- The paper demonstrates that a high-quality, causally consistent SFT pipeline enables interleaved visual reasoning and retrieval without reinforcement learning.
- The model attains SOTA performance on benchmarks like MMSearch and FVQA and shows up to 15× speed improvements over RL-based systems.
- Its integration of code-driven image manipulation, dynamic search, and agentic planning sets a new baseline for efficient and transparent multimodal reasoning.
Toward Unified Agentic Multimodal Intelligence: An Expert Analysis of Skywork-R1V4
Motivation and Novel Contributions
Skywork-R1V4 (2512.02395) addresses fundamental deficiencies in contemporary multimodal agentic systems by introducing a model that achieves dynamic, interleaved reasoning across visual manipulation, search, and multimodal planning without any reinforcement learning, utilizing only high-fidelity supervised trajectories. Unlike preceding frameworks, which often silo image manipulation and search as independent modules or depend heavily on unstable and resource-intensive RL protocols, Skywork-R1V4 tightly integrates executable visual operations, fact-grounded multi-step retrieval, and explicit agentic planning within a unified, data-efficient supervised learning pipeline.
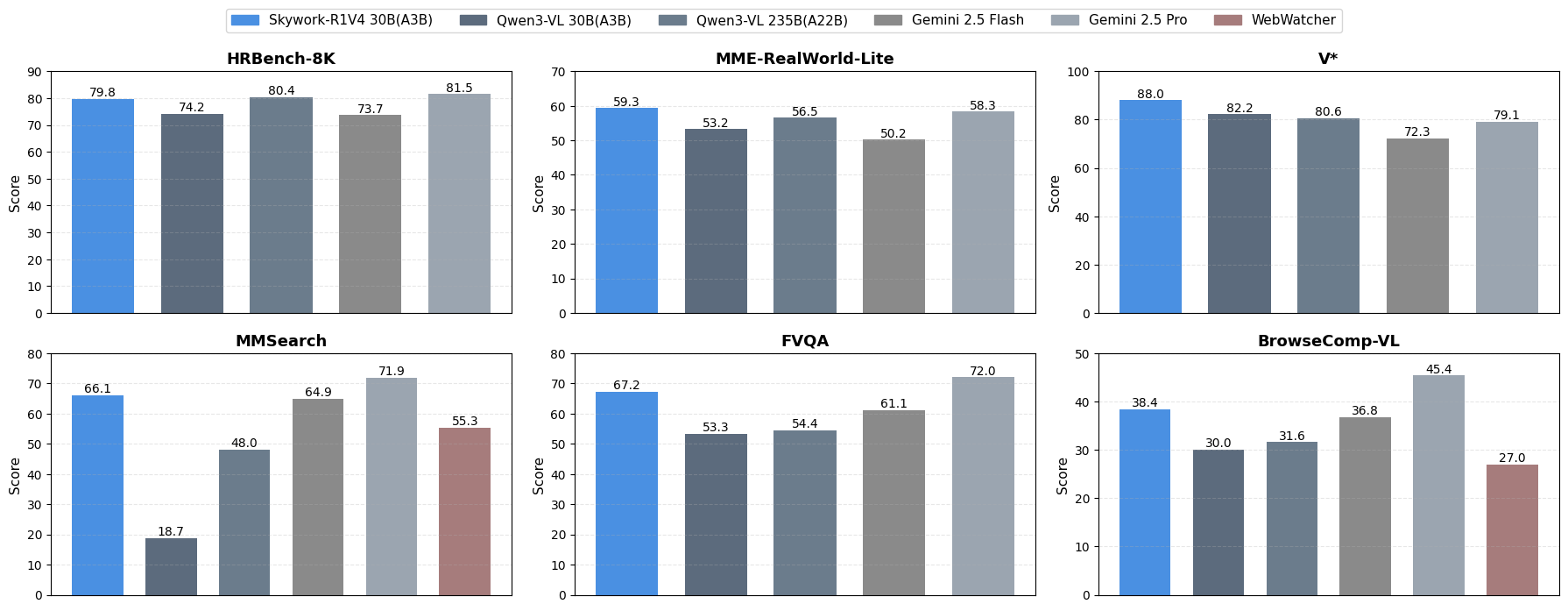
Figure 1: Skywork-R1V4 30B (A3B) demonstrates exceptional proficiency in code-based image manipulation, text and image search, and web browsing, achieving performance on high-resolution perception benchmarks that rivals or surpasses larger-scale and specialized models, while also showing advantages in multimodal Deepsearch tasks.
Data Curation and Processing Methodology
The model’s emergent generalization capabilities are rooted in a multi-stage data pipeline that yields high-quality, planning-consistent SFT samples with explicit validation at each reasoning and execution step. For "thinking with images," the data comprises multi-turn trajectories prompting the model to propose Python-based visual operations (e.g., cropping, zooming, contrast normalization), with sandboxed code execution and step-wise output consistency checks. Deep multimodal search trajectories are derived from knowledge-walks and open datasets, further distilled via strict answer-location filtering (using external judge models), with all searches executed through image/text/webpage search APIs. Importantly, interleaved datasets combine both visual manipulation and retrieval within a single episode, filtering for fine-grained action-perception alignment via external vision-language validation.
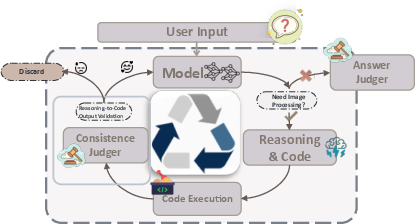

