Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
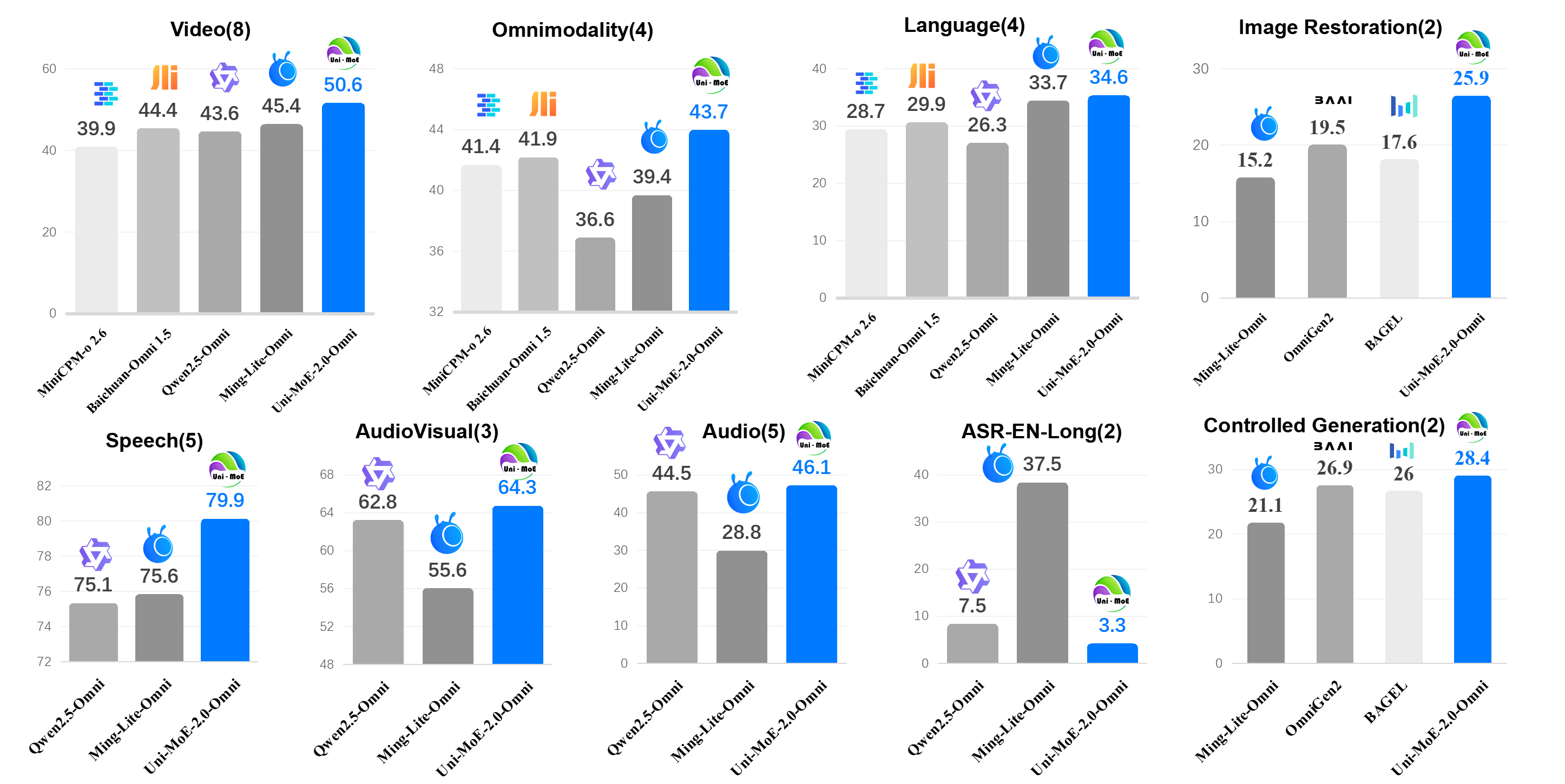
Abstract: We present Uni-MoE 2.0 from the Lychee family. As a fully open-source omnimodal large model (OLM), it substantially advances Lychee's Uni-MoE series in language-centric multimodal understanding, reasoning, and generating. Based on the Qwen2.5-7B dense architecture, we build Uni-MoE-2.0-Omni from scratch through three core contributions: dynamic-capacity Mixture-of-Experts (MoE) design, a progressive training strategy enhanced with an iterative reinforcement strategy, and a carefully curated multimodal data matching technique. It is capable of omnimodal understanding, as well as generating images, text, and speech. Architecturally, our new MoE framework balances computational efficiency and capability for 10 cross-modal inputs using shared, routed, and null experts, while our Omni-Modality 3D RoPE ensures spatio-temporal cross-modality alignment in the self-attention layer. For training, following cross-modal pretraining, we use a progressive supervised fine-tuning strategy that activates modality-specific experts and is enhanced by balanced data composition and an iterative GSPO-DPO method to stabilise RL training and improve reasoning. Data-wise, the base model, trained on approximately 75B tokens of open-source multimodal data, is equipped with special speech and image generation tokens, allowing it to learn these generative tasks by conditioning its outputs on linguistic cues. Extensive evaluation across 85 benchmarks demonstrates that our model achieves SOTA or highly competitive performance against leading OLMs, surpassing Qwen2.5-Omni (trained with 1.2T tokens) on over 50 of 76 benchmarks. Key strengths include video understanding (+7% avg. of 8), omnimodallity understanding (+7% avg. of 4), and audiovisual reasoning (+4%). It also advances long-form speech processing (reducing WER by 4.2%) and leads in low-level image processing and controllable generation across 5 metrics.

