Repurposing Synthetic Data for Fine-grained Search Agent Supervision
Abstract: LLM-based search agents are increasingly trained on entity-centric synthetic data to solve complex, knowledge-intensive tasks. However, prevailing training methods like Group Relative Policy Optimization (GRPO) discard this rich entity information, relying instead on sparse, outcome-based rewards. This critical limitation renders them unable to distinguish informative "near-miss" samples-those with substantially correct reasoning but a flawed final answer-from complete failures, thus discarding valuable learning signals. We address this by leveraging the very entities discarded during training. Our empirical analysis reveals a strong positive correlation between the number of ground-truth entities identified during an agent's reasoning process and final answer accuracy. Building on this insight, we introduce Entity-aware Group Relative Policy Optimization (E-GRPO), a novel framework that formulates a dense entity-aware reward function. E-GRPO assigns partial rewards to incorrect samples proportional to their entity match rate, enabling the model to effectively learn from these "near-misses". Experiments on diverse question-answering (QA) and deep research benchmarks show that E-GRPO consistently and significantly outperforms the GRPO baseline. Furthermore, our analysis reveals that E-GRPO not only achieves superior accuracy but also induces more efficient reasoning policies that require fewer tool calls, demonstrating a more effective and sample-efficient approach to aligning search agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching “search agents” (AI programs that read the web and answer complex questions) to learn better from their mistakes. Instead of only rewarding them when they get the final answer right, the authors give partial credit when the agent finds the right pieces of information (called “entities”) along the way. This helps the agent improve faster and make smarter decisions.
The main goal in simple terms
The authors wanted to solve a common training problem: when an AI nearly gets a question right but makes a small mistake at the end, it usually gets the same zero points as a totally wrong answer. That wastes useful learning signals.
So they asked:
- Can we use the “key facts” baked into synthetic training data (like names, dates, places) to give partial credit to “near-miss” answers?
- Will this “entity-aware” partial credit make agents more accurate and more efficient?
How they approached it (explained simply)
What is a search agent?
Think of a search agent like a careful student-detective:
- It reads the question and thinks about what to do.
- It searches the web, visits pages, and gathers clues.
- It tries to combine those clues into a final answer.
This thinking-and-acting loop repeats until the agent gives its answer.
What is synthetic data and “entities”?
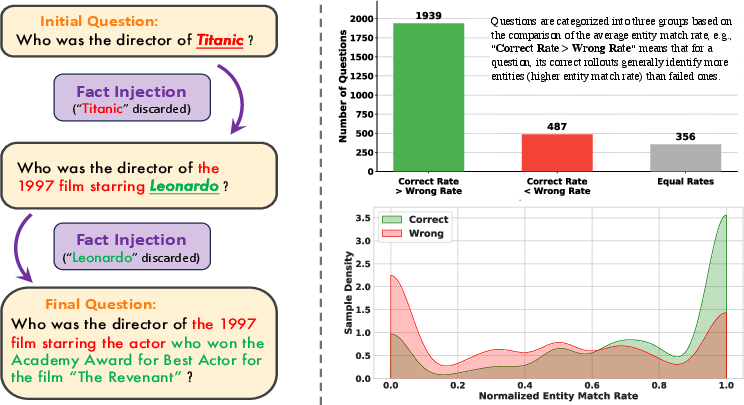
Synthetic data means the training questions are created by an automated process. To make questions harder, the process mixes in or hides important facts—like names, titles, years, locations—called “entities.” These entities are the backbone of the correct answer.
Example:
- Question: “Who directed the 1997 film starring the actor who won Best Actor for ‘The Revenant’?”
- Entities: “Leonardo DiCaprio,” “Titanic,” “James Cameron,” “1997,” “The Revenant.”
Even if the agent’s final answer is wrong, it might still correctly find many of these entities while thinking, which is useful progress.
