- The paper introduces a novel 'Think-with-Omni' paradigm that uses recursive tree search for efficient and deliberative audio-visual reasoning.
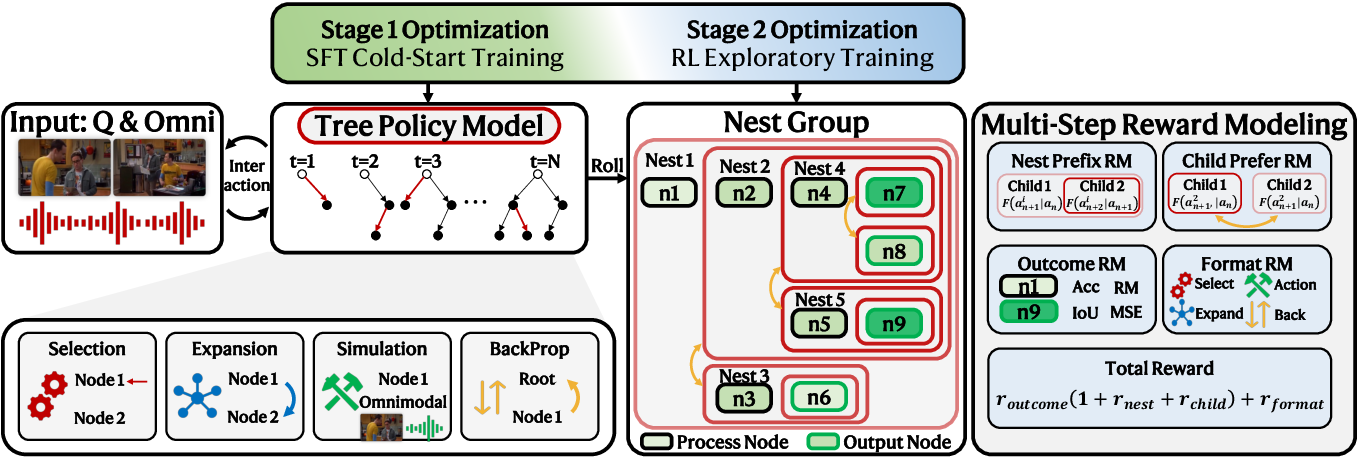
- It employs a two-stage training process combining SFT and RL, with an MCTS-driven data engine to curate high-quality multi-turn reasoning trajectories.
- Experimental results demonstrate significant performance gains across 11 benchmarks, outperforming both open-source and closed-source audio-visual systems.
Deep Nested Omnimodal Deduction for Deliberative Audio-Visual Reasoning: Omni-o3
Motivation and Framework Overview
Omnimodal reasoning with MLLMs exposes the model to a massive, highly redundant search space dominated by complex cross-modal interactions, demanding both efficiency and deliberative reasoning. Prevailing paradigms—linear stepwise (CoT) or parallel rollout—lack mechanisms for intermediate sharing and self-correction, which results in inefficient exploration and compounding errors in dense, multi-turn audio-visual tasks.
Omni-o3 introduces a fundamentally distinct paradigm ("Think-with-Omni"), elevating shallow verbal CoT protocols into a deliberative omnimodal tree search structure. By embedding omni skills and recursive deduction within multi-round reasoning, Omni-o3 overcomes the limitations of direct-response and isolated CoT models, inherently sharing omnimodal reasoning prefixes across branches to maximize computational efficiency.
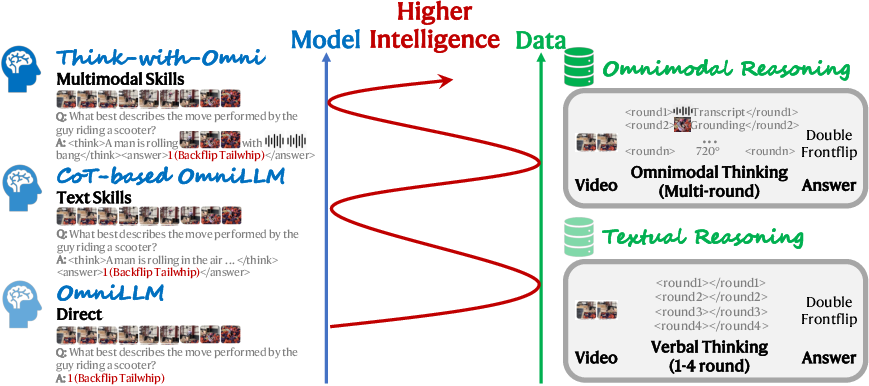
Figure 1: Paradigm comparison—Omni-o3’s Think-with-Omni enables deliberative omnimodal reasoning beyond direct response and verbal CoT.
