- The paper introduces OmniClean, a novel visually debiased evaluation suite that accurately differentiates true omni-modal integration from unimodal shortcuts.
- The paper details a three-stage post-training protocol—combining balanced bi-modal SFT, RLVR, and self-distillation SFT—that significantly enhances multimodal reasoning.
- The paper demonstrates that controlling unimodal shortcuts through leakage-aware evaluation is critical for achieving reliable omni-modal performance gains.
Boosting Omni-Modal LLMs: Staged Post-Training with Visually Debiased Evaluation
Motivation and Problem Statement
Omni-modal LLMs aspire to unify audio, visual, and textual reasoning within a single architecture, yet current benchmark methodologies often fail to distinguish unimodal shortcut exploitation from genuine multi-modal evidence integration. Specifically, many audio-visual-language benchmarks yield high scores when visual evidence alone suffices, conflating unimodal dominance with intended omni-modal capability. The paper systematically audits this evaluation bias, introduces the OmniClean testbed—an operational visually debiased subset constructed via visual-only probing—and quantitatively studies post-training strategies on Qwen2.5-Omni-3B to answer whether balanced bimodal SFT, RLVR, and self-distilled synthetic supervision collectively facilitate true omni-modal gains when visual shortcuts are controlled.
Visual Leakage Audit and OmniClean Dataset Construction
The core technical contribution is a rigorous query-level visual-only screening over nine contemporary omni-modal benchmarks. Each query is evaluated by withholding audio and testing whether a strong vision-LLM (Qwen3-VL-30B-A3B-Thinking) can recover the ground-truth answer from vision plus text alone. Queries passing this probe are excluded from the evaluation set, producing OmniClean—a visually debiased evaluation suite comprising 8,551 retained queries out of 16,968 audited, spanning diverse tasks including temporal reasoning, intent recognition, counting, and open-ended multimodal QA.
