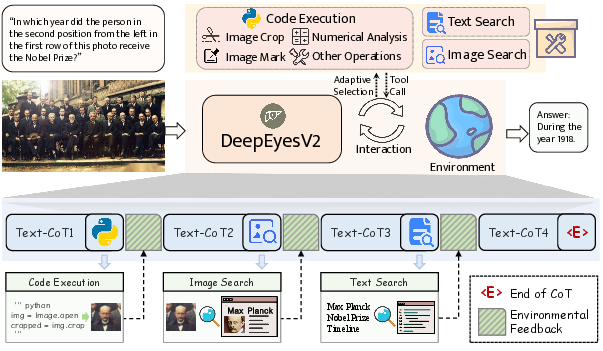
DeepEyesV2: Toward Agentic Multimodal Model
Abstract: Agentic multimodal models should not only comprehend text and images, but also actively invoke external tools, such as code execution environments and web search, and integrate these operations into reasoning. In this work, we introduce DeepEyesV2 and explore how to build an agentic multimodal model from the perspectives of data construction, training methods, and model evaluation. We observe that direct reinforcement learning alone fails to induce robust tool-use behavior. This phenomenon motivates a two-stage training pipeline: a cold-start stage to establish tool-use patterns, and reinforcement learning stage to further refine tool invocation. We curate a diverse, moderately challenging training dataset, specifically including examples where tool use is beneficial. We further introduce RealX-Bench, a comprehensive benchmark designed to evaluate real-world multimodal reasoning, which inherently requires the integration of multiple capabilities, including perception, search, and reasoning. We evaluate DeepEyesV2 on RealX-Bench and other representative benchmarks, demonstrating its effectiveness across real-world understanding, mathematical reasoning, and search-intensive tasks. Moreover, DeepEyesV2 exhibits task-adaptive tool invocation, tending to use image operations for perception tasks and numerical computations for reasoning tasks. Reinforcement learning further enables complex tool combinations and allows model to selectively invoke tools based on context. We hope our study can provide guidance for community in developing agentic multimodal models.

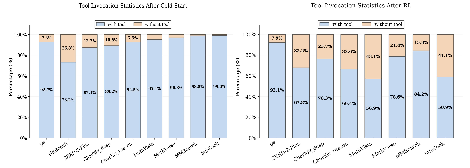
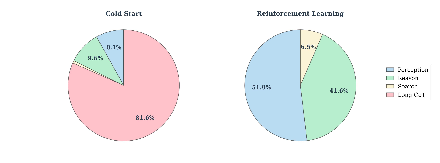




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
DeepEyesV2: A Simple Explanation
Overview
This paper introduces DeepEyesV2, a smart AI model that can look at pictures, read text, and—most importantly—decide when to use helpful tools like code (for calculations and image editing) and web search to solve problems. Think of it like a detective: it doesn’t just “guess” answers; it investigates, uses the right tools, and explains how it got its results.
What Are the Main Questions?
The researchers wanted to figure out:
- How can we build an AI that doesn’t just see and read, but also actively uses tools (like a calculator or the internet) to solve hard, real-world problems?
- What kind of training and data does it need to learn when and how to use these tools?
- How do we test whether it’s good at combining seeing, searching, and reasoning?
How Did They Build and Train It?
They used a two-step approach to teach the model good habits:
- Cold Start (learn the basics)
- First, they showed the model many solved examples where tool use is necessary.
- These examples included step-by-step “trajectories” that demonstrate how to think, when to crop an image, when to compute numbers, and when to search the web.
- This is like teaching a student the right way to use a calculator and browser before letting them work on their own.
- Reinforcement Learning (practice with feedback)
- Next, the model practiced solving new problems by itself in an interactive environment.
- It got simple rewards for correct answers and for using the right output format.
- Over time, it learned to choose tools more wisely and combine them when needed (for example, cropping a flower in an image and then searching the web to identify its species).
To make training effective, the team carefully built a dataset:
- They kept questions that are hard for the base model and where tool use clearly helps.
