OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM
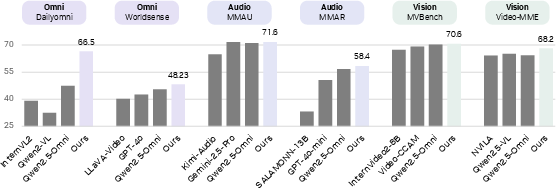
Abstract: Advancing machine intelligence requires developing the ability to perceive across multiple modalities, much as humans sense the world. We introduce OmniVinci, an initiative to build a strong, open-source, omni-modal LLM. We carefully study the design choices across model architecture and data curation. For model architecture, we present three key innovations: (i) OmniAlignNet for strengthening alignment between vision and audio embeddings in a shared omni-modal latent space; (ii) Temporal Embedding Grouping for capturing relative temporal alignment between vision and audio signals; and (iii) Constrained Rotary Time Embedding for encoding absolute temporal information in omni-modal embeddings. We introduce a curation and synthesis pipeline that generates 24M single-modal and omni-modal conversations. We find that modalities reinforce one another in both perception and reasoning. Our model, OmniVinci, outperforms Qwen2.5-Omni with +19.05 on DailyOmni (cross-modal understanding), +1.7 on MMAR (audio), and +3.9 on Video-MME (vision), while using just 0.2T training tokens - a 6 times reduction compared to Qwen2.5-Omni's 1.2T. We finally demonstrate omni-modal advantages in downstream applications spanning robotics, medical AI, and smart factory.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces OmniVinci, a new open-source AI model that can understand and reason across different types of information at the same time: pictures and videos (vision), sounds and speech (audio), and text (language). The goal is to help AI “see” and “hear” together—like humans do—so it can answer questions, describe scenes, follow instructions, and solve problems more accurately and efficiently.
Key Objectives
The researchers focused on four simple questions:
- How can we make an AI’s “eyes” (vision) and “ears” (audio) work together smoothly?
- How can the AI understand what happens first, next, and last in a video (time)?
- How can we create enough good training data that teaches the AI to use multiple types of information at once?
- How can we train such a model to be strong without using huge amounts of computing and data?
Methods and Approach
To build OmniVinci, the team improved both the model’s design and its training data. Here’s how, using everyday analogies:
How the model blends vision and audio
Think of the AI as a team where “vision” and “audio” members must meet in the same room and agree on what’s happening.
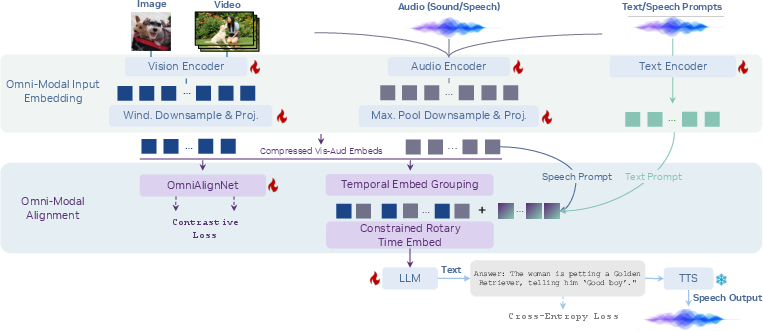
- OmniAlignNet: A “matchmaker” that brings together the right sounds with the right visuals from the same video. It learns which video clip matches which sound clip by pulling correct pairs closer and pushing incorrect pairs apart—like sorting matching socks from a mixed pile.
How the model understands time
Videos aren’t just single pictures—they’re sequences that unfold over time. The model needs to know what happens when.
- Temporal Embedding Grouping (TEG): The model divides the video timeline into chunks (like chapters in a book) and places related visual and audio pieces into the same time group. This helps it understand the order of events and which sounds go with which moments.
- Constrained Rotary Time Embedding (CRTE): The model gives each piece of visual or audio information a “clock” with angles that rotate at different speeds. Fast rotations capture tiny time differences (like noticing a quick sound), while slow rotations capture big time changes (like a scene shift). This “multi-speed clock” helps the AI remember both short and long-term timing.
