale needs profiling (memory overhead, compile-time constraints).
- Beyond internal data constraints
- The framework presumes minimal/no external data during sleep; how to safely and effectively incorporate small trusted streams (e.g., curated refreshes) without reintroducing catastrophic forgetting?
- Evaluation of “knowledge incorporation”
- Although claimed, concrete experiments measuring incorporation of new factual knowledge, timestamped updates, and temporal generalization (with leakage controls) are absent; standardized protocols are needed.
- Safety of self-modification
- What governance mechanisms bound the scope of self-edits (e.g., guardrails, capability containment) and detect misalignment or capability escalation introduced by sleep-time RL?
These gaps suggest concrete avenues: formal analyses of stability and convergence; budgeted capacity-growth strategies with principled pruning/merging; robust dream quality control and safety filters; richer, compute-normalized benchmarks and ablations; and operational protocols for triggering, monitoring, and governing sleep-time self-modification.
Practical Applications
Overview
Based on the paper “LLMs Need Sleep: Learning to Self-Modify and Consolidate Memories,” practical applications flow from two core innovations:
- Memory consolidation via self-Knowledge Seeding (SKS): a periodic, offline “upward distillation” process that transfers knowledge from higher-frequency (short-term) modules to lower-frequency (longer-term) modules, with low-rank parameter expansion (e.g., new MoE experts) to preserve old knowledge and mitigate catastrophic forgetting.
- Dreaming for self-improvement: an RL-driven, self-generated synthetic data curriculum (with selection and rewards) that helps refine and expand recent capabilities without human supervision.
Below are actionable use cases grouped by deployment horizon, with sectors, potential products/workflows, and feasibility notes.
Immediate Applications
These can be piloted today with access to model weights and basic RL/distillation tooling (e.g., LoRA/MoE frameworks, on-policy distillation, evaluation harnesses).
- Enterprise chatbots and support agents with nightly “sleep” consolidation
- Sectors: software, customer support, enterprise IT
- What: Schedule sleep cycles (off-peak) to distill session-specific ICL knowledge (e.g., new product SKUs, FAQs) into low-rank experts/adapters via SKS, reducing reliance on long prompts and mitigating catastrophic forgetting across shifts or product updates.
- Tools/workflows:
- LLMOps “Sleep Scheduler” that triggers SKS + imitation learning;
- Low-rank expert manager for MoE/adapters;
- Distillation trainer combining on-policy (student-generated) and teacher logits;
- Post-sleep regression tests for legacy intents.
- Assumptions/dependencies: Requires parameter-level access (closed APIs may limit this). Compute budget for off-peak distillation. Safety filters for self-generated data.
- On-device assistants that consolidate while charging
- Sectors: mobile, consumer electronics, automotive
- What: Personalization learned in-session (wake) compressed into masked, pre-allocated low-rank slots during charging (“sleep”) to persist preferences offline and enhance privacy.
- Tools/workflows:
- Pre-masked parameter banks activated during sleep;
- Tiny reward models for local imitation signals;
- Thermal- and power-aware scheduling.
- Assumptions/dependencies: On-device fine-tuning capability (or micro-adapters), storage for masked parameters, privacy consent.
- Team-aware code assistants that “sleep” on day’s commits
- Sectors: software engineering
- What: Mine PRs/reviews and in-context hints during the day, then nightly SKS distills conventions and new APIs into low-rank experts to improve autocomplete and review suggestions.
- Tools/workflows:
- CI/CD-integrated Sleep Jobs that select training snippets;
- Adapter bank per repository/team;
- Post-sleep lint/test-based guardrails.
- Assumptions/dependencies: Repository access; risk of overfitting to anti-patterns; IP/governance requirements.
- RAG memory compaction for high-traffic queries
- Sectors: enterprise search, knowledge management
- What: Identify frequently retrieved facts and consolidate them into low-rank memory via SKS, reducing latency and retrieval costs while retaining long-tail RAG for rare facts.
- Tools/workflows:
- Query analytics to rank “hot” facts;
- SKS for high-frequency material;
- Drift monitors to revert/adapt when source content changes.
- Assumptions/dependencies: Must maintain provenance and freshness guarantees; rollback pathways.
- Customer personalization in e-commerce and media
- Sectors: retail, advertising, media
- What: Session behavior (wake) distilled into user- or segment-level adapters (sleep) for better recommendations and messaging without retaining raw logs.
- Tools/workflows:
- Segment-level adapter banks;
- Consent-aware orchestration;
- A/B testing gated by post-sleep uplift metrics.