Figure 2: Overview of the data processing pipeline facilitating joint reasoning, tool usage, and rigorous consistency checks at each step.
This dataset, consisting of fewer than 30K curated SFT samples, explicitly excludes low-informational-value samples (e.g., error-fixing chains, failed recroppings), prioritizing logical causal dependencies and high behavioral fidelity.
Model Architecture and Training Regimen
Skywork-R1V4 is instantiated as a 30B (A3B) parameter multimodal LLM, architecturally similar to recent MLLMs but distinguished by its action-oriented, agentic training protocol. The model is stratified into multiple dialogue modes—General, DeepResearch, and Plan—each engaging tool APIs for code execution, visual transformation, textual retrieval, image-based search, and structured web content extraction. Unified plan-oriented prompts encode tool dependencies and output format constraints, resulting in stepwise, interpretable, actionable agent plans.
Mix-mode SFT incorporates attribute recognition, spatial reasoning, VQA, and both code and search-augmented reasoning, yielding mutual transfer: planning enhances search performance, and detailed perception data improves both attribute and relation recognition under tool-oriented reasoning.
Benchmarks and Strong Numerical Results
Skywork-R1V4 attains SOTA or near-SOTA results across both perception and deep research benchmarks:
- MMSearch: 66.1 (vs. 18.7 Qwen3-VL; +47.4), outperforming Qwen3-VL-235B and Gemini 2.5 Flash.
- FVQA: 67.2 (vs. 53.3 Qwen3-VL; +13.9), again exceeding larger models.
- Perception: HRBench-4K FSP 91.8 (+3.3), V* Attribute 90.4 (+8.7), MME-Real-CN Reasoning 59.4 (+14.4).
- Skywork-R1V4 exceeds Gemini 2.5 Flash on all 11 reported metrics and Gemini 2.5 Pro on 5/11, despite a much smaller parameter budget.
These results not only surpass all previous Skywork iterations but empirically challenge the necessity of scale or RL for robust agentic performance in high-resolution, heterogeneous multimodal settings.
Inference Efficiency and Practicalities
Inference throughput is a critical axis for agentic deployment. Skywork-R1V4 achieves ∼4–15× the single-turn inference speed of Gemini-2.5-Pro/Flash on MMSearch and FVQA, and approximately doubles tokens/sec in multi-turn, tool-augmented settings, even after accounting for external API latency.
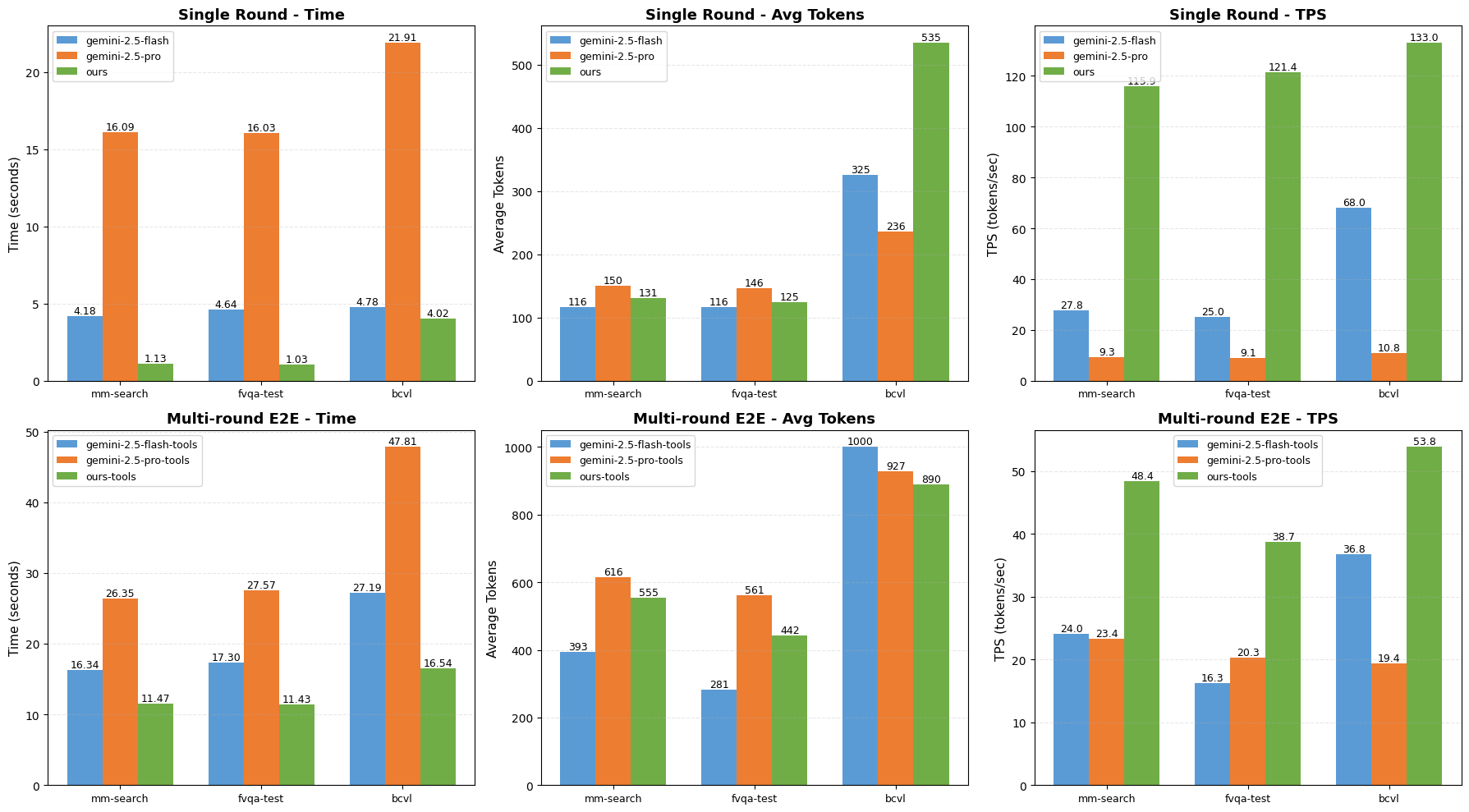
Figure 3: Relative inference efficiency of Skywork-R1V4 versus Gemini-2.5 models under different benchmarking conditions.
Skywork-R1V4 is capable of adaptive, goal-driven plans that decompose tasks into actionable visual and search steps anchored by explicit tool calls.