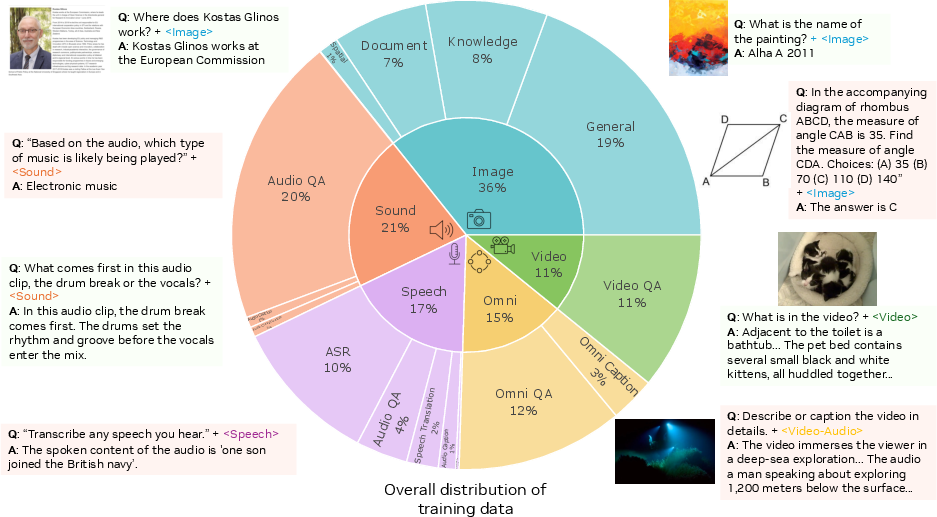
How the team built better training data
Getting good multi-modal training data is hard. So the team built a smart data pipeline:
- Two reporters approach: One AI “watches” video and writes a visual caption; another “listens” to the audio and writes an audio caption. Each alone can be wrong (for example, visuals without voice might miss meaning, and audio alone might misinterpret the scene).
- Editor step: A third AI acts like an editor who combines both captions, fixes errors, and produces a single, accurate joint summary. This reduces “hallucinations” (mistakes caused by relying on only one modality).
- Implicit vs. explicit learning:
- Implicit learning: Use videos with sound and ask questions without directly telling the AI how to use both—this encourages natural cross-modal learning.
- Explicit learning: Create labeled training data that clearly ties audio and visual clues together, so the AI can learn exactly how to combine them.
Training strategy
- Stage 1: Train the model separately on only vision or only audio tasks (teach each skill independently).
- Stage 2: Joint training on videos with audio plus text to blend skills together and build true “omni-modal” understanding.
Main Findings and Why They Matter
OmniVinci performs strongly across tasks that require seeing and hearing:
- Better cross-modal understanding:
- DailyOmni: +19.05 points higher than a strong model (Qwen2.5-Omni), meaning it’s much better at tasks that require mixing video and audio understanding.
- Worldsense: +2.83 points improvement.
- Audio tasks:
- MMAR: +1.7 points over Qwen2.5-Omni, showing stronger general audio understanding.
- Video tasks:
- Video-MME (without subtitle hints): +3.9 points over a popular video model (Qwen2.5-VL), showing better video comprehension when audio matters.
- Efficiency:
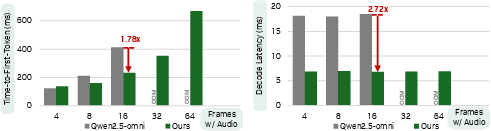
- Trained with only 0.2 trillion tokens—about 6 times fewer than some competitors (which used 1.2 trillion tokens). This means you can get high quality without huge costs.
- Real-world benefits:
- The model helps in robotics (voice-guided actions), broadcasting (understanding live events), healthcare (combining visuals with doctors’ speech), and factories (monitoring machines with sound and video).
In short: adding sound to vision doesn’t just help the model “perceive” better—it also helps it “reason” better.
Implications and Impact
OmniVinci shows that:
- AI becomes more reliable when it combines sight and sound, reducing mistakes caused by using only one source.
- Smart design (OmniAlignNet, TEG, CRTE) plus a thoughtful data pipeline can produce top results without massive training budgets.
- This approach can power future assistants that watch videos, listen to speech, and respond helpfully in everyday situations—guiding robots, analyzing medical videos with narration, understanding sports clips, or monitoring factories.
- Because it’s open-source and efficient, more people and organizations can use and build upon it, speeding up progress in multi-modal AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper and could guide future research:
- Modality breadth: The model is “omni-modal” across vision, audio, and text, but excludes other high-value modalities (e.g., depth, LiDAR/point clouds, thermal/infrared, IMU, haptics). How to extend OmniAlignNet/TEG/CRTE to heterogeneous sensors?
- Fine-grained cross-modal alignment: OmniAlignNet reduces each modality to a single token via learned queries, which risks losing temporally localized cross-modal relations (e.g., sound events aligned to specific frames). Explore segment-level or multi-token alignment, time-aware negatives, or contrastive alignment at varying granularities.
- Temporal hyperparameter adaptivity: TEG and CRTE depend on hand-tuned , , and . There is no guidance for choosing these across clip lengths, frame/sample rates, or domains. Can these be learned per-instance (e.g., via meta-learning) or adapted dynamically at inference?
- Robustness to desynchronization and noise: No evaluation under audio–video misalignment (lag, drift), background noise, reverberation, codec artifacts, or mismatched frame/sample rates. How resilient are TEG/CRTE and OmniAlignNet to real-world synchronization errors and audio degradation?
