GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Abstract: LLMs are increasingly adapted to downstream tasks via reinforcement learning (RL) methods like Group Relative Policy Optimization (GRPO), which often require thousands of rollouts to learn new tasks. We argue that the interpretable nature of language can often provide a much richer learning medium for LLMs, compared with policy gradients derived from sparse, scalar rewards. To test this, we introduce GEPA (Genetic-Pareto), a prompt optimizer that thoroughly incorporates natural language reflection to learn high-level rules from trial and error. Given any AI system containing one or more LLM prompts, GEPA samples system-level trajectories (e.g., reasoning, tool calls, and tool outputs) and reflects on them in natural language to diagnose problems, propose and test prompt updates, and combine complementary lessons from the Pareto frontier of its own attempts. As a result of GEPA's design, it can often turn even just a few rollouts into a large quality gain. Across four tasks, GEPA outperforms GRPO by 10% on average and by up to 20%, while using up to 35x fewer rollouts. GEPA also outperforms the leading prompt optimizer, MIPROv2, by over 10% across two LLMs, and demonstrates promising results as an inference-time search strategy for code optimization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to improve how AI systems work, especially those built from LLMs like GPT. Instead of training the AI with lots of trial-and-error using reinforcement learning (which needs many practice runs), the authors show that we can make big improvements by using the AI’s natural ability to read and write language. Their method, called GEPA, teaches the AI to read what happened during each run, reflect on it in plain language, and update its instructions (prompts) to do better next time. They find that this can beat a popular reinforcement learning method while using far fewer runs.
What questions does the paper try to answer?
The paper sets out to answer three simple questions:
- Can an AI learn faster by reading and reflecting on what happened during its attempts, rather than just getting a score at the end?
- Can updating the AI’s instructions (prompts) be as powerful—or even better—than changing its internal settings with reinforcement learning?
- How can we choose which ideas to keep and improve so we don’t get stuck on one strategy that looks good but isn’t the best overall?
How does their method (GEPA) work?
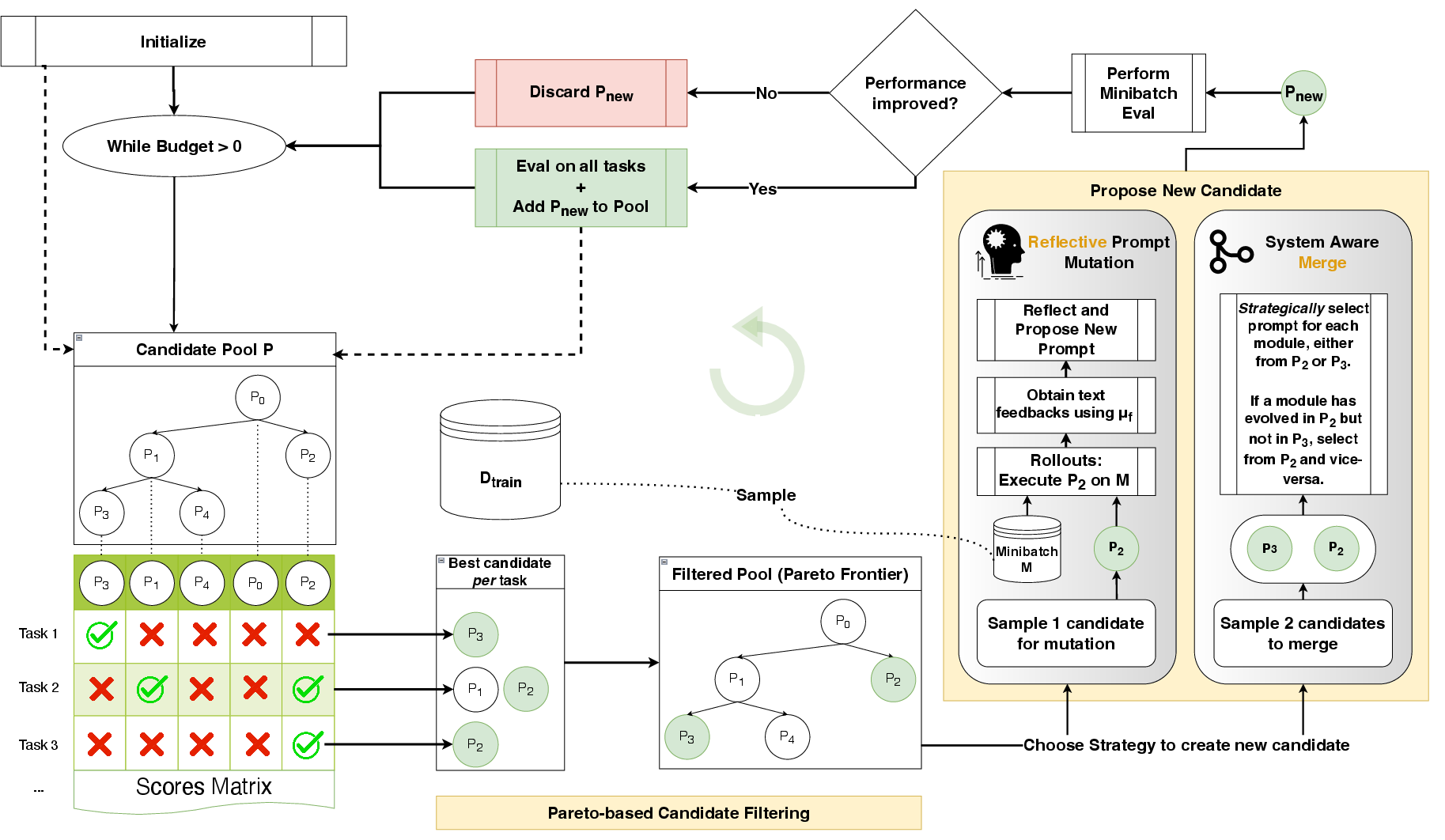
Think of an AI system like a team following a playbook. Each part of the team (each AI module) has its own short instructions, called a prompt. GEPA improves those prompts using a three-part process:
1) Reflective Prompt Mutation
- Analogy: After each practice game, the coach reads a detailed game log: what each player did, which tools they used, and where things went wrong or right.
- GEPA asks an LLM to:
- Read the “trace” (the step-by-step text of what the system did, including tool outputs and errors).
- Read feedback from the “referee” (the evaluation system that checks answers or code and gives hints, not just a score).
- Write clearer, smarter instructions for the specific player (module) that needs improvement.
- This is like updating the playbook with lessons learned, in the AI’s own language, after just a few examples.