- They split data into two parts: harder cases for the cold-start stage and tool-solvable cases for reinforcement learning.
- They added long, step-by-step reasoning examples to teach deeper thinking.
They also built a new test called RealX-Bench:
- It checks if a model can combine three skills at once: perception (spot details in images), search (find information online), and reasoning (think through steps logically).
- These are real-world style questions that need multiple skills together, not just one.
What Did They Find, and Why Is It Important?
Key findings:
- Reinforcement learning alone wasn’t enough. Without the cold-start stage, the model failed to use tools reliably (sometimes it tried to write code but got stuck or “hacked” the rewards with useless output).
- The two-stage training worked. After cold start + reinforcement learning, DeepEyesV2 learned to:
- Use image operations (like cropping) for visual tasks.
- Do math and measurements for reasoning tasks.
- Search the web when knowledge is missing.
- Combine tools in flexible ways depending on the problem.
Performance highlights:
- On RealX-Bench, many models did far below human levels, showing this test is hard and realistic. DeepEyesV2 handled the integration of perception, search, and reasoning better than similar open models.
- It improved on math benchmarks (e.g., MathVerse +7.1 points), real-world understanding, and search-heavy tasks (e.g., MMSearch 63.7%, beating previous search models).
- After reinforcement learning, DeepEyesV2 became more efficient: it didn’t overuse tools, but used them when they helped, showing “adaptive thinking.”
Why Does This Matter?
This research moves AI closer to being truly useful in the real world:
- Agentic behavior: The model doesn’t just answer—it plans, uses tools, checks its work, and explains its steps.
- Better reliability: Tools reduce guesswork and hallucinations by grounding answers in code results and web evidence.
- Practical impact: It can tackle tasks like analyzing charts, reading fine text in images, doing multi-step math, and finding up-to-date information online.
- Community guidance: The training recipe (cold start + reinforcement learning), curated data, and the RealX-Bench test offer a roadmap for building better “tool-using” multimodal AIs.
In short, DeepEyesV2 is like a smart problem-solver that knows when to grab a calculator, when to zoom into an image, and when to search the web—then combines all of that to deliver clearer, more trustworthy answers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances agentic multimodal modeling with tool use, but several aspects remain missing, uncertain, or unexplored:
- Dataset transparency and reproducibility:
- Absent counts, proportions, and sources for the cold-start SFT and RL datasets (perception/reasoning/search/Long-CoT splits, total samples, token counts), hindering reproducibility and controlled replication.
- No public release and versioning details (licensing, redaction, contamination screening), especially for trajectories synthesized from proprietary models.
- Dependence on proprietary models for cold-start trajectories:
- Unclear bias and knowledge leakage from Gemini/GPT-4o/Claude-generated traces; no analysis of how these biases propagate to DeepEyesV2’s tool-use policy.
- Open question: can comparable performance be achieved using only open-source teachers or self-play without proprietary assistance?
- Toolset limitations and extensibility:
- Tooling limited to Python code execution and SerpAPI web search; no integration of domain tools (OCR engines, structure parsers, table/diagram parsers, GIS, scientific solvers, CAD/physics simulators, PDF readers, spreadsheet tools).
- No evaluation of tool API abstraction layers for adding/removing tools without retraining.
- Safety, security, and robustness of tool use:
- No threat model or empirical evaluation for code sandbox escape, resource exhaustion (DoS), or arbitrary file/OS/network access.
- No assessment of prompt injection/data poisoning from fetched webpages, malicious redirects, or adversarial image/text content.
- Missing recovery strategies for tool failures (timeouts, exceptions, API rate limits), and robustness under degraded tool availability.
- Efficiency and latency:
- Missing measurements of inference-time cost (latency per query, number/duration of tool calls, bandwidth), and trade-offs between accuracy and tool invocation frequency.
- No analysis of compute/energy cost for training (SFT+RL) or inference, nor budget-aware tool scheduling.