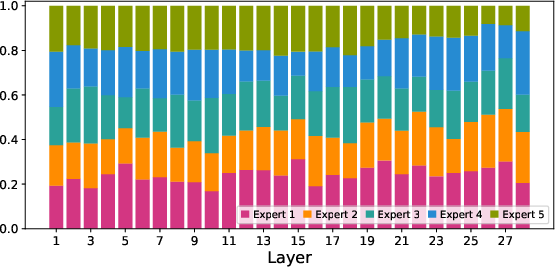
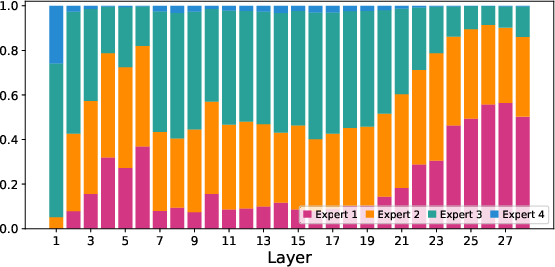
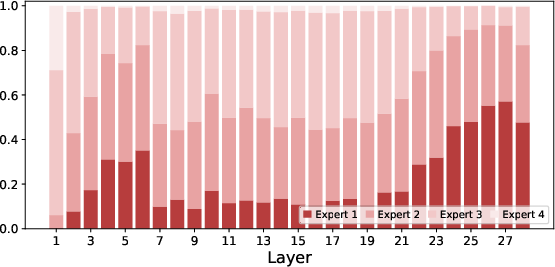
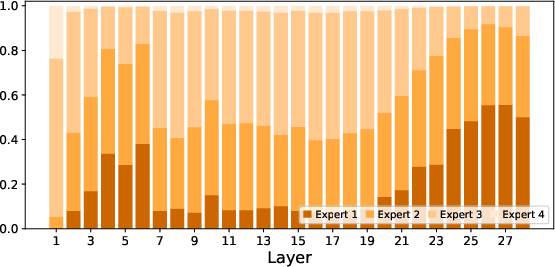
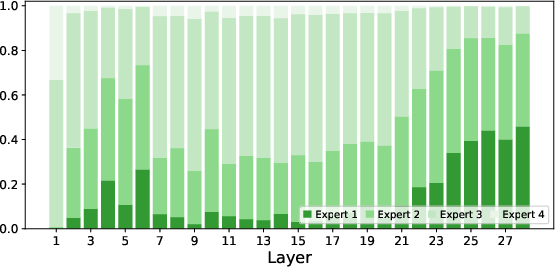
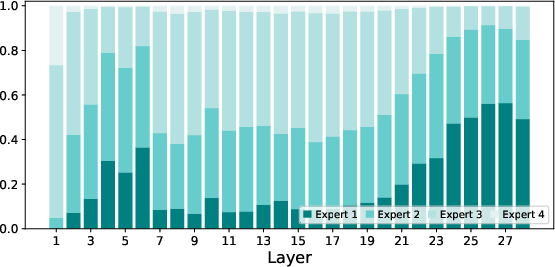
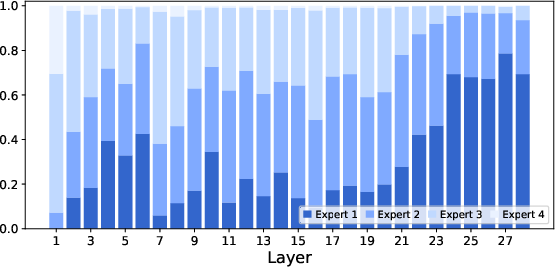
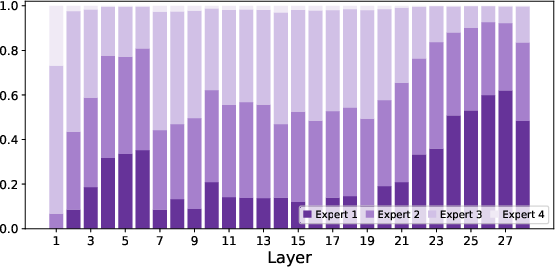

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Uni-MoE-2.0-Omni”
1. What is this paper about?
This paper introduces Uni-MoE-2.0-Omni, a powerful, open-source AI model that can understand and create many kinds of content—text, images, audio, and video. Think of it as a language-centered “all-in-one” brain that can listen, look, talk, and draw. The researchers focus on making the model good at both understanding context and generating high-quality outputs, while keeping it efficient to train and use.
2. What questions are the researchers trying to answer?
The paper asks clear, practical questions:
- How can we build one model that understands different types of data (words, pictures, sounds, videos) and can also create them?
- How do we make that model efficient and stable to train, so it doesn’t need huge amounts of data or computing power?
- How do we help different inputs, like audio and video, line up correctly in time and space so the model understands connections between them?
- How can we use “specialist” parts inside the model (called experts) to handle different tasks well?
- Can we do all this while keeping the model open-source so others can use and improve it?
3. How does the model work? (Explained simply)
The design uses language as the “glue” that connects everything. Just like people often use words to explain pictures or sounds, the model uses text to coordinate different tasks. Here are the main pieces, with simple comparisons:
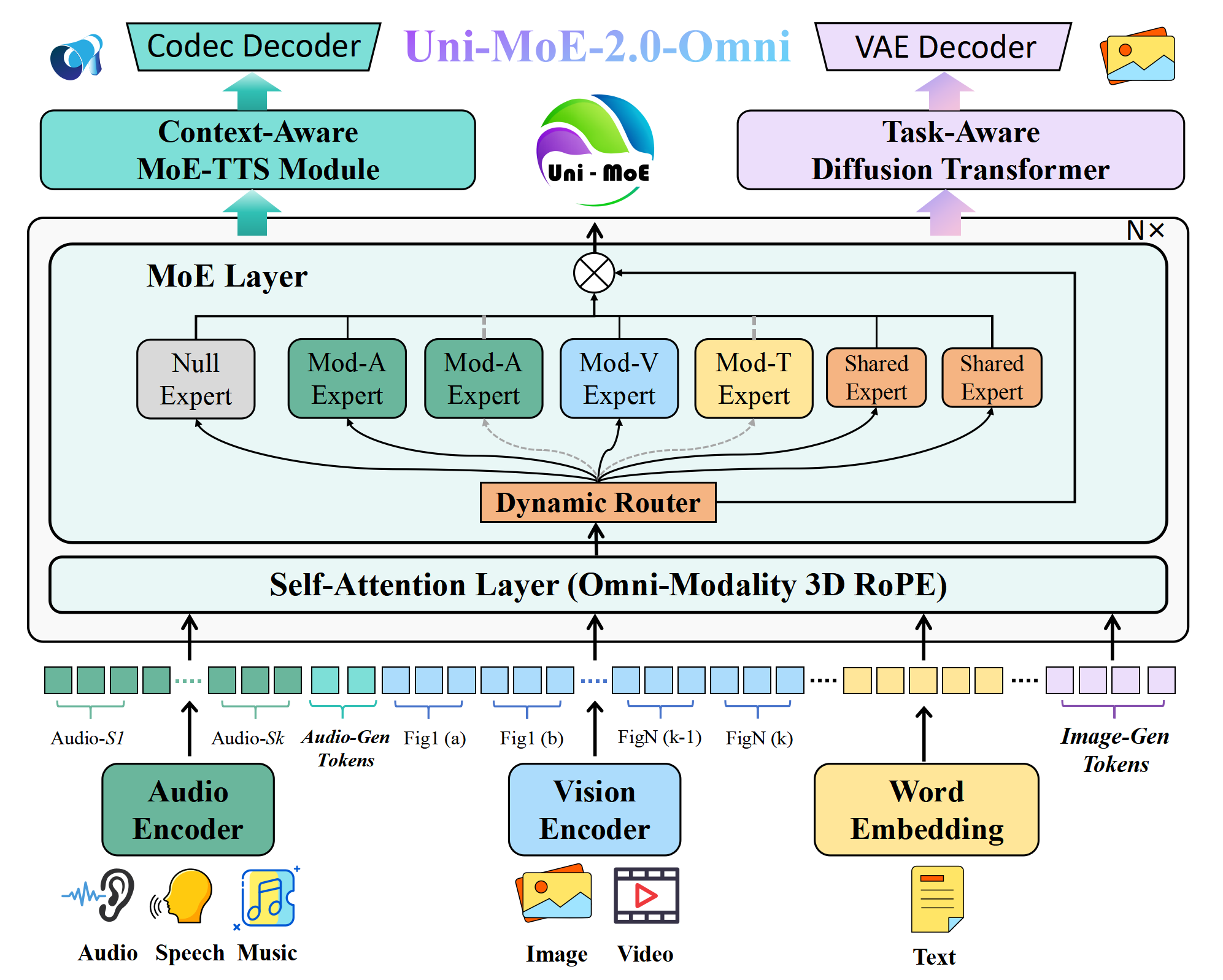
- Unified tokenization: The model breaks inputs into small chunks called “tokens” (like tiny puzzle pieces). It uses a consistent way to turn audio, images, text, and video into tokens, so they can be processed together.
