- The paper presents a systematic framework using the Persona Modality Graph and a new Calibrated Accuracy metric to assess omnimodal personalization.
- It employs RL-driven training (RLVR) to enhance calibration, significantly reducing hallucinations and improving cross-modal grounding.
- Experimental results show that RLVR outperforms SFT in boosting personalization performance, despite trade-offs in lexical fluency and abstention precision.
Systematic Benchmarking and RL-Driven Advances in Omnimodal Personalization
Introduction and Omnimodal Personalization Motivation
Omni-Persona delivers a technically rigorous benchmark and diagnostic framework for personalization in omnimodal LLMs that natively process text, image, and audio. While progress in multimodal LLMs has accelerated, research on systematic personalization — enabling models to ground responses in user-specific context across all modalities — is stunted by blind spots in existing benchmarks, which predominantly evaluate vision-text tasks and disregard absent-persona scenarios and personalized calibration. This paper formalizes omnimodal personalization as a cross-modal routing paradigm utilizing the Persona Modality Graph (PMG), explicitly incorporating audio as a core modality and addressing the calibration challenge by proposing the Calibrated Accuracy (Cal) metric, which jointly measures correct grounding and abstention given real-world retrieval noise.
The domain-specific formulation and diagnostic tools of Omni-Persona illuminate the insufficiencies of current methodologies and scalar metrics. The benchmark comprises 4 scenario groups and 18 fine-grained tasks, systematically assessing the capacity for perceptual grounding, retrieval, and abstention in both answerable and unanswerable scenarios.

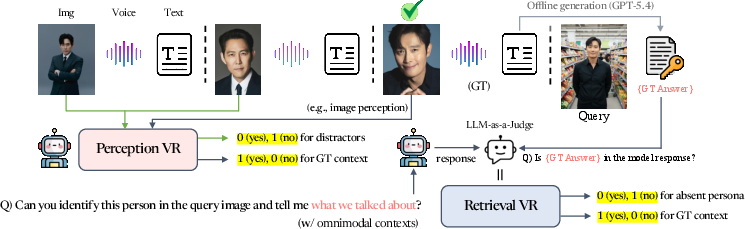
Figure 1: Task formulation in Omni-Persona — user queries comprise a target modality and text prompt, decomposed along axes of perceptual identification and realistic retrieval.
Benchmark Design, Task Taxonomy, and Methodological Innovations
The Persona Modality Graph (PMG) represents the critical abstraction unifying multi-context, omnimodal grounding in personalization. Each user profile is encoded as a triplet node containing image, audio, and text contexts. Given a query (with any modality as cue), the model is tasked with correctly matching the query to the appropriate context node and integrating its details in response generation. For unanswerable queries—where the correct persona is absent—the benchmark requires the model to abstain systematically rather than hallucinate, a dimension largely unaddressed in prior protocols.
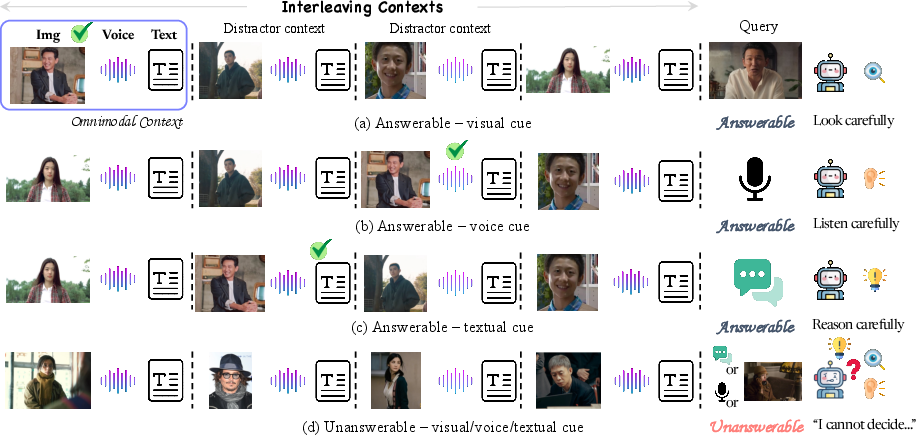
Figure 2: Context construction, query cues, distractors, and unanswerable cases are visually depicted; the benchmark simulates realistic retrieval complexity.