OmniClean intentionally does not guarantee exclusive audio dependence but operationally suppresses the impact of visual shortcuts, offering a more robust basis for benchmarking omni-modal progress.
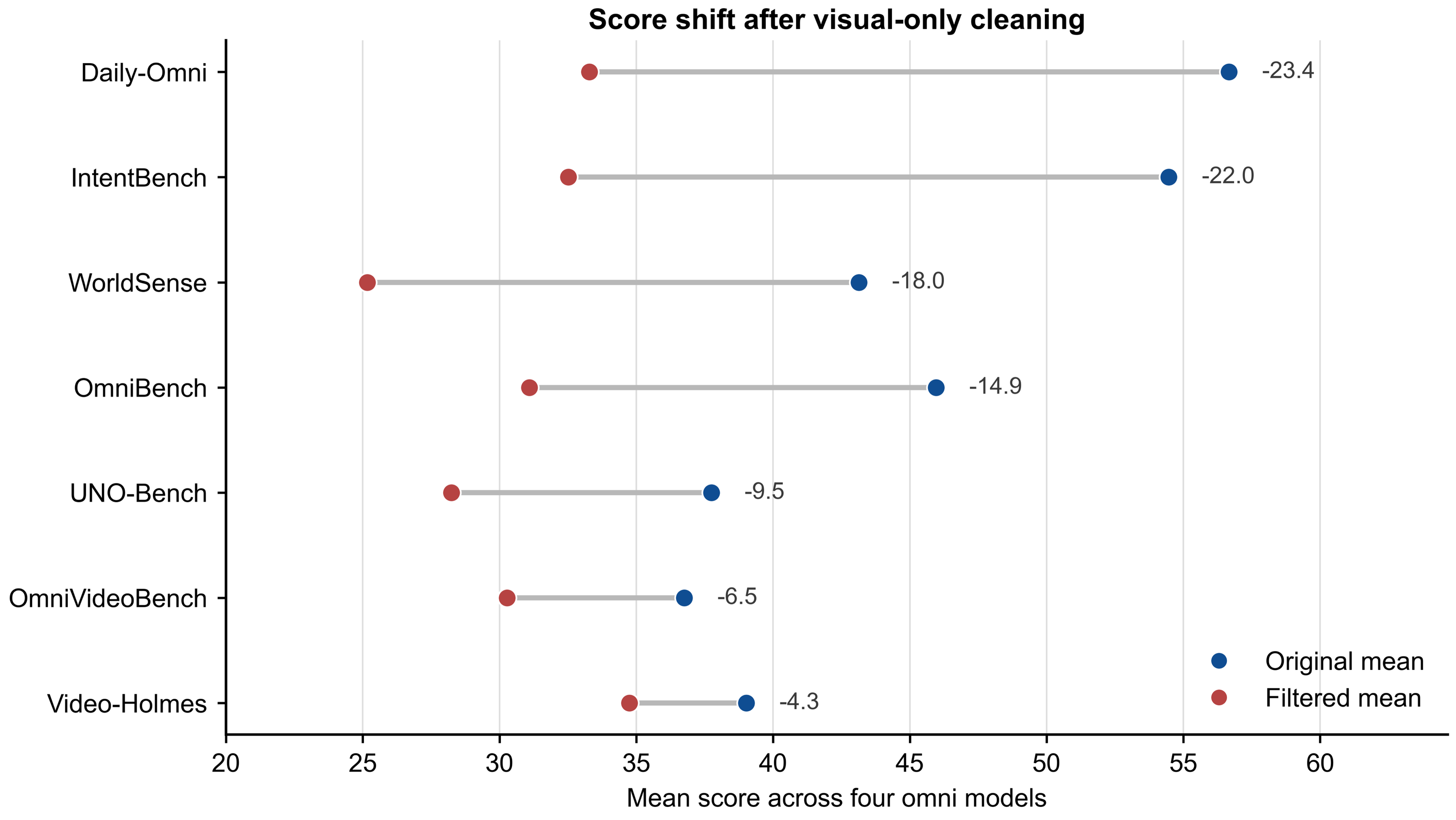
Figure 1: Score distributions before and after query-level cleaning for benchmarks with both original and filtered score views, reflecting the magnitude of visual leakage.
Post-cleaning results show large benchmark-dependent drops, e.g., Daily-Omni and OmniBench scores decline sharply (Δ >20 points), confirming substantial visual leakage. In contrast, Video-Holmes and AV-Odyssey retain more of their unimodal challenge. Correlation analysis further reveals that cleaned scores are much less predictable from vision-reference model strength—especially for WorldSense, Daily-Omni, and IntentBench—underscoring the necessity of leakage-aware evaluation.

Figure 2: Correlation shifts after cleaning; visual leakage removal decreases vision/audio reference score correlations, clarifying modality-specific contributions.
Staged Post-Training: OmniBoost Protocol Analysis
The OmniBoost post-training strategy is decomposed into three stages:
- Stage 1: Balanced Bi-modal SFT
Mixed supervised fine-tuning over audio-text, image-text, video-text, and pure-text from 1B output tokens each. This baseline controls for aggregate unimodal competence.
- Stage 2: Mixed-Modality RLVR
Reinforcement learning with verifiable rewards (DAPO) using curated queries requiring explicit audio-visual-text evidence integration. The mixture design prioritizes audio-video-text (54.8%) and audio-image-text, distributing query categories to optimize for omni-modal reasoning.
