- The paper introduces a self-supervised RL post-training method that employs a proxy jigsaw task to restore the temporal order of shuffled video-audio clips.
- It leverages advanced modality orchestration strategies, including clip-level modality masking, to overcome bi-modal shortcuts and enhance benchmark performance.
- Ablation studies highlight that rigorous data filtering and accuracy-dependent reward adjustments are critical for robust omni-modal reasoning.
OmniJigsaw: Modality-Orchestrated Temporal Reordering for Self-Supervised Omni-Modal Reasoning
Motivation and Context
The transition from unimodal (typically textual or visual) LLMs to omni-modal paradigms, where models are tasked with simultaneous reasoning over temporally and semantically entangled video and audio streams, presents formidable data and supervision challenges. While reinforcement learning (RL) post-training has advanced complex reasoning in LLMs, the lack of scalable, high-quality annotated omni-modal data fundamentally limits transference of these advances. "OmniJigsaw: Enhancing Omni-Modal Reasoning via Modality-Orchestrated Reordering" (2604.08209) directly addresses this, proposing a self-supervised RL post-training method for omni-modal models that leverages large volumes of unannotated video-audio data through a proxy task: chronological reordering of shuffled clips. This approach is reinforced by a nuanced modality orchestration framework that overcomes key limitations found in naive multimodal proxy tasks, notably the modal shortcut phenomenon.
Framework and Methodology
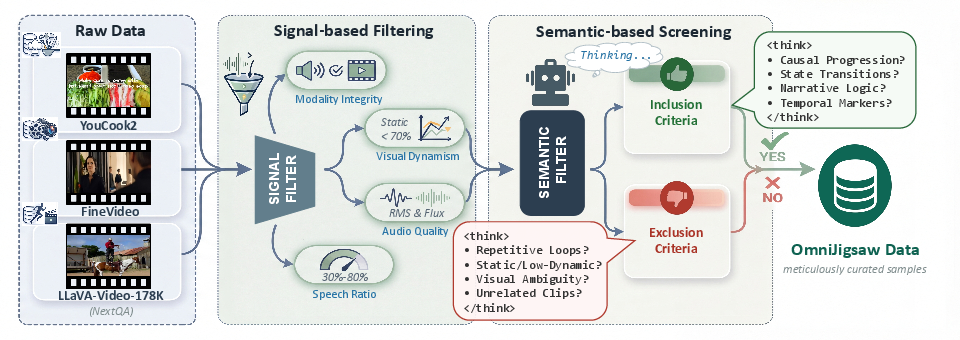
OmniJigsaw structures its self-supervised post-training objective around restoring the original temporal order of shuffled video-audio clips. The framework adapts the classic jigsaw permutation task to the omni-modal domain, deploying the following pipeline:
- Data Preprocessing and Filtering: Raw videos are segmented temporally into non-overlapping synchronized clips. To maximize task informativeness, a two-stage data filtering pipeline is introduced:
- Modality-Orchestration Strategies: To balance cross-modal integration and avoid trivial shortcut solutions, three distinct strategies are deployed:
- Joint Modality Integration (JMI): Provides all visual and acoustic data for each clip, naively expecting the model to leverage joint signals.
- Sample-level Modality Selection (SMS): Selects a global dominant modality per sample, suppressing the non-informative stream based on model-driven arbitration.
- Clip-level Modality Masking (CMM): Enforces an information bottleneck by masking less salient modalities at the clip level via an adaptive selection process, driving the model to perform fine-grained cross-modal integration during temporal reordering.
