- The paper introduces InteractiveOmni, a parameter-efficient omni-modal model that integrates vision, audio, text, and speech for interactive multi-turn dialogue.
- The methodology employs a unified architecture with InternViT, Whisper-large-v3, Qwen3, and Cosyvoice2 to achieve state-of-the-art performance across multi-modal benchmarks.
- The model demonstrates robust long-term memory and efficient streaming capabilities, making it suitable for real-time AI assistants and interactive applications.
InteractiveOmni: A Unified Omni-modal Model for Audio-Visual Multi-turn Dialogue
Motivation and Problem Statement
The development of LLMs with multi-modal capabilities has advanced rapidly, yet most existing models are limited to single-turn interactions or focus on a subset of modalities (e.g., vision-language or audio-language). Human communication, in contrast, is inherently multi-modal and multi-turn, requiring integration of vision, audio, and language, as well as long-term memory and contextual understanding. The paper introduces InteractiveOmni, an open-source, parameter-efficient omni-modal LLM (4B–8B parameters) designed for end-to-end audio-visual multi-turn dialogue, with unified perception and generation across image, video, audio, and text, and direct streaming speech output.
Model Architecture
InteractiveOmni employs a modular yet unified architecture, integrating a vision encoder (InternViT), an audio encoder (Whisper-large-v3), a LLM decoder (Qwen3), and a streaming speech decoder (Cosyvoice2). The model processes arbitrary combinations of image, video, audio, and text inputs, and generates both text and speech outputs in a streaming fashion.
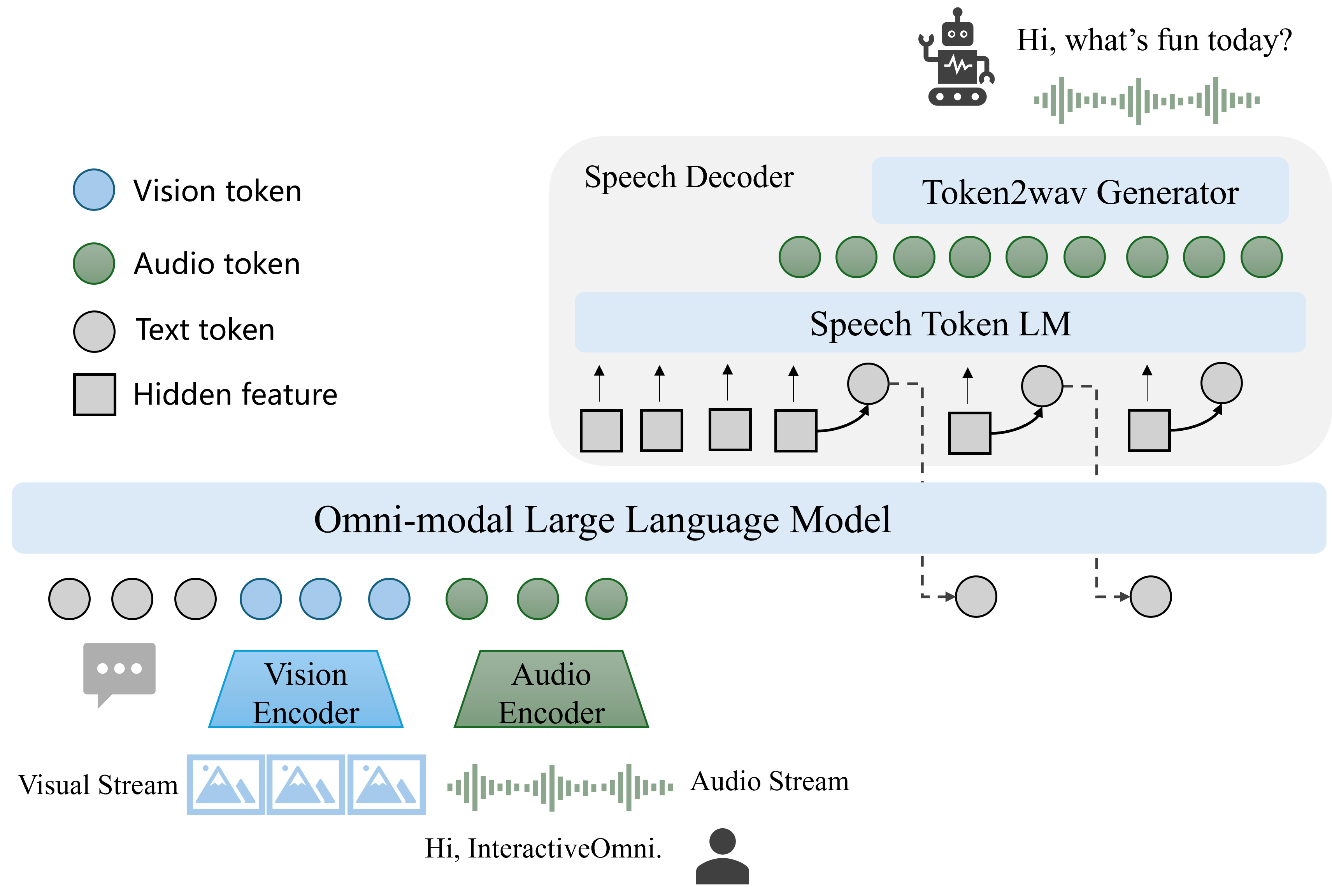
Figure 1: The overview framework of InteractiveOmni, showing the integration of vision encoder, audio encoder, LLM decoder, and streaming speech decoder for sequential text and speech generation.