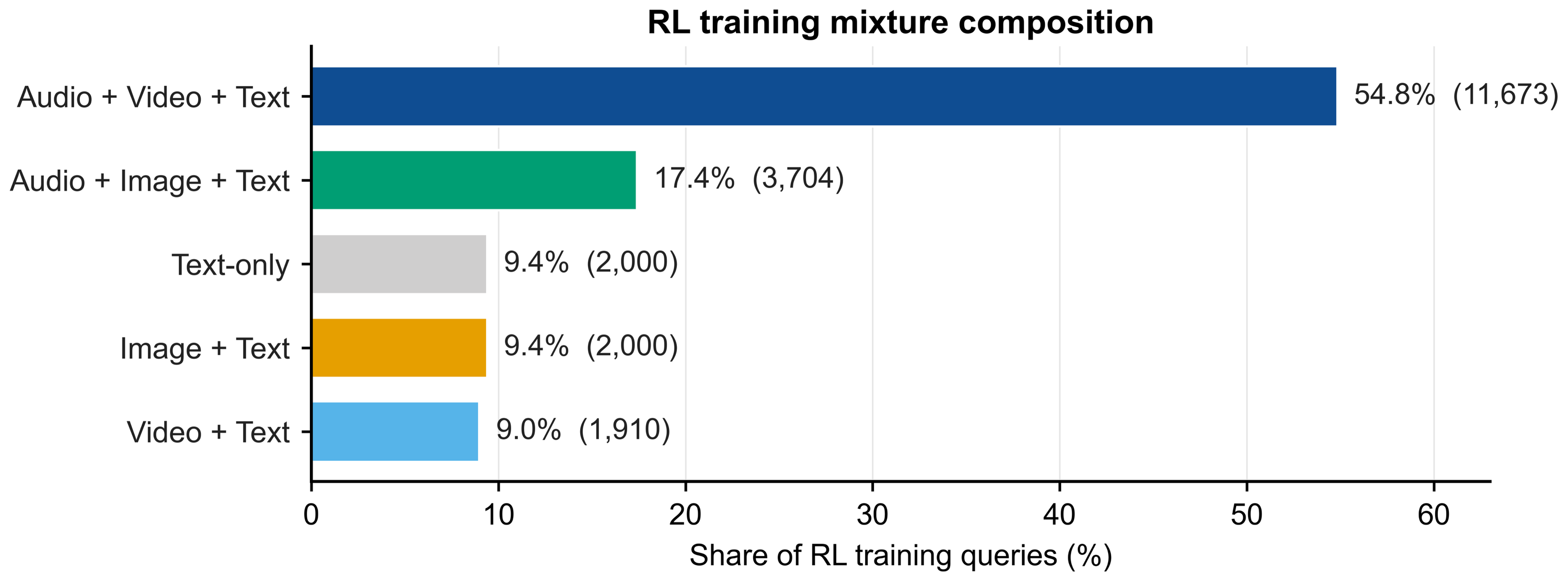
Figure 3: The composition of RLVR training mixture by modality categories, highlighting the predominance of audio-video-text queries.
- Stage 3: Self-Distillation SFT with Synthetic Queries
Synthetic query construction leverages entity-relation scaffolds synthesized from segmented audio and visual captions (Step-Audio-R1, Qwen3-VL, LLaVA-Video), structured by gpt-oss-120b, yielding hard-matchable QA pairs. Reasoning traces are subsequently generated from the RLVR checkpoint and filtered in quality-control passes (F1–F3), ensuring retained queries are neither trivial nor perception-defective.

Figure 4: Illustrates the synthetic query pipeline, showing segmentation, captioning, entity graph construction, and synthetic QA generation process.
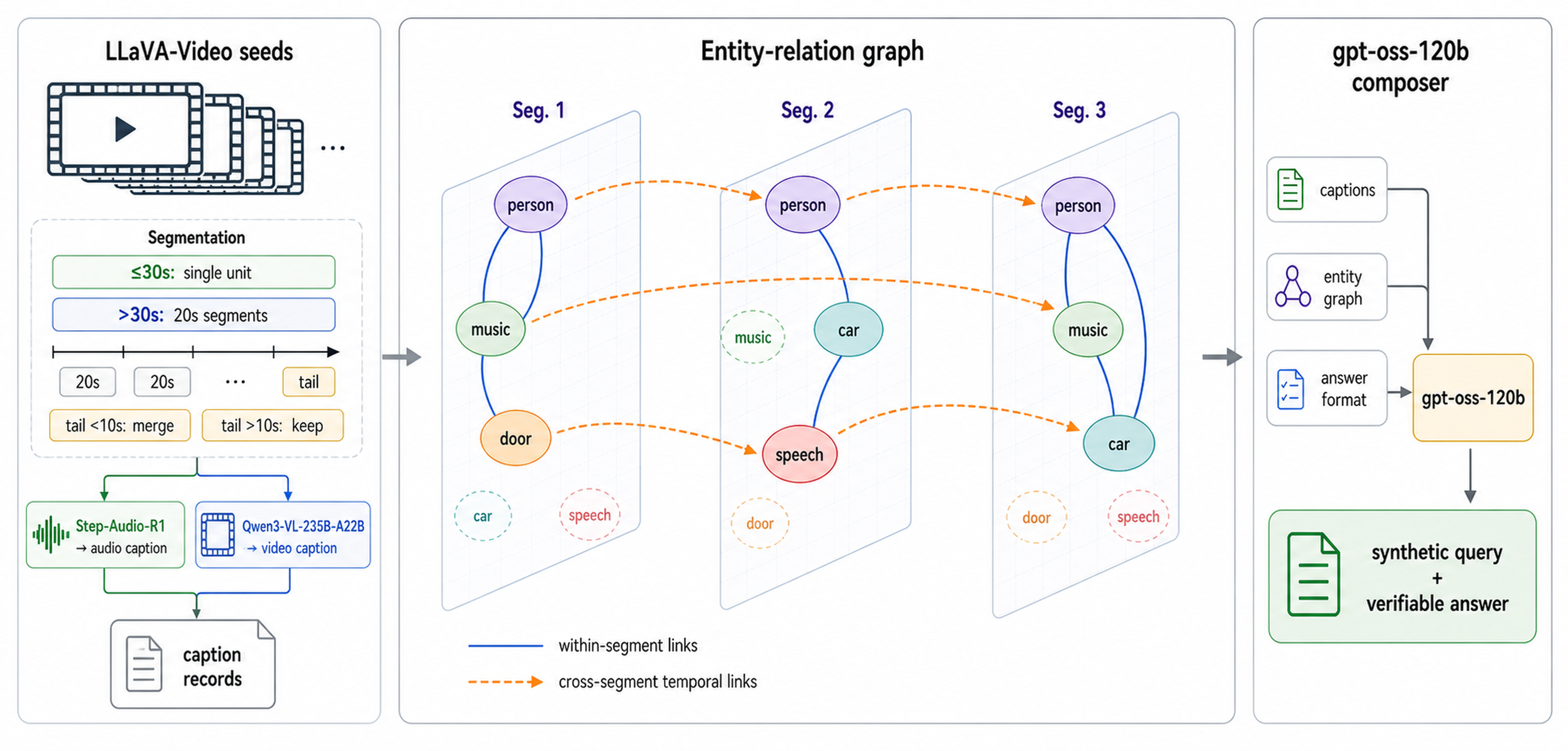
Figure 5: Detailed depiction of the synthetic query construction process: segmentation/recording, entity-graph design, and structured prompt synthesis.
Quantitative Results and Benchmark Analysis
Macro average scores across OmniClean demonstrate:
- Stage 1 (Bi-modal SFT): 26.49
- Stage 2 (RLVR): 31.43
- Stage 3 (Self-distillation SFT): 31.03