Figure 4: Example of model-generated plan in Plan Mode, sequencing visual grounding with search and verification.
In fine-grained visual exploration, Skywork-R1V4 dynamically zooms and crops image regions across multiple steps to localize small, contextually relevant objects, including sub-figure navigation and region-specific search.

Figure 5: Iterative image manipulation and dynamic region focus for target localization in complex urban scenes.
Moreover, the model flexibly interleaves image and text search to resolve ambiguous geographic queries, demonstrating robust cross-modal context fusion.

Figure 6: Integrated image and text search yielding high-accuracy geolocation under ambiguous visual descriptors.
Skywork-R1V4 further demonstrates the ability to alternate between image operations and retrieval, integrating subimage analysis and web search to collect and reason over multimodal evidence.

Figure 7: Interleaved manipulation and retrieval for precise, grounded answers to composite queries.
Theoretical and Practical Implications
The primary claim put forward—that high-quality, causally consistent SFT is sufficient for strong agentic multimodal reasoning across perception, search, and planning domains, obviating RL—directly challenges the prevailing assumption that RLHF or similar protocols are necessary for robust tool utilization and perception-search integration in multimodal LMs. The success of a relatively lightweight, SFT-only training regime (under 30K trajectories) demonstrates that dataset consistency, action-perception alignment, and execution-trace grounding are more decisive than scale per se. This has significant implications for both the cost and sustainability of deploying performant agentic MLLMs in production workloads.
Additionally, the integration of visual manipulation with active tool selection and trajectory-level planning advances the state of interpretable, verifiable agent design in complex, open-world scenarios.
Future Directions
The Skywork-R1V4 paradigm opens several promising avenues for further research:
- Enhanced tool integration (segmentation, depth, structured web/DOM navigation) to mediate more complex tasks and environments.
- Memory and predictive planning modules for persistent, long-horizon task coherence.
- Hybrid supervision protocols combining SFT for stability with light RL or active learning for specific edge adaptivity.
- Systematic study of minimal data curation strategies for domain transfer and sample-efficient generalization in agentic multimodal models.
Conclusion
Skywork-R1V4 provides compelling evidence that properly curated, plan- and execution-grounded SFT data can unlock advanced agentic multimodal reasoning, perception, and retrieval without reliance on expensive reinforcement learning or scale. Its architectural and data-centric advances yield practical gains in accuracy, speed, and transparency, and establish a new baseline for efficient, actionable agentic systems in open-ended multimodal environments. The approach challenges entrenched RL-centric paradigms and re-centers the role of structured, high-integrity data in next-generation multimodal intelligence research.