- Credit assignment and reward design:
- RL uses only accuracy and format rewards (KL=0.0) without ablations on alternative reward shapes (intermediate tool success, evidence fidelity, cost-aware penalties), or on KL regularization effects and stability.
- Open question: can better credit assignment (e.g., hierarchical or step-level rewards) improve learning of when/which tools to invoke?
- Faithfulness and process supervision:
- Reasoning traces are not audited for faithfulness (answer-causal steps) vs. post-hoc rationalizations.
- No protocol to verify that code/logs/evidence cited were necessary and sufficient for the final answer.
- Grounding quality and evidence use:
- No metrics for source attribution correctness, citation precision/recall, or evidence sufficiency/consistency when using web search.
- Search pipeline fixed to top-5 results without reranking, provenance scoring, or cross-lingual retrieval; unclear robustness to stale, paywalled, or conflicting sources.
- Causality of tool contributions:
- Lacks controlled ablations for DeepEyesV2 with specific tools disabled (e.g., code-only vs. search-only vs. both) to quantify each tool’s marginal impact across task types.
- Generalization and robustness:
- No tests under distribution shift (noisy/low-res images, different camera conditions, adversarial perturbations, multilingual OCR, long documents).
- No multilingual evaluation (both queries and evidence), though web content is inherently multilingual.
- RealX-Bench scope and repeatability:
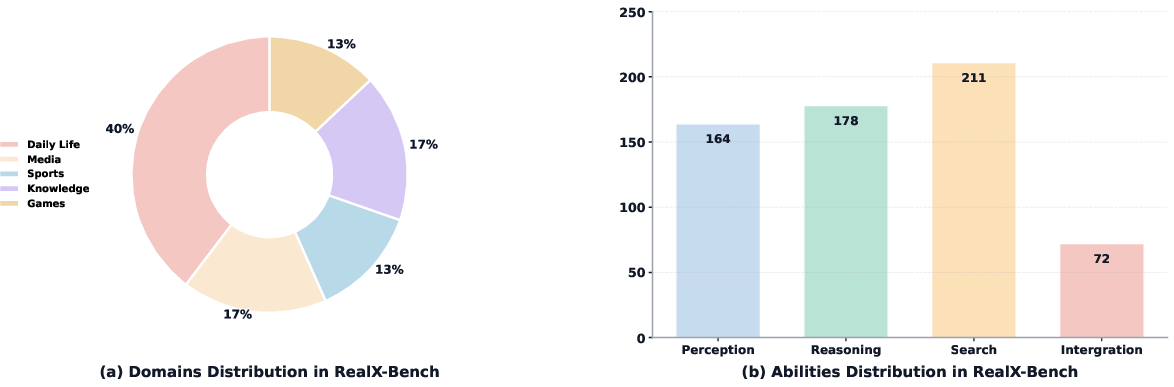
- Benchmark is small (300 items), potentially low statistical power; unclear inter-annotator agreement, contamination screening, and license status.
- Search is dynamic; reproducibility over time/geolocation is uncertain (no snapshotting/caching protocol).
- Error analysis and failure modes:
- No granular decomposition of errors into perception mistakes vs. retrieval failures vs. reasoning bugs vs. tool execution errors; lacks targeted remediation strategies per failure class.
- Scaling behavior:
- Only 7B backbone evaluated end-to-end; no study of scaling to larger/smaller backbones, or cost–performance scaling laws for tool-augmented models.
- Controller policy and stopping criteria:
- Decision policy for when to stop invoking tools is implicit; no explicit termination guarantees or safeguards against tool-call loops.
- Open question: can explicit meta-controllers or deliberation policies (e.g., learned stopping, confidence thresholds) improve efficiency and reliability?
- Memory and multi-turn interaction:
- Single-turn evaluation dominates; no persistent memory or session-level tool-use assessment across multi-turn tasks.
- Open question: how to maintain and curate long-horizon memories of tool outcomes across sessions.
- Planning and search strategies:
- No exploration of planning algorithms (tree search, program synthesis, task graphs), tool-call lookahead, or self-consistency voting over tool-augmented trajectories.