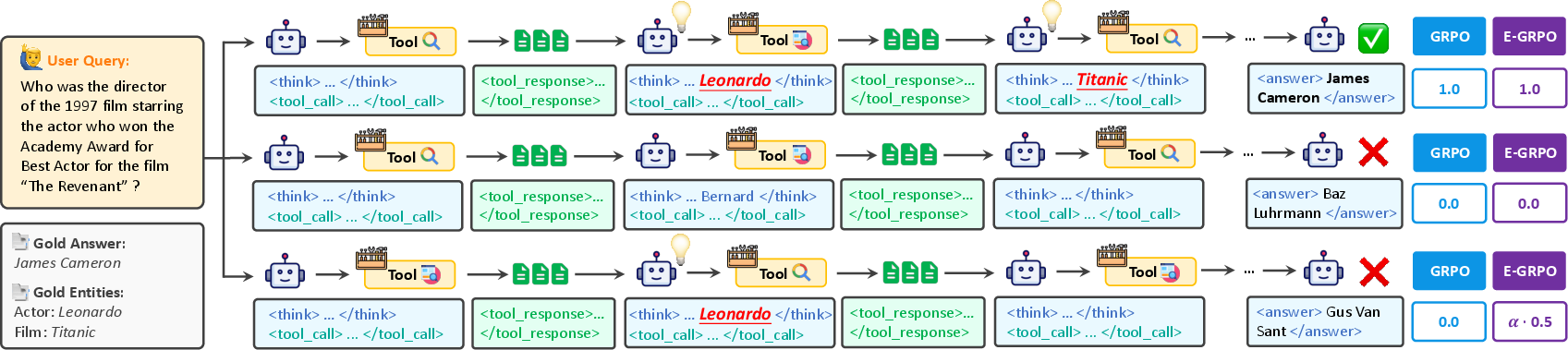
What’s wrong with the usual training method (GRPO)?
GRPO is a common way to train agents using rewards:
- If the final answer is correct, reward = 1.
- If the final answer is wrong, reward = 0.
This is called a “sparse reward” because it only looks at the end result and ignores the process. It treats all wrong answers the same—even ones that were close (“near-misses”) and ones that were totally off.
The key idea: give partial credit for “near-misses”
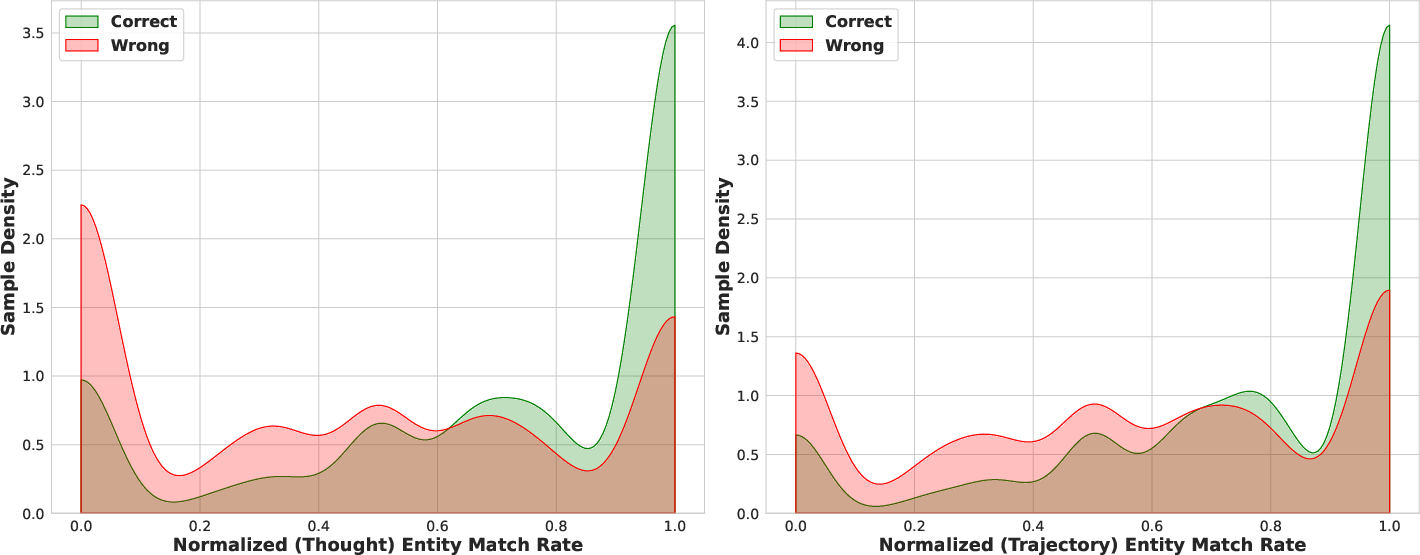
The authors found a strong positive link between:
- How many ground-truth entities an agent correctly mentions during reasoning (the “entity match rate”),
- And whether the final answer is correct.
So they created E-GRPO (Entity-aware GRPO), which adds a bonus for wrong answers based on how many of the right entities the agent found. The more correct entities the agent mentions, the more partial credit it gets.