Key architectural features include:
- Vision Encoder: InternViT-300M, with dynamic resolution tiling and pixel shuffle to reduce token count for high-res images and long videos.
- Audio Encoder: Whisper-large-v3, with mel-spectrogram preprocessing and a pooling layer to align audio token rates with the LLM.
- LLM Decoder: Qwen3, which receives concatenated visual and audio embeddings and decodes text tokens.
- Speech Decoder: Cosyvoice2, with a speech token LM and token2wav generator, interleaving text and speech tokens (5:25 ratio) for streaming output.
This design enables end-to-end training and inference, supporting both speech-to-text and speech-to-speech dialogue, with style-controllable speech synthesis.
Data Construction and Training Paradigm
A critical contribution is the construction of a large-scale, high-quality, multi-turn, multi-modal training dataset. The data pipeline samples visual elements from curated repositories, generates contextually relevant questions using vision-LLMs, and synthesizes speech-based question-answer pairs via TTS, ensuring coverage of various memory and reasoning types (image-irrelevant, image-relevant, historical image/text/mixed memory).
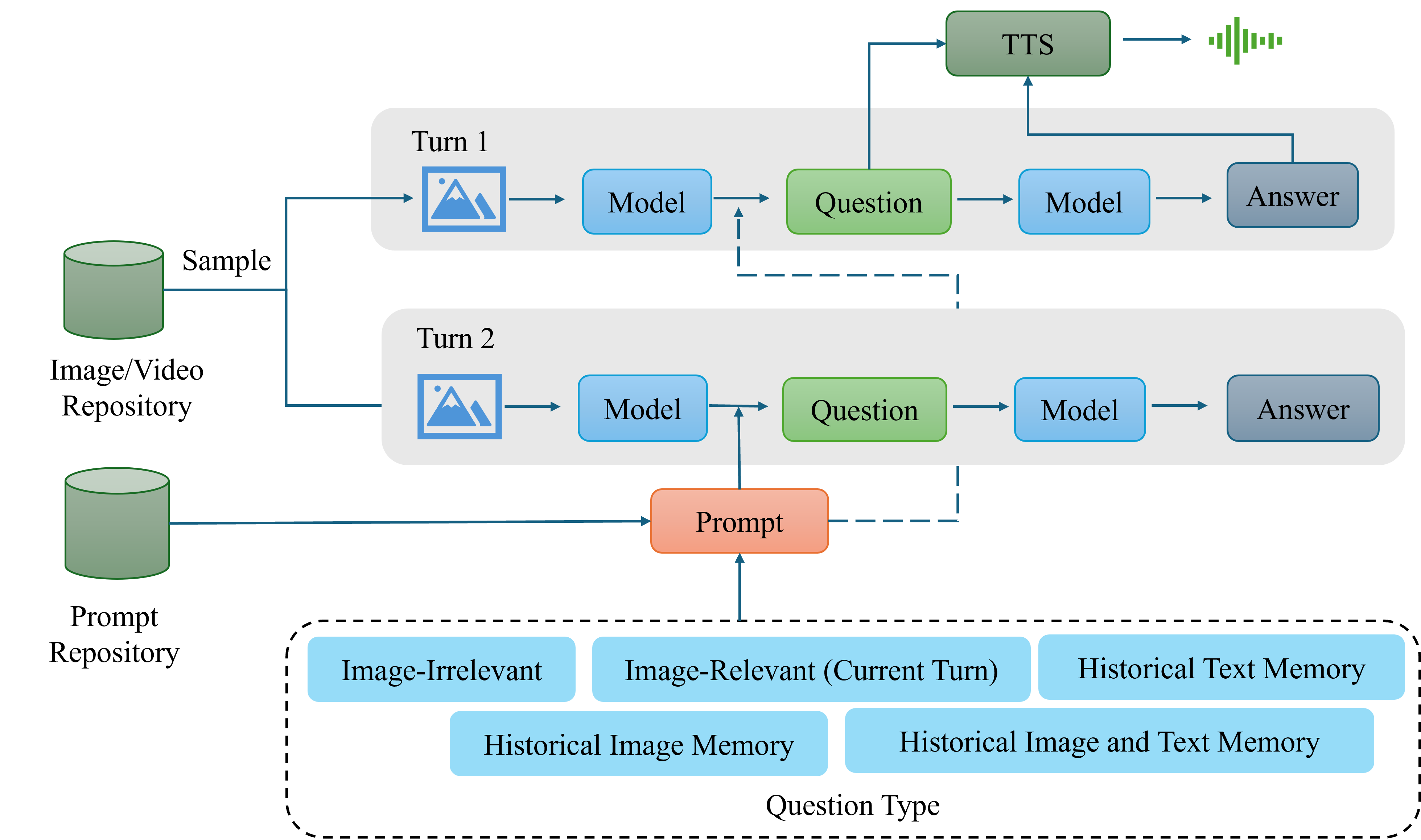
Figure 2: Data construction pipeline for multi-turn dialogue, including visual sampling, question generation, memory turn design, and TTS conversion for end-to-end training.