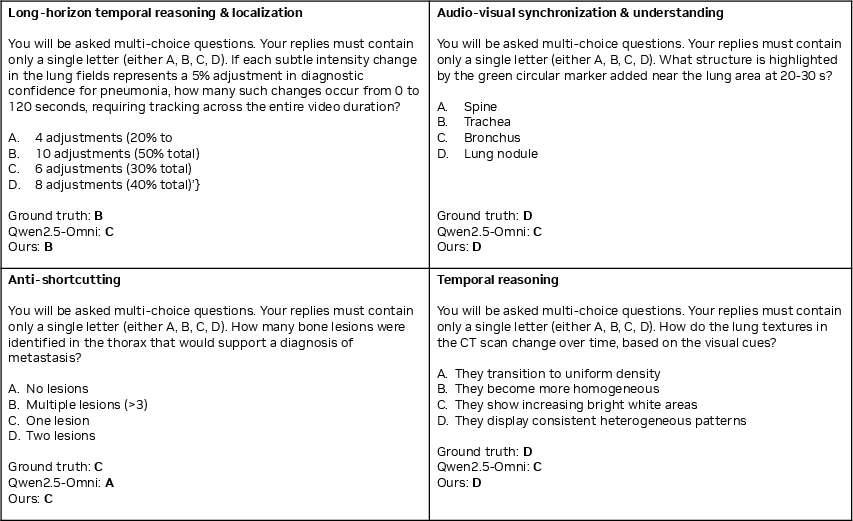
- Long-horizon reasoning: Training/evaluation uses up to 64 frames and segment lengths of 20 seconds to 2 minutes. There is no study of hour-long videos, multi-scene narratives, or streaming inputs. What memory/compression strategies enable long-horizon omni-modal reasoning with stable performance?
- Image–audio underperformance: OmniVinci is substantially worse than Qwen2.5-Omni on Omnibench (image–audio). What causes this gap (data mixture, encoder unification, alignment granularity)? Provide targeted ablations and interventions to close it.
- Unified audio encoder trade-offs: A single audio encoder handles speech and non-speech sounds. There is no ablation on specialization (separate encoders or mixture-of-experts) or modality-gated processing. Does unification reduce peak performance for either class?
- Data quality and validation: The omni-modal data engine relies on LLM-generated corrections/summaries without human validation. Quantify hallucination rates, factuality, and propagation of LLM biases; introduce human auditing or automatic consistency checks between modalities.
- Safety, privacy, and consent: Training on videos with audio may include personally identifiable information or sensitive speech. Define and evaluate filtering, consent, redaction, and compliance procedures; report dataset licenses and provenance.
- Distributional transparency: The 24M-sample data mixture spans 150+ sub-datasets, but detailed distributions, licenses, and overlap with benchmarks are in appendices and remain opaque here. Provide a clear, reproducible catalog and contamination analysis with evaluation sets.
- Efficiency and latency at inference: TEG and omni-modal token interleaving increase sequence lengths. There is no measurement of latency, memory, throughput, or energy under real-time streaming constraints. Benchmark streaming audio–video decoding and alignment overhead.
- Fair comparison controls: Report controlled comparisons at matched parameter count, training token budgets, and compute (FLOPs/GPU hours) to isolate architecture/data effects from scale. Clarify whether the 0.2T vs 1.2T token comparison accounts for token definition differences.
- Learned time embedding negative result: “Learned Time Embedding” degraded performance, but the paper does not analyze why. Provide a diagnostic (e.g., overfitting to discretized bins, poor extrapolation) and test hybrids (learned + rotary) or continuous-time neural ODE variants.
- TEG design choices: It is unclear how the grouping boundaries are selected or whether interleaving order is optimal. Experiment with learned grouping, content-aware chunking, or cross-attention alignment instead of fixed timestamp-based interleave.
- CRTE sensitivity and generality: No analysis of CRTE’s sensitivity to and across datasets or modalities, nor theoretical characterization (aliasing, extrapolation, invariances). Study CRTE under variable frame/sample rates and discontinuities.
- Misalignment and conflict resolution: The data engine assumes LLM-based cross-modal correction resolves “modality-specific hallucinations,” but does not address true inter-modality conflicts (e.g., dubbing vs visuals). Develop explicit conflict detection/resolution policies.
- Multilingual and code-switch robustness: ASR and audio understanding are largely evaluated on English datasets. Assess multilingual speech, code-switching, low-resource languages, and alignment with non-English visual contexts; quantify performance and failure modes.
- Non-speech audio tasks: Limited coverage of tasks like sound source localization, event boundary detection, audio–visual grounding, and spatial audio. Add benchmarks and analyses for these core audio–visual tasks.
- Benchmark leakage and subtitle effects: Some video benchmarks include subtitle variants. Test resistance to misleading or contradictory subtitles, and quantify reliance on text vs audio signals.
- Streaming and real-time agentic use: The paper does not address streaming alignment, incremental inference, or conversational turn-taking with live audio/video. Evaluate chunking strategies, buffering policies, and end-to-end latency for real-time applications (e.g., robotics).