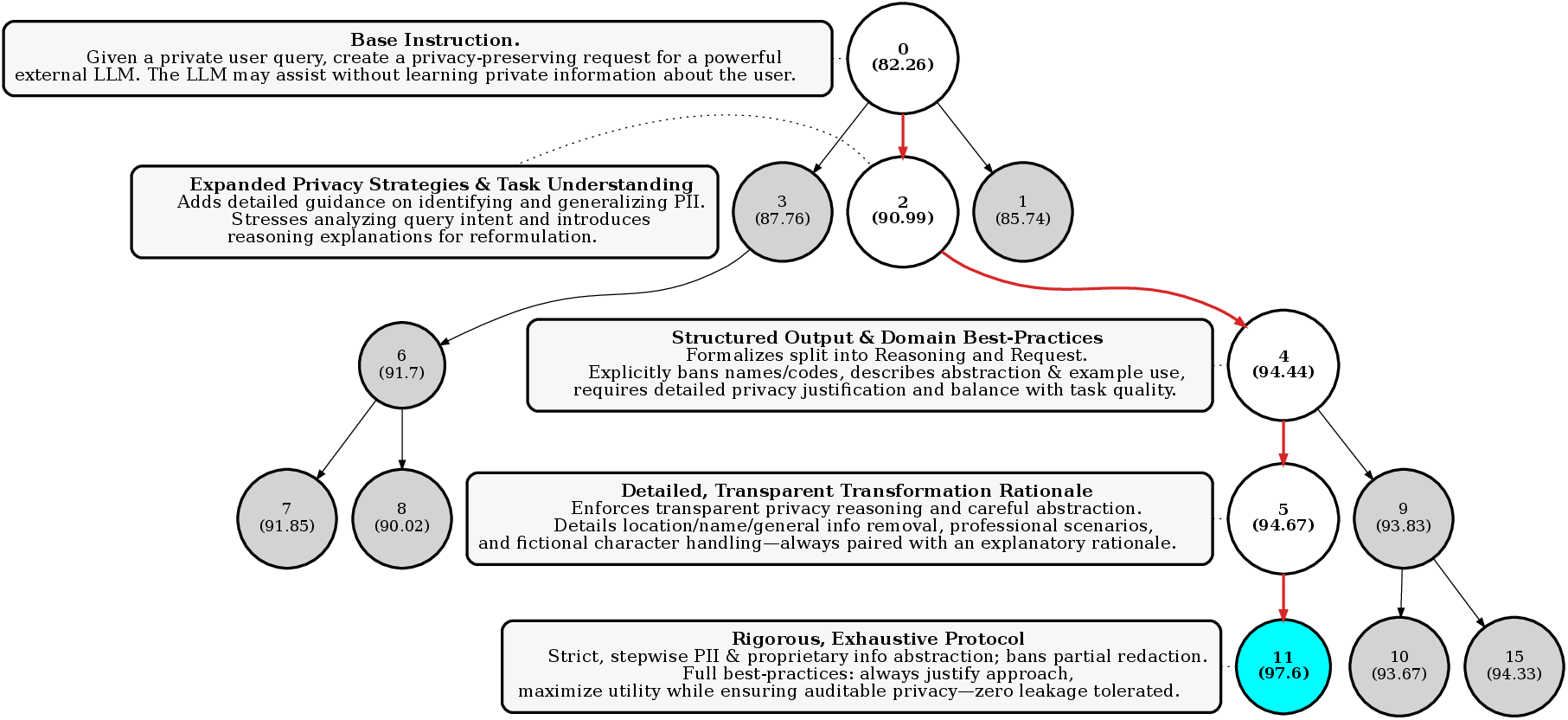
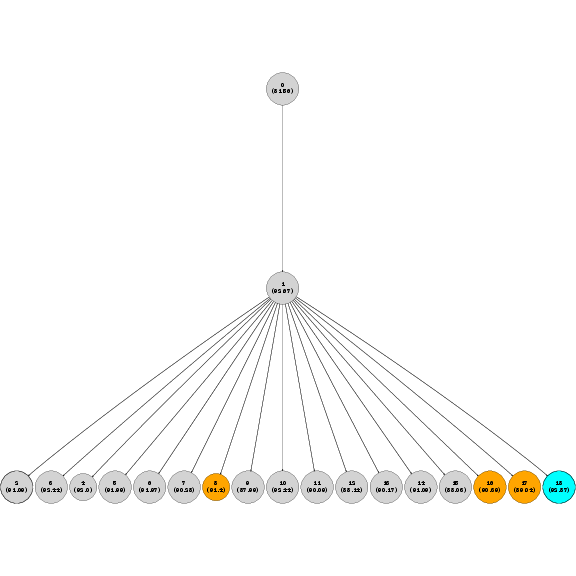
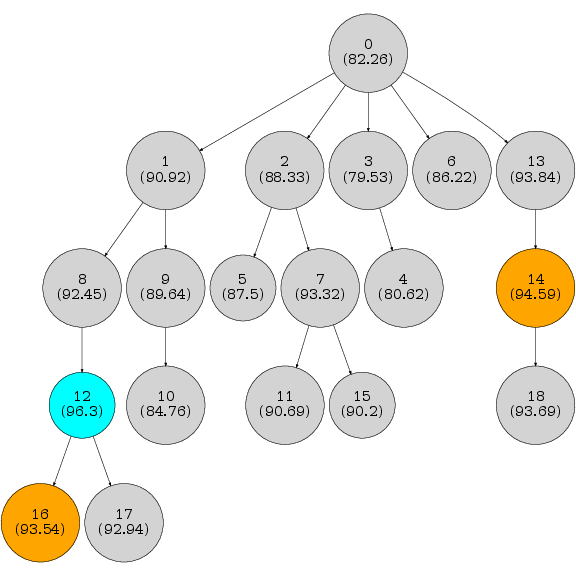
2) Genetic Evolution of Prompts
- Analogy: Prompts are like parents and children. A new prompt is created by tweaking an older one based on lessons learned. Good ideas accumulate as “descendants” keep the best parts from their “ancestors.”
- GEPA keeps a pool of candidate prompts and adds new ones as they show improvement on small test batches.
3) Pareto-Based Candidate Selection
- Analogy: Don’t just pick the “best overall” player every time—that can get you stuck. Instead, keep any player who’s the best at something.
- “Pareto frontier” means the set of prompts that each win on at least one training example. None of them are strictly worse than another across the board.
- GEPA samples from these “best-at-something” prompts, so it explores diverse strategies and avoids getting trapped by a single good-looking approach.
To make this concrete:
- “Rollouts” = a single end-to-end attempt by the AI system on one example (like a practice run).
- “Scalar reward” = a single number score at the end (like “7/10”), which doesn’t explain why you got that score.
- GEPA uses detailed text feedback (e.g., why a code failed or which facts were missing), not just the final score.
What did they test, and how?
They tested GEPA on four different tasks that represent common AI challenges:
- HotpotQA: Answer complex questions that require reading multiple documents.
- IFBench: Follow strict instructions like “answer only with ‘yes’ or ‘no’.”
- HoVer: Verify claims using evidence gathered across multiple Wikipedia pages.