Benchmarks are designed to entangle models with hard distractors (visually/vocally similar but incorrect personas) and a substantial fraction (≈50%) of absent-persona cases. This design directly tests resistance to hallucination, a key practical limitation for RAG-integrated LLMs. By structuring open-ended cross-modal tasks—e.g., requiring semantic bridges from audio cue to text, or vice versa—Omni-Persona rigorously measures grounding expressiveness and exposes modality-specific biases.
Calibration, Metrics, and Evaluation Paradigm
Omni-Persona introduces Calibrated Accuracy (Cal), defined as the mean of answerable recall and unanswerable recall (abstention):
Cal=21(Ans+Unans),
where "Ans" is LLM judge-based correctness for answerable queries, and "Unans" is abstention rate for unanswerable queries, determined via keyword matching. This metric closes the gap left by recall-only evaluation, reflecting not only successful retrieval but also appropriate failure in the face of missing evidence — critical for deployment in open contexts.
Complementary anti-hallucination metrics, 1−FA (false abstention complement for answerable items) and TA (true abstention for unanswerable cases), quantify generation quality and error polarization. The framework additionally cross-references conventional metrics (ROUGE-L, token-F1, BERTScore), but demonstrates systematically that these do not align with calibrated personalization behavior, justifying the need for judge-based assessment.
Systematic Model Evaluation and Post-Training Regimes
The experimental analysis covers multiple open- and closed-source omnimodal models — notably Qwen2.5-Omni, Gemma4 (E2B, E4B), MiniCPM-o, and the Gemini-3 family — under various post-training regimes: zero-shot, SFT (1K and 10K samples), and RLVR (Reinforcement Learning with Verifiable Rewards).
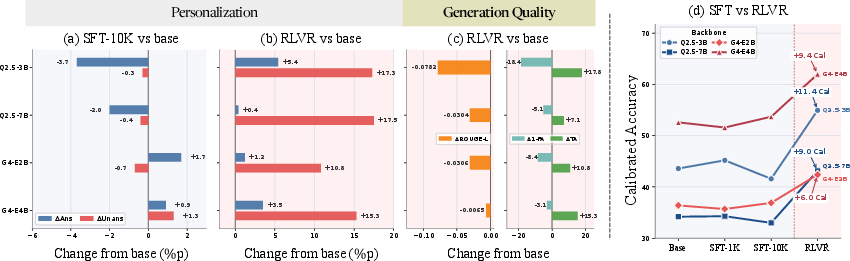
Figure 3: Comparative calibration and personalization performance for SFT scaling vs. RLVR in Gemma4 E4B and Qwen2.5-Omni models.
Strong empirical findings include:
Diagnostic Analysis and Key Empirical Findings
Three critical diagnostic findings emerge from the systematic evaluation:
- Audio perception lags visual perception: Open-source models consistently underperform on audio-based (A2A) grounding compared to visual (I2I) tasks (performance gap: 15–25%p in answerable recall). RLVR closes this gap partially through dense, rule-based perceptual supervision.
- Recall and scale are incomplete diagnostics: Larger models (e.g., Qwen3-Omni-30B) may have higher recall on certain tasks but perform worse in calibrated accuracy and hallucinate more often. Cal exposes these divergences, necessitating dual-axis reporting for deployment-critical personalization.
- RLVR versus SFT: SFT’s effectiveness is bottlenecked by the scarcity and noise of ground-truth supervision in diverse settings, and simply scaling the SFT corpus does not improve Cal. RLVR circumvents this bottleneck with outcome-level verifiable rewards, reliably improving calibration but at a modest cost to lexical overlap and answer length due to conservative answering policies.