- Assumptions/dependencies: Privacy consent and data minimization practices; guard against bias amplification.
- Continual intent classification without catastrophic forgetting
- Sectors: fintech, telecom, virtual assistants
- What: Apply memory consolidation to class-incremental text classification (as evaluated on CLINC/Banking/DBPedia), preserving old intents while adding new ones.
- Tools/workflows:
- Periodic expansion of low-rank experts;
- On-policy self-distillation;
- Continual evaluation suites.
- Assumptions/dependencies: Access to backbone LLM parameters or classification head; monitoring for interference.
- Compliance and policy update pipelines
- Sectors: finance, healthcare, legal
- What: Parse new rules/protocols during wake; consolidate verified summaries into low-rank experts during sleep with imitation rewards tuned to semantic equivalence.
- Tools/workflows:
- Human-in-the-loop validation queue for critical updates;
- Reward models focused on semantic correctness;
- Audit trails (“sleep logs”).
- Assumptions/dependencies: Strong validation and audit; high-precision reward models; legal oversight.
- Self-improvement via “dream” curricula for agents
- Sectors: autonomous agents, devops bots, task automation
- What: Generate synthetic tasks with ReSTEM-style selection, then reinforce tasks that yield measurable post-finetuning gains. Useful for sharpening recent skills (e.g., tool-use sequences).
- Tools/workflows:
- Dream generator with router randomness for diversity;
- Gradient-based sample selection;
- Safety-filtered reward models.
- Assumptions/dependencies: Risk of distribution drift or reward hacking; careful evaluation sandboxing.
- MLOps compute orchestration leveraging off-peak “sleep”
- Sectors: cloud, energy-conscious IT
- What: Shift consolidation and dreaming to off-peak hours/low-carbon windows, reducing costs and emissions.
- Tools/workflows:
- Carbon-aware job scheduler;
- Budgeted sleep cycles with SLAs;
- Cost/benefit dashboards.
- Assumptions/dependencies: Reliable energy/price signals; flexible maintenance windows.
- Academic replication kits for continual learning
- Sectors: academia, open-source
- What: Release reference pipelines implementing SKS + dreaming on public LLMs/classifiers to benchmark continual learning and long-context tasks.
- Tools/workflows:
- Open-source “Sleep Lab” (distillation + imitation + selection);
- Benchmarks for class-incremental and long-context tasks.
- Assumptions/dependencies: Suitable open models (weights available); compute grants.
- Privacy-by-design memory retention
- Sectors: policy, privacy engineering
- What: Replace raw session log retention with lossy distilled weights to minimize PII exposure while retaining utility.
- Tools/workflows:
- Differentially-private distillation variants;
- Memory pruning policies after consolidation.
- Assumptions/dependencies: DP variants not included in the paper—must be added; regulator acceptance.
Long-Term Applications
These require broader architectural changes, stronger safety controls, or sector-specific validation and regulation.
- Autonomous lifelong-learning agents with regulated wake/sleep cycles
- Sectors: robotics, industrial automation, smart homes
- What: Agents learn continually on the job and consolidate at rest, expanding capacity (low-rank experts) as tasks evolve, reducing re-training needs and CF.
- Tools/products:
- “Neuroplasticity manager” that controls parameter activation/pruning;
- On-device reward models;
- Federated sleep across fleets.
- Dependencies: Hardware acceleration for masked parameters; robust safety validation.
- Rolling maintenance for foundation models via fleet-wide sleep
- Sectors: AI infrastructure
- What: Replace infrequent, costly re-pretraining with continuous, distributed sleep cycles that seed new knowledge upward across versions while preserving stability.
- Tools/products:
- Distributed SKS orchestrators;
- Versioned adapter registries;
- Global regression and drift gates.
- Dependencies: Strong governance to avoid divergence; cross-version compatibility constraints.
- Memory governance and auditability standards
- Sectors: policy, compliance, enterprise risk
- What: Standardize “sleep logs” (what consolidated, from where, with which reward signals) for audit and incident response.
- Tools/products:
- Tamper-evident memory change logs;
- Explainability dashboards for consolidation events.
- Dependencies: Industry consensus; mapping to legal frameworks (e.g., AI Act, HIPAA, SOX).
- Safety-aware dreaming with constrained generative policies
- Sectors: healthcare, finance, govtech
- What: Dream generation constrained by safety policies and clinically/legally validated reward models to avoid unsafe self-training.
- Tools/products:
- Policy-constrained RL;
- Domain-specific reward models (e.g., guideline adherence).
- Dependencies: High-quality, validated reward models; rigorous post-sleep validation.