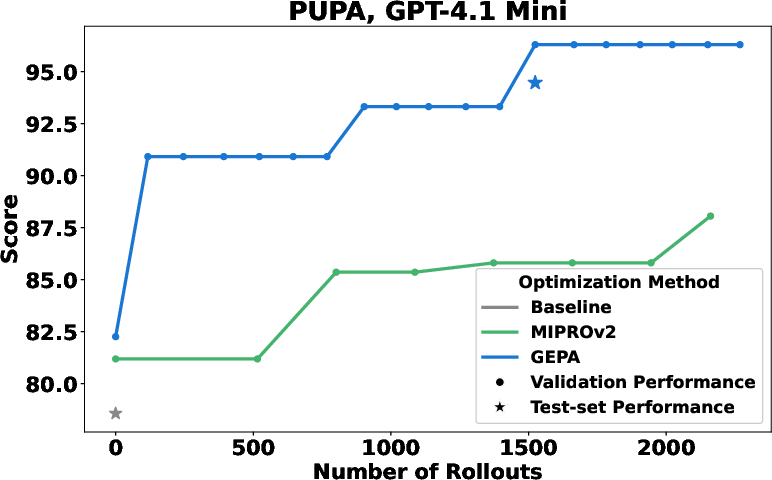
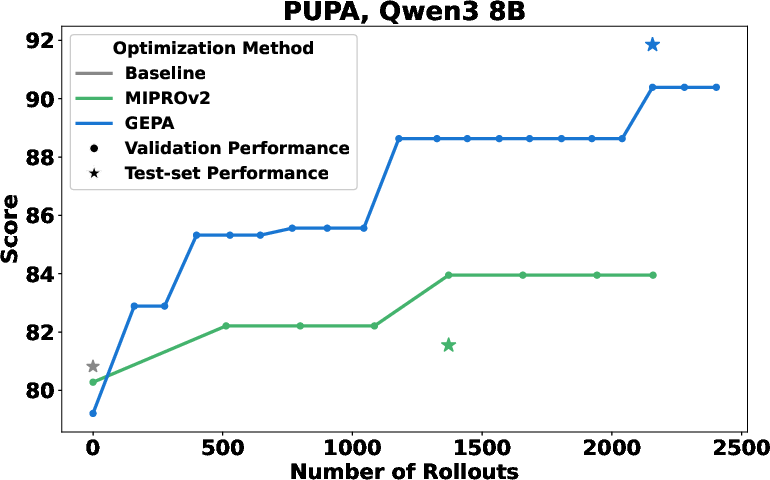
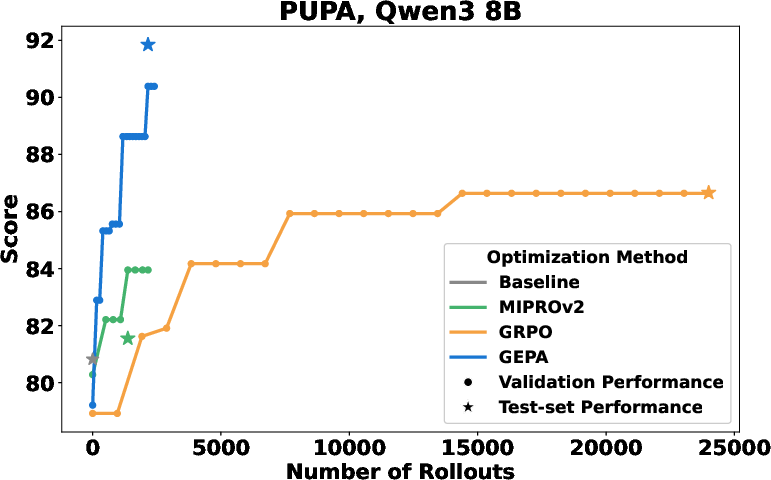
- PUPA: Write helpful answers while keeping personal info private (use trusted and untrusted models carefully).
They compared GEPA to:
- GRPO (a reinforcement learning method): trains model weights using thousands of rollouts.
- MIPROv2 (a popular prompt optimizer): picks instructions and examples using Bayesian search.
They ran these on two models:
- Qwen3-8B (open-source)
- GPT-4.1 mini (commercial)
What did they find, and why does it matter?
Here are the main results, explained simply:
- GEPA outperformed GRPO by about 10% on average and up to 20% on some tasks.
- GEPA needed up to 35 times fewer rollouts than GRPO to reach those gains. In some cases, GEPA matched GRPO’s validation scores with up to 78× fewer “learning” runs.
- GEPA also beat MIPROv2 by more than 10% across both models.
- Just updating instructions (prompts) with reflection can be better than training with reinforcement learning—thanks to the AI’s strong language skills and GEPA’s smart search.
- The Pareto selection strategy mattered a lot. When GEPA always picked the current “best” prompt, it often got stuck. The Pareto strategy kept multiple “best-at-something” prompts and led to higher final performance.
Why this matters:
- Many real-world AI systems run expensive tools (like code compilers or web searches) and can’t afford tens of thousands of training runs. GEPA makes big improvements with small budgets.
- GEPA improves whole AI workflows without changing the model’s internal weights—useful when you can’t finetune big models.
- The method is interpretable: you can read the improved prompts and understand the strategy.
What are the broader implications?
- Faster, cheaper tuning: Organizations can optimize complex, tool-using AI systems with far fewer attempts, saving time and money.
- Better generalization: Because GEPA keeps diverse “winning strategies,” it tends to avoid overfitting to a single trick.
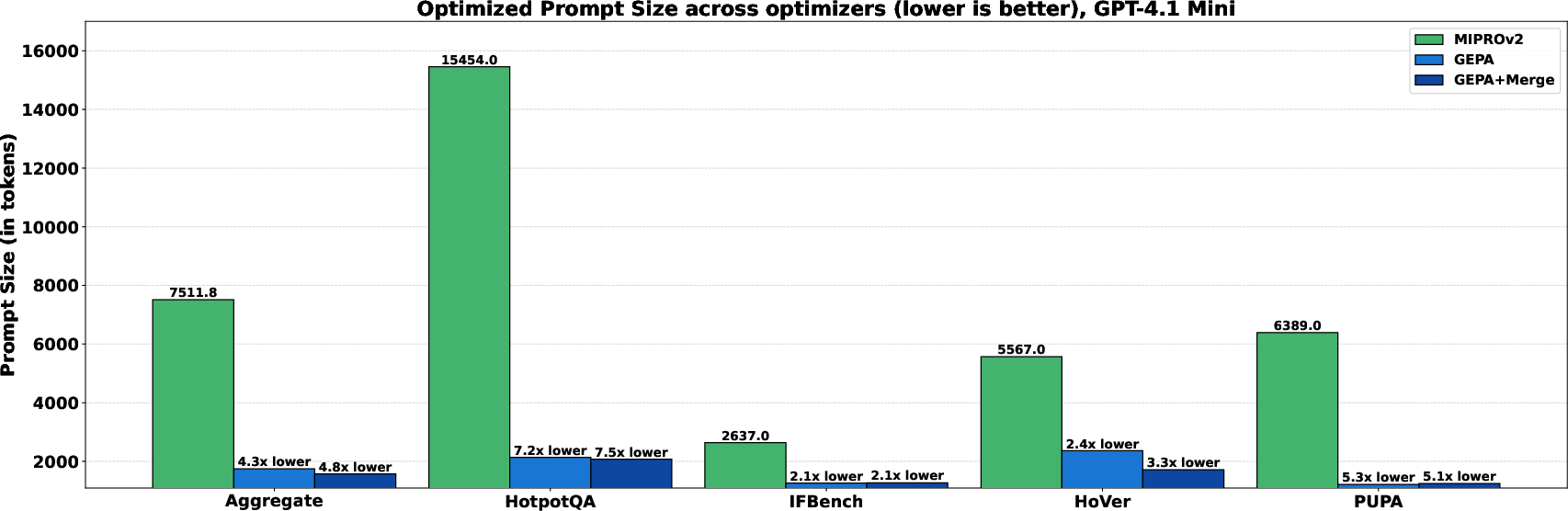
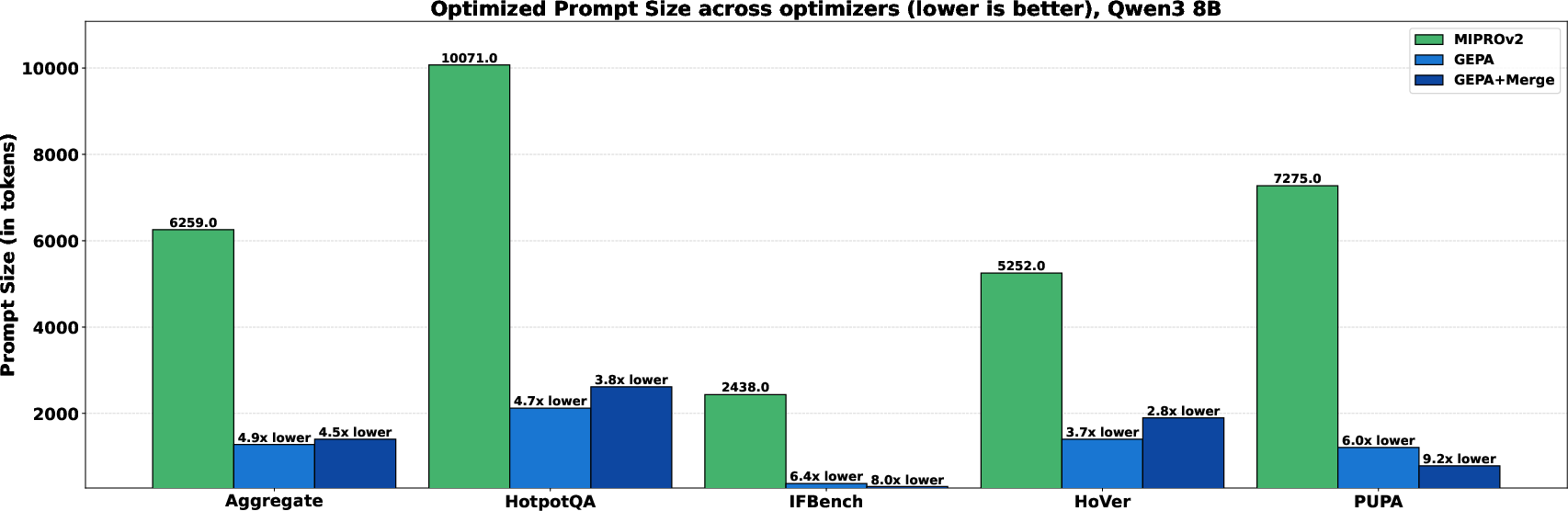
- Human-understandable updates: The improved prompts are readable and often include clear rules and tactics—useful for auditing and sharing best practices.
- Beyond prompts: The idea of “learning from rich text feedback” can be applied to other tasks, like optimizing code at inference time, where GEPA also shows promising early results.
- Future directions: GEPA might get even more efficient by smarter validation (e.g., smaller validation sets or dynamic subsets) and stronger merging of complementary prompts.
In short, the paper shows that teaching AIs to read their own “game logs” and rewrite their playbook can beat traditional training methods, and do so with far fewer practice games.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete research directions suggested by the paper.
- Baseline coverage and fairness:
- Compare GEPA against a broader set of RL and prompt-optimization baselines (e.g., PPO/RLAIF/DPO, RLHF/RLAIF variants, Best-of-N search, ProTeGi/LION/LLM Compiler) under matched budgets.