Think of it like grading a math problem:
- You don’t only check if the final number is right.
- You also give points for showing the right steps, even if the last step is wrong.
Why is this cheap and practical?
- The entity list already exists from synthetic data generation.
- Matching entities inside the agent’s thoughts is simple (string matching).
- No extra labeling or expensive “step-by-step judge” models are needed.
What they found and why it matters
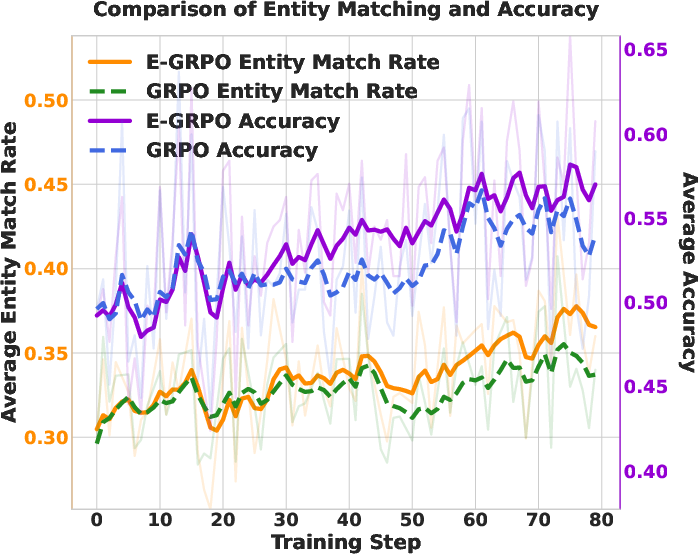
After testing on 11 different benchmarks (covering both standard question answering and tougher “deep research” tasks), they found:
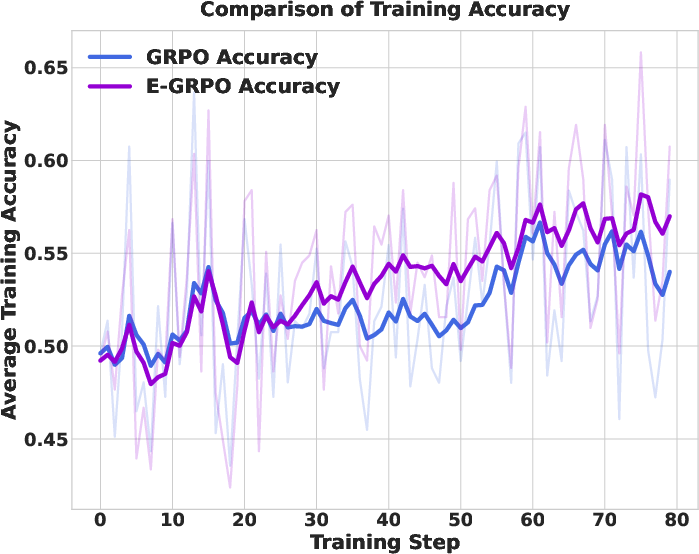
- E-GRPO consistently beat the regular GRPO baseline.
- Agents trained with E-GRPO were more accurate across many datasets.
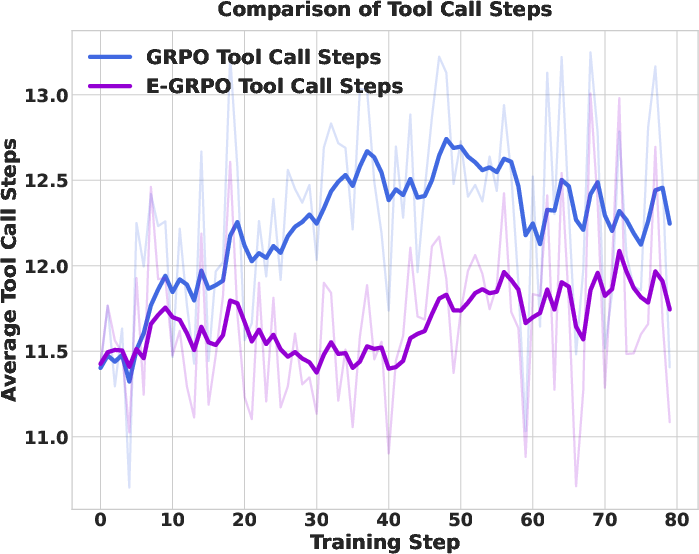
- They also used fewer tool calls (fewer searches/visits), meaning they learned to reason more efficiently.