- Omni-Modality 3D RoPE: Imagine every token gets a label saying “where” and “when” it belongs—like coordinates in a 3D map (time, height, width). This helps the model keep audio and video synchronized and align image patches correctly.
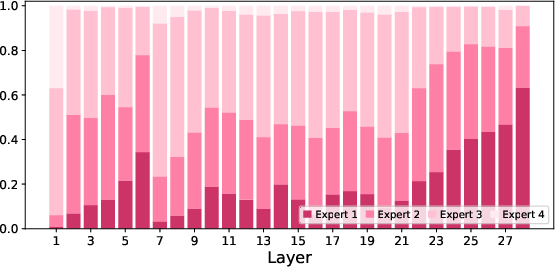
- Mixture-of-Experts (MoE): Picture a team with different specialists:
- Routed experts are specialists for a specific type (like audio or visual).
- Shared experts are generalists who help all tokens, keeping common knowledge available.
- Null experts are “skip” slots that allow the model to ignore unneeded work, saving time.
- Dynamic capacity means the model decides how many experts to use per token based on need, like calling more specialists for harder problems and fewer for easy ones.
- Routing gradient estimation is a training trick that lets the “traffic director” (the router deciding which expert to use) learn better, even though expert choice is usually a yes/no decision.
- Vision and audio encoders:
- Images/videos go through a strong visual encoder (SigLIP), which turns frames and patches into features the language core can understand.
- Audio goes through Whisper-Large-v3, which captures not just words but also tone, emotion, and voice characteristics.
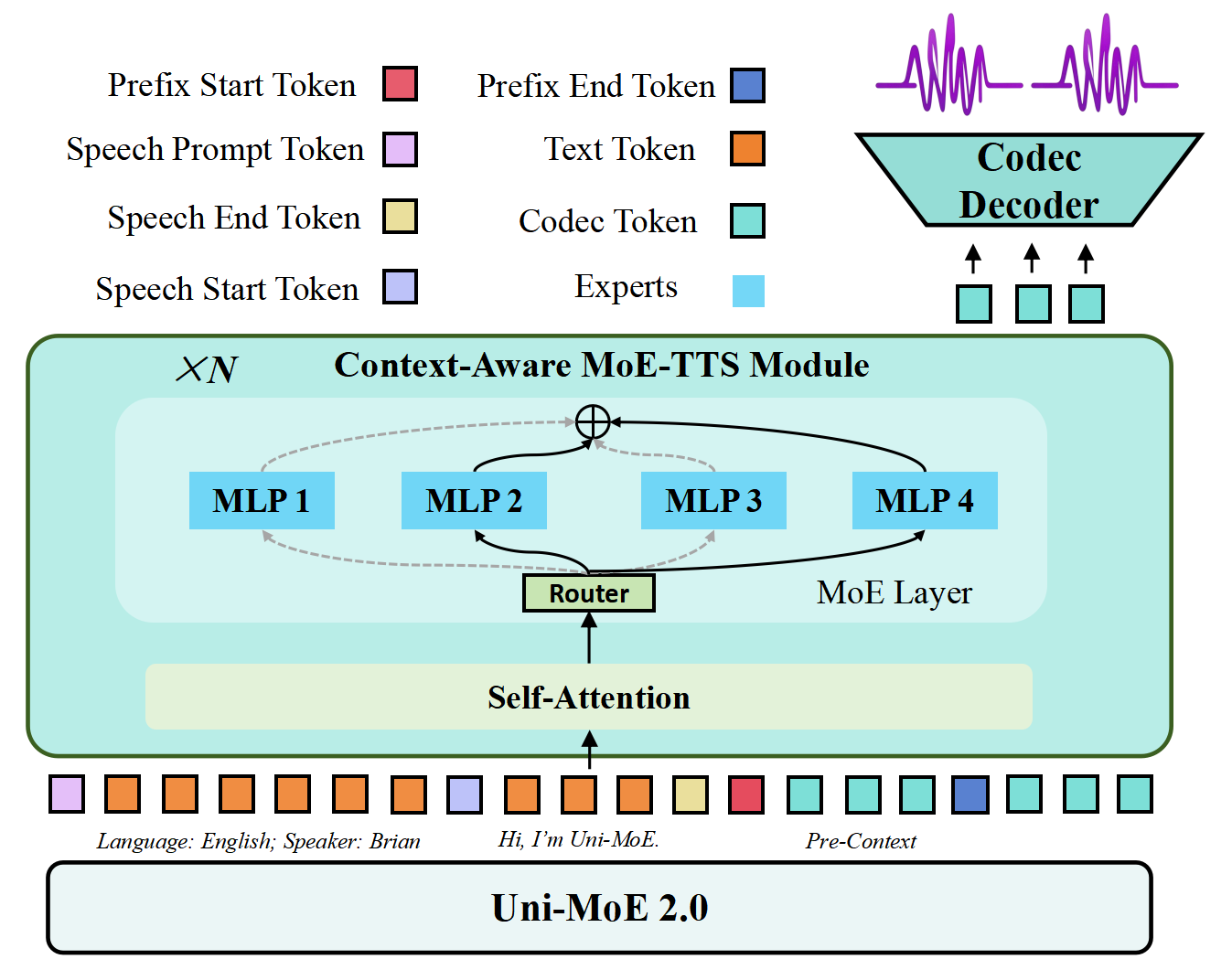
- Speech generation (MoE-TTS): The model can talk using a controllable text-to-speech module. Think of a voice studio where you can set language, timbre (voice color), emotion, and produce long, smooth speech. It splits long messages into sentences and stitches them together so the result sounds natural.