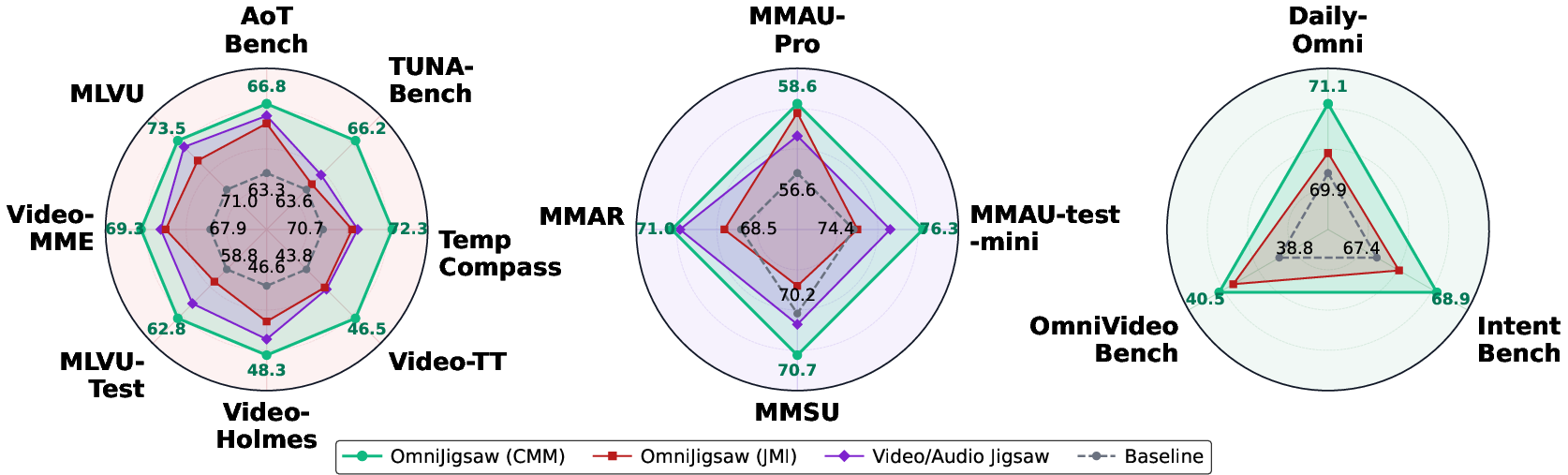
Figure 2: Performance comparison of JMI, CMM, and uni-modal Jigsaw across video, audio, and omni-modal benchmarks. CMM's consistent superiority and JMI's performance degradation relative to uni-modal Jigsaw baselines compellingly support the "bi-modal shortcut phenomenon".
Empirical Results
The framework is instantiated on Qwen3-Omni-30B-A3B-Instruct, and extensively evaluated on fifteen benchmarks: eight for video, four for audio, and three for collaborative omni-modal reasoning. All results emphasize the importance of fine-grained data curation and modality orchestration.
Key findings:
- CMM outperforms both JMI and SMS across all domains, especially on complex benchmarks such as MLVU-Test (+4.38), MMAR (+2.50), and OmniVideoBench (+1.70), indicating that enforced cross-modal bottlenecks catalyze mutual modality synergy and robust timeline reasoning.
- JMI reveals a "bi-modal shortcut phenomenon", as performance degrades compared to uni-modal Jigsaw baselines (Figure 2). The model tends to default to the most informative single modality, under-utilizing complementary cues and impairing weaker modality representation learning.
- Ablations demonstrate that data quality and reward function granularity are critical: The two-stage data filter eliminates samples where reordering is ill-posed, yielding higher downstream gains; introducing an accuracy-dependent reward discount catalyzes optimal sequence restoration by suppressing sub-optimal reasoning plateaus.

Figure 3: Comparison of CoT reasoning between CMM and JMI at training step 800. CMM (left) compels the model to jointly analyze visual and auditory cues by masking less salient modalities (dashed boxes) to create an information bottleneck, while JMI (right) exhibits a bi-modal shortcut by solely relying on linguistic cues and bypassing the necessary visual analysis.