- E-GRPO was especially strong in Pass@3 (succeeding within three attempts), suggesting it helps agents explore promising solution paths and build diverse strategies.
They also showed:
- The more entities the agent matched during reasoning, the higher its accuracy—supporting their main idea.
- There’s a sweet spot for how much partial credit to give. Too little behaves like normal GRPO; too much can distract from getting the final answer right. A moderate balance worked best.
Why this research could matter in the real world
This work is useful if you want AI agents to:
- Handle complex, multi-step web tasks,
- Learn from near-misses instead of throwing them away,
- Be more efficient, using fewer searches and page visits,
- Improve quickly without needing expensive extra labels or complicated training setups.
In short, E-GRPO turns “almost-right” attempts into valuable lessons. By giving partial credit for finding the right pieces of the puzzle—even when the final answer is wrong—the agent learns smarter, faster, and more efficiently. This could make future web-searching AIs more reliable for research, homework help, fact-checking, and other knowledge-heavy tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored, with concrete directions for future research.
- Reliance on synthetic datasets with ground-truth entities: How to obtain reliable entity sets for human-authored, real-world tasks where no synthesis metadata is available (e.g., via automatic entity extraction, KB linking, or distant supervision), and how reward noise affects learning in such settings.
- Exact string matching for entity detection in thoughts: Robustness to aliases, synonyms, abbreviations, coreference, paraphrases, and morphological variants is unaddressed; evaluate fuzzy matching, entity linking, and canonicalization to reduce false negatives and improve reward fidelity.
- Multilingual robustness: The entity-matching method for non-English languages (e.g., Chinese in BrowseComp-ZH) is unspecified; assess cross-lingual alias resolution, script normalization, and multilingual entity linking.
- Reward gaming risk: The agent can earn credit by naming entities in thoughts without verifying them or grounding in observations; develop safeguards (evidence-linked matching, penalizing unsupported mentions, citation checks) and measure whether E-GRPO increases hallucinated or ungrounded entity mentions.
- Credit assignment scope: Entity matching is computed only over “thought” text, ignoring entities discovered in tool outputs or observations; explore step-level rewards tied to tool feedback and evidence grounding rather than thoughts alone.
- Group-normalized entity reward (using γ_max): Sensitivity to group size G, sampling variance, and instability when γ_max=0 or when all rollouts are wrong is not analyzed; conduct ablations on G, variance analysis, and alternative normalizations that reduce sensitivity to group composition.
- Hyperparameter α selection: Only static α is explored with limited ablation; investigate adaptive schedules (e.g., annealing, context-aware α), meta-learning, or bandit tuning across tasks/models to balance entity rewards and final-answer accuracy.
- Token-level advantage application: Advantages are applied uniformly to all tokens in a rollout; compare with per-step/per-token credit assignment (e.g., reward shaping when an entity is first correctly grounded) to improve granularity and stability.
- Theoretical grounding: Provide analysis of convergence, bias, and variance properties of E-GRPO’s dense reward shaping; clarify the conditions under which optimizing a proxy (entity match rate) guarantees improvement in task accuracy.
- Importance weighting of entities: All entities are treated equally, yet some are more pivotal to the final answer; explore learning or estimating per-entity importance weights (e.g., via graph centrality or causal relevance) and test their impact on performance.
- Handling distractors and noisy entities: Synthetic pipelines inject fuzzed/obfuscated entities; quantify robustness when ground-truth entity lists include irrelevant or misleading items, and design noise-aware reward formulations.
- Applicability beyond entity-centric tasks: Validate E-GRPO on domains where entities are not the backbone (math/code/procedural reasoning), and compare against PRMs or other process-level signals suited to those domains.
- Effect on reasoning style and verbosity: E-GRPO may incentivize explicit entity enumeration; measure changes in thought length, readability, and cognitive load, and study cost-accuracy trade-offs under token budgets.
- Overlength/format error handling: Assigning zero reward and excluding overlength rollouts from loss may bias learning and mask failure modes; evaluate alternative strategies (e.g., truncated credit, curriculum constraints) and quantify their prevalence and impact.
- Tooling and extraction dependencies: The Visit tool uses Qwen3-30B for content extraction; analyze how tool quality and configuration (retriever, browser, extractor models) affect entity matching and E-GRPO gains, and test portability across tool stacks.
- Evaluation reliability: LLM-as-Judge may introduce bias; validate with human annotation, exact-match/EM+F1 baselines, or multi-judge consensus, and report inter-rater agreement and statistical significance of improvements.