- Elastic capacity co-design (hardware + software)
- Sectors: semiconductors, edge devices
- What: Hardware support for activating masked parameter blocks and low-rank ops, enabling efficient periodic expansion and pruning.
- Tools/products:
- Mask-aware accelerators;
- Runtime kernels for dynamic expert routing.
- Dependencies: Vendor ecosystem support; compiler/runtime changes.
- Regulatory frameworks for self-modifying AI
- Sectors: public policy, standards bodies
- What: Define requirements for self-modification (e.g., consolidation frequency, logging, rollback, human oversight) to ensure safety and accountability.
- Tools/products:
- Conformance test suites;
- Certification programs for wake/sleep lifecycle.
- Dependencies: Multi-stakeholder standardization; enforcement mechanisms.
- Clinical decision support with validated offline consolidation
- Sectors: healthcare
- What: Systems that absorb updated clinical guidance, consolidate offline with conservative imitation rewards, and deploy only after clinical gatekeeping.
- Tools/products:
- Clinician-in-the-loop validation;
- Locked “safe experts” plus “learning experts” with rollout gating.
- Dependencies: Clinical trials; regulatory approvals (FDA, EMA).
- Finance and trading copilots with risk-controlled updates
- Sectors: finance
- What: Agents that learn changing rules/market structures via sleep cycles; deployment gated by risk models and compliance checks.
- Tools/products:
- Consolidation gating with backtests;
- Model cards tracking sleep-induced deltas.
- Dependencies: Strict risk and compliance frameworks; adversarial robustness.
- Lifelong personalized tutors with curriculum dreaming
- Sectors: education
- What: Tutors that consolidate student progress and generate adaptive dream curricula to reinforce weak areas, improving long-term retention.
- Tools/products:
- Per-student adapter banks;
- Mastery-based reward models;
- Teacher dashboards for oversight.
- Dependencies: Parental/educator consent; fairness and bias monitoring.
- Federated “sleep” for IoT/edge swarms
- Sectors: energy, manufacturing, logistics
- What: Devices learn locally, then perform federated consolidation (no raw data sharing) to propagate robust patterns across the fleet.
- Tools/products:
- Federated SKS protocols;
- Privacy-preserving aggregation;
- Edge reward models.
- Dependencies: Connectivity constraints; privacy/security guarantees.
- Carbon-aware sleep computing as a grid flexibility asset
- Sectors: energy, sustainability
- What: Align sleep compute windows with renewable surpluses and demand response, turning AI maintenance into a grid-friendly load.
- Tools/products:
- Energy market-aware schedulers;
- SLAs that treat sleep compute as shiftable.
- Dependencies: Utility integrations; reliable forecasting.
Key Assumptions and Dependencies Across Applications
- Access to model internals: Many applications require fine-grained control (freezing/unfreezing, low-rank expansion, MoE routing). Hosted black-box APIs may not support this.
- Architectural prerequisites: Best fit with MoE or adapter-capable stacks. For dense models, low-rank adapters can approximate expansion but may limit capacity growth.
- Reward modeling quality: Dreaming and imitation rely on semantic/absolute similarity rewards; poor reward models can cause drift or reinforcement of errors.
- Safety and governance: Self-generated data can encode mistakes or bias; use filters, human oversight for critical domains, and post-sleep regression tests.
- Compute budgets and scheduling: Sleep cycles need dedicated compute; off-peak or carbon-aware scheduling improves cost and sustainability.
- Monitoring and rollback: Always maintain evaluation gates, drift detectors, and rollback mechanisms to contain adverse sleep-induced changes.
- Data privacy and consent: Memory consolidation should adhere to privacy principles; consider DP distillation for sensitive contexts.
By operationalizing wake/sleep cycles with controlled parameter expansion and upward distillation, organizations can achieve continual learning with reduced catastrophic forgetting, improve long-context retention, and move toward more sustainable and self-improving AI systems.
Glossary
- Anterograde amnesia: A neurological condition that prevents forming new long-term memories after onset. "anterograde amnesiaâa neurological condition where a person cannot form new memories after the onset of the disorder, while existing memories remain intact"
- Catastrophic Forgetting (CF): Degradation of performance on previously learned tasks when learning new ones in continual settings. "Catastrophic Forgetting (CF)~{kemker2018measuring, shi2024continual}âa well-known phenomenon where the model's proficiency on original tasks degrades catastrophically as it learns new ones."