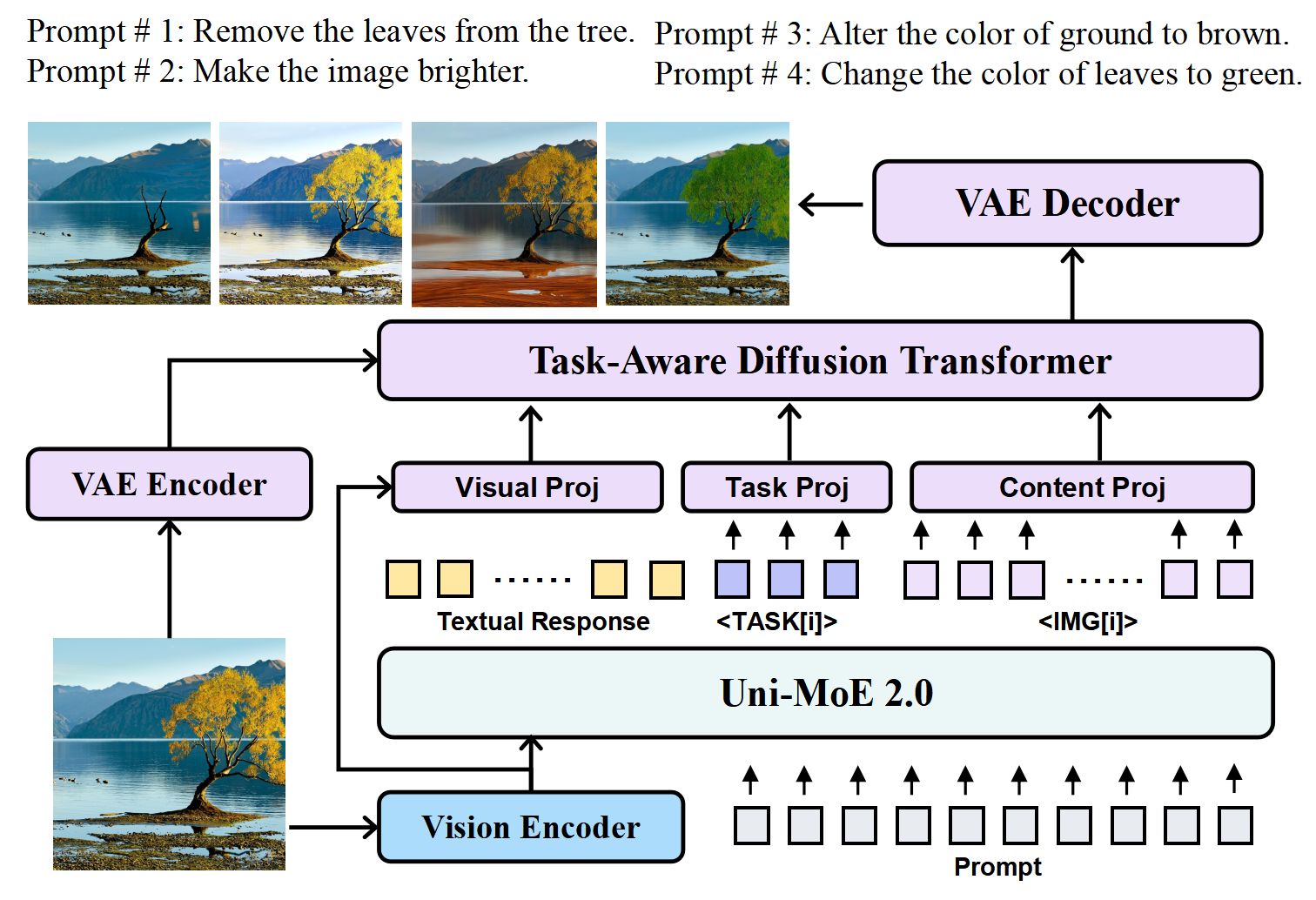
- Image generation (Task-Aware Diffusion Transformer): The model guides a “frozen” high-quality image generator (a skilled painter who never forgets how to paint) with lightweight task tokens and content tokens. This lets it do many tasks—like text-to-image, editing, or improving an image—without damaging the painter’s skills.
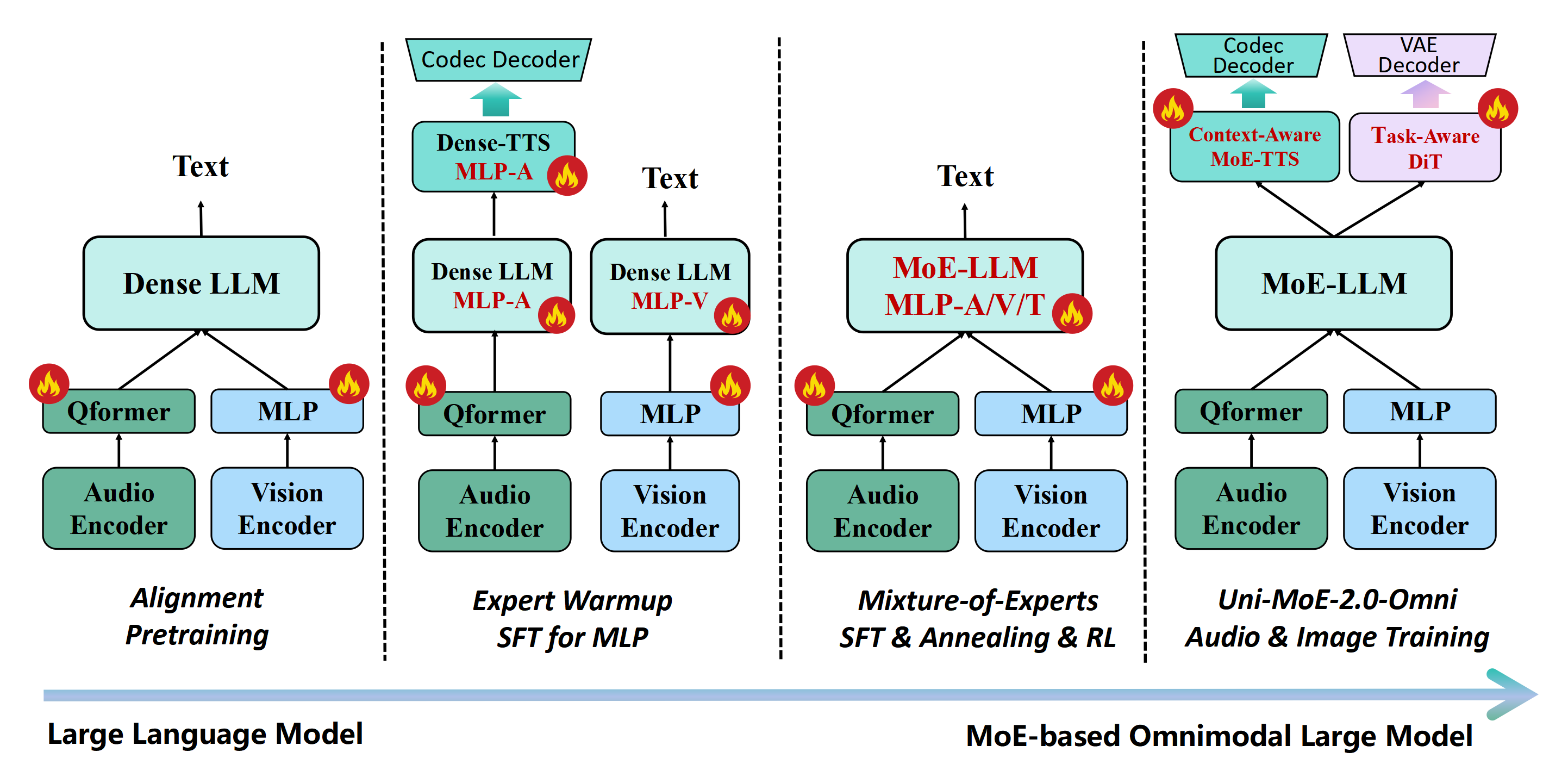
- Progressive training strategy:
- Pretraining alignment: Teach the model to map audio, images, and video into the language space so it understands them together.