- Assess whether GRPO performance improves with more/fewer rollouts or different hyperparameters (convergence behavior), rather than fixing at 24k rollouts.
- Token-, time-, and monetary cost accounting:
- Report token usage and wall-clock time per rollout for GEPA (including reflection steps and candidate evaluation on D_pareto), and compare to RL and MIPROv2; sample-efficiency in rollouts may mask higher token costs.
- Statistical robustness:
- Provide multiple runs with distinct seeds, confidence intervals, and statistical tests; current results appear single-run and small-sample, which increases variance and threatens reproducibility.
- Generalization breadth:
- Evaluate on more tasks, domains, and modalities (e.g., math reasoning, code generation beyond preliminary NPUEval/KernelBench, tool-using agents, web interaction, multi-agent scaffolds, non-English languages, domain-shifted datasets) to test external validity.
- Evaluator feedback dependence (μ_f):
- Quantify how much GEPA’s gains depend on having rich evaluator traces; ablate μ_f to raw scalar rewards, partial feedback, or noisy feedback to measure robustness.
- Address risk of label/evaluator leakage (reward hacking): ensure μ_f does not reveal gold answers or rubrics in ways that overfit prompts to evaluators rather than true task competence.
- Reflection reliability and failure modes:
- Characterize when LLM-based reflection misattributes credit or hallucinates fixes; introduce guardrails, calibration, or verification to ensure proposed prompt changes are causally linked to improved behavior.
- Pareto-based candidate selection theory and sensitivity:
- Provide theoretical justification for the Pareto frontier selection, its sample complexity, and scaling with numbers of instances/modules.
- Analyze sensitivity to validation set size and composition; quantify overfitting risk to D_pareto and test generalization with controlled shifts.
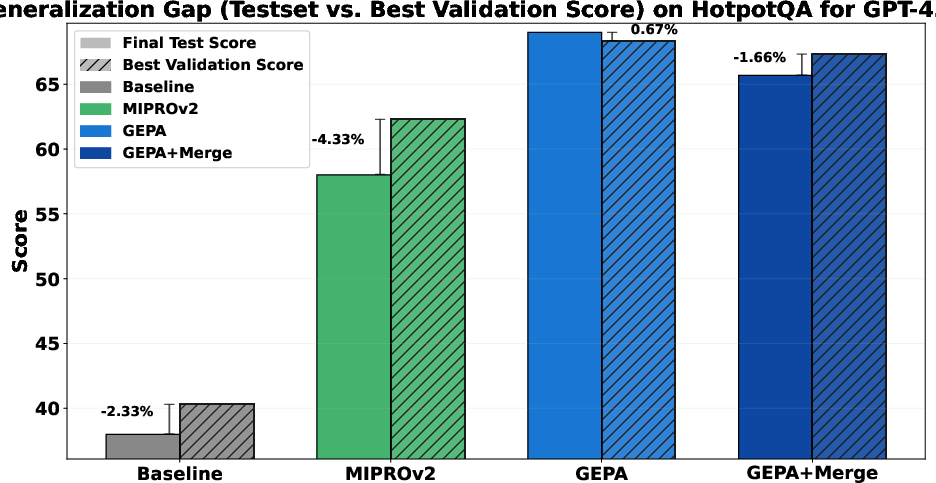
- Merge (System-Aware Merge) design and efficacy:
- The merge procedure is only described in the appendix and shows mixed results (e.g., IFBench degradation). Clarify algorithmic details, failure modes, and criteria for when/where merge helps.
- Multi-objective optimization across metrics:
- For tasks like PUPA (quality vs privacy), move beyond a single aggregated score and optimize a true multi-objective Pareto front across metrics; report trade-off curves and selection policies.
- Module selection strategy:
- Round-robin module selection may be suboptimal; investigate learned or feedback-driven module targeting, per-module credit assignment, and joint/coordinated updates.
- Identity of the reflection LLM:
- Specify and study whether reflection uses the same model as the system or a stronger/different model; analyze cross-model effects (e.g., GPT optimizing Qwen prompts) on outcomes and transfer.
- Hybrid methods with RL:
- Explore using GEPA to warm-start RL (initialization), interleave reflective prompt evolution with weight-space updates, or use RL to refine GEPA-derived prompts.