Deep Nested Deduction: Methodology
Omni-o3 formulates its reasoning policy as a dynamic recursive search, structuring the reasoning process into hierarchical trees. The model executes four atomic cognitive actions: expansion (generating new thoughts/sub-goals), selection (branch preference), simulation (invoking intrinsic omnimodal skills), and backpropagation (updating node values). This nested deduction enables iterative exploration, backtracking, and multi-turn self-verification, substantially reducing redundant multimodal encoding and shifting computational focus to actual cognitive exploration.
The overall pipeline is decoupled into two progressive optimization stages:
Automated Data Engine: MCTS-driven Reasoning Trajectory Curation
To address the scarcity and complexity of multi-turn omnimodal reasoning data, an automated MCTS-driven data engine is deployed. This pipeline iteratively constructs reasoning trees from a vast pool of 3.5M samples, employing selection, expansion, simulation (with specialized solvers), and backpropagation. The result is a high-quality dataset: 101K sampled trajectories for SFT and 18K diverse, challenging cases for RL, spanning deep conversational structures, dense multimodal combinations, and extended context lengths.
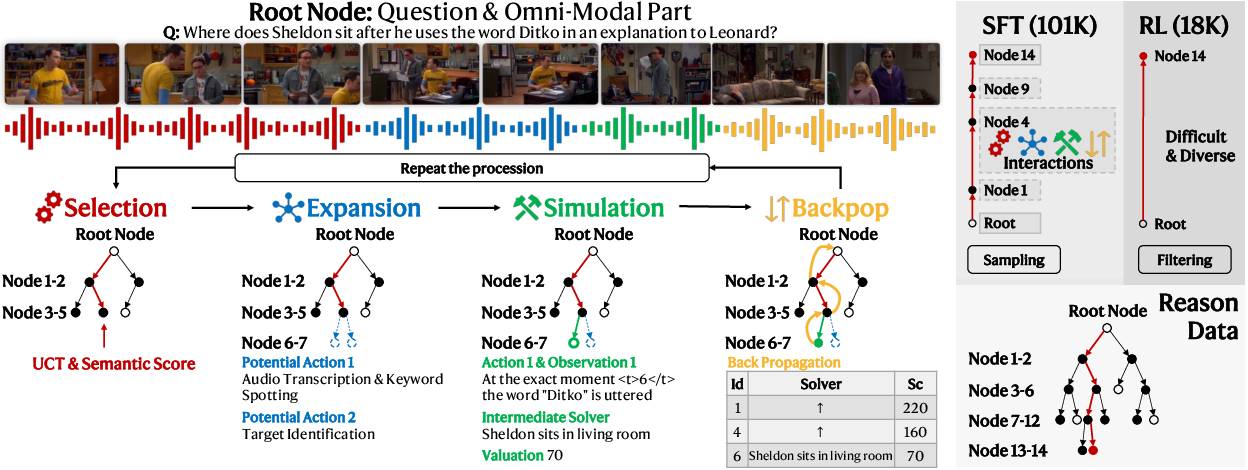
Figure 3: MCTS-driven reasoning trajectory curation yields high-quality, diverse audio-visual data essential for SFT and RL training.
Comprehensive data statistics show deep conversational turn lengths, rich multimodal sources (Audio, Video, Image, their combinations), and demanding long-context requirements up to 20K tokens, ensuring robust training for system-2 multimodal reasoning.