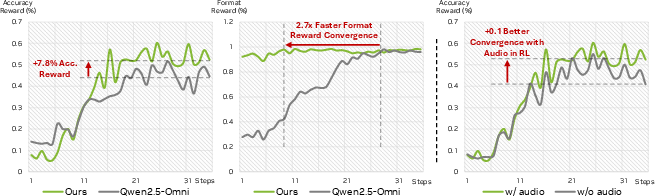
- Reward design for omni-modal RL: GRPO uses rule-based format/accuracy rewards with modest gains. Explore richer rewards (reasoning trace fidelity, cross-modal grounding), human preference optimization, and penalties for cross-modal hallucinations; report robustness to reward hacking.
- Reasoning evaluation: Claims of audio–video synergy for reasoning are supported by small GRPO gains. Provide systematic reasoning benchmarks isolating cross-modal evidence use, with error analyses (e.g., when audio contradicts visual cues).
- Catastrophic forgetting and training stability: Two-stage training mixes modality-specific and omni-modal data, but there is no study of forgetting or interference. Monitor per-modality performance through joint training and propose curriculum or replay strategies if needed.
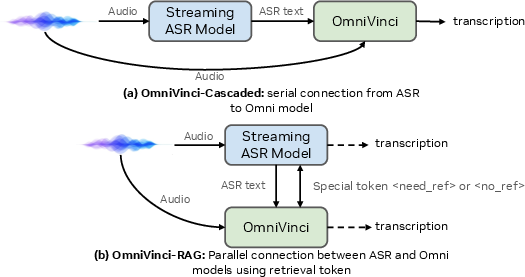
- Retrieval augmentation integration: ASR improves with test-time retrieval, but retrieval is not explored for omni-modal understanding (e.g., retrieving audio exemplars or video frames). Study RAG for cross-modal retrieval and its interaction with alignment modules.
- Prosody and speech output: Output speech via external TTS is not evaluated for content fidelity, prosody, and emotion alignment with visual context. Establish metrics and fine-tune TTS for cross-modal grounded speech generation.
- Security/adversarial robustness: No assessment against adversarial audio (e.g., inaudible perturbations), spoofed speech, or deceptive visuals. Evaluate and harden the model against audio–visual adversarial attacks and injection risks.
- Failure cases and qualitative diagnostics: The paper highlights successes but lacks a taxonomy of failure modes (e.g., when CRTE fails, when audio overrides correct visual cues). Provide qualitative error analysis and mitigation strategies.
- Reproducibility gaps: Many critical details (encoder architectures, projector specifics, training schedules, data sources) are pushed to appendices. Ensure the open-source release includes all configs, data recipes, and alignment losses to reproduce claims end-to-end.
Practical Applications
Immediate Applications
The following applications can be deployed now with the model and data pipeline described in the paper, leveraging OmniVinci’s omni-modal perception, time-aware alignment (TEG, CRTE), and audio–vision embedding alignment (OmniAlignNet).
- Multimedia captioning and summarization assistant
- Sector: Media, EdTech, Accessibility
- What it does: Generates accurate joint audio–video captions, summaries, and highlights for long-form content (lectures, documentaries, sports, webinars), correcting modality-specific hallucination by fusing speech, ambient sounds, and visuals.
- Tools/workflows: Integrate with video production tools (e.g., OBS), platforms (YouTube, Twitch), and TTS; batch captioning pipelines; lecture note generation in LMS.
- Assumptions/dependencies: Synchronized audio/video streams; acceptable latency for near-real-time use; basic domain prompting for jargon-heavy content.
- Meeting and classroom companion
- Sector: Enterprise software, Education
- What it does: Real-time transcription, slide/image understanding, action-item extraction, and multi-step reasoning over discussions; supports audio prompts and responses.
- Tools/workflows: Zoom/Teams plugins; document and figure understanding; summarization into productivity suites.
- Assumptions/dependencies: Good mic quality; permissioned capture; robust diarization for multi-speaker scenarios.
- Sports broadcast co-pilot
- Sector: Media & Entertainment
- What it does: Detects events using audio cues (crowd, commentary) and video context; generates live analytics and explainers; helps editors create highlight reels.
- Tools/workflows: On-air graphics and automated lower-thirds; timeline-aware highlight indexing; editorial review interface.
- Assumptions/dependencies: Integrations with live pipelines; latency budgets; domain prompts for specific sports.