- Instruction-only vs few-shot examples:
- GEPA optimizes instructions only; compare against variants that also evolve few-shot demonstrations or hybrid instruction+demo approaches with reflective credit assignment.
- Scalability and memory/computation:
- Analyze computation/memory overhead of maintaining large candidate pools and per-instance Pareto scores; provide scalable variants (e.g., dynamic validation subsampling, bounded pool sizes).
- Decoding/inference hyperparameters:
- Study sensitivity to temperature/top-p/top-k across optimizers; standardize or tune consistently to rule out confounds.
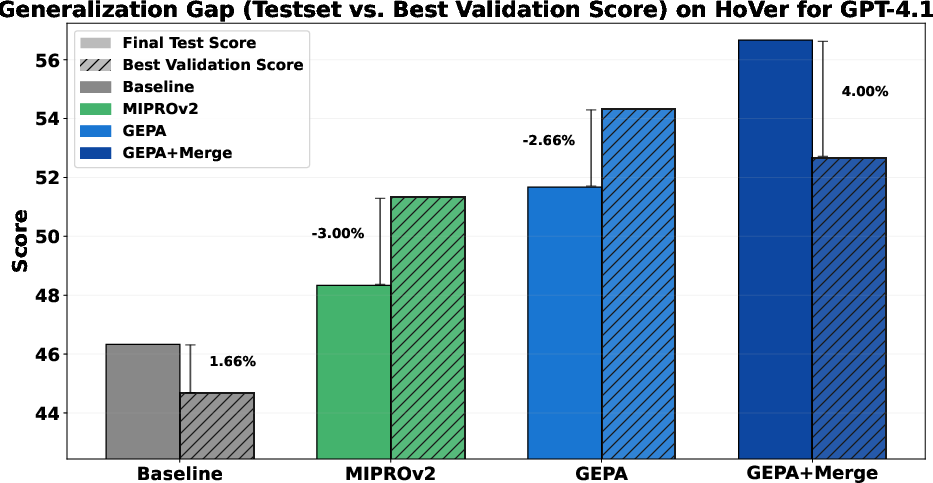
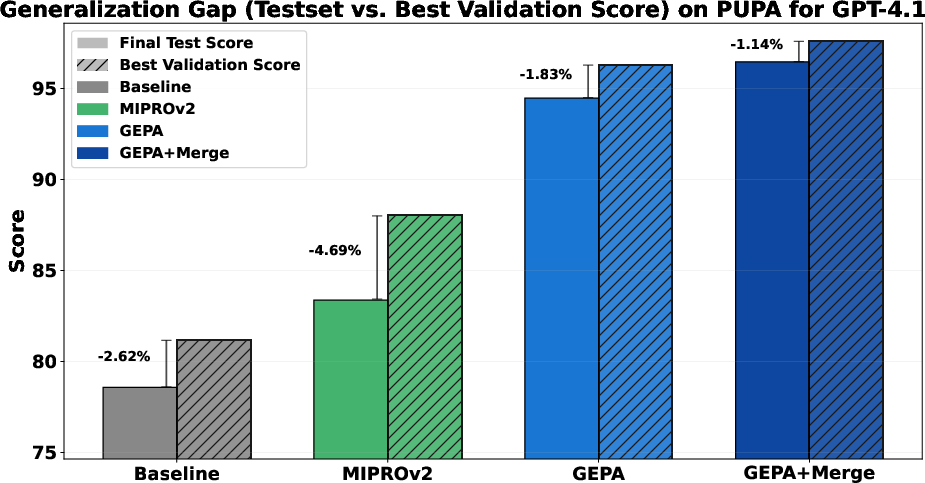
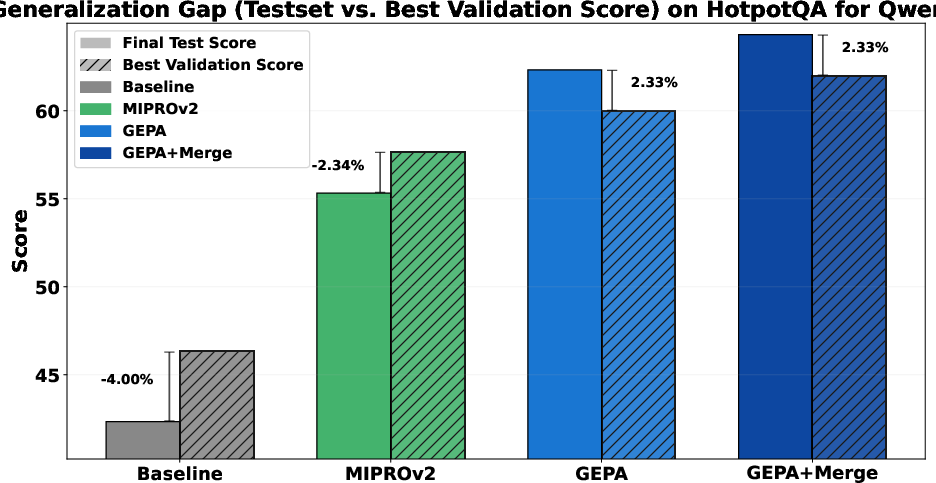
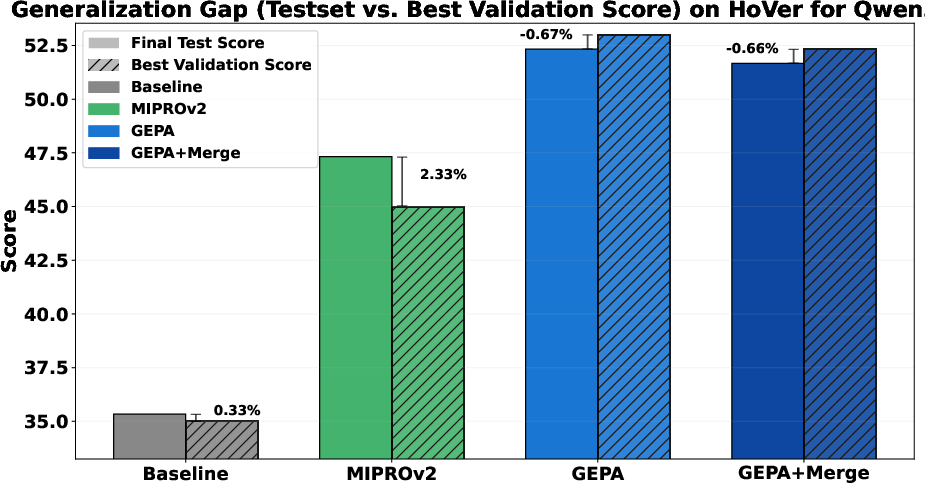
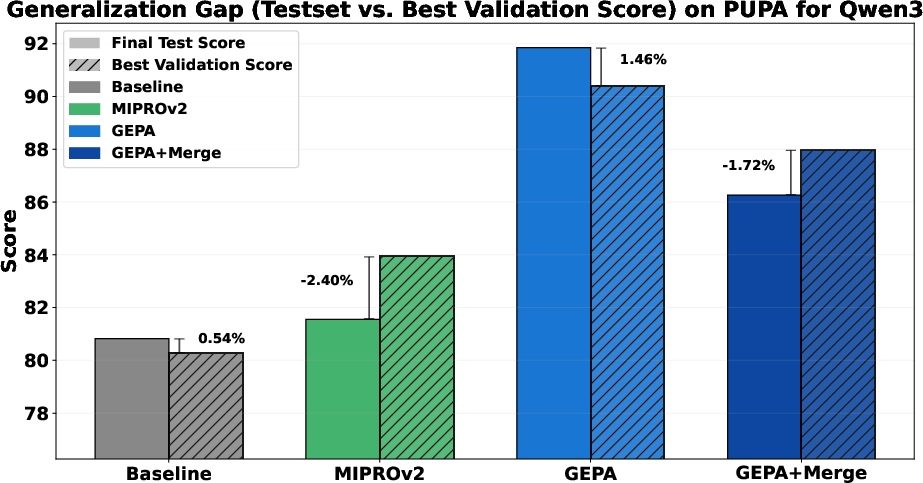
- Test-set generalization gap:
- The paper references a generalization gap study but lacks detailed results; report gaps with statistical uncertainty and explore strategies (e.g., regularization, smaller validation, cross-validation) to reduce overfitting.