- Expert warmup: Train specialist modules (like speech understanding/generation and visual understanding) so MoE experts start strong.
- Mixed-data MoE fine-tuning: Combine all modalities and fine-tune the MoE layers so they cooperate well.
- Annealing: Rebalance training with a carefully mixed dataset to even out skills across tasks.
- Reinforcement learning (GSPO) + preference learning (DPO): Practice reasoning with feedback—first the model explores, then uses “teacher” feedback (including judgments from other models) to refine its logic.
- Generative training: Finally connect and tune the speech and image generation modules; since the base model already understands their tokens, this step is fast.
4. What did they find, and why is it important?
The model was tested on 85 benchmarks (standard tests for AI) and showed strong or leading performance compared to other big, modern models:
- It beats or matches top models like Qwen2.5-Omni on over 50 of 76 shared tests—even though Qwen2.5-Omni was trained with around 1.2 trillion tokens, and Uni-MoE-2.0-Omni used about 75 billion. That’s a big efficiency win.
- Strong in video understanding and reasoning, multimodal comprehension (handling multiple types at once), and audiovisual tasks.
- Better long-form speech processing—lower error rates when listening to and generating long speech.
- Competitive image generation and editing; it especially shines in controllable edits and low-level image improvements.
Why this matters: It shows you don’t need a massive amount of data to build a capable “omnimodal” AI if your architecture and training are smart. It also proves language-centric design can unify understanding and generation across modalities.
5. What’s the impact?
- More natural AI assistants: A model that can look, listen, talk, and draw makes interactions smoother—imagine explaining a problem with a photo and getting a spoken answer with an edited image and a caption.
- Better tools for creators and educators: From audio narration to image edits, this model can help produce content quickly and accurately.
- Efficient and open: Because it’s open-source, other researchers and developers can build on it, test it, and use it in real projects. The efficiency gains (good results with fewer training tokens) lower the barrier to entry.
- A unified roadmap: Using language as a bridge helps avoid splitting understanding and generation into separate silos. It points to a future where one adaptable model supports many tasks—and does them well.
In simple terms: Uni-MoE-2.0-Omni is like a smart, coordinated team inside one brain—generalists plus specialists—guided by language. It understands many kinds of inputs, can create high-quality outputs, learns efficiently, and shares its tools with the world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future work could address:
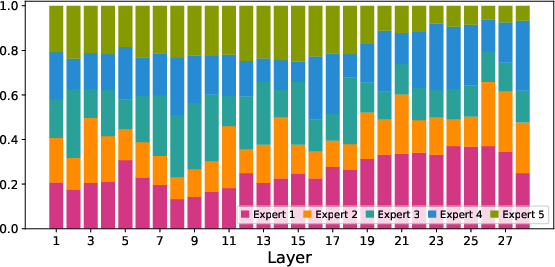
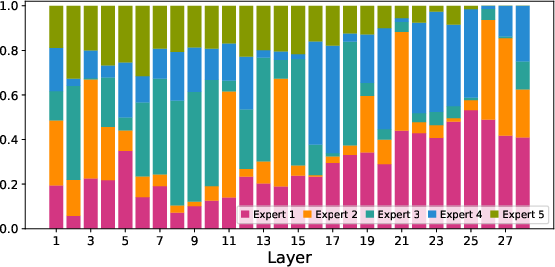
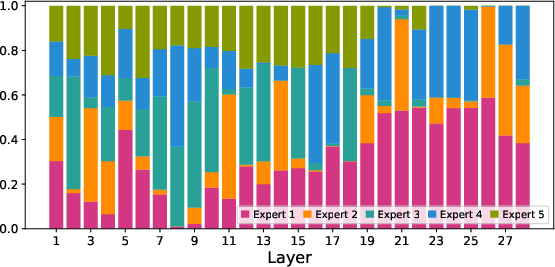
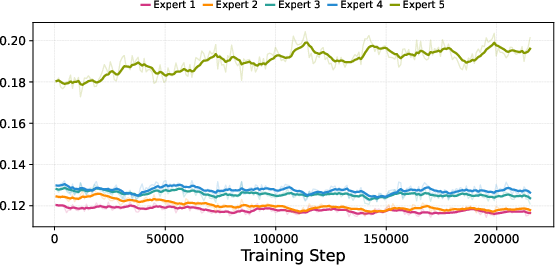
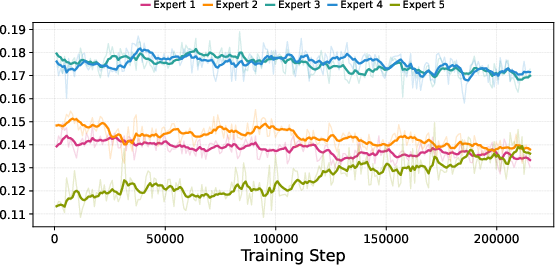
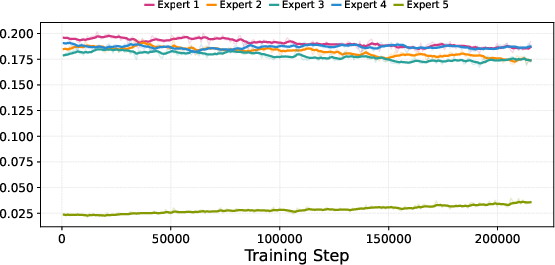
- MoE routing specifics and stability
- No quantitative analysis of routing stability (e.g., expert collapse, token–expert entropy) across modalities or phases; missing auxiliary load-balancing losses, temperatures, and gating regularizers.
- The dynamic-capacity Top-P routing threshold P, router temperature, and capacity constraints are unspecified; sensitivity analyses to P and temperature are absent.
- The claimed “token skipping” via null experts lacks criteria, rates, and compute savings; no ablation isolating the effect of null experts versus shared/routed experts.