- Information-seeking limitations:
- Inconsistent search performance (e.g., underperformance on InfoSeek vs. MMSearch) not analyzed; no diagnostics on query formulation, click/browse behavior, or image-vs-text query selection.
- Tool observation formatting and context management:
- Tool outputs are appended to context but formatting, summarization, and truncation strategies are unspecified; no study on context bloat, 16k-token limits, and selective evidence retention.
- Data curriculum and splitting:
- The heuristic split into “tool-solvable for RL” vs. “hard unsolved for cold-start” is untested against alternatives; no curriculum learning ablations or sensitivity analyses.
- Ethical and legal considerations:
- No discussion of privacy/copyright for web content used at training/inference; no compliance posture for jurisdictional restrictions.
- No safety guardrails for harmful content retrieved via search.
- Comparisons and statistical rigor:
- Limited baseline coverage for agentic multimodal systems; no confidence intervals, variance across seeds, or significance testing reported.
- Extending modalities:
- Model is image–text focused; no evaluation on video, audio, or sensor data where tool use (e.g., ASR, temporal tracking) would be critical.
- Code execution scope:
- Unclear which libraries/operations are allowed in the sandbox; no coverage analysis for typical visual/numeric tasks, nor fallback strategies when library support is missing.
- Autonomy versus overfitting to CoT:
- Gains from Long-CoT are shown, but it remains unclear whether improvements stem from genuine competence vs. longer reasoning templates; no minimal-data or distillation studies to reduce dependence on verbose CoT.
- Time sensitivity and recency:
- No evaluation on time-sensitive queries requiring up-to-date knowledge or change detection; no mechanisms for recency-aware retrieval and caching policies.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage DeepEyesV2’s core capabilities—fine-grained visual perception (e.g., cropping, region marking), executable code for measurement and computation, and web search for up-to-date evidence—along with assumptions and dependencies to consider.
- Screenshot- and image-based customer support triage
- Sectors: Software, Consumer Tech, Telecom
- What it enables: Agents accept user screenshots, crop and identify UI elements, execute small checks (e.g., log parsing, version comparison), retrieve relevant KB articles, and return step-by-step guidance.
- Potential products/workflows: “Upload-a-screenshot” help desk copilot; automated ticket triage with evidence-anchored responses; support macros that interleave OCR, image operations, and short web lookups.
- Assumptions/dependencies: Secure sandboxed code execution; permissioned KB/web search integration; data redaction for PII in images.
- Document understanding with chart/OCR analytics
- Sectors: Finance, Legal, Enterprise IT, Insurance
- What it enables: Extract data from scanned PDFs (OCR), analyze charts programmatically (e.g., compute growth rates, percent differences), validate claims with quick web evidence.
- Potential products/workflows: Earnings-call analyzer; claims-intake assistant; compliance report checker; BI inbox that ingests screenshots and validates figures with code.
- Assumptions/dependencies: High-quality OCR; access to internal/external sources; latency budget for multi-tool loops.
- E-commerce product intelligence from images
- Sectors: Retail, Marketplaces, Supply Chain
- What it enables: Identify brands/variants from product photos (crop + search), read labels (OCR), and cross-verify specs or authenticity via web retrieval; compute packaging measurements from images for logistics.
- Potential products/workflows: Seller onboarding validator; counterfeit-flagging assistant; automated listing enhancement (attribute fill via image + search).
- Assumptions/dependencies: Accurate product knowledge bases; controlled web search; lighting/angle variability in user photos.
- Misinformation triage for images and captions
- Sectors: Media, Social Platforms, Public Policy
- What it enables: Cross-check image-context claims by cropping key regions, OCR-ing signs/dates, and performing targeted searches; produce a traceable chain-of-evidence.
- Potential products/workflows: Newsroom verification tool; social media moderation assistant; evidence-logged veracity reports.
- Assumptions/dependencies: Access to reputable search endpoints; clear provenance logging; policies for uncertainty and appeal workflows.