- Reproducibility and environment variability: Web results fluctuate (search engine dynamics, indexing changes); provide cached corpora or controlled replay environments, report seeds, and quantify variance across runs.
- Scaling behavior and compute: Training uses modest data (11k SFT, 1k RL); establish scaling laws (data size, rollout count, group size), compute budgets, and sample-efficiency curves to guide practical deployment.
- Alternative fine-grained rewards: Compare E-GRPO to other inexpensive proxies (evidence coverage, citation consistency, retrieval quality, claim-veracity checks) to determine when entity matching is optimal versus complementary.
- Pass@k dynamics: Improvements are highlighted for Pass@3; analyze Pass@k beyond 3, success diversity, and rollout correlation to understand how entity-aware reward affects exploration breadth.
- Causality vs. correlation: The observed positive correlation between entity match rate and accuracy lacks causal tests; perform controlled interventions (e.g., masking entities, injecting spurious entities) to disentangle causality from correlation.
- Fairness across question complexity: Normalizing by entity count m may still disadvantage questions with many entities; test alternative normalizations (e.g., per-entity thresholds, diminishing returns) to ensure fair credit across varying complexity.
- Data and code artifacts: Clarify release of synthesis entity annotations, matching scripts, prompts, and evaluation pipelines to enable third-party replication and stress-testing under alternative settings.
Practical Applications
Practical Applications of “Repurposing Synthetic Data for Fine-grained Search Agent Supervision (E-GRPO)”
Below are actionable, real-world uses of the paper’s findings and method, grouped by deployment horizon. Each item notes relevant sectors, likely tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Enterprise research assistants with lower cost-per-task
- Sectors: software/SaaS, enterprise search, consulting
- What: Swap outcome-only GRPO with E-GRPO in existing ReAct-style research agents to increase accuracy while reducing tool calls, lowering API and crawling costs for market/competitive research.
- Tools/products/workflows: RL fine-tuning module for entity-aware reward; logging dashboards tracking entity coverage and tool-call budgets; plug-in for TRL or similar RL libraries.
- Assumptions/dependencies: Access to entity-centric synthetic datasets or a generation pipeline that stores ground-truth entities; simple α tuning; governance for web scraping.
- Newsroom fact-checking and editorial research
- Sectors: media, journalism
- What: Agents trained with E-GRPO to verify claims by progressively matching named entities (people, places, organizations) and citations; “entity coverage” used as a reliability signal.
- Tools/products/workflows: Browser/Search tools; entity-coverage meter in UI; automatic claims-to-entities mapping; near-miss mining to improve training data.
- Assumptions/dependencies: High-precision entity recognition/linking to avoid brittleness of exact string match; source provenance retention.
- Legal e-discovery and due diligence triage
- Sectors: legal, compliance
- What: Use entity coverage as an intermediate quality metric during document triage (parties, jurisdictions, statutes) to surface promising “near-miss” search trails for human review.
- Tools/products/workflows: On-prem document search + entity extraction; dashboards showing entity coverage per query; audit logs of agent reasoning.
- Assumptions/dependencies: Confidential data handling; domain ontologies (e.g., statutes, case IDs); stricter matching than exact strings (entity linking/coreference).
- Healthcare literature search and guideline summarization
- Sectors: healthcare, life sciences
- What: E-GRPO-trained agents prioritize key biomedical entities (conditions, genes, drugs, outcomes) to improve recall and reduce browsing depth in PubMed/clinical guidelines.
- Tools/products/workflows: Integration with PubMed/clinical guideline APIs; ontology-backed entity match (UMLS, SNOMED CT, MeSH); coverage score for QA/summarization.
- Assumptions/dependencies: Regulatory guardrails; high-precision domain NER; licensed access to literature.
- Financial analyst desk research and vendor/ESG screening
- Sectors: finance, procurement
- What: Faster research loops with fewer tool calls; entity coverage over tickers, issuers, facilities, ESG categories as decision support.
- Tools/products/workflows: Finance-aware entity dictionary; integration with internal/external terminals and news feeds; confidence and cost dashboards.
- Assumptions/dependencies: Data licensing; strong ticker/issuer disambiguation; risk controls for hallucinated entities.
- Academic and student research copilots with source coverage guidance
- Sectors: education, academia
- What: Copilots that expose entity coverage and source grounding to guide literature discovery and citation practices.
- Tools/products/workflows: UI widget showing “entities matched so far”; workflows for planning queries; lightweight SFT→E-GRPO training stack.