- Grin-MoE gradient estimation is adopted but hyperparameters (step size, estimator variant, ODE order) and empirical comparisons to standard STE or dropless MoE are missing.
- Expert role specialization and “selective forgetting”
- No concrete protocol for triggering or evaluating “knowledge deletion” with null experts (what to delete, how to route deletions, how to verify removal without collateral forgetting).
- No measurement of retention–forgetting trade-offs, nor safety/memorization audits demonstrating effective removal of undesired knowledge.
- Omni-Modality 3D RoPE design
- The absolute-time scaling factor θ is undefined; no guidance on setting θ, nor sensitivity to frame/sample rates, or to cross-modality time jitter and desynchronization.
- Handling variable frame rates, dropped frames, or asynchronous audio–video streams is unspecified; robustness under such conditions is untested.
- Inconsistency between text: video sampling is described as “1 fps” in one section and “1 frame every two seconds” in the RoPE example; the intended setting and its impact on alignment are unclear.
- No evidence on long-context extrapolation limits with 3D RoPE for multi-hour audio/video or ultra-high-resolution images.
- Vision/audio tokenization and compression
- The number of tokens per visual patch (T), sliding-window stride for high-resolution images, and the memory/latency trade-offs are not reported.
- Audio compression to 20 tokens/3s could lose fine-grained prosody/phonetics; no ablation quantifies recognition/generation degradation versus higher token rates.
- No robustness evaluation for noisy, far-field, accented, code-switched, or low-resource languages beyond Chinese/English.
- Uni-Perception mapping modules
- Whisper decoder as Qformer: lack of analysis on bottlenecks (200 queries/30s), layer choices, and cross-lingual generalization.
- Mapping network design (two-layer MLP + pooling) is fixed without ablations (depth/width, pooling strategies, learned vs fixed compression).
- Uni-Generation modules
- MoE-TTS: limited to three fixed timbres and prompt-based descriptions; generalization to unseen voices, voice privacy/cloning risks, and cross-sentence prosody consistency over very long speech remain untested.
- No latency, streaming, and throughput measurements for real-time TTS, nor MOS/prosody metrics or subjective human evaluations.
- Task-DiT: the frozen generator bridge approach lacks comparisons to partial/fine-tuned generators; no ablations on projector capacity, conditioning token counts, or catastrophic interference risks.
- Image generation/editing quality controls and safety filters (e.g., harmful/NSFW content, watermarking) are not described.
- Training recipe and RL fine-tuning
- The GSPO/DPO reward design for multimodal tasks is unspecified (accuracy proxies, reward sparsity handling, judge prompts, inter-annotator reliability).
- Use of LLM-as-a-Judge and closed-source teachers (Gemini-2.5-Flash) risks bias and leakage; no audits for judge/teacher bias or dependency.
- Annealing stage details (sampling ratios, curriculum pacing, stopping criteria) are missing; no ablation proving annealing necessity versus more balanced SFT.
- Risks of policy collapse, reward hacking, and overfitting to judged styles are not analyzed; no iterative convergence diagnostics or safety constraints during RL.
- Data composition, licensing, and potential leakage
- Data sources, licenses, filtering, and deduplication for the ~75B-token corpus are not enumerated; potential benchmark leakage is unaddressed.
- Language coverage and balance are unclear (ASR dominates pretraining); fairness across demographics, accents, and non-English languages is not reported.
- Audio–visual alignment data quality (e.g., ensuring clean, meaningful audio tracks) is only briefly mentioned; no quantitative data quality metrics.
- Evaluation methodology and reproducibility
- The “85 benchmarks” claim lacks a full list, per-benchmark scores, and evaluation protocols; no statistical significance tests or variance across seeds.
- For generation tasks, human evaluations, preference studies, or standardized metrics (e.g., CLIP-based for image gen, MOS for TTS) are not documented.
- Ablations are largely absent (3D RoPE vs baselines, Top-P routing settings, shared-expert size ratio, null-expert presence, token rates, encoder swaps).
- Compute, efficiency, and deployment
- Compute budget (FLOPs), training time, and hardware footprint are unspecified; cost comparisons to dense baselines are missing.
- Inference-time activated parameters (Min 1.5B; Max 18B) are given without latency/throughput on common hardware; practical deployment feasibility is unclear.
- Memory footprint with large visual contexts and long audio/video inputs, plus batching strategies and kv-cache behavior under MoE, are not reported.
- Multimodal interaction capabilities and limits
- The paper claims “10 cross-modal inputs,” but only text, audio, images, and videos are detailed; the remaining modalities, interfaces, and adapters are not described.
- No support or roadmap for additional modalities (depth, 3D/point clouds, tabular, sensor streams, haptics) or embodied/action outputs.
- Safety, misuse, and alignment
- Safety guardrails for speech and image generation (deepfake prevention, consent, watermarking, prompt moderation) are unaddressed.
- No red-teaming or adversarial robustness evaluations (jailbreak prompts, toxic content, impersonation via TTS).
- Alignment of multimodal reasoning (hallucination rates, calibration/uncertainty estimates, refusal behaviors) is not measured.
- Long-context and streaming interactions
- While speech chunking beyond 30s is described, end-to-end streaming for mixed modalities (live A/V streams, partial context updates) is not specified.
- Cross-chunk reasoning coherence for video and multi-image tasks and mechanisms for global memory or retrieval are not discussed.
- Generalization and distribution shift
- Robustness to domain shifts (e.g., medical, legal, scientific A/V), low-resource settings, and extreme conditions (occlusions, compression artifacts) is not evaluated.
- No analysis of cross-benchmark generalization versus overfitting to specific datasets used in SFT/RL.
- Licensing and openness
- Model and code are open-sourced, but licensing terms, allowed use (especially for TTS and image generation), and compliance with third-party model/data licenses (Whisper, SigLIP, PixWizard) are not clarified.
Practical Applications
Summary
The paper introduces Uni-MoE-2.0-Omni, a fully open-source, language-centric omnimodal large model that can understand and generate across text, images, audio, and video. Key innovations include a dynamic-capacity Mixture-of-Experts (MoE) with routed/shared/null experts, Omni-Modality 3D RoPE for precise spatio-temporal alignment, unified tokenization for audio/video/images, a context-aware MoE-TTS for long and controllable speech synthesis, and a Task-Aware Diffusion Transformer (Task-DiT) that preserves high-fidelity image generation/editing via lightweight, task-conditioned bridges. A progressive training recipe (alignment → expert warmup → MoE fine-tuning → annealing → GSPO-DPO RL → generative modules) yields strong benchmark performance, particularly in video understanding, audiovisual reasoning, long-form speech, and controllable image editing. Code, models, and data lists are open-sourced.
Immediate Applications
The following applications can be deployed now, leveraging the open-source checkpoints and code, with integration effort and standard engineering practices.