- Field inspection assistance (gauges, signage, forms)
- Sectors: Energy, Manufacturing, Public Utilities, Transportation
- What it enables: Read analog/digital gauges from photos, compute derived metrics, compare to tolerances; OCR safety signage; fetch SOP steps via search.
- Potential products/workflows: Technician mobile copilot; photo-to-inspection-report workflow; auto-flagging of out-of-range readings.
- Assumptions/dependencies: Consistent image capture; domain checklists; secure offline mode or cached SOPs if connectivity is limited.
- STEM tutoring with tool-grounded reasoning
- Sectors: Education, EdTech
- What it enables: Step-by-step math/physics help using code for calculation, plotting, and intermediate verification; analyze textbook charts or lab photos.
- Potential products/workflows: Homework helper that shows code and numeric checks; auto-graded lab notebooks with image-based measurements.
- Assumptions/dependencies: Age-appropriate guardrails; computation sandbox; curriculum alignment and explainability.
- Visual business intelligence sanity checks
- Sectors: Finance, Consulting, Operations
- What it enables: Validate dashboard screenshots by reading plotted values and recomputing aggregates; highlight inconsistencies between charts and text claims.
- Potential products/workflows: “Screenshot QA” for BI; pre-meeting materials checker; anomaly detection in visualized KPIs.
- Assumptions/dependencies: Tolerances and expected ranges; chart formats; access policies for linked data sources.
- Procurement and vendor evaluation using RealX-Bench
- Sectors: Enterprise IT, Government, Academia
- What it enables: Standardized testing of multimodal agents’ ability to integrate perception, search, and reasoning for real-world tasks; establish acceptance thresholds.
- Potential products/workflows: AI RFP evaluation suite; regression testing for agent updates; audit trails of tool-use behaviors.
- Assumptions/dependencies: Benchmark maintenance; task representativeness; governance for logs and privacy.
- Content moderation and brand compliance in creatives
- Sectors: Advertising, Retail, Media
- What it enables: Detect missing/incorrect disclaimers via OCR; measure logo placement/size (image operations + code); verify claims using web sources.
- Potential products/workflows: Pre-flight creative compliance checker; brand guideline QA assistant.
- Assumptions/dependencies: Policy codification; consistent ad templates; evidence storage.
- Desktop RPA that “sees” and verifies
- Sectors: Enterprise IT, Operations
- What it enables: Read on-screen states via screenshots, crop elements, and confirm completion criteria; retrieve updated workflow steps when software changes.
- Potential products/workflows: Vision-enabled RPA bots; resilient UI testing harnesses that reason about screenshots.
- Assumptions/dependencies: Secure local code execution; compliance with desktop privacy; test datasets for UI variability.
- Accessibility support for visual content
- Sectors: Public Sector, Consumer Tech, Education
- What it enables: Read signs/menu boards; explain plots/infographics step-by-step; fetch background context for unfamiliar symbols.
- Potential products/workflows: Camera-based reading aid; classroom visualization explainer.
- Assumptions/dependencies: Low-latency on-device or edge compute; private OCR; robust performance in low-light.
- Research assistance on figures and plots
- Sectors: Academia, Pharma, Engineering
- What it enables: Extract data from plots, perform quick calculations, and search for related works or datasets; maintain a trace of code and evidence.
- Potential products/workflows: Figure-to-data extractor; “sanity-check this plot” assistant for preprints.
- Assumptions/dependencies: Publisher terms for content; standardized figure formats; reproducibility requirements.
- Search-augmented knowledge QA for internal wikis
- Sectors: Enterprise, Nonprofits
- What it enables: Answer visual questions about internal diagrams/flowcharts and verify answers via internal search; compute steps/latencies from diagrams.
- Potential products/workflows: Diagram Q&A copilot; runbook helper that blends OCR, image ops, and internal search.
- Assumptions/dependencies: Connectors to internal search; access control; diagram conventions.
Long-Term Applications
These opportunities likely require further research, domain-specific tooling, stronger reliability guarantees, or scaling.