- Class-incremental learning: A continual learning setup where new classes are introduced over time and the model must retain prior knowledge. "We first focus on class-incremental learning on three datasets of CLINC~{larson2019evaluation}, Banking~{casanueva2020efficient}, and DBpedia~{auer2007dbpedia} (see \autoref{app:data} for the details)."
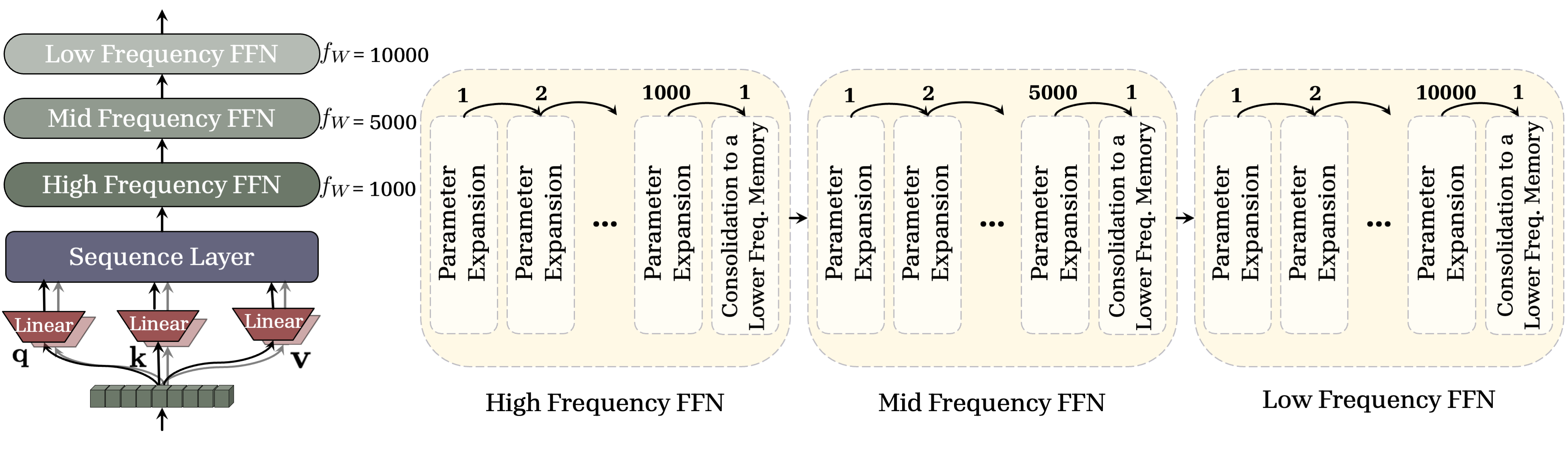
- Continuum Memory System (CMS): An architecture with modules updated at different frequencies to represent a spectrum from short- to long-term memory. "presented Continuum Memory System (CMS), where the architecture is a sequence model such as attention, followed by a chain of MLP layers, each of which updated with its own frequency."
- Curriculum of synthetic data: A structured progression of generated examples designed to improve learning and practice. "generate a curriculum of synthetic data to rehearse new knowledge and refine existing capabilities without human supervision."
- Dreaming: A sleep-phase self-improvement process where the model generates synthetic data to refine capabilities. "Dreaming: a self-improvement phase, where the model uses RL to generate a curriculum of synthetic data to rehearse new knowledge and refine existing capabilities without human supervision."
- Elastic Weight Consolidation (EWC): A regularization method that protects important parameters to mitigate forgetting. "we compare against ICL (same continual pre-training process but without sleep), Elastic Weight Consolidation (EWC)~{kirkpatrick2017overcoming}, and In-context Continual Learning with an External Learner (InCA)~{momeni2025context}."
- Fast-weight Programs: Models with rapidly updated weights within a sequence, used to illustrate high update frequency. "we use a simple example of Fast-weight Programs~{schmidhuber1992learning}, where the input is a sequence of length ."
- Generalized Knowledge Distillation (GKD): A distillation framework mixing teacher data with student on-policy samples. "we build upon Generalized Knowledge Distillation (GKD)~{agarwal2024onpolicy}, which allows a mixture of on-policy student generated data with a teacher-generated data"
- Hope architecture: A multi-level in-context updating architecture used for continual learning. "The Hope architecture consistently outperforms other continual learning approaches, achieving the highest accuracy."
- Imitation learning: Training a model to mimic an expert or teacher’s behavior or outputs. "the combination of on-policy distillation with Reinforcement Learning (RL)-based imitation learning"
- In-Context Learning (ICL): The capability of LLMs to adapt to tasks from prompts without parameter updates. "In recent years, In-Context Learning (ICL)~{brown2020language} has gained attention as a highly efficient and successful form of continual learning~{akyurek2022learning, dong2024survey, akyurek2024context, li2025longcontext}."