- Safety, ethics, and robustness:
- Assess GEPA’s tendency to “game” evaluators, produce brittle prompts, or degrade safety (e.g., privacy trade-offs); include human evaluation and adversarial tests for evaluator exploitation.
- Construction cost and portability of μ_f:
- Provide practical guidelines and templates for building μ_f across tasks (how to extract module-level feedback from evaluators) and measure engineering overhead vs benefits.
- Control-flow and trace complexity:
- Evaluate GEPA on systems with more complex control flow (loops, branching, tool orchestration) and noisy/missing logs to test robustness of reflection and credit assignment.
- Reproducibility gaps:
- Resolve missing/placeholder references (e.g., “mmgrpo_future_ref”) and release full code, prompts, seeds, and hyperparameters for GEPA, MIPROv2, and GRPO configurations.
- Aggregate metrics reporting:
- Clarify how “Aggregate” scores are computed (task weighting, normalization), include per-task variance, and justify aggregation choices to avoid misleading cross-task summaries.
Glossary
- Bayesian optimization: A probabilistic black-box optimization method that models the objective and selects promising candidates via an acquisition function. "It works by jointly optimizing both instructions and demonstrations using Bayesian optimization."
- bf16 precision: A 16‑bit floating-point format (Brain Floating Point) used to reduce memory and improve throughput during training/inference. "using bf16 precision targeting the projection modules ."
- Compound AI system: A modular AI pipeline of one or more LLM invocations interleaved with tools, orchestrated by control flow. "We follow related work in defining a compound AI system as any modular system composed of one or more LLM invocations, potentially interleaved with external tool calls, orchestrated through arbitrary control flow."
- Crossover: An evolutionary search operation that combines components of two candidate solutions to produce a new one. "or by performing crossover between two candidates---and evaluates this new variant on a minibatch of tasks."
- Few-shot demonstrations: Example input-output pairs embedded in the prompt to steer model behavior without weight updates. " is its (system) prompt including instructions and few-shot demonstrations;"
- GEPA: Genetic-Pareto; a reflective prompt optimizer that uses language feedback and multi-objective evolutionary search with Pareto fronts. "We introduce GEPA (Genetic-Pareto), a sample-efficient optimizer for compound AI systems motivated by three core principles: genetic prompt evolution (Section~\ref{sec:genetic_optimization_loop}), reflection using natural language feedback (Section~\ref{sec:reflective_prompt_mutation}), and Pareto-based candidate selection (Section~\ref{sec:pareto_based_selection})."
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm that estimates advantages relative to a group of trajectories to improve policies. "Group Relative Policy Optimization (GRPO) is a reinforcement learning algorithm that estimates advantages in a group-relative manner."
- Gradient checkpointing: A memory-saving technique that recomputes intermediate activations during backpropagation instead of storing them. "Non-reentrant gradient checkpointing is enabled to further reduce memory usage."
- Gradient norm clipping: A stabilization technique that limits the norm of gradients to prevent exploding updates. "and gradient norm clipping of 0.1."
- Illumination strategy: A MAP‑Elites–style search approach that maintains diverse high-performing solutions across behavior niches. "GEPA employs a Pareto-based ``illumination" strategy~\citep{map_elites}"
- Implicit credit assignment: Inferring which components or decisions in a pipeline contributed to success or failure without explicit labels. "LLMs can then leverage these traces via reflection to perform implicit credit assignment, attributing responsibility for the final outcome to the relevant modules."
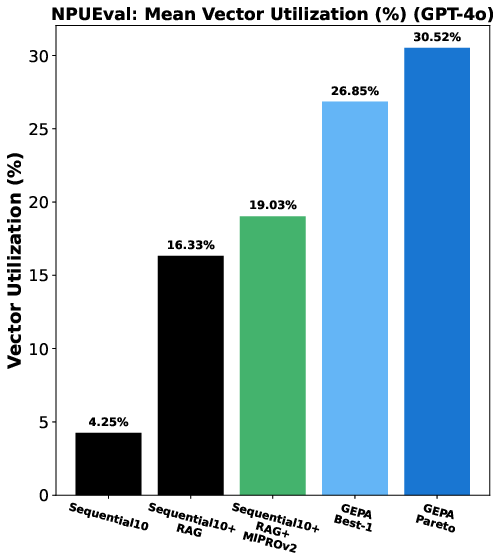
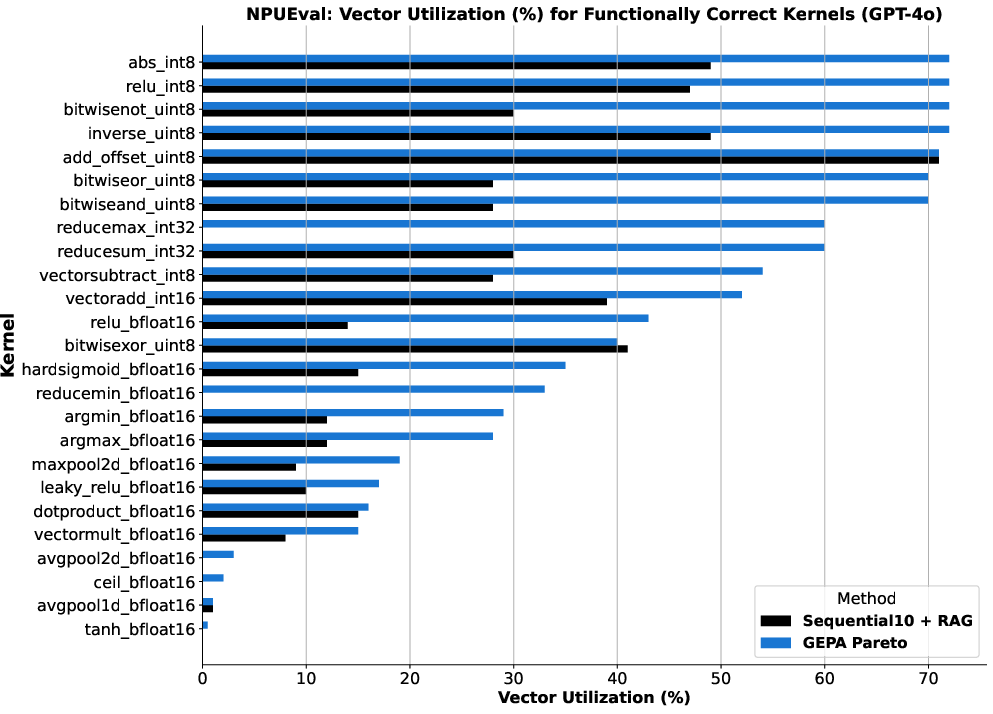
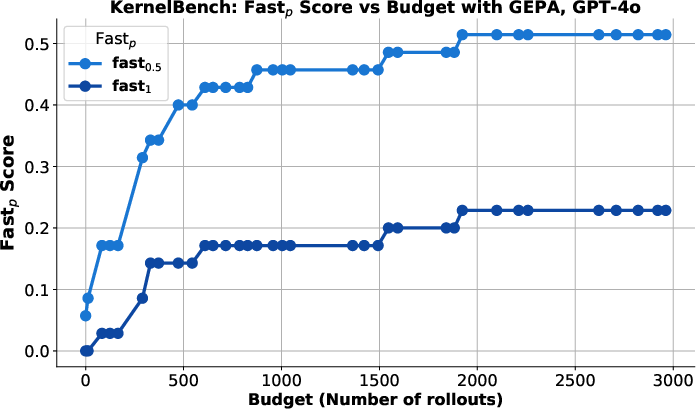
- Inference-time search: Exploration of alternative prompts or strategies during inference rather than training, to improve outputs. "demonstrating GEPAâs use as an inference-time search strategy for code optimization over NPUEval~\citep{npueval} and KernelBench~\citep{kernelbench}."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects trainable low-rank matrices into pretrained layers. "Training employs LoRA~\citep{lora_paper} with rank dimension 16, , and dropout 0.05, using bf16 precision targeting the projection modules ."