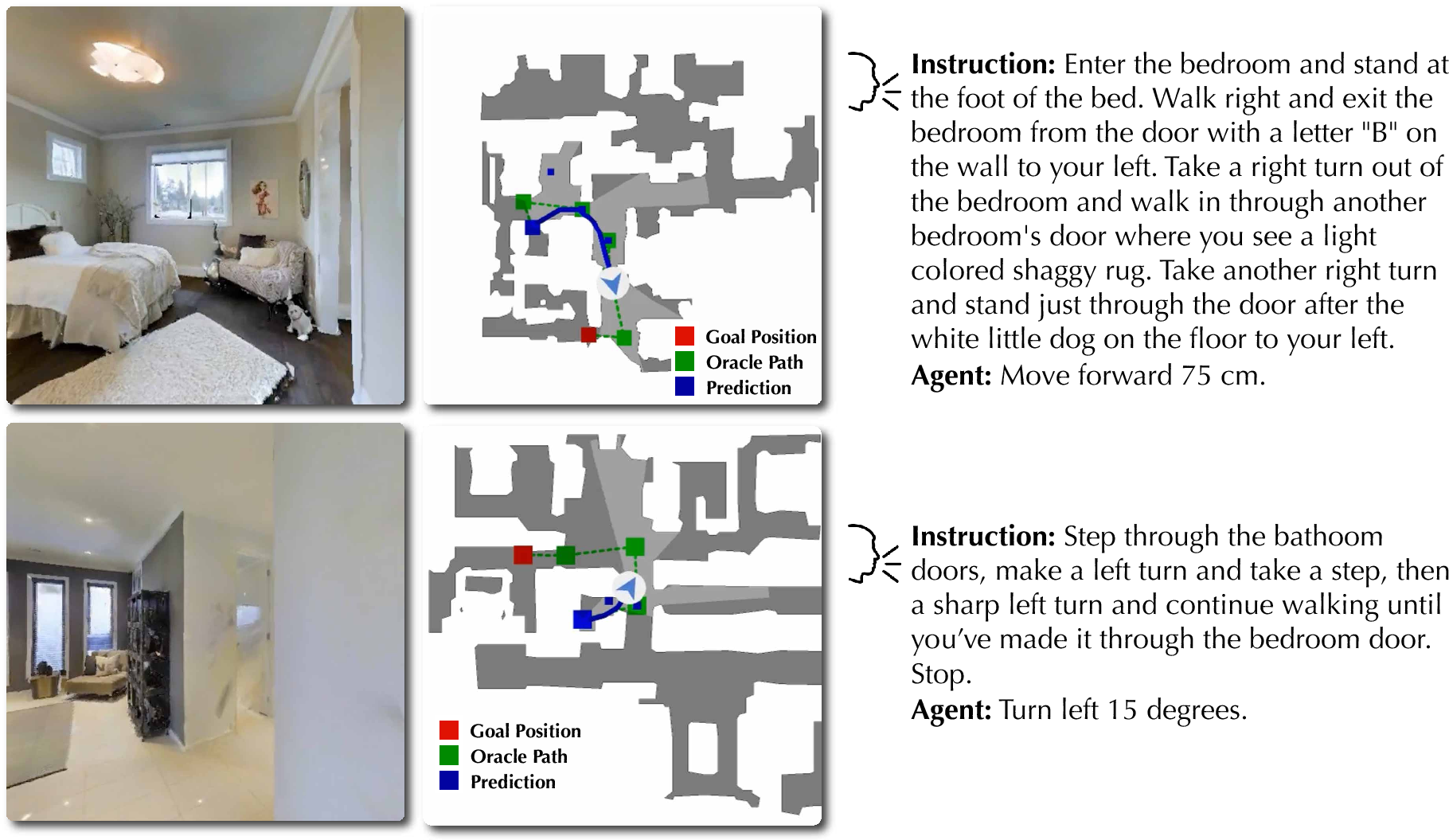
- Speech-prompted robot navigation (human-in-the-loop)
- Sector: Robotics, Logistics
- What it does: Interprets spoken instructions and camera feeds to guide robots through navigation tasks; multimodal reasoning improves robustness in noisy environments.
- Tools/workflows: ROS 2 node integration; speech-to-action; visual grounding and verification; closed-loop human oversight.
- Assumptions/dependencies: Safe operating envelopes; calibrated cameras/mics; task-specific constraints.
- Smart factory monitoring and incident analysis
- Sector: Manufacturing
- What it does: Joint audio–video anomaly detection (alarms, abnormal vibrations, visual defects), with contextual summaries and triage recommendations.
- Tools/workflows: CCTV + industrial microphones; SCADA/IIoT integration; timeline-aware incident reports.
- Assumptions/dependencies: Sensor placement and calibration; domain-specific thresholds; operator-in-the-loop validation.
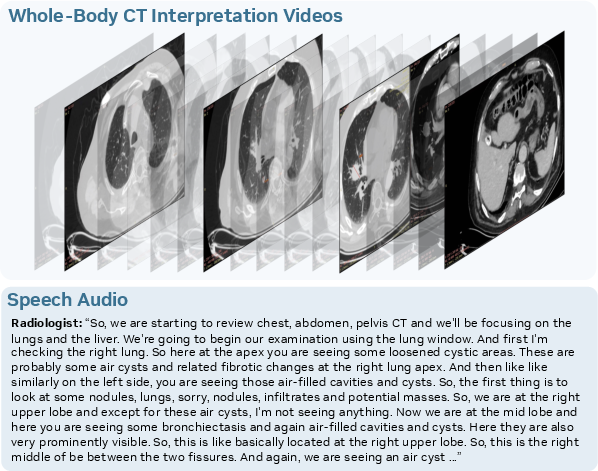
- Clinical visit documentation companion (non-diagnostic)
- Sector: Healthcare administration
- What it does: Captures physician explanations and patient interactions, produces structured notes, highlights key findings referenced in visuals (e.g., diagrams, charts).