The RLVR stage delivers the first broad aggregate improvement, particularly in complex reasoning tasks (Video-Holmes, OmniBench), whereas self-distillation SFT redistributes strength towards larger query sets (AV-Odyssey, Daily-Omni) and achieves strongest query-weighted average (32.15), surpassing larger references such as Qwen3-Omni-30B-A3B-Instruct despite no external teacher distillation.
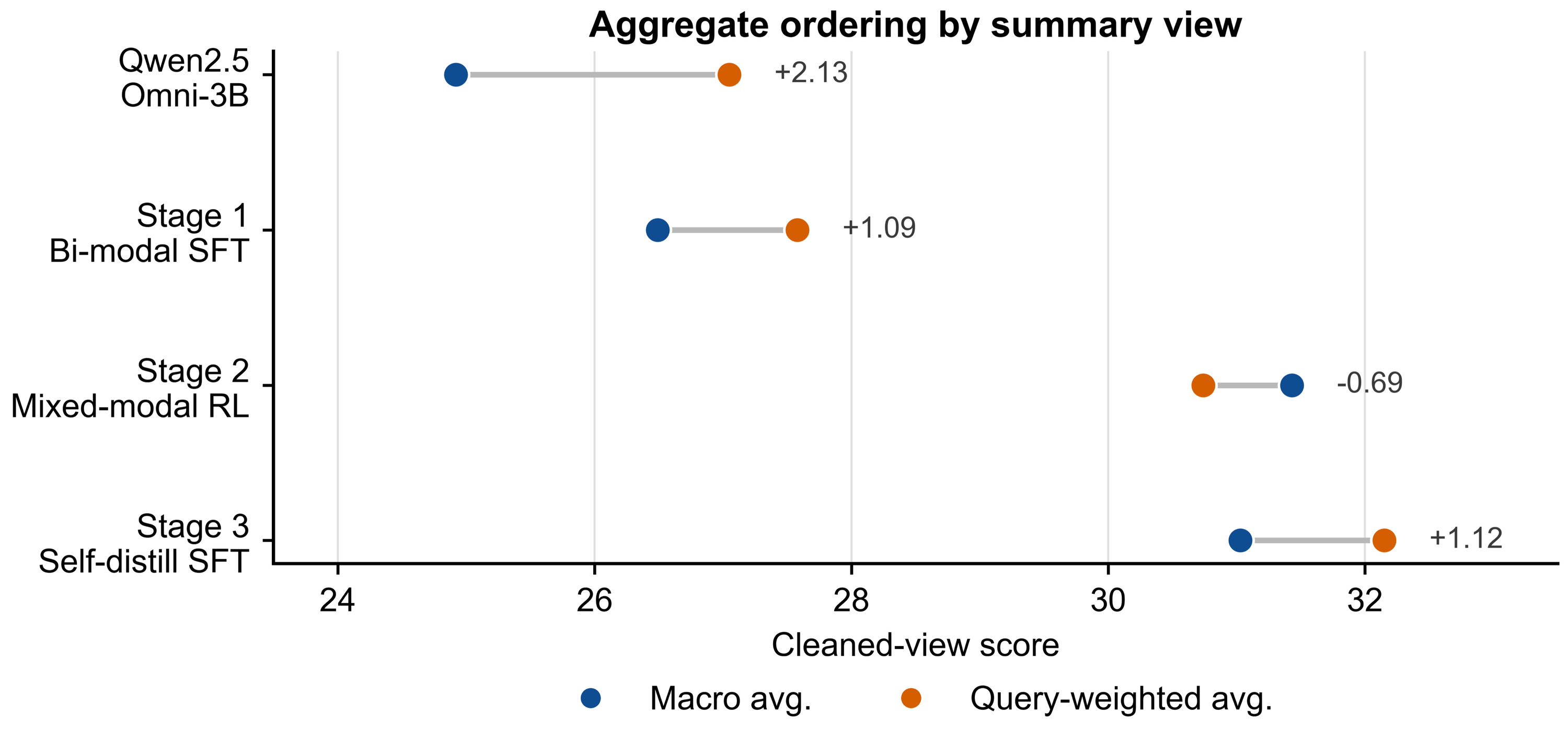
Figure 6: Macro and query-weighted performance aggregation for Qwen2.5-Omni-3B and three OmniBoost stages, visualizing stage order reversal under different aggregation views.
Self-distillation ablations with filtered synthetic datasets further show that even direct SFT from retained synthetic data (without RLVR lineage) outperforms the baseline, with strongest macro gains in challenging benchmarks (Video-Holmes, Daily-Omni, UNO-Bench).
Implications and Future Directions
The empirical findings assert that traditional bimodal SFT does not suffice for robust omni-modal gains when visual leakage is suppressed. Explicit omni-modal RLVR optimization is necessary for consistent improvement, while self-distillation on synthetic queries amplifies pattern stabilization and redistributes strengths across benchmarks. The study delineates that visual leakage-aware evaluation is critical to meaningful progress and recommends releasing OmniClean for broader adoption.
Practically, these staged post-training protocols indicate that small-scale omni-modal models (3B) can approach the performance of much larger open-source references via careful optimization and synthetic supervision. Theoretically, this work identifies the need for benchmark construction to control unimodal leakage and isolate true multimodal evidence integration. Future directions include extending leakage audits to other modalities (e.g., audio-dominant queries), refining synthetic query pipelines with richer entity dynamics, and exploring cross-lineage transferability in self-distillation scenarios.
Conclusion
The paper introduces OmniClean as a robust visually debiased benchmark suite and demonstrates, through systematic staged post-training, that genuine omni-modal progress emerges only when evaluation protocols rigorously control for unimodal shortcuts. Mixed-modality RLVR is necessary for broad gains, while self-distillation on synthetic queries provides complementary improvement. These methodologies and datasets lay a principled foundation for evaluating and training omni-modal LLMs with true cross-modal integration, informing both practical deployment and future methodological advances in the field.