- MIPROv2: A prompt optimizer for compound systems that uses Bayesian optimization and TPE to optimize instructions and few-shot examples. "MIPROv2 is a widely used compound AI system prompt optimizer and has been integrated into the DSPy~\citep{dspy} and llama-prompt-ops~\citep{llama_prompt_ops} frameworks."
- Multi-hop reasoning: Solving tasks that require chaining multiple steps or documents to reach a conclusion. "multi-hop reasoning (HotpotQA; \citealt{hotpotqa_bench})"
- Pareto-based candidate selection: Choosing non-dominated candidates that are best on at least one instance to balance exploration and exploitation. "Pareto-based candidate selection (Section~\ref{sec:pareto_based_selection})."
- Pareto frontier: The set of solutions not dominated by any other with respect to multiple objectives (instance-wise scores here). "combine complementary lessons from the Pareto frontier of its own attempts."
- Policy gradients: RL methods that estimate gradients of expected reward with respect to policy parameters. "policy gradients derived from sparse, scalar rewards."
- Reflective prompt evolution: Iteratively improving prompts using natural-language reflection on trajectories, tools, and evaluator traces. "GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning"
- Reflective prompt mutation: A GEPA step that revises a module’s prompt using reflective analysis of traces and feedback. "Reflective Prompt Mutation (Section ~\ref{sec:reflective_prompt_mutation})"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL approach that uses verifiable signals (e.g., unit tests or exact match) as scalar rewards. "reinforcement learning with verifiable rewards (RLVR), including algorithms such as Group Relative Policy Optimization (GRPO)~\citep{grpo_paper}."
- Retrieval-augmented verification: Verifying claims or facts by retrieving supporting documents and reasoning over them. "retrieval-augmented verification (HoVer; \citealt{hover_bench})"
- Reward scale normalization: Normalizing the magnitude of rewards during RL training to stabilize optimization. "reward scale normalization,"
- Rollouts: Executions of a system on task instances to collect trajectories and rewards for learning or evaluation. "require thousands of rollouts to learn new tasks."
- System Aware Merge: A GEPA strategy that merges complementary lessons from different candidates while accounting for system structure. "System Aware Merge (Appendix ~\ref{sec:merge})"
- Tree-Structured Parzen Estimator (TPE): A sequential model-based optimization algorithm used to propose candidates during search. "Candidate assignments are proposed with the Tree-Structured Parzen Estimator (TPE),"
Practical Applications
Overview
The paper introduces GEPA (Genetic-Pareto), a sample-efficient prompt optimizer for compound AI systems. GEPA uses natural-language reflection on system trajectories (reasoning, tool calls, evaluator traces) and Pareto-based candidate selection to iteratively evolve module prompts. Across multi-hop reasoning, instruction-following, privacy-aware delegation, and retrieval verification, GEPA outperforms GRPO (a reinforcement learning method) by ~10% on average, with up to 35× fewer rollouts, and beats the leading prompt optimizer MIPROv2. The method is model-agnostic and deployable for systems built on open-source or commercial LLMs, especially where fine-tuning is impractical or budgets are constrained.
Below are practical applications derived from GEPA’s findings, methods, and innovations, organized by deployment horizon.
Immediate Applications
The following applications are deployable with current tooling and practices, especially for organizations already running LLM-based pipelines and evaluators.
- PromptOps for compound AI pipelines
- Sectors: software, customer service, content operations, research platforms
- Application: Integrate GEPA into existing orchestration frameworks (e.g., ReAct-style agents, LangChain/DSPy pipelines) to iteratively evolve prompts for modules like retrieval, summarization, verification, or rewriting, using reflective feedback and Pareto-based selection.
- Tools/products/workflows: GEPA SDK or plugin for orchestration frameworks; “Pareto Board” for candidate tracking; round-robin module updates; configurable minibatch rollouts.
- Assumptions/dependencies: Serialized system traces; a capable base LLM; access to evaluator functions and scores.
- Budget-efficient optimization for closed-weight or expensive models
- Sectors: enterprise AI, SaaS platforms
- Application: Replace or complement reinforcement learning fine-tuning with GEPA to improve task performance under tight rollout budgets, especially with commercial models (e.g., GPT-4.1 mini).
- Tools/products/workflows: “GEPA runner” as an internal PromptOps service; budget-aware search policies.
- Assumptions/dependencies: API rate limits and cost management; reliable eval metrics.
- Multi-hop retrieval tuning (HotpotQA/HoVer analogs)
- Sectors: legal e-discovery, media intelligence, pharma R&D, scientific literature review
- Application: Evolve query-writing and summarization prompts to systematically retrieve missing but logically linked documents across multiple hops.
- Tools/products/workflows: Query-writer prompt evolution; feedback integration listing “missing” gold docs; retrieval evaluation dashboards.
- Assumptions/dependencies: Document corpora; corpus-specific evaluators; robust retrievers.
- Instruction compliance and output constraint enforcement (IFBench analog)
- Sectors: compliance, customer support, marketing, education tech
- Application: Add a second-stage “constraint rewriter” module and evolve its prompt to satisfy strict formatting rules (e.g., “answer yes/no,” repetition counts, token limits).
- Tools/products/workflows: Constraint rubric evaluators; policy-driven rewriter module; ruleset libraries.
- Assumptions/dependencies: Clear constraint definitions; evaluator traces describing satisfied/failed constraints.
- Privacy-conscious model delegation (PUPA analog)
- Sectors: healthcare, finance, HR, legal
- Application: Route tasks between trusted/untrusted models with prompt-evolved query/response rewriters that minimize PII leakage while maintaining utility.
- Tools/products/workflows: PII detectors as feedback functions; privacy score breakdown in evaluators; privacy-aware routing policies.
- Assumptions/dependencies: Accurate PII detection; privacy policies; audit logging; human oversight for sensitive cases.