- Tools/workflows: EHR note generation; consent capture workflows; redaction for PHI.
- Assumptions/dependencies: Regulatory compliance (HIPAA/GDPR); non-diagnostic use; local/secure deployment.
- Cross-lingual speech translation with visual grounding
- Sector: Localization, Customer support
- What it does: Translates speech with visual context (slides, product demos), improving disambiguation and terminology handling.
- Tools/workflows: ASR + translation + TTS pipeline; terminology injection via retrieval; live webinar support.
- Assumptions/dependencies: Domain-specific glossary; multi-language ASR quality; reliable network for streaming.
- Accessibility co-pilot
- Sector: Accessibility, Consumer apps
- What it does: Generates audio descriptions for visually impaired users and accurate captions for hearing-impaired users by combining audio cues and visual content.
- Tools/workflows: Smartphone/desktop overlay; offline batch processing; TTS personalization.
- Assumptions/dependencies: On-device vs cloud trade-offs; personalization data; consistent AV sync.
- Content moderation and trust & safety
- Sector: Platform governance, Policy
- What it does: Flags risky scenes by combining audio signals (slurs, threats) and visual context (symbols, actions); produces evidence with temporal references.
- Tools/workflows: Moderation queues; evidence snippets aligned via TEG/CRTE; human review escalation.
- Assumptions/dependencies: Context sensitivity; cultural nuance; policy definitions; appeal workflow.
- Scientific figure and document comprehension
- Sector: Academia, Publishing
- What it does: Jointly interprets figures, charts, and spoken explanations from talks; extracts claims, methods, and limitations; supports peer-review assistance.
- Tools/workflows: Conference talk summarization; figure QA; bibliographic linking; prompt templates for scientific domains.
- Assumptions/dependencies: Domain tuning for field-specific notation; citation grounding.
- Developer training recipe and alignment toolkit
- Sector: ML/AI tooling
- What it does: Uses OmniAlignNet, TEG, and CRTE to build time-aware AV alignment; 24M data pipeline for omni-modal conversations; reduces tokens needed to reach SOTA-level performance.
- Tools/workflows: Training pipelines; synthetic omni-modal data engine; evaluation harnesses (WorldSense, DailyOmni, Video-MME, MMAR).
- Assumptions/dependencies: GPU availability; licensing for models/datasets; data governance.
- Home video assistant
- Sector: Consumer, Daily life
- What it does: Automatically summarizes family events, DIY tutorials, cooking sessions using speech, ambient sound, and visuals; produces searchable timelines.
- Tools/workflows: Smart camera integrations; private local processing; timeline-based retrieval.
- Assumptions/dependencies: Privacy safeguards; on-device inference or encrypted cloud; household consent.
Long-Term Applications
These applications require further research, scaling, safety validation, domain adaptation, or edge deployment optimizations before broad rollout.
- Autonomous robot policies trained with omni-modal RL
- Sector: Robotics, Warehousing, Field operations
- What it could do: End-to-end policies that fuse audio cues (alarms, human guidance) with visual perception for reliable autonomy; faster convergence shown by AV-granular GRPO.
- Dependencies: Safety certification; sim-to-real transfer; failure mode analysis; continual learning.
- Clinical decision support using audio–visual signals
- Sector: Healthcare
- What it could do: Triaging and risk assessment by combining patient visuals (e.g., swelling, gait), medical imagery, and clinician commentary; explainable recommendations.
- Dependencies: Regulatory approval, large curated datasets, bias and fairness audits, robust generalization across hospitals.
- Edge omni-modal co-pilots on consumer devices
- Sector: Consumer electronics, Automotive, AR/VR
- What it could do: On-device camera–mic assistants for privacy-preserving AV reasoning (dashcams, AR glasses, smartphones); low-latency local decisions.
- Dependencies: Model compression/distillation; hardware acceleration; battery constraints; offline robustness.
- Smart city public safety sensing
- Sector: Public sector, Policy
- What it could do: Multi-sensor deployments analyzing ambient audio, camera feeds, and context for incident detection and response (accidents, crowd turbulence).
- Dependencies: Privacy regulations, public consent, false positive minimization, scalable infrastructure, transparency.
- Finance and compliance surveillance
- Sector: Finance, Legal
- What it could do: Audit trader floor videos and meeting audio for potential policy violations, with timeline-aligned evidence and multi-hop reasoning.
- Dependencies: High accuracy thresholds, legal admissibility, retention policies, domain adaptation for financial jargon.
- Industrial predictive maintenance with acoustic–vision fusion
- Sector: Manufacturing, Energy
- What it could do: Detect early machine faults via acoustic signatures aligned with visual observations; schedule interventions; reduce downtime.
- Dependencies: Sensor coverage, labeled failure datasets, plant-specific calibration, integration into CMMS.
- Advanced broadcast automation
- Sector: Media & Entertainment
- What it could do: Automated camera switching, narrative generation, lower-thirds production, and multilingual dubbing driven by AV reasoning and production rules.