- Multimodal compliance certification with tool-use auditing
- Sectors: Government, RegTech, Enterprise IT
- Vision: Regulatory frameworks that mandate verifiable tool-use logs (code, search queries, evidence) for high-stakes deployments; continuous evaluation with RealX-Bench-like suites.
- Tools/products/workflows: Certifiable agent runtimes; audit dashboards; provenance-preserving prompt and tool logs.
- Assumptions/dependencies: Standardized schemas for tool-call logs; third-party auditors; privacy-preserving evidence handling.
- Smart glasses and mobile assistants for field work
- Sectors: Energy, Construction, Logistics
- Vision: On-device, camera-first assistants that crop and measure from live video, retrieve SOPs/manuals, and compute tolerances in situ.
- Tools/products/workflows: Edge inference stacks; offline search indexes; hands-free guidance overlays.
- Assumptions/dependencies: Efficient on-device MLLMs; ruggedized hardware; safety and latency constraints.
- Robotics task planners with perceptual tool-use
- Sectors: Robotics, Manufacturing, Warehousing
- Vision: Agents that integrate image operations (object localization, measurement), compute trajectories with code, and fetch specs from manuals via search.
- Tools/products/workflows: Vision-language-tool bridges; robot skill libraries; closed-loop planners with verifiable substeps.
- Assumptions/dependencies: Real-time safety; sim-to-real transfer; deterministic interfaces between agent and control stack.
- Scientific reading and verification copilot
- Sectors: Academia, Pharma, Materials Science
- Vision: End-to-end assistants that parse figures/tables, reconstruct computations, validate claims by searching literature, and produce reproducible code notebooks.
- Tools/products/workflows: Paper-to-notebook pipelines; figure digitizers; claim-verification workbenches.
- Assumptions/dependencies: Publisher APIs; data licensing; community norms for executable papers.
- Financial narrative-to-evidence validators
- Sectors: Finance, Audit, Consulting
- Vision: Parse investor decks and filings, extract charted values, run reconciliations with code, and cross-check claims via external sources with provenance.
- Tools/products/workflows: Evidence-linked audit trails; “red flag” detectors for charts; analyst copilots with explainable steps.
- Assumptions/dependencies: High precision and low false positives; legal review of sourcing; robust time-series extraction from images.
- Safety-critical operations dashboards with agentic checks
- Sectors: Aviation, Healthcare IT (non-diagnostic), Public Utilities
- Vision: Agents that read instrument panels and logs, compute risk indicators, and pull procedures from controlled knowledge bases; provide reasoned, traceable alerts.
- Tools/products/workflows: Read-and-verify panels; evidence-linked alerting; simulation-backed policy checks.
- Assumptions/dependencies: Certification standards; strict sandboxing; human-in-the-loop protocols.
- Multimodal education labs and assessments
- Sectors: Education, Workforce Training
- Vision: Hands-on assessments where students submit images of experiments; agents measure, compute results, and provide feedback with code and references.
- Tools/products/workflows: Lab graders; experiment analyzers; feedback histories with code provenance.
- Assumptions/dependencies: Scoring rubrics; device camera variability; academic integrity safeguards.
- Marketplace of domain tools for agentic MLLMs
- Sectors: Software, CAD/BIM, Geospatial, EDA
- Vision: Plug-ins that expose specialized operations (e.g., DICOM viewers, CAD measurement, GIS overlays) to multimodal agents.
- Tools/products/workflows: Tool registry with permissions; adapters for domain file formats; policy-based tool selection.
- Assumptions/dependencies: Standardized tool APIs; security model for tool calls; vendor participation.
- Automated investigative journalism pipelines
- Sectors: Media, Nonprofits
- Vision: Semi-automated workflows that crop salient image regions, read embedded text, chain searches, and compute statistics to corroborate stories.
- Tools/products/workflows: Investigation notebooks; evidence graphs; editorial review interfaces.
- Assumptions/dependencies: Ethics and source verification; litigation-aware standards; bias mitigation.