The training procedure is multi-stage:
- Omni-modal Pre-training: Progressive alignment of vision-text, audio-text, and mixed multi-modal data, with instruction-following data included. Data-packing and long-context support (up to 32k tokens) are used for efficiency.
- Post-training: Supervised fine-tuning on audio-visual interaction and speech-to-speech data, with hard sample mining and DPO (Direct Preference Optimization) for improved multi-turn conversational quality. Model merging is used to further enhance performance.
Multi-turn Interaction and Long-term Memory
InteractiveOmni is evaluated on newly constructed multi-turn benchmarks:
- Multi-modal Multi-turn Memory Benchmark (MMMB): Assesses the ability to recall and reason over historical images and text in multi-turn dialogues.
- Multi-turn Speech Interaction Benchmark (MSIB): Evaluates end-to-end speech-to-speech dialogue across dimensions such as emotional expression, rate control, role-playing, and instruction following.

Figure 3: Schematic of multi-turn audio-visual interaction, highlighting perception of external audio/video, active user interaction, multi-turn memory, and empathy.
InteractiveOmni demonstrates robust long-term memory, maintaining high accuracy even as the number of memorized images and turn distance increases, outperforming open-source baselines and approaching proprietary models like Gemini-2.5-Flash and GPT-4o-mini.