- Dependencies: Latency guarantees, editorial oversight, brand safety, integration with broadcast control rooms.
- Scientific multimedia assistant for research workflows
- Sector: Academia, R&D
- What it could do: Align talk audio, slide visuals, and papers to produce structured knowledge graphs, reproducibility checks, and cross-paper comparisons.
- Dependencies: Domain-specific fine-tuning; citation grounding; provenance tracking.
- Synthetic omni-modal data engine as a product
- Sector: ML Ops, Data platforms
- What it could do: Commercial service to generate joint AV captions and QA with reasoning traces for training, evaluation, and benchmarking across domains.
- Dependencies: Content licensing; scalable curation; hallucination control; auditing pipelines.
- Policy-grade content classification and incident documentation
- Sector: Platform governance, Law enforcement
- What it could do: Standardized incident reports from AV footage with temporal alignment, multimodal evidence, and structured summaries for regulatory compliance.
- Dependencies: Clear policy definitions; transparency tools; human oversight; robust chain-of-custody.
Cross-cutting assumptions and dependencies
- Data governance and privacy: Many applications involve personal or sensitive data; consent, anonymization/redaction, and secure storage are required.
- Domain adaptation: While general benchmarks are strong, specialized domains (medicine, finance, manufacturing) require fine-tuning and expert-validated evaluation.
- Latency and compute: Real-time and edge scenarios need model compression, distillation, and hardware acceleration to meet performance targets.
- Robustness and safety: Audio-visual noise, occlusions, and adversarial content require resilience; safety-critical deployments need formal risk assessment.
- Integration: Tooling must bridge to existing systems (ROS/SCADA/EHR/LMS/broadcast), with clear operator workflows and human-in-the-loop safeguards.
- Legal and regulatory: Healthcare, public safety, and finance use cases need compliance and auditability; policy frameworks must define acceptable use and accountability.
These applications build directly on the paper’s contributions: improved AV alignment (OmniAlignNet), temporal modeling (TEG, CRTE), efficient training with reduced tokens, and the omni-modal data engine for high-quality supervision—enabling both immediate deployments and a roadmap for longer-term, high-impact systems.
Glossary
- Agentic-cascaded setups: A pipeline where an LLM is augmented by chained components (agents) at test time to improve performance. Example: "two agentic-cascaded setups: (i) incorporating ASR text history and (ii) leveraging retriever-based training"
- Aliasing: A signal-processing artifact where high-frequency patterns appear as lower-frequency due to insufficient sampling. Example: "without the issue of aliasing or ``wrapping around'' that would occur with high-frequency signals."
- Auto-regressive regime: A modeling setup where tokens are processed/generated sequentially, each conditioned on previous ones. Example: "we adopt an auto-regressive regime to encode visual and audio signals"
- Automatic Speech Recognition (ASR): The task of transcribing spoken audio into text. Example: "To assess the automatic speech recognition~(ASR) capabilities of OmniVinci, we evaluate it on four widely used benchmarks"
- Bidirectional alignment: Training that encourages two modalities to align in both directions (A→B and B→A). Example: "encouraging a bidirectional alignment between the modalities:"
- CLIP-style contrastive loss: A contrastive objective (as in CLIP) that pulls matched pairs closer and pushes mismatched pairs apart. Example: "we now apply CLIP-style contrastive loss on the output embeddings"
- Constrained Rotary Time Embedding (CRTE): A time-encoding method that applies bounded, multi-frequency rotations to embeddings to encode absolute timestamps. Example: "After CRTE, the temporally-aligned omni-modal embedding sequence is passed into the LLM backbone,"
- Contrastive learning: A representation learning paradigm that learns by contrasting positive and negative pairs. Example: "and then aligns them via contrastive learning, inspired by ImageBind"
- Cross-entropy loss: A standard classification loss; here used symmetrically for contrastive alignment. Example: "formulated as a symmetric cross-entropy loss"
- Data curation: The process of selecting, filtering, and organizing datasets for training. Example: "design choices across model architecture and data curation."
- Dot product: A similarity measure between vectors used in contrastive objectives. Example: "computed as their dot product, ."
- Explicit omni-modal learning: Direct supervision for joint visual-audio understanding using explicitly labeled multimodal data. Example: "we further propose an omni-modal data engine to synthesize omni-modal labeling for videos with audio tracks, enabling us to conduct explicit omni-modal learning."
- Factual grounding: Ensuring model outputs are tied to evidence present in input data. Example: "core vision-language capabilities such as factual grounding, reasoning over structured data, and complex multi-step inference"
- Frequency modulation: Scaling base frequencies by timestamps to encode time in rotations. Example: "To adapt frequencies to actual timestamps, we scale them as: "
- Geometric progression: A sequence where each term is a constant multiple of the previous; used for multi-scale frequency design. Example: "designed to have a geometric progression of frequencies."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that optimizes generation quality using group-normalized rewards. Example: "Building on advances in the Group Relative Policy Optimization (GRPO) algorithm"
- Implicit omni-modal learning: Learning joint multimodal understanding from naturally paired video-audio data without explicit cross-modal labels. Example: "This practice, we refer as implicit omni-modal learning, leads to notably improved performance"
- Joint captioning: A method that fuses audio and visual information to create a single, cross-modal caption. Example: "a joint captioning approach is preferred to integrate both modalities and produce comprehensive summaries across clips."