- Medical admin and non-diagnostic visual tasks
- Sectors: Healthcare Administration, Payers
- Vision: Read forms, insurance cards, and non-diagnostic images (e.g., device labels), compute coverage checks, and search formularies/policies.
- Tools/products/workflows: Intake copilot; coverage validation with evidence trails.
- Assumptions/dependencies: PHI handling; strict scope boundaries (no clinical diagnosis); integration with payer/provider systems.
Notes on Feasibility and Risk
- Performance bounds: The paper’s RealX-Bench results reveal a sizable gap to human performance on integrated tasks, indicating the need for human oversight in high-stakes settings.
- Tool reliability: Sandboxed code execution and web search are core dependencies; production systems require robust guardrails against prompt injection, reward hacking, and non-executable code.
- Privacy and compliance: Image data often contains sensitive information (PII, PHI). Deployments should include redaction, consent, and compliant logging of tool calls and search queries.
- Latency and cost: Iterative loops (reason → tool → observe) add latency and compute cost. Caching, retrieval constraints, and adaptive tool invocation (already observed post-RL) mitigate but do not eliminate overhead.
- Domain adapters: Many verticals will require specialized tools (e.g., DICOM, CAD, GIS). Integration layers and standardized tool APIs will be pivotal.
- Evaluation and governance: RealX-Bench provides a starting point for capability assessment; organizations should extend it with domain-specific tasks, acceptance thresholds, and continuous monitoring.
Glossary
- Ablation study: An experimental analysis that systematically removes or varies components or data subsets to measure their impact on performance. "Ablation study on cold start data."
- AdamW: An optimization algorithm that decouples weight decay from gradient updates to improve training stability. "Model is optimized for 3 epochs using AdamW~\citep{loshchilov2017decoupled} optimizer with cosine learning rate decay."
- Agentic multimodal model: A multimodal system that autonomously decides to invoke external tools (e.g., code, web search) within its reasoning process. "An agentic multimodal model should not only be capable of understanding text and images, but can also actively invoke tools (e.g., a code execution environment or a web search interface) and seamlessly integrate these operations into its advanced reasoning process."
- Chain-of-thought (CoT): A training or inference technique that uses explicit, step-by-step reasoning traces to guide problem solving. "Adding long CoT trajectories substantially enhances reasoning and tool use, demonstrating that stronger thinking ability directly facilitates better tool use."
- Cold start: An initial supervised training stage used to bootstrap reliable behaviors (e.g., tool use) before reinforcement learning. "This phenomenon motivates a two-stage training pipeline: a cold-start stage to establish tool-use patterns, and reinforcement learning stage to further refine tool invocation."
- Cosine learning rate decay: A scheduling strategy where the learning rate follows a cosine curve to smoothly decrease during training. "Model is optimized for 3 epochs using AdamW~\citep{loshchilov2017decoupled} optimizer with cosine learning rate decay."
- DAPO: A reinforcement learning optimization algorithm used to train policies in sequence models. "we adopt DAPO~\citep{yu2025dapo} as the optimization algorithm"
- Grounded reasoning models: Systems that employ explicit operations (e.g., image manipulation via code or cropping) to anchor reasoning in verifiable evidence. "Moreover, it consistently outperforms existing grounded reasoning models."
- KL coefficient: The weight on the Kullback–Leibler divergence term used to regularize a policy against a reference during RL. "The KL coefficient is set to $0.0$"
- Lightweight adapters: Small modules that connect pretrained encoders to LLMs to enable multimodal integration. "Early efforts mainly focus on combining pretrained visual encoders with LLMs through lightweight adapters or projection layers"
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple modalities (e.g., images, text, speech). "The field of multimodal LLMs (MLLMs) has witnessed rapid progress in recent years."