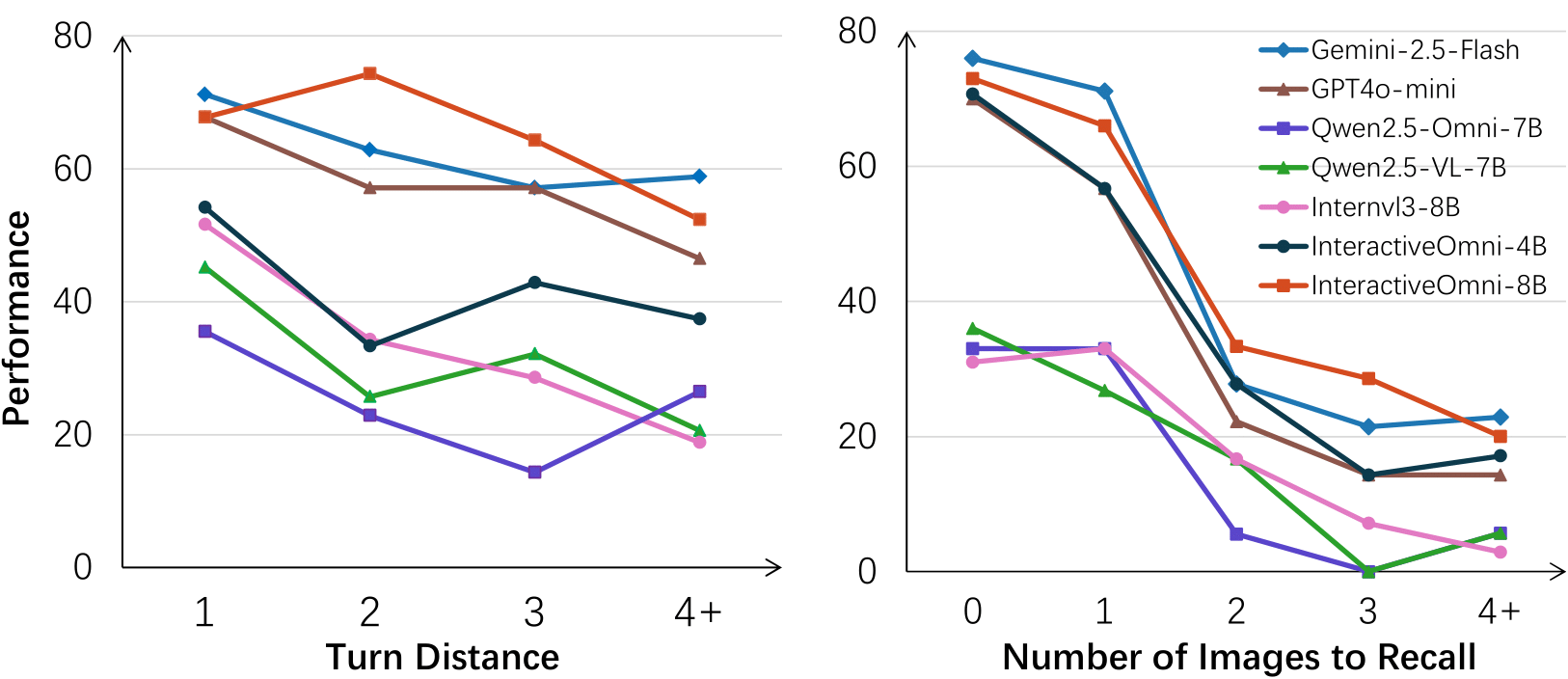
Figure 4: Performance degradation with increased recall burden; InteractiveOmni maintains superior accuracy compared to open-source models as turn distance and memory load increase.
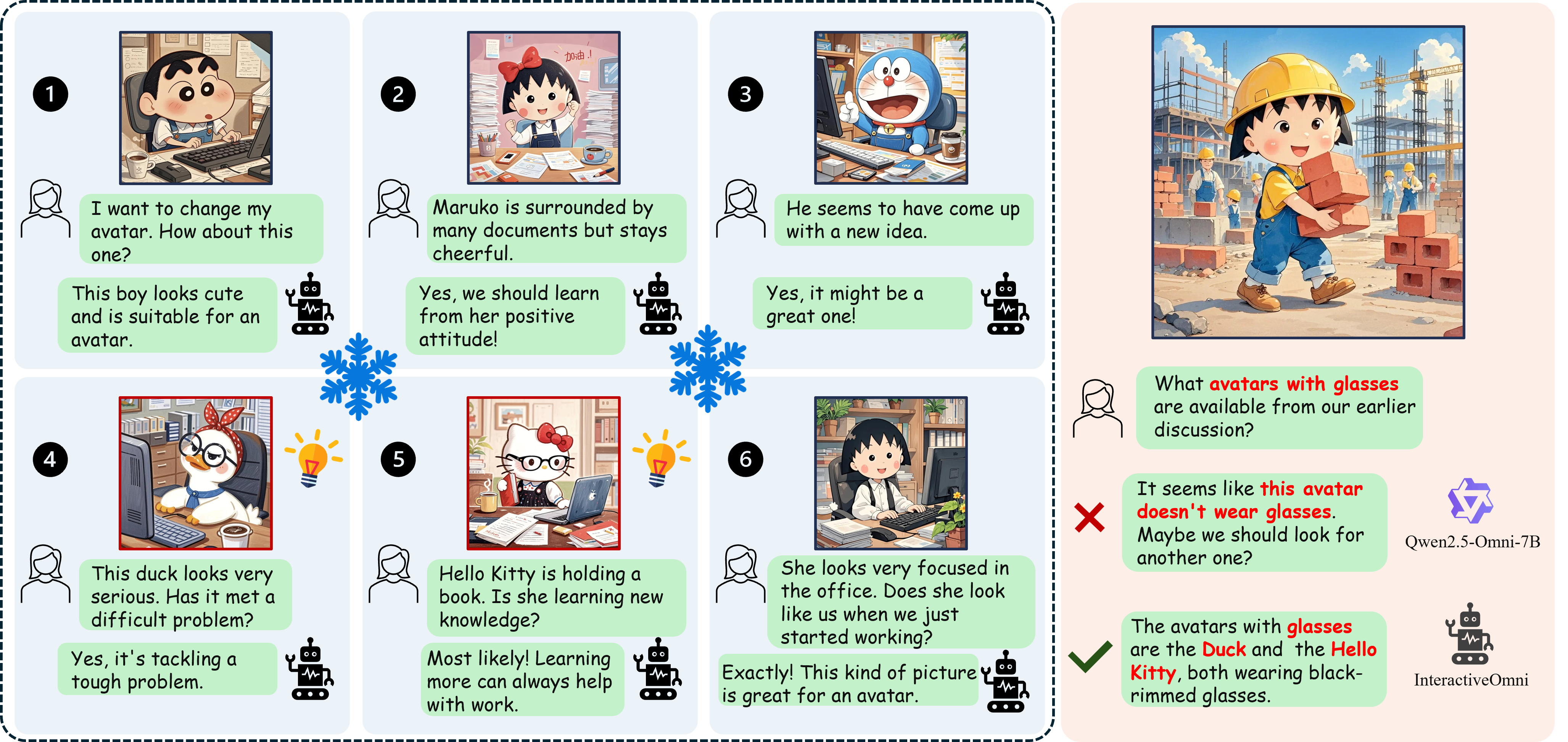
Figure 5: Example of multi-turn conversation requiring historical image context, where InteractiveOmni outperforms Qwen2.5-Omni-7B in long-term memory.
Benchmark Results and Comparative Analysis
InteractiveOmni achieves state-of-the-art or highly competitive results across a broad spectrum of open-source benchmarks:
- Image, Video, and Audio Understanding: Outperforms or matches leading open-source models (e.g., Qwen2.5-VL-7B, InternVL3-8B, Kimi-Audio) on MMBench, MMStar, MMAU, AIR-Bench, and others.
- Speech Generation and TTS: Achieves WER on Seed-TTS and EmergentTTS-Eval comparable to professional TTS systems, with strong performance on style-controllable and complex prosodic scenarios.