- Enterprise speech and video analytics assistant (industry: finance, telecom, customer support)
- Use Uni-MoE-2.0-Omni’s long-form speech understanding (chunked 30s windows, low WER) and audiovisual temporal alignment (3D RoPE) to transcribe, summarize, and analyze calls and meetings; extract compliance/risk signals; index and search video archives.
- Product/workflow: ingestion → Whisper-based encoding/Qformer mapping → omnimodal reasoning → summary/compliance report; dashboards with searchable transcripts and video timelines.
- Assumptions/dependencies: GPU inference for the 26B MoE-LLM; privacy/security controls; domain adaptation for jargon; latency optimization for live monitoring.
- Contact center voicebots with controllable, natural TTS (industry: retail, logistics, banking)
- Deploy MoE-TTS with prompt-controllable timbres (e.g., Brain/Jenny/Xiaoxiao), languages (Chinese/English), and >2-minute coherent speech; combine with omnimodal understanding for task handling.
- Product/workflow: dialog manager → Uni-MoE reasoning → <speech start>/<speech prompt>/<speech end> control tokens → WavTokenizer decoding.
- Assumptions/dependencies: real-time streaming integration; voice/timbre selection governance and consent; compute capacity for low-latency synthesis.
- Multimodal content creation and editing studio (industry: marketing, e-commerce, media)
- Use Task-DiT to bridge instruction-following understanding to high-quality image generation/editing (preserving PixWizard fidelity); exploit controllable generation and low-level image processing strengths.
- Product/workflow: prompt/task tokens (<TASK[i]>) + content tokens (<IMG[i]>) → Task Projector + Content/Visual Projectors → DiT cross-attention → SD-XL VAE decoding; plugins for Photoshop/GIMP/Figma.
- Assumptions/dependencies: adequate VRAM and GPU memory; licensing compatibility for third-party components (PixWizard, SD-XL); brand safety and rights management.
- Accessibility tools for captioning and audio description (daily life, public sector, education)
- Provide image/video descriptions and long-form read-aloud with controllable voices; generate alt-text and synchronized captions leveraging 3D RoPE alignment.
- Product/workflow: image/video encoder (SigLIP) → linguistic space mapping → caption/description → MoE-TTS narration.
- Assumptions/dependencies: accuracy and safety guardrails; support for additional languages; UI/UX compliance with accessibility standards.
- Educational multimodal tutoring and lecture assistants (education)
- Explain diagrams, lab videos, and complex visuals; narrate step-by-step reasoning; generate study notes and voice-based guidance; support bilingual use.
- Product/workflow: multimodal input → chain-of-thought (GSPO-DPO “Thinking” variant) → adaptive explanations → TTS output.
- Assumptions/dependencies: correctness in high-stakes subjects; content alignment with curricula; teacher-in-the-loop workflows for verification.
- Media moderation and content indexing (industry: media platforms)
- Use improved video understanding (+7% avg across benchmarks) and audiovisual reasoning (+4%) to flag harmful content, index scenes/events, and detect policy violations.
- Product/workflow: frame/audio sampling → 3D RoPE-aligned reasoning → moderation decisions with evidence spans.
- Assumptions/dependencies: policy calibration, false positive/negative management; regional legal compliance; throughput scaling.
- Developer/ML engineer toolkit for omnimodal applications (software)
- Leverage open-source code, five checkpoints, and data lists to build unified pipelines: text+image+audio+video in one API; integrate MoE routing and null experts for cost-aware inference.
- Product/workflow: OSS inference server; modular encoders (Whisper, SigLIP); configurable routed/shared/null expert composition; benchmark harness for 85 tasks.
- Assumptions/dependencies: serving stack (CUDA, Triton/ONNX), quantization/compression for production, robust logging and observability.
- Data labeling and pre-annotation for audio/video (industry, academia)
- Auto-caption audio/music/environmental sounds; generate image/video descriptions; support active learning loops to reduce human labeling costs.
- Product/workflow: batch inference → candidate annotations → human review UI → incremental fine-tuning.
- Assumptions/dependencies: quality thresholds; dataset licenses; bias auditing; human verification remains necessary.
- Cost-adaptive serving with dynamic-capacity MoE (software/platforms)
- Exploit dynamic expert activation and null experts (token skipping) to trade off compute vs quality; prioritize “hard” tokens; maintain shared-general knowledge.
- Product/workflow: routing thresholds (Top-P), expert budgets per request, SLAs for latency/cost; A/B tests for quality loss.
- Assumptions/dependencies: careful router training; monitoring of routing drift; graceful degradation strategies.
Long-Term Applications
These applications are promising but require further research, scaling, domain adaptation, or safety/regulatory readiness.
- Real-time embodied robotics assistants (robotics)
- Combine 3D RoPE cross-modal alignment, audiovisual reasoning, and language-centric planning with control policies for manipulation and navigation in noisy, multi-sensory environments.
- Potential tools/workflows: perception-to-action loop; multimodal scene grounding; continual learning with MoE expert specialization per environment.
- Assumptions/dependencies: on-robot compute or efficient distillation; safety constraints; integration with control stacks (ROS); domain sim-to-real transfer.
- Clinical voice and imaging triage/assistants (healthcare)
- Use speech understanding for patient interviews and low-level image processing for pre-screening/anonymization; multimodal reasoning for clinical decision support.
- Potential tools/workflows: HIPAA-compliant pipelines; radiology image edits (e.g., de-identification), symptom summarization; clinician-in-the-loop verification.
- Assumptions/dependencies: medical dataset fine-tuning; regulatory approvals; bias/fairness audits; robust performance under domain shift.
- Multilingual real-time dubbing and translation with timbre preservation (media, education, accessibility)
- Stream video/audio, generate synchronized captions and natural TTS with maintained speaker style; live lecture or broadcast translation.
- Potential tools/workflows: streaming encoders; timbre extraction and transfer; synchronization via absolute-time RoPE.
- Assumptions/dependencies: expanded language coverage; latency optimization; voice cloning consent and governance.
- Omnimodal content governance frameworks and safety evaluations (policy, platforms)
- Establish standards and testbeds for evaluating multimodal safety (deepfakes, synthetic audio, image editing misuse), provenance, and watermarking; use open benchmarks and OSS models for reproducible audits.
- Potential tools/workflows: policy simulation datasets; detection filters; red-teaming harness; public reporting dashboards.
- Assumptions/dependencies: accepted standards; community governance; tooling for watermark embedding/detection across modalities.
- Auto-MoE serving and scheduling at hyperscale (software/cloud)
- Build orchestration that adapts expert activation, memory, and compute allocation per request/user tier; align SLAs and cost controls.
- Potential tools/workflows: router-aware schedulers; observability for expert hot spots; elastic scaling; serverless adapters.
- Assumptions/dependencies: production-grade gradient-estimation stability; hardware-aware routing; failure isolation.
- Personalized digital twins and generative media companions (media, consumer apps)
- Create agents with consistent voice, visual style, and multimodal memory; produce personalized video/audio content.