- Assumptions/dependencies: Institution-specific access to libraries; safe browsing policies; multilingual entity mapping as needed.
- Customer support knowledge retrieval and deflection
- Sectors: customer experience, SaaS
- What: Train support agents to match product entities (features, SKUs, error codes) and surface fewer, more relevant docs per case.
- Tools/products/workflows: Product entity catalogs; RL training on synthetic tickets with embedded entities; integration with help centers.
- Assumptions/dependencies: Up-to-date product taxonomy; guardrails against suggesting obsolete fixes.
- Software documentation and API troubleshooting search
- Sectors: software engineering
- What: Agents trained to prioritize API/class/function entities to find fixes with fewer page visits.
- Tools/products/workflows: Entity inventories mined from code/docstrings; reward shaping over API symbol matches; IDE or portal integration.
- Assumptions/dependencies: Accurate symbol extraction and disambiguation across versions; synthetic tasks that embed API entities.
- OSINT and cyber threat intelligence triage
- Sectors: cybersecurity, public sector
- What: Use entity-aware rewards over IOCs, CVEs, actors, TTPs to improve signal extraction and reduce browsing overhead in investigations.
- Tools/products/workflows: Security-specific NER; threat intel feeds; case notebooks with entity coverage timelines.
- Assumptions/dependencies: Legal/ethical collection; resilience to obfuscation and multilingual content.
- Patent prior-art and IP landscape search
- Sectors: IP, R&D
- What: Improve search agents via rewards on matched entities (assignees, IPC/CPC codes, claims) to quickly narrow candidate sets.
- Tools/products/workflows: Patent corpora connectors; entity linkage to assignees/classes; coverage-based triage UI.
- Assumptions/dependencies: Domain-specific entity linking; access/licensing to full-text patent databases.
- Better training/evaluation operations for agent teams
- Sectors: AI/ML platforms, MLOps
- What: Adopt entity match rate as a training-time and offline evaluation KPI; exploit “all-wrong group” gradients via E-GRPO to stabilize training and reduce compute.
- Tools/products/workflows: RL pipelines with entity-aware reward; experiment tracking of match rate vs. accuracy; cost dashboards linked to tool-call counts.
- Assumptions/dependencies: Storage of entity traces from data synthesis; consistent formatting for thoughts/actions; hyperparameter α calibration.
Long-Term Applications
- Process-level reward generalization beyond entities
- Sectors: software, education, code, math
- What: Extend the “structure-aware dense reward” idea to other domains (e.g., proof steps, API usage graphs, function contracts) as a PRM-free alternative for process supervision.
- Tools/products/workflows: Structure extractors (ASTs for code, proof schema detectors); hybrid reward models mixing outcome + structure coverage.
- Assumptions/dependencies: Robust structural extractors; defenses against reward hacking (superficial step padding).
- Regulatory-grade auditability of AI research agents
- Sectors: policy, compliance, high-stakes industries
- What: Standardize “entity-trace logs” as auditable provenance showing how conclusions were formed and which entities were considered.
- Tools/products/workflows: Provenance schemas; attestations tied to entity coverage; conformance testing suites.
- Assumptions/dependencies: Emerging standards for AI provenance; legal clarity on acceptable evidence.
- Autonomous systematic reviews and evidence synthesis at scale
- Sectors: healthcare, public policy, academia
- What: Orchestrate large-scale agents that maximize coverage over predefined entity schemas (PICO elements, interventions, outcomes) for living reviews.
- Tools/products/workflows: Domain ontologies; de-duplication and contradiction tracking; human-in-the-loop adjudication.
- Assumptions/dependencies: Access to paywalled literature; high-recall domain NER; robust de-biasing across sources.
- Multimodal deep-search agents (text + image/video)
- Sectors: retail, robotics, media, manufacturing
- What: Apply entity-aware rewards to entities recognized in images/videos (logos, parts, scenes) to guide browsing/planning and reduce sensory tool calls.
- Tools/products/workflows: OCR and visual entity linkers; unified reward across modalities; multimodal ReAct variants.
- Assumptions/dependencies: Reliable multimodal entity detection; compute budgets for vision models.
- Cross-lingual, low-resource, and region-specific monitoring
- Sectors: global policy, supply chain, risk intelligence
- What: Train agents with multilingual entity alignment to track policies, suppliers, or incidents across languages.
- Tools/products/workflows: Cross-lingual knowledge graphs; transliteration/alias tables; language-specific crawling.