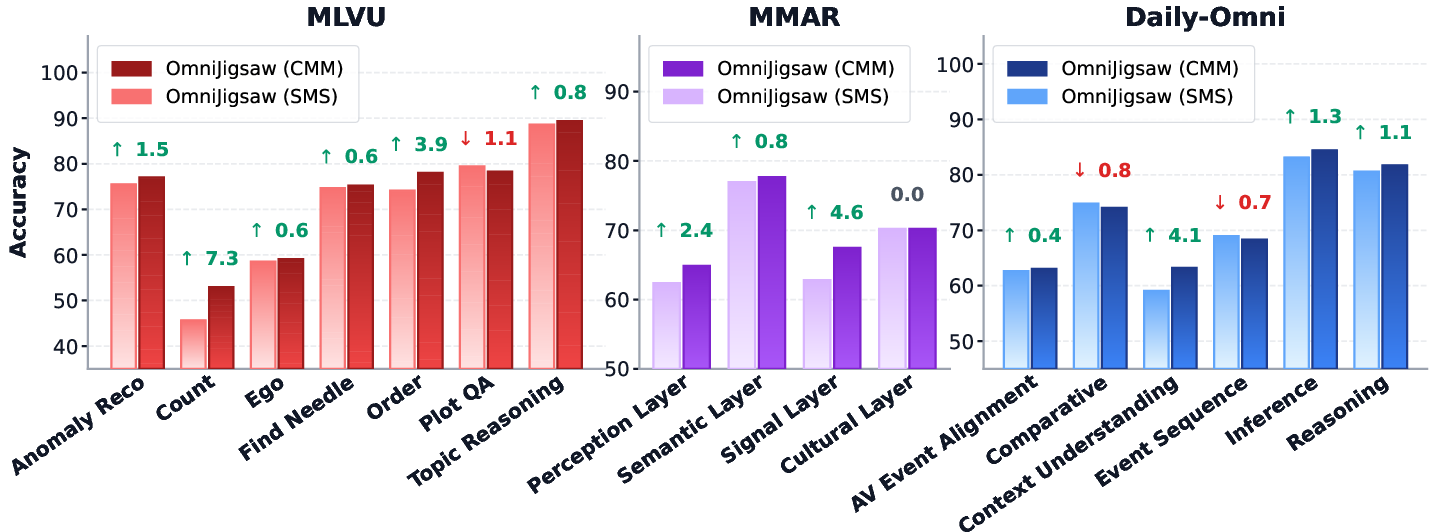
Figure 4: Sub-capability performance comparison between CMM and SMS across fine-grained dimensions. CMM's predominant superiority over SMS highlights the efficacy of clip-level orchestration in capturing temporally non-uniform audio-visual cues, whereas sample-level arbitration often misses local high-value modal information.
Analysis of Modality-Orchestration Paradigms
The ablation and breakdown reveal several high-impact design observations:

Figure 7: Qualitative example of Sub-Scene Captioning. Comparison between the Qwen3-Omni-30B-A3B-Instruct baseline and its OmniJigsaw (CMM)-post-trained variant.
Implications and Future Directions
The results establish that a properly designed, annotation-free proxy task can drive non-trivial gains in omni-modal collaborative reasoning. Several implications arise:
- Theoretical: These findings reinforce that information redundancy in multimodal proxy tasks can undermine cross-modal representation quality unless mitigated by active orchestration and dynamic information bottlenecks.
- Practical: The two-stage filtering pipeline, paired with modality-dynamic masking, provides a scalable blueprint for self-supervised omni-modal post-training that is agnostic to costly manual annotations.
- Future Work: Open avenues include curriculum and capability-aware data curation, exploration of more sophisticated reward shaping functions, extension to other proxy puzzles (e.g., variable-length or overlapping segments, spatio-temporal reordering), and systematization across additional model families and architectures.
Conclusion
OmniJigsaw delivers a scalable, annotation-free methodology for post-training omni-modal models, validated by consistent state-of-the-art performance across a suite of challenging video, audio, and collaborative reasoning benchmarks. Its data curation pipeline and clip-level modality-masking orchestration together counteract the modal shortcut phenomenon, catalyze robust temporal and cross-modal reasoning, and offer critical design insights for the development of next-generation self-supervised omni-modal AI systems.