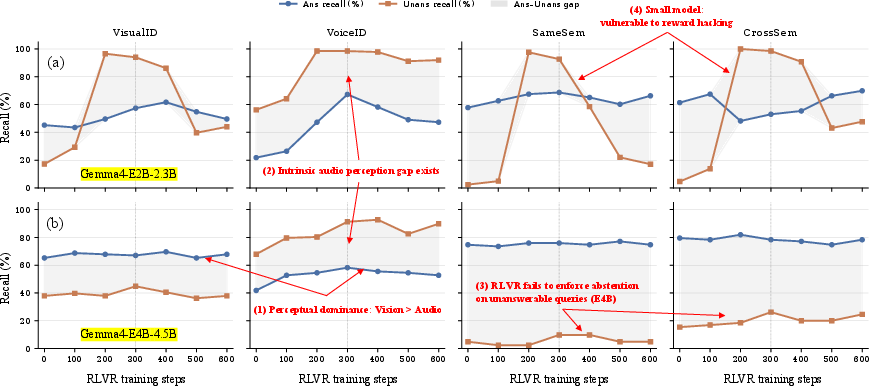
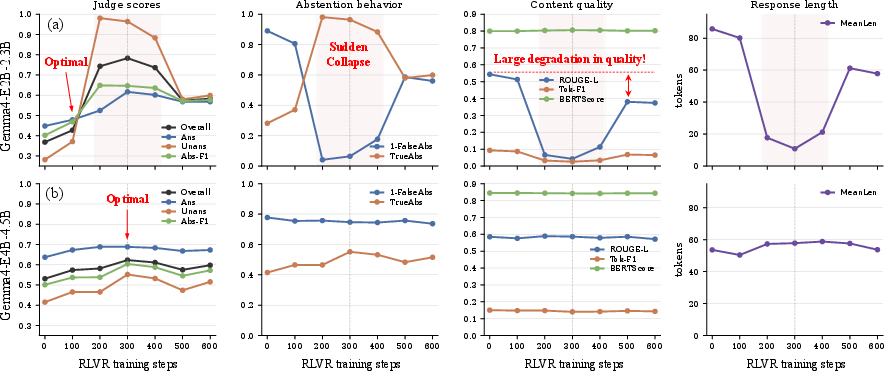
Figure 5: RLVR training dynamics illustrate divergent behavioral trajectories, with different models exhibiting characteristic trade-offs between grounding, abstention, and output fluency.
Qualitative Analysis and Generalization
Qualitative comparisons further evidence that baseline models favor visual cues even when audio is the dominant signal, whereas RLVR-tuned models more appropriately ground responses in the correct modality—even in the presence of confounding distractors.

Figure 6: RLVR-trained Gemma4-E4B leverages audio cues for grounding, while the base model erroneously defaults to visual signals.
Additional scenario analyses and per-group task breakdowns reveal the limits of post-training: while RLVR consistently boosts calibrated abstention and reduces hallucinations, cross-modal semantic tasks and highly textual tasks (T2T, T2Any) remain failure modes for smaller and less-capable backbones, suggesting inherent representational and optimization limits.
Implications and Future Directions
Omni-Persona sets a new methodological standard for research in personal AI assistants by introducing rigorous absent-persona calibration, evaluating raw audio-text-image fusion, and providing detailed error taxonomies. Practically, its findings indicate that proximate deployment of omnimodal assistants must address residual perceptual biases, the risk of over-conservative abstention under RL reward designs, and the challenges of constructing high-fidelity, in-domain supervision for SFT.
Theoretically, the work strongly supports outcome-level RL for open-ended personalization and characterizes the behavioral and distributional shifts introduced by such approaches. Future research should extend reward shaping for asymmetric abstention/grounding trade-offs, explore on-device fine-tuning using private user signals, and develop agentic frameworks capable of dynamic memory expansion and multi-hop reasoning over evolving personal context.
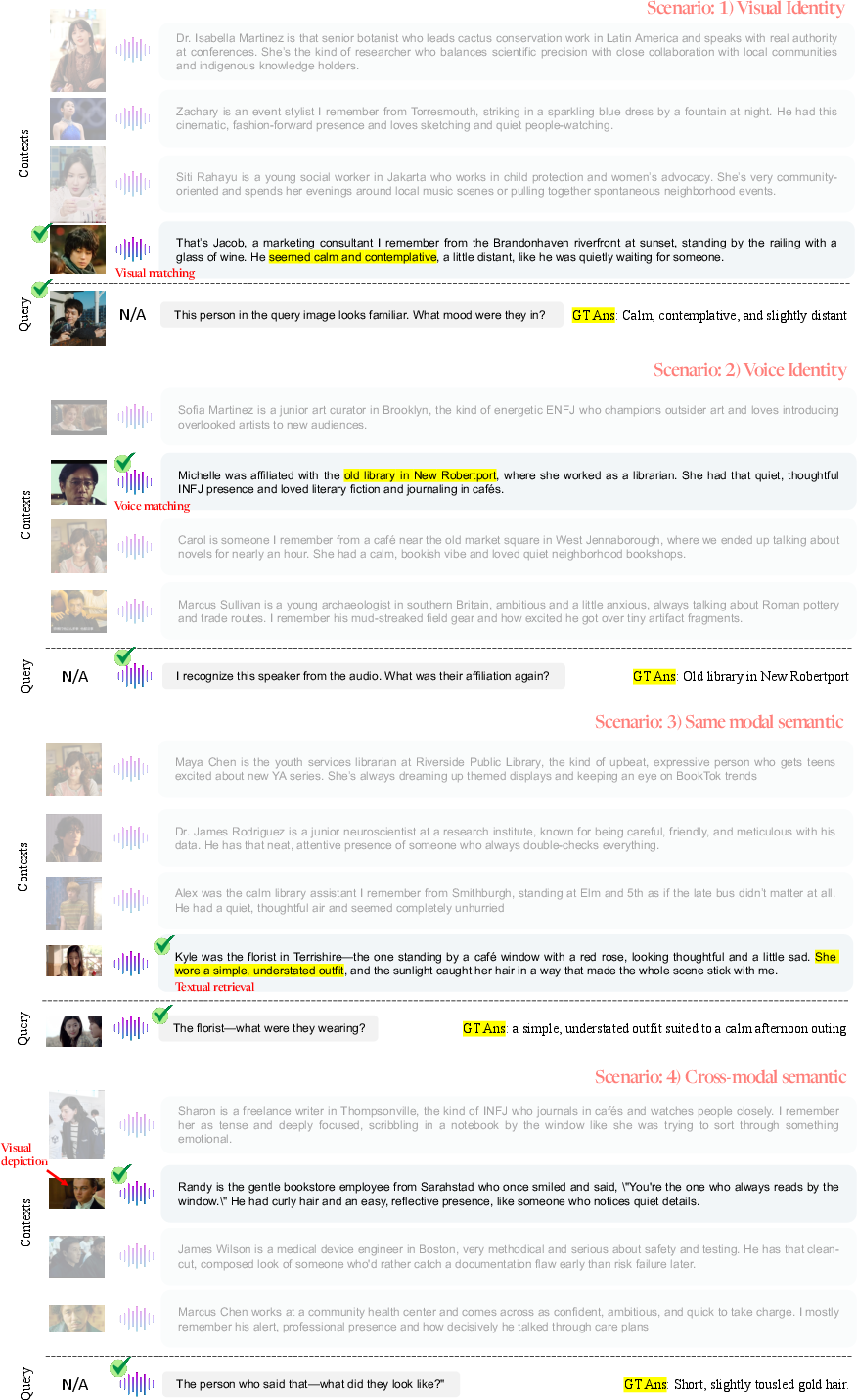
Figure 7: Example visualizations from each evaluation scenario, highlighting the breadth and complexity of omnimodal personalization cases tested by the benchmark.
Conclusion
Omni-Persona establishes a principled foundation for benchmarking and improving omnimodal personalization. RLVR, as validated by this benchmark, provides robust calibration benefits and mitigates hallucination failures that are invisible to traditional recall-based metrics and SFT scaling. The framework, metrics, and diagnostic taxonomy advanced here delineate the active research frontiers for personal AI assistants capable of authentic, flexible, and responsible personalization.