- The paper introduces the Daily-Omni benchmark that integrates temporal alignment for audio-visual reasoning in real-world scenarios.
- The methodology leverages an automated QA pipeline with models like Gemini 2.0 Flash and Deepseek-R1 to generate diverse, scalable datasets.
- Results demonstrate that the Daily-Omni Agent improves cross-modal integration, setting a new baseline for multimodal reasoning benchmarks.
Daily-Omni: Towards Audio-Visual Reasoning with Temporal Alignment across Modalities
The "Daily-Omni" paper introduces a benchmark designed to evaluate and enhance the ability of Multimodal LLMs (MLLMs) in reasoning through synchronized audio-visual information. The paper addresses the gap in current MLLMs which struggle to integrate cross-modal data synchronously, a skill necessary for real-world applications where audio and visual signals provide essential contextual understanding.
Introduction
Daily-Omni consists of 684 videos reflecting everyday scenarios, enriched with audio and visual elements, along with 1197 multiple-choice questions across six major tasks. The goal is to explore how MLLMs manage information requiring both auditory and visual integration, measuring their performance and identifying typical challenges faced during perception and reasoning.
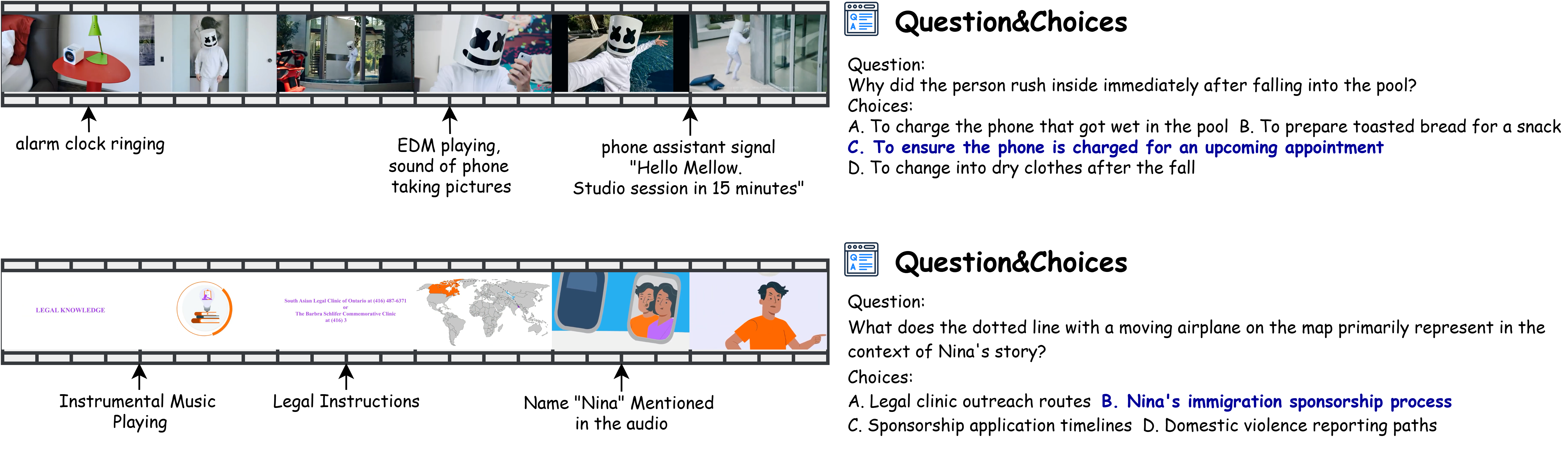
Figure 1: Examples of Daily-Omni QAs. The audio and visual information required for answering the questions are provided in the figure. The correct answer for the given questions are highlighted.
Existing models have achieved impressive results in isolated tasks such as ASR and OCR but fall short of effectively merging these modalities. The benchmark developed here focuses on tasks that require temporally aligned audio-visual comprehension beyond isolated sensory processing.
Benchmark and Methodology
Data Curation: Videos for the Daily-Omni benchmark are sourced from publicly available datasets, including AudioSet, Video-MME, and FineVideo. The criteria include ensuring a diverse representation of real-life scenarios and rich temporal dynamics, avoiding bias from static content or harmful material.
Daily-Omni QA Generation Pipeline: This innovative framework includes modules for video annotation, temporal alignment, and QA synthesis. The automated pipeline leverages cutting-edge models like Gemini 2.0 Flash and Deepseek-R1 to generate high-quality question-answer pairs with efficiency and scalability (Figure 2).