- Speech-to-Speech Dialogue: Delivers high MOS and model-as-judge scores on MSIB, with clear advantages in emotional expressiveness, role-playing, and creative capacity.
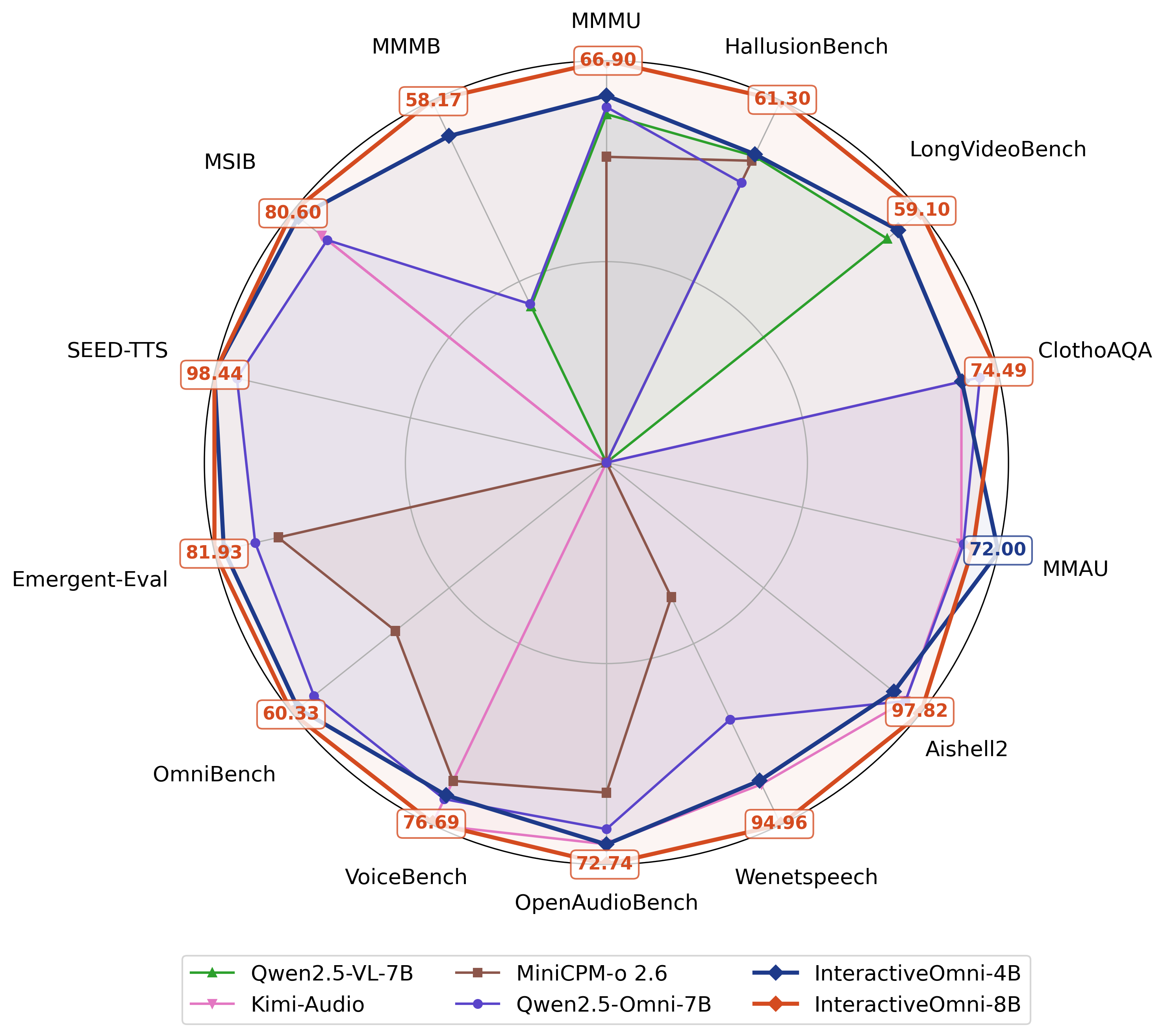
Figure 6: Evaluation across image, video, and audio modalities; InteractiveOmni outperforms current leading multi-modal models on open-source benchmarks.
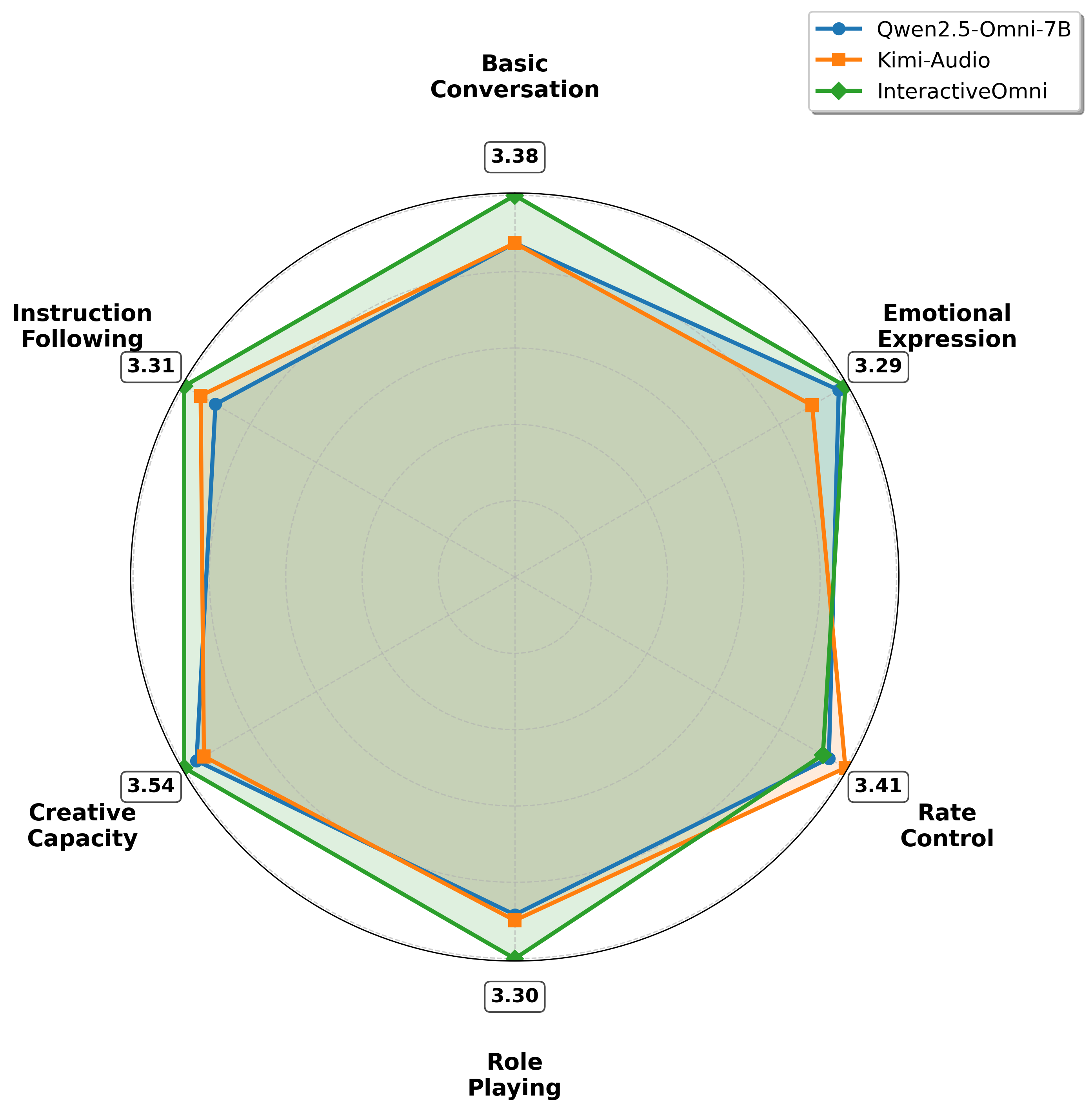
Figure 7: Human evaluation of speech-to-speech interactions on MSIB, showing InteractiveOmni's superiority in conversational quality and expressiveness.
Implementation Considerations and Trade-offs
- Parameter Efficiency: InteractiveOmni-4B retains 97% of the 8B model's performance at half the size, and matches or exceeds larger models like Qwen2.5-Omni-7B on general benchmarks.
- Unified End-to-End Pipeline: The architecture supports seamless integration of all modalities, reducing system complexity and latency compared to cascaded ASR-LLM-TTS pipelines.