- Assumptions/dependencies: Quality of multilingual NER/linking; local data access and legal compliance.
- Dynamic reward from live web without pre-stored entities
- Sectors: software platforms, research tooling
- What: Automatically infer “ground-truth entity sets” on-the-fly via retrieval + entity linking, enabling E-GRPO without synthetic data.
- Tools/products/workflows: On-policy retrieval to bootstrap entity sets; consensus/aggregation across sources to create pseudo-ground truth.
- Assumptions/dependencies: Noise-robust entity consolidation; safeguards against spurious correlations.
- Integration with tree/planning algorithms for complex tasks
- Sectors: autonomous agents, applied AI
- What: Combine E-GRPO with TreeRPO/planning to reward branch expansions that increase entity coverage, improving exploration efficiency.
- Tools/products/workflows: Hybrid planners; branch-level entity coverage scoring; compute-efficient sampling strategies.
- Assumptions/dependencies: Scalable on-policy search; careful variance control to prevent instability.
- Safety and hallucination mitigation via entity-aware constraints
- Sectors: safety-critical AI, healthcare, finance
- What: Penalize unsupported or fabricated entities and reward corroborated ones to reduce hallucinations and enforce cite-as-you-say behavior.
- Tools/products/workflows: Real-time evidence checkers; negative rewards for unverifiable entities; source-consistency validators.
- Assumptions/dependencies: Dependable verification tools; robust citation extraction; defense against adversarial sources.
- Entity-first browser/tooling ecosystem
- Sectors: developer tools, data platforms
- What: New search/browse APIs that return structured entities with every call, making entity-aware reward “zero-cost” and encouraging ecosystem standardization.
- Tools/products/workflows: Entity-enriched SERP APIs; instrumented headless browsers; JSON schemas for entity traces.
- Assumptions/dependencies: Search/hosting providers exposing structured entity endpoints; standard formats across tools.
- Auto-curriculum and difficulty shaping via entity graphs
- Sectors: AI training platforms, education
- What: Adjust task difficulty by manipulating entity graph obfuscation or coupling to progressively challenge agents, guided by match-rate learning curves.
- Tools/products/workflows: Entity-centric curriculum generators; adaptive α scheduling; learning progress estimators.
- Assumptions/dependencies: High-quality synthesis pipelines; robust measurement of match rate across tasks.
- Commercial SDKs and marketplaces for entity-aware agent training
- Sectors: AI tooling, cloud providers
- What: Packaged E-GRPO training kits and datasets with entity traces, plus hosted services for training/evaluation.
- Tools/products/workflows: Managed RL fine-tuning; dataset hosting with entity annotations; benchmarking harnesses.
- Assumptions/dependencies: Licensing of datasets; privacy and compliance for enterprise data.
Notes on feasibility across applications
- Core dependencies: availability (or automatic construction) of entity traces; reliable entity recognition/linking (beyond exact string match); hyperparameter α tuning (empirically ~0.3 works best in the paper); stable ReAct-style tool integration; budget/latency controls for tool calls.
- Risk and mitigation: reward hacking (agents over-mention entities) can be mitigated with penalties for unsupported mentions, deduplication, and source verification; domain ontologies and entity linking reduce brittleness; guardrails for overlength/format errors as in the paper.
- Transferability: although demonstrated for web search agents, the entity-aware reward principle applies wherever target-relevant “units” can be extracted (entities, symbols, steps, APIs), enabling broader process-level supervision without costly PRMs.
Glossary
- Advantage normalization: Normalizing advantages within a rollout group to stabilize learning signals. "while these rollouts contribute to the advantage normalization (i.e., computing the group's mean and standard deviation), they are excluded from the final loss computation"
- Entity-aware Group Relative Policy Optimization (E-GRPO): A reinforcement learning framework that incorporates entity-level signals into the reward to provide fine-grained supervision. "We introduce Entity-aware Group Relative Policy Optimization (E-GRPO), a novel framework that formulates a dense entity-aware reward function."
- Entity-aware reward: A reward formulation that grants partial credit based on matched entities, not just final correctness. "We introduce E-GRPO, a novel RL framework that enhances policy optimization by formulating a dense, entity-aware reward function"
- Entity match rate: The proportion of ground-truth entities mentioned during an agent’s reasoning trajectory. "validates our core hypothesis: the entity match rate serves as a powerful proxy for factual correctness"
- Entropy-based rollout mechanism: A technique that encourages exploration by injecting entropy into rollout selection or scoring. "Notable advancements within this paradigm, such as ARPO, have adapted the framework with an entropy-based rollout mechanism for complex multi-turn web search settings."