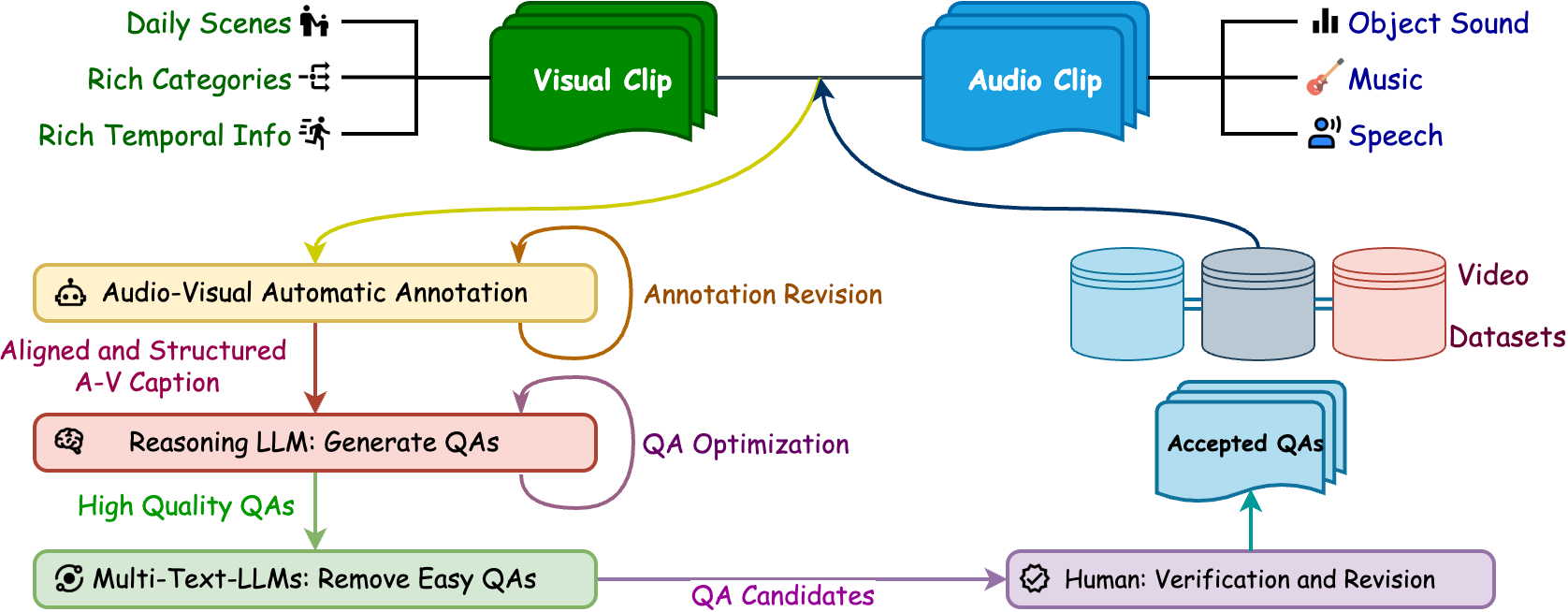
Figure 2: The outline of Daily-Omni QA construction pipeline. The arrows indicates the sequence of the processes.
Daily-Omni Agent: Comprising of open-source models, including Qwen2.5-VL and Qwen2-Audio, the agent demonstrates significant performance improvements through combined visual and audio processing techniques, establishing a baseline for this benchmark.
Experiments
Experiments indicate substantial challenges remain in achieving integrated audio-visual reasoning. Current models excel in general domain understanding but show limitations in complex scenarios demanding nuanced cross-modal temporal awareness.
(Table 1)
Figure 3: MLLMs' accuracy over different question categories.
Results and Discussion
The Daily-Omni Agent shows promising results as the best-performing open-source approach, emphasizing the efficacy of simple but effective alignment techniques. Through a combination of segmented audio-visual annotations and priority event alignment, it achieves superior performance compared to previous benchmarks. Gemini models, despite being proprietary, demonstrate advanced capabilities in cross-modal synergy, highlighting areas for potential open-source improvement.
Conclusion
The conclusions drawn from Daily-Omni underline the need for more robust temporal correlation methods when designing multimodal systems. Enhanced integration techniques would pave the way for AI capable of more sophisticated understanding in complex, real-world environments. The benchmark facilitates future research into improving audio-visual models' perceptive accuracy and reasoning abilities, contributing significantly to MLLM advancements.
In summary, Daily-Omni offers valuable insights into current MLLM limitations while providing a strategic path forward for researchers aiming to develop more nuanced and capable audio-visual integration systems. The methodology and findings serve as a cornerstone for ongoing advancements in multimodal learning and application.