- Inference-time code optimization search
- Sectors: software development, ML systems, HPC/AI infra
- Application: Use GEPA to iteratively optimize code snippets or kernels at inference time using evaluator traces (compiler errors, benchmark performance) to propose fixes and improvements.
- Tools/products/workflows: CI step integrating unit tests and profiling harnesses; “feedback adapters” parsing build/runtime logs; Pareto selection across test suites.
- Assumptions/dependencies: Reliable test/profiling environments; reproducible builds; sandboxed execution.
- Evaluator-trace-driven observability and debugging
- Sectors: engineering productivity, platform teams
- Application: Instrument evaluators (unit tests, content filters, graders) to emit structured feedback_text; feed this into GEPA’s reflective mutation to accelerate diagnosis and module-level credit assignment.
- Tools/products/workflows: EvalTrace adapters; standardized feedback schemas; trace visualization dashboards.
- Assumptions/dependencies: Access to detailed evaluator logs; secure logging/storage.
- A/B prompt portfolio managed via Pareto frontier
- Sectors: multi-tenant AI services, personalization
- Application: Maintain a diverse set of Pareto-optimal prompts tuned to specific instance types or user segments; stochastically select effective candidates by frequency of “wins.”
- Tools/products/workflows: Candidate frequency tracking; instance-type routing; prompt portfolio management.
- Assumptions/dependencies: Stable instance segmentation; monitoring generalization vs overfitting.
- Rapid prototyping of agent modules
- Sectors: automation, robotics (simulated), IT operations
- Application: Apply GEPA’s round-robin module selection and reflective updates to quickly refine tools such as entity extraction, plan generation, or action selection modules in compound agents.
- Tools/products/workflows: Agent scaffolds with module-level prompts; iterative minibatches; per-module feedback functions.
- Assumptions/dependencies: Clear module interfaces; deterministic tool APIs.
- Cost reduction and sustainability benefits
- Sectors: cloud cost management, sustainability
- Application: Reduce optimization rollouts by 10–35× vs RL-based approaches; lower energy use and compute bills for model adaptation.
- Tools/products/workflows: Budget-aware rollout policies; cost dashboards; carbon accounting (optional).
- Assumptions/dependencies: Accurate rollout tracking; ops discipline; baseline cost benchmarks.
- Education and tutoring systems with constraint adherence
- Sectors: education technology
- Application: Evolve prompts for curriculum-aware tutors to adhere to pedagogical constraints (hint levels, problem steps, formative feedback) and multi-step retrieval of example materials.
- Tools/products/workflows: Rubric-based evaluators for educational quality; persona modules; content filters.
- Assumptions/dependencies: Human oversight; age-appropriate safeguards; curated content.
- Content moderation and redaction workflows
- Sectors: social platforms, content publishing
- Application: Optimize rewriter prompts to enforce moderation policies (redaction of PII, removal of banned content) without overly degrading utility.
- Tools/products/workflows: Policy evaluators; audit logs; Pareto selection balancing quality vs safety.
- Assumptions/dependencies: Reliable moderation rules; appeal/escalation pathways.
Long-Term Applications
These applications require further research, scaling, formalization, or organizational change before broad deployment.
- Continuous, self-evolving production agents
- Sectors: customer service, operations, devops
- Vision: Closed-loop systems that learn from live rollouts (with safety gating) and continually evolve prompts, maintaining strategy diversity via Pareto selection.
- Dependencies: Safe online learning frameworks; drift detection; human-in-the-loop checkpoints; robust rollback.
- Hybrid RL + GEPA training pipelines
- Sectors: foundation model ops, advanced AI systems
- Vision: Combine weight-space RL (e.g., GRPO) and reflective prompt evolution to leverage rich language feedback and gradient updates jointly.
- Dependencies: Offline datasets; scheduling strategies; interference mitigation; compute orchestration.
- Standardization of evaluator-trace interfaces
- Sectors: software tooling, policy/regulation, audits
- Vision: A cross-industry standard (DSL/schema) for feedback_text and module-level evaluator signals to enable interoperable PromptOps and transparent audits.
- Dependencies: Consortium buy-in; privacy/security compliance; reference implementations.
- Formal privacy guarantees in delegation
- Sectors: healthcare, finance, public sector
- Vision: Integrate GEPA with formal privacy techniques (e.g., differential privacy, robust redaction proofs) in routing systems to guarantee leakage bounds while preserving utility.
- Dependencies: Verified PII detection; DP mechanisms; legal/regulatory alignment.
- Instruction library transfer across domains
- Sectors: model operations, enterprise AI
- Vision: Curate and reuse reflectively evolved instruction sets across tasks and domains, enabling faster adaptation and reduced rollout costs.
- Dependencies: Metadata-taxonomy for tasks; versioning; evaluation of transfer performance.
- Autotuning compilers and GPU kernel optimization via GEPA
- Sectors: HPC, AI infrastructure, energy efficiency
- Vision: Systematically evolve code and kernel prompts using performance evaluators to optimize throughput/latency/energy across hardware targets.
- Dependencies: Stable benchmarking harnesses; safety sandboxing; robust search spaces; hardware heterogeneity support.
- Safety alignment via evaluator feedback
- Sectors: platform safety, policy/regulation
- Vision: Use rich safety evaluators (toxicity, hallucination risk, misuse patterns) to drive reflective evolution of safety prompts and policies.
- Dependencies: High-quality safety evaluators; red-team data; policy governance; incident response integration.
- Adaptive multi-agent coordination with strategy diversity
- Sectors: logistics, autonomous systems (simulated), operations research
- Vision: Maintain multiple Pareto-optimal strategies for coordination/planning, adaptively selecting tactics per instance/region/resource mix.
- Dependencies: Simulator fidelity; multi-objective evaluators; real-time selection policies.
- Low-resource language/domain adaptation
- Sectors: global NGOs, public sector, local media
- Vision: Use GEPA’s sample efficiency to adapt prompts for low-resource languages or niche domains where labeled data and budgets are scarce.
- Dependencies: Local evaluators; culturally appropriate policies; community partnerships.
- Green AI initiatives
- Sectors: sustainability, corporate ESG
- Vision: Replace or reduce heavy RL-based adaptations with GEPA to lower energy footprints and compute costs while maintaining performance gains.
- Dependencies: Measurement frameworks; ESG reporting; procurement policies recognizing compute efficiency.
- Regulated financial document retrieval and compliance assistants
- Sectors: finance, insurance, accounting
- Vision: Evolve multi-hop retrieval and constraint-compliant responses for regulated disclosures, with transparent evaluator traces for audits.
- Dependencies: Compliance teams; legal sign-off; robust evidence tracking; audit trails.
Cross-cutting assumptions and dependencies
- Access to detailed system traces (prompts, reasoning, tool calls) and evaluator feedback; secure storage and privacy compliance.
- A capable base LLM and tool APIs; predictable inference latency/costs.
- Well-defined, verifiable metrics (exact match, F1, pass rates, PII leakage scores, performance benchmarks).
- Monitoring to prevent overfitting to validation subsets and to maintain generalization on held-out/test data.
- Human-in-the-loop oversight for sensitive domains (healthcare, finance, minors).
- Organizational readiness for PromptOps (versioning, CI/CD for prompts, candidate tracking, rollback procedures).
Collections
Sign up for free to add this paper to one or more collections.