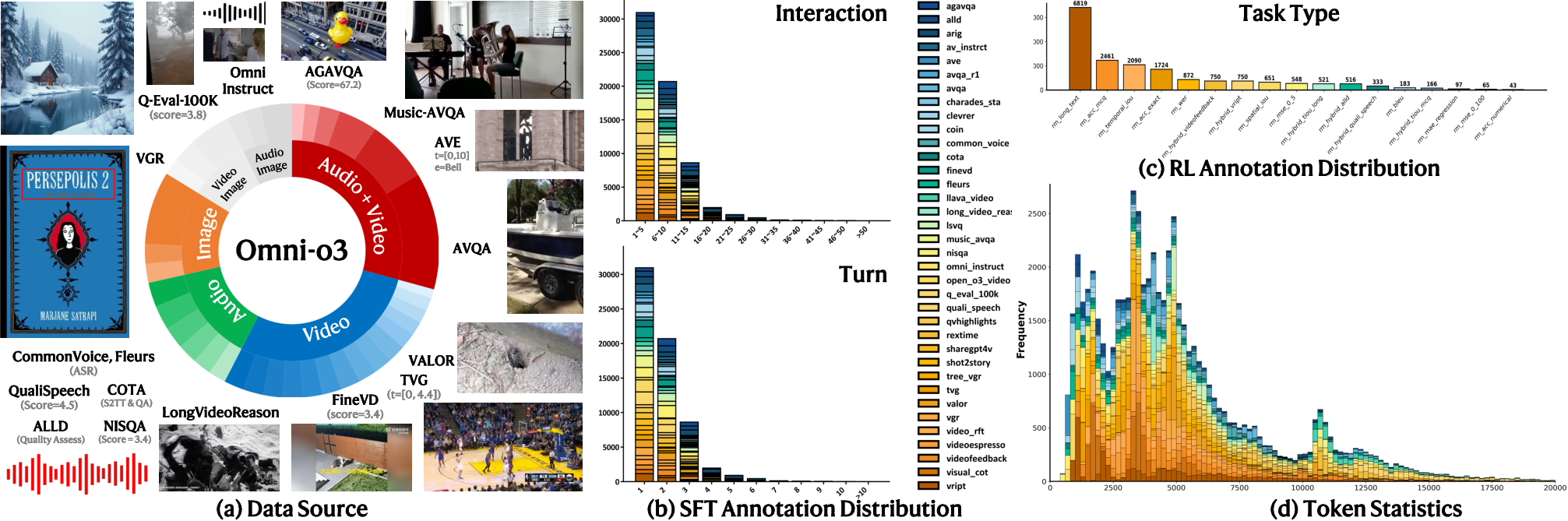
Figure 4: Omni-o3 training data encompass diverse sources, deep annotation structures, and long-context token statistics.
Omni-o3 exhibits substantial gains across 11 benchmarks in video, audio, and audio-visual modalities:
- Audio-Visual reasoning: On Video-MME (75.7) and AVE (85.1), Omni-o3 outperforms Qwen3-Omni (+5.2/+4.3). On complex reasoning benchmarks (Video-Holmes, WorldSense, IntentBench), it consistently surpasses open-source and even closed-source APIs (e.g., 54.0 on Video-Holmes vs. GPT-4o's 42.0; 67.6 on IntentBench vs. GPT-4o's 60.0).
- Video reasoning and grounding: Omni-o3 achieves robust spatial-temporal comprehension (Vript-RR = 75.0, FineVD Most = 53.2), substantially outpacing omnimodal baselines.
- Audio reasoning: In QualiSpeech (0.492), NISQA (0.82), MMSU (70.4), Omni-o3 delivers strong performance, surpassing specialized models and matching or exceeding closed-source systems on reasoning scores.
These results validate the nested deduction paradigm’s ability to bridge the gap between raw perception and high-level cognitive reasoning, achieving state-of-the-art performance in competitive benchmarks.
Qualitative Visualization: Deliberative Reasoning Trajectories
Visualizations demonstrate Omni-o3’s capability for both foundational and advanced reasoning. In single-turn spatial grounding, the model aligns auditory cues with visual entities and outputs precise coordinates. In complex multi-turn temporal grounding, it dynamically constructs a reasoning tree, iteratively self-corrects based on internal valuations, and refines its deductions until the correct event is localized.

Figure 5: Visualization—Omni-o3 showcases accurate spatial grounding in single-turn reasoning and robust self-correction in multi-turn video tasks.
Practical and Theoretical Implications
Omni-o3 establishes a paradigm shift for MLLMs in omnimodal contexts, marrying fine-grained perception and system-2 deduction with interpretable, structured reasoning. Practically, the model offers substantial improvements for embodied agents, audio-visual QA systems, and autonomous cognitive exploration in rich multimodal environments. Theoretically, tree-based reasoning and multi-step reward modeling foreground new approaches for long-context exploration, modality interference mitigation, and traceable agent policy learning.
Limitations include susceptibility to hallucinations in noisy contexts and incomplete support for real-time interaction. The framework provides a robust foundation for future extensions toward dynamic, embodied, and real-time omnimodal agents.
Conclusion
Omni-o3 integrates deep nested deduction and advanced data curation, yielding state-of-the-art performance across audio-visual, visual, and audio benchmarks. Its recursive, tree-based reasoning fundamentally augments omnimodal cognition, mitigates inefficiencies, and enables interpretable, multi-turn deduction. This paradigm supports further development of robust, high-capacity omnimodal LLMs and agentic reasoning frameworks (2604.24191).