- Potential tools/workflows: timbre/style profiles; content safety layers; preference learning (GSPO-DPO pipelines).
- Assumptions/dependencies: privacy controls; consent and IP rights; mitigation of synthetic identity risks.
- Energy and infrastructure monitoring via multimodal sensing (energy, public sector)
- Fuse audio (e.g., transformer hum, machinery), video (inspections), and text logs for predictive maintenance and anomaly detection.
- Potential tools/workflows: sensor-to-language mapping; temporal alignment across modalities; event triage dashboards.
- Assumptions/dependencies: domain-specific encoders for industrial signals; labeled incidents; deployment on edge devices.
- Knowledge editing and compliance updates with null experts (software, policy)
- Use null experts for selective forgetting of outdated or harmful knowledge; controlled updates without full retraining.
- Potential tools/workflows: “Forgetful MoE” admin panel; compliance audit trails; evaluation harness for knowledge removal side effects.
- Assumptions/dependencies: reliable measurement of forgetting without collateral damage; versioned policy management; legal considerations.
- Cross-modal search-and-generate systems (software, media, education)
- Retrieve relevant video frames and audio segments, reason over them, and generate answers/explanations or edited media.
- Potential tools/workflows: unified retrieval indexing (time, height, width IDs); RAG over multimodal stores; Task-DiT editing on retrieved content.
- Assumptions/dependencies: scalable multimodal indexing; latency constraints; content rights for transformation.
- Academic research platforms for MoE routing and RL reasoning (academia)
- Use Dynamic-Capacity MoE and GSPO-DPO pipelines to study expert specialization, gradient estimators, and multimodal chain-of-thought.
- Potential tools/workflows: ablation suites; routing diagnostics; VerIPO iterative optimization; community benchmarks.
- Assumptions/dependencies: sustained open release of checkpoints/datasets; reproducibility across hardware; standardized evaluation protocols.
Glossary
- Annealing: A training phase that gradually refines model parameters or balances capabilities across tasks or modalities. Example: "we conducted a subsequent annealing training phase using a balanced mixture of all data types."
- Audiovisual reasoning: Reasoning that jointly exploits audio and visual signals to answer questions or make inferences. Example: "and audiovisual reasoning (+4%)."
- Cross-attention: An attention mechanism where one sequence attends to another (e.g., text attending to audio features) to fuse information across sources. Example: " and denote the multihead self-attention and cross-attention operations, and is the layer norm function."
- Cross-modal alignment: Techniques to align representations across different input modalities (e.g., text, image, audio, video) so they can interact coherently. Example: "Deep Cross-Modal Alignment: To enable deep and efficient fusion of any modality, we introduce an Omni-Modality 3D RoPE mechanism in the self-attention layers."
- Direct Preference Optimization (DPO): A preference-based training method that optimizes a model to prefer higher-quality responses without reinforcement learning from scalar rewards. Example: "Direct Preference Optimization (DPO)"
- Dynamic capacity routing: A routing strategy that adaptively selects how many experts to activate per token based on cumulative probability thresholds. Example: "We address this limitation by introducing a dynamic capacity routing strategy"
- Dynamic-Capacity MoE: An MoE architecture that enables differentiable routing, specialized expert roles, and variable numbers of activated experts per token. Example: "we propose the Dynamic-Capacity MoE architecture"
- Feed-forward network (FFN): The MLP submodule in transformer blocks that stores and processes a large share of parametric knowledge. Example: "feed-forward network (FFN) modules"
- Group Sequence Policy Optimization (GSPO): A reinforcement learning algorithm tailored for sequence models that enables online policy improvement. Example: "online reinforcement learning (GSPO)"
- Layer norm (LN): A normalization technique applied across the hidden units of a layer to stabilize and accelerate training. Example: "and is the layer norm function."
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of specialized feed-forward networks (experts) to increase capacity efficiently. Example: "Mixture-of-Experts (MoE)"
- M-RoPE: A variant of rotary positional embeddings designed for multimodal or multi-dimensional positional encoding. Example: "Inspired by the M-RoPE design in Qwen2-VL"
- Null experts: Experts whose output is zero, used for token skipping and selective forgetting of irrelevant knowledge. Example: "Null experts: These are ``empty'' experts whose output is identically zero."
- Omni-Modality 3D RoPE: A rotary positional embedding scheme that encodes temporal, height, and width dimensions to align text, audio, image, and video tokens. Example: "we propose Omni-Modality 3D RoPE"
- Omnimodal Large Model (OLM): A large model that handles understanding, reasoning, and generation across multiple modalities within one system. Example: "omnimodal large model (OLM)"
- Qformer: A query-based transformer module used to extract compact token representations from encoder features for downstream LLMs. Example: "by using the decoder module of Whisper-Large-v3 as the Qformer"
- RoPE (Rotary Positional Embeddings): A positional embedding method that applies rotations in feature space to encode token positions for attention. Example: "Suppose the RoPE ID of the last text token preceding the visual sequence is ."
- Routed experts: Task- or modality-specific experts that are dynamically selected by the router for specialized processing. Example: "Routed Experts: These are task-specific experts responsible for modeling domain-specific knowledge."
- Shared experts: Always-on experts that capture general knowledge and provide a stable backbone for all tokens. Example: "Shared Experts: These experts capture general, domain-independent knowledge."
- SigLIP: A vision-language pretraining approach and model variant used as the visual encoder backbone. Example: "initialized with SigLIP \citep{zhai2023sigmoid} vision transformer"
- Straight-through gradient estimators: A technique to approximate gradients through non-differentiable operations, enabling end-to-end training. Example: "straight-through gradient estimators"
- Task-Aware Diffusion Transformer (Task-DiT): A diffusion-based image generator steered by task and content tokens via lightweight projectors for instruction-followed synthesis. Example: "Task-Aware Diffusion Transformer (Task-DiT)"
- Top-K: A selection operation that keeps only the K highest-scoring items (e.g., experts) per token. Example: "Top-K function"
- Top-P sampling: A nucleus-based selection strategy that activates as many items as needed to reach a probability mass P. Example: "Top-P sampling"
- VAE: Variational Autoencoder, used here as the image decoder component in the generation pipeline. Example: "VAE Decoder & SD-XL"
- ViT (Vision Transformer): A transformer architecture applied to image patches for visual feature extraction. Example: "encoded by ViT"
- WavTokenizer: A neural codec tokenizer/decoder that converts between waveforms and discrete tokens for audio generation. Example: "WavTokenizer-large-600-24k-4096"
- Whisper-Large-v3: A large pretrained speech encoder-decoder model used to extract audio features and as a Qformer for audio-language mapping. Example: "We adopt the Whisper-Large-v3 encoder"
- Word Error Rate (WER): A standard metric for ASR and TTS quality measuring substitution, deletion, and insertion errors relative to reference text. Example: "WER reduced by up to 4.2\%)"
Collections
Sign up for free to add this paper to one or more collections.