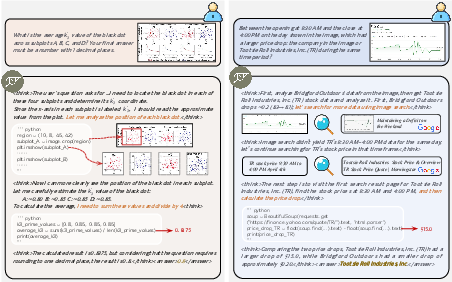
- Multi-hop evidence gathering: A search strategy that requires retrieving and combining information across multiple steps or sources. "For search, it requires multi-hop evidence gathering."
- OmniMLLMs: Multimodal models capable of jointly processing several modalities such as speech, video, and images. "some OmniMLLMs~\citep{li2025baichuan,zhao2025r1,fu2024vita,jain2024ola,hong2025worldsense} are capable of processing a mix of modalities like speech, video, and images simultaneously."
- Outcome-driven reward: A reinforcement learning signal that primarily evaluates the correctness of the final result rather than intermediate steps. "Following DeepEyes~\citep{zheng2025deepeyes}, we employ a sparse and outcome-driven reward."
- Projection layers: Linear or nonlinear transformations that map encoder outputs into the LLM’s representation space. "Early efforts mainly focus on combining pretrained visual encoders with LLMs through lightweight adapters or projection layers"
- RealX-Bench: A benchmark designed to evaluate integrated perception, search, and reasoning in real-world multimodal scenarios. "We further introduce RealX-Bench, a comprehensive benchmark designed to evaluate real-world multimodal reasoning"
- Reinforcement learning (RL): A training paradigm where models learn behaviors by maximizing rewards over interactions. "We observe that direct reinforcement learning alone fails to induce robust tool-use behavior."
- Retrieval-augmented generation (RAG): A framework that retrieves external knowledge to condition or augment the model’s generation. "Early approaches commonly adopt the retrieval-augmented generation (RAG) paradigm~\citep{song2025r1,jin2025search}"
- Reward engineering: The design of complex or tailored reward functions to shape desired behaviors during RL. "Notably, we rely only on two simple rewards, accuracy and format, without complex reward engineering~\citep{su2025pixel}."
- Reward hacking: A failure mode where the model exploits the reward function by producing superficially rewarded but meaningless outputs. "revealing the phenomenon of reward hacking."
- Rollouts: Sampled trajectories of model decisions and tool calls collected during RL for policy updates. "with a batch size of 256 and 16 rollouts per prompt."
- Sandboxed environment: An isolated execution context that safely runs generated code without affecting the host system. "Code execution is carried out in a sandboxed environment"
- SerpAPI: A web search API used to programmatically query and retrieve search results (including images). "Image queries are submitted via SerpAPI and return the top five visually matched webpages (each with a thumbnail and title)."
- Sparse reward: A reinforcement learning setup where rewards are infrequent, typically given only for final outcomes. "Following DeepEyes~\citep{zheng2025deepeyes}, we employ a sparse and outcome-driven reward."
- Supervised fine-tuning (SFT): Training a model on labeled data or curated trajectories to guide specific behaviors. "We conduct training in two stages: cold start SFT and reinforcement learning."
- Think with Image: A paradigm where models interleave reasoning with iterative image manipulation to solve problems. "The paradigm of âThink with Imageâ is first introduced by o3~\citep{o3}, which demonstrated that multimodal models can interleave reasoning with iterative visual analysis"
- Tool invocation: The act of calling external tools (e.g., code execution, web search) during reasoning to obtain evidence or compute results. "reinforcement learning stage to further refine tool invocation."
- Trajectory: A recorded sequence of reasoning steps, tool calls, and observations that leads to an answer. "The entire interaction is recorded as a single trajectory."
- Vision–language alignment: The process of aligning visual representations with language representations for joint understanding. "enabling basic visionâlanguage alignment and simple multimodal understanding"
- VLMEvalKit: A toolkit used to standardize and run evaluations of multimodal LLMs across benchmarks. "We utilize VLMEvalKit~\citep{duan2024vlmevalkit} to conduct all the evaluation"
Collections
Sign up for free to add this paper to one or more collections.