- Fuzzing: An entity-focused obfuscation operation that replaces specific entities with ambiguous descriptions during data synthesis. "Fuzzing, which substitutes specific entities with more ambiguous, general descriptions."
- Group Relative Policy Optimization (GRPO): A policy optimization method that computes advantages relative to a group of rollouts and uses outcome-based rewards. "E-GRPO consistently and significantly outperforms the GRPO baseline."
- Group-relative advantage: An advantage value computed relative to the mean and variance of rewards within a rollout group. "This reward is then used to compute a group-relative advantage."
- Importance sampling ratio: The ratio between new and old policy probabilities used to reweight gradients in off-policy updates. "where $r_{i,j}(\theta) = \frac{\pi_{\theta}(\mathcal{H}^{(i)}_j \mid q, \mathcal{H}^{(i)}_{j-1})}{\pi_{\theta_{\text{old}(\mathcal{H}^{(i)}_j \mid q, \mathcal{H}^{(i)}_{j-1})}$ is the importance sampling ratio."
- Injection: An entity-focused operation that replaces named entities with descriptive facts to increase question difficulty. "Injection, which replaces named entities with descriptive facts"
- KL-divergence regularization: A term that penalizes deviation from the old policy to prevent instability; often removed for exploration in GRPO variants. "Following DAPO, we remove the KL-divergence regularization term in GRPO and apply the \"clip-higher\" method"
- LLM-as-Judge: An evaluation setup where a LLM assesses the correctness of answers. "evaluated for correctness using Qwen2.5-72B-Instruct under the LLM-as-Judge setting."
- Mixture-of-Experts (MoE): A model architecture that routes inputs to specialized expert sub-networks to improve efficiency and capacity. "covering different model sizes and architectures (dense and MoE)."
- Near-miss: An incorrect response that contains substantially correct intermediate reasoning or entities, thus providing informative training signal. "a \"near-miss\" that correctly identifies the actor (Leonardo) and the film (Titanic) but fails on the final answer"
- Normalized entity match rate: The entity match rate rescaled within a rollout group to the 0–1 range to stabilize reward computation. "We utilize the normalized entity match rate rather than the raw rate"
- Open-world web exploration: An evaluation or training environment where the agent interacts with the live, dynamic web. "an open-world web exploration (Web) environment."
- Outcome-based reward: A sparse reward signal that depends only on final answer correctness, ignoring intermediate reasoning quality. "Existing GRPO-like frameworks for search agents typically employ outcome-based reward."
- Overlength rollouts: Trajectories that exceed token or tool-call limits and are penalized or excluded to prevent training instability. "Overlength rollouts (i.e., those exceeding token or tool-call limits) are also assigned a reward of 0."
- Pass@1: The fraction of questions correctly answered on the first attempt. "We report the average Pass@1 over all test samples"
- Pass@3: The fraction of questions correctly answered within three sampled rollouts. "as well as the Pass@3 across three rollouts."
- Policy collapse: A failure mode where the policy converges to degenerate behaviors that harm performance. "directly optimizing on these rollouts can lead to policy collapse."
- Process Reward Model (PRM): A model that scores intermediate reasoning steps to provide dense, step-level supervision. "evaluating each intermediate step with a Process Reward Model (PRM)"
- Random walk: A stochastic traversal over a graph used to construct complex knowledge structures for question generation. "constructs a complex knowledge graph via a random walk from a seed entity"
- ReAct: A paradigm that interleaves reasoning (“thought”) and actions, enabling tool-integrated multi-step decision-making. "We adopt the ReAct paradigm for search agents."
- Reward collapse: A training issue where reward signals become uninformative, leading to poor learning dynamics; mitigated by SFT. "This step, following~\cite{dong2025arpo}, mitigates reward collapse and ensures the model understands the agentic format before RL."
- Reward sparsity problem: The challenge that arises when rewards depend only on final outcomes, providing little guidance for learning. "This mechanism leads to the reward sparsity problem"
- Tree-based search: A sampling strategy that explores multiple reasoning branches to derive step-level advantages. "employing complex sampling mechanisms (e.g., tree-based search)"
- Upper clipping bound ("clip-higher" method): An increased PPO-style clipping threshold to encourage exploration by allowing larger policy updates. "apply the \"clip-higher\" method, which increases the upper clipping bound $\varepsilon_{\text{high}$"
Collections
Sign up for free to add this paper to one or more collections.