- Knowledge cutoff: A fixed date beyond which a model lacks awareness of new facts and events. "operating with a fixed "knowledge cutoff" date beyond which it is unaware of new facts, events, and evolving information~{cheng2024dated}."
- Knowledge Seeding (KS): Upward distillation transferring knowledge from smaller models into a larger model. "We present a new form of knowledge transfer, called knowledge seeding, where one or some smaller models distill their knowledge to a larger model."
- Levenshtein distance: An edit-distance metric measuring the minimum edits needed to transform one string into another. "absolute reward is defined based on the Levenshtein distance of the two sequences (denoted by )"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method using low-rank adapters. "finetuning (with LoRA~{hu2022lora})"
- Memory consolidation: The process of transforming recent, fragile information into stable, long-term knowledge. "Memory Consolidation: an upward distillation process, called Knowledge Seeding, where the memories of a smaller-self are distilled into a larger network to provide more capacity while preserving the knowledge."
- Mixture of Experts (MoE): An architecture that routes inputs to a subset of specialized expert networks. "we assume that the MLP blocks are sparse mixture of experts (MoEs) with a router "
- Nested Learning (NL): A paradigm where modules with different update frequencies transfer knowledge from faster to slower components. "{behrouz2025nested}, recently, presented the Nested Learning (NL) paradigm"
- Non-REM (NREM) sleep: A sleep stage associated with slow-wave activity, synaptic homeostasis, and memory consolidation. "two critical and alternating stages of sleep: Rapid Eye Movement (REM) and Non-REM (NREM) sleep."
- On-policy distillation: Distillation where the student is trained using its own sampled outputs in addition to teacher supervision. "the combination of on-policy distillation with Reinforcement Learning (RL)-based imitation learning"
- Periodic Parameter (De)Activation: A schedule that deactivates/activates parameters across modules to balance plasticity and stability. "Periodic Parameter (De)Activation: Building on the Nested Learning (NL) paradigm~{behrouz2025nested} that allows each component to have its own frequency of update, we suggest a periodic and gradual parameter (de)activation process"
- Rapid Eye Movement (REM) sleep: A sleep stage linked to dreaming, selective synaptic strengthening, and integration with existing networks. "two critical and alternating stages of sleep: Rapid Eye Movement (REM) and Non-REM (NREM) sleep."
- ReSTEM algorithm: A reinforcement learning training approach used to optimize self-improvement from generated data. "We follow SEAL and use ReST algorithm~{singh2024beyond} to optimize the above process."
- Router (MoE): The gating mechanism that selects which experts process a given input. "In the sampling process, each router in MoE blocks additionally chooses a random expert"
- Self-Knowledge Seeding (SKS): Distilling knowledge from a smaller version of the same model into a larger version. "we present self-Knowledge Seeding (SKS), where a smaller version of a model (e.g., some parameters are not active), distill the knowledge to a larger version of the model"
- Sleep paradigm: A framework that alternates between active and sleep phases to consolidate memory and self-improve. "we present Sleep paradigm, in which contrary to the model's waking time (or active time), the model does not receive any external input data and concentrates its internal computations on self-improvement, consolidating the past memories, and abstracting knowledge."
- Synaptic homeostasis: A biological mechanism proposing global downscaling of synaptic strengths during sleep to maintain balance. "The first is synaptic homeostasis, a process that globally downscales synaptic strengths to counteract the net increase in connectivity from waking experiences, thereby maintaining metabolic balance and preventing neural saturation~{tononi2006sleep}."
- Synaptic pruning: The elimination of unnecessary or redundant neural connections to improve efficiency. "This step, can be interpreted as a similar procedure of synaptic pruning in human brain, in which brain prunes connections that are unnecessarily and/or redundant~{li2017rem} to enhance its efficiency and performance."
- Systems consolidation: An offline process that replays and reorganizes newly encoded patterns into long-term cortical storage. "An ``offline'' consolidation (also known as systems consolidation) process repeats the replay of the recently encoded patterns during sleep and reorganizes the memory and supports transfer to cortical sites~{ji2007coordinated, peyrache2009replay, foster2006reverse}."
- Update frequency: The number of updates a parameter undergoes per unit of time in the CMS/NL framework. "For any weight component of , we define its frequency, denoted as , as its number of updates per unit of time."
Collections
Sign up for free to add this paper to one or more collections.