- L2 normalization: Scaling vectors to unit length to stabilize similarity computations. Example: "and L2 normalized, yielding the vision-omni embedding"
- Latent space: An internal vector space where multimodal inputs are represented and aligned. Example: "We next integrate embeddings from all modalities into a unified latent space as input for LLM."
- Learned Time Embedding: A trainable embedding that maps discrete timestamps to vectors (often via MLP). Example: "(i) ``Learned Time Embedding'' that defines a trainable embedding matrix, where each discrete timestamp in the range is mapped to a unique vector via MLP."
- LLM backbone: The core LLM that consumes aligned multimodal tokens. Example: "as input for LLM backbone."
- Long-RL: A reinforcement learning framework specialized for long-context multimodal training. Example: "we utilize the Long-RL as the training framework"
- Modality-specific hallucination: Errors arising when a model infers from a single modality and misses cross-modal context. Example: "We refer to this limitation as ``modality-specific hallucination''."
- Multi-hop reasoning: Answering questions via several inferential steps across multiple pieces of evidence. Example: "and multi-hop reasoning."
- Multi-scale representation: Encoding information at multiple temporal frequencies to capture fine-to-coarse time cues. Example: "enables a rich, multi-scale representation of temporal information"
- Omni-modal alignment mechanism: The procedure that fuses vision, audio, and text into a unified input stream for the LLM. Example: "via the proposed omni-modal alignment mechanism."
- Omni-modal data engine: A pipeline that synthesizes joint visual-audio annotations and QA data for explicit training. Example: "we further propose an omni-modal data engine to synthesize omni-modal labeling"
- Omni-modal joint training: The phase that trains on both unimodal and multimodal data to integrate capabilities. Example: "We employ two types of data in the omni-modal joint training phase"
- Omni-modal token sequence: A single sequence of tokens that interleaves and aligns multiple modalities. Example: "into a unified omni-modal token sequence via the proposed omni-modal alignment mechanism."
- OmniAlignNet: A module that aligns audio and visual embeddings into a shared space with contrastive objectives. Example: "we propose OmniAlignNet, which strengthens the learning of vision and audio embeddings"
- Policy model: The model being optimized in RL that generates candidate responses under a policy. Example: "the policy model, under the old policy $\pi_{\theta_{old}$, generates a set of candidate answers"
- Projector (modality-specific projector): A learnable mapping that converts modality features into a common embedding space. Example: "outputs of modality-specific projectors"
- Query embedding: A learned vector used to aggregate or attend over a sequence into a fixed-size representation. Example: "we initialize a vision query embedding and an audio query embedding ."
- Retriever-based training: Augmenting inputs with retrieved context to improve recognition or reasoning. Example: "leveraging retriever-based training"
- RoPE (Rotary Positional Embedding): A method that encodes positions via complex rotations across embedding dimensions. Example: "Similar to RoPE~\citep{su2024roformer}, given an embedding vector"
- RoTE (Rotary Time Embedding): A prior method that injects absolute time via rotation-based embeddings. Example: "``RoTE''~\citep{goel2024omcat}, a recent embedding method introduced in Section~\ref{sec:omni_align_mechanism}."
- Self-attention: A mechanism where tokens attend to each other to compute contextualized representations. Example: "processed through three layers of self-attention modules"
- Temporal Embedding Grouping (TEG): A method that organizes embeddings into temporally ordered groups to encode relative time. Example: "Temporal Embedding Grouping (TEG)."
- Time horizon (T_max): The maximum temporal span used to bound frequency scales in time embeddings. Example: "defines a maximum time horizon, $T_{\text{max}$, enabling a more balanced temporal sensitivity."
- Token concatenation: A baseline that forms inputs by simply concatenating tokens from modalities without alignment. Example: "Token Concatenation -- Baseline"
- Top-p sampling: Probabilistic decoding that samples from the smallest set of tokens whose cumulative probability exceeds p. Example: "a temperature of 1.0 and a top-p value of 0.99"
- Unified audio encoder: A single encoder used for both non-speech audio and speech to simplify the pipeline. Example: "employ a unified audio encoder to handle both acoustic and speech information"
- Word Error Rate (WER): A standard ASR metric measuring transcription errors as a percentage. Example: "word error rates (WER) of {1.7} on LibriSpeech-clean and {3.7} on LibriSpeech-other,"
- Test-time scaling: Techniques applied at inference (e.g., retrieval, history) to boost performance without retraining. Example: "These test-time scaling studies are provided in Appendix~\ref{sec:rag} (Table~\ref{tab:asr_appendix})."
Collections
Sign up for free to add this paper to one or more collections.