- Streaming and Real-time Capabilities: The interleaved token generation enables low-latency, streaming speech output, suitable for interactive applications.
- Data and Compute Requirements: The model leverages extensive open-source, synthetic, and in-house data, with multi-stage training and large context windows, necessitating significant compute resources for pre-training and fine-tuning.
- Limitations: Despite strong results, performance degrades with increased memory burden, and further improvements in long-term context modeling and multi-modal alignment remain open challenges.
Implications and Future Directions
InteractiveOmni establishes a new standard for open-source, parameter-efficient omni-modal LLMs with robust multi-turn, multi-modal, and speech-to-speech capabilities. The unified architecture and training paradigm facilitate deployment in real-world interactive systems, including AI assistants, accessibility tools, and multi-modal agents.
The results highlight the importance of high-quality, multi-turn, multi-modal data and end-to-end training for achieving human-like conversational flow and memory. Future work should focus on:
- Enhancing real-time efficiency and reducing inference latency for deployment on edge devices.
- Expanding the model's capacity for abstract, cross-modal reasoning and more complex inter-modal relationships.
- Further improving long-term memory and context retention, especially in extended multi-turn dialogues.
- Exploring more advanced alignment and fusion strategies for heterogeneous modalities.
Conclusion
InteractiveOmni demonstrates that a unified, open-source omni-modal LLM can achieve state-of-the-art performance in multi-turn audio-visual dialogue, long-term memory, and expressive speech generation, while maintaining parameter efficiency. The model's architecture, training methodology, and benchmark results provide a robust foundation for the next generation of multi-modal AI assistants and interactive systems, with significant implications for both research